
Haitian Zhai
School of Electronics and Information, Northwestern Polytechnical University, Shaanxi, 710129, China
Hui Li
School of Electronics and Information, Northwestern Polytechnical University, Shaanxi, 710129, China
Mingui Sun
Swanson School of Engineering, University of Pittsburgh, PA 15213, United State of America
Journal of Software Engineering
Year: 2015 | Volume: 9 | Issue: 3 | Page No.: 520-533







ABSTRACT
Super-resolution is the process of combining a sequence of low-resolution images to produce a higher resolution image. The conventional super-resolution algorithms usually apply the same regularization factor for the whole image, regardless of region characteristics. One regularization factor is not good enough for all regions since an image consists of various regions having different characteristics. In this study, we propose a region adaptive super-resolution method to apply an adaptive regularization factor for each separate region. The regions are generated by segmenting the reference frame using the improved hierarchical segmentation algorithm. Regularization parameters are then adaptively determined based on the region characteristics. The software of the proposed algorithm is also implemented on an Intel quad core computer. Finally, the experimental results using both synthetic and unsynthetic image sequences show the effectiveness of the proposed algorithm compared to three state-of-the-art super resolution algorithms.
PDF Abstract XML References Citation
Received: November 24, 2014;
Accepted: January 08, 2015;
Published: March 05, 2015
How to cite this article
Haitian Zhai, Hui Li and Mingui Sun, 2015. Region Adaptive Super Resolution Based on Total Variational Regularization. Journal of Software Engineering, 9: 520-533.
DOI: 10.3923/jse.2015.520.533
URL: https://scialert.net/abstract/?doi=jse.2015.520.533
DOI: 10.3923/jse.2015.520.533
URL: https://scialert.net/abstract/?doi=jse.2015.520.533
INTRODUCTION
High Resolution (HR) images can be obtained directly from high-resolution acquisition systems in some cases. However, obtaining an image of a scene with high spatial resolution is not possible in many image acquisition systems due to a number of theoretical and practical limitations including the Rayleigh resolution limit, data transfer rate, the sensor resolution, the increased cost and the noise introduced by the digital sensor. In such cases, Super Resolution (SR) methods (Park et al., 2003) can be utilized to process one or more Low-Resolution (LR) images of the scene together to obtain a HR image. Super resolution image reconstruction which can be considered as an image restoration technique, refers to a process that produces an HR image from a sequence of LR images using the non-redundant information among them. Different from the traditional restoration algorithms, SR reconstruction needs to maximize the use of low-resolution image-sequence information and postulated the degraded factors of imaging to produce a HR image. The basic principle of super resolution is that changes in the LR images caused by the blur and the camera motion provide additional information that can be used to reconstruct the HR image from a set of LR images. Currently, it is possible to implement the SR software since the power of the dual or quad core CPU is strong enough to deal with the calculation generated in image reconstruction process. Nowadays, SR has been widely applied to many areas, such as biomedical imaging, video enhancement, video surveillance, deep-space exploration and reconstruction.
Since the super-resolution problem was first addressed, numerous algorithms, such as the iterative back-projection (Song et al., 2010; Li and Lam, 2013), POCS (Aguena and Mascarenhas, 2006; Su and Li, 2011; Panda et al., 2011), maximum likelihood (Kasahara et al., 2007; Chantas et al., 2007) and MAP algorithms (Kasahara et al., 2007; Chantas et al., 2007), have been developed. Generally, SR reconstruction techniques can be divided into two main categories: Spatial domain methods and frequency domain methods. Discrete Fourier Transform (DFT) was used in the earlier SR work, where high-frequency part is extracted from low frequency signal in the given LR frames (Wang et al., 2010). Then, many other methods were proposed in discrete cosine transform domain. However, the frequency domain methods are extremely sensitive to model error. Compared with the frequency domain methods, the spatial domain methods are generally computationally expensive. Belekos et al. (2010) introduced a new spatially hierarchical Gaussian non-stationary version of the multichannel prior which takes into account both the within-frame smoothness and the between-frame smoothness. Huang et al. (2011) applied the Douglas-Rachford splitting technique to the constrained TV-based variational SR model which is separated into three subproblems that are easy to solve. Another fast spatial domain method that LR images are registered with respect to a reference frame defining a nonuniformly spaced HR grid was recently suggested. All of the above methods assumed the additive Gaussian noise model. Furthermore, regularization was either not implemented or it was limited to Tikhonov regularization.
Although, the SR reconstruction literature is rich, it is still an open and widely research topic. Recently, motivated by its success in image recovery problems, the use of the Total Variation (TV) function and its variants has become popular in super resolution (Ng et al., 2007). Among all spatial domain algorithms, regularization methods are effective to solve the multi-frame SR reconstruction problem and deliver good performance for the restoration of edge sharpness. Both regularization-based and Bayesian formulations have been proposed which utilize TV functions to characterize the HR images. However, certain model parameters in these algorithms need to be set by the users which is in general a difficult task. In this study, we propose a region adaptive algorithm for better SR. The algorithm is based on region segmentation regularization for suitable regularization depending on pixel characteristic. In the algorithm, we first divide an image into homogeneous and inhomogeneous regions and apply the different filter depending on the pixel characteristic in each region. In addition, the regularization parameter is adaptively determined during the iteration.
PROBLEM FORMULATION
An image acquisition system composed of an array of sensors has recently been popular for increasing the spatial resolution with high Signal-to-Noise Ratio (SNR) beyond the performance bound of technologies that constrain the manufacture of imaging devices. In this study, we focus on the problem of reconstructing a high-resolution image from several blurred low-resolution image frames. In HR image reconstruction, we need to select an image from the low resolution frame sequence as the referenced one. The image formation model mainly relates the desired referenced HR image with all the observed LR frames. As is shown in Fig. 1, typically, the imaging process consists of warping, blurring and down-sampling to generate LR frames from the HR image. The LR frame can be denoted as:
 | |
| Fig. 1: | Observation model relating LR images to HR images |
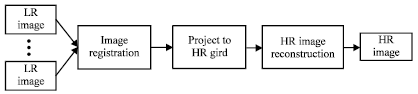 | |
| Fig. 2: | Flowchart of conventional super resolution process |
![]()
where, {k = 1, 2, …, S}, S is the number of LR frames. Then, the observation model can be denoted as:
| (1) |
Where:
![]()
is the desired HR image in the vector form, L1N1xL2N2 is the size of HR image, L1 and L2 denote the downsampling factors in the horizontal and vertical directions, respectively, each observation has the size of N1xN2, Mk is the motion matrix including rotation, zooming and translation, with the size of L1N1L2N2xL1N1L2N2, Bk represents the blur matrix including sensor blur, motion blur and atmosphere blur, also of size L1N1L2N2xL1N1L2N2, D is an N1N2xL1N1L2N2 down-sampling matrix and ξk represents the N1N2x1 zero-mean white Gaussian noise vector. In this study the matrices D and Bk are assumed known.
SR reconstruction is an ill-posed problem and it is difficult to be solved through a direct approach. Shown in Fig. 2 is the flow chart of the conventional super resolution method. In the HR reconstruction step, regularized optimization techniques are adopted to stabilize the inversion of the ill-posed problem. The idea behind the regularization method is to obtain a stable approximate solution of the original problem by using some prior information. The traditional regularization can be divided into two categories: Deterministic algorithms and stochastic algorithms. Their representatives are constrained least-square and maximum a posteriori (MAP), respectively. The constrained least-square method minimizes the L2 norm of the residual vector to obtain a feasible solution of SR. It can incorporate prior knowledge of the image and noise to estimate the HR image. The constrained least-square method can be written as:
| (2) |
where, J (f) is a specific regularization term which describes prior information of the motion and λ is the regularization factor. The regularization term J (f) which controls the perturbation of the solution, solves the ill-posed problem for SR reconstruction and guarantees a stable HR estimation, plays a very important role in the SR process. For the HR image f, the regularization term can be defined as follows:
| (3) |
where, ![]() and
and ![]() are linear operators corresponding to, respectively, horizontal and vertical first order differences, at pixel i; that is,
are linear operators corresponding to, respectively, horizontal and vertical first order differences, at pixel i; that is, ![]() , where, j denotes the nearest neighbor to the left of i and
, where, j denotes the nearest neighbor to the left of i and ![]() , where, k denotes the nearest neighbor above i.
, where, k denotes the nearest neighbor above i.
MATERIALS AND METHODS
Motion estimation: Motion estimation plays a critical role in SR reconstruction. In general, subpixel displacements between the referenced frame and the input frames can be modeled and estimated by a parameter model, or they may be scene dependent and have to be estimated for every point. This section introduces two motion estimation methods employed in this study. In this study we use the Fourier based subpixel image registration algorithm which allows accurate registration of two images with large upsampling factors and optical flow based motion estimation which can model the image sequences consisting of independently moving objects or changing illumination of a static scene.
Fourier based motion registration: The basic idea behind the Fourier based subpixel registration method is that the phase of the Fourier spectra of an image pair contains sufficient information to determine the displacement of the images. Given a referenced image and a translated and rotated version of the image, we wish to find an efficient algorithm that gives the displacement and rotation vector. If f2 (x, y) is a translated and rotated replica of f1 (x, y) with translation (x0, y0) and rotation θ0, then:
| (4) |
According to the Fourier translation property and the Fourier rotation property, translations of f1 and f2 are related by:
| (5) |
Let M1 and M2 be the magnitudes of F1 and F2. Therefore, from Eq. 5 we have:
| (6) |
If we consider the magnitudes of F1 and F2, then from Eq. 6, it is easy to see that the magnitudes of both the spectra are the same but one is a rotated replica of the other. The displacement in the spatial domain is reflected as a phase difference in the frequency domain. In order to get rid of the luminance variation influence, we normalize the cross-power spectrum by its magnitude and obtain its phase:
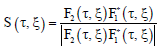 | (7) |
The inverse Fourier transform of S (τ, ξ) is the Dirac delta function centered at (x0, y0) corresponding to the spatial shift between images F1 and F2. The displacement can be found easily by detecting a highest peak of the response.
Rotational movement without translation can be deduced in a similar manner using the phase correlation by representing the rotation as a translational displacement with polar coordinates. i.e., in polar representation:
| (8) |
using phase correlation, the rotation angle can be easily found out.
Optical flow based motion estimation: The frame in videos may consist of independently moving objects or changing illumination of a static scene. In such cases, the motions cannot be modeled by Fourier transform but optical flow based methods can be used to estimate the motions of all pixels. Here we propose a simple MAP motion estimation method. Here, m = (mu, mv) denotes a 2D motion field which describes the motions of all pixels between the observed frames y1 and yk with mu and mv being the horizontal and vertical fields, respectively and ![]() is the predicted version of yk from frame l using the motion field m, the MAP motion estimation method has the following minimization function:
is the predicted version of yk from frame l using the motion field m, the MAP motion estimation method has the following minimization function:
| (9) |
where, U (m) describes prior information of the motion filed m and λ1 is the regularization parameter. In this study, we choose U (m) as a Laplacian smoothness constraint consisting of the terms ||Qmu||2+||Qmv||2, where, Q is a 2D Laplacian operator. Using steepest descent method, we can iteratively solve the motion vector field by:
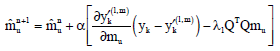 | (10) |
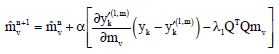 | (11) |
where, α is the step size and n again is the iteration number.
 | |
| Fig. 3: | Flowchart of the proposed SR method |
The derivative in the above equation is computed on a pixel by pixel basis, given by:
| (12) |
| (13) |
Proposed algorithm: Based on the observations in previous section, we propose a region based SR. Figure 3 illustrates the flowchart of proposed region-based method which consists of three parts. In the first part, the image is segmented into different regions by using the hierarchical segmentation algorithm. In the second step, the regularization factor is calculated based on region smoothness. At last, a different SR process is performed for each region based on consideration of each region’s characteristics.
Image segmentation: To obtain a reliable region map from x, we adopt the improved hierarchical segmentation algorithm (Dobigeon et al., 2007) which uses all locations in the image and is the most natural way to generate locations at all scales. Size and appearance features which are efficiently propagated throughout the hierarchy, making it reasonably fast, are used in our algorithm. Figure 4 shows an example of image segmentation of the Cameraman image. Make clear that we keep this method basic to make certain of reproducibility and our result does not stem from parameter tuning but from better thinking of the goal of image segmentation.
As we can obtain much more information from regions than that of pixels, it can be started with an over-segmentation (a set of small regions which do not spread over multiple objects). The fast method is used to be our starting point which found well suited for generating an over segmentation.
 | |
| Fig. 4(a-b): | Image segmentation, (a) Cameraman image and (b) Region map of the cameraman |
Starting from the initial regions, a greedy algorithm which iteratively combines the two most similar regions together and calculates the similarities between this new region and its neighbors is utilized. We continue doing this until the whole frame turns into a single region. As potential object locations, we consider the tight bounding boxes around these segments, or we consider either all segments throughout the hierarchy (including initial segments).
We define the similarity S between region a and b as:
| (14) |
where, Ssize (a, b) is defined as the fraction of the image that the segment a and b jointly occupy and Stexture (a, b) is defined as the histogram intersection between SIFT-like texture measurements. Both components result in a number in range [0, 1] and are weighed equally. Ssize (a, b) encourages small regions to merge early and prevents a single region from gobbling up all others one by one. For Stexture (a, b), we aggregate the gradient magnitude in 8 directions over a region, just like in a single sub-region of SIFT with no Gaussian weighting. For color information, texture measurements in each color channel are done separately and results are then concatenated.
Our segmentation process is performed in a variety of color channels with different invariance properties to obtain multiple segmentations which are complementary. Specifically, we consider multiple color spaces with different degrees of sensitivity to highlight edges, shading and shadow. Standard RGB is the most sensitive. The opponent color space is insensitive to highlight edges but sensitive to shadows and shading edges. The normalized RGB space is insensitive to shadow and shading edges but still sensitive to highlights. An alternative approach to multiple color spaces would be the use of different thresholds for the starting segmentation.
The choice of regularization factor: The main objective of the content based super resolution is to employ an iterative algorithm to estimate the regularization parameter at the same time with the restored image. The available estimate of the restored image at each iteration step will be used for determining the value of the regularization factor. That is, the regularization factor is defined as a function of the original image. Therefore, Eq. 2 can be rewritten as:
| (15) |
Various choices of the functional λ (x) can potentially result in meaningful minimizers of:
![]()
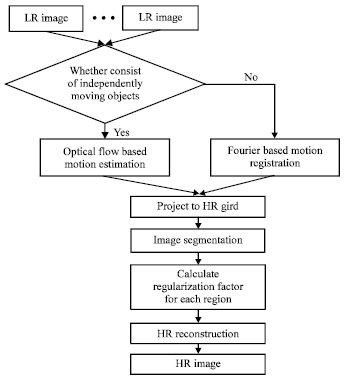
in Eq. 15. First, λ (x) should be a function of the smoothing functional: We choose λ (x) to be proportional to M which represents the regularized noise power. That is, we set in general:
| (16) |
where, f (•) is a monotonically increasing function. The justification behind this choice of λ (x) is based on the set theoretic formulation of the restoration problem. According to it, λ (x) is proportional to ||y-Dx||2, that is:
| (17) |
It should also be inversely proportional to the low-frequency energy of the restored image:
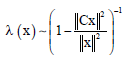 | (18) |
In other words, if the energy of a restoration at low frequencies is relatively large, then a smaller value of λ (x) should be used, so that the higher frequencies are further restored. The opposite should occur if the energy of a restoration at low frequencies if relatively small. This property can be rewritten as:
| (19) |
A consequence of the choice of λ (x) is that an optimal estimate x which satisfies ∇xM(λ(x), x) = 0, also satisfies ∇x λ(x) = 0. This is the case since:
| (20) |
Provided:
![]()
is finite. This last observation will prove useful in obtaining a suitable expression for the restored image and for analyzing the convergence of the iterative algorithm that will be employed. Another desired property of M (λ (x), x) is that its minimizer should represent a solution between two extreme solutions: One representing the generalized inverse solution of Eq. 2, when the data are noiseless and the other representing the smoothest possible solution (x = 0), when the noise power becomes infinite. These requirements translate into the conditions:
| (21) |
and:
| (22) |
Equation 21-22 result in:
| (23) |
and:
| (24) |
Therefore, f (M) and consequently λ (x) should map (0, ∞) into (0, ∞) and be a monotonically increasing function of M.
The functional M should be convex for all choices of λ (x): This requirement on convexity is obviously very important, since a local extremum of a nonlinear functional becomes a global extremum, if the functional is convex. Therefore, the iterative algorithm that will be employed for obtaining a minimizer of M will not depend on the initial condition. Clearly, for λ (x) = c, a constant independent of x, M is convex.
One function that satisfies all these properties can be written as:
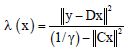 | (25) |
where, γ is the coefficient representing the roughness of the region and also controls the regularization factor. γ can be calculate as follows:
| (26) |
where, 0≤k≤kmax, k is the grayscale, kmax is the maximum grayscale, H (k) is the histogram of the region and m is the mean of the grayscale defined as follows:
| (27) |
High resolution reconstruction: As has already been mentioned, a restored image is a minimizer of the smoothing functional M defined in Eq. 2. Since it was shown that M is convex, for choices of λ that satisfy certain properties, if there exists a minimizer it will be a unique and therefore global minimizer. We show that there exists a minimizer of M by establishing sufficient conditions for an iteration to converge to a vector satisfying the necessary conditions for an optimum of M. The necessary condition for a minimum is that the gradient of M with respect to x is equal to zero that is:
| (28) |
Since ∇xλ (x) = 0, the equation for the optimal solution becomes:
| (29) |
Since is nonlinear, it is solved by employing the successive approximations iteration:
| (30) |
It is mentioned here that no relaxation parameter is used in the above iteration, since another control parameter is used in the above.
RESULTS AND DISCUSSION
In this section, we tested the performance of the proposed SR reconstruction method on both synthetic images and real images by comparing with different algorithms such as Tikhonov regularization, variational Bayesian super resolution (Huang et al., 2011) and total-variation regularization (Ng et al., 2007) SR.
In the first experiment, we evaluate the performance of three SR algorithms in comparison with the proposed algorithm in cases where exact displacements and rotation information is available. We have conducted three image sequences including “cameraman”, “Lena” and “baboon”. In this study, only the result of “cameraman” is shown. The HR resolution image is first shifted with sub-pixel displacements of (0, 0), (0, 0.5), (0.5, 0), (0.5, 0.5) and then rotate with angles of (0°, 2°, -2°, 4°, -4°) to produce four images. The image sequence is then convolved with a Gaussian-type PSF of 5x5 window size and unit variance and down-sampled with a factor of 2 in both the vertical and horizontal directions. Shown on Fig. 5a is one of the 4 synthetic LR images generated from the HR image. For the purpose of comparison, three different algorithms are implemented on the same set of LR images and the results are shown in Fig. 5b-d. Figure 5e shows the result of an SR image reconstructed by the proposed method. The Fourier based image registration method is used as the motion estimation method. It can be seen from the zooming area of Fig. 5 that in proposed method the LR effect is significantly reduced and the resolution is highly enhanced.
In order to measure performance analysis, the HR image is first down-sampled into LR images and then reconstructed using the proposed algorithm to HR image. Since the original HR image is available, the restoration quality is measured by Peak Signal-to-Noise Ratio (PSNR) of the image as:
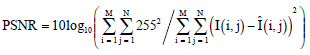 | (31) |
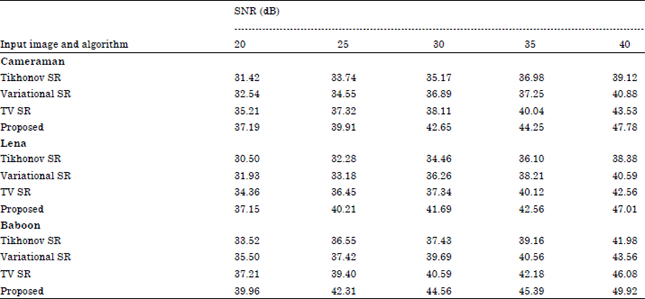
where, I is the original HR image and Î is the reconstructed image. An image with higher PSNR means better reconstruction but it doesn’t always represent the true quality of image. The simulation results of the Cameraman data are showed in Table 1 for SNRs of 15, 20, 25, 30 and 35 dB. As we can see in the Table 1, the PSNR improvement in the intermediate regions is negligible, whereas the improvements in the smooth and edge regions are noticeable for all SNRs.
 | |
| Fig. 5(a-f): | An example of HR reconstruction from different super resolution methods; Results (2x resolution increase) by (a) Original low resolution image interpolated by nearest neighbor interpolation, (b) Tikhonov regularization, (c) Variational Bayesian SR, (d) Total-variation regularization SR and (e) Proposed method and (f) Synthetic LR images |
| Table 1: | PSNR for different algorithms |
 | |
 | |
| Fig. 6(a-e): | An example of HR reconstruction from different super resolution methods; Results (2x resolution increase) by (a) Original low resolution image interpolated by nearest neighbor interpolation, (b) Tikhonov regularization, (c) Variational Bayesian SR, (d) Total-variation regularization SR and (e) Proposed method (Extracted images) |
In the real data experiments, two datasets are used to verify the proposed algorithm. One dataset is the text video sequence which consists of 42 LR frames with a size of 80x80. In order to reduce the computational load, we just select 10 frames. Figure 6a shows one of the extracted images. It is observed that there are obvious artifacts in most parts of this image. Figure 6e is the SR reconstruction result using the proposed algorithm. Figure 6b-d show the results of three different algorithms using Tikhonov regularization, variational Bayesian super resolution and total variation regularization SR, respectively. Another dataset is the disk video sequence which consists of 36 LR frames with a size of 66x84.10 frames are used in this test. Figure 7 show the results of different algorithms. The computational complexity of our solution is also not high, although the initial motion estimates by optical flow algorithm are relatively time-consuming. We test the proposed algorithm on an Intel Quad Core 3.40 GHz PC and it is able to upscale an image of size 80x80 in less than 4 sec on average.
 | |
| Fig. 7(a-e): | An example of HR reconstruction from different super resolution methods; Results (2x resolution increase) by (a) Original low resolution image interpolated by nearest neighbor interpolation, (b) Tikhonov regularization, (c) Variational Bayesian SR, (d) Total-variation regularization SR and (e) Proposed method |
CONCLUSION
The SR reconstruction of digital video becomes difficult when there is blurring, noise, missing regions, compression artifacts, or inevitable motion estimation errors in the system. The conventional super-resolution algorithms usually apply the same regularization factor for the whole image, regardless of region characteristics. One regularization factor is not good enough for all regions since an image consists of various regions having different characteristics. In this study, we propose a region-based super-resolution algorithm to apply an adaptive regularization factor for each separate region. The regions are generated by segmenting the reference frame using the improved hierarchical segmentation algorithm. Regularization parameters are then adaptively determined based on the region characteristics. The experimental results using both synthetic and unsynthetic image sequences show the effectiveness of the proposed algorithm compared to three state-of-the-art SR algorithms.
ACKNOWLEDGMENT
This research was supported by National Natural Science Foundation of China (Grant No. 61171155), Natural Science Foundation of Shaan Xi Province (Grant No. 2012JM8010) and Doctorate Foundation of Northwestern Polytechnical University (No. CX201316).
REFERENCES
- Park, S.C., M.K. Park and M.G. Kang, 2003. Super-resolution image reconstruction: A technical overview. IEEE Signal Process. Mag., 20: 21-36.
CrossRefDirect Link - Song, H., X. He, W. Chen and Y. Sun, 2010. An improved iterative back-projection algorithm for video super-resolution reconstruction. Proceedings of the Symposium on Photonics and Optoelectronic, June 19-21, 2010, Chengdu, China, pp: 1-4.
CrossRef - Li, H. and K.M. Lam, 2013. Guided iterative back-projection scheme for single-image super-resolution. Proceedings of the IEEE Global High Tech Congress on Electronics, November 17-19, 2013, Shenzhen, pp: 175-180.
CrossRef - Aguena, M.L.S. and N.D.A. Mascarenhas, 2006. Multispectral image data fusion using POCS and super-resolution. Comput. Vision Image Understanding, 102: 178-187.
CrossRefDirect Link - Su, X. and S. Li, 2011. Multi-frame image super-resolution reconstruction based on sparse representation and POCS. Int. J. Digital Content Technol. Applic., 5: 127-135.
Direct Link - Panda, S.S., M.S.R.S. Prasad and G. Jena, 2011. POCS based super-resolution image reconstruction using an adaptive regularization parameter. Int. J. Comput. Sci. Issues, 8: 155-158.
Direct Link - Kasahara, R., T. Ogata, T. Kawasaki, H. Miura and K. Yokoi, 2007. Decision feedback partial response maximum likelihood for super-resolution media. Jpn. J. Applied Phys., 46: 3878-3881.
CrossRefDirect Link - Chantas, G.K., N.P. Galatsanos and N.A. Woods, 2007. Super-resolution based on fast registration and maximum a posteriori reconstruction. IEEE Trans. Image Process., 16: 1821-1830.
CrossRef - Belekos, S.P., N.P. Galatsanos and A.K. Katsaggelos, 2010. Maximum a posteriori video super-resolution using a new multichannel image prior. IEEE Trans. Image Process., 19: 1451-1464.
CrossRefDirect Link - Wang, S., S.H. Kim, Y. Liu, H.K. Ryu and H.M. Cho, 2010. Super-resolution algorithm based on discrete fourier transform. Proceedings of the 6th International Conference on Intelligent Computing, August 18-21, 2010, Changsha, China, pp: 368-375.
CrossRef - Ng, M.K., H. Shen, E.Y. Lam and L. Zhang, 2007. A total variation regularization based super-resolution reconstruction algorithm for digital video. EURASIP J. Adv. Signal Process.
CrossRefDirect Link - Dobigeon, N., J.Y. Tourneret and M. Davy, 2007. Joint segmentation of piecewise constant autoregressive processes by using a hierarchical model and a bayesian sampling approach. IEEE Trans. Signal Process., 55: 1251-1263.
CrossRef - Huang, L.L., L. Xiao and Z.H. Wei, 2011. Efficient and effective total variation image super-resolution: A preconditioned operator splitting approach. Mathe. Problems Eng.
CrossRefDirect Link