
Zahraddeen Sufyanu
Faculty of Informatics and Computing, Universiti Sultan Zainal Abidin (UniSZA), Gong Badak Campus, 21300, Terengganu, Malaysia
Fatma Susilawati Mohamad
Faculty of Informatics and Computing, Universiti Sultan Zainal Abidin (UniSZA), Gong Badak Campus, 21300, Terengganu, Malaysia
Abdulganiyu Abdu Yusuf
Faculty of Informatics and Computing, Universiti Sultan Zainal Abidin (UniSZA), Gong Badak Campus, 21300, Terengganu, Malaysia
Bashir Muhammad
Department of Electrical Engineering, Faculty of Engi
neering, Kaho University of Science and Technology,
Wudil, 3244, Kano, Nigeria
Journal of Applied Sciences
Year: 2015 | Volume: 15 | Issue: 6 | Page No.: 903-910







ABSTRACT
Hough Transform (HT) is one of the useful algorithms in pattern recognition. It is popularly used to detect straight lines, circles and curves in images. This study discovered a new feature detection and extraction using the HT. The intensity of the input image was enhanced and histogram plot of the stretched image was obtained. However, HT functions perform transformation of Hough matrix, locate peak values and superimpose a plot on the features representing the original image. Hence, face features were detected and the extracted features proceeded for verification. Cross Correlation Technique (CCT) and Euclidean Distance (ED) were computed to determine the similarity between test images and neutral image. The experiment on FEI face database demonstrated the effectiveness of the new technique and obtained recognition with minimal error. Furthermore, the application of HT was improved and the benefits of the proposed algorithm were verified. It is believed that, the discovery is new in the domain.
PDF Abstract XML References Citation
Received: February 02, 2015;
Accepted: April 25, 2015;
Published: May 23, 2015
How to cite this article
Zahraddeen Sufyanu, Fatma Susilawati Mohamad, Abdulganiyu Abdu Yusuf and Bashir Muhammad, 2015. A New Hough Transform on Face Detection and Recognition Using Integrated Histograms. Journal of Applied Sciences, 15: 903-910.
DOI: 10.3923/jas.2015.903.910
URL: https://scialert.net/abstract/?doi=jas.2015.903.910
DOI: 10.3923/jas.2015.903.910
URL: https://scialert.net/abstract/?doi=jas.2015.903.910
INTRODUCTION
Biometrics is essentially a pattern recognition system (Ghandehari and Safabakhsh, 2011) which uses physiological and behavioral characteristics of a person (Bhattacharyya et al., 2009), such as fingerprint, iris, face, voice and signature. Face detection and recognition has become a major research interest in biometric system for the past few decades, employing existing and new developed algorithms to mimic human recognition ability.
Face detection is the first stage in an automatic face recognition system; the process aims to separate a face in an image from its background, since the exact positions and size of face has to be located in the input image before it is verified. Firstly, the whole image is examined to find regions that are identified as face. After estimating the rough position and size of the face, a localization procedure which provides a more accurate estimation of the exact position and scale of the face is carried out. Face detection becomes a challenging task in computer vision, since face varies from one person to another due to race, gender, age and other physical characteristics of an individual. It also varies in scale, orientation, pose, facial expressions and lighting conditions. Thus, it becomes more challenging and many methods have been proposed to detect the faces.
Hough Transform (HT) is one of the feature extraction techniques used in image analysis, computer vision and digital image processing (Shapiro and Stockman, 2001). It was patented by Hart (2009) in 1962 and assigned to the U.S. Atomic Energy Commission with the name “Method and means for recognizing complex patterns”. The HT universally applied today was invented by Duda and Hart (1972) and called it “Generalized Hough Transform (GHT)”. The transform was popularized in the computer vision community by Ballard (1981), through a journal article titled “Generalizing the Hough transform to detect arbitrary shapes” most commonly circles or ellipses. The use of the transform to detect straight lines in digital images is probably one of the most widely used procedures in computer vision (Duda and Hart, 1973; Bradski and Kaehler, 2008; Davies, 2005). Besides, some of the important applications of this transform are: Detection of muon tracks in the hadron collider (Amran, 2008) and lane mark recognition system to detect when a vehicle is departing from a lane (Mineta et al., 2000). Therefore, several researches were conducted on biometrics using this transform and it has been an efficient method to date. The research conducted by Porwik (2007) used HT for feature extraction in signature recognition, using algorithm that identified a set of straight lines appeared in analyzed signature and extracted the most likely lines representing the unique feature of the signature.
However, the GHT proposed by Bevilacqua et al. (2008) used HT to detect nose tips of three dimensional (3D) faces with different poses and beam spheres as pattern. The mean value of face vertices was calculated with the purpose of obtaining information about face orientation in the 3D space and searched for the closest face vertex to the nose-tip previously extracted. The vertex represented the real nose-tip. In applying HT to detect circular objects, the presence of circular shapes (coconut as case study) was detected by Rizon et al. (2005).
Another algorithm adopted in iris segmentation was introduced by Tian et al. (2004), trying to locate the centre and boundary of pupil with high precision. Relatedly, a ridge-based technique for fingerprint matching proposed by Marana and Jain (2005) used HT for extraction of fingerprint ridges by applying two masks that adaptively captured the maximum gray level values along the direction perpendicular to the ridge orientation. In addition, other experimental works are proposed by Kapadia and Patel (2013) on barcode scanning and Verma et al. (2012), Liu-Jimenez et al. (2011) and Mabrukar et al. (2013) on iris. All these researches and many more in the literature that used HT were reported on detecting lines, signature, fingertip positions, nose tips and iris. To the best of the authors’ knowledge, the HT has never been applied to extract a whole face region.
Detecting algorithms can be achieved through scanning the original image by positioning the so called rectangular sliding window and determining the region of face and non-face. Tremendous amount of work was implemented in the literature attempting to improve these algorithms, for complexity reduction (Yi et al., 2010), constitutes using Viola-jones algorithm, Haar cascade and other combination of weak classifiers such as AdaBoost, require more training time in practical applications (Haider et al., 2014). In addition to that, none of the detection technique proceeds for recognition simultaneously, another algorithm has to be exploited for feature extraction. The major drawback of all these approaches is their high degree of complexity, since face contains a lot of parameters that have to be estimated. To address this issue, the shape of the face histogram was used to design a simple but effective technique that enables detection and recognition of face feature simultaneously.
In this study, a new framework for automatic face detection and recognition using HT and histograms is discovered. The research uses Hough lines function to detect the features representing face images and match the extracted features to verify an individual. This is another benefit that promotes the use of HT in biometrics and the approach proposed an alternative way of extracting features of images that cannot be represented into a set of parameters, this is the significance of the discovery. The proposed idea can be applied to easily detect numerous features and classify them according to their pattern.
MATERIALS AND METHODS
Theory of the new scheme: The effects of histograms in relation to contrast stretching and basic concept behind lines detection using HT are discussed here.
Histograms: Image histogram is a plot of the relative frequency of occurrence of each permitted pixel values in an image against the values themselves. It shows information of an image using its contrast and reveals any potential difference in color distribution of the image foreground and background scene components (Solomon and Breckon, 2011). The histogram plot transforms total pixel of images (Mohamad et al., 2010) and it is always a solution for comparison of colors. The histogram plots of the same image with different sizes show resemblance in the pixel distributions. The higher the dimension of an image, the larger the pixel distribution is. This implies that the type of geometry or outline of any histogram depends on the total information in an image. However, illumination variations in images can be easily observed from their equivalent histograms. Although poor illuminated image might not affect the final classification or verification output. This is because, many techniques such as Histogram Equalization can be used to stretch the range of pixel intensities of the input image to occupy a larger dynamic range in the output image (Solomon and Breckon, 2011). In addition, taking a histogram plot on a rotated image lowers the heights of the bins and reduces display time of the plot.
Pixel distributions modeling: Histogram is a graphical display of tabulated frequencies shown as adjacent bars (Howitt and Cramer, 2008). It represents a contrast of an image and the contrast occupies a very small region in a space. Stretching the contrast often called normalization increases this region by creating a wider range of visualizing a histogram plot of the image which results in distribution of the histogram. Thus, widens the width of the pixel and area under the counterpart bars remains the same. Therefore, both the histograms before and after the distributions can be model using impulse function.
Figure 1 shows the behavior of a scaled rectangle function, where the histogram of an image before and after the contrast stretching can be represented separately. As ‘a’ is compressed, ‘b’ tends to a vanishingly smaller region. Meanwhile, the height (1/b) increases. Consider rectangles of widths ‘a’and ‘b’.
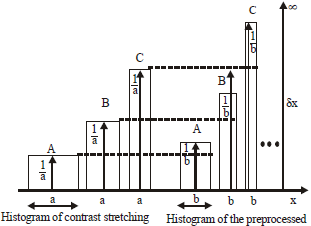 | |
| Fig. 1: | A scaled rectangle using impulse function to represent the behavior of histograms |
The 1-D rectangle function is defined as:
The impulse function can be defined as:
| (1) |
| (2) |
| (3) |
where, Eq. 1 and 2 represent 1-dimensional and 2-dimensional delta functions respectively, Eq. 3 defines a function which is zero everywhere except at x = 0 precisely. At this point, the function tends to a value of infinity but remains a finite (unit area) under the function. Therefore, the areas under both rectangles ‘a and b’ remain the same despite the height variations.
Detecting lines using the Hough transform: The earlier classical Hough for detecting straight lines can be described in Eq. 4 (equation of straight line). Where x, y are the image points, m and c are slope and intercept respectively which can represent the straight line in the parameter space. As the line approaches horizontal position, both the intercept and the slope tend to zero. On the other hand, if the line approaches vertical position, both the slope and the intercept tend to infinity. These instances lead to an unbalanced transform space. For this reason, image must be inclined to certain degrees before the lines are detected properly.
Therefore, polar coordinates ‘r’ and θ (theta) are used to represent the lines in the HT. Figure 2 shows the main idea in the HT, where ‘r’ represents the distance from ‘P’ to origin, θ represents the vector angle produced by ‘r’ from the base (x) axis. Equation 4 can be written in the form of Eq. 5 and rearranged to form Eq. 6.
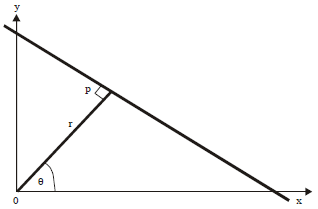 | |
| Fig. 2: | Line and polar coordinates representation |
For an arbitrary point on the image plane with coordinates, for example (x1, y2), the lines that get through it are represented in Eq. 7, this corresponds to a sinusoidal curve in the r, θ plane, which is unique to that point.
The edge detection particularly using canny is applied on the original image before computing the HT. The Hough function computes the Standard Hough Transform (SHT) of the binary image using the parametric representation of a line. The result of the HT is stored in a matrix often called an accumulator. After computing the HT, the Hough peaks function finds the peak values in the parameter space. The peaks represent the most likely lines in the input image and identified by superimposing a plot on the image of the transform. The Hough lines function finds the endpoints of the line segments equivalent to peaks in the HT by automatically filling in small gaps in the line segments and can be extracted by looking for local maxima in the accumulator space. Therefore, finding the appropriate peaks signifies the appropriate lines:
| (4) |
| (5) |
| (6) |
| (7) |
The experiment was conducted using FEI face database. This is a Brazilian face database that contains a set of face images taken between June 2005 and March 2006. There are 200 individuals, each with 14 images. All images are colorful and taken against a white homogeneous background in an upright frontal position with profile rotation of up to 180°. The original size of each image is 640×480 pixels. Figure 3 shows some of the variations from the FEI face database.
The performance of the new algorithm was studied on 20 subjects (280 images). The neutral images were used for training and the remaining 13 were used for verification. The number of male and female subjects considered is exactly the same.
 | |
| Fig. 3: | Sample of images variations from FEI face database |
 | |
| Fig. 4: | Neutral images extracted from FEI face database |
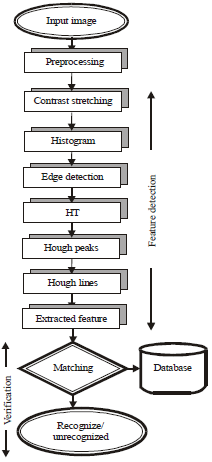 | |
| Fig. 5: | Flowchart of the new algorithm |
Figure 4 depicts some of the training images used in of different subjects and for the purpose of experiment, MAT LAB software was used on PC Intel core of 2.10 GHz, 3.00 GB DDR3 Memory.
The proposed scheme consists of two phases. In the first phase, the input images were taken into the system, each image was converted to gray-scale and cropped to a dimension of 215×250 to capture the whole face region. Then the noise was removed using median filter. However, the range of pixel intensities of the preprocessed image was stretched (i.e., contrast stretching) and equivalent histogram with distributed bins was obtained using histogram plot function. This represents the original image (face) that is easier to extract the features and minimizes error during matching. The histogram plot was rotated by 30° to reduce the dimension of the images and prevent a distorted transform. In addition, canny detector was used to detect the edges of the rotated histograms. Finally, the appropriate feature representing the face was detected using the idea of detecting lines and extracted using HT algorithm’s functions.
In the second phase of the system, the extracted feature of the test images were matched with that of the training using CCT and ED. Therefore, the similarities of the test images against the neutral image were found and evaluated. Figure 5 shows the flowchart of the new system.
RESULTS AND DISCUSSION
Phase I (Detection): Figure 6 illustrates one of the results of the experiment during enrollment of the 20 neutral faces.
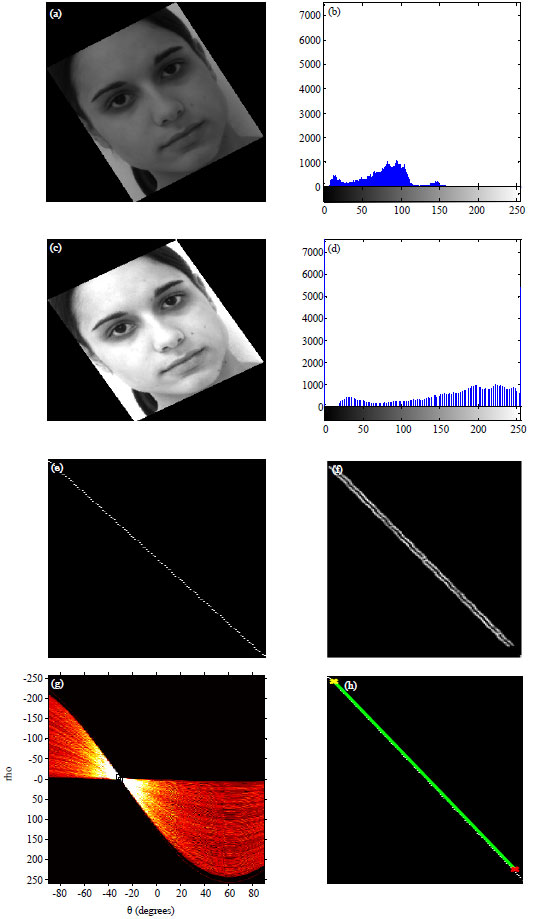 | |
| Fig. 6(a-h): | Result extracted from the experiment, phase 1, (a) Preprocessed images, (b) Histogram of preprocessed images, (c) Contrast stretching, (d) Histogram of contrast stretching (e) Rotated histogram by 30°, (f) Canny detected image, (g) Plot of Hough matrix and (h) Plot of Hough lines |
| Table 1: | Best matching results from 20 individuals |
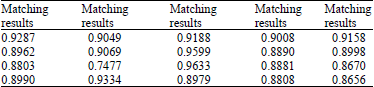 | |
| Table 2: | Average results obtained from 20 subjects |
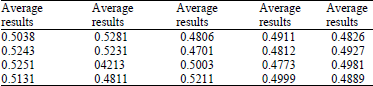 | |
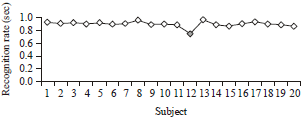 | |
| Fig. 7: | Comparison of highest correlation values from 20 subjects (260 test images) |
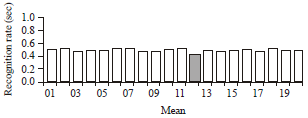 | |
| Fig. 8: | Graph representing average correlation of 20 subjects (260 test images) |
When images ‘a’ and ‘b’ show the results of the preprocessed image and its histogram, respectively. Image ‘c’ is the result of contrast stretching, using stretchlim function at 0.05 and 0.95 (minimum and maximum) pixel points of the normalized histogram image. The corresponding histogram of the contrast stretching is depicted in ‘d’. In addition, image ‘e’ shows the rotated histogram by 30°, ‘f’ is the detected image using the Canny method, while ‘g’ and ‘h’ represent the plots of Hough matrix and Hough lines, respectively.
Phase II (Matching): Table 1 illustrates the highest correlation results selected from individual subject (13 test images) after the matching using CCT. These results signify the image that is most similar to the neutral image in the database. The highest and lowest values obtained are 0.9633 and 0.7477 as indicated in the table representing subjects ‘13’ and ‘12’ respectively. Figure 7 demonstrates the performance variations of the highest correlation results depicted in Table 1. Table 2 represents the average results obtained from the 20 subjects and the graph equivalent to this table is shown in Fig. 8. These results were calculated to determine the expected correlation values using this algorithm. It is clear that subject ‘12’ also has the least average value in Table 2.
| Table 3: | Three individual results of Euclidean distance |
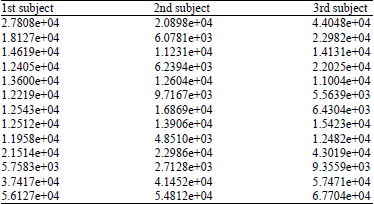 | |
To fully observe and ascertain the behavior of the new framework, the same test images were matched against the neutral image using ED. Table 3 indicates three of the results obtained using this matching technique, where few samples from the three subjects generated closer distances to their corresponding neutral images. The graph showing these results is shown in Fig. 9. The last samples with lowest illuminations got the highest distances as reported and indicated in the Table 3.
Additionally, to determine the expected distance value in each subject, mean values were calculated and the graph is shown in Fig. 10. Comparably, the subject ‘12’ that reported the least performance using CCT, now acquired the highest distance as shown in Fig. 10, proving the new algorithm as realizable.
The initial rotation of the input image as shown in Fig. 6 ‘a’, lowered the histogram bins as shown in ‘b’ and reduced the overall detection time by 124 msec. The histogram plot is affected by poor illuminated images and increases similarity distance as reported under samples ‘13’ in Table 3. Thus, taking contrast stretching of the image in ‘c’, it enhances the illumination of the images and produced a distributed histogram in ‘d’. The second rotation of the histogram as shown in ‘e’ is the critical stage where dimension is highly reduced and new features are generated. However, the binary image shown in ‘f’ is the result of canny edge detection which is necessary before applying the HT functions to obtain Hough matrix in ‘g’ and find appropriate peaks. Hence, by superimposing a plot on the feature representing the original image, the reduced face feature was detected as depicted in ‘h’. Generally, after the dimension reduction through the histograms, the rotation estimates the most important feature and the algorithm examined this feature to find the size and exact position or regions representing the face.
During the evaluation of the results, it was discovered that upon all the histogram visually inspected, none of them contains similar bins orientation at the same pixel positions. This denotes that equivalent histogram of an image retains the uniqueness of the information in that image.
During the matching using CCT the occurrence of frequent mean values within the range of 0.4701-0.5281 was observed. The calculated mean values decrease the errors that might be encountered in the course of acquiring the results.
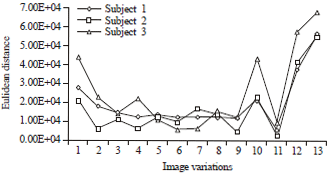 | |
| Fig. 9: | Comparison of Euclidean distance from neutral images |
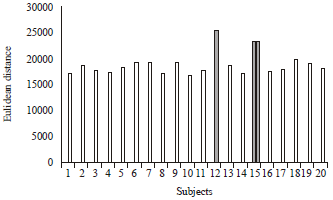 | |
| Fig. 10: | Average Euclidean distance for 20 subjects (260 test images) |
While taking the mean ED in Fig. 10, the occurrence of frequent values below 2e+04 was observed, this should be considered as a threshold value for correct acceptance. Although subject ‘15’ is outside the effective range of the mean ED but is within the acceptable range of the mean correlation.
We should point out some of the perhaps undesirable properties that were not anticipated. The least performance in subject ‘12’ with smallest correlation value of 0.7477 and mean amount to 0.4213 certainly constituted error according to the behavior of the algorithm in this study. But we cannot account for the cause. The justification achieved by this method proved the applicability of HT on face detection and the results were encouraging. Hence, the present study proposed a new framework that extend the use of HT in image processing using relatively simple approach to produced a hybrid system that detect meanwhile proceeds for recognition using the extracted features. Unlike barcode scanning by Kapadia and Patel (2013), where its application focused on items and prices reading. This study leads to identification of faces using the integrated histograms and is a novel detection method that shows no rectangular window on the original image. Surely to design automatic systems user friendly, the registration of a client should not take much time, this leads to implementation of the new framework. The system surpassed the state of the art approaches in terms of quick detection. The similarity measure using correlation is employed for the template matching which is the simplest approach to pattern recognition. In this approach, the query patterns are matched against the stored templates while rotation and translation are taken into account. Although template matching is a simple learning algorithm but the correlation is feature size dependent and often fails if the image illumination conditions vary with position. In addition it is slower than the Euclidean distance. This is the major limitation of this framework. Even though the dynamic range of the images were increased but similarity distance is high especially in the last samples with poorest illumination. It is therefore necessary to set all the images in to equal illumination for correct classification. We believe, the study can be improved and thereby implemented on other biometric features.
CONCLUSION
The use of HT and histograms on face detection and recognition was achieved with minimal error. The study advances the research in this field by converting the original image (of face) into integrated histogram before applying the HT. This research introduces an alternative means of detecting and recognizing faces using single algorithm. The new discovery aimed at making HT work in diversified areas and minimizing complexity of hybrid systems in integrated models. Finally, the subsequent study will verify some of the insignificant behaviors encountered in this study using many subjects and different matching techniques. We hope to see how HT can be applied on other biometric features such as palmprint and fingerprint.
ACKNOWLEDGMENT
We appreciate the efforts of Universiti Sultan Zainal Abidin (UniSZA) Malaysia, for supporting this work academically and extend our gratitude to Kano State Government, Nigeria for financing the work.
REFERENCES
- Marana, A.N. and A.K. Jain, 2005. Ridge-based fingerprint matching using Hough transform. Proceedings of the 18th Brazilian Symposium on Computer Graphics and Image Processing, October 9-12, 2005, USA., pp: 112-119.
CrossRef - Ghandehari, A. and R. Safabakhsh, 2011. A comparison of principal component analysis and adaptive principal component extraction for palmprint recognition. Proceedings of the International Conference on Hand-Based Biometrics, November 17-18, 2011, Hong Kong, pp: 1-6.
CrossRef - Bhattacharyya, D., R. Ranjan, F. Alisherov and M. Choi, 2009. Biometric authentication: A review. Int. J. U E Serv. Sci. Technol., 2: 13-28.
Direct Link - Duda, R.O. and P.E. Hart, 1972. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM, 15: 11-15.
CrossRef - Kapadia, H. and A. Patel, 2013. Application of Hough transform and sub-pixel edge detection in 1-D barcode scanning. Int. J. Adv. Res. Electr. Electr. Instrum. Eng., 2: 2173-2184.
Direct Link - Liu-Jimenez, J., R. Sanchez-Reillo and B. Fernandez-Saavedra, 2011. Iris biometrics for embedded systems. IEEE Trans. Large Scale Integration (VLSI) Syst., 19: 274-282.
CrossRef - Mohamad, F.S., A.A. Manaf and S. Chuprat, 2010. Histogram matching for color detection: A preliminary study. Proceedings of the International Symposium in Information Technology, Volume 3, June 15-17, 2010, Kuala Lumpur, pp: 1679-1684.
CrossRef - Rizon, M., H. Yazid, P. Saad, A.Y.M. Shakaff and A.R. Saad et al., 2005. Object detection using circular hough transform. Am. J. Applied Sci., 2: 1606-1609.
CrossRefDirect Link - Hart, P.E., 2009. How the Hough transform was invented [DSP History]. Signal Process. Mag., 26: 18-22.
CrossRef - Porwik, P., 2007. The compact three stages method of the signature recognition. Proceedings of the 6th International Conference on Computer Information Systems and Industrial Management Applications, June 28-30, 2007, Minneapolis, MN., pp: 282-287.
CrossRef - Verma, P., M. Dubey, S. Basu and P. Verma, 2012. Hough transform method for iris recognition: A biometric approach. Int. J. Eng. Inn. Technol., 1: 43-48.
Direct Link - Mabrukar, S.S., N.S. Sonawane and J.A. Bagban, 2013. Biometric system using Iris pattern recognition. Int. J. Innovat. Technol. Exploring Eng., 2: 54-57.
Direct Link - Bevilacqua, V., P. Casorio and G. Mastronardi, 2008. Extending Hough Transform to a Points' Cloud for 3d-Face Nose-Tip Detection. In: Advanced Intelligent Computing Theories and Applications. With Aspects of Artificial Intelligence, Huang, D.S., D.C. Wunsch, D.S. Levine and K.H. Jo (Eds.). Springer, New York, pp: 1200-1209.
- Haider, W., H. Bashir, A. Sharif, I. Sharif and A. Wahab, 2014. A survey on face detection and recognition approaches. Res. J. Rec. Sci., 3: 56-62.
Direct Link - Ballard, D.H., 1981. Generalizing the hough transform to detect arbitrary shapes. Patt. Recog., 13: 111-122.
CrossRef