
Chahinez Meriem Bentaouza
Department of Computer Science, Modeling and Optimization of Industrial Systems Laboratory, Faculty of Science, University of Science and Technology of Oran, P.O. Box 1505, El Menaour, Oran, Algeria
Mohamed Benyettou
Department of Computer Science, Faculty of Science and Computer Science, University of Mostaganem, B.P. 188, Mostaganem, Algeria
Pakistan Journal of Biological Sciences
Year: 2014 | Volume: 17 | Issue: 3 | Page No.: 335-345







ABSTRACT
This study presents the compression of microscopic medical images by Support Vector Machines using machine learning. The visual cortex is the largest system in the human brain and is responsible for image processing such as compression, because the eye does not necessarily perceive all the details of an image. Medical images are a valuable means of decision support. However, they provide a large number of images per examination that can be transmitted over a network or stored for several years under the law imposed by the country. To apply the reasoning of biological intelligence, this study uses Support Vector Machines for compression to reduce the pixels of medical images in order to transmit data in less time and store information in less space. The results found by using this method are satisfactory for compression though the time must be improved.
PDF Abstract XML References Citation
Received: March 15, 2013;
Accepted: April 02, 2013;
Published: November 25, 2013
How to cite this article
Chahinez Meriem Bentaouza and Mohamed Benyettou, 2014. Support Vector Machines for Microscopic Medical Images Compression. Pakistan Journal of Biological Sciences, 17: 335-345.
DOI: 10.3923/pjbs.2014.335.345
URL: https://scialert.net/abstract/?doi=pjbs.2014.335.345
DOI: 10.3923/pjbs.2014.335.345
URL: https://scialert.net/abstract/?doi=pjbs.2014.335.345
INTRODUCTION
The human visual system is more very sensitive to changes but the removal of a significant portion of the information is only slightly visible and therefore not noticeable to the eye (Herellier, 1993). Today, digital images have about a million pixels, with each pixel requiring three bytes for RGB (Red, Green, Blue) images. Without compression, this is 3MB for a single image (Chirollet, 2005).
In addition, medical images represent a large enough depending on the tool acquisition. For example, the scanner is 200 MB to 1 GB per examination, an MRI (Magnetic Resonance Imaging) is an average of 50 MB per examination (Seret and Hoebeke, 2006) and the resulting images of a microscope of up to 1GB for examination (Brisset, 2008). In all, the annual production of a medical imaging center is estimated at several hundred or even thousands of GB. So, storage for these types of files on disks and the transfer will also take considerable time (Dillenseger and Moerschel, 2009).
Storage should be done for short-term use in order to respect the laws forcing hospitals to archive medical records of patients for several years. Consequently, image compression is the only solution for archiving despite the increase in storage capacity (Hyvarinen et al., 2008). Many researches have focused on compression by statistical learning methods or machine learning methods (Hu and Hwang, 2002). The Compression of digital images is consequently one of the most active areas research.
Saad et al. (1998) Mahmoud presented an Artificial Neural Network (ANN) and Vector Quantization for image compression. Better reconstructed images can be obtained if a variety of different activity images are used in the design phase of the proposed neural system (1993). Similarly, the Principal Component Analysis (PCA) technique and (ANN) Multi Layer Perceptron (MLP) architecture for compression of Lena image was proposed. The result shows the good quality of reconstructed image (Gaidhane et al., 2010). Also, compression was made by the Fourier Transform (FT). It can be stated that the use of FT is an important tool which offers an improvement in image compression (Singh et al., 2009). Forchhammer et al. (2011) proposed Moving Picture Experts Group (MPEG) coded images and Discrete Cosine Transform (DCT) (2011).
The growth of medical imaging involves storage and transmission of large amounts of digital information. It is possible to reduce the data amount with caution so that the result is very similar to the original, if not identical, to the human eye without losing information so as to not distort the medical diagnosis.
For medical imaging, an ANN MLP architecture was applied to digital X-ray image compression with a high reconstruction quality (Steudel et al. 1995). The nonlinear Principal Component Analysis (PCA) technique shows the best compression results in combination with the ANN MLP of the mammographic image (Meyer-Baese 2000). According to Ziguang et al., the Binary Decision Diagrams compression technique performs better than WINZIP in terms of compression ratio though the execution time is rather high (2009). The authors present Coded Excitation systems Ultrasound Medical Imaging which improves the Signal-to-Noise Ratio (SNR) and resolution (Toosi and Behnam, 2009). Alternatively, the Discrete Cosine Transform (DCT) provides medical images of the brain reconstructed in high-fidelity compression (Al-Fayadh et al., 2009). Robinson and Kecman, 2003 deduced that Combining Support Vector Machine (SVM) with the Discrete Cosine Transform (DCT) produces better image quality than the JPEG compression algorithm (2003).
Finally, although all the proposed approaches are efficient , they are not sufficient to achieve very good compression. In this study, we propose Separator with Vast Margin (SVM) for performance in machine learning and classification (Sahbi and Geman, 2006; Chiou et al., 2009; Chen, 2009; Bentaouza and Benyettou, 2010) applied to microscopic image of brain tumor because these images contain a lot of redundant information.
The objective of the study is to find out that SVM is the most frequently used method and can be applied to compression of microscopic images.
MATERIALS AND METHODS
Image compression: Compression is the action used to reduce the physical size of information block. By compressing the data, we can place more information in the same storage space, or use less time to transfer through a network. Since the images require high capacity, compression becomes an essential part that can reduce the number of pixels by exploiting the informational redundancy in the image (Incerti, 2003).
Physical and logical compression: The physical compression acts directly on the data and it is to watch a redundant data bit stream to another. But the logic compression is performed by substituting information in a different representation (Incerti, 2003). In this article, we treat the logical compression.
Symmetric and asymmetric compression: A symmetric compression method uses the same algorithm and requires the same computing capacity, both for compression than for decompression. Asymmetric compression methods require more work in one direction than another. Normally, the compression step requires much more time and system resources than the decompression stage. Incerti (2003) We can't discuss of this point because we are interested by the compression and the decompression is our perspectives.
Lossy and lossless compression: This is the most important criterion for comparing compression algorithms.
Lossy compression methods make it possible to find an approximation of the image. The data are removed and cannot be to recover. The losses are generally undetectable with the eye but the initial image is not identical to the decompressed version. These algorithms are applicable to data with high levels of redundancy, such as images, or sounds. Joint Photographic Expert Group (JPEG) and Moving Picture Experts Group (MPEG) are lossy compression algorithms.
Lossless compression methods make it possible to find exactly the pixels of the original image. Thus, after decompression, the image is rebuilt perfectly and identical to the initial image. Much of the compression schemes used are lossless compression algorithms. Shannon-Fano, Huffman and Run-Length Encoding (RLE) are lossless compression algorithm.
In this research, we can’t tolerate the compression with information loss because we have sensitive images which are the important medical information for their archiving.
CRITERION OF COMPRESSION
Compression quality: Peak Signal to Noise Ratio (PSNR) measures the relationship between information and noise in an image. It is expressed with a logarithmic scale in decibels (dB) because it can take a very large range of values:
| (1) |
EQM is the mean square error calculated between the original image and the reconstructed image:
| (2) |
where, n is the number of pixels in the image, Xij is the value of the pixel (i, j) in the original image and Yij is the value of the pixel (i, j) in the reconstructed image. The PSNR gives only a rough idea of the quality of the reconstructed image after decompression, does not replace the visual assessment of the image. This part is not used in our article because we are interested by the compression.
Compression ratio: The compression ratio is used to refer to the ratio between the uncompressed data size and the compressed data size. There are several ways to calculate the compression ratio:
| • | Bit rate: |
| (3) |
| • | Compression ratio: |
| (4) |
| • | Compression rate: |
| (5) |
| • | Gain compression: |
| (6) |
We used to evaluate compression of medical images by SVM using rate compression as seen in Eq. 5.
Support vector machines: The support vector machine is a new method for classification of data. This technique of supervised classification suggested in 1992 by Vladimir VAPNIK (Vapnik, 1998) results from the statistical theory of the training. Now, it is an active zone of search for machine learning (Bentaouza and Benyettou, 2010). The fundamental idea is to build an optimal learning machine for better generalization, having:
| • | A definite surface in an optimal way |
| • | In general non linear in the space of entry |
| • | Linear in a dimensional space more raised |
| • | Implicitly defined by a kernel function |
Binary SVM: The principal idea of the binary SVM is to implicitly trace data with a dimensional space more raised by the intermediary of a kernel function and to solve a problem of optimization to identify the hyperplane whose margin is maximum which separates the examples from training (Vapnik, 1998). The hyperplane is based on the support vector i.e., a whole of examples of training being on the margin. New examples are classified according to the side of the hyperplane. The problem of optimization generally is formulating in a manner and takes account of the inseparable data while penalizing distort them classifications.
Separable linear case: The solution of the problem of optimization (Burges, 1998) is as follows:
| • | Result of the stage of training: The optimal hyperplane is: |
| (7) |
| (8) |
| (9) |
| αi Correspond to the closest points, i.e., the support vectors that are no null. They are found by solving the following equation: |
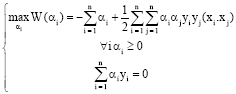 | (10) |
| • | Result of the stage of test: The function of decision is obtained by: |
| (11) |
Non separable linear case: The algorithm established for the separable linear case cannot be used in many real problems. In general, of the noisy data will make separation linear impossible. For this there, the approach above can be extended to find a hyperplane that minimizes the error on the training example (Training error). This approach also indicated under the name of “soft margin hyperplane” (Vapnik, 1995). We introduce the “slack variable” ξi the error of the example xi with ξi>0, i = 1,…, n. The value of ξi indicates, where are xi before a hyperplane of separation:
| • | If ξi≥1 then xi is badly classified |
| • | If 0<ξi<1 then xi is correctly classified but is inside margin |
| • | If ξi = 0 then xi is correctly classified and is outside the margin or with the band of the margin |
Alternatively, the expression of the function changes from:
where, C is the weight of error, it is a parameter to be chosen by the user, larger C corresponding to assign a higher penalty with the errors, is generally taken 1/n.
Non linear case: How the methods above can be generalized if the function of decision is not a linear function of the data? In the linear case space used is Euclidean space. Separation by hyperplanes is a relatively poor framework of classification, bus for much of case; the examples which one wants to separate are not separable by hyperplanes. To continue to profit from the theory which justifies the search for hyperplanes of maximum margin while using more complex surfaces of separation (nonlinear), VAPNIK (Boser et al., 1992) suggests separating not items xi but of representatives this points Xi = φ(xi) in a space F of dimension much larger, than VAPNIK calls: feature space. One gives oneself a nonlinear function noted φ, such as φ: Rm→F. The separation nonlinear of maximum margin consists in separating the points Xi = φ(xi), as the function of decision is expressed exclusively using scalar products is thus, one in practice never uses the function directly but only the kernel K is defined by: K(x, x') = φ(x).φ(x') it is a nonlinear scalar product. Therefore, the problem is solved; it is enough to make a transformation: xi.xj→φ(xi)φ(xj) in all the formulas of hard margin by using a type of following kernel (Cornuejols, 2002) function:
| • | Polynomial function: |
| (12) |
| • | Radial function: |
| (13) |
| • | Sigmoid function: |
| (14) |
The solution of optimization problem in the non-linear case is:
| • | Result of the stage of training: The optimal hyperplane is: |
| (15) |
| (16) |
| (17) |
| αi is found by solving the following equation: |
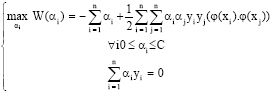 | (18) |
| • | Result of the stage of test: The function of decision is obtained by: |
| (19) |
Multiclass SVM: There are several methods for the multiclass (Platt, 1999) but in this article, we tried out One Versus Rest (OVR) which is implemented in multiclass SVM. OVR is conceptually the method of simplest SVM multiclass. Here we build of the binary classifiers of K SVM: classify 1 positive against all other negative classes, classifies 2 against all other classes..., class K against all other classes. The combined function of decision of OVR chooses the class of a sample which corresponds to the maximum value of the binary functions of decision of K indicated by the other positive hyperplane (Statnikov et al., 2005). While thus making, hyperplanes of decision calculated by K SVM which call into question the optimality of multiclass classification.
RESULTS
Configuration: The data base is extracted from classification of OMS (Brucher et al., 1999); the ranks are like degrees of malignity, indicating the biological behavior. In the atlas used, the various tumor entities are also grouped according to their rank which corresponds to the images taken to make our compression by SVM.
Images used are Astrocytoma of grade 2, tumors of the central nervous system, whose growth is slow on different categories according to their main localization.
The machine used to carry out these experimentation is a PC (Pentium 4, 2.80 GHz with 2 GO of RAM).
And concerning the programming two essential tools were used:
| • | C++ Builder 6 under Windows Virtual PC to create a graphic interface summer developed on the one hand for the pretreatment of the classification of the medical images which consists in extracting significant information in RGB (Red, Green and Blue) which will make the object of the supervised training, so, the input of the Multi-classes SVM |
| • | SVM Multiclass (OVR) under Windows Virtual PC is a free tool (Joachims, 1999) which was developed for the scientific research whose problem of optimization was included |
Pretreatment: We have several pictures of different types and sizes where each image is divided into several blocks of 16x16 pixels, this block will be grouping identical pixels in a class and then we’ll start learning about the block using SVMs because it is easier to make learning as a block to learning a whole image.
The result of learning gives us the support vectors and it is these points that there will be compression.
The compression rate for each block is calculated in this form:
| (20) |
The total compression rate for sample image is calculated in this form:
| (21) |
The number of pixels in sample image is calculated in this form:
| (22) |
The parameters chosen for the polynomial function and the radial function are parameters which minimize the learning error and maximize the classification rate as presented in the article (Bentaouza and Benyettou, 2010).
EXPERIMENTATION
Case 1: The sample used is Astrocytoma image with frontal section of 98x98 pixels for small image and 230x230 pixels for average image (Table 1).
The result obtained after the learning of all the blocks with the SVM on a small image is presented on figures (Fig. 1-4).
The result obtained after the learning of all the blocks with the SVM on an average image is presented on figures (Fig. 5-8).
| Table 1: | Features of a small and an average image in case 1 |
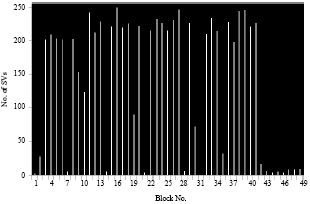 | |
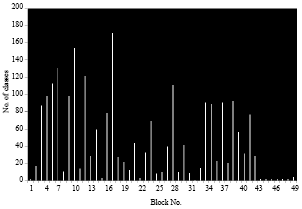
| Fig. 1: | Number of SVs for each block of a small image in case 1 |
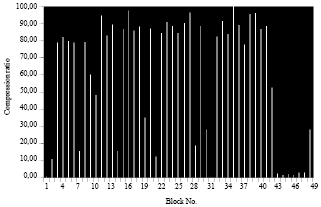 | |
| Fig. 2: | Compression ratio for each block of a small image in case 1 |
 | |
| Fig. 3: | Number of classes for each block of a small image in case 1 |
Note that in this case, the compression rate of the same image with different size is almost the same as it is for the polynomial function and for the radial function.
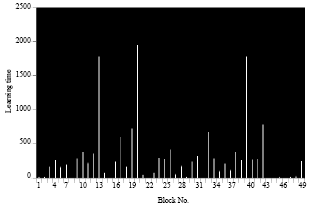 | |
| Fig. 4: | Learning time for each block of a small image in case 1 |
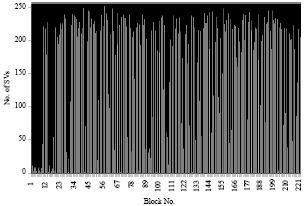 | |
| Fig. 5: | Number of SVs for each block of a average image in case 1 |
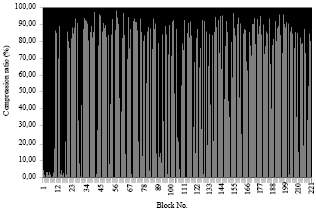 | |
| Fig. 6: | Compression ratio for each block of an average image in case 1 |
But it took a long time for the polynomial function but a less time for the radial function (Table 2 and 3).
Also, more than the number of pixels increases, more than the learning time is high because we have more blocks including more classes to learn.
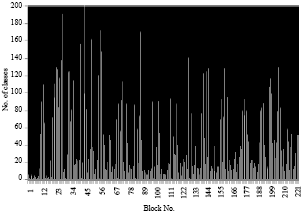 | |
| Fig. 7: | Number of classes for each block of an average image in case 1 |
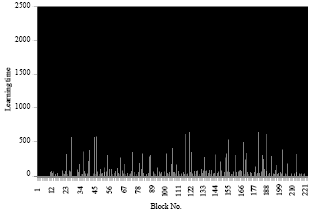 | |
| Fig. 8: | Learning time for each block of an average image in case 1 |
| Table 2: | Compression results for a small image in case 1 |
 | |
| Table 3: | Compression results for an average image in case 1 |
 | |
| Table 4: | Features of a small and an average image in case 2 |
And if we make a forecast for a third image pixels larger than the second, we can expect to have the same compression rate with a time of higher learning.
Case 2: The sample used is Astrocytoma image, fibrillary subtype with magnification of 100 of 98x98 pixels for small image and 229x229 pixels for average image (Table 4).
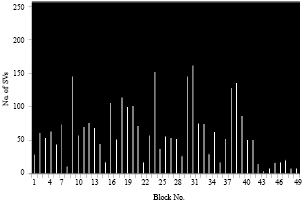 | |
| Fig. 9: | Number of SVs for each block of a small image in case 2 |
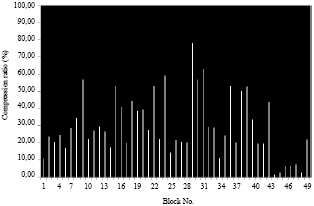 | |
| Fig. 10: | Compression ratio for each block of a small image in case 2 |
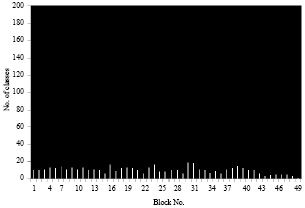 | |
| Fig. 11: | Number of classes for each block of a small image in case 2 |
The result obtained after the learning of all the blocks with the SVM on a small image is presented on figures (Fig. 9-12).
The result obtained after the learning of all the blocks with the SVM on an average image is presented on figures (Fig. 13-16).
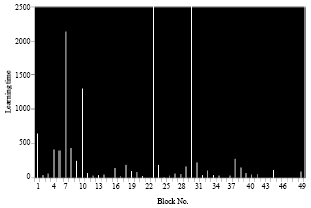 | |
| Fig. 12: | Learning time for each block of a small image in case 2 |
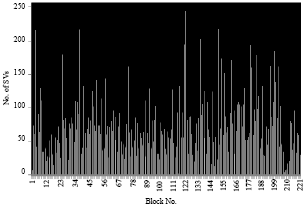 | |
| Fig. 13: | Number of SVs for each block of an average image in case 2 |
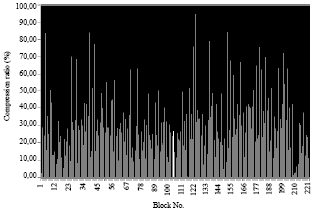 | |
| Fig. 14: | Compression ratio for each block of a small image in case 2 |
This case is identical to the first case point of view comparison between the polynomial function and the radial function except the difference is that the compression rate is smaller compared to the first case. Also learning time increased if the pixels is larger as the first case (Table 5 and 6).
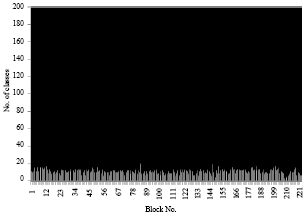 | |
| Fig. 15: | Number of classes for each block of an average image in case 2 |
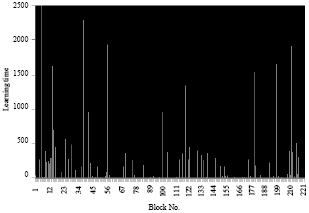 | |
| Fig. 16: | Learning time for each block of an average image in case 2 |
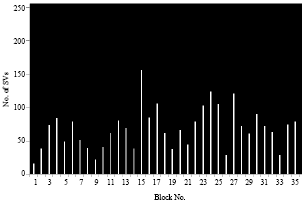 | |
| Fig. 17: | Number of SVs for each block of a small image in case 3 |
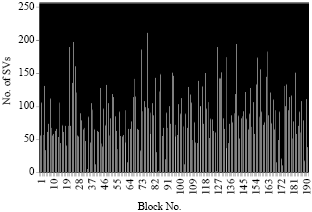
We notice despite the number of pixels of the first image is identical to the number of pixels of the second image, the number of Svs found is higher in the first image that in the second image because the number of classes learned is higher in the first case.
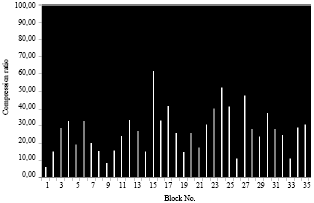 | |
| Fig. 18: | Compression ratio for each block of a small image in case 3 |
 | |
| Fig. 19: | Number of classes for each block of a small image in case 3 |
 | |
| Fig. 20: | Learning time for each block of a small image in case 3 |
Case 3: The sample used is Astrocytoma image, fibrillary subtype with magnification of 40 of 95x95 pixels for small image and 221x221 pixels for average image (Table 7).
The result obtained after the learning of all the blocks with the SVM on an small image is presented on figures (Fig. 17-20).
 | |
| Fig. 21: | Number of SVs for each block of an average image in case 3 |
 | |
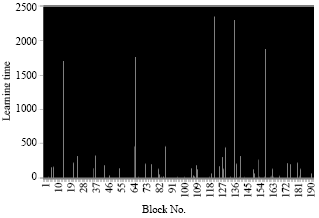
| Fig. 22: | Compression time for each block of an average image in case 3 |
 | |
| Fig. 23: | Number of classes for each block of an average image in case 3 |
The result obtained after the learning of all the blocks with the SVM on a average image is presented on figures (Fig. 21-24).
The results found using the image resembles the results generated by the second image point of view number of SVs, compression rate and learning time because the number of classes is similar and the pixels in the same block are homogeneous, so we get fewer classes than in the first case (Table 8 and 9).
 | |
| Fig. 24: | Learning time for each block of an average image in case 3 |
| Table 5: | Compression results for a small image in case 2 |
 | |
| Table 6: | Compression results for an average image in case 2 |
 | |
| Table 7: | Features of a small and an average image in case 3 |
| Table 8: | Compression results for a small image in case 3 |
 | |
| Table 9: | Compression results for an average image in case 3 |
 | |
DISCUSSION
We note that as the number of SVs decreases, we obtain a satisfactory compression rate except when using the radial function as the rate is too small and can cause great loss of information especially for medical images such loss is not permitted.
This number of SVs depends on the number of classes learned by block, so that we have more classes, more we have a high number of SVs and therefore the compression rate increases.
And if we make a forecast for a third image number of pixels larger than the second image, we can expect to have the same compression rate with a time of higher learning because we have more classes.
We compare the rates found by the different images, we can say that the optimal compression with large margin separator up to 3:1 with the use of the polynomial function with a period that exceeds three hours for the compression of a single sample image.
Therefore, we can tolerate this compression time as long as the compression will be done only once when the consultation will occur several times so we can’t allow this time to decompress.
NB: Much research has been done on image compression by different methods with lossy and lossless even using methods from artificial intelligence but this article presented efficient method.
In addition, the introduction discusses the state of the art of all that has been done before. Especially the article (Robinson and Kecman, 2003) but we can't compare the results found with respect to that section because the scope is different and our research treats sensitive images.
CONCLUSION
SVM is one of classification models to score the pattern recognition by providing a theoretical framework for statistical learning theory.
The purpose of this article stems from the need to test the SVM compression. In particular, the need to say whether SVMs are made for compression as does the human being.
Point of view compression rate, we can say that SVM have proven again their success against the compression of brain tumor cells.
We suggest some research avenues such as the reconstruction of the original image through the SVs generated by learning, optimization of time learning and testing the SVMs on other medical images.
ACKNOWLEDGMENT
I want to thank Professor Mohamed Benyettou for having me accept in his laboratory LAMOSI - USTO to carry out this research work which I am very grateful. My thanks also go to Doctor Frédéric Alexandre for having me welcome in his team CORTEX - INRIA to complete my research which I express my gratitude, Professor Bernard Girau from Lorraine university and Doctor Eric James Nichols for his help.
REFERENCES
- Dillenseger, J.P. and E. Moerschel, 2009. Guide des Technologies de L'imagerie Medicale et de la Radiotherapie: Quand la Theorie Eclaire la Pratique. [Guide Technologies of Medical Imaging and Radiotherapy: When Theory Informs Practice]. Elsevier Masson, Issy-Les-Moulineaux, ISBN: 978-2-294-70431-4.
- Saad, E.S.M., A.A. Abdelwahab and M.A. Deyab, 1998. Using feed forward multilayer neural network and vector quantization as an image data compression technique. Proceedings of the 3rd IEEE Symposium on Computers and Communications, June 30-July-2, 1998, Athens, pp: 554-558.
CrossRef - Gaidhane, V., V. Singh and M. Kumar, 2010. Image compression using PCA and improved technique with MLP neural network. Proceedings of the IEEE International Conference on Advances in Recent Technologies in Communication and Computing, October 16-17, 2010, Kottayam, pp: 106-110.
CrossRef - Singh, K., N. Singh, P. Kaur and R. Saxena, 2009. Image compression by using fractional transforms. Proceedings of the IEEE International Conference on Advances in Recent Technologies in Communication and Computing, October 27-28, 2009, Kottayam, Kerala, pp: 411-413.
CrossRef - Forchhammer, S., H. Li and J.D. Andersen, 2011. No-reference analysis of decoded MPEG images for PSNR estimation and postprocessing. J. Visual Commun. Image Represent., 22: 313-324.
CrossRefDirect Link - Steudel, A., S. Ortmann and M. Glesner, 1995. Medical image compression with neural nets. Proceedings of the 3rd IEEE International Symposium on Uncertainty Modelling and Analysis, September 17-19, 1995, College Park, MD., pp: 571-576.
CrossRef - Meyer-Baese, A., 2000. Medical image compression by Neural-gas network and principal component analysis. Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks, Volume 5, July 24-27, 2000, Como, pp: 489-493.
CrossRef - Toosi, T.K. and H. Behnam, 2009. Combined pulse compression and adaptive beamforming in coded excitation ultrasound medical imaging. Proceedings of the IEEE International Conference on Signal Processing Systems, May 15-17, 2009, Singapore, pp: 210-214.
CrossRef - Al-Fayadh, A., A.J. Hussain, P.J.G. Lisboa, D. Al-Jumeily and M. Al-Jumaily, 2009. A hybrid image compression method and its application to medical images. Proceedings of the 2nd IEEE International Conference on Developments in Esystems Engineering, December 14-16, 2009, Abu Dhabi, pp: 237-240.
CrossRef - Robinson, J. and V. Kecman, 2003. Combining support vector machine learning with the discrete cosine transform in image compression. IEEE Trans. Neural Networks, 14: 950-958.
CrossRefDirect Link - Sahbi, H. and D. Geman, 2006. A hierarchy of support vector machines for pattern detection. J. Mach. Learn. Res., 7: 2087-2123.
Direct Link - Chiou, Y.J., H.M. Chen, J.W.W. Chai, C.C.C. Chen and Y.C. Ouyang et al., 2009. Brain tissue classification using independent vector analysis (IVA) for magnetic resonance image. Proceedings of the 9th IEEE International Conference on Bioinformatics and Bioengineering, June 22-24, 2009, Taichung, pp: 324-329.
CrossRef - Chen, C.J., 2009. 3D breast tumor classification using image registration framework. Proceedings of the IEEE International Conference on Future Computer and Communication, April 3-5, 2009, Kuala Lumpar, pp: 153-157.
CrossRef - Bentaouza, C.M. and M. Benyettou, 2010. Support vector machines for brain tumours cells classification. J. Applied Sci., 10: 1755-1761.
CrossRefDirect Link - Burges, C.J.C., 1998. A tutorial on support vector machines for pattern recognition. Data Mining Knowl. Discov., 2: 121-167.
CrossRefDirect Link - Boser, B.E., I.M. Guyon and V.N. Vapnik, 1992. A training algorithm for optimal margin classifiers. Proceedings of the 5th Annual Workshop on Computational Learning Theory, July 27-29, 1992, Pittsburgh, Pennsylvania, USA., pp: 144-152.
CrossRef - Cornuejols, A., 2002. [A new method of learning: SVM, separators wide margin]. Bulletin de L'afia, 51: 14-23.
Direct Link - Statnikov, A., F. Aliferis, I. Tsamardinos, D. Hardin and S. Levy, 2005. A comprehensive evaluation of multicategory classification methods for microarray gene expression cancer diagnosis. Bioinformatics, 21: 631-643.
CrossRefDirect Link