
Chen Yehui
Electronic Communications Engineering College, Anhui Xinhua University, 230088 Hefei, China
Liu Hao
Department of Physics, University of Science and Technology of China, 230026 Hefei, China
Yi Bo
Department of Physics, University of Science and Technology of China, 230026 Hefei, China
Journal of Software Engineering
Year: 2016 | Volume: 10 | Issue: 4 | Page No.: 408-415







ABSTRACT
Background: The RGBD-based human activity recognition has captured extensive concerns of researchers from the domains of entertainment, surveillance, robotics and a variety of systems that involve interactions between persons and electronic devices. However, it is a non-trivial task due to the spatial and temporal variations in the activity data. Materials and Methods: This study propose a Conditional Random Fields (CRF) with star structure to model the variations and accurately recognize activity patterns. The human body is partitioned into five parts, the torso, the left arm, the right arm, the left leg and the right leg. Each vertex in this CRF model corresponds to one part of the human body in an activity sequence. Joint angle features are extracted to support this model. Results: This method not only takes advantage of multiple features and temporal context but also captures the spatial context among the human body parts. Conclusion: Experimental results show that this method achieved a higher recognition rate and it is still effective when self-occlusion happened.
PDF Abstract XML References Citation
Received: February 25, 2015;
Accepted: June 16, 2016;
Published: September 15, 2016
How to cite this article
Chen Yehui, Liu Hao and Yi Bo, 2016. Human Activity Recognition Based-on Conditional Random Fields with Human Body Parts. Journal of Software Engineering, 10: 408-415.
DOI: 10.3923/jse.2016.408.415
URL: https://scialert.net/abstract/?doi=jse.2016.408.415
DOI: 10.3923/jse.2016.408.415
URL: https://scialert.net/abstract/?doi=jse.2016.408.415
INTRODUCTION
Human activity recognition has become a hot topic in the field of computer vision and can be widely used in human-computer interaction, military surveillance, robotics and virtual reality games. The goal of human activity recognition is to automatically detect and analyze human activities from the information acquired from sensors, e.g., a sequence of images, either captured by RGB cameras, range sensors or other sensing modalities.
Recent advances in sensing technology have enabled us to capture the depth information in real-time, which inspired the study on activity recognition from 3D data. In 2011, Shotton et al.1 proposed to extract 3D body joint locations from a single depth image using an object recognition scheme. The human body is labeled as body parts based on the per-pixel classification results. The parts include LU/RU/LW/RW head, neck, L/R shoulder, LU/RU/LW/RW arm, L/R elbow, L/R wrist, L/R hand, LU/RU/ LW/RW torso, LU/RU/LW/RW leg, L/R knee, L/R ankle and L/R foot (left, right, upper, lower). Skeletal joints tracking algorithms were built into the Kinect device, which offers easy access to the skeletal joint locations. This excited considerable interest in the computer vision community. Many algorithms have been proposed recognizing activities using skeletal joint information.
This study addresses the issue of human activity recognition, which is useful in many practical applications. However, human activity recognition is a non-trivial task. The factors that contribute to the challenges include the followings: (1) The activity is of high dimensionality, which is difficult to extract features, (2) Activities are often similar. For example between the activities "Run"and "Walk", there are several similar frames and (3) Because of the sensor’ direction, there is always some of the human body parts which are invisible.
To recognize human activities, several approaches have been proposed past few years. The Dynamic Time Warping (DTW)2, a method for measuring similarity between two temporal sequences, is one of the most popular temporal classification algorithms. However, DWT is not appropriate for a large number of classes. Another popular classifier for human activity recognition is Hidden Markov Models (HMM)3, which is proved successful in speech recognition. Uddin et al.4 proposed a detection method with joint angle feature and HMM model. The HMM model has a set of states that changes with the time, whose process is more in line with people’s activity. However, because of the output independence assumption of HMM, it can't get access to the context, resulting in the feature selection limitation. To solve this problem, Phillips et al.5 proposed maximum entropy method but the maximum entropy model can only find a local optimum value, it also brings a label bias problem. Recently, Conditional Random Fields (CRFs)6 has been applied to the activity detection7-9. The CRF model is an undirected probabilistic graph which can model the posterior probability directly. Also, it does not rely on conditional independence assumptions, has the ability to get use of multi-feature and the context. Long et al.10 had used CRF models in the abnormal activity detection task and achieved better detection results.
In this study, we propose a human activity recognition method (Fig. 1) which can model the human activity class well and recognize them effectively. We observed that: First, even if some different activities have similar frames, these frame’s temporal adjacent frames are different. Second there is a class of spatial context. For example, when people walk, two arms will swing alternately on both sides of the body to keep balance. But when people jump, two arms will always swing at the same direction. This spatial context also makes sense to self-occlusion. So the invisible body part’s state can be inferred from the visible body parts. For feature extraction, first, the human body is partitioned into five parts, the torso, the left upper limb, the right upper limb, the left lower limb, the right lower limb. Then the joint angle features are extracted which are invariant to the camera location and subject appearance and invariant to human body size. To do recognition, a conditional random fields is designed with star structure called star-CRF which can model human activity with both the temporal context and the spatial context. Also, this method can jointly recognize human activity with five human body parts. The experiment results showed that this method achieved a higher recognition rate and it is still effective when self-occlusion happened.
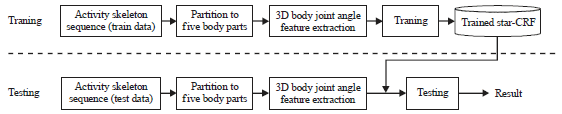 | |
| Fig. 1: | Overview of proposed framework |
MATERIALS AND METHODS
The skeleton structures are different from each other in different motion capture or RGB-D skeleton datasets (Fig. 2). For example, in the CMU Graphics Lab Motion Capture Database and the Motion Capture Database HDM05 the skeleton contain 31 joints, the Prime Sense Natural Interaction Middleware (NiTE) provides 15 joints and the Microsoft Kinect SDK provides 20 joints. Although, the number of joints are different, the essential joints are available in all skeletons. They are head, neck, root, L/R hand, L/R elbow, L/R shoulder, L/R foot, L/R knee, L/R crotch.
These 15 joints are partitioned into 5 parts, torso, right upper limb, left upper limb, right lower limb, left lower limb (Fig. 3).
With a skeleton sequence, to describe the gesture at each frame, the joint angle features are extracted. The skeletal joint angle features are invariant to the camera location and subject appearance and it is invariant to human body size Fig. 4.
Uddin et al.4 proposed the joint angle feature extraction method. In this study, Uddin’s method is used to extract joint angle feature. The 24D feature vector at frame t is:
| (1) |
Then divide it into five parts:
| • | The torso feature |
| • | The left upper limb feature |
| • | The right upper limb feature |
| • | The left lower limb feature |
| • | The right lower limb feature |
In this study, torso feature is used to present the global gesture, left upper limb feature, right upper limb feature, left lower limb feature and right lower limb feature are used to present the left upper gesture, the right upper limb gesture, the left lower limb gesture and the right lower limb gesture respectively.
Star CRF model: The X is a random variable over data sequences to be labeled, Y is a random variable over corresponding label sequences. In this study, X is features and Y is activity classes.
Let G = {V, E} be an undirected graph model. Each element in X and Y is a vertex of G. Edges in G represent the relationships among these vertices.
The structure of traditional CRF is show in Fig. 5a. Y = {Yt, t = 1, 2,…, N} is an observed sequence, X = {Xt, t = 1, 2,…, N} is a label sequence represents the states of X. Xt∈{1, 2,…, S} where, S is the number of activity classes. This structure use one vertex Xt at each frame to represent the state of the frame. There are two sets of edges, one connect Xt and Yt representing the relationship between the state vertex and the observed vertex, another connect Xt and Xt+1, representing the temporal context. The disadvantage of the traditional CRF is it can’t get use of the spatial context.
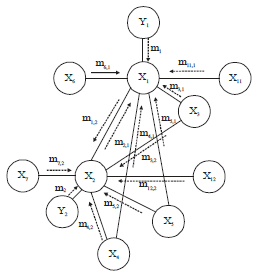
Therefore, a CRF model with star structure showed in Fig. 5 is designed. At each frame, there are five observed vertices and five state vertices and each vertex corresponds to one human body part. Although, the number of vertices increased, the dimension of data at each vertex is reduced. denote the features of the human torso left upper limb right upper limb left lower limb right lower limb while represent the states of the human torso, left upper limb, right upper limb, left lower limb, right lower limb at time t.
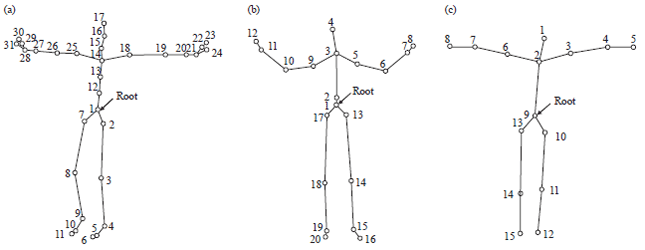 | |
| Fig. 2(a-c): | Skeleton models in different sources, (a) HDM05, (b) Kinect SDK and (c) Kinect NiTe |
In Star CRF, there are five time sequences standing for five parts of human body. Also, there are three sets of edges standing for different relational meanings. The edge set Ea, by which each state is connect with the observation, represents the relationship between the observation sequence and the state sequence. The edge set Eb, by which each state is connect with its neighboring states in the same time sequence, represents the relationship between the states of the same human body part at different times.
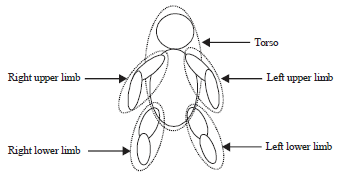 | |
| Fig. 3: | Five human body parts |
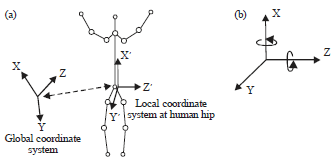 | |
| Fig. 4(a-b): | (a) Articulated skeletal human body model and (b) two rotational euler angles around the X-axis and Z-axis (two DOF at each joint) controlling the movement of each segment |
The edge set Ec, by which each state is connect with its neighboring states across time sequences, represents the relationship between the states of different parts of human body at the same time.
Potential functions ![]() is defined for each edge
is defined for each edge ![]() is defined for each edge
is defined for each edge ![]() and
and ![]() is defined for each edge
is defined for each edge ![]() Star CRFs is determined as:
Star CRFs is determined as:
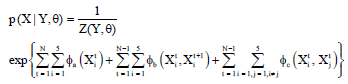 | (2) |
where, z (Y, θ) is the normalization constant.
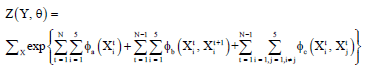 | (3) |
For Multinomial Logistic Repression (MLR)11, observational data does not need to meet the normal distribution restrictions, so that MLR can be adapted to more types of observational data. The potential function ![]() is defined by MLR as:
is defined by MLR as:
| (4) |
The potential functions ![]() and
and ![]() are defined by the promotion of ising/potts model as:
are defined by the promotion of ising/potts model as:
 | |
| Fig. 5(a-b): | The structure of conditional random fields, (a) Traditional CRF and (b) Star CRF |
| (5) |
| (6) |
where, gt, t+1 and gi, j are feature vectors extracted from the pair (t, t+1) and the pair (i, j) of the observational data. The λ is the parameter vector of the potential function ![]() .The
.The ![]() and
and ![]() are the parameter vectors of the potential functions
are the parameter vectors of the potential functions ![]() and
and ![]()
![]() is the set of parameters in the model, where
is the set of parameters in the model, where ![]() ,
, ![]() .
.
Parameter estimation: For estimating the parameters θ = {λ, σb, σc}, it can be assumed that M independent identically distributed labeled training samples {Xm, Ym, = 1, 2,…, M}. The parameters can be estimated by the standard maximum-likelihood (ML) approach. The ML training chooses parameter values such that the logarithm of the likelihood:
| (7) |
For the Star CRFs used in this study, likelihood maximization can be performed using a gradient ascent (BFGS) method12.
Inference: To recognize human activity, the most possible label sequence of observed sequence need to be inferred. There are many inference algorithms for CRFs, including forward-backward algorithm, Viterbi algorithm, junction tree13 and Loopy Belief Propagation (LBP)14,15. In this study, the popular inference algorithm LBP is used to release the restrictive condition.
The Star CRF model can be rewritten as the following form:
| (8) |
Where:
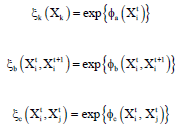
 | |
| Fig. 6: | Local message passing in star CRF network |
Let mkl (Xl) be the message that node Xk sends to Xl, mk (Xk) be the message that observed node Yk send to node Xk and bk (Xk) be the belief at node Xk (Fig. 6). The standard "Max-product" algorithm is shown below:
| • | Initialize all messages mkl (Xl) as uniform distributions and messages mkl (Xk) = ξk (Xl) |
| • | Update messages mkl (Xl) iteratively for d = 1, 2,…, D: |
| (9) |
| • | Compute beliefs: |
| (10) |
| (11) |
RESULTS AND DISCUSSION
The proposed method is used to recognize human activities and compare the performance to existing methods.
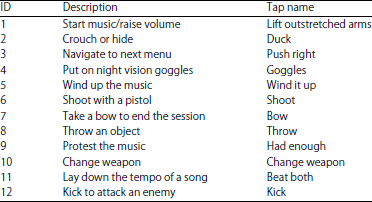
Microsoft Research Cambridge-12 Kinect (MRC12K)16 gesture database is used in our experiments. Microsoft Research Cambridge-12 Kinect gesture database is captured by the depth sensor Kinect. The dataset is comprised of 119 sequences collected from 30 people performing 12 gestures (Table 1). In total, there are 1223 gesture instances. The motion files contain tracks of 20 joints estimated using the Kinect Pose Estimation pipeline.
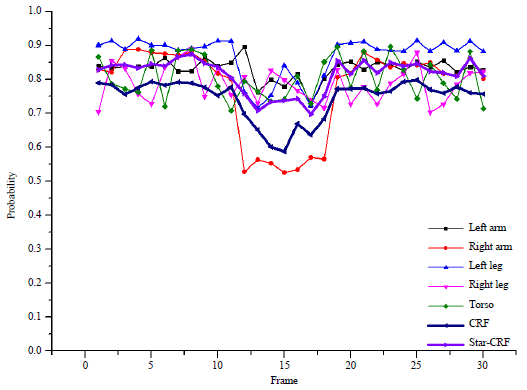 | |
| Fig. 7: | Temporal evolution of probabilities when self-occlusion happened. The right arm is invisible between frame 11 and 19, the probability of recognition with CRF is reduced to 0.6. With Star-CRF, the probability is reduced to 0.7, because the Star-CRF can get use of the spatial context of body parts |
Experimental platform in this experiment is the personal computer with Inter CPU E3-1230v3, 16.0 GB memory and Windows 8.1×64 operating system. The main function of algorithm coded in C++ were called in Matlab. The parameters θ = {λ, σb, σc} of the Star CRF components were learned by the standard ML approach. Each parameter vector λ was initialized to be 0, while the elements of σb and σc were initialized to be random numbers between 0 and 0.5.
In order to evaluate the performance of the proposed method. The correct rate and error rate should be calculated. The correct rate is calculated by:
![]()
where, C and N represent the number of correct recognition and test activities.
The error rate is calculated by:
![]()
where, D represent the number of detection errors, Y represent the number of non-recognize gestures. Star-CRF jointly model five body parts, so it get five labels after inference respective to the five body parts. In the five labels, if there are no more than 3 labels are the same label, it can be considered as a non-recognized activity. The activity recognition results are showed in Table 2.
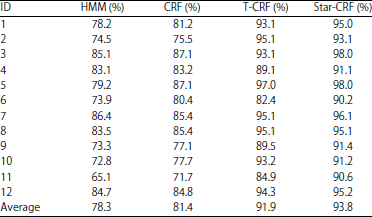
In order to evaluate the performance of Star-CRF, experiments on MRC12K database with Hidden Markov Model (HMM) and Conditional Random Fields (CRF) are also taken. The experiments results are shown in Table 3.
Compare with the results of HMM, CRF, T-CRF17 and Star-CRF, the correct recognition rate of the Star-CRF is higher than those of the HMM, CRF and T-CRF. Because of the output independence assumption of HMM, it can only get access to the above information in temporal context, the correct recognition rate of HMM is 78.3% lower than CRF, T-CRF and Star-CRF. The CRF can get access of temporal context but it ignore the spatial context. Hyunsook Chung proposed a Threshold-CRF to do activity recognition and get a correct recognition rate of 91.9%, however the threshold need to be set manually. Star-CRF has the ability to model human activity with both the temporal context and the spatial context, get a higher correct recognition rate of 93.8%.
The performance of Star-CRF is also tested when self-occlusion happened. Figure 7 shows a recognition result with CRF and Star-CRF for a sequence contain the gestures "Lift outstretched arms".
| Table 1: | Microsoft Research Cambridge-12 Kinect (MRC12K) gesture database |
 | |
| Table 2: | Recognition results with Star-CRF on MRC12K database |
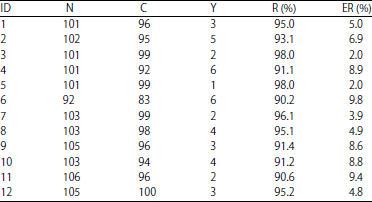 | |
| C: No. of correct recognition, N: No. of test activities, R: Rate, Y: No. of Non-recognize gesture and ER: Error rate | |
| Table 3: | Human abnormal activity recognition results |
 | |
The time evolution of probabilities are illustrated by curves. In Fig. 7, the right upper limb part of the actor is invisible between frame 11 and frame 19. The probability of CRF is reduced to 0.6, while the probability of CRF is reduced to 0.7. The reason is the CRF only get use of temporal context and the spatial context makes Star-CRF to get a better performance.
CONCLUSION
In this study, a novel method of human activity recognition was proposed. In order to do feature extraction, depth information from Microsoft’ Kinect was used. First, the temporal context and the spatial context in human activity sequence were discussed. Second, human body were partitioned into five body parts and extract five feature vectors for the five body parts. Third, a Star-CRF model was proposed to model the five body parts with the temporal context and the spatial context.
In this study, a public data set, the Microsoft Research Cambridge-12 Kinect gesture database is used. The experimental results demonstrated that the proposed method can be efficient and effective for human activity recognition. Near-term future study includes extending the proposed method to real-world applications.
ACKNOWLEDGMENT
We thank the National Natural Science Foundation of China (No. 61071173).
REFERENCES
- Shotton, J., T. Sharp, A. Kipman, A. Fitzgibbon and M. Finocchio et al., 2013. Real-time human pose recognition in parts from single depth images. Commun. ACM, 56: 116-124.
CrossRefDirect Link - Pham, C.H., Q.K. Le and T.H. Le, 2014. Human action recognition using dynamic time warping and voting algorithm. VNU J. Sci. Comput. Sci. Commun. Eng., 30: 22-30.
Direct Link - Lehrmann, A.M., P.V. Gehler and S. Nowozin, 2014. Efficient nonlinear markov models for human motion. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, June 23-28, 2014, Columbus, OH., pp: 1314-1321.
CrossRefDirect Link - Uddin, M.Z., N.D. Thang, J.T. Kim and T.S. Kim, 2011. Human activity recognition using body joint-angle features and hidden Markov model. ETRI J., 33: 569-579.
CrossRefDirect Link - Phillips, S.J., R.P. Anderson and R.E. Schapire, 2006. Maximum entropy modeling of species geographic distributions. Ecol. Modell., 190: 231-259.
CrossRefDirect Link - Lafferty, J.D., A. McCallum and F.C.N. Pereira, 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. Proceedings of the 18th International Conference on Machine Learning, June 28-July 1, 2001, Williamstown, MA., USA., pp: 282-289.
Direct Link - Song, Y., D. Demirdjian and R. Davis, 2012. Continuous body and hand gesture recognition for natural human-computer interaction. ACM Trans. Interact. Intell. Syst., Vol. 2, No. 1.
CrossRefDirect Link - Siddiquie, B., S. Khan, A. Divakaran and H. Sawhney, 2013. Affect analysis in natural human interaction using joint hidden conditional random fields. Proceedings of the IEEE International Conference on Multimedia and Expo, July 15-19, 2013, San Jose, CA., pp: 1-6.
CrossRefDirect Link - Liu, A.A., W.Z. Nie, Y.T. Su, L. Ma, T. Hao and Z.X. Yang, 2015. Coupled hidden conditional random fields for RGB-D human action recognition. Sig. Process., 112: 74-82.
CrossRefDirect Link - Long, Z., G. Li, X. Jinsheng and L. Hao, 2012. Video abnormal target description based on CRF model. Proceedings of the International Conference on Audio, Language and Image Processing, July 16-18, 2012, Shanghai, pp: 519-524.
CrossRefDirect Link - Li, J., J.M. Bioucas-Dias and A. Plaza, 2012. Spectral-spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens., 50: 809-823.
CrossRefDirect Link - Wallach, H., 2003. Efficient training of conditional random fields. Proceedings of the 6th Annual CLUK Research Colloquium, January 6-7, 2003, Edinburgh, UK., pp: 1-8.
Direct Link - Vats, D. and R.D. Nowak, 2014. A junction tree framework for undirected graphical model selection. J. Mach. Learn. Res., 15: 147-191.
Direct Link - Yasuda, M., S. Kataoka and K. Tanaka, 2014. Erratum: Inverse problem in pairwise Markov random fields using loopy belief propagation [J. Phys. Soc. Jpn. 81, 044801 (2012)]. J. Phys. Soc. Jpn., Vol. 83.
CrossRefDirect Link - Fothergill, S., H. Mentis, P. Kohli and S. Nowozin, 2012. Instructing people for training gestural interactive systems. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, May 5-10, 2012, Austin, TX., USA., pp: 1737-1746.
CrossRefDirect Link - Chung, H. and H.D. Yang, 2013. Conditional random field-based gesture recognition with depth information. Opt. Eng., Vol. 52, No. 1.
CrossRefDirect Link