
Zhongping Chen
Hunan Engineering Polytechnic, 410151 Changsha, China
Journal of Software Engineering
Year: 2016 | Volume: 10 | Issue: 3 | Page No.: 253-262







ABSTRACT
In order to meet the needs of goods delivery and pick-up, a mixed integer programming model with simultaneous delivery and pick-up requirement (VRPSDP) was presented for vehicle routing problem. An adaptive hybrid genetic algorithm was developed to solve VRPSDP, a special optimal splitting procedure was used to get the fitness values and a local search was taken as the mutation operator. A novel crossover and a population replacement scheme were designed. Measurement of population diversity and the adjustment rules of mutation probability were also defined. Numerical computations indicated that it was an effective algorithm for solving VRPSDP and VRP.
PDF Abstract XML References Citation
Received: October 18, 2015;
Accepted: May 09, 2016;
Published: June 15, 2016
How to cite this article
Zhongping Chen, 2016. A Routing Optimization Adaptive Hybrid Genetic Algorithm
Research. Journal of Software Engineering, 10: 253-262.
DOI: 10.3923/jse.2016.253.262
URL: https://scialert.net/abstract/?doi=jse.2016.253.262
DOI: 10.3923/jse.2016.253.262
URL: https://scialert.net/abstract/?doi=jse.2016.253.262
INTRODUCTION
Vehicle routing problem with simultaneous delivery and pick-up (VRPSDP) is an important extension of classic Vehicle Routing Problem (VRP). Delivery requirement is that goods are delivered to the customer as customer demand from the logistics centerin, pick-up requirement is that vehicle collects goods and returns logistics center from the customer point. The VRPSDP goal is generally that vehicle travels with the shortest total distance, the requirements of each customer is serviced only once, VRPSDP is widespread in the actual logistics. For example, many logistics companies in the port logistics park have dual function of both logistics center and forwarder, when the container terminals are transported to the logistics enterprises, the goods inside the container will be divided into individual customer goods, the goods are shipped to customers through corporate vehicles; these vehicles will also gather customer goods at the same time, these goods are shipped back to the district for consolidation and shipment. Moreover, VRPSDP is also an important study direction of VRP reverse logistics. The VRP reverse logistics was usually considered separately forward logistics and reverse logistics in past study, vehicle idling was serious, it is not conducive to environmental protection. Customers may have both the distribution and recovery needs in many practical cases. For example, soft drinks are distributed for the grocery store, the owner’s empty bottles may be recycled at the same time.
The VRPSDP was first proposed in the late 1980s (Min, 1989) there were no published results about these issues in the next 10 years. In recent years, the problem once again aroused widespread interest from scholars, the existing study of the issue is to design approximation algorithms. Insertion algorithm was proposed based on load capacity (Salhi and Nagy, 1999), a customer not only was inserted every time. A plurality of customers can also be inserted at the same time, experiments showed that inserting multiple customers may get better results. On the basis of the definition of VRPSDP strong viable and weak viable state, the heuristic method was proposed based on neighborhood search (Nagy and Salhi, 2005), the overall effect was better than the plug-in algorithm. The corresponding mathematical model was established to study VRPSDP from the perspective of reverse logistics (Dethloff, 2001) and insertion algorithm was given based on the remaining load capacity. The Tabu search was combined with variable neighborhood search algorithm (Crispim and Brandao, 2005) hybrid algorithm was proposed to solve the problem. Because the algorithm was used to solve a packing problem in the construction process of the initial solution, its algorithm can reduce the number of vehicles, but there was a substantial increase in the total distance. After the initial solution was generated by inserting rules, record-to-record travel method was used as a framework and neighborhood search was combined with Tabu table, a heuristic algorithm was presented to solve this problem (Chen and Wu, 2006) experiments showed that the algorithm can be the most optimal solution in small-scale examples. The VRPSDP Tabu search algorithm was designed (Montane and Galvao, 2006) four different neighborhood structure was used in the algorithm, focus search and dispersion search mechanisms were increased based on Tabu frequency. A four-stage heuristic algorithm CLOVES (Cluster nodes, orients nodes along a route, assign vehicles to the routes, using GA to improve the search) was proposed (Ganesh and Narendran, 2007), it was used to solve various types of customer demand VRP including VRPSDP. The construction method, neighborhood search method and Tabu search were used for solving VRP with mixed or delivery requirements simultaneously (Bianchessi and Righini, 2007) experimental results showed that the complex structure and variable neighborhood search algorithm were better. The genetic algorithm was improved for solving the machine scheduling problem and it was used to solve VRPSDP (Vural, 2003).
MATERIALS AND METHODS
Symbol definition: The H for the customer set, H = {1, 2,..., n}, H0 is the customer and logistics center set (logistics center point 0), H0 = H∪{0}, K is the maximum number of vehicles in the logistics center that can be used, cij is the distance between the customer i and j, cij = cji, cik+ckj>cij, i, j = 1, 2,..., n, qi is the collection demand for customer i, i = 1, 2,..., n; di is delivery demand of customer i, i = 1, 2,..., n, Q is the maximum capacity of each vehicle, xij is decision variables and only when the vehicle passes arc (i, j), xij = 1, otherwise xij = 0, j = 1, 2,..., n, i ≠ j, yij is the total amount of the loaded and collected goods when the vehicle passed the arc (i, j), i, j = 0, 1,..., n, i ≠ j and zij is total amount of no-distribution goods on board when the vehicle passed the arc (i, j), i, j = 0, 1,..., n, i ≠ j.
Mixed integer programming model: The VRPSDP goal is to design vehicle path with the shortest total distance, it satisfies the constraint: (1) Each path begins from a logistics center and ends at the logistics center, (2) Each path (each car) maximum cargo capacity must be less than or equal to Q at any moment and (3) Every customer is served only once.
For VRPSDP, three subscript vehicle path models are given in this study (Montane and Galvao, 2006), the label indicates with the serial number of the vehicle are removed, the following more compact two subscript mixed integer programming model is given in Eq. 1-9, respectively:
| (1) |
s.t.
| (2) |
| (3) |
| (4) |
| (5) |
| (6) |
yij+zij≤Qxij, i, j = 0, 1,..., n, i ≠ j | (7) |
xij∈{0, 1}, i, j = 0, 1,..., n, i ≠ j | (8) |
yij, zij≥0, i, j = 0, 1,..., n, i ≠ j | (9) |
Equation 1 is minimizing the minimizing objective of the total distance, Eq. 2 and 3 ensure that every customer is accessing the same vehicle and is accessed only once, Eq. 4 is up to limit which vehicle can be used, Eq. 5 and 6 are traffic demand constraint for the distribution and collection, two requirements meet for each customer’s needs, Eq. 7 ensures that cargo does not exceed vehicle capacity in this path and Eq. 8 and 9 are variable value constraints.
VRPSDP’s adaptive hybrid genetic algorithm: Many scholars used genetic algorithms to solve different types VRP, the corresponding study was obtained (Zhao et al., 2004; Jiang and Wang, 2006; Zou et al., 2004; Prins, 2004). In these genetic algorithm for solving VRP, clients are mostly used as a chromosome coding arrangement, then each vehicle is assigned sequentially by number of customers, until the customer has been allocated so far to meet various constraints. This decoding method is simple but the best solution is lost in the chromosome coding and the genetic algorithm often appears premature convergence in solving VRP, problem is easy to fall into local extreme points, the improvement of the standard genetic algorithm also need to be considered in population diversity and genetic operators. Adaptive hybrid genetic algorithm is designed to solve VRPSDP in this article.
Chromosome structure: The problem solution vector is encoded into a permutation of the n natural numbers {1, 2,..., n} in this study, that is H = (g1, g2,..., gn).
Chromosome decoding method: The chromosome structure may form a large path from a logistics center g0, n customers are accessed in g1, g2,..., gn order and it ultimately back to the logistics center g0, as is shown in Fig. 1a. In this study, optimal partitioning method (optimal splitting procedure) of dynamic programming is used to split the shortest path to this big paths, customers will be divided into different sub-path, so that the total length is made the shortest paths to obtain the solution VRPSDP and it is as chromosome fitness value F (H).
Chromosome H = (g1, g2,..., gn) can form a simple directed graph G = (V, A) where, V set is composed of the n+1 nodes (g0, g1,..., gn). The (g0, g1, gi+1,..., gj, g0) can form a path (meet capacity constraints), the arc (gi, gj) is feasible, i.e., the arc (gi, gj)∈A, i≤j. The right value on the arc defines in Eq. 10:
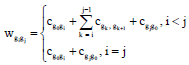 | (10) |
Figure 1 is an example of the optimal partitioning method for decoding chromosome. Wherein the chromosome structure is H = (g1, g2,..., g5), vehicle capacity Q = 5, the two type demands of each customer indicated in parentheses in the Fig. 1a, the first requirement is for the collection and the second is for the distribution requirements, the digital on line is the distance between two points. Figure 1a is a large path, which is formed by the chromosome structure, Fig. 1b is a directed graph of all possible arc, which is gived by the structure of chromosome H, g1 g2: 70 on the arc represents the path (g0, g1, g2, g0) with the 70 length and to meet the capacity constraints.
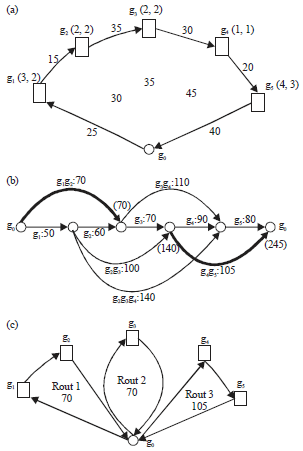 | |
| Fig. 1(a-c): | Chromosome decoding method example |
Thick line part is the shortest path with resource constraints on the directed graph. According to the shortest path in Fig. 1b, customers will be divided into three sub-path, VRPSDP solution is obtained, as shown in Fig. 1c, the optimal objective function value is 70+70+105 = 245.
Since, VRPSDP involves two needs of customers, two resources π and δ need be defined to determine, whether the path is feasible. The π at the customer represents the continue collected capacity after the vehicle passes j. In the initial stage of the iterative determining path feasibility, π is the maximum capacity of each vehicle (π = Q), π decreases with the increase in collect demand. Thus, through arc (i, j), π new value is π = π-qj. Similarly, δ at the customer j represents the distribution capacity after the vehicle passes j, the initial stage δ is the maximum capacity of the vehicle (δ = Q). The δ is different to π, δ not only reduce, while distribution demand increases but also it decreases with the increase in collect demand, after the vehicle passes customer j, maximum amount of distribution is not greater than the maximum amount of the collection. Therefore, through the arc (i, j), δ new value δ = min {δ-dj, π-qj}. The π and δ resources decreases with the iteration, when π<0 or δ<0 a car need to be re-send and the initial value Q are re-set for π and δ the next iteration is done. These are shortest path problems with resource constraints.
Since G does not contain any sub-circle, G shortest path can be obtained by the dynamic programming method, while the H is divided into multiple sub-paths. The algorithm is as follows:
| Step 1: | According chromosome H = (g1, g2,..., gn), all possible arcs (gi, gj) and arc weights wgigj are obtained as previously described method and the Eq. 10, i.e., digraph G is obtained as shown in Fig. 1b |
| Step 2: | Dynamic programming method of the solving shortest path is used to obtain the shortest path of a directed graph G from the start point to the end |
| Step 3: | The various sub-path is obtained according to the shortest path, which is VRPS-DP solution |
Chromosome cross-replication: A new cross-way is introduced in this study, the information can better retained in a path of the parent, even when two parents are the same individual, new individuals still be produced, thereby the standard genetic algorithm "Premature convergence" shortcomings are effectively avoided, this is that a conventional crossover are not available. Figure 2 illustrates its operation: Customers which belong to a path are randomly selected from P1 and P2, respectively as a mating area. For example, the clients in a path of P1 are 6 7 8, the client in a path of P2 is 5 2 1 8, the selected customers are added to the front of each other, the second portion is shown in Fig. 2. Finally, the same natural number is erased in the mating region, the final progeny C1 and C2 are obtained.
The achieved cross way requires to record each client belong paths, chromosome in this study consists of two parts: (1) Vehicle routing order and (2) Customer belong path. After each cross, optimal partitioning method is called again the new generation chromosomes were decoded to determine the path to your customers and adapted value is obtained.
Mutation operator: For VRPSDP, neighborhood search (local search) is used as a method of mutation operator to constitute hybrid genetic algorithm (hybrid genetic algorithm). Here the following three methods are mainly used as neighborhood structure:
| • | Or-opt: A customer point i or two consecutive clients point (i, j), which belong to the same path are removed from the original location, they are inserted into point k. Where k can be customer point and can also be a starting point on any path, k and i can be on the same path or on different paths. The relative positions of the two customer points (i, j) can be unchanged, they can be swaped from a certain probability |
| • | 2-opt: Any two client’s points (i, j) are taken, which belong to the same path, their locations are interchanged |
| • | 2-exchange: 2-exchange is a 2-opt extension, client positions of two points i and j are selected respectively and swaped from the two different paths r1 and r2 |
| Fig. 2: | Cross-way example |
The sub-individual C is formed after cross, neighborhood search will be done in mutation probability pm. In each cycle, possible combinations (i, j), i, j = 1, ..., n, i ≠ j will in turn be searched, each combination (i, j) are sequentially searched by these three neighborhood structure, after an improved solution obtained, the original solution is modified, the no-search neighborhood structures no longer have be searched, the cycle is end, the next cycle is done on the basis of the modified solution and the combination (i, j), which has not been searched modified, possible combinations (i', j') is re-searched, the above neighborhood search method is repeated continuously until solutions can not be any improvement and termination is made. Because (i, j) and (j, i) are two different combinations, the combination number is up to n2.
Population structure and generating initial population: Because each variability will improve chromosome solution after cross, the diversity of population could be undermined, premature convergence is leaded. In this study, it is design a new group structure, premature convergence generation is prevented with the aforementioned crossover together.
For the population Ω with a scale pop, according to fitness ascending order, the chromosome is sorted to obtain (H1, H2,..., Hpop). In the initial population generation and group’s update process, it is not allowed to generate "clone" (identical) individuals, the population adiversity need to be checked for each new individual. Fitness is taken to characterize the diversity of the population. Specifically, the definition of a constant λ>0, for a new generation of individuals H'k, only to meet ∀Hi∈Ω, if |F(Hi)-F(H'k)|≥λ, H'k can be added to Ω.
If the new generation individual H'k does not satisfy the diversity of the population, their fitness is better than the best individual H1 of the present population, H'k diversity of the population is no longer check, it is directly allowed to replace an individual in the original population. This method is similar to defy guidelines to ensure that the best solutions from the update process will not be discarded, thereby the convergence rate is speeded up.
Initial population is randomly generated. When a new individual Hk is generated, if Hk diversity of the population does not meet the requirements, they need be regenerated. This study stipulates that the regenerated number of single individuals do not exceed σ times, σ = 30. If the requirements of Hk still can be meet inside σ times, the initial generation process of population is stopped, the population size is reduced to k-1, (i.e., pop = k-1). This situation will happen only when the problem of relatively small-scale or set of pop too large.
Adaptive mutation probability: Adaptive mutation probability of genetic algorithm has significant improvements in maintaining population diversity and optimization capabilities. Adaptive genetic algorithm with the original mutation probability is directly determined by the fitness value, it is different from mutation probability of this study, this mutation probability is decided by number k of individual fitness value from small to large order, the individual is generated by the cross in the original population. It is defined as follows in Eq. 11:
| (11) |
Adjustment rule: In the process of updating population, if the current number of times that the best solution remains unchanged is more than half a predetermined maximum number of algorithms, the probability of individual variability need to be increased, a new mutation probability is taken p'm(k) = 1.5 pm; once the current best solution is improved, the mutation probability will be restored into p'm(k) = pm(k).
Algorithm steps: The αmax is maximum number of crosses, βmax is maximum number of the current unchanged best solution, they are as the algorithm termination conditions.
Step 1 (Initialization): Generated scale is pop, it meets the initial population 0 of the population diversity, the fitness value is calculated for each individual and the fitness values are sorted from small to large order; α, β are assigned to 0.
Step 2 (Select): Father individuals (P1, P2) are generated by tournament selection method, two individuals are selected randomly from population, each parent individual is the merit between two individuals.
Step 3 (Cross): Father individuals (P1, P2) are intersected and a individual C is randomly selected from the two sub-cross individuals, it is used as the variability and the updated object.
Step 4 (Updated individuals are selected): A individual Hk is randomly selected from the second half of population, k≥[pop/2], it is as the individual that need to be updated in n individuals of the original population, thus the best individuals are retained.
Step 5 (Adaptive mutation probability): According to adaptation value F (C) ranking position of offspring C in Ω, mutation probability pm is calculated by Eq. 11, if β>0.5 βmax, pm = 1.5 pm is obtained by the adjustment rules.
Step 6 (Variation): According to the mutation probability pm or p'm, C is mutated with a neighborhood search method to get new chromosome M and only when chromosome M meets diversity of the population (refers to the original population, in which Hk was removed), C is replaced with M.
Step 7 (Contempt guidelines): If F(C)<F(Hk), Hk is replaced with C, the best solution remains the same frequency β = 0, cross number α plus 1, the population is reordered to go to Step 9, otherwise continue.
Step 8 (Update): If the chromosome C satisfy the diversity of population, Hk is placed by chromosome C, population is reordered α, β, respectively, plus 1, go to Step 9; otherwise C does not satisfy the diversity of the population directly to Step 9.
Step 9 (Termination or transfer): If α≥αmax or β≥βmax, algorithm ends, otherwise go to step 2.
RESULTS AND DISCUSSION
To test the effectiveness of the algorithm, VRP and VRPSDP typical examples are used to test in this study, they are compared with different optimization algorithms.
To test the algorithm on the sensitivity and effectiveness in solving various parameters, different values of the parameters were set as follows: pop = 30, 50, λ = 0.3, 0.5, 0.8; ![]() and
and ![]() are given by the Eq. 12 and 13,
are given by the Eq. 12 and 13, ![]() and
and ![]() represent respectively low, middle and high three cases of the mutation probability; αmax = 20000, βmax = 10000 are unchanged.
represent respectively low, middle and high three cases of the mutation probability; αmax = 20000, βmax = 10000 are unchanged.
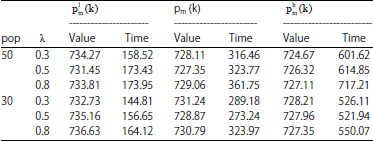
Experiment: The various combinations of the above parameters are tested for instance the size of 100 VRPSDP (CMT3X) (Salhi and Nagy, 1999) and they run 10 times at random for each combination of parameters, the results are shown in Table 1. Wherein, after algorithms runn for 10 times, value and time was respectively average calculation time and average value of the resulting solution, the time unit is second.
| (12) |
| (13) |
Analysis: Table 1 shows that, in the same pop and λ, computing time will grow significantly with increasing the mutation probability, due to the number of neighborhood search is increased, the average search quality of algorithm has also been improved. At the same mutation probability and λ except a pair of data, λ = 0.3 and mutation probability p, average search quality will be improved with the increase of population size, computing time will increase, which is due to increased algorithmic search space. The λ impact of changes is not clear on the quality of the search algorithm, in most cases the computing time will increase with the increases. In addition, after the population size, mutation probability, λ and other parameters are fixed, the results of other experiments show that αmax and βmax role in the algorithm is similar to evolution generation number in the standard genetic algorithm.
After the search quality and computation time are weighed, the algorithm parameters are taken as pop = 50, λ = 0.5, αmax = 20000 and βmax = 10000 in the following experiments. Mutation probability pm is determined by the Eq. 11.
| Table 1: | Calculated results of AHGA algorithm solving CMT3X |
 | |
| Table 2: | Comparison of several algorithm’s optimal values for E-n51-k5 VRP |
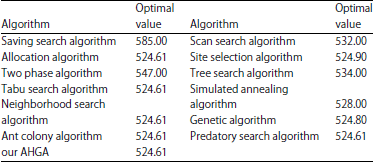 | |
Experiment example 1-VRP: When VRPSDP collected demand of all customers are 0:00, it can be translated into a general VRP, therefore our algorithm can also be used to solve general VRP. For E-n51-k5 VRP test case was proposed by Christofides and Eilon (Salhi and Nagy, 1999), the examples are used to test our AHGA algorithm, Predatory search algorithm (Jiang and Wang, 2006), as well as the other optimization algorithms, which were summarized in literature (Jiang and Wang, 2006). Table 2 shows the results were obtained after these algorithms randomly run 10 times. Data in the Table 2 shows that the obtained optimal value reached the best known solution in the proposed algorithm, the corresponding five vehicle path was exactly the same with the literature (Jiang and Wang, 2006).
In order to verify the effectiveness of our AHGA algorithm for solving large-scale VRP, VRP were calculated with size L, respectively 100, 150 and 199 which Christofides Mingozzi and Toth proposed (separately calculated 10 times), our AHGA results were compared with the literature summary optimization algorithms (Jiang and Wang, 2006). From Table 3 shows that the compared results with other algorithms, this algorithm can be morethan other algorithms in best solution, it fully shows the effectiveness of our AHGA algorithm. Because there is no summary of the relevant algorithm computation time in the literature (Jiang and Wang, 2006), comparison of computation time is not done. Even when the VRP problem with scale 199 is solved by our AHGA algorithm, maximum calculation time is also within 22 min, it is acceptable.
Experiment example 2-VRPSDP: Christofides, examples of the VRP were about transformation, it was converted into VRPSDP instance, the scale was 50, 75, 100, 120, 150 and 199 (Salhi and Nagy, 1999). The "Y" type problem is instances of interchangeable collection and delivery demands in "X" type problem.
| Table 3: | Compared effect with other heuristics optimal algorithm |
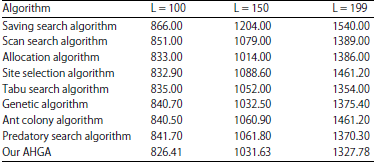 | |
Since then, intelligent optimization algorithms, which is mostly related to solving VRPSDP were tested by this instance, the existing best results were made on different scale (Chen and Wu, 2006; Montane and Galvao, 2006). Our AHGA algorithm were compared with the results of the literature (Chen and Wu, 2006; Montane and Galvao, 2006), it was also calculated to 10 times and the best solution was obtained, the compared the results are shown in Table 4. Where, RTR is record-to-record travel proposed algorithm (Chen and Wu, 2006), TS is Tabu search algorithm (Montane and Galvao, 2006), AHGA is proposed in this study. Value was total path length which corresponding algorithms obtained the best solution, veh wasthe number of the used vehicles, time was the required time of the algorithm running, the time unit is second(s). "Total" line represents sum of the best solutions which each algorithm obtained in all instances.
Due to the randomness of the proposed algorithm, the stability of the algorithm is tested, Table 5 shows the obtained solution average of 10 times calculation, the worst value and standard deviation, two columns under average were solving mean and mean time, the two columns under worst were the worst value and maximum computing time to solve. For ease of comparison, Table 5 once again shows the best solution, which were given in the literature (Chen and Wu, 2006; Montane and Galvao, 2006).
Comparative analysis: Table 4 shows that the proposed algorithm results exceed the best available solution in 10 instances of 14 instances VRPSDP and AHGA results in example CMT12X are basically the same with the best available solution. Only in these three instances of CMT2Y, CMT3Y and CMT4Y, algorithm does not meet the best known solution, but the gap is very small between the AHGA result and the best known solution, the relative error is less than 0.5%. In comparison the number of the used vehicles is more than the best known solution except the number of the used vehicles in example CMT5Y, AHGA results in the other instances already have reached the number of the used vehicles in the best known solution, especially for instance CMTl1Y, our algorithm vehicles are fewer than the best known solution.
| Table 4: | Comparison of the best existing solutions in VRPSDP examples |
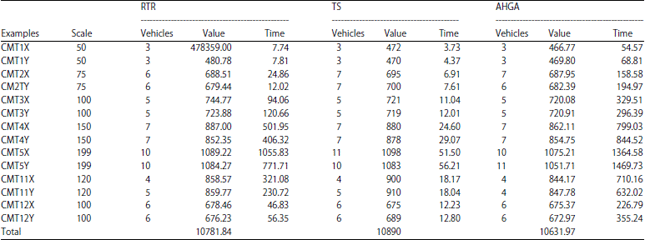 | |
| Table 5: | AHGA stability |
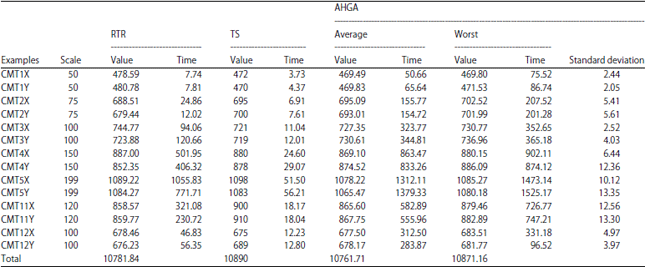 | |
The sum of all best solutions in AHGA algorithm is also less than other algorithms in 14 instances, it increases by 1.4 and 2.4%, respectively than RTR and TS. In the running time, although computation time in AHGA algorithm is longer than TR and TS, it is still within the acceptable range.
Table 5 shows that the average value and the worst value of our algorithm solution b for 10 times still be better than or to achieve the best available solution in these 4 instances of CMT1X, CMT4X, CMT5X and CMT5Y, AHGA average is better than the best available solution for solving instances CMT1Y. In the rest of the practice and the gaps of the average and the worst value are small between AHGA algorithm solution and the best known solution, the relative error is less than 3 and 4%. Apart CMT3Y, the average of AHGA algorithm solution is better than the RTR algorithm and TS algorithm in other instances. With increasing instance’s size, standard deviation of solutions has tended to increase, but also the largest standard deviation is within 14, it has described that AHGA is stable in solving VRPSDP. In addition, the average sum of our algorithm solutions is also less than other algorithms for solving the 14 instances, it is better 0.2 and 1.2%, respectively than RTR and TS. Table 5 shows the average computation time and maximum computing time, the computation time of the algorithm is still long than RTR and TS, but even the longest computing time is also acceptable range.
Figure 3 shows the optimal evolution processes of AHGA algorithm to seek the best solution on the CMT3X and CMT4X.
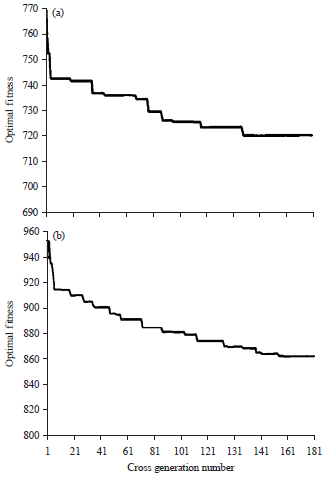 | |
| Fig. 3(a-b): | Optimal evolution figure of AHGA solving (a) CMT3X and (b) CMT4X |
Since this algorithm does not "Evolution generation number" concept when the optimal evolution diagrams are drawed, cross for every 100 generations is as a generation, the best value of the current population is taken as the best value of this generation, the best evolution is showed in Fig. 3. As can be seen from Figure 3 that the adaptive hybrid genetic algorithm in this paper has a faster convergence rate.
During the experiment, if the optimal partitioning method is not used for decoding, only according to natural number arrangement of chromosomes and the vehicle capacity limits to decoded, it will greatly reduce the quality of the algorithm. If a simple two exchange variation is used to substitute neighborhood search algorithm as the mutation operator, computation time is reduced but the quality of the solution has been significantly reduced. In addition, some of the more difficult or large-scale problems are solved, adaptive changes of mutation probability may increase the computation time but it can improve the quality of the solution.
CONCLUSION
Adaptive Hybrid Genetic Algorithm (AHGA) is designed to solve VRPSDP in this study. Replacement ranks are used as chromosome structure in algorithm, it is convert into a simple directed figure, dynamic programming method for solving the shortest path is used to get the VRPSDP best solution at this chromosome structure. A mutation operator is obtained by neighborhood search algorithm, which is composed of a variety of neighborhood structures, such as 2-opt, 2-exchange and or-opt other components, the probability of individual variation adaptively changes in ascending order of number k of its fitness value and it is combined with innovative crossover and update policies, as well as the structure of population diversity and many other technologies, the effect of genetic algorithms are greatly improved to solve. The VRP and VRPSDP two sets of experiments are compared with existing optimization algorithms in their result of the comparison example, in most instances, the proposed algorithm outperforms the existing methods, it shows that the algorithm is efficient algorithm for solving the VRP and VRPSDP.
This algorithm still needs to continue to improve in order to be applicable to other types of VRP, such as VRPSDP and VRP with time windows, mileage and vehicle restrictions. In addition, our algorithm did not get comparative advantage in the calculation of time and therefore, the effect of the solution need to be maintained and improved continuely to shorten the calculation time.
REFERENCES
- Min, H., 1989. The multiple vehicle routing problem with simultaneous delivery and pick-up points. Transp. Res. Part A: Gen., 23: 377-386.
CrossRefDirect Link - Salhi, S. and G. Nagy, 1999. A cluster insertion heuristic for single and multiple depot vehicle routing problems with backhauling. J. Operat. Res. Soc., 50: 1034-1042.
CrossRefDirect Link - Nagy, G. and S. Salhi, 2005. Heuristic algorithms for single and multiple depot vehicle routing problems with pickups and deliveries. Euro. J. Operat. Res., 162: 126-141.
CrossRefDirect Link - Dethloff, J., 2001. Vehicle routing and reverse logistics: the vehicle routing problem with simultaneous delivery and pick-up. OR-Spektrum, 23: 79-96.
CrossRefDirect Link - Crispim, J. and J. Brandao, 2005. Metaheuristics applied to mixed and simultaneous extensions of vehicle routing problems with backhauls. J. Operat. Res. Soc., 56: 1296-1302.
Direct Link - Chen, J.F. and T.H. Wu, 2006. Vehicle routing problem with simultaneous deliveries and pickups. J. Operat. Res. Soc., 57: 579-587.
Direct Link - Montane, F.A.T. and R.D. Galvao, 2006. A tabu search algorithm for the vehicle routing problem with simultaneous pick-up and delivery service. J. Comput. Operat. Res., 33: 595-619.
CrossRefDirect Link - Ganesh, K. and T.T. Narendran, 2007. CLOVES: A cluster-and-search heuristic to solve the vehicle routing problem with delivery and pick-up. Eur. J. Operat. Res., 178: 699-717.
CrossRefDirect Link - Bianchessi, N. and G. Righini, 2007. Heuristic algorithms for the vehicle routing problem with simultaneous pick-up and delivery. Comput. Operat. Res., 34: 578-594.
CrossRefDirect Link - Zhao, Y.W., B. Wu, L. Jiang, H.Z. Dong and W.L. Wang, 2004. Double populations genetic algorithm for vehicle routing problem. Comput. Integr. Manufact. Syst., 10: 303-306.
Direct Link - Prins, C., 2004. A simple and effective evolutionary algorithm for the vehicle routing problem. Comput. Operat. Res., 31: 1985-2002.
CrossRefDirect Link