
Xing Chen
Triticeae Research Institute, Sichuan Agricultural University, Yaan, Sichuan 625014, China
Wei Li
Triticeae Research Institute, Sichuan Agricultural University, Yaan, Sichuan 625014, China
Yuming Wei
Triticeae Research Institute, Sichuan Agricultural University, Yaan, Sichuan 625014, China
Guoyue Chen
Triticeae Research Institute, Sichuan Agricultural University, Yaan, Sichuan 625014, China
Youliang Zheng
Triticeae Research Institute, Sichuan Agricultural University, Yaan, Sichuan 625014, China
Journal of Biological Sciences
Year: 2008 | Volume: 8 | Issue: 3 | Page No.: 542-548







ABSTRACT
The aim of this research was to isolate and characterize the α-gliadin genes from T. turgidum ssp. paleocolchium. Nine genes were isolated from T. turgidum ssp. paleocolchicum (2n = 4x = 28, AABB) using the designed primers PF1 and PF2. The deduced protein sequences of the nine genes share the same typical polypeptide structures with known α-gliadin sequences. Among the nine α-gliadin genes, only Gli1-7 and Gli 2-4 encoded putative mature proteins and the others were assumed to be pseudogenes due to their in-frame stop codon, which are attributed to the single base change C to T. Multi-alignment analysis indicated that the difference of the nine sequences mainly existed in the repetitive domain and the two polyglutamine regions. The repetitive domain could be considered as the array of 14 motifs based on the codon series CCA TT/AT CCA/G CAR, where CAR represents a 3-6 glutamine codon-rich region. Almost all codons in polyglutamine domains encode glutamine. However, 26 codons are not glutamine codons, which mainly resulted from single base changes. It is also found that the polyglutamine domain II is more variable than the polyglutamine domain I. Gli1-2 contained an extra cysteine, which was created by a serine-to-cysteine residue change at position 240, thus, it would have one free cysteine for intermolecular disulfide bond formation. Cluster analysis showed that sequences Gli1-10, Gli2-5 and Gli2-4 might be obtained from the genome A, whereas Gli2-2 and Gli1-9 from the genome B.
PDF Abstract XML References Citation
How to cite this article
Xing Chen, Wei Li, Yuming Wei, Guoyue Chen and Youliang Zheng, 2008. Cloning and Molecular Characterization of Nine α-gliadin Genes from Triticum turgidum ssp. paleocolchicum. Journal of Biological Sciences, 8: 542-548.
DOI: 10.3923/jbs.2008.542.548
URL: https://scialert.net/abstract/?doi=jbs.2008.542.548
DOI: 10.3923/jbs.2008.542.548
URL: https://scialert.net/abstract/?doi=jbs.2008.542.548
INTRODUCTION
In bread wheat and related species, the seed storage proteins mainly consist of glutenins and gliadins. Gliadins were traditionally divided into three groups (α-, γ- and ω-gliadins) based on their electrophoretic mobility in acidic polyacrylamide gel electrophoresis (Metakovsky et al., 1984). The α-gliadins are monomeric prolamines. They are the most abundant wheat seed proteins, comprising 15-30% of the seed protein of most cultivars. An unfortunate aspect of this human consumption is that the α-gliadins are a major initiator of intestinal damage in coeliac disease (Shewry et al., 1992).
α-gliadins were encoded by the genes located at the Gli-2 loci (Gli-A2, Gli-B2 and Gli-D2). The number of α-gliadin proteins synthesized had higher variation among different cultivars (D`Ovidio et al., 1992). These differences are believed to be due to duplications and deletions of chromosome segments, probably generated by unequal crossing-over and by gene conversion events. D`Ovidio et al. (1991) have described one such deletion of a block of α-gliadin genes and the existence of closely related α-gliadin sequence sub-families has been described (Anderson, 1991; Anderson et al., 1991).
More recently, different α-gliadin genes not only in bread wheat but also in the relative species have been cloned and characterized (Teun et al., 2006). Triticum turgidum ssp. paleocolchicum (2n = 4x = 28, AABB) is a valuable source of genes for wet resistance and diseases, such as stripe rust, leaf rust and dust brand, resistances. It also has a high protein content. To date, the studies of its agronomic characters and phylogeny have been reported (Mori et al., 1997). However, there is no literature report on the characterization of its α-gliadin genes. The aim of this research was to isolate and characterize the α-gliadin genes from T. turgidum ssp. paleocolchicum.
MATERIALS AND METHODS
Plant materials: Two T. turgidum ssp. paleocolchicum accessions, AS2274 and AS2275, were collected and conserved by the Triticeae Institute of Sichuan Agricultural University.
DNA extraction and PCR amplification: Seed were germinated under the dark at 23 °C for 1 week, young leaves were harvested and crushed into powder with the aid of liquid nitrogen and the genomic DNA was extracted by a CTAB method (Yan et al., 2002). A pair of primers (PF1 and PR1) was designed to amplify the complete ORF (open reading frame) based on known α-gliadin gene sequences. The sequences of primers were PF1: 5`- GSTCAATACAAATCCAYCATG-3`, PR1: 5`- TTCTCTTCTCAGTTRGTACCR-3` (synthesized by Sangon). PCR amplifications were performed in 50 μL reaction volume, which containing 1.5 U Taq plus DNA polymerase, 100 ng templet DNA, 5 μL PCR buffer (supplied with Taq plus DNA polymerase), 1.5 mM MgCl2, 100 mM of each dNTP, 150 ng each primer and some of ddH2O. The reactions were conducted in a PTC-100 (Bio-Rad) using the following program: 94 °C for 4 min denaturation followed by 35 cycles of 45 sec at 94 °C, 1 min at 55 °C, 1 min at 72 °C and 10 min at 72 °C.
Molecular cloning and DNA sequencing: PCR products were separated on 1.0% agarose gels. The expected fragments were purified from the gels using Quick DNA extraction kit (OMIGA). Subsequently purified products were ligated into pMD18-T vector (TaKaRa, Dalian, China) and transformed into competent cells of Escherichia coli (DH-5α). The positive clones were sequenced by TaKaRa (Dalian, China).
Sequence analysis: The obtained sequences were compared to known sequences using BLAST (http://www.ncbi.nlm.nih/gov). The nucleotide and deduced amino acid sequence analysis were conducted by using programs deposited in the NCBI network. Sequence alignment was completed by DNAMAN 5.2.2 (http://www.lynnon.com). MEGA3.1 (Gaut et al., 1996; Kumar et al., 2004) was used to carry out the phylogenic analysis.
RESULTS AND DISCUSSION
Cloning and sequencing: All the known α-gliadins genes contained no intron, so the entire gene sequences with no intervention can be amplified by using genomic DNA as a template. The obtained PCR amplification products had around 900 bp in size. Five sequences, designated Gli1-2, Gli1-4, Gli1-7, Gli1-9 and Gli1-10, were obtained from accession AS2274. Four sequences, named as Gli2-1, Gli2-2, Gli2-4 and Gli2-5, were obtained from accession AS2275, respectively. These nucleotide sequences were deposited in Genbank under the accession numbers EU401787, EU394709, EU401785, EU401788, EU401789, EU401790, EU401791, EU401792 and EU401793, respectively.
Comparison of deduced amino-acid sequences: Length of Gli1-2, Gli1-4, Gli1-7, Gli1-9, Gli1-10, Gli2-1, Gli2-2, Gli2-4 and Gli2-5 are 948, 948, 891, 882, 933, 891, 882, 855 and 860 bp, respectively. The deduced proteins of nine sequences had a similar structure to previously characterized α-gliadin genes, which consist of six main structural regions, including a signal peptide with 20 amino -acid residues, N-terminal repetitive region composed of imperfect repeats of 7-14 amino acid residues, polyglutamine domain I, unique region, polyglutamine domain II and C-terminal unique sequence (Anderson et al., 1997). Gli1-7 and Gli1-2 could encode two putative mature proteins with 296 and 284 amino acid residues, respectively. Seven sequences, including Gli1-2, Gli1-4, Gli1-9, Gli1-10, Gli2-1, Gli2-2 and Gli2-5, were considered as pseudogenes, due to the premature stop codons. The comparison for the nine amino acid sequences indicated that they share a homology of 85.09%. According to the alignment of deduced amino acid, the signal peptide is the most conserved domain of the α-gliadin sequences, most variability occurred in coding region, especially in the two polyglutamine domains.
Repetitive structure: The repetitive domain of the gliadins is composed of short peptide motifs. Various consensus motifs for the α-gliadin genes have been proposed: PQPQPFP and PQQPY (Shewry and Tatham, 1990), PF/YPQ0-1PQ1-2 (Anderson and Greene, 1997). Our analyses have concentrated on the codon structure, since this is the primary level of sequence change and interaction among the DNA repeat motifs (Anderson and Greene, 1997; Cassidy et al., 1998). A vertical array of the repeat structure of Gli-2 was displayed (Table 1). The
| Table 1: | Repetitive domain motif structure of the Gli1-2 |
The DNA sequ ence of the Gli1-2 repetitive domain is arranged by codons and suggested repeats are arrayed vertically. A consensus structure is given below. The vertical line separates the conserved first three codons of each repeat motif from the variable-length glutamine-rich part of the repeat ence of the Gli1-2 repetitive domain is arranged by codons and suggested repeats are arrayed vertically. A consensus structure is given below. The vertical line separates the conserved first three codons of each repeat motif from the variable-length glutamine-rich part of the repeat | |
 | |
| Fig 1: | Amino-acid sequence of isolated α–gliadins genes. And *represented the deletions and stop codons, respectively. The cysteine residues are in the boxes |
DNA sequences of the repetitive domain could be considered as the array of 14 motifs based on the codon series CCA TT/AT CCA/G CAR, where CAR represents a 3-6 glutamine codon-rich region. The first three codons for VRV and the last three codons for PSI of the repetitive region were not included. As shown in Fig. 1, Gli1-2 and Gli1-4 contains an extra repeat composed of LQPFPQ, Gli1-7 and Gli2-1 show an extra repeat of the sequence PQLFPQ. Gli1-9 shows a deletion repeat of the sequence PYPQP/L. It is possible that during replication, the repetitive region diverges rapidly by allowing slippage to leading to duplication or deletion of sequences (Cassidy and Dvorak, 1991). As other prolamin evolution (Anderson and Greene, 1989), single base, single repeat changes and unequal crossover and so on could be responsible for the variations of the repetitive domain. A comparison of the proposed consensus repeat motifs of all four major gliadin types was shown (Table 2). The motifs of α-gliadin are more similar to those of LMW-glutenin, while those of γ-gliadin are most similar with ω-gliadin. Presumably the patterns of the repeats have diverged subsequent to the separation of the gliadin gene families, similar to the manner in which specific DNA sequences diverge after gene duplication. The properties and interactions of the repetitive domain are also the major determinant of wheat flour quality besides the number and distribution of cysteines (Shewry et al., 2002). The repetitive domain contains high content of glutamine, which resulted in the high levels of -OH groups. They are available to form hydrogen bonds and might contribute to the elasticity of the proteins (Shewry et al., 2002; Khatkar et al., 2002).
Microsatellite structure and variation: Polyglutamine stretches are a prominent feature in all the α-gliadins (Anderson and Greene, 1997). The residues numbers of polyglutamine regions are high variable in all sequences. The polyglutamine domain II of Gli1-10 contains 33 residues and its size was four times than that in Gli2-4, which contains 8 residues (Table 3). For the nine sequences, the identity of the polyglutamine domain I is 58.55%, while the identity of the polyglutamine domain II is 34.60%. The polyglutamine domain II is more variable than the polyglutamine domain I. Size variation of α-gliadin protein is mainly due to different microsatellite length variation. There are a total of 23 residues of amino-acid sequence length difference between sequences Gli1-4 and Gli1-7 and 21 residues occur in the two polyglutamine domains. Furthermore, it is found that polyglutamine domains almost only contain glutamine. However, several other proteins were also founded in the polyglutamine domains. They are mainly resulted from single base changes in glutamine codons (CAA to TAA, CAA to GAA, CAA to CAG etc.), except for the codon GCA (alanine). The stop codons were detected, because of the changes of CAA to TGA in C-terminal polyglutamine domain of Gli1-4 and CAA to TAA in N-terminal polyglutamine domain of Gli1-4 and Gli2-2. The two codons for glutamine, CAA and CAG, are not randomly distributed in the α-gliadin, but tend to occur in homomeric runs of single codons. Moreover, in the two polyglutamine domains, the use of CAA is far more than CAG (Table 4).
Number and placement of cysteine residues: Most α-gliadin sequences contain six conserved cysteine residues that form intramolecular disulphide bonds. Similar to most α-gliadin sequences, six cysteine residues are found in the two unique regions (four in the N-terminal region and two in C-terminal region) in eight amino-acid sequences. These cysteine residues could form three intramolecular disulphide bonds, resulting in the compact structure (Müller and Wieser, 1995). It is also find that sequence Gli1-2 has an additional cysteine created by
| Table 2: | Repeat domain motifs for the major classes of the gliadin superfamily |
 | |
| Table 3: | Comparison of polyglutamine regions of α-gliadins |
 | |
| Table 4: | Microsatellites encoding the polyglutamine within the nine α-gliadin gene sequences |
 | |
a serine-to-cysteine residue change at position 240 and thus contained seven cysteines. Thus, sequence Gli1-2 would have one free cysteine for intermolecular disulfide bond formation. Such gliadins could participate in the gluten polymer and effectively serve as polymer terminators (Kasarda, 1989). The distribution of cysteines in α-gliadin could also influence to gluten quality. Changes in position of cysteine residues might affect the pattern of disulphide bond formation, resulting in a failure of two cysteine residues in a protein. Such two cysteine residues would then be available for intermolecular disulphide bond formation (Masci et al., 2002). Lew et al. (1992) and Masci et al. (1995) have reported that a substantial portion of the lower-molecular weight polypeptides in the glutenin polymer are α-gliadins and γ-type gliadin sequences. More detailed examination is needed to determine the relationships between α-gliadins and the flour quality.
Pseudogenes: A number of cereal pseudogenes have been reported (Forde et al., 1985; Rafalski, 1986; Harberd et al., 1987). In this report, only Gli1-7, Gli2-4 could encode mature proteins; the other seven α-gliadin genomic fragments are assumed to be pseudogenes because of the internal stop codons. It is nearly 80% of the genes were pseudogene. The ratio is far more than 50% which was estimated by Anderson and Greene (1997). Almost all of the nonsense mutations were resulted from the C to T change in glutamine codons. In addition, 15.5% of the premature stop codons were caused by T to A change, altering the codon of leucine (TTG) into a stop codon (TAG) (Teun et al., 2006). The C to T transition has been theorized to predominate because of the ability of 5-methyl-cytidine to be incorrectly replicated as a thymidine (Gojobori et al., 1982). The changes into stop codons were not distributed randomly across the amino acid residue positions in the sequences. As shown in Fig. 1, the internal stop codons were nearly always located at positions where the full-ORF genes contained a glutamine residue codon. Farthermore, most of the internal stop codons gathered together in the unique region II. Three of the seven pseudogenes have more than one premature stop codon. A high percentage
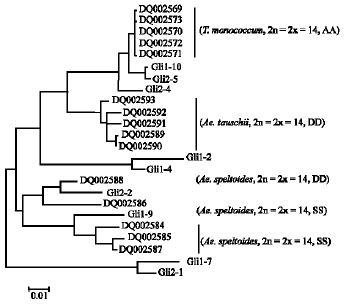
| Fig. 2: | The evolutionary relationships of isolated sequences with known α-gliadin genes |
 | |
of stop codons occurred jointly in one pseudogene and many pseudogenes from one species contained the same set of stop codons, suggesting that they have been duplicated after the mutations created the stop codons.
Phylogenetic tree of α-gliadin sequences: In order to obtained more information between the α-gliadin genes from T. turgidum ssp. paleocolchicum and other related species, fifteen representative α-gliadin genes were retrieved from the NCBI. Five out of the fifteen genes (DQ002589-DQ002573) derived from T. monococcum (2n = 2x = 14, AA), another five genes (DQ002584-DQ002588) derived from Ae. speltoides (2n = 2x = 14, SS), which was considered to be the B genome ancestor. Five genes (DQ002589-DQ002593) derived from Ae. tauschii (2n = 2x = 14, DD) (Teun et al., 2006). As shown in Fig. 2, it is obvious that the genes retrieved from the NCBI gathered into three groups. The sequences derived from the A genome (T. monococcum) as well as the sequences from the D genome (Ae. tauschii) each formed a separate cluster of relatively closely related genes in the phylogenetic tree. The sequences originated from the Ae. speltoides (B genome) formed a relatively diverse cluster. Gli1-10, Gli2-5 and Gli2-4 are closely related to the genes from the genome A, while Gli2-2 and Gli1-9 seem to be more homologous with the genes from the genome B. No genes were clustered into the groups of genome D, which is consistent with the genome of T.turgidum ssp. paleocolchicum (2n = 4x = 28, AABB). Four clones were out of the three groups. Among the four clones, Gli1-2 and Gli1-4 seem more homologous with genes from genome A and D, while Gli1-7 and Gli2-1 were the least genetically related to the other genes. The reason for this is not clear at present and further researches are needed.
ACKNOWLEDGMENTS
This research was supported by the National High Technology Research and Development Program of China (863 program 2006AA10Z179 and 2006AA10Z1F8), the Key Technologies RandD Program (2006BAD01A02-23) and the FANEDD project (200357 and 200458) from Ministry of Education, China. Y.-M.Wei was supported by the Program for New Century Excellent Talents in Universities of China (NCET-05-814). Y.-L. Zheng was supported by the Program for Changjiang Scholars and Innovative Research Teams in Universities of China (IRT0453).
REFERENCES
- Anderson, O.D. and F.C. Greene, 1989. The characterization and comparative analysis of high-molecular-weight glutenin genes from genomes A and B of a hexaploid bread wheat. Theor. Applied Genet., 77: 689-700.
CrossRefDirect Link - Anderson, O.D. and F.C. Greene, 1997. The-gliadin gene family. II. DNA and protein sequence variation, subfamily structure and the role of group 6 and group 2 chromosomes in gliadins synthesis. Theor. Applied Genet., 95: 59-65.
CrossRef - Cassidy, B.G. and J. Dvorak, 1991. Molecular characterization of a low-molecular-weight glutenin cDNA clone from Triticum durum. Theor. Applied Genet., 81: 653-660.
CrossRef - Cassidy, B.G., J. Dvorak and O.D. Anderson, 1998. The wheat low-molecular-weight glutenin genes: Characterization of six genes and progress in understanding gene family structure. Theor. Applied Genet., 96: 743-750.
CrossRefDirect Link - D’Ovidio, R., D. Lafiandra, O.A. Tanzarella, O.D. Anderson and F.C. Greene, 1991. Molecular characterization of bread wheat mutants lacking the entire cluster of chromosome 6A-controlled gliadin components. J. Cereal Sci., 14: 125-129.
CrossRef - D’Ovidio, R., O. Tanzarella, S. Masci, D. Lafiandra and E. Porceddu, 1992. RFLP and PCR analyses at Gli-1, Gli-2, Glu-1 and Glu-3 loci in cultivated and wild wheats. Hereditas, 116: 79-85.
CrossRef - Forde, J., J.M. Malpica, N.G. Halford, P.R. Shewry O.D. Anderson, F.C. Greene and B.J. Miflin, 1985. The nucleotide sequence of a HMW glutenin subunit gene located on chromosome 1A of wheat (Triticum Aestivum L.). Nucleic Acids Res., 13: 6817-6832.
CrossRef - Gaut, B.S., B.R. Morton, B.C. Mccaig and M.T. Clegg, 1996. Substitution rate comparisons between grasses and palms: Synonymous rate differences at the nuclear gene Adh Parallel rate differences at the plastid gene rbcL. Proc. Nat. Acad. Sci., 3: 10274-10279.
Direct Link - Gojobori, T., W.H. Li and D. Graur, 1982. Patterns of nucleotide substitution in pseudogenes and functional genes. J. Mol. Evol., 18: 360-369.
CrossRefDirect Link - Harberd, N.P., R.B. Flavell and R.D. Thompson, 1987. Identification of a transposon-like insertion in a Glu-1 allele of wheat. Mol. Gen. Genet., 209: 326-332.
CrossRefDirect Link - Khatkar, B.S., R.J. Fido, A.S. Tatham and J.D. Schofield, 2002. Functional properties of wheat gliadins.II. Effects on dynamic rheological properties of wheat gluten. J. Cereal Sci., 35: 307-313.
Direct Link - Kumar, S., K. Tamura and M. Nei, 2004. MEGA3: Integrated software for molecular evolutionary genetics analysis and sequence alignment. Brief. Bioinform., 5: 150-163.
CrossRefPubMedDirect Link - Lew, E.J.L., D.D. Kuzmicky and D.D. Kasarda, 1992. Characterization of low molecular weight glutenin subunits by reversed-phase high-performance liquid chromatography, sodium dodecyl sulfate-polyacrylamide gel electrophoresis and N-terminal amino acid sequencing. Cereal Chem., 69: 508-515.
Direct Link - Masci, S., E.J.L. Lew, D. Lafiandra, E. Porceddu and D.D. Kasarda, 1995. Characterization of low molecular weight glutenin subunits in durum wheat by reversed-phase high-performance liquid chromatography and N-terminal sequencing. Cereal Chem., 72: 100-104.
Direct Link - Masci, S., L. Rovelli, D.D. Kasarda, W.H. Vensel and D. Lafiandra, 2002. Characterisation and chromosomal localisation of C-type low-molecular-weight glutenin subunits in the bread wheat cultivar Chinese Spring. Theor. Applied Genet., 104: 422-428.
CrossRef - Metakovsky, E.V., A.Y. Novoselskaya and A.A. Sozinov, 1984. Genetic analysis of gliadin components in winter wheat using two-dimensional polyacrylamide gel electrophoresis. Theor. Applied Genet., 69: 31-37.
CrossRef - Mori, N., T. Moriguchi and C. Nakamura, 1997. RFLP analysis of nuclear DNA for study of phylogeny and domestication of tetraploid wheat. Genes Genet. Syst., 72: 153-161.
CrossRef - Shewry, P.R. and A.S. Tatham, 1990. The prolamin storage protein of cereal seeds: Structure and evolution. Biochem. J., 267: 1-12.
PubMed - Shewry, P.R., N.G. Halford, P.S. Belton and A.S. Tatham, 2002. The structure and properties of gluten: An elastic protein from wheat grain. Phil. Trans. R. Soc. Lond. B, 357: 133-142.
CrossRefDirect Link - Teun, W.J.M., van Herpen and S.V. Goryunova, 2006. α-gliadin genes from the A, B and D genomes of wheat contain different sets of celiac disease epitopes. BMC. Genomics, 7: 1-1.
PubMed