
Mei Zhang
Library, Linyi University, Linyi, 276000, Shandong, China
Journal of Applied Sciences
Year: 2014 | Volume: 14 | Issue: 9 | Page No.: 892-900







ABSTRACT
With the rapid development of multimedia and network technologies, the image became an important source of obtaining information and it was a hot research topic how to retrieve the wanted information from many pictures. In order to effectively retrieve the image information, the image retrieval system based on digital watermarking technology was designed and implemented. Two commonly used image retrieval methods were introduced, including text-based image retrieval and content-based image retrieval and their advantages and disadvantages were analyzed. The characteristics, basic principles and typical algorithms of digital watermark were briefly discussed. On the basis of them, the watermarking algorithms based on discrete cosine transform were focused on. The processes of watermark embedding, extracting were emphatically analyzed and their processes were given. The image matching was implemented to retrieve the desired image based on normalized cross correlation method. The experimental simulation results showed that the watermark had good invisibility and the system quickly realized watermark embedding, extracting and matching which had certain theoretical and practical values.
PDF Abstract XML References Citation
Received: October 10, 2013;
Accepted: January 10, 2014;
Published: March 22, 2014
How to cite this article
Mei Zhang, 2014. Study on Image Retrieval Technology Based on Digital Watermark. Journal of Applied Sciences, 14: 892-900.
DOI: 10.3923/jas.2014.892.900
URL: https://scialert.net/abstract/?doi=jas.2014.892.900
DOI: 10.3923/jas.2014.892.900
URL: https://scialert.net/abstract/?doi=jas.2014.892.900
INTRODUCTION
With the rapid development of the technologies of network and multimedia, the emergence and wide application of high-capacity storage devices and digital equipment, the data of image and video has been growing exponentially in recent years. The multimedia information exchange becomes more and more convenient, of which the digital image becomes an important way. At the same time, the infringement on multimedia works is also easier than before and there is more and more illegal copy and distort which greatly damages the interests of authors and copyright holders. It has become an urgent problem how to effectively prevent data from being illegally copied and identify the intellectual property rights of multimedia products (Wang, 2006a). The digital watermarking technology emerges in this context which plays an important role in information security and copyright protection.
In order to protect the complex images and make the information be accessed and used effectively in network, it is inevitable to use quick and accurate technology of finding and accessing images, namely image retrieval technology. Image retrieval is a major component of multimedia information retrieval technologies and it has a pivotal position in the field of information retrieval. Image retrieval is to extract and query an associated image and image collection from image database according to the queries users submit (Zhang, 2008).
After decades of research, a variety of image retrieval technologies had been developed. In general, the existing retrieval methods of multimedia information are mainly divided into two categories, text-based information retrieval and content-based information retrieval, TBIR and CBIR for short (Zhang and Xu, 2011).
TBIR can build the index information through describing the characteristics of image. Alternatively, some additional descriptive information can be used as the index to establish the index database of image files. In this way, the link of storage path and key words of image can be established and the image itself can still be stored in the external way. The retrieval of image file is generally carried out by the way of classification browsing and keyword questioning and the querying operation is essentially the exact match or probability match according to the text description (Haimiti and Haimiti, 2012). Although some retrieval model can be supported by the dictionary, they only retrieve the artificial description information of image file which are not relevant to the image file itself.
The text-based image retrieval technology has some limitations as follows (Wang and Hu, 2005), it is difficult to fully express the richness of image, has different understanding of image, indexing obstacle in different languages and is not fit for mass information and so on.
CBIR is defined that the software automatically analyzes the image to extract the content characteristics of the image. The characteristics include color, shape and texture and the combination of these features which can be stored into the image feature database as the feature vectors. During the process of image retrieval, it analyzes the image to extract image feature vector for a given image, calculates the similarity of vectors between the querying image and the image from feature library using similarity matching algorithm. Lastly, the retrieval result can be output according to the similarity degree.
The core of CBIR method is to retrieve the image using visual features. Essentially, it is an approximate matching technology and integrates technological achievement in many fields including computer vision, image processing, image understanding and databases. The feature extraction and index building can be realized automatically by the computer, so it avoids the subjectivity of artificial description (Xu et al., 2008).
The implementation of this method relies on two key technologies, extracting and matching of image features. This method also has some defects (Zhang, 2011), including subjectivity and differences of class perception, disjoint between low-level visual features and high-level semantics, diversity of similarity measurement and so on.
This study builds an image retrieval research system based on digital watermarking and analyzes the methods of digital watermark embedding and extracting using DCT transform. The methods can effectively realize the digital image retrieval and they have good practical value and application prospects.
BASIC FRAMEWORK OF DIGITAL WATERMARKING TECHNOLOGY
With the further development of network, the interconnection of systems becomes very easy which greatly facilitates the information exchange and resource sharing. The rapid information dissemination and easy operation change the traditional work and life way but it also brings many negative effects, such as copyright infringement, information tampering which can produce great difficulties and challenges to confidential work. Therefore, it has received great attention how to make full use of the network facilities and protect the image copyright effectively.
In addition, in the process of image retrieval, it is also a big problem how to effectively manage large capacity image database and storage space. For this reason, researchers have begun to consider introducing the information hiding technology into image retrieval field and technologies of encryption, decryption, digital signature, digital labels, digital fingerprints and digital watermarking are proposed. Among them, the digital watermarking is a new technology emerged in the 1990s. It uses redundant data and randomness to embed the numbers, serial numbers, texts and image signs into digital multimedia products in the perceptible or imperceptible forms. The embedded information is used for copyright protection, content inspection and other information provision so as to determine the ownership of digital products and verify the primitiveness of digital contents (Pang, 2010).
Digital watermarking technology is a new direction in the field of information security technology and a new technology for copyright protection and source authentication in the open network environment. People cannot perceive the watermark from the surface of digital product, only the special software can detect the hidden digital watermarking.
Basic features: The basic function of digital watermark is to embed the watermark signal into the digital media and the embedded watermark signal should not reduce the quality of original data and not be easy to be perceived. Therefore, the digital watermark has the following characteristics (Su, 2004).
Imperceptibility: The embedded digital watermark should not make the original data change and not let the protected data distort perceivably.
Robustness: After the protected data was modified or attacked, such as transmission, encoding and lossy compression, the embedded watermark information should maintain certain integrity and can be detected by certain correct probability (Wang, 2006b).
Security: It is difficult for digital watermark to be forged or processed. The unauthorized individuals cannot read and modify the watermark. In the ideal situation, the unauthorized customers cannot detect whether the watermark exists or not.
Provability: In the actual application process, the watermark can be added repeatedly and then the digital watermarking technology must allow that the multiple watermarks can be embedded into the protected data. Each watermark can be proven independently.
Basic framework of digital watermarking technology: The basic idea of digital watermark is to embed secret information into the digital image, audio, video and other digital products to protect copyright, prove the authenticity, track piracy and provide additional information. The implementation process of digital watermarking includes watermark embedding, watermark extracting and watermark detecting (Bors and Pitas, 1998).
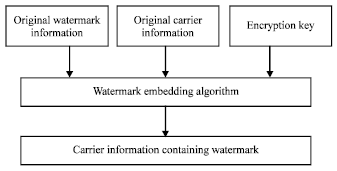 | |
| Fig. 1: | Model of watermark embedding |
Watermark embedding: Watermark embedding is to embed the watermark information into the original image with the key by watermark embedding algorithm on the premise of ensuring the invisibility and generate carrier image of watermarking information. The model of watermark embedding is shown in Fig. 1.
The watermark information can be voice, text or image, the key is generally the encryption algorithm parameter which is mainly used to improve the watermark security.
The process of watermark embedding can be described to embed the digital watermark signal W = {w(k)} into the original carrier image Xi = {xi(k)} and obtain the watermarked carrier image Xw = {wx(k)}.
In the process, there are two embedding rules, addition rule and multiplication rule (Eyadat, 2004). The addition rule is shown in Eq. 1 and the multiplication rule is shown in Eq. 2:
| (1) |
| (2) |
where, a indicates the watermark embedding strength and the value choice should consider the nature of images and the human vision characteristics. On the premise of ensuring the invisibility of watermark, the embedding strengths should be increased as far as possible.
The addition rule is used commonly previously, but it does not consider the differences between each pixel of original image when watermark is embedded which changes the quality of watermark image a lot and affects the robustness. The multiplication rule accordingly makes up for this, so it is superior to addition rule in performance.
Watermark extraction: Watermark extraction is to restore the original watermark information from the carrier image to ensure the integrity of the multimedia data. Watermark extraction can involve the original image or not. The model of watermark extracting is shown in Fig. 2.
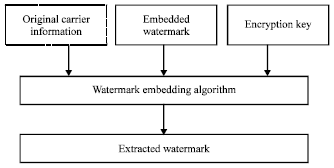 | |
| Fig. 2: | Model of watermark extracting |
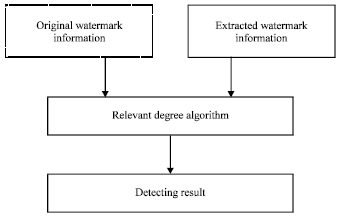 | |
| Fig. 3: | Model of watermark detecting |
The box with dashed line in Fig. 2 indicates that the original image is not necessary as watermark embedding which depends on the embedding algorithm. It is called blind watermarking method when it does not involve the original image and it has greater value.
Watermark detecting: Watermark detection is to determine whether a data contains the specified watermark or not. When the watermarked image is attacked by regular attacks or malicious tampering attacks, the extracted watermark signal may also changes accordingly. Thus, when detecting the watermark, it is necessary to calculate the correlation between the original watermark and the extracted watermark which can determine the presence or absence of watermark information. Watermark detection can involve the original image or not (Xu et al., 2009). The model of watermark detecting is shown in Fig. 3.
Classic algorithms of digital watermarking: Watermark technology is a cutting-edge technology and involves image processing, communication, multimedia and cryptography. Since Tirkel et al. (1993) proposed a digital watermarking algorithm, new algorithms have been constantly emerging, the typical methods include spatial domain algorithm, transform domain algorithm and compressed domain algorithm.
Spatial domain watermarking algorithm: This method can embed the watermark information through changing some data in the host data directly and most of them are designed aiming at the spatial domain of gray scale image which is the basic content of early digital watermarking research. The algorithm has low computational complexity, real-time and strong concealment but it has poor performance to resist attacks. Most of the spatial algorithms belong to fragile watermark or semi-fragile watermarking algorithm and are mainly used in the digital watermarking application that need less demanding robust, such as tamper detection watermark. Typical spatial domain watermarking methods generally include least significant bit method, Patchwork method and texture block mapping coding method (Chen, 2005).
Transform domain watermarking algorithm: The algorithm changes the image from the spatial domain to the frequency domain through transformation and then modifies part of the frequency domain coefficients to realize watermark embedding. The transformation methods mainly include Discrete Cosine Transform (DCT), Discrete Wavelet Transform (DWT) and Discrete Fourier Transform (DFT). It can also compound many transforms to design the watermark with certain properties (Zhao and Wang, 2005).
Compressed domain algorithm: The digital watermarking system based on JPEG compression standard saves a lot of time in the processes of decoding and re-encoding and has high application value in digital broadcast and television. In recent years, the research on watermarking system continues to deepen which include graphics, audio and video. Some new concepts and algorithms have been put forward. For example, in the watermark embedding process, the watermark cannot be embedded directly but firstly the features of original image signal are extracted and then the watermark can be constructed. It is called zero watermarking technology. Besides, there is reversible watermarking technology. These novel algorithms and concepts enrich the research contents of watermarking technology (Zhao, 2008). In addition, the digital media content authentication technology based on watermark is also focused on currently.
Comparison of algorithm performance: In the above-mentioned algorithms, the spatial domain method is proposed earliest. It is simple and has large capacity for hiding information. Its biggest drawback is poor robustness for lossy compression and processing, so it is only applicable to the process without too much treatment. The transform domain watermarking algorithm has strong robust but need long calculating time and a great amount of computation. During robustness attacking, the existing algorithms have no strong robustness for rotation operation and stretching deformation. So it is difficult to design an algorithm which can better resist such operations. In the above methods, in order to satisfy both invisibility and robustness requirements, it should be combined with the human vision system, selecting suitable location to embed, improve the robustness of the watermark, ensure the fidelity of the image and reach balance for both factors (Yang, 2012).
MATERIALS AND METHODS
Discrete cosine transform: Discrete cosine transform is one of the most common linear transform in digital signal processing technology. DCT is a commonly used transform coding method for digital rate compression. It is a lossless and reversible mathematical process and transforms the spatial amplitude data into spatial frequency data. This method can divide the overall image into NxN pixel blocks and then carry on DCT transform for them. It is a real transform and has capabilities of good energy compression and de-correlation. It has wide application in the field of image compression and digital audio signal compression. In particular, JPEG compression standard of the digital image is based on this transform. The watermark embedding algorithm based on JPEG model can enhance the ability to resist JPEG compression attack, so discrete cosine transform has been widely used in digital watermarking technology.
The transform formula is the core of this algorithm, the core of transform and inverse transform is cosine transform and its calculation speed is fast. Because the image processing uses two dimensional transform, here only two-dimensional DCT is given. Let digital image f(x, y) is a matrix with M rows and N columns, in order to reduce or remove the correlation of the spatial domain at the same time and transform the image from the spatial domain to the frequency domain (Mohanty and Ramakrishna, 2000), the two-dimensional DCT transformation formula is shown as Eq. 3:
| (3) |
where, x and y are spatial sampling values; u and v are frequency domain samples; x = 0,1,…, M-1; y = 0,1,…, N-1; u = 0,1,…, M-1; v= 0,1,…, N-1. c(u) and c(v) can be expressed, as shown in Eq. 4 and 5, respectively.
| (4) |
| (5) |
The two-dimensional inverse DCT transform is shown in Eq. 6:
| (6) |
If the digital image is identified by square matrix of pixel, i.e. M = N, the transform and inverse transform can be simplified, as shown in Eq. 7 and 8, respectively:
| (7) |
| (8) |
where, x, y, u, v = 0,1,…, N-1. c(u) and c(v) can be re-expressed, as shown in Eq. 9:
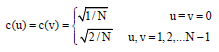 | (9) |
Digital watermarking algorithm based on DCT: The general approach of digital watermarking algorithm based on DCT is to firstly divide the digital image into 8x8 non-overlapping pixel blocks, after DCT transform, obtain the frequency blocks composed of DCT coefficients and then select some frequency blocks according to certain rules. Changing their coefficients slightly can meet certain relation and the digital watermark information can be embedded. The watermark extraction can be realized through selecting the same DCT coefficients as them in the watermark embedding process.
Process of watermark embedding: In this process, the robustness of the watermark should be considered which can be improved by embedding watermark repeatedly (Zou, 2007). The process of watermark embedding is shown in Fig. 4.
The realizing process of watermark embedding is as follows:
| • | The original image and the watermark information are respectively blocked into 8x8 pieces. If the information amount of embedded watermark is relatively small, the embedding process can be carried out repeatedly to enhance the watermark |
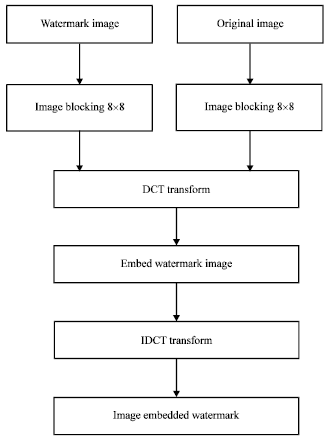 | |
| Fig. 4: | Process of watermark embedding based on discrete cosine transform |
| • | Two-dimensional discrete cosine transform is carried on for the original image |
| • | After image blocking, the watermark information can be embedded into each sub-block according to the expression, as shown in Eq. 10: |
| (10) |
where, Ai is the DCT coefficient of the original image, Awi represents the coefficient of the embedded image, Wi means the watermark image information which has the same block number as the original image and a represents watermarked intensity factor (Ahmidi and Safabakhsh, 2004)
| • | The inverse DCT transform is carried on for every DCT coefficient block of the embedded watermark and the watermarked images is obtained. So, the watermark can be adaptively embedded in the image in accordance with the vision characteristics |
Process of watermark extracting: The watermark extraction is the inverse process of watermark embedding (Barni et al., 1998), the process of watermark extracting is shown in Fig. 5.
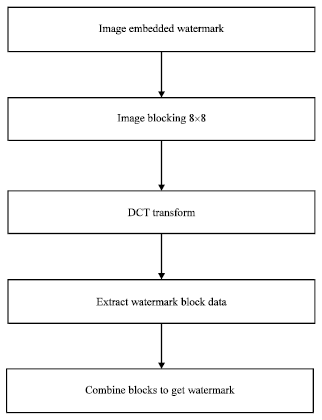 | |
| Fig. 5: | Process of watermark extracting based on discrete cosine transform |
The concrete process based on DCT is as follows:
| • | Firstly, the image to be tested is blocked into 8x8 pieces |
| • | DCT is carried on for each sub-block |
| • | Each watermark block embedded into the image is extracted from the DCT coefficients |
| • | Finally, all watermark data blocks are combined to obtain the embedded watermark information |
Image retrieval: Image retrieval is to match the querying information and the extracted watermark information. In the ideal case, it can obtain the only search result. The essence of image retrieval is image matching, that is, each pixel position of the same object in two images can be identified and the correspondence is established. There are many image matching ways, of which the point matching method based on gray scale is most simple and common. The usual matching similarity measuring functions include SAD (Sum of Absolute Differences), SSD (Sum of Squared Differences), NCC (Normalized Cross Correlation) and so on. Where, the two former algorithms make the similarity measuring function get the minimum value by searching method while the NCC algorithm is to get the maximum value (Huang and Chen, 2011).
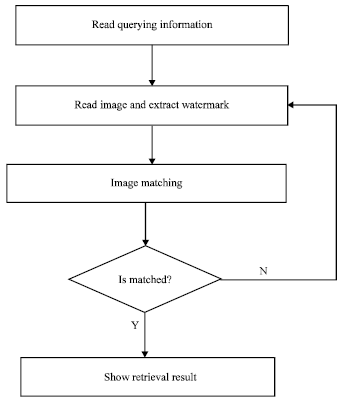 | |
| Fig. 6: | Process of image retrieval based on digital watermark |
This study uses NCC method to realize image retrieval which can effectively remove the interference of luminance information in low-frequency background and it is easy to set the value of detection threshold.
Let the size of digital watermark image is MxN, the querying image is I(x, y) and the extracted watermark image is T(x, y), then NCC can be described, as shown in Eq. 11:
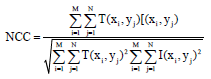 | (11) |
When image is queried, if the value of NCC is greater, the correlation degree is higher and it is more likely that it is the image to be retrieved (Xie et al., 2011). The process of image retrieval is shown in Fig. 6. The extracted watermark information and the querying information are matched and the corresponding search result can be gotten.
RESULTS AND DISCUSSION
In the experiment, the library image of 512x512 pixel is used as the host information and the 8-bit grayscale image of 64x64 is used as the meaningful digital watermark information.
 | |
| Fig. 7 (a-d): | Embedding and extraction of an image watermark, (a) Original image, (b) Original watermark image, (c) Image embedded watermark and (d) Extracted watermark image |
According to the above presented algorithms, the results are shown in Fig. 7a-d. (a) is the original image, (b) is the original watermark image, (c) is the image embedded watermark and (d) is the extracted watermark image.
From a visual point of view, there is no difference between (a) and (c) which indicates that the watermark algorithm has good invisibility. Theoretically, the PSNR of the watermarked image and the original image is 41.16 dB and the similarity of the extracted watermark and the original watermark is 1.000, namely NCC = 1.000. The results show that the algorithms can completely extract the original watermark.
CONCLUSION
On the basis of analyzing the theory of image retrieval, the watermark embedding, watermark extracting and image retrieval are realized based on DCT transform. The experiment results show that this method can improve the security of network transmission for digital image because of the invisibility of digital watermark through embedding the watermark into an image. The extracted digital watermark is made as the querying information for image retrieval which can ensure the retrieval pertinence of image retrieval process, avoid constructing the large-capacity index database and solve the problem of storage space. Because the embedded digital watermark has good robustness, it can effectively extract the embedded watermark even if the digital image has been processed or attacked, then the accuracy of image retrieval can be ensured.
The image retrieval method based on the watermark is a new research area and it can solve the problems of copyright and retrieval at the same time, so it has wide development prospect and attracts great interest of researchers. But the image retrieval method based on watermark also has limitations in application, for example, the watermark information must be embedded when storing image. In addition, there are many problems to be solved, such as, the contents and capacity of embedded watermark, real time of watermark extracting and so on. Then, there are many technical aspects to be improved. Especially, considering the endless data types and attacking means, the researchers should constantly update ideas and learn the latest achievements of signal processing, cryptography and computer network to find new algorithms.
ACKNOWLEDGMENTS
This study is supported by the Social Science Research Project of Linyi, Shandong Province, P. R. China (No. 2011SKL229). The author acknowledges the support of Linyi Academy of Social Science and Linyi University for the study.
REFERENCES
- Ahmidi, N. and R. Safabakhsh, 2004. A novel DCT-based approach for secure color image watermarking. Proceedings of the International Conference on Information Technology: Coding and Computing, Volume 2, April 5-7, 2004, Tehran, Iran, pp: 709-713.
CrossRef - Barni, M., F. Bartolini, V. Cappellini and A. Piva, 1998. A DCT-domain system for robust image water marking. Signal Process., 66: 357-372.
CrossRefDirect Link - Bors, A. and I. Pitas, 1998. Image watermarking using block site selection and DCT domain constraints. Optics Express, 3: 512-523.
CrossRefDirect Link - Eyadat, M., 2004. Factors that affect the performance of the DCT-block based image watermarking algorithms. Proceedings of the International Conference on Information Technology: Coding and Computing, Volume 1, April 5-7, 2004, Carson, CA., USA., pp: 650-654.
CrossRef - Mohanty, S.P. and K.R. Ramakrishna, 2000. A DCT domain visible watermarking technique for images. Proceedings of the IEEE International Conference on Multimedia and Expo, July 30-August 2, 2000, New York City, USA., pp: 1029-1032.
Direct Link - Xie, W.D., Y.H. Zhou and R.L. Kou, 2011. An improved fast normalized cross correlation algorithm. J. Tongji Univ. (Nat. Sci.), 39: 1233-1237.
Direct Link