
Yan Zhang
School of Computer and Information, Southwest Forestry University, Kunming, China
Danjv Lv
School of Computer and Information, Southwest Forestry University, Kunming, China
Ran Guo
School of Computer and Information, Southwest Forestry University, Kunming, China
Journal of Software Engineering
Year: 2017 | Volume: 11 | Issue: 1 | Page No.: 60-65







ABSTRACT
Background: Classifier selection is a crucial problem for ensemble learning to speed up the classifier prediction, reduce the storage space requirements and to further improve the classification accuracy. Materials and Methods: To select the best classifier subset from a pool of classifiers, the diversity metrics are exploited to evaluate the classifier for ensemble classification. Based on accuracy and differences between classifiers, this study presented AD and concurrency metrics to measure diversity of ensemble classifiers. With the greedy search method, the back-forward reduction with diversity (BRD) is proposed to delete the classifier with smallest diversity with evaluation function according to the diversity metrics. Experiments were conducted on ten data sets from UCI, remote sensing image and environmental audio data. Bagging, AdaBoost and MCS ensemble strategies were exploited in those experiments. Results: Six diversity metrics were involved in the BRD method to select the optimal subset individual classifiers to constitute the final ensemble. Ensemble selection method BRD outperformed Multiple Classifiers System (MCS) in classification performance and generalization. Conclusion: The BRD is effective method to ensemble selection to improve the performance and generalization in classification. Considering both accuracy and difference of classifiers, the concurrency and AD measure methods obtained the better classification results in ensemble selection than that of the other four diversity metrics including the Q-statistics, Kappa-statistic, correlation coefficient and dis diversity metrics.
PDF Abstract XML References Citation
Received: May 18, 2016;
Accepted: September 05, 2016;
Published: December 15, 2016
Copyright: © 2017. This is an open access article distributed under the terms of the creative commons attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
How to cite this article
Yan Zhang, Danjv Lv and Ran Guo, 2017. Selective Ensemble Learning Based on Greedy Reduction with Diversity. Journal of Software Engineering, 11: 60-65.
DOI: 10.3923/jse.2017.60.65
URL: https://scialert.net/abstract/?doi=jse.2017.60.65
DOI: 10.3923/jse.2017.60.65
URL: https://scialert.net/abstract/?doi=jse.2017.60.65
INTRODUCTION
Ensemble learning methods1,2 train a set of base learners and combine their predictions to make the final decision. Due to their potential to greatly increase classification accuracy and generalization ability, the study of the methods for construction good ensembles has attracted a lot of attentions in machine learning community and successfully applied in many real world applications3-5.
Compared with the individual classifier, ensemble classifiers could obtain better performance but some disadvantages exist. With the increasing of the number of the base classifiers, training and predictive processing is time-consuming and the computational cost is high. Besides, not any ensemble classifier member is beneficial to the classification result. Zhou et al.6 firstly proposed the concept of selective ensemble learning, which is giving a set of trained individual classifiers, instead of combining all of them. Ensemble selection tries to select a subset of individual classifiers to comprise the final ensemble. In the selective ensemble learning, the storage resources required for storing the base classifiers reduces when the size of ensemble is smaller and for calculating outputs of individual classifiers, the efficiency in the training and prediction is improved. In the selective ensemble process, the weak or bad base classifiers are deleted. The generalization performance of selected ensemble may be even better than the ensemble consisting of all the given individual classifiers. The success of ensemble selection lies in how to select the optimal individual classifiers to improve performance with higher accuracy and stronger generalization. The hotspot attracts many researchers to focus the issue and presented some effective algorithm to select the base classifiers in ensemble methods7-12.
MATERIALS AND METHODS
The central problem of ensemble selection research is how to design practical algorithms leading to smaller ensembles without sacrificing or even improving the generalization performance contrasting to all-member ensembles.
Different type classifiers are trained by the same training data, respectively and combined with some strategies. The final classifier classifiers new data and gives their label by predictions. The ensemble methods comprise three phases:
| • | Production of multiple diverse base classifiers |
| • | Ensemble selection or ensemble pruning |
| • | Combination of the final base classifiers |
The model of ensemble selection method process is shown as Fig. 1. The key step is the selection strategies.
The main idea of ensemble selection learning is that some are selected to build the ensemble classifier from an existing base classifier set based on some criteria, to speed up the classifier prediction, reduce the storage space requirements and to further improve the classification accuracy. In theory, the optimal classifier subset can be obtained through the exhaustive enumeration. But when the number of base classifiers is larger, its calculation is time-consuming and is not feasible in practice. Therefore, effective evaluation method to select the useful ones to construct the final ensemble the is the key step to ensemble selection.
During the past decade, many effective ensemble selection methods have been proposed. Those methods can be classified into three categories2,13:
| • | Ordering-based selection: The base classifiers are ordered based on some criterion. The final ensemble will only include classifiers in the front-part |
| • | Clustering-based selection: Those methods try to identify a number of representative prototype individual classifiers to constitute the final ensemble |
| • | Optimization-based selection: Those methods consider the ensemble selection problem as an optimization problem, which tries to find the subset of individual classifiers that maximizes or minimizes a classifier related to the generalization ability of the final ensemble |
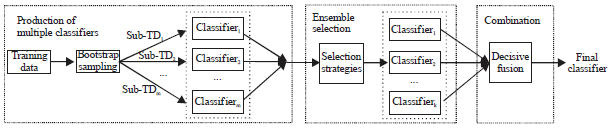 | |
| Fig. 1: | Model of ensemble selection method process |
Some metrics for diversity: Kuncheva and Whitaker14 compared 10 statistics that can be applied to the measurement of diversity. They look at 4 statistics that are averaged pair-wise results and 6 that are non-pair-wise result. In this study, the 4 pair-wise statistics are exploited and other two metrics are presented.
To measure ensemble diversity, a classical approach is to measure the pairwise dissimilarity between 2 learners and then average all the pairwise measurements for the overall diversity4. Given a data set D = {(x1,y1),…,(xm,ym)}, for 2 classifier hi and hj, some characters are denoted:
| (1) |
| (2) |
| (3) |
| (4) |
| • | Disagreement measure: |
| (5) |
The value disij is in [0, 1] as well as the larger the value, the large the diversity.
| • | Q-statistic: |
| (6) |
The value Qij is in the range of [-1, 1]:
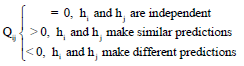 |
| • | Correlation coefficient: |
| (7) |
This is a classic statistic for measuring the correlation between two binary vectors. The value indicates that the smaller the measurement, the larger the diversity.
| • | Kappa-statistic: |
| It is defined as : |
| (8) |
where, θ1 and θ2 are the probabilities that the two classifiers agree and agree by chance, respectively. The probabilities for hi and hj can be estimated on the data set D:
| (9) |
| (10) |
The value indicates that the smaller the measurement, the larger the diversity.
| • | Accuracy and diversity (AD): In order to simply the calculating process, the metric Accuracy and Diversity (AD) can be proposed to take both accuracy and diversity of two classifiers into account. The metric AD is defined as: |
| (11) |
where, a, b, c, d and m are the same definition over above. The first term of numerator defines the accuracy of both 2 classifiers, while the second term is the difference between them and α, β are the coefficient to trade-off the accuracy and diversity. Their value is in range [0, 1] and α+β = 1. The diversity increases as the value of ADij metric becomes larger.
| • | Concurrency: |
| (12) |
This metric is derived from the concurrency of a model ht with respect to a sub-ensemble S in literature Banfield9, which based on the correctness of both the ensemble and the classifier with regard to a thinning set. In this study, the concurrency metric is defined as between classifier hi and hj.
 | |
| Fig. 2: | Description of back-forward reduction with diversity process |
The hi is rewarded for obtaining a correct decision, the rewarded more for obtaining a correct decision when the classifier hj is incorrect. Both hi and hj are incorrect, there is a penalization. For CONij metric, that is the larger the value, the large the diversity.
Measure matrix: According to the methods to measure the diversity between two different classifiers, the Diversity Matrix (DM) can be defined as:
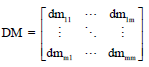 | (13) |
where, dmii = 0 (i = 1, ..., m), dmij = dmji (I, j = 1, ..., m).
Each dmij (i ≠ j) denotes the diversity two classifiers hi and hj. The pair-wise statistic metric can be obtained as the value for dmij (i ≠ j), so can the dmji. So DM is a symmetry matrix.
For a classifier hi in ensemble, its diversity can be simply acquired by:
| (14) |
Classifiers selection on elimination with diversity: Greedy ensemble selection algorithm attempts to find the globally best subset of classifiers by taking local greedy decision for changing the current subset. In this study, backward elimination is exploited in the greedy selection. Firstly, the current classifier subset S is initialized to the complete base classifier set H. Then, at each iteration, the classifier ht ε S that optimizes the evaluation function f will be removed from S to improve the classification accuracy. With the idea of greedy methods, the evaluation function f selects the classifier ht which has the smallest diversity in the current subset S. The iterative process will not stop until the error of ensemble subset S start to increase. This process is named as back-forward reduction with diversity (BRD). The description of BRD is illustrated in Fig. 2.
RESULTS AND DISCUSSION
In order to compare the performance of the above methods, some experiments are carried out to show the results of the classification. Eight UCI datasets15, a remote sensing image and environmental audio data are used in the experiments. The dataset TM_RS comes from the remote sensed data, including six kinds of type of land, such as forest, grass, arable land, sand, bare land and others. The environmental audio data, named as EnAudio, is acquired from network and field recording, with 8k sampling rate, 16 bits and mono-track. It includes five classes, the sound of birds, frogs, wind, rain and thunder. The audio length amounts to almost 10 min. In the pre-processing, silence and noise are removed. Information on these data is given in Table 1.
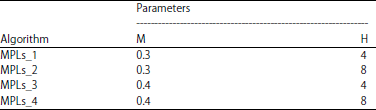
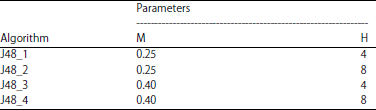
Method of experiment: The single classifier includes the traditional classifying methods such as decision tree J48, neural network and Radius Basic Function (RBF), while Bagging, AdaBoost and Multiple Classifier System (MCS) are involved in the ensemble strategies. Ten base classifiers are used as candidates in the ensemble selection. The WEKA machine learning library16 was used as the source of learning algorithms. Four multilayer perceptrons (MLPs), 4 decision trees (J48), one Radium Basis Function (RBF) classifier and one Naïve Bayes classifier were trained. The different parameters used to train the algorithms for MPLs and decision trees are listed in Table 2 and 3. The rest of the parameters were left unchanged in their default values.
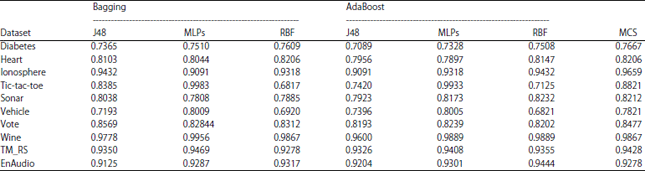
Ensemble classifiers: Table 4 are illustrated the results of the classification accuracy of three ensemble strategies. The J48, MPLs and RBF are base classifier for Bagging and AdaBoost respectively and the default parameters are explored in the J48 and MPLs. The number of iterations is 10. The MCS is ensemble of 10 individual classifiers, whose result is obtained by majority voting. The Overall Accuracy (OA) of three ensemble methods is listed in Table 4.
| Table 1: | Characteristics of the used datasets |
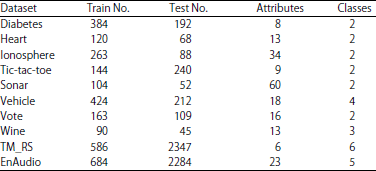 | |
| Table 2: | Different parameter in MLPs |
 | |
| Table 3: | Different parameter in decision trees |
 | |
As the results indicate, three datasets obtained best accuracy by Bagging with MLPs; one by Bagging with J48, two obtained best accuracy by AdaBoost with MLPs, one by AdaBoost with RBF and three by MCS with 10 base classifiers. Overall, the MCS could acquire better classification performance.
Select diverse base classifiers for ensemble: In order to make best use of the larger difference among the base classifiers involved in the Ensemble learning, 6 metrics including Q-statistics, Kappa-statistic, correlation coefficient, disagreement, AD and concurrency are exploited to measure the diversity of classifiers. The search method uses the back-forward reduction with diversity (BRD). So, classification results are summarized in the Table 5.
In Table 5 the 2nd column is the accuracy of MCS in all members ensembles, while the 3rd column to the last one show the results of ensemble with subset of classifiers, which selected by BRD including 6 different measure diversity metrics, respectively. For each dataset, the highest accuracy is in bold font.
The results indicate that it is better to ensemble subset classifiers instead of all of the entire base classifiers. The back-forward reduction with diversity (BRD method) outperforms the MCS in all datasets. In the six measure diversity methods, different metrics have different performance. The BRD-Con, which is concurrency measure, in 5 out of 10 datasets, obtains the highest classification accuracy.
| Table 4: | Classification accuracy for three ensemble methods on each dataset |
 | |
| Table 5: | Classification results of reduction with diversity in ensemble selection |
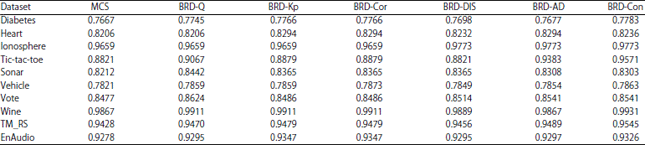 | |
And using BRD-AD, 2 datasets wins the highest accuracy and outperforms the DIS measure in all cases. The BRD-Q, BRD-Kp and BRD-Cor have the same accuracy in most datasets, especially BRD-Kp and BRD-Cor. Thus, the diversity measure methods, considering both accuracy and differences, concurrency and AD are the most effective methods in the ensemble selection. Compared with other metrics, the DIS is not optimal in the BRD method.
CONCLUSION AND FUTURE RECOMMENDATIONS
Selective ensemble learning trains a number of base classifiers and selects part of their outcomes according to a certain rule to assemble. How to select the optimal classifiers involved in the ensemble classification is key factor in ensemble selection performance. In this stud Accuracy and Diversity (AD) and concurrency metrics are proposed to measure the optimal classifiers from the entire base classifiers as well as the Q-statistics, Kappa-statistic, correlation coefficient, dis diversity metrics. In the experiments, ensemble methods including Bagging, AdaBoost, MCS and Back-forward reduction diversity are carried on ten datasets. According to the analysis of experimental results, the proposed ensemble selection method BRD outperformed MCS in classification performance and generalization. Especially, considering both accuracy and difference of classifiers, the concurrency and AD measure methods obtained the better classification results in ensemble selection.
In this study, the initial base classifiers with the random setting the parameters, are not in big scale and only four kinds of the learning methods are explored in the experiments. In the further study, the effective search method will be focus on and the number of ensemble base classifiers is increased to analyze the performance and the effectiveness.
ACKNOWLEDGMENT
This study was supported by the national natural science foundation of China under the Grant No. 61462078.
REFERENCES
- Dietterich, T.G., 1997. Machine-learning research: Four current directions. AI Mag., 18: 97-136.
CrossRefDirect Link - Zhou, Z.H., J. Wu and W. Tang, 2002. Ensembling neural networks: Many could be better than all. Artif. Intell., 137: 239-263.
CrossRefDirect Link - Bi, K., X.D. Wang, X. Yao and J.D. Zhou, 2014. Adaptively selective ensemble algorithm based on bagging and confusion matrix. Acta Electronica Sinica, 42: 711-716.
Direct Link - Zhang, C.X. and J.S. Zhang, 2011. A survey of selective ensemble learning algorithms. Chin. J. Comput., 34: 1399-1410.
Direct Link - Banfield, R.E., L.O. Hall, K.W. Bowyer and W.P. Kegelmeyer, 2005. Ensemble diversity measures and their application to thinning. Inform. Fusion, 6: 49-62.
CrossRefDirect Link - Zhang, M., F. Di and J. Liu, 2015. Universal steganalysis based on selective ensemble classifier. J. Sichuan Univ. (Eng. Sci. Edn.), 47: 36-41.
Direct Link - Kuncheva, L.I. and C.J. Whitaker, 2003. Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy. Mach. Learn., 51: 181-207.
CrossRefDirect Link - Blake, C.L. and C.J. Merz, 1998. UCI Repository of Machine Learning Databases. 1st Edn., University of California, Irvine, CA.
Direct Link