
Arezoo Bagheri
National Population Studies and Comprehensive Management Institute, Tehran, Iran
LiveDNA: 98.12751
Mahsa Saadati
National Population Studies and Comprehensive Management Institute, Tehran, Iran
Journal of Applied Sciences
Year: 2017 | Volume: 17 | Issue: 4 | Page No.: 196-203







ABSTRACT
Background: Sampling and estimating of hidden population sizes, such as injection drug users are important issues for health policy makers, because of exposing these populations to high risks diseases, such as HIV/AIDS. Materials and Methods: Respondent driven sampling is a successful method in terms of resulting in representative sample of hidden populations and finding unbiased estimates comparing to the other existing conventional methods. Results: The main purpose of this study is to define population proportion estimation of this sampling method for dichotomous and non-dichotomous variables. For non-dichotomous variables, reciprocal approach results in over-determination equations which can be solved by either least squares or data smoothing approaches, though the late one is much more effective. A hypothetical data has been employed to find the estimation of dichotomous and non-dichotomous variables for respondent driven sampling method. Conclusion: The novelty of data smoothing procedure to find respondent driven sampling estimates has been proved by this hypothetical data. Respondent driven sampling method could result in unbiased estimates of population proportions and it has been recommended to be applied for studying hidden population proportions.
PDF Abstract XML References Citation
Received: October 18, 2016;
Accepted: January 24, 2017;
Published: March 15, 2017
Copyright: © 2017. This is an open access article distributed under the terms of the creative commons attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
How to cite this article
Arezoo Bagheri and Mahsa Saadati, 2017. Population Proportion Estimator of Respondent Driven Sampling for Non-dichotomous Variables, Data Smoothing Approach. Journal of Applied Sciences, 17: 196-203.
DOI: 10.3923/jas.2017.196.203
URL: https://scialert.net/abstract/?doi=jas.2017.196.203
DOI: 10.3923/jas.2017.196.203
URL: https://scialert.net/abstract/?doi=jas.2017.196.203
INTRODUCTION
Collecting accurate information about the behavior and composition of hidden social groups specially those exposing high risk and transmitted diseases such as HIV/AIDS is one of the vital issues of the most policy makers all around the world. Some well-known examples of such populations are Injection Drug Users (IDU)1-3, sex workers4 and men who have sex with men (MSM)5.
Conventional sampling methods can not achieve a good prospective of these populations who influence the public health of society. These methods require a known probability of selection which means to have a sampling frame from all members of these populations. This information mostly does not exist6. One of the efficient methods of collecting information about hidden populations is institutional sampling method. Sampling IDU population by this method will be restricted for example to those attending to a drug rehabilitation program. In this way, any inferences from the resulting sample are not statistically valid7.
Another two most common approaches of sampling these populations are targeted and time-space sampling methods. Both of these methods treat the hidden population members discretely and they do not use population’s networks relationships to estimate accurately. Targeted sampling or street outreach mostly can not reach a large number of non-institutional members of the hidden population8. The sample is not selected randomly and the probability selection of sample is unknown. Time-space sampling method introduced to select samples with known probability in the identified venues and ease inferences in this way9. Safety and cost concerns of some venues cause them not to be accessible for the researchers and the sample in this way is not representative of target populations10. Coverage problem of this method which makes unknown bias to the hidden population estimates by Stueve et al.10.
Another common approach is chain-referral sampling which can successfully penetrate in hidden populations and recruit their members but the estimations from these populations are statistically invalid. These methods has been called as non-probability methods due to have unknown probability of sample selection11. One of the most applicable chain-referral sampling methods is snowball sampling, which is first introduced by Goodman12.
A new sampling method, called Respondent Driven Sampling (RDS) introduced by Heckathorn13,14. It is an altered method of snowball sampling. Since, last two decades of introducing RDS method, lots of researchers in different field of science, such as health and demography are studying and applying this sampling method15-21.
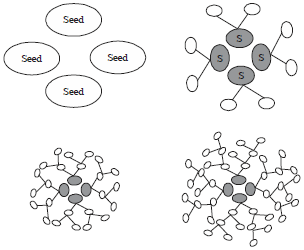 | |
| Fig. 1: | Recruitment process in RDS method |
The RDS sample is gathered in the same way as any chain-referral sampling method. Figure 1 presents the sampling process of RDS method. In this study, sampling starts from initial members, which are called seeds. Seeds are non-random members of the sample that are selected by researchers from their interested hidden population. They are those members who have bigger social networks among the others. These new members (recruiters) start recruiting from their social networks and introduce new members to the sample (recruits). These new recruiters recruit new members and ties are formed. This procedure continues till the desired sample size is achieved.
The RDS is an indirect method of estimating from sample about the population. The sample is used to make estimations about social network connections and then this information could be applied to make asymptotically unbiased population proportion estimates6. The bias of these estimates is on the order of sample size inverse, so, it is negligible for meaningful sample sizes22.
To find population estimators of RDS samples, there are different approaches for dichotomous (for example, HIV+, HIV-) and non-dichotomous variables (for example, quartiles of age, 20, 30 and 30-40 and etc). The main aim of this study is to review estimator for dichotomous variables and define data smoothing estimators for non-dichotomous variables.
MATERIALS AND METHODS
The RDS recruitment network reflects pre-existing social relationships that link recruiters and recruits. These relationships are reciprocal. In this way, Tab the number of ties from A-B equals those from B-A that means as shown in Eq. 1:
Tab = Tba | (1) |
The number of such crosscutting ties depends on three following factors in Eq. 2:
Tab = NaDaSab | (2) |
The same results can also be concluded for Tba. Setting these two equations in Eq. 1 and dividing 2 parts of the equation to N, population size can get following Eq. 3:
PaDaSab = PbDbSba | (3) |
By substituting (1-Pa) for Pb, the Eq. 3 will be an estimate of population size of group A, Pa, based on the reciprocity model given Eq. 4:
| (4) |
The same results can also be concluded for Pb. Equation 4 provides an estimation of the proportional size of the hidden population according to the transition probabilities based on recruitment patterns and self-reported personal network size14,23.
To find unbiased estimators of the population proportion size, the transition probabilities and personal network size should be estimated. A recruitment matrix, R, where Rab is the number of recruitments by the members of group A of members of group B could be considered as in Eq. 5:
| (5) |
According to this matrix, the unbiased estimators of Sab and Sba can be computed as in Eq. 6:
| (6) |
where, RBa = Raa+Rab and RBb = Rbb+Rba. The second element of RDS population size estimator is the mean degree of each group which could be estimated as Salganik and Heckathorn6 given in Eq. 7:
| (7) |
The RDS is based on the theories of Markov chain model so the recruitment process in RDS has the following characteristics.
A memory less process: The recruitment pattern of each recruiter depends only on its own recruiter. It has been termed as a first Markov process characteristic by Heckathorn13.
An ergodic process: A recruiter with one set of characteristics recruiting another subject with the same or different characteristics. After one or more recruitment waves, a recruit can have the same characteristics as the earlier recruiter.
To reduce the bias of not selecting RDS seeds randomly, the recruitment should be continued until equilibrium is reached. To compute equilibrium analytically, the low of large numbers for Markov chains can be applied. The equilibrium for a system of two groups, A and B could be defined as in Eq. 8:
| (8) |
Ea = SaaEa+SbaEb |
Solving this Eq. 8 system results in Eq. 9:
| (9) |
Population proportion estimator for non-dichotomous variables: Reciprocity model for a system with N groups can be shown by a system of equations, where the 1st equation express equality of summing the population proportion size of groups to one. Each of the other ![]() equations shows reciprocity principals for each of the other two groups that can be shown as following in Eq. 10 and 11 for a 4 group system of A, B, C and D:
equations shows reciprocity principals for each of the other two groups that can be shown as following in Eq. 10 and 11 for a 4 group system of A, B, C and D:
1 = Pa+Pb+Pc+Pd | (10) |
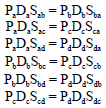 | (11) |
This system of equations are over-determined because the number of unknowns and equations are not equal. This problem could happen for non-dichotomous variables (any three or more categories variables). There are two different approaches for dealing with this problem. Linear least square is a standard solving process for these systems which has the same logic as linear regression24. Another approach that is explained in the study is an alternative method for calculating the population proportion estimates that is drawn from the same logic as reciprocity models.
Data smoothing approach: Data smoothing approach as a solution for overcoming the problem of over-determination in finding population proportion estimates for non-dichotomous variables has been introduced by Heckathorn14. The main idea in this study which comes from reciprocity models is about equality of the number of recruits, RO and the number of recruitments, RB for each group. By considering random recruitments from personal networks, cross-group recruitments will be equal for each pair of groups. The best estimate for the number of cross-recruitments between each pair of groups is the mean of recruitments in each direction. In this way, the problem of over-determination is solved by reducing the number of terms from which population estimates are calculated. This approach results in more efficient estimates comparing to linear-least squares approach25. The point estimations are not affected for dichotomous variables by this approach, though for estimating variance it could be effective25. This study can be done in the following steps.
Ranking or demographic adjustment step: That could be done by transforming the recruitment matrix using two conditions of not changing recruitment pattern and equaling the row and column sums for recruitment matrix (for any group, RO = RB). Each element in the transformed recruitment matrix (Rab) is the product of three terms of the selection proportion ![]() the equilibrium for the recruiter’s group
the equilibrium for the recruiter’s group ![]() and the total number recruitments (RB). For a system with N group, the adjusted recruitment matrix R* is given in Eq. 12:
and the total number recruitments (RB). For a system with N group, the adjusted recruitment matrix R* is given in Eq. 12:
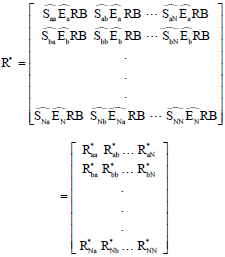 | (12) |
So for any groups, such as A, ![]() and
and ![]() .
.
Smoothing step: The best estimate for demographically adjusted recruitment counts are smoothed counts which are calculated by finding the mean of these counts across groups. In this way, the smoothed matrix, R** is found as in Eq. 13:
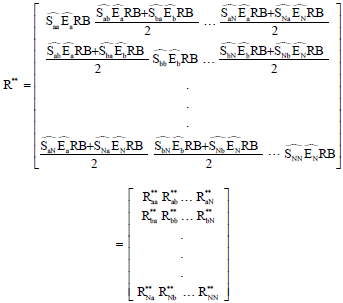 | (13) |
The R** becomes the basis for all the other calculations and the smoothed population proportion estimate could be computed according to this matrix.
RESULTS
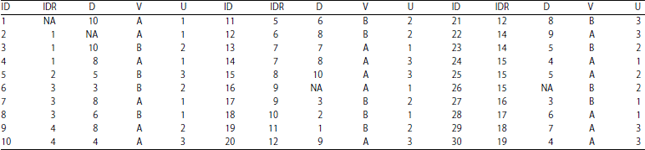
In this study, by considering a hypothetical population which is made of two groups, Injection Drug User (IDU) with positive HIV (HIV+), group A and Injection Drug User (IDU) with negative HIV (HIV‾), group B, the population proportion estimates are calculated. Table 1 presents this population consisting of 30 cases. According to Table 1, ID is respondent identification, IDR is respondent identification of each respondent’s recruiter, D is respondent’s self-reported degree and V is a dichotomous variable (IDU with HIV+ and IDU with HIV‾) and U is a non-dichotomous variable (educational levels, (1) <Diploma, (2) Diploma and bachelor and (3) >Bachelor).
Respondent driven sampling estimates for dichotomous variables: The population proportion estimates for these two groups, IDU with HIV+ and IDU with HIV‾ are computed by RDS estimators. According to the Table 1, the first respondent is seed, so it doesn’t have any recruiter. Note that the degree data for cases of 2, 16 and 26 are missing.
| Table 1: | Characteristics of hypothetical population |
 | |
| Table 2: | Recruitment of matrix of IDU with HIV+ and IDU with HIV‾ groups |
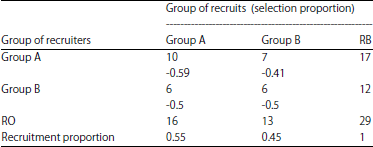 | |
Table 2 presents recruitment matrix of data in Table 1. As it is presented in Table 1, the first respondent (seed) is a member of group IDU with HIV+, recruited respondents 2, 3 and 4, respondents 2 and 4 are members of group IDU, respondent 3 is a member of group IDU with HIV‾. So, transition probabilities could be computed according to this recruitment pattern. Table 2 also consists of recruitment proportions which are computed from the recruitment counts.
The number of each group can be found from extracting seeds and members with missing data of degree, so na = 17-1-2 = 14 and nb = 13-1 = 12. The estimated degrees for these two groups according to the Eq. 7 are:
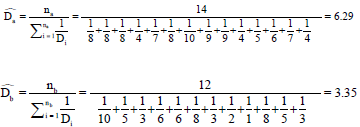
The population estimates for these two groups also are shown in Eq. 14:
| (14) |
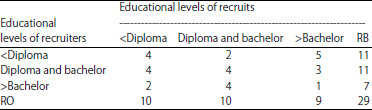
| Table 3: | Recruitment matrix of three educational levels |
 | |
| Table 4: | Selection probabilities of three educational levels |
 | |
| Table 5: | Equilibrium of three educational levels |
| (15) |
The equilibriums for these two groups are calculated from transition probabilities as given in Eq. 15:
Respondent driven sampling estimates for non-dichotomous variables: In this study, data smoothing procedure is examined in driving population proportion estimates for variables with three or more categories. Table 3 demonstrates recruitment matrix by educational levels. Table 4 also presents selection probabilities for this variable.
According to the selection probabilities in Table 4, solving following equations results in equilibrium of these three levels of education which has been shown in Table 5:
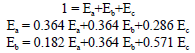 |
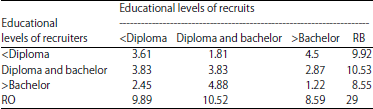
| Table 6: | Demographically adjusted matrix of three educational levels |
 | |
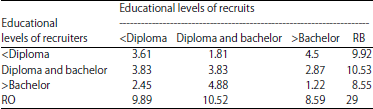
| Table 7: | Data smoothed recruitment matrix of three educational levels |
 | |
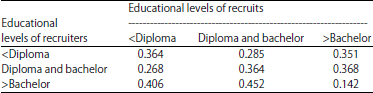
| Table 8: | Data smoothed selection probabilities of three educational levels |
 | |
To find the demographically adjusted matrix that is presented in Table 6 similar to the demographically adjusted matrix in Eq. 7, each cell has been multiplied by the selection probabilities in Table 4, equilibrium in Table 5 and the total recruitment (RB).
Table 7 presents smoothed recruitment matrix according to the Eq. 13 that is found by averaging the cross-recruitment counts. Then this matrix could be employed to recalculate all the other terms such as data smoothed selection probabilities in Table 8 and estimated degrees:
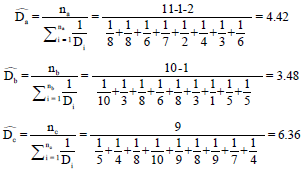
According to the results of estimated degrees and smoothed selection probabilities, following equations could be concluded:
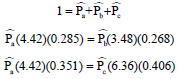
So, the population proportion estimates for three educational levels are equal to ![]() .
.
DISCUSSION
Most of present studies about hidden populations result in samples which have been collected by lots of effort and could not be generalized to the interested populations6,15-21,26,27. So, in this way, some descriptive statistics could be drown from these samples and no statistical inferences could be possible to conclude13,14. It also leads researchers to some misleading conclusions6. The RDS method which has been introduced by Heckathorn13,14 and reviewed in this study could solve this problem. However, if the expected procedure in RDS couldn’t be followed it will not result in more efficient estimators comparing to chain referral sampling methods28. The RDS results in asymptotically unbiased population proportion estimates when theoretical and analytical assumptions of this sampling method could achieve6. In the condition that some of non-sampling errors, such as non-random selection of seeds, not-achieving to equilibrium in most important interested variables in the study and countering homophile which is recruiting non-randomly from social networks exist, RDS will not conclude in unbiased estimators6,13,14. Moreover, no statistical inferences could be drown from RDS samples.
For finding estimates of non-dichotomous variables in RDS method, reciprocal approach introduced by Salganik and Heckathorn6 and Heckathorn14 results in over-determination equations which can be solved by either least squares or data smoothing approaches. Data smoothing approach has been reviewed and calculated for a hypothetical data in this study. This method has been claimed that is much more effective in calculating unbiased estimators comparing to least squares6,13,14.
CONCLUSION
The RDS sample could result in asymptotically unbiased estimates of population proportions, by collecting the information about social networks. By applying the theories behind reciprocal models, RDS results in population proportion estimates for dichotomous and non-dichotomous variables. The main purpose of this study is to introduce data smoothing that is an effective method to overcome over-determination problem in non-dichotomous variables case has been reviewed. An hypothetical data has been applied to show the novelty of this method for finding population proportion estimates for non-dichotomous variables.
ACKNOWLEDGMENTS
The authors would like to acknowledge the following article extracted from a survey under the title of "Respondent Driven Sampling Statistical Inferences to Estimate Demographical Parameters" which is supported by National Population Studies and Comprehensive Management Institute in 2015 by the registered number of 20/18616.
REFERENCES
- Mumtaz, G.R., H.A. Weiss, S.L. Thomas, S. Riome and H. Setayesh et al., 2014. HIV among people who inject drugs in the Middle East and North Africa: Systematic review and data synthesis. PLoS Med., Vol. 11.
CrossRefDirect Link - Young, A.M., R.J. DiClemente, D.S. Halgin, C.E. Sterk and J.R. Havens, 2014. Drug users' willingness to encourage social, sexual and drug network members to receive an HIV vaccine: A social network analysis. AIDS Behav., 18: 1753-1763.
CrossRefDirect Link - Stormer, A., W. Tun, L. Guli, A. Harxhi and Z. Bodanovskaia et al., 2006. An analysis of respondent driven sampling with Injection Drug Users (IDU) in Albania and the Russian Federation. J. Urban Health, 83: 73-82.
CrossRefDirect Link - Liu, H., H. Liu, Y. Cai, A.G. Rhodes and F. Hong, 2009. Money boys, HIV risks and the associations between norms and safer sex: A respondent-driven sampling study in Shenzhen, China. AIDS Behav., 13: 652-662.
CrossRefDirect Link - Chopra, M., L. Townsend, L. Johnston, C. Mathews, M. Tomlinson, H. O'Bra and C. Kendall, 2009. Estimating HIV prevalence and risk behaviors among high-risk heterosexual men with multiple sex partners: Use of respondent-driven sampling. J. Acquired Immune Deficiency Syndromes, 51: 72-77.
CrossRefDirect Link - Salganik, M.J. and D.D. Heckathorn, 2004. Sampling and estimation in hidden populations using respondent-driven sampling. Sociol. Methodol., 34: 193-240.
CrossRefDirect Link - Watters, J.K. and Y.T. Cheng, 1987. HIV-1 (Human Immunodeficiency Virus-type one) infection and risk among intravenous drug users in San Francisco: Preliminary results and implications. Contemp. Drug Problems, 14: 397-410.
Direct Link - Watters, J.K. and P. Biernacki, 1989. Targeted sampling: options for the study of hidden populations. Social Problems, 36: 416-430.
CrossRefDirect Link - Muhib, F.B., L.S. Lin, A. Stueve, R.L. Miller and W.L. Ford et al., 2001. A venue-based method for sampling hard-to-reach populations. Public Health Rep., 116: 216-222.
Direct Link - Stueve, A., L.N. O'Donnell, R. Duran, A. San Doval and J. Blome, 2001. Time-space sampling in minority communities: Results with young Latino men who have sex with men. Am. J. Public Health, 91: 922-926.
Direct Link - Heckathorn, D.D., 1997. Respondent-driven sampling: A new approach to the study of hidden populations. Social Probl., 44: 174-199.
CrossRefDirect Link - Heckathorn, D.D., 2002. Respondent-driven sampling II: Deriving valid population estimates from chain-referral samples of hidden populations. Social Problems, 49: 11-34.
CrossRefDirect Link - Bagheri, A., 2016. Respondent driven sampling: A new approach to sampling rare and hidden diseases. J. Health Syst. Res., 11: 753-761.
Direct Link - Saadati, M. and A. Bagheri, 2016. Respondent driven sampling method compared with other sampling methods of hidden populations. Iran. J. Epidemiol., 12: 63-74.
Direct Link - Bagheri, A. and M. Saadati, 2015. Exploring the effectiveness of chain referral methods in sampling hidden populations. Indian J. Sci. Technol., 8: 1-8.
CrossRefDirect Link - Erdos, P. and A. Renyi, 1959. On random graphs, I. Publicationes Mathematicae, 6: 290-297.
Direct Link - Heckathorn, D.D., 2007. Extensions of respondent‐driven sampling: Analyzing continuous variables and controlling for differential recruitment. Sociol. Methodol., 37: 151-207.
CrossRefDirect Link - Volz, E. and D.D. Heckathorn, 2008. Probability based estimation theory for respondent driven sampling. J. Official Stat., 24: 79-97.
Direct Link