
Ecevit Eyduran
Biometry Genetics Unit, Department of Animal Science, Faculty of Agriculture,
University of Yuz:Uncu Yil, 65080 Van, Turkey
Taner Ozdemir
Biometry Genetics Unit, Department of Animal Science, Faculty of Agriculture,
University of Yuz:Uncu Yil, 65080 Van, Turkey
M. Kazim Kara
Biometry Genetics Unit, Department of Animal Science, Faculty of Agriculture,
University of Adnan Menderes, Aydm, Turkey
Siddik Keskin
Biostatistics Unit, Faculty of Medicine,
Bahattin Cak
Department of Animal Science, Faculty of Veterinary Medicine,
University of Yuz:Uncu Yil, 65080 Van, Turkey
Pakistan Journal of Biological Sciences
Year: 2006 | Volume: 9 | Issue: 7 | Page No.: 1324-1327







ABSTRACT
The objective of this study was to examined Chi-Square and G test statistics in place of enough sample size, contingency coefficient and power of test for different four contingency tables (data set) regarding biology sciences. Besides, this study was to determine whether sample sizes of various four samples in biology sciences were sufficient. The reliability of two statistics related to Sample size, contingency coefficient and power of test. Power analysis for Chi-Square and G test statistics were performed using a special SAS macro According to results of power analysis, sample sizes of other sets of data except the third data set were determined to be sufficient because power values for both statistics were more than 88%. With respect to power analysis, G statistics for the initial two data sets were more advantageous than other as power value of G statistics were larger than that of other. In the last data set, as sample size were 1607 and power values for both statistics were 100%, both were asymptotically equivalent each other. As power values of the third data set for Chi-Square and G test statistics were approximately 46.77 and 58.16%, respectively, sample size with 20 for both were determined to be insufficient. When we artificially increased 30 to 200 by 10, sufficient sample size for third data should be 50 so as to provide power values of 80% with respect to results of SAS special macro. As a result, this study emphasized that researchers should have taken into sample sizes and power of test account except for probability of Type Error I in contingency tables in order to determine the best one of both statistics.
PDF Abstract XML References Citation
How to cite this article
Ecevit Eyduran, Taner Ozdemir, M. Kazim Kara, Siddik Keskin and Bahattin Cak, 2006. A Study on Power of Chi-square and G Statistics in Biology Sciences. Pakistan Journal of Biological Sciences, 9: 1324-1327.
DOI: 10.3923/pjbs.2006.1324.1327
URL: https://scialert.net/abstract/?doi=pjbs.2006.1324.1327
DOI: 10.3923/pjbs.2006.1324.1327
URL: https://scialert.net/abstract/?doi=pjbs.2006.1324.1327
INTRODUCTION
Chi-Square and G (which is also called as Likelihood Ratio Chi-Square) statistics have been widely used to test independence or goodness of fit in contingency tables (row by column) (Sokal and Rohlf, 1981; Duzguneo et al., 1983; Everitt, 1992; Agresti, 2002; Ozdemir et al., 2004; Eyduran and Ozdemir, 2005; Eyduran et al., 2005). The number of variables for two statistics should be two (e.g. x and y) which have either grouped or categorical measurements (Sokal and Rohlf, 1981; Duzguneo et al., 1983; Agresti, 2002; Eyduran and Ozdemir, 2005; Eyduran et al., 2005). G statistic of these two statistics has the Chi-squared approximation when n→+∞ is (Duzguneo et al., 1983; Agresti, 2002; Eyduran and Ozdemir, 2005). Two Statistics gives an idea about whether (or not) an association between two variables is. However, when more than 20% of the cells have expected counts less than 5, Chi-Square Statistic may not be a valid statistic. In other words, Statistics package programs for this case, one of which, SAS program, gives warning Chi-square statistic may not be a valid statistic (SAS, 1998). It was stated, therefore, many authors preferred G statistic to Chi-square statistic (Sokal and Rohlf, 1981; Duzguneo et al., 1983; Everitt, 1992; Ozdemir et al., 2004; Eyduran and Ozdemir, 2005; Eyduran et al., 2005). Besides, it was reported that for contingency tables, G statistic could be more favorable approach than Chi-square where n/rc was less than five (Agresti, 2002; Eyduran and Ozdemir, 2005). In addition, it was suggested that G test was more suitable than other when observed counts in contingency table were less than five (Sokal and Rohlf, 1981; Duzguneo et al., 1983; Everitt, 1992; Ozdemir et al., 2004; Eyduran and Ozdemir, 2005). However, it was suggested that values of two statistics were similar to each other when sample size was sufficient or much (Sokal and Rohlf, 1981; Ozdemir et al., 2004; Eyduran and Ozdemir, 2005).
The reliability of two statistics associated to sample size, contingency coefficient and power of test. In this context, three criteria are different for each contingency table, which can be composed the various numbers of observations in all cells (Eyduran and Ozdemir, 2005). Besides, in any contingency table, one can concern whether sample size, n, for gaining power with at least 80% is sufficient except for probability of type error I. Besides, the best choice between both statistics was based on their power values.
The aim of this study was to examine Chi-Square and G test statistics in place of enough sample size, contingency coefficient and power of test for different contingency tables regarding biology sciences, which were mentioned in materials and methods section, by means of a special macro downloaded from SAS library (http://ftp.sas.com/techsup/download/stat/powerrxc.html). In other hand, by using the special SAS macro, the goal of present paper was to test or determine whether sample sizes for different four sets of sample data on biological sciences were sufficient.
MATERIALS AND METHODS
Materials: As a research material, different data sets were used. Various data sets in relation to biology sciences are given in form of contingency tables as given in Table 1.
| Table 1: | Contingency tables in data sets regarding biological sciences |
 | |
Data set 1 was composed of questionnaire records on psychological cases and sex of 107 refugees in 2001 (Ozdemir, 2001). The numbers of female and male were 22 and 85, respectively as well as the numbers of refugees being occurrence and absences of any psychological problem were 76 and 31, respectively. As a psychological sample, a question of interest was whether relationship between psychological cases and sex was significant.
Data set 2 was consisted of results of an immunological study that the effects of different two experiments on survivor of 121 mice were examined. One hundred and twenty one mice were separated into two groups, 57 that given standard dose of pathogenic bacteria followed by an antiserum and a control group of 54 received only the bacteria. After satisfactory time elapsed for incubation period, 38 dead mice and 73 survivors were counted. A question of interest was whether association between various experiments and sex is considerable, that is, whether the antiserum had protected mice (Sokal and Rohlf, 1981).
Data set 3 was made up of records on levels of dirty fleece yield and transferrin types of 20 Norduz Goat in 2001 (Eyduran et al., 2005a). The number of transferrin type A and AB were 17 and 3 sheep, respectively as well as the number of low and high levels of fleece yield were both 10 sheep. In this sample on animal science, a question of interest was whether relationship between different transferrin types and levels of dirty fleece yield was important.
Data set 4 was comprised of results of questionnaire performed on 1607 women (Eyduran et al., 2005). A question of interest for the data set was the relationship between contraceptives uses and desiring children was significant.
Different data sets concerning biological sciences in Table 1 were analyzed using a special SAS macro (http://ftp.sas.com/techsup/download/stat/powerrxc.html).
METHODS
Chi-Square 1 and G statistics 2 are used for testing goodness of fit in contingency tables (Everitt, 1992; Agresti, 2002; Eyduran and Ozdemir, 2005) and the notation of two statistics are given below:
| (1) |
| (2) |
Where, f, observed frequency and fi , expected frequency.
Power estimation for Chi-Square and G statistics: Theoretical details regarding special SAS macro were explained by Agresti (2002) as follows:
Assume that H0 is equivalent to model M for a contingency table. Let πi denote the true probability in ith cell and Let πi (M) denote the value to which the Maximum Likelihood (ML) estimate πi for model M converges, where Σπi = Σπi(M) = 1. For multinomial sample of size n, the non-centrality parameter for Chi-Square 3 can be expressed as follows:
| (3) |
Expression 3 is the same form as Chi-Square statistics, with in place of the sample proportion pi and πi(M) in place of πi. The non-centrality parameter for Likelihood Ratio Chi-Square Statistics 4 can be expressed below:
| (4) |
RESULTS AND DISCUSSION
The values, power values and contingency coefficient of G and Chi-Square Statistics for different four sets of data (or contingency tables) on the subject of biology sciences mentioned above are given in Table 2.
Examined all values of two statistics for the first contingency table (Table 2), there was a close relationship between psychological cases and sex (p<0.01). It could be said, therefore, sample size (n = 107) for the first contingency table was sufficient. Because, the power values of G and Chi-Square statistics for the first contingency table were approximately 98.6% and 91.940%, both of which, were much high-level. In other words, it could be suggested that results of the first contingency table were much more reliable. However, for the first contingency table, power value of G statistics were little larger than other and it could be suggested that G statistics were more advantageous than other when one cell of the first contingency table in Table 1 were zero (less than five). As examined in Table 1, the finding, results of power analysis, was in agreement with those reported by Sokal and Rohlf (1981), Duzguneo et al. (1983), Everitt (1992), Ozdemir et al. (2004) and Eyduran and Ozdemir (2005).
By examining for the second contingency table in Table 2, all values of the second contingency table were close on each other. The findings on being same as the values of statistics were consistent with those reported by Sokal and Rohlf (1981), Ozdemir et al. (2004), Eyduran and Ozdemir (2005). There was a significant association between various experiments and sex (p<0.01). Besides, power values for G and Chi-square statistics of the second contingency table were both also approximately 89%, which had high-reliability. In other words, it could be said that sample size of the second contingency table was sufficient because power values of two statistics was larger than 80%. Many authors were reported that the values of both statistics could be similar (Sokal and Rohlf, 1981; Everitt, 1992; Ozdemir et al., 2004; Eyduran and Ozdemir, 2005). It could be suggested that both statistics were similar to each other as frequencies of the cells in the contingency table were more than five.
All values of fourth contingency table in Table 2 were close and similar to each other. As Sample size was 1607, power values of two statistics were both 100%. It could be suggested that an ideal data set was data set 4. If sample n→+∞, the reliability of study increases.
As to the fourth contingency tables in Table 2, the relationship between contraceptives use and desiring children was much more significant (p<0.001).
Considered on the third contingency tables in Table 2, sample size could be said to be insufficient. As shown in Table 1, G Statistic was more reliable than other because two of observed frequencies in the third contingency table were less than five (Sokal and Rohlf, 1981; Duzguneo et al., 1983; Everitt, 1992; Ozdemir et al., 2004; Eyduran and Ozdemir, 2005). Moreover, SAS program for this contingency table gave warning 50% of the cells have expected counts less than 5. Chi-Square may not be a valid test (SAS, 1998). This was meant, therefore, for the third contingency table, G statistic was more reliable than Chi-Square. The power values of third contingency table for G and Chi-Square statistics were moderate level (58.2%) and low-level (46.8%), respectively.
Although the third data set were sparse data, its contingency coefficient was higher than those of the other sets of data were. However, other data sets had high power value.
| Table 2: | The values, power values and contingency coefficient of G and Chi-Square statistics in each data set alpha = 0.05 |
 | |
 WARNING: 50% of the cells have expected counts less than 5. Chi-Square may not be a valid test WARNING: 50% of the cells have expected counts less than 5. Chi-Square may not be a valid test | |
| Table 3: | The power values obtained by artificially increasing sample size in data set 3 for alpha = 0.05 |
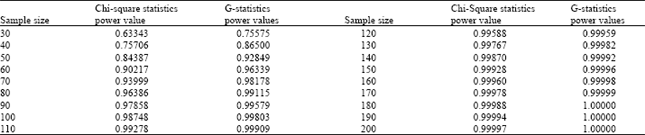 | |
It could be suggested that this case could be resulted from being sufficient sample size (Table).
On condition that contingency coefficients for the third contingency table was fixed when we artificially increased 30 to 200 by 10 by using special SAS macro mentioned above in order to determine sufficient sample size for the third contingency table, minimum sample sizes should be 50 as two statistics were reliable. However, if sample size were 200, the power values of Chi-square and G statistics would be achieved to 99.997 and 100%.
CONCLUSIONS
The aim of this study was to examine Chi-Square and G test statistics in place of contingency coefficient and power of test and to determine sufficient sample size for various contingency tables regarding biology sciences by using a special macro.
As the power values of the first, second and fourth contingency tables in Table 2 were larger than 88%, it could be said that sample size, n, (107, 121 and 1607, respectively) of those contingency tables were more sufficient, and it could be suggested, therefore, G and Chi-Square Statistics results of those contingency tables were more much reliable. However, sample size of the third contingency table was insufficient. Because, the power values of third contingency table for G and Chi-Square statistics were moderate level (58.2%) and low-level (46.8%). Provided that contingency coefficient of two statistics in third contingency table was fixed, when we raised 20 to 200 by 10 in order to find out sufficient sample size for the contingency table (at alpha = 0.05 level), minimum sufficient sample size for it should be 50 with respect to Table 3. In other words, to obtain a reliable result, sample size for G and Chi-Square statistics in the third contingency table should be minimum 50.
If researchers were encountered in warning 50% of the cells have expected counts less than 5. Chi-Square may not be a valid test as being the third contingency table, they could prefer G statistics to other (SAS, 1998).
As a result, it was concluded that the reliability of G and Chi-Square statistics could be changed to sample size, frequencies combination in the cells of contingency table. Besides, This research emphasized that researchers should have taken into sample sizes and power of test account it order to determine the best selection between both statistics rather than probabilities of Type Error I for both were statistically significant.
ACKNOWLEDGMENT
We are thankful to Prof. Dr. Cemil TUNÇ due to his support.