
Yong Yang
Northeast Petroleum University, Daqing, 163318, China
Mingtao Wu
Institute of Petroleum Economics and Management, Northeast Petroleum University, Daqing, 163318, China
Jianjun Xu
Northeast Petroleum University, Daqing, 163318, China
Journal of Software Engineering
Year: 2015 | Volume: 9 | Issue: 3 | Page No.: 666-672







ABSTRACT
Arithmetic based on wavelet transform and process Support Vector Machine (SVM) for automatically identifying log-curve formation is proposed. Wavelet transform can transform any log-curve to space vector which the experiment system requires, then use the theory of process SVM automatically to identify log-curve. The results of experiment indicate this arithmetic has good identification ability and strong generalization ability on occasion that the number of training swatch is limited.
PDF Abstract XML References Citation
Received: October 30, 2014;
Accepted: February 07, 2015;
Published: March 05, 2015
How to cite this article
Yong Yang, Mingtao Wu and Jianjun Xu, 2015. Arithmetic Based on Wavelet Transform and Process SVM for Automatically
Identifying Log-Curve Formation. Journal of Software Engineering, 9: 666-672.
DOI: 10.3923/jse.2015.666.672
URL: https://scialert.net/abstract/?doi=jse.2015.666.672
DOI: 10.3923/jse.2015.666.672
URL: https://scialert.net/abstract/?doi=jse.2015.666.672
INTRODUCTION
Now-a-days, many oil fields take the method of water flooding to get the oil. The identity of the situation of water out behavior is an important problem that is urgent to solve in the middle and later period of the oilfield development (Yan et al., 2014). The identity of the water-flooded zone is mainly based on the log-curves that reflect the formation’s physical and chemical properties. How to classify automatically according to this information is a problem in the analysis of the oilfield geology (Xu and Hu, 2010). Artificial perception calls for a lot of work and it’s too slow to meet the actual need. The highest accuracy of the recognition at the present is between 70-80%, for the water flooded layer recognition is influenced by a lot of conditions underground (Wang et al., 2012).
To know the condition of the water-flooded zone, in the process of the analysis of the oilfield geology, we often take the method of making a coring well, then guide the analysis of the geology according to the property of the underground core, corresponding the log-curve (Gao and Wang, 2010). Because it cost a big amount of money to make the coring wells, the amount of the coring wells is highly limited (Grbic et al., 2010). Our topic is how to make the data we get reflect the actual curve’s geometric property in the space, using the limited information from the log-curve of the coring well, then to get the right rules and use them in the later geologic analysis (Vapnik, 1995). There are many identification methods of the log-curves, we have many transformations in extracting the characteristics of the curves. In this text, we have disposed the original data with wavelet, thus decreased the complexity of calculation greatly and reflected the geometry characteristics of the original data in the aspects of wave crests and inflection points very well (Cui et al., 2014).
The literatures put forward the model of identification method (Wang et al., 2010). The process neuron has a similar formation with the traditional MP model which is constituted by weight, aggregation and excitation operation (Peng et al., 2013). The difference between the traditional neuron and the process neuron is that the later one calls for time-varying inputting and weighting, its aggregation operation contents multi-input aggregation as well as the accumulation of the time process (Xu et al., 2011). For the training of the process neuron net, the literature has given us a general learning algorithm based on gradient descent algorithm. In this text, we improved the traditional algorithm and put forward a model of identifying process SVM log-curve (Shang et al., 2006). The results of experiment indicate this arithmetic has good identification ability and strong generalization ability on occasion that the number of training swatch is limited.
MATERIALS AND METHODS
Process support vector machine model: The process support vector machine is made up of wavelet transform, Kernel function transform and maximum liberal classification. The output (decision rule) is resolution analysis. Its basic thought:
| (1) |
In this equation, (x1(t), x2(t), x3(t),…, xn(t)) are the input vectors, (y1(t), y2(t), x3(t),…, ym(t)) are vectors we get after wavelet transform. K(yi, y) is the Kernel function. yi (i = 1, 2,..., k) in the equation is the support vector after training. y is the input vector y = (y1(t), y2(t), x3(t),…, yn(t)). Weight Wi = aizi,.b is the constant. The structure is shown in the Fig. 1.
In the work of oil field geological analysis, people get a group of oil reservoir information from different depths after analyzing. Each information of a reservoir is a group of log-curve information, i.e., a group of time functions in different lengths. In order to standardize the information, we must standardized interpolate the information.
The fitted time function must reflect the character of the origin data; this character should present the space geometric characteristics. So, it is not just a simple question of numerical approach.
Basic wavelet theory: Wavelet is a function or signal ψ(x) which meets the following condition in the function space L2(R):
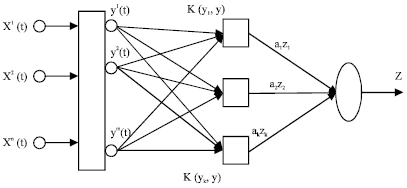 | |
| Fig. 1: | Process support vector machine model |
| (2) |
where, R* = R-{0} stands for all the nonvanishing real numbers. Sometimes, ψ(x) is also known as wavelet generating functions, with the aforementioned condition called admissible condition. For any real number pair (a, b), in which the parameter a must be a nonvanishing real number, we call the functions of the following form:
| (3) |
The parameter (a, b) dependent continuous wavelet functions which is created by the wavelet generating functions ψ(x). It is also called xiaobo for short in Chinese.
Wavelet transform: Wavelet transform is a kind of new transformational analysis method, it is originated from multi-is to represent the function f(t) in L2(R) as a series of step-by-step formulation, each one of it is a form of f(t) after smoothing, they correspond different resolutions separately (Pontil and Verri, 1997).
The sampling step length of wavelet transform is adjustable in the time and space domain for different frequency components. Precisely to say, time decides frequency longer the time, lower the frequency, vice versa. It is just in this sense that wavelet transform is called the mathematics microscope. It can decompose the signals or pics into mixed multi-scales, as well as taking the corresponding thickness step length in the certain time domain for the different frequency components, thereby consistently focus on any tiny details. This is where wavelet transform is better than the classic Fourier Transform and windowed FFT (Cristianini et al., 2002).
Support vector machine: The SVM (Support Vector Machine) is a kind of new machine learning method developed on the basis of the statistical learning theory. It focus on the research of statistical law and learning method. The basic thought of the SVM is like the following, to reflect the input vector x to a high-dimensional characteristic space Z by the formerly chosen nonlinear mappings and construct a optimal separating hyperplane. The main target of SVM is to get the optimal solution with the existing information, rather than the one when the sample size is nearly infinite. There are several algorithms that are most frequently used (Shang et al., 2003).
| • | C-support vector classification (C-SVC) |
| • | V-support vector classification (v-SVC) |
| • | Distribution estimation (one-class SVM) |
| • | Epsilon-support vector regression (epsilon-SVR) |
| • | V-support vector regression (v-SVR) |
Among all of the methods, C-SVC and v-SVC are used for classification algorithm; epsilon-SVR and v-SVR are used for regression algorithm and one-class SVM, classification assessment (Yan et al., 2013).
In the mapping process from the low-dimensional input space to the high-dimensional output space, the space dimensional grows rapidly. For example, under the m times of polynomial map, the original n-dimensional input space will be reflected to the O(n2) dimensional space, thus making it difficult to calculate the optimal segregated plane directly in the feature space in the most cases. SVM transforms this problem to the input space to calculate by defining the kernel functions. At present, the main kernel functions contains RBF function, linear function, poly function and sigmoid function.
After nonlinear transformation, we come to consider the following linear classification problems can be divided into two:
| (4) |
In the Eq. 4, the xi is independent and identically distributed.
The property of linear separability reveals that such classification problem bears no empirical risk, according to the theory of Structural Risk Minimization, all we have to do is to minimize the confidence interval. As the confidence interval is the increasing function of the VC dimension h, the Structural Risk Minimization reflects in minimizing the VC dimension h. In order to reduce the repeat of the classification plane, we bind the (w, b) as when the data points x1, x2…, xl w situate in the globe with the radius of r, in the formula of, the VC dimension h≤min{r2A2, N} in SVM, under the situation of linearly separable, the problem of calculating the (w, b) with the minimal expected risk can be attributed as the following:
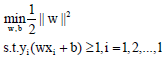 | (5) |
From the former analysis, we know that this optimization problem means to minimize the bound of the VC dimension when there is no expected risk, thereby minimizing the VC dimension. So, that we say SVM is the approximate realization of the structural risk minimization theory.
Aiming to the former optimization problem, we can use the Lagrange multiplier method which is equivalent to:
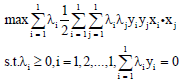 | (6) |
Obviously, this optimization problem is a convex optimization problem, so that its local solution must be a global optimal solution. Transforming the classification problem into a convex optimization problem has never been achieved, though the feed forward neural network has made much effort in many ways. The other important meaning of this optimization problem is that it is only related to the inner product and it lays the foundation of the application of the kernel trick. From the optimization problem, we can get the λi, thus comes:
| (7) |
In the Eq. 7, λi is the solution towards the dual programming problem given by the former optimization problem. It is one of the most important features of SVM that the vector of the classification hyperplane is the linear combination of the sample points. The data point xi that is corresponding λi is called support vector.
The final decision function is as following:
| (8) |
Description of the algorithm: The Support Vector Machine (SVM) we choose is the C-SVC, in the following algorithm, we separately use three kind of kernel functions, RBF function, poly function and sigmoid function and compare the experiment results.
The algorithm is as the following:
| Step 1: | Reflect the log-curve to the vector space by wavelet transforming |
| Step 2: | Input the vector we get to the SVM training model |
| Step 3: | Output the support vector and the relative parameters |
| Step 4: | Found the SVM curve identification model based on wavelet |
| Step 5: | Input the log-curve that is to be analyzed |
| Step 6: | Output the recognition effect |
RESULTS AND DISCUSSION
The recognition of the water-flooded zone is largely based on the log-curves that can reflect the physical and chemical properties. After the relative analysis and statistics, according to the experience of the field experts, the writer chose Spontaneous Potential (SP), high resolution acoustic transit time (AC), High resolution deep lateral resistivity Rlld and the difference between micro potential and micro gradient, Rmn-Rmg, as the logging feature parameters for the recognition of the water-flooded zone’s water flooded grade and the output is the water flooded grade.
From the limited reservoir data of the core holes, we chose 450 representative water-out reservoir sample to form a training set and 225 reservoir sample to form a test suite. According to the determination method of the pattern classes number, the water flooded grade of the reservoir can be divided into 4 situations, strong water flooding, secondary water flooding, weak water flooding and not flooded.
We deal with the 450 training samples by wavelet transform, then input the results to SVM to train. After training, we get the corresponding support vectors and weight parameters, thus getting the model as shown in Fig. 1. In the experiment, when we use RBF function as the kernel function; we get the most support vectors, the highest classification accuracy in a fast running speed. So, we choose RBF function as the kernel function, the experiment results are shown in Table 1 and 2.
When we back to judge the training sample with the studied SVM actuator, the correct recognition rate is 90.5%; when judging the 305 samples in the test suite, the correct recognition rate is 78.1%. It is a fairly good result in terms of flooded layer’s automatic recognition. When the same data are used in the neural network, the sample accuracy will come to 96.4% but the accuracy of the test suite is only 73.4%. The experiment results are shown in Table 3.
| Table 1: | Conditions of supporting vectors obtained by several kernel functions |
 | |
| Table 2: | Conditions of training speed and accuracy obtained by several kernel functions |
 | |
| Table 3: | Comparison between B-SVM algorithm and process neural network |
 | |
CONCLUSION
We can know from the experiment results that although the accuracy of the training sample is only 90.5%, it has a strong ability of generalization. So the process support vector machine presented in this study overcame the problem of long neural network training time and weak generalization ability. Furthermore, it has a very good reference value in solving the problems of pattern identification of time varying system, system identification and simulation modeling.
ACKNOWLEDGMENT
This study was supported by Youth science fund project (2013QN204); Education science “twelfth five-year” plan project for 2013 of Heilongjiang province (GBD1213032).
REFERENCES
- Yan, L., Y. Zhu, J. Xu, W. Ren, Q. Wang and Z. Sun, 2014. Transmission lines modeling method based on fractional order calculus theory. Trans. China Electrotech. Soc., 29: 260-268.
Direct Link - Xu, J. and S. Hu, 2010. Nonlinear process monitoring and fault diagnosis based on KPCA and MKL-SVM. Proceedings of the International Conference on Artificial Intelligence and Computational Intelligence, Volume 1, October 23-24, 2010, Sanya, China, pp: 233-237.
CrossRef - Grbic, R., D. Sliskovic and E.K. Nyarko, 2010. Application of PLS and LS-SVM in difficult-to-measure process variable estimation. Proceedings of the 8th International Symposium on Intelligent Systems and Informatics, September 10-11, 2010, Subotica, Serbia, pp: 313-318.
CrossRef - Cui, J., Y.Q. Huang, Y.B. Xie, J.J. Xu, L.M. Yan and Y.S. Zhu, 2014. Power system state estimation of quadrature Kalman filter based on PMU/SCADA measurements. Electr. Mach. Control, 18: 79-84.
Direct Link - Wang, A., M. Sha, L. Liu and F. Zhao, 2010. Fault diagnosis of TE process based on ensemble improved binary-tree SVM. Proceedings of the IEEE 5th International Conference on Bio-Inspired Computing: Theories and Applications, September 23-26, 2010, Changsha, China, pp: 908-912.
CrossRef - Peng, Y., X. Zhang, Z. Han and J. Jiao, 2013. Dynamic fault diagnosis in chemical process based on SVM-HMM. Proceedings of the IEEE International Conference on Mechatronics and Automation, August 4-7, 2013, Takamatsu, Japan, pp: 1687-1691.
CrossRef - Xu, J.J., L.N. Sha, Y. Zhang, D.F. Zhang, G.C. Liu, A.H. Xu and H.Y. Li, 2011. A new algorithm for minimum spanning tree. Power Syst. Prot. Control, 39: 107-112.
Direct Link - Shang, F.H., X.J. Miao, Z.Y. Wang and S.W. Xin, 2006. Automatic identifying algorithm of water-flooded zone based on B-SVM. Proceedings of the International Conference on Machine Learning and Cybernetics, August 13-16, 2006, Dalian, China, pp: 4035-4039.
CrossRef - Shang, F.H., T.J. Zhao and S. Li, 2003. A normalized fuzzy neural network and its application. Proceedings of the International Conference on Machine Learning and Cybernetics, Volume 2, November 2-5, 2003, Xi'an, China, pp: 1088-1091.
CrossRef - Yan, L., Y. Xie, J. Xu, C. Xue, H. Zhao and L. Bai, 2013. Improved forward and backward substitution in calculation of power distribution network with distributed generation. J. Xi'an Jiaotong Univ., 47: 117-123.
Direct Link