
Soro Etienne
Ecole Superieure Africaine des TICs (ESATIC), Direction de la Recherche et l�Innovation Technologique (DRIT), Boulevard de Marseille, Abidjan-Treichville Zone 3-km 4, C�te d`Ivoire
Brou Pacome
Ecole Superieure Africaine des TICs (ESATIC), Direction de la Recherche et l`Innovation Technologique (DRIT), Boulevard de Marseille, Abidjan-Treichville Zone 3-km 4, C�te d`Ivoire
Diaby Moustapha
Ecole Superieure Africaine des TICs (ESATIC), Direction de la Recherche et l`Innovation Technologique (DRIT), Boulevard de Marseille, Abidjan-Treichville Zone 3-km 4, C�te d`Ivoire
Asseu Olivier
Ecole Superieure Africaine des TICs (ESATIC), Direction de la Recherche et l`Innovation Technologique (DRIT), Boulevard de Marseille, Abidjan-Treichville Zone 3-km 4, C�te d`Ivoire
Aka Boko Matthieu
Laboratoire des Mathematique Informatique (LMI), Universite Nangui Abrogoua (UNA), Abidjan (Axe Abobo-Adjame), C�te d`Ivoire
Konate Adama
Ecole Superieure Africaine des TICs (ESATIC), Direction de la Recherche et l`Innovation Technologique (DRIT), Boulevard de Marseille, Abidjan-Treichville Zone 3-km 4, Cote d`Ivoire
Oumtanaga Souleymane
Institut National Polytechnique-Houphouet Boigny (INP-HB), Laboratoire de Recherche en Informatique et Telecommunication (LARIT), Abidjan-Cocody Danga, Cote d`Ivoire
Journal of Applied Sciences
Year: 2016 | Volume: 16 | Issue: 12 | Page No.: 549-561







ABSTRACT
Background and Objective: This study proposes an optimization model for assigning cells to serving gateway (SGW) in Long Term Evolution Advanced (LTE-A) network in architecture: "Centralized control/distributed bearer". The objective is to minimize the costs of connection and handover operations to ensure a transparent mobility management related to moving all-out users. Methodology: A heuristic based on genetic algorithm according to Charles Darwin's theory of survival of the species is proposed in order to get solutions fairly close to the optimum by reducing the runtimes of test. The process is essentially to find iteratively a feasible solution to each generation from an initial population consists of heterogeneous chromosome respecting the constraint on the ability of each SGW. Results: The proposed genetic code permits to obtain a feasible solution after a number of iteration, however, the uncontrollable factor of randomness in the genetic process affects the quality of solutions. Conclusion: The results show that an adequate application of genetic operators (Selection, crossover and mutation) permits to obtain solution to any generation whatever the number of chromosome in the population.
PDF Abstract XML References Citation
Received: August 29, 2016;
Accepted: September 30, 2016;
Published: November 15, 2016
How to cite this article
Soro Etienne, Brou Pacome, Diaby Moustapha, Asseu Olivier, Aka Boko Matthieu, Konate Adama and Oumtanaga Souleymane, 2016. Assigning eNode B to Switches in LTE Advanced Network by an Approach Genetic. Journal of Applied Sciences, 16: 549-561.
DOI: 10.3923/jas.2016.549.561
URL: https://scialert.net/abstract/?doi=jas.2016.549.561
DOI: 10.3923/jas.2016.549.561
URL: https://scialert.net/abstract/?doi=jas.2016.549.561
INTRODUCTION
The radio technology Long Term Evolution Advanced (LTE-A) is the new radio communication standard mobile network of the 4th generation with high-speed, wide band coverage, low latency and seamless mobility management services include packet switching compared to GSM and GPRS in 2nd generation (2G) and UMTS 3rd generation (3G)1-3. The LTE architecture, named Evolved Packet System (EPS) shown in Fig. 1 consists of two parts. The access network or Evolved UMTS Terrestrial Radio Access Network (E-UTRAN) divided into cells. Each cell represented by a hexagon has a centralized base station called eNode B which may be interconnected by X2 interface (optional) and the core network or Evolved Packet Core (EPC) whose essential functioning is ensured by the Mobility Management Entity (MME) in the control plan, the serving gateway (SGW) connected to the access network through the S1-U interface in the user plan (or data plan), the packet data network gateway (PGW) and nominal subscriber server (HSS) is a central database that contains customer information, the mobile location information4-6.
Planning is a fundamental step before deployment and networking of the service, one of its most fundamental aspects studied in the literature remains the problem of entities to cells assignment (switches) of the core network. Indeed, it is to determine a cell assignment scheme to switches in order to minimize some cost function, while taking into account a number of constraints, one of which is related to the capacity of the switches and the optimization mathematical models proposed in this regard are mainly based on two main parameters that are:
| • | The studied technology and architecture levels considered in the access network of the given technology7-9 |
| • | The cell planning is the subject of intense research activity because of the expansion of technological standards |
In the literature, several cell assignment models are presented.
Thus, in the architecture of cellular communication networks of 2nd generation (2G), the researchers considered two levels of equipment with a single assignment that is to assign the Base Transceiver Station (BTS) to the Mobile Switching Center (MSC). Level 1 includes the Base Transceiver Station (BTS) each occupying a cell, while level 2 is composed only of switches Mobile Switching Center (MSC). Thus all optimization models developed in the literature have ignored the presence of the BTS controllers (BSC: Base station controller) for purpose of simplicity10-12 (Fig. 2). In this study, solving the problem means finding a cell model assignment to MSC switches.
At the 3rd generation (3G) mobile networks, Universal Mobile Telecommunications System (UMTS), the researchers considered three equipment levels. Indeed, the addition of the RNC and SGSN equipment provides data traffic in addition to voice unlike the previous 2G GSM technology. This new configuration is the basis of a new model formulation optimization mathematical problem of assigning cells to switches in considering two assignments of assigning the Node B to the RNC and the RNC to MSC and SGSN. Level 1 contains the cells. Each cell has a centralized base station called Node B, level 2 is composed only of Radio Network Controllers (RNC) and level 3 consists of the MSC and Serving GPRS Support Nodes (SGSN)7 (Fig. 3).
For the 4th generation of mobile networks, the approaches proposed by the researchers only concerns traffic control within the cells13-19. However, in a planning model of a 4G network (LTE) from an existing 3G network (UMTS)20, we see that the cell assignment is a major development, four equipment levels are considered. The first level includes the Node B, the second level the RNC, the third level of the MSC and SGSN of the core network UMTS and the fourth level includes MME and SGW core network LTE. However, the presence of MSC equipment in the core network UMTS technology does not provide packet switching telephony.
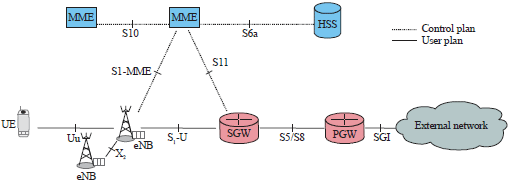 | |
| Fig. 1: | Network LTE advanced architecture with interfaces5, MME: Mobility management entity, HSS: Nominal subscriber server, SGW: Serving gateway, PGW: Packet data network gateway, eNB: eNode B and LTE: Long term evolution |
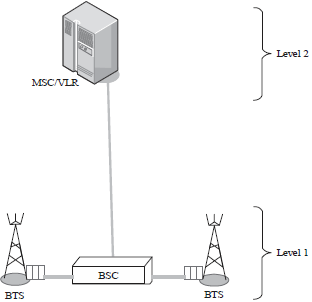 | |
| Fig. 2: | A typical cell assignment in GSM networks, GSM: Global system for mobile communications, BSC: Base station controller, BTS: Base transceiver and MSC: Mobile switching center |
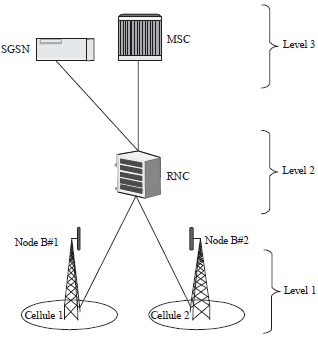 | |
| Fig. 3: | A typical cell assignment in UMTS network, UMTS: Universal mobile telecommunications system, MSC: Mobile switching center, RNC: Radio network controller and SGSN: Serving GPRS support node |
In terms of the research presented in the literature study, there are many models available in 2G and 3G. These are functions of two main parameters: the communication technology used and the number of equipment at each level in the access network. In network 4G LTE advanced, the proposed models are for optimization of bandwidth, load and capacity of a cell, that the allocation of cells to the core network of the switches was not treated.
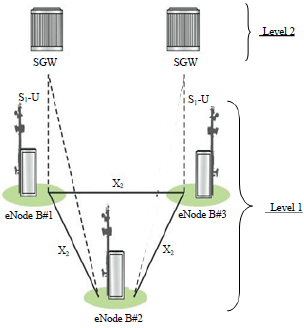 | |
| Fig. 4: | A typical cell assignment LTE advanced network, LTE: Long term evolution and SGW: Serving gateway |
The fundamental differences in the technologies (GSM-2G and UMTS-3G) particularly in architectures mean that optimization models proposed for these two technologies can’t be applied in 4G LTE advanced network. On the other hand, the phenomenon of succession or intercellular transfer (succession) in 4G LTE advanced is not interpreted in the same way as in 2G and 3G network if the principle is the same in the background. So it follows that the resulting costs do not express the way in view of the equipment used.
In this context, this study proposes a planning model to assigns the eNode B to switches of the core network LTE (Evolved packet core) in the user data plan by X2 and interfaces S1-U.
To achieve such an objective, a two level architecture equipment for two assignments is considered (Fig. 4). Thus, an interconnection of eNode B at level 1 and assigning these eNode B to SGW level 2 thanks to the X2 and S1-U interfaces are made. Then, the optimization model is a cost function that minimizes data loss rate and the time of the handover of operations when the user changes cells in the allocation constraints in both levels of the architecture and ability SGW switches user plane.
The main contributions in this study are:
| • | The definition of concepts and basic concept of cell assignment problem (eNode B) network switches 4G LTE advanced in the data plan | |
| • | The development of the optimization model taking into account the new type of handover achieved in the cells without the involvement of a network equipment of the core network in this case (the SGW or MME) and assignment between cells by X2 interface | |
| • | Adaptation of the genetic algorithm for solving the problem of affection networked cells 4G LTE advanced | |
| • | Level 1 includes the cells. Each cell has a centralized base station called eNode B and an interconnection between eNode B is achieved through the X2 interface | |
| • | Level 2 consists only of the SGW and the second sub allocation made is an assignment of eNode B to SGW by the S1-U interface in the data plan | |
The rest of the document is organized according to the following plan. We model the cell assignment problem at first, then study the model complexity. Secondly, we will present the method of resolution and the implementation of the model. The presentations computational results will be analysed. Finally, the conclusion and the presentation of the prospects for further work will conclude this document.
MATERIALS AND METHODS
Mathematical formulation of cell assignment problem: To model the problem of cells assignment in LTE advanced network, the following assumptions are considered.
The network consists of n eNode B each installed in one of the network cells, m SGW which are respectively identified by the indices 1 and 2 such that:
| • | I = {1, 2, 3,…, n}, the set of eNode B |
| • | J = {1, 2, 3,…, m}, the set of SGW |
| • | To each eNode B in the center of a cell is connected to a single SGW (level two assignment) and can be interconnected with other adjacent eNode B in cells (level one assignment) |
| • | The total capacity of the links connected to SGW can’t exceed this capacity (bit per second) |
| • | Finally, the cell assignment problem is divided into two problems: The interconnection of eNode B between them and the allocation of the eNode B to SGW |
Consider:
| : | The link cost between eNode B i (i∈I) and eNode B i’ (i’∈I) avec i ≠ I’ | |
| : | The link cost between eNode B i (i∈I) and SGW j (j∈J) | |
| : | The cost of handoff operation per unit time between the eNode B i and i’ with no change of SGW | |
| : | The cost of a handoff complex operation per unit of time report between the eNode B i and i’ without SGW | |
| : | The cost of single handoff operation per unit time between the eNode B i and i’ involving a change of SGW | |
| : | The cost of handoff complex operation per unit time between the eNode B i and i’ involving a change of SGW | |
| : | Represents the reduced cost per unit of time of a complex handoff between two eNode B i and i’ with SGW not changing | |
| : | Represents the reduced cost per unit of time of a complex handoff between eNode B i and i’ with a change of SGW | |
| : | The maximum capacity of the entity SGW J in (bps: bit per second) | |
| : | The data volume supported by the interface S1 between the eNode B i and entity SGW j |
Consider the following decisions variables:
To better understand the cost incurred by a handoff operation with change of SGW, we define the following additional variables: ![]() and
and ![]() with:
with:
| (1) |
These variables make it possible to formulate mathematically that two cell center which the eNode B and i and i’ are assigned to the same SGW j by the following property:
It is now:
| (2) |
Such as:
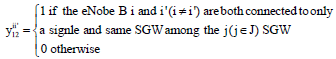 |
The global objective function F consists of the sum of total depreciation costs of connections and reduced costs per unit time of the handoff operations is thus written as:
| (3) |
Then it will minimize the cost function F defined in Eq. 3 under the following constraints.
Constraints of assignments: Each eNode B can be interconnected at most six other adjacent eNode B:
| (4) |
Each eNode B must be assigned to only one SGW:
| (5) |
Constraint on the ability of SGW: The amount of data coming from eNode B i should not exceed the capacity of SGW j:
| (6) |
Nonlinear constraints: Relation in Eq. 1 and 2 are nonlinear. Therefore, the problem cannot be solved with traditional methods of linear programming. Thus Merchant and Sengupta21,22 proposed a set of equivalent stresses. So relation in Eq. 1 and 2 will be replaced by the constraints defined below:
| (7) |
| (8) |
| (9) |
| (10) |
Accordingly, the initial allocation problem can be formed as follows:
Minimize f:
| (11) |
Subject constraints:
| (12) |
| (13) |
| (14) |
| (15) |
| (16) |
| (17) |
| (18) |
Equation 3 means the objective function to minimize: The first two terms represent the total cost of interconnection respectively between the eNode B cell level (Level 1 in Fig. 4) and the total cost of the assignments of eNode B and SGW (Level 2 in Fig. 4). The third and fourth terms represent respectively the reduced cost per time unit complex shifts without involvement of SGW and reduced cost per time unit complex shifts with a change of SGW.
Equation 4 states that an eNode (i) can be interconnected in more than six other adjacent eNode B because a cell only six neighbours. Equation 5 is the constraint related to the assignment so each eNode B should be assigned to one and only one SGW. Equation 6 imposes the constraint on the ability of SGW. Finally, constraints Eq. 7-10 are linearized to be equivalent to Eq. 1 to reduce the problem to an integer programming21,22.
Despite performed transmutations, the problem of allocation in an LTE-A network is still quite complex to solve. In the following section, we study the complexity of the assignment model established in Eq. 11 to show that it is more convenient to use a heuristic to solve our model to obtain a feasible solution close to the optimum in a reasonable calculation time.
Study of complexity of assignment model: The complexity of the mathematical model established in Eq. 11 is influenced by two levels seen in the architecture and the number of equipment present (Fig. 4). Indeed, it is to make a double assignment, first interconnection between eNode B and eNode B assignment at SGW. And by analysing more closely, we notice that it is similar to the cell assignment problem to switches in the work completed for mobile networks of second generation21,22 where the researchers show the equivalence this problem comparatively to the partitioning of graphs. Thus by analogy, each cell served by eNode B will be considered a vertex of the graph. Transaction costs of handovers due to mobility of users between each pair of nodes represent, in this case an arc connecting two nodes of the graph. In fact, this assignment problem in this context belongs to the class of NP-hard problems that are well known in operations research: The transportation problem or concentrators location23,24 and the one of graphs partitioning25,26. Their resolution by an enumerative method usually leads to an exponential growth of the execution time. Should therefore be excluded the use of an exact method.
In this study, first assignment is to interconnect n eNode B, requiring an algorithm with exhaustive enumeration examining of 6nn possible combinations to solve part of the problem. Then it will also affect these n eNode B to m SGW which is to argue another mn combinations. With this computing time that grows exponentially, we would not be able to find a solution in a reasonable time. This is an NP-hard problem. Accordingly, we search a rather close to the optimum solution, developing heuristics for its resolution practice in a reasonable calculation time.
Among the known heuristics, the solving approach chosen by the genetic algorithm is presented in this study.
Resolution approach by genetic algorithm: There are a large number of optimization problem whose resolution requires the use of heuristics; the objective is to obtain a feasible solution to an optimization problem where it cannot be solved with an exact method in a reasonable time. In this section, we will do an overview of genetic algorithms as a problem-solving method.
The Genetic Algorithms (GA) belonging to the class of so-called evolutionary algorithms27 were introduced by Holland28, inspired by Darwin’s law of nature the module based on the theory of survival the strongest species. Just as in nature where specimens are reproduced in the module genetic algorithms specimens also recur, especially those deemed stronger. Genetic operators (Crossover, mutation, selection…) are applied to two candidates hoping to get two new candidates perform better than their parents.
Genetic algorithms follow all the same principle29 and the method used in this study is not an exception. One distinguishes an encoding principle of the element of the population (chromosome), a phase of initial population creating, a phase alteration of that population genetic operators, an evaluation phase of each of the members of this population, selecting the best elements (based on the principle that only the best will be able to reproduce). Every generation is supposed to provide the most efficient components than previous generations. So we seek a stronger offspring, near an optimal solution.
Encoding of the chromosome to solve the problem cell assignment of LTE advanced network is well presented: In this adaptation, we chose to make a non-binary coding of chromosomes30. Each chromosome is an assignment diagram (topological network configuration) is an element of the population and defines a feasible solution of the problem.
In this adaptation, the chromosome length is equal to twice the number of network cell.
Length_Chromo = 2×number_eNode B
The reading of chromosomes is from left to right and the first half of the length of the chromosome represents the interconnection of cells and the other second half is the allocation of cells to SGW switches. The bits of chromosome represent the successive order of the cells (in ascending order of index):
| • | The first bit of chromosome contains the number of a cell to which the first cell is interconnected and so on until the end of the first half of the length of the chromosome |
| • | The first bit of the second half the length of the chromosome contains the number of a SGW in which the first cell is affected, the second bit contains the number of another SGW and so on until the last bit of chromosome, that is to say at the end of the second half |
| • | Finally, each chromosome respects the constraint on assignment but not the constraint on the capacity of the SGW switch |
| • | Each chromosome is a given configuration under after both performed assignments |
| Fig. 5: | Representation of a chromosome to a network 5 eNode B, 3 SGW |
For an allocation schemes to 5 cells (eNode B) and 3 SGW, Fig. 5 is a chromosome of this configuration.
The reading of the chromosome is as follows: The cells 3 and 4 are interconnected to the cell 1 and the cells 2 and 3 are assigned to the SGW 1 and SGW respectively 3. We will notice that the cell 4 is not interconnected with any other cell of the network and SGW 1 and 2 have each two cells assigned to them.
Genetic methodology adopted for the cell assignment problem in this study is to that presented by Bertrand et al.31. Thus, the pseudo code resulting process is as follows:
| Algorithm: | Pseudo-code Genetic for cells assigning in 4G/LTE-A network |
  | |
Environmental test execution: The performance of the adaptation of the genetic algorithm is based essentially on a good choice of its parameters. In the absence of actual data, our experiment was carried out by considering a number of tests generated by a MATLAB program.
The cost of link between the various entities is proportional to the distance separating them, with a coefficient of proportionality equal to unity21,22.
Traffic modelling: Traffic in a telecommunications network is the volume of transported or processed by the network information. Unlike previous technologies, a 4G LTE-A network has only one type of traffic, the transportation data in packet form.
The exponential increase in subscribers in recent years and their random behaviour leads32 us to assume that the traffic in the network follows a Markov chain in continuous time following a process of birth and death and as there is no mathematical laws which formalises accurately the behaviour of the packet-switched traffic in a 4th generation (4G) long term evolution advanced, we consider all of our cells network as queues M/M/1 forming a network Kleinrock33. Remember, an M/M/1 queue is a queue with a Markov process input and output, a single server, a discipline of service first come, first served, an infinite capacity and an infinite number of customers which can enter the queued.
In this adaptation, the server is a cell with an infinite capacity that can take an infinite number of subscriber in its queue. The arrival process of the data packets in a cell is fish λi rate and the occupancy duration or time of service in the cell is distributed according to an exponential distribution with parameter μi (λi and μi is strictly positive). At steady state, we have: ![]()
The case generated tests assume that:
| • | The rate of data packets from a cell i with mean gamma distribution and variance equal to unity |
| • | Service time (residence time: for example, the talk time or download time of a file) data within cells are distributed according to an exponential law of parameter equal to unity |
| • | The succession rate among cells is assessed taking into account the adjacent cells, so if a cell j has k neighbour, [0,1] intervals is divided into k+1 intervals in choosing k uniformly distributed random number between 0 and 1 |
For a data packet which ends its service within a cell j, there may be two from:
| • | Let the data packet is transferred to the ith neighbouring cell (i = 1, 2, 3,…, k) rij with a transfer probability equal to the length of the ith interval |
| • | Let the data packet is interrupted with a probability equal to the length of the k+1th interval |
| • | αi arrival rates of data packets in the cells at equilibrium are obtained by solving the following system |
Where:
| n | = | The number of network cells and rij, the probability of handover between cells i and j |
| rij | = | Being the traffic data rate from cell i. |
Is selected as the data volume of an eNode B, the average length of its queue.
The handoff rate hij is defined by: hij = ti rij:
| • | All m SGW have the same capacity packet M0 calculated as follows for the purposes of the simulation: |
where, k is uniformly distributed between 10 and 50, which ensures an overall surplus of 10-50% of the capacity of SGW compared to the data volume of the cells.
Experimental design: Generation testing and execution environment: To verify the performance of our adaptation, a series of experiments is conducted. It has 5 sets of 5 data sets by considering a network 15, 30, 50, 80 and 100 cells. Thus covers a large number of test.
Material: The data necessary for the experiment are generated using a program MATLAB R2015b.The algorithms were implemented in C summers and tests were performed on a station with the following characteristics: Intel® Core™ i3-3110M, CPU@ 2.40 GHz, RAM: 8 Gb.
The following parameters are used for basic simulation:
| • | Population size: 100 |
| • | Number of generation: 90 |
| • | Crossover probability: 0.9 |
| • | Mutation probability: 0.07 |
RESULTS
Test No. 1: The genetic adaptation is performed depending on the setting set out above. The shape of the graph in Fig. 6 shows the variation of the optimum of 90 generations for a population of 100 chromosomes for a genetic process of an LTE-A network with15 cells and SGW 3. However, only the best results of 5 experiments was kept.
The process starts with a value of 704.60 U of the first generation. The best chromosome obtained in the first seven generations in an evaluation of 679 and 65 U, an improvement of 3.54% from the optimum value to the 1st generation.
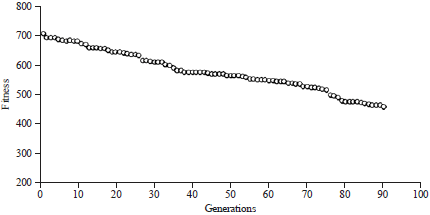 | |
| Fig. 6: | Evolution of the optimal value over generations |
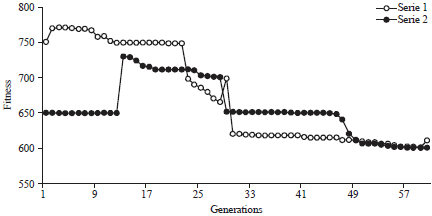 | |
| Fig. 7: | Behaviour of population of 15 chromosomes for 60 generation |
However, in the eighth generation, a degradation is observed in the solution compared to the best feasible chromosome obtained in the 7th generations with an increase of 0.23% for an evaluation of 681.24 U. From the 8th generation, there notice a significant improvement of 32.49% up to the 90th generation, an evaluation of 459.85. However, if improvement is noted with gaps very cut of 0.01% between 71th and 72th generations, between the 80th and 81th generations. Note that the model of assignment corresponding to feasible chromosome obtained in the 90th generations shows that all SGWs are used and interconnected cells, therefore the complex handover costs are practically negligible hence the value of 459.85 U compared to the chromosome obtained in the first generation and we then notice a significant improvement of 35%.
The deterioration observed in the genetic process can be explained by the fact that all the genetic operations are based on the uncontrollable factor of chance (creating the initial population and implementation of random genetic operators); indeed, wrong genetic combining or mutation can happen at any time in the genetic process.
To study the influence of the number of chromosome of the population on the quality of the solutions, five test series are performed for the populations of 15, 70, 100, 200 and 250 on chromosome 60 generations. Each experimental design was executed 3 times to better observe the behaviour of genetic adaptation.
Test No. 2: Study of the influence of the size of the population in the quality of solutions.
Analysis of the results confirms the hypothesis that a small population does not improve the value of the optimum. Indeed, there is a stagnation of the optimal solution because the same elements are found in every generation to undergo genetic processes. This is the case where the population size is equal to 15, especially when we have a large number of generation (Fig. 7).
However, from an increase in the size of the population provides heterogeneity specimens (chromosome) on the exploration space in each generation but does not necessarily ensure that the larger the size of the population is high more the optimal solution is improved.
For a population of size equal to 70 or 100 chromosomes, a response to diversity is observed in every generation but wrong combining occurs in the genetic process which deteriorates the optimal solution.
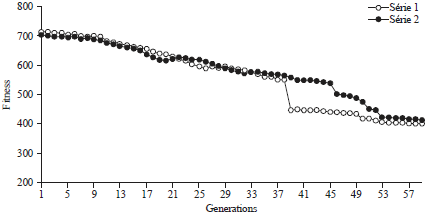 | |
| Fig. 8: | Behaviour of population of 250 chromosomes for 60 generations |
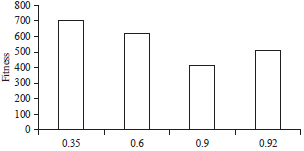 | |
| Fig. 9: | Effect crosses probabilities |
A degradation of the solution is observed for the population to 70 chromosomes to the 21th and 67th generations. Population equal to 100 specimens, this degradation is found between the 8th and the 10th generation as stated in the test No. 1. An explanation for this phenomenon can be found in the fact that the algorithm has no control over the initialization of the initial population. They are completely random and the only connection between them the first element that is common to them, too wrong combining can occur at any time throughout the process.
For populations where size increases in (200 and 250 chromosomes), a variety of specimens (chromosome) is observed on the research portion and the high number of generation provides the best solution for each genetic process (Fig. 8). Unfortunately, the random mode being responsible for genetic operations (crossover and mutation); there was the negative impact of these operations that degrades optimal solutions. However, a small population may lead so quickly to a good solution provided that the genetic operators are judiciously applied.
On the other hand, a large population with a small number of generation may also lead to a stagnation of the optimum value; Indeed, there will be a reduction in the difference of improvement between the optimal solutions.
In another vein, it was studied the impact of the probability associated with genetic operators (mutation and crossover) on the quality of the solution.
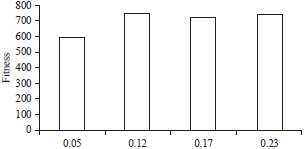 | |
| Fig. 10: | Effect of mutation probabilities |
To do this, we consider the parameters in Table 1 for the series of experience.
Test No. 3: Study of the influence of the different probabilities associated with genetic operators on the quality of the solution.
The first series of experiments was to vary the probability crossover to study its impact on the quality of the solution. Considered crossover probability values are: 0.35, 0.6, 0.9 and 0.95 the value of the probability of mutation remains the reference. Analysis of the results shows that the probability of the order of 90% generally provide good results; This confirms the theory of Darwin natural selection on which is based on our genetic adaptation34. Indeed, we must remember that we opt for a selection mode, which stipulates that only the best performance judged specimens are able to reproduce (Fig. 9). The second series of experiments was to vary the probability of mutation to study its impact on the quality of the solution. Mutation probability values considered are: 0.05, 0.1, 0.2 and 0.13 the value of the probability remains the crossover reference. A review of the results confirms that the 5% mutation probabilities generally provide the best results. This result is predictable because very little mutant specimen created accordingly the algorithm will tend to move to (Fig. 10).
DISCUSSION
In the literature, the researchers used several heuristic techniques to solve the cell assignment problem: taboo research7 the evolutionary approach11, the Lagrangian relaxation method10, simulated annealing35, the genetic algorithm36, a hybridizing heuristic approach based on iterative local reearch12.
In another allegory, to assess its performance, genetic adaptation solutions are compared with those simulated annealing. Given the limitation of hardware problems and computing time, the tests focused on the following configurations: (eNode B; SGW) = {(95; 5), (150; 6), (200; 7) and (300; 9)} in addition to those in Table 1.
Observing the results in Fig. 11 show that the genetic algorithm allows to have the best results for configurations up to 95 eNode B. With 100 eNode B, a slight degradation of the more or less acceptable compared to the solution of simulated annealing is observed. But beyond eNode B 100, the best solutions are for the benefit of the simulated annealing.
These same findings were observed in the research results obtained8,11,36 in favour of simulated annealing, when the researchers make a comparative study between these two heuristics. However, Salcedo-Sanz and Yao36, a genetic algorithm hybridized called hybrid II provides better solution irrespective ofthe configuration relative to the genetic algorithm, the same for an evolutionary approach based on Ford-Fulkerson developed by Le et al.11.
| Table 1: | Test runs composition |
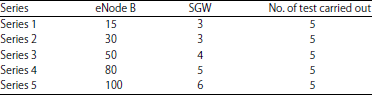 | |
However, Dac-Nhuong8 and Pierre and Legault37, the adopted genetic approach permits to achieve the best results compared to simulated annealing by taking into account small, medium and large size networks to solve the cell allocation problem. These results seem to derive from a careful selection from the initial population.
On the other hand, collate experience between three heuristic approaches: The tabu research, simulated annealing and genetic algorithm in a cell assignment by Pierre et al.38 show that the taboo research the best cost irrespective of configurations for each heuristics. However, a study of the interaction between these three approaches shows that a large number generation (500 or 800) allows the genetic algorithm to provide good solution including improvements generated by simulated annealing or taboo research is not significant. Parameters used are: Genetic algorithm: Crossover rate = 0.9, mutation rate = 0.08, population size = 100 chromosomes and simulated annealing: Annealing factor = 0.7. However, there is a growth of the execution time when the number of generation becomes increasingly big with the genetic approach. Which allows to study the effect of the execution time on the quality of solutions.
Indeed, we should not neglect the importance of runtime because we solve a planning problem, a fundamental step before the deployment and implementation of a network service. So we imagine that with the current level of technological development and the power of performance workstations today, designers have to offer optimized models that offer the possibility of rapid deployment to telephone operatorswhich allow them to save money (gain, day, time, …) to provide faster services to users.
Thus, several research papers have studied the influence of the execution time of various heuristic methods on the quality of the solution7,10,31,37,38. The overall result, the runtime increases in these heuristics, when passing from a small size network to a large size network.
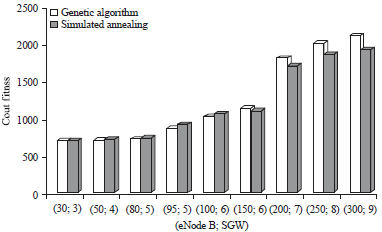 | |
| Fig. 11: | Cost comparison obtained between genetic algorithm and simulated annealing |
Goldberg29, the genetic approach proposed to solve a global problem of planning shows that the running time to a linear growth when the size of the population and the number generation increases. This study confirms this assertion; it is the same for the proposed research study by Pierre et al.38. But a careful choice of parameters allows to reach a good compromise in an acceptable time.
Finally, a comparison the genetic approach to an exact method of ILP classic shows that both methods provide good solution for configurations where the number of eNode B is less than 35 with a linear growth of the computation time for both approaches.
For a higher number of 35 eNode B, all calculation data exceeds the available memory, the computation time becomes excessive and not applicable to obtain an optimal solution with the exact method. This leads to a combinatory explosion of computation time. A research article12 confirms this study. Indeed, tests show that for a number of cells less than 30, adopted heuristic approach and the exact programming method produce good results by providing feasible solutions to a number of constant or variable switch (between 2 and 6). But for more than 30 cells, the exact resolution method does not product solution because of the exponential growth of computation time.
In light of the above, we could thus conclude that genetic algorithm manipulates the coding of all genetic parameters rather than the parameters themselves because an appropriate choice of parameters provides very fast good feasible solution in an acceptable computation time.
CONCLUSION
The study described in this study have allowed to propose an optimization model to solve the problem of cell assignment to switches LTE advanced network considering two equipment levels for two assignments under the sub network E-UTRAN access. Given the complexity of the model, a proposed genetic approach provides an optimal solution after a number of generations, every time a degradation of the solution may occur at any time due to the process of unfortunate crossover explained by the uncontrollable factor random genetic operations. A large population is a guarantee of a good diversity of chromosome however but does not necessarily lead to an optimal solution. In fact, a good choice of genetic parameters will get good solution to any generation. Also, it is important to note that our cells assignment model ignores the interfaces defined in the architecture of control plan of an LTE advanced network. This is a prospective point that could fit into this model to provide a complete cell allocation model.
ACKNOWLEDGMENTS
This study was supported by the Laboratoire de Recherche en Informatique et Télécommunications of the Institut National Polytechnique Houphouët-Boigny (INPHB, Abidjan-Cocody Danga) and the Direction de Recherche et de l’Innovation technologique of the Ecole Supérieure Africaine des TICs (ESATIC, Abidjan-Treichville, Zone 3, km 4). The authors wish to acknowledge these two institutions or their valuable support.
REFERENCES
- Martin-Sacristan, D., J.F. Monserrat, J. Cabrejas-Penuelas, D. Calabuig, S. Garrigas and N. Cardona, 2009. On the way towards fourth-generation mobile: 3GPP LTE and LTE-advanced. EURASIP J. Wireless Commun. Networking.
CrossRefDirect Link - Diallo, M.M., S. Pierre and R. Beaubrun, 2010. A tabu search approach for assigning node BS to switches in UMTS networks. IEEE Trans. Wireless Commun., 9: 1350-1359.
CrossRefDirect Link - Dac-Nhuong, L., 2013. GA and ACO algorithms applied to optimizing location of controllers in wireless networks. Int. J. Electr. Comput. Eng., 3: 221-229.
Direct Link - Anu, 2014. An overview of memetic approach to design problems of wireless networks. Int. J. Adv. Res. Comput. Sci. Software Eng., 4: 902-905.
Direct Link - Hong, J.M. and J.H. Lee, 2011. Designing cellular mobile network using lagrangian based heuristic. J. Korean Inst. Ind. Eng., 37: 19-29.
CrossRefDirect Link - Rajalakshmi, K., P. Kumar and H.M. Bindu, 2010. Hybridizing iterative local search algorithm for assigning cells to switch in cellular mobile network. Int. J. Soft Comput., 5: 7-12.
CrossRefDirect Link - Ibrahim, K.M., M. Hano, G. George, M. Fawzy and G. Nagib, 2014. LTE dimensioning tool using C#. Proceedings of the 9th International Conference on Computer Engineering and Systems, December 22-23, 2014, Cairo, Egypt, pp: 324-329.
CrossRef - Li, X., U. Toseef, D. Dulas, W. Bigos, C. Gorg, A. Timm-Giel and A. Klug, 2013. Dimensioning of the LTE access network. Telecommun. Syst., 52: 2637-2654.
CrossRefDirect Link - Azzam, S.M. and T. Elshabrawy, 2015. Re-dimensioning number of active eNodeBs for green LTE networks using genetic algorithms. Proceedings of the 21th European Wireless Conference, May 20-22, 2015, Budapest, Hungary, pp: 1-6.
Direct Link - Dababneh, D., M. St-Hilaire and C. Makaya, 2015. Data and control plane traffic modelling for LTE networks. Mobile Networks Applic., 20: 449-458.
CrossRefDirect Link - Jaber, M., Z. Dawy, N. Akl and E. Yaacoub, 2016. Tutorial on LTE/LTE: A cellular network dimensioning using iterative statistical analysis. IEEE Communi. Surveys Tutorials, 18: 1355-1383.
CrossRefDirect Link - Merchant, A. and B. Sengupta, 1994. Multiway graph partitioning with applications to PCS networks. Proceedings of the 13th IEEE Networking for Global Communications Conference, June 12-16, 1994, Toronto, Canada, pp: 593-600.
CrossRefDirect Link - Merchant, A. and B. Sengupta, 1995. Assignment of cells to switches in PCS networks. IEEE/ACM Trans. Networking, 3: 521-526.
Direct Link - Skorin-Kapov, J., 1990. Tabu search applied to the quadratic assignment problem. ORSA J. Comput., 2: 33-45.
CrossRefDirect Link - Klincewicz, J.G., 1991. Heuristics for the p-hub location problem. Eur. J. Operat. Res., 53: 25-37.
CrossRefDirect Link - Sanchis, L.A., 1989. Multiple-way network partitioning. IEEE Trans. Comput., 38: 62-81.
CrossRefDirect Link - Kernighan, B.W. and S. Lin, 1970. An efficient heuristic procedure for partitioning graphs. Bell Labs Tech. J., 49: 291-307.
CrossRefDirect Link - Bertrand, B.A.P., D. Moustapha, S. Etienne, O. Souleymane and A.B. Matthieu, 2016. A genetic algorithm for overall designing and planning of a long term evolution advanced network. Am. J. Operat. Res., 6: 355-370.
Direct Link - Menon, S. and R. Gupta, 2004. Assigning cells to switches in cellular networks by incorporating a pricing mechanism into simulated annealing. IEEE Trans. Syst. Man Cybern. Part B: Cybern., 34: 558-565.
CrossRefDirect Link - Salcedo-Sanz, S. and X. Yao, 2008. Assignment of cells to switches in a cellular mobile network using a hybrid Hopfield network-genetic algorithm approach. Applied Soft Comput., 8: 216-224.
CrossRefDirect Link - Pierre, S. and G. Legault, 1996. A heuristic method for designing computer network topologies. Ann. Telecommun., 51: 143-157.
Direct Link - Pierre, S., A. Quintero and A. de Montgolfier, 2004. Approches heuristiques pour l'affectation de cellules aux commutateurs dans les reseaux mobiles. IEEE Can. Rev., 46: 9-14.
Direct Link