
Z. Zamani
Department of Biochemistry, Pasteur Institute of Iran, Pasteur Avenue, Tehran, Iran
M. Arjmand
Department of Biochemistry, Pasteur Institute of Iran, Pasteur Avenue, Tehran, Iran
M. Tafazzoli
Department of Analytical Chemistry, Sharif University of Technology, Tehran, Iran
A. Gholizadeh
Department of Analytical Chemistry, Sharif University of Technology, Tehran, Iran
F. Pourfallah
Department of Biochemistry, Pasteur Institute of Iran, Pasteur Avenue, Tehran, Iran
S. Sadeghi
Department of Biochemistry, Pasteur Institute of Iran, Pasteur Avenue, Tehran, Iran
R. Mirzazadeh
Department of Biochemistry, Pasteur Institute of Iran, Pasteur Avenue, Tehran, Iran
F. Mirkhani
Department of Biochemistry, Pasteur Institute of Iran, Pasteur Avenue, Tehran, Iran
S. Taheri
Department of Analytical Chemistry, Sharif University of Technology, Tehran, Iran
A. Iravani
Department of Biochemistry, Pasteur Institute of Iran, Pasteur Avenue, Tehran, Iran
P. Bayat
Department of Biochemistry, Pasteur Institute of Iran, Pasteur Avenue, Tehran, Iran
F. Vahabi
Department of Analytical Chemistry, Sharif University of Technology, Tehran, Iran
Pakistan Journal of Biological Sciences
Year: 2011 | Volume: 14 | Issue: 3 | Page No.: 195-203







ABSTRACT
Vaccines require a period of at least three months for clinical trials, hence a method that can identify elicitation of immune response a few days after the first dose is a necessity. Evolutionary variable selections are modeling approaches for proper manipulation of available data which were used to set up an animal model for classification of time dependent 1HNMR metabolomic profiles and pattern recognition of fluctuations of metabolites in two groups of male rabbits. One group of rabbits was immunized with human red blood cells and the other used as control. Blood was obtained every 48 h from each rabbit for a period of six weeks and the serum monitored for antibodies and metabolites by 1HNMR spectra. Evaluation of data was carried out using orthogonal signal correction followed by principal component analysis and partial least square. A neural network was also set up to predict immunization profiles. A distinct separation in patterns of significant metabolites was obtained between the two groups, just a few days after the first and the second dose. These metabolites were used as targets of neural networks where each sample was used as test, validation and training and their quantitative influence predicted by regression. This model could be used for prediction of immunization in rabbits a few days after the first dose with 96% accuracy. Similar animals and human vaccine trials would assist greatly in reaching early conclusions in advance of the usual two month immunization schedule; resulting in an appreciable saving of cost and time.
PDF Abstract XML References Citation
Received: November 09, 2010;
Accepted: January 22, 2011;
Published: March 11, 2011
How to cite this article
Z. Zamani, M. Arjmand, M. Tafazzoli, A. Gholizadeh, F. Pourfallah, S. Sadeghi, R. Mirzazadeh, F. Mirkhani, S. Taheri, A. Iravani, P. Bayat and F. Vahabi, 2011. Early Detection of Immunization: A Study Based on an Animal Model using 1H Nuclear Magnetic Resonance Spectroscopy. Pakistan Journal of Biological Sciences, 14: 195-203.
DOI: 10.3923/pjbs.2011.195.203
URL: https://scialert.net/abstract/?doi=pjbs.2011.195.203
DOI: 10.3923/pjbs.2011.195.203
URL: https://scialert.net/abstract/?doi=pjbs.2011.195.203
INTRODUCTION
Vaccination protocols take from two months to a year before complete sero-protection is achieved as reported by Committee of Immunization Practices (CIP, 2002). Non responder status to some vaccines are seen in certain cases but they can be detected only after the end of the full term of immunization, their identification early during the period can help determine the course of treatment in some vaccines like the hepatitis B vaccine or the new cancer vaccines (Heininger et al., 2010; Schmittling et al., 2008; Di Pietro et al., 2008). Animal trials also take a few months before final results can be discerned for new vaccines (Grimaldi, 2008). Seasonal vaccines like the recent swine flu outbreak make early conclusions of clinical trials imperative as the usual two to three months which is the standard required period would result in the termination of the season.
Metabonomic processes profiling serum or plasma are used for diagnosis of various diseases like diabetes, cancer, inborn errors of metabolism and various haematologic disorders (Nicholson et al., 2002; Lindon et al., 2004; Gartland et al., 1991; Wevers et al., 1999; Arjmand et al., 2010). The two leading technologies used in metabonomics are Mass Spectrometry (MS) and Nuclear Magnetic Resonance (NMR) 1HNMR spectroscopic profiling of biological fluids combined with multivariate analysis to identify the metabolites that correlate with changes of physiological conditions is used to effectively screen for abnormal metabolite profiles in tissue extracts or cell suspensions. High resolution 1HNMR spectroscopy data sets are represented as complex matrices with several hundreds of proton signals originating from various metabolites (Lindon et al., 2004). This complexity can be simplified by the application of chemometrics methods such as Principle Component Analysis (PCA), Partial Least Square (PLS), PLS discriminate analysis (PLS-DA) and Neural Networks (NN) which are multivariate tools used to generate models or patterns for classification of disease states and toxic shocks (Niazi and Goodarzi, 2008; Fearn, 2008; Wold et al., 2001). These methods select only a small subset of the recorded variables carries essential information and assist build simple models which are not only cost effective but also help in proper understanding and easier knowledge extraction from a set of computational data.
Metabonomic processes using biofluids are also being increasingly used for monitoring of the immune system reaction to kidney damage and transplants which show the role of amino acids alanine and glycine besides other compounds in detection of kidney damage. Damaged kidneys also appear to rapidly elevate serum and urinary levels of urine and markers of Kreb's cycle like lactate, acetate, succinate and citrate (Wishart et al., 2007). The immune and cell modulation in post aggression syndrome has been extensively studied by Roth (2007). This is a syndrome seen after surgery or trauma, when the body’s different metabolic functions are disturbed to help wound healing and survival in which amino acids are seen to play an important part, especially glutamine which is reported to have a regulatory role. Catabolism is involved and the leading phenomena are increase of general turnover rates, glycogenolysis, gluconeogenesis, lipolysis and protein degradation (Quevedo et al., 2008).
In this study, an attempt to obtain pattern recognition of the metabolites between sera of normal and immunized rabbits was carried out. This was done by immunization of a set of rabbits with human red blood cells as antigen. A time dependent study was carried out and the 1HNMR spectroscopy of the serum was correlated with antibody production every 48 h. We managed to obtain biomarkers using chemometrics methods mentioned above and construct a prediction model for early identification of immune response.
MATERIALS AND METHODS
Sample collection: This study was carried out for a period of one year in 2007 in two centers, the Pasteur Institute of Iran and Sharif Unversity of Technology, Tehran, Iran in 2007. Two groups consisting of six male rabbits, each weighing approximately 2.5 kg were used for our experiment. One group was the immunized one and the other unimmunized and used as control. After allowing for 72 h acclimatization of the rabbits, the first blood sample was collected on the 3rd day from the ear vein of all the animals and this procedure was repeated every 48 h for a period of six weeks. One group was immunized with 109 human red blood cells in an equal volume of Freund's complete adjuvant on day 5, the second group was unimmunized and used as controls. Human red blood cells were chosen as an immunogen as host immune response can be detected in a few minutes using the Haemmagglutination test (Roitt et al., 1969). A booster dose of 109 RBCs in Freund's incomplete adjuvant was given on day 21. The sera obtained were immediately divided into two batches, one of which was lyophilized for 1HNMR studies and the other used for antibody detection. Samples were stored at -70°C.
Antibody detection: Presence of antibody was detected by Haemagglutination test (Roitt et al., 1969).
Separation of serum for 1HNMR spectroscopy: Fifty milligram of lyophilized samples and 700 μL D2O were mixed in a 1HNMR tube and spectroscopy carried out at pH 7.2 with Trimethylsilane (TMS) as external standard. 1HNMR spectroscopy was carried out in Sharif University of Technology, Tehran, Iran.
NMR data collection: one dimensional 1HNMR spectra were acquired from a Bruker DRX-500 NMR spectrometer operating at 500.13 MHZ at 298 κ. For each serum sample, the Free Induction Decay (FID) was weighted by an exponential function with a 0.3 Hz line broadening factor prior to Fourier Transformation (FT). Water pre-saturation pulse sequence (D-90-t1-90-tm-90-acquired FID) with relaxation delays of 5 sec and flip angle 90 were used. The water signals and broad protein resonances were suppressed by a combination of two methods: pre-saturation along with Carr-Purcell-Meiboom-Gill (CPMG) (90-(t-180-tn-acquisition) (τ = 200, n = 100) pulse sequence (Lasic et al., 2006).
Data reduction of NMR data: Each 1H-NMR spectrum was corrected for phase and baseline distortion using Chenomx NMR suite (version 6.0) and the 0.0-10.0 parts per million (ppm) spectral regions was reduced to 250 integral segments of equal width of 0.04. Auto phase and automatic baseline correction were the chosen options prior to spectral binning. This optimal width of segmented regions is based on previous studies, which found that regions of 0.04 ppm accommodated any small pH-related shifts in signals and variation in binning quality (Lindon and Nicholson, 1997).
Chemometrics analysis
Pinciple component analysis (PCA): All the NMR variables were initially mean centered and then PCA was carried out using MATLAB 6.0 software (The MathWorks Inc.). Each PC is a linear combination of variables whereby each successive PC explains the maximum amount of variance possible that is not accounted for by the previous PCs. Hence, each PC is orthogonal to the other PCs. Outliers are detected by either Hotelling’s (T2) for strong outliers and Q residuals for modest ones with 95% confidence. Then, the remaining data were categorized into days of sample collection and PCA was carried out for each day.
Data were visualized by plotting the PC scores, where each point on the scores plot represents one spectral region. The scores and loading plots are complementary and super imposable.
Orthogonal signal correction: Structured noise disturbs both modeling and interpretation; it is valuable, therefore, to process the data prior to analysis. Preprocessing methods can be applied in such situations to enhance the relevant information to make resulting models simpler and easier to interpret (Zhang et al., 2005). Orthogonal Signal Correction (OSC) filters was developed to remove strong structured (i.e., systematic) variation in X that is not correlated to Y. That is, they remove structured Y-orthogonal variation from X, in such a way that the filter can be applied to future data. The OSC filters need information about Y. The OSC filter must fulfill three requirements, it must; (1) contain (large) systematic variation in X; (2) be predictive using X (in order to be applied to future data) and (3) be orthogonal to Y. The original OSC approach is to, first, find a Y-orthogonal score vector tosc and then use it to find wosc (another OSC component ), usually by means of PCA or PLS/ PCR regression, The OSC method introduced by Wold et al. (2001) identified the suitable Y orthogonal vector through an internal iterative procedure. The initial tosc is the first PC score vector t in X, orthogonalized to Y. In each iteration, a PLS model is calculated with a predefined number of PLS components. After each iteration, a convergence check is performed to determine whether the predicted tosc is the same as the last orthogonalized tosc. The main problem associated with this procedure concerns overfitting the estimated components. Crossvalidation, or any other validation method, is not usually implemented (Niazi and Goodarzi, 2008). In the OSC procedure, the identity of the sample classes is included in the calculation and assigned by a vector, Y. The first step in the OSC procedure calculates the first principal component, or score vector t*, that is an optimal linear combination of the spectral data and describes maximum separation based on class. Then, the longest orthogonal vector to Y is calculated. This vector, t*, describes the greatest source of variation which is not related to the required class and yet still provides a good summary of the spectral data. After this step, the loading vector, p*, relating to this corrected vector is calculated and the product of the orthogonal score and loading vectors is subtracted from the spectral data. Examination of the OSC scores, t* and loadings p* can be useful in determining the source of the removed variation. The residual matrix represents the filtered spectral data and is then used for calculation of PLS and ANN. Overfitting was a problem after OSC pre-treatment; hence, precise determination of the number of removed OSC factors was imperative.
Partial Least Square (PLS): It is a method that instead of finding hyperplanes of maximum variance between the response and independent variables, finds alinear regression model by projecting the predicted variables and the observable variables to a new space. This method was carried out twice after OSC, using a y matrix with 0 denoting normal and 1 for abnormal data and the NMR spectrum as x matrix. Initially, all the data sets were included in the y matrix to get a pattern separation between normal and abnormal sets. The second PLS was employed using data for each day of sample collection separately and to obtain time related metabolic variations (Wold et al., 2001).
Neural networks: The Neural Network (NN) models were designed with two purposes in mind : firstly to determine the quantitative and qualitative effect of each metabolite (NN1) and then use the most effective ones to design a second prediction model to identify unknown samples whether normal or immunized (NN2). These networks are mathematical orcomputational modelsthat tries to simulate the structure and/or functional aspects ofbiological neural networks (Despagne and Massant, 1998). For NN1 the data sets obtained from the first five PCAs were used as input (x) and the quantity of metabolites obtained from PLS were used as y matrix. The next step was to divide the data into three subsets named as training, validation and test, with half the data put randomly into the training and the other divided equally into the validation and test subsets. We used the Levenberg-Marquardt (Levenberg, 1944) which is iterative and has become a standard technique for nonlinear least-squares problems and can be thought of as a combination of steepest descent and the Gauss-Newton method. It is looked upon as a very simple, but robust, method for approximating a function. For training the neural network, a two layered network with 5 nodes and a tan sigmoid transfer function in the hidden layer along with a linear transfer function in the output layer was used. To analyze the network response, the entire data set was put through the network and regression R2 which is simply the square of the sample correlation coefficient between the outcome and the values being used for prediction in the outputs and the corresponding targets were extracted, the values varying from 0 to 1 (those closest to 1 showed the best prediction).
| Table 1: | Lists the metabolites detected in the metabolic flux by PLS studies, the last two metabolites were detected by Neural networks (NN1) |
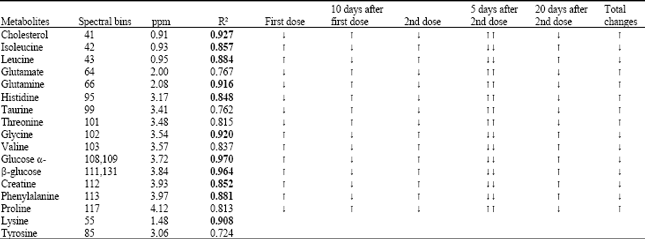 | |
| Bold values show the best pridiction and correspond to the most influential metabolities. Arrows pointing upwards show ascending amounts and downwards show descending amount of metabolites | |
These steps were repeated until the best model was obtained and the most effective metabolites were recognized.
In NN2 the X matrix consisted only of the areas of the spectrum which showed the most influential metabolites (Table 1) and a similar network was applied for construction of an NN predictive model where the y matrix consisted of 0 for normal and 1 for immunized. Then as before, the data was randomly divided into test, validation and training and all the data was put through the training set. A prediction model was obtained with two layers, ten nodes and one linear transfer function in the outer layer with very good regression results.
RESULTS AND DISCUSSION
The 1HNMR CPMG spectrum of normal rabbit serum with water pre-saturation is shown in Fig. 1; the chemical shift region between (0.6-3.1 δ) shown in the rectangle is expanded in the inset demonstrating the main metabolites involved in our work.
After filtering outliers, PCA was the first step for data reduction. Out of 120 samples, about 20 were removed as outliers and PCA on total samples did not divide the two groups clearly, but when carried out for each day of sample collection a rough separation was obtained between normal and immunized groups using samples from day 5 (first dose), day 15, day 21 (second dose) 26th and 40th days, 5 days and 20 days after the second dose (Fig. 2a), the data obtained was used for NN1.
However, PLS was carried out on the basis of each day of sample collection demonstrating very good pattern recognition after removal of one OSC factor (Fig. 2b). PLS scores exhibited a metabolite flux or a fluxatome five days after each dose, the metabolites influenced are seen in PLS biplot (Fig. 2c). It is very interesting to note that the fluxatome occurred in correlation with graph of antibody production (Fig. 3).
Metabolites involved were those that participated in protein synthesis like glycine, phenylalanine and threonine (Table 1). The glycolysis cycle was effected as shown by glucose flux in the blood and Kreb's cycle involvement indicated by key presence of glutamate (Newsholme, 2003).
Biplot of PLS with total data sets in Fig. 2c exhibited the most significant metabolites (Table 1).
The first 5 PCAs were used as data for NN1 which determined the quantitative and qualitative influence of each metabolite in the model and training is stopped after 16 epochs to prevent increase in validation error (Fig. 4).
The results were reasonable and there seemed to be no significant over fitting and the best model was obtained from 24 areas of the spectrum, two metabolites not identified by PLS in the fluxatome were recognized by NN1 (Table 1). In the prediction network, NN2, the most effective metabolites (Table 1), were used as the x matrix and this was repeated 5 times with more than 96% confidence as shown in Fig. 5 and the training was stopped after 11 times by the validation set.
This model could predict immunization of rabbits with 96% confidence 5 days after each dose and only 3 out of 53 samples were predicted inaccurately (Fig. 6) which showed very close correlation of the three sets.
A fluxatome was detected immediately after each dose of immunization but no single biomarker could be obtained. Of all the metabolites the ten most effective ones whose squared regression was closest to 1 were used as matrix for NN2 which resulted in an accurate prediction network.
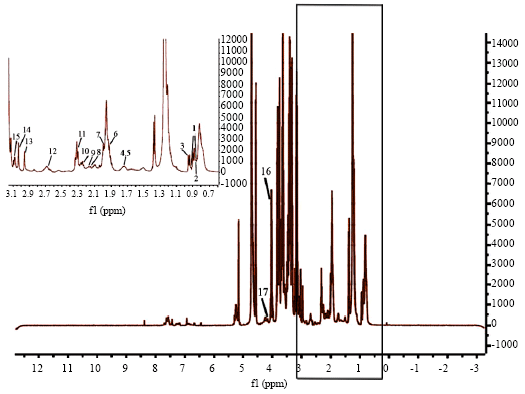 | |
| Fig. 1: | 1HNMR CPMG spectrum of rabbit serum with water presaturation. Inset figure shows expanded region seen in the rectangle between (δ 0.7-3.1). Numbers show position of different metabolite peaks. Key: 1. isoleucine 2. leucine 3. valine 4, 5. arginine, lysine 6. glutamate 7. glutamine 8. acetoacetate 9. valine 10. 3-hydroxybutirate 11. glutamine 12. dimethylamine 13. creatine 14. histidine 15. tyrosine 16. lactate 17. threonine. Height of peaks correspond to amount of metabolites |
Metabonomics has been used as a tool to detect safety assessment and disease diagnosis in toxicology (Griffin and Bollard, 2004; Griffin, 2003; Robosky et al., 2002). Pattern recognition is frequently used for biomarker validation (Serkova and Niemann, 2006; Zhang et al., 2010; Issaq, 2009) diagnosis of diseases, like inborn errors of metabolism (Wevers et al., 1999) and even recommended for the surgeon (Goldsmith et al., 2010). It is interesting to note that a study was carried out on metabonomics of parasitic infections cause a myriad of responses in their mammalian hosts, on immune as well as on metabolic level. This study demonstrates that the inherently differential immune response to single-and multicellular parasites not only manifests in the cytokine expression, but also consequently imprints on the metabolic signature and calls for in-depth analysis to further explore direct links between immune features and biochemical pathways (Saric, 2010). Present results too corroborated the above results and the metabolic flux detected by multivariate analysis was concomitant with antibody production.
The metabolites involved in the flux as in Table 1 were mainly amino acids which are the main building blocks of antibodies; also creatine, sugars like glucose and fats like cholesterol and creatine. The cycles effected besides protein synthesis, were glycolysis, gluconeogenesis and fatty acid metabolism (Wishart et al., 2007; Harwood, 1988; Greenstein and Winitz, 1961). The presence of different amino acids in the fluxatome underlines their importance in antibody synthesis. Amino acids have also been reported to play a key role in immune modulation in post aggression syndrome especially glutamine, glycine, tryptophan, arginine and cysteine which was very similair to our findings (Roth, 2007). A smaller fluxatome was detected in a metabonomic study carried out in a small number of cases on the biofluids of childhood pneumonia in Africa (Laiakis et al., 2010) and a statistically significant difference (p<0.05) was detected between the two groups of patients and normals with the following metabolites: uric acid, hypoxanthine and glutamic acid which were higher in plasma from patients, while their urine L-tryptophan and adenosine-59-diphosphate (ADP) were lower; uric acid and L-histidine were lower. Another study on the response and recovery of plasma metabolites in acute LCMV infection shows once more besides the role of other metabolites that of glutamate as glutamyl leucine and glutamyl valanine which decrease and then increase significantly during the recovery period of two weeks (Wikoff, 2009).
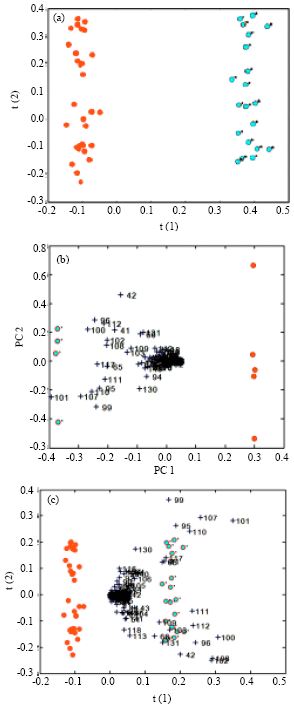 | |
| Fig. 2: | (a) PLS score plot of all the data sets (53 sample) showing complete separation of two sets of rabbits. (b) PLS biplot of samples for a single day, (5th day after the second dose, red circles indicate control and green circles show immunized groups. Numbers indicate spectral bins for significant metabolites have been showed in Table 1 and (c) PLS biplot inclusive of all data sets showing relevant metabolites. Spectral bins for significant metabolites have been shown in Table 1. (Circles indicate control and barred circles show immunized groups) |
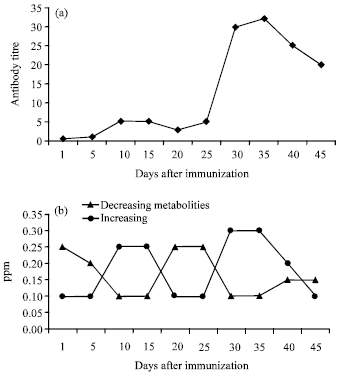 | |
| Fig. 3: | (a) Graph of antibody production against time and (b) Fluxatome or time dependence variations of metabolites during immunization |
These three amino acids and histidine were involved in the fluxatome for antibody formation in our study. Glutamine has been reported as being very important for cell metabolism (Newsholme, 2003).
This network if designed for human subjects can be used for predicting responder status or limited seroconversion with no seroprotection exhibited in many vaccines, like the hepatitis B vaccine and the new in trial dendritic cell vaccine that fights malignant tumors like gliblastoma multiforme (GBM) (Heininger et al., 2010; Schmittling et al., 2008; Di Pietro, 2008). It may prove helpful for response to immunization of subjects with different disorders (Kingsley et al., 2006). Early identification of non responder states using this network model for detection of the fluxatome a few days after the first dose would greatly assist in determination of the course of treatment.
Animal vaccine trials also take at least a few months and the use of these neural networks to detect the immune response fluxatome three days after the first dose would help in cutting short the time required for these trials. The controversial recent swine influenza vaccine could benefit from a neural network based on animal and human data decreasing the time required for release of vaccines.
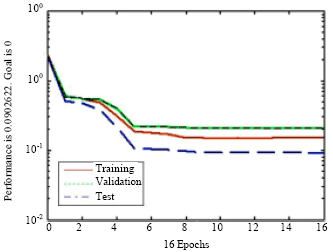 | |
| Fig. 4: | NN1 determined the quantitative influence of each metabolite in the model and training is stopped after 16 epochs to prevent increase in validation error. (Dashed lines are training, green- grey validation and continuous lines test sets) |
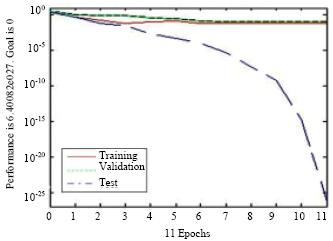 | |
| Fig. 5: | NN2 using the most effective metabolites of NN1 as x matrix this was repeated 5 times with more than 96% confidence. Training was stopped after 11 epochs by the validation set |
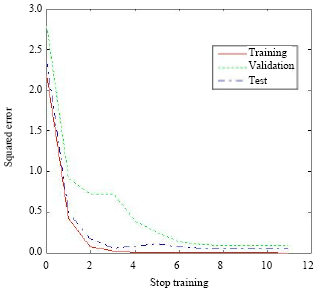 | |
| Fig. 6: | Squared error of three sets in NN2 showing close correlation of the three showing good prediction of the model |
ACKNOWLEDGMENTS
The Authors wish to acknowledge Pasteur Institute of Iran for the grant provided for this project. We wish to acknowledge Dr. Anis Jaferi and Ms. Mohammad Zadeh for their help. Special thanks to Dr. J.C. Lindon of Imperial College, London for his unstinted support and guidance throughout this work.
REFERENCES
- Fearn, T., 2008. Principal component discriminant analysis. Stat. Appl. Genet. Mol. Biol., Vol. 7, No. 2.
CrossRefDirect Link - Gartland, K.P., C.R. Beddell, J.C. Lindon and J.K. Nicholson, 1991. Application of pattern recognition methods to the analysis and classification of toxicological data derived from proton nuclear magnetic resonance spectroscopy of urine. Mol. Pharmacol., 39: 629-642.
PubMedDirect Link - Griffin, J.L. and M.E. Bollard, 2004. Metabonomics: Its potential as a tool in toxicology for safety assessment and data integration. Curr. Drug Metab., 5: 389-398.
Direct Link - Griffin, J.L., 2003. Metabonomics: NMR spectroscopy and pattern recognition analysis of body fluids and tissues for characterisation of xenobiotic toxicity and disease diagnosis. Curr. Opin. Chem. Biol., 7: 648-654.
Direct Link - Grimaldi, G. Jr., 2008. The utility of rhesus monkey (Macaca mulatta) and other non-human primate models for preclinical testing of Leishmania candidate vaccines. Mem. Inst. Oswoaldo Cruz., 103: 629-644.
CrossRefPubMedDirect Link - Goldsmith, P., H. Fenton, G.M. Stiff, N. Ahmad, J. Fisher and K.R. Prasad, 2010. Metabonomics: A useful tool for the future surgeon. J. Surg. Res., 160: 122-132.
CrossRefDirect Link - Harwood, J.L., 1988. Fatty acid metabolism. Annu. Rev. Plant Physiol. Mol. Biol., 39: 101-138.
CrossRefDirect Link - Heininger, U., M. Gambon, V. Gruber and D. Margelli, 2010. Successful hepatitis B immunization in non- and low responding health care workers. Hum Vaccin, 6: 725-758.
PubMedDirect Link - Issaq, H.J., Q.N. Van, T.J. Waybright, G.M. Muschik and T.D. Veenstra, 2009. Analytical and statistical approaches to metabolomics research. J. Sep. Sci., 32: 2183-2199.
CrossRefDirect Link - Kingsley, J.D., M. Varman, A. Chatterjee, R.A. Kingsley and K.S. Roth, 2006. Immunizations for patients with metabolic disorders. Pediatrics, 118: 460-470.
CrossRefPubMedDirect Link - Laiakis, E.C., G.A.J. Morris, A.J. Fornace Jr. and S.R.C. Howie, 2010. Metabolomic analysis in severe childhood pneumonia in The Gambia, West Africa: Findings from a pilot study. PLoS One, (In Press).
Direct Link - Lasic, S., J. Stepisnik and A. Mohoric, 2006. Displacement power spectrum measurement by CPMG in constant gradient. J. Magn. Reson., 182: 208-214.
PubMedDirect Link - Levenberg, K., 1944. A method for the solution of certain non-linear problems in least-squares. Q. Applied Math., 2: 164-168.
Direct Link - Lindon, J.C. and J.K. Nicholson, 1997. Recent advances in high resolution NMR spectroscopic methods in analytical chemistry. Trends Anal. Chem., 16: 190-200.
CrossRef - Lindon, J.C., E. Holmes and J.K. Nicholson, 2004. Metabonomics and its role in drug development and disease diagnosis. Exp. Rev. Mol. Diagn., 4: 189-199.
CrossRefPubMedDirect Link - Newsholme, P., J. Procopio, M.M. Lima, T.C. Pithon-Curi and R. Curi, 2003. Glutamine and glutamate: Their central role in cell metabolism and function. Cell Biochem. Funct., 21: 1-9.
PubMedDirect Link - Niazi, A. and M. Goodarzi, 2008. Orthogonal signal correction-partial least squares method for simultaneous spectrophotometric determination of cypermethrin and tetramethrin. Spectrochim Acta A Mol. Biomol. Spectrosc., 69: 1165-1169.
PubMedDirect Link - Nicholson, J.K., J. Connelly, J.C. Lindon and E. Holmes, 2002. Metabonomics a platform for studying drug toxicity and gene function. Nat. Rev. Drug Discov., 1: 153-161.
CrossRefPubMedDirect Link - Quevedo, A.L., A.I. Linares Quevedo, F.J. Burgos Revilla, J.J.V. Sanz and J.Z. Romero et al., 2008. Usefulness of cytokines as surgical aggression markers in the ischemia-reperfusion syndrome and post transplant renal function in an experimental model of laparoscopic vs. open renal autotransplantation. Arch. Esp Urol., 61: 41-54.
PubMedDirect Link - Robosky, L.C., D.G. Robertson, J.D. Baker, S. Rane and M.D. Reily, 2002. In vivo toxicity screening programs using metabonomics. Comb Chem. High Throughput Screen, 5: 651-662.
Direct Link - Roitt, I.M., M.F. Greaves, G. Torrigiani, J. Brostoff and J.H. Playfair, 1969. The cellular basis of immunological responses. A synthesis of some current views. Lancet, 2: 367-371.
PubMedDirect Link - Roth, E., 2007. Immune and cell modulation by amino acids. Clin. Nutr., 26: 535-544.
PubMedDirect Link - Serkova, N.J. and C.U. Niemann, 2006. Pattern recognition and biomarker validation using quantitative 1H-NMR-based metabolomics. Expert Rev. Mol. Diagn, 6: 717-731.
Direct Link - Wevers, R.A., U.F. Engelke, S.H. Moolenaar, C. Br�utigam and J.G. de Jong et al., 1999. AH.H-NMR spectroscopy of body fluids: Inborn errors of purine and pyrimidine metabolism. Clin. Chem., 45: 539-548.
PubMedDirect Link - Wikoff, W.R., E. Kalisak, S. Trauger, M. Manchester and G. Siuzdak, 2009. Response and recovery in the plasma metabolome tracks the acute LCMV-induced immune response. J. Proteome. Res., 8: 3578-3587.
CrossRefPubMedDirect Link - Wishart, D.S., C. Tzur, C. Knox, R. Eisner and A.C. Guo et al., 2007. HMDB: The human metabolome database. Nucleic Acids Res., 35: D521-D526.
PubMedDirect Link - Zhang, L., L. Zhang, Y. Li and J. Wang, 2005. Orthogonal signal correction used for noise elimination of open path fourier transform infrared spectra. J. Environ. Sci. Health A Tox. Hazard. Subst. Environ. Eng., 40: 1069-1079.
PubMedDirect Link - Zhang, S., G.A. Nagana Gowda, T. Ye and D. Raftery, 2010. Advances in NMR-based biofluid analysis and metabolite profiling. Analyst, 135: 1490-1498.
CrossRefPubMedDirect Link - Wold, S., M. Sjostrom and L. Erikson, 2001. PLS-regression: A basic tool of chemometrics. Chemometrics Intell. Lab. Syst., 58: 109-130.
CrossRefDirect Link