
Wichian Sittiprapaporn
Faculty of Medicine, Mahasarakham University, Mahasarakham, 44000, Thailand
Journal of Biological Sciences
Year: 2012 | Volume: 12 | Issue: 7 | Page No.: 411-415







ABSTRACT
Mismatch Negativity (MMN) was used to investigate the processing of cluster and noncluster initial consonants in consonant-vowel syllables in the human brain. The MMN was elicited by either syllable with cluster or noncluster initial consonant, phonetic contrasts being identical in both syllables. Compared to the noncluster consonant, the cluster consonant elicited a more prominent MMN. The strong MMN peaks at ~128 msec after change onset in cluster-to-noncluster initial consonants changes and at ~212 msec in noncluster-to-cluster initial consonants changes. The significantly different neuronal populations were thus active between 128-212 msec when syllables with cluster and noncluster initial consonants were present. Microstate segmentation analyses showed that the phonological perception for cluster consonant was at 212 msec whereas 128 msec for non-cluster consonant. After approximately 220 msec, semantic perception started in order to perceive the meaning of the words.
PDF Abstract XML References Citation
Received: September 13, 2012;
Accepted: September 18, 2012;
Published: December 27, 2012
How to cite this article
Wichian Sittiprapaporn, 2012. Language-Related Brain Potential Maps for Semantic Perception of Cluster Consonants in Consonant-Vowel Syllables. Journal of Biological Sciences, 12: 411-415.
DOI: 10.3923/jbs.2012.411.415
URL: https://scialert.net/abstract/?doi=jbs.2012.411.415
DOI: 10.3923/jbs.2012.411.415
URL: https://scialert.net/abstract/?doi=jbs.2012.411.415
INTRODUCTION
Mismatch Negativity (MMN) is an ERP component elicited by rare deviant stimuli within a sequence of repetitive auditory stimuli. The MMN component appears as a frontocentrally negative wave usually peaking between 100 and 300 msec after the onset of stimulus deviation (Naatanen et al., 1978). The MMN/MMF component, reflective neuronal correlates of change detection and sound discrimination (Naatanen, 2001), is enhanced by acoustic deviances of duration, frequency, or intensity in speech and non-speech (Naatanen et al., 1978). Previous studies have shown that the MMN amplitude is enhanced when the acoustic discrepancy between the stimuli is increased (Naatanen et al., 1978; Jaramillo et al., 2000). Parallel behavioral and MMN studies have shown that MMN amplitude correlates with the accuracy of perceptual discrimination (Lang et al., 1990; Naatanen et al., 1993) thus, MMN provides an objective method for measuring the accuracy of auditory processing (Nenonen et al., 2003).
It is well-known that auditory signals can be differentiated by a variety of factors including temporal information. It is also important to recognize that languages differ in the way they exploit temporal cues (Gandour et al., 2002). Standard Thai, the official language of Thailand, exhibits a phonological contrast in consonant. Perceptually, duration has been shown to be the primary cue in signaling the contrast between cluster and noncluster consonant phonemes (Sittiprapaporn et al., 2006). The phonemic consonant is sometime not predictable from context but can change the meaning of a word (e.g., /kaang/ ‘spread or make wider’ vs. /klaang/ ‘middle’).
Thai consonants are classified into three classes-namely, high, middle and low consonants-which can affect the syllable tone when functioning as initial sound. The Thai sound system is best described in relationship to the syllable, the tone-bearing unit. A Thai syllable has the maximum shape of C(C)V(V)(C)+Tone. There are twenty consonants in syllable-initial position. Among these, the initial cluster consonants include the labials -pr, pl, phr and phl; the alveolars -tr, thr and the velars - kr, kl, khr, khl, khw. Cluster simplification (kl>k, for example) is often a fixed feature in spoken communication. In the present study, preattentive brain processes during the discrimination of cluster and noncluster initial consonants in consonant-vowel syllables was compared. A single pair of consonant-vowel syllables with cluster and noncluster initial consonants were selected to represent ideal exemplars. In spoken communication, the consonant-vowel syllable with cluster initial consonant is usually pronounced as a simplification of the cluster initial consonant. This study chose to record and compared the MMN elicited by the consonant-vowel syllables with cluster and noncluster initial consonants, hoping to find evidence for specific brain signatures of cluster and noncluster initial consonant processing. Additionally, the ERP Microstate Segmentation Analysis technique was used to locate the pint where semantic perception started in order to perceive the meaning of the words.
MATERIALS AND METHODS
Subjects: Ten healthy right-handed (Handedness assessed according to Oldfield (1971) native speakers of Thai (7 females; aged 18-35 years) with normal hearing sensitivity gave their written informed consent before participation in the study. The mean (±SD) age was 24.35 (±4.95) years. All subjects were adults with normal hearing and no known neurological disorders. The approval of the institutional committee on human research and written consent from each subject were obtained.
Stimuli: Stimuli consisted of two monosyllabic Thai words. All stimuli were spoken by native female Thai speaker and digitally generated and edited to have equal peak energy level in decibels SPL with the remaining data within each of the stimuli scaled accordingly using the Cool Edit Pro v. 2.0 (Syntrillium Software Corporation) with 500 msec duration. The sounds were presented binaurally via headphones (Telephonic TDH-39-P) at 85 dB (determined using a Brüel and Kjaer 2230 sound level meter). Five Native speakers listened to the synthesized words and evaluated them all as natural sounding. Two different stimuli were synthetically generated as follows:
| • | Stimulus 1: Monosyllabic with cluster initial consonant /kl-/as/klaang/ ‘middle’ -cluster consonant, level tone |
| • | Stimulus 2: Monosyllabic with noncluster initial consonant /k-/as in: /kaang/ ‘spread or make wider’-noncluster consonant, level tones |
The standard (S)/deviant (D) pairs for each experiment which was randomized across subjects, were shown:
| • | Experiment 1: Standard (1)-Deviant (2): (Stimulus 1: /klang/-cluster consonant, level tone)-(Stimulus 2: /kang/-noncluster consonant, level tone) |
| • | Experiment 2: Standard (2), Deviant (1): (Stimulus 2: /kang/-noncluster consonant, level tone)-(Stimulus 1: /klang/-cluster consonant, level tone) |
All The standard (S)/deviant (D) pairs for each condition were:
| • | Condition 1: Cluster-to-noncluster change: S-(2), D-(1) |
| • | Condition 2: Noncluster-to-cluster change: S-(1), D-(2) |
Thus, in both conditions pairs were designed to contrast noncluster and cluster initial consonants. Deviant stimuli appeared randomly among the standards at 10% probability. The stimuli were binaurally delivered using SuperLab software (Cedrus Corporation, San Pedro, USA) via headphones (Telephonic TDH-39-P) at 85 dB. The inter-stimulus interval (ISI) was 1.25 sec (offset-onset). EEG signal recording was time-locked to the onset of a word. Subjects were instructed not to pay attention to the stimuli presented via headphones but rather to concentrate on a self-selected silent, subtitled movie. Afterwards, they reported the impression of the movie. The experiment lasted 1-2 h, including breaks.
Procedures: Subjects were seated in an electrically and acoustically shielded chamber, instructed to focus their attention on reading books of their own choices and to ignore any auditory signals. During the auditory stimulation, electric activity of the subjects’ brain was continuously recorded with 21 active electrodes positioned according to the International 10/20 System of Electro-cap and referred to linked mastoids.
Electroencephalographic (EEG) recording: The Electroencephalogram (EEG) was recorded in a sound-attenuated and electrically shielded room with a Biologic Brain Atlas III system and amplifier using a sampling rate of 128 Hz. During the auditory stimulation, electric activity of each subject’s brain was continuously recorded with 21 active electrodes (Fp1/2, F3/4, C3/4, O1/2, F7/8, T3/4, T5/6, P3/4, Fpz, Fz, Cz, Pz and Oz) positioned according to the International 10/20 System of Electro-cap and referred to linked mastoids. All 21 recording channels used for Microstate segmentation. A biologic Brain Atlas system amplified (bandpass 0.01-100 Hz), analog-digital converted (128 samples/s/channel) and stored the data. Epochs of-100-924 msec from stimulus onset were averaged and digitally filtered (bandpass 1-30 Hz). Epochs contaminated by artifacts exceeding±100 μV at any electrode as well as 10 standards after each deviant were rejected.
EEG data processing: The recordings were filtered and carefully inspected for eye movement and muscle artifacts. Event-Related Potentials (ERPs) were obtained by averaging epoch which started 100 msec before the stimulus onset and ended 900 msec thereafter; the-100-0 msec interval was used as a baseline. Epochs with voltage variation exceeding ±100 μV at any EEG channel were rejected from further analysis. Grand-averaged difference waveforms were calculated by subtracting the S from the D wavefoms. For each condition, presence of a prominent MMN was identified by measuring the integrated power amplitudes over the 40-msec time window centered on the MMN peak in the difference waveform. An MMN component was judged prominent if the amplitude difference between S and D within predefined the window was statistically significant. For each subject, the averaged MMN responses contained 125 accepted deviants.
Spatial analysis: The average MMN latency was defined as a moment of the Global Field Power (GFP) with an epoch of 40 msec time window related stable scalp-potential topography (Lehmann, 1987). The individual momentary potential measures from 21 electrodes at the MMN latency were analyzed with Microstate Segmentation technique to determine the MMN generator. In addition, the comparison between the microstate segmentation of cluster-and-noncluster consonants were analyzed using ERP Microstate Segmentation Analysis techniques (Koenig and Lehmann, 1996; Koenig et al., 1999, 2002).
Statistical analysis: During the auditory stimulation, electric activity of the subjects’ brain was continuously recorded. The MMN was obtained by subtracting the response to the standard from that to the deviant stimulus. The statistical significance of MMN was tested with one sample t-test. An across-experiment ANOVA was carried out so as to make cross-linguistic comparisons. The statistical significance of MMN was tested with paired-sample t-tests between the MMN amplitude of consonant-vowel syllables with noncluster and cluster initial consonants. This was done by comparing the mean MMN amplitude against a hypothetical zero at the frontal (Fz) electrode site, where the MMN is most prominent. The MMN latency values were also compared.
RESULTS
The results of the grand-mean difference waveform analysis demonstrated that significantly different neuronal populations were active between 128-212 msec when syllables with cluster and noncluster initial consonants were present. Both cluster and noncluster initial consonants elicited MMN with reference to the standard-stimulus ERPs. The MMN mean amplitude was statistically significant ( t-test) for both cluster-and noncluster initial consonants changes.
| Table 1: | MMN mean amplitude, standard deviations and t-values for the different deviant stimuli used |
The paired-sample t-test (Table 1) revealed a significant difference between conditions (t (10) = 73.00; p<0.0001) showing that both cluster and noncluster initial consonants changes in consonant-vowel syllables equally elicited a MMN.
The results of the grand-mean difference waveform analysis demonstrated that the MMN latency for the cluster and noncluster initial consonant differences was significantly longer in the syllable with noncluster-to-cluster initial consonants changes than in the cluster-to-noncluster initial consonants changes. The strong MMN peaks at ~128 msec after change onset in cluster-to-noncluster initial consonants changes and at ~212 msec in noncluster-to-cluster initial consonants changes. The significantly different neuronal populations were thus active between 128-212 msec when syllables with cluster and noncluster initial consonants were present. The comparison between the microstate segmentation of cluster-and-noncluster consonants were analyzed using ERP Microstate Segmentation Analysis techniques (Koenig and Lehmann, 1996; Koenig et al., 1999, 2002). Microstate segmentation analyses showed that the phonological perception for cluster consonant was at 212 msec whereas 128 msec for non-cluster consonant. After approximately 220 msec, semantic perception started in order to perceive the meaning of the words (Fig. 1).
DISCUSSION
The main finding of the present study indicates that the prominent response to consonant-vowel syllables with cluster and noncluster initial consonant changes elicited MMN peaking at 128-212 msec from stimulus onset. The magnitude of the acoustic difference between the stimulus pairs was reflected by the MMN amplitude, showing larger MMN amplitudes in consonant-vowel syllable deviants with cluster initial consonants compared to the noncluster consonant. Microstate segmentation analyses showed that the phonological perception for cluster consonant was at 212 msec whereas 128 msec for non-cluster consonant. After approximately 220 msec, semantic perception started in order to perceive the meaning of the words.
The difference in MMN latencies to /kaang/ and /klaang/ may reflect differential processing of syllables with physical differences in their initial consonants. The delay in the MMN to the cluster initial consonant of deviant stimulus i.e., /kl-/ as in /klaang/, may reflect additional time required to process the syllable. This processing apparently involves activation of a memory trace, or cell assembly which possibly represents and the processes the initial consonant in the syllable (Sittiprapaporn et al., 2006).
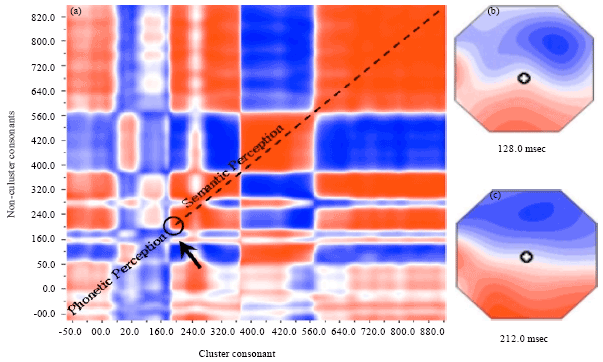 | |
| Fig. 1(a-c): | (a) The comparison between the microstate segmentation of cluster-and-noncluster consonants. Phonological perception for (b) cluster consonant is at 212 msec and for (c) non-cluster consonant is at 128 msec, After approximately 220 msec, semantic perception started in order to perceive the meaning of the words (arrow) |
The tuned processing of initial consonant may be caused by the different roles of consonant phonemes in the subjects’ native languages. This implies that even if one has two almost closely related phonemes, i.e., cluster and noncluster consonant, fine tuning in the processing of syllable may be inhibited at the pre-attentive level (Sittiprapaporn et al., 2006). As it is well established that the MMN amplitude indexes the accuracy of change detection (Naatanen et al., 1978), the larger MMN amplitude to the speech sound change in the present study suggests more accurate sound change detection in syllables with cluster rather than with noncluster initial consonants. The electric MMN responses differed significantly between syllables with either cluster or noncluster initial consonant. Importantly, there was significant difference between exemplar syllables with cluster and noncluster initial consonants, implying that the basic ability to detect speech sound changes in general is on average different in the two initial consonant phonemes.
The present study found an earlier MMN for the short noncluster consonant stimulus and a delayed MMN for the cluster consonant, as well as differential topography of the two responses (Fig. 1). The difference in MMN latencies to the two stimuli may reflect differential processing of the syllables. Thus, the delay in the MMN to syllable with cluster initial consonant deviant stimulus may reflect additional time required to process the syllable. Because the MMN is known to depend primarily on the magnitude of stimulus contrast (rather than on its direction) (Shtyrov and Pulvermuller, 2002). The acoustic difference per se between syllables with the cluster and noncluster initial consonants is therefore, unlikely to have confounded the present results. The present results parallel the findings in previous studies (Inouchi et al., 2002, 2003; Sittiprapaporn et al., 2005) demonstrating that the detection of speech sound changes is most likely acoustically driven rather than semantically driven, such that the stimuli were processed without any access to semantic information. The acoustic aspect in the absence of phonetic or higher-order properties may account for why syllable with cluster consonant had similar neuronal responses to noncluster one. The present finding is, thus, in accord with a previous experiment that reported a clear MMN elicited by both increments and decrements of speech sound duration (Naatanen et al., 1989) but a larger MMN elicited by increments than decrements (Jaramillo et al., 1990).
CONCLUSION
The MMN component is more sensitive to consonant-vowel syllables with cluster initial consonant rather than noncluster consonant. After approximately 220 msec, semantic perception might start in order to perceive the meaning of the words. Automatic detection of changes in cluster initial consonant-vowel syllable may be a useful index of auditory memory traces of word.
REFERENCES
- Gandour, J., D. Wong, M. Lowe, M. Dzemidzic, N. Satthamnuwong and Y. Long, 2002. Neural circuitry underlying perception of duration depends on language experience. Brain Lang., 83: 268-290.
CrossRef - Inouchi, M., M. Kubota, P. Ferrari and T.P.L. Roberts, 2002. Neuromagnetic auditory cortex responses to duration and pitch changes in tones: Cross-linguistic comparisons of human subjects in directions of acoustic changes. Neurosci. Lett., 331: 138-142.
CrossRef - Inouchi, M., M. Kubota, P. Ferrari and T.P.L. Roberts, 2003. Magnetic mismatch fields elicited by vowel duration and pitch changes in Japanese words in humans: Comparison between native-and non-speakers of Japanese. Neurosci. Lett., 353: 165-168.
CrossRef - Jaramillo, M., P. Alku and P. Paavilainen, 1990. An Event-Related Potential (ERP) study of duration changes in speech and non-speech sounds. Neuroreport, 10: 3301-3305.
Direct Link - Jaramillo, M., P. Paavilainen and R. Naatanen, 2000. Mismatch negativity and behavioural discrimination in humans as a function of the magnitude of change in sound duration. Neurosci. Lett., 290: 101-104.
CrossRef - Koenig, T. and D. Lehmann, 1996. Microstates in language-related brain potential maps show noun-verb differences. Brain Lang., 53: 169-182.
CrossRef - Koenig, T., D. Lehmann, M.C.G. Merlo, K. Kochi, D. Hell and M. Koukkou, 1999. A deviant EEG brain microstate in acute, neuroleptic-naive schizophrenics at rest. Eur. Arch. Psychiatry Clin. Neurosci., 249: 205-211.
CrossRef - Koenig, T., L. Prichep, D. Lehmann, P.V. Sosa and E. Braeker et al., 2002. Millisecond by millisecond, year by year: Normative EEG microstates and developmental stages. Neuroimage, 16: 41-48.
CrossRef - Lang, H., T. Nyrke, M. Ek, O. Aaltonen, I. Raimo and R. Naatanen, 1990. Pitch Discrimination Performance and Auditory Event-Related Potentials. In: Psychophysiological Brain Research, Brunia, C.M., A.K. Gaillard, A. Kok, G. Mulder and M.N. Verbaten (Eds.). Tilburg University Press, Tilburg, The Netherlands.
- Naatanen, R., 2001. The perception of speech sounds by the human brain as reflected by the Mismatch Negativity (MMN) and its Magnetic Equivalent (MMNm). Psychophysiology, 38: 1-21.
CrossRef - Naatanen, R., A.W.K. Gaillard and S. Mantysaalo, 1978. Early selective-attention effect on evoked potential reinterpreted. Acta Psychol., 42: 313-329.
CrossRef - Naatanen, R., P. Paavilainen and K. Reinikainen, 1989. Do event-related potentials to infrequent decrements in duration of auditory stimuli demonstrate a memory trace in man?. Neurosci. Lett., 107: 347-352.
PubMed - Naatanen, R., E. Schroger, S. Karakas, M. Tervaniemi and P. Paavilainen, 1993. Development of a memory trace for a complex sound in the human brain. Neuroreport, 4: 503-506.
PubMedDirect Link - Nenonen, S., A. Shestakova, M. Huotilainen and R. Naatanen, 2003. Linguistic relevance of duration within the native language determines the accuracy of speech-sound duration processing. Cognitive Brain Res., 16: 492-495.
CrossRef - Oldfield, R.C., 1971. The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia, 9: 97-113.
CrossRef - Shtyrov, Y. and F. Pulvermuller, 2002. Memory traces for inflectional affixes as shown by mismatch negativity. Eur. J. Neurosci., 15: 1085-1091.
CrossRef - Sittiprapaporn, W., C. Chindaduangratn and N. Kotchabhakdi, 2006. Pattern of language-related potential maps in consonant-vowel (cv) syllables. Songklanakarin J. Sci. Tech., 28: 911-920.
Direct Link