
Paweena Tangjuang
School of Applied Statistics, National Institute of Development Administration,Bangkapi, Bangkok, 10240, Thailand
Pachitjanut Siripanich
School of Applied Statistics, National Institute of Development Administration,Bangkapi, Bangkok, 10240, Thailand
Journal of Applied Sciences
Year: 2014 | Volume: 14 | Issue: 20 | Page No.: 2507-2515







ABSTRACT
This study focuses on the outlier detection for Multivariate Multiple Regression in Y-direction however, we propose an alternative method based on the squared distances of the residuals. The proposed method refers to the robust estimates of location and covariance matrices derived from the squared distances of the residuals. The proposed method is compared to Mahalanobis Distance method, Minimum Covariance Determinant method and Minimum Volume Ellipsoid method which are used to detect multivariate outliers. An advantage of the proposed method is that it is an alternative method to solve the complicated problem of resampling algorithm in detecting multivariate outliers in Y-direction in the case of having a large sample size and correlation between the dependent variables.
PDF Abstract XML References Citation
Received: January 09, 2014;
Accepted: April 21, 2014;
Published: June 28, 2014
How to cite this article
Paweena Tangjuang and Pachitjanut Siripanich, 2014. Outlier Detection for Multivariate Multiple Regression in Y-direction. Journal of Applied Sciences, 14: 2507-2515.
DOI: 10.3923/jas.2014.2507.2515
URL: https://scialert.net/abstract/?doi=jas.2014.2507.2515
DOI: 10.3923/jas.2014.2507.2515
URL: https://scialert.net/abstract/?doi=jas.2014.2507.2515
INTRODUCTION
Multivariate outliers are observations appearing to be inconsistent with the correlation structure of the data (Quintano et al., 2010). That is, multivariate outlier detection examines the dependence of several variables, whereas univariate outlier detection is carried out independently on each variable. Multivariate outlier detection is of interest since the existence of outliers can randomly change the values of the estimators. A capable technique for the treatment of these observations, or an insight of the relative worth of the available methods, is necessary. Wilks (1963) formed the Wilks’ statistic for the detection of a single outlier. Wilks’s procedure is applied to the reduced sample of multivariate observations by comparing the effects of deleting each possible subset. Gnanadesikan and Kettenring (1972) proposed attaining the principal components of the data and searching for outliers in those directions. The method of Rousseeuw (1985) was based on the computation of the ellipsoid with the smallest covariance determinant or with the smallest volume that would include at least half of the data points, this procedure has been extended by Hampel et al. (1986), Rousseeuw and Leroy (1987), Rousseeuw et al. (1990), Cook et al. (1993), Rocke and Woodruff (1993, 1996), Maronna and Yohai (1995), Agullo (1996), Hawkins and Olive (1999), Becker and Gather (1999), Rousseeuw and Van Driessen (1999) and Acuna and Rodriguez (2004). Atkinson (1994) considered a forward search from random element sets and then selected a subset of the data having the smallest half-sample ellipsoid volume. Rocke and Woodruff (1996) used a hybrid algorithm utilizing the steepest descent procedure of Hawkins (1993) for obtaining the MCD estimator which was used as a starting point in the forward search algorithm of Atkinson (1993) and Hadi (1992). Billor et al. (2000) proposed an approach based on the methods of Hadi (1992, 1994) and Hadi and Simonoff (1993) concerning Mahalanobis distances. Pena and Prieto (2001) presented a simple multivariate outlier detection procedure and a robust estimator for the covariance matrix, based on information obtained from projections onto the directions that minimize and maximize the kurtosis coefficient of the projected data. Hardin and Rocke (2004) used the Minimum Covariance Determinant estimator for outlier detection in the multiple cluster. Rousseeuw et al. (2006) used the reweighted MCD estimates to obtain a better efficiency. The residual distances were then used in a reweighting step in order to improve the efficiency. Filzmoser and Hron (2008) proposed the outlier detection method based on the Mahalanobis distance. Riani et al. (2009) used a forward search to provide the robust Mahalanobis distances to detect the presence of outliers in a sample of multivariate normal data. Noorossana et al. (2010) extended four methods including likelihood ratio, Wilk’s lambda, T2 and principal components to monitor multivariate multiple linear regression in detecting both sustained and outlier shifts. Cerioli (2010) developed multivariate outlier tests based on the high-breakdown Minimum Covariance Determinant estimator. Oyeyemi and Ipinyomi (2010) tried to find a robust method for estimating the covariance matrix in multivariate data analysis by using the Mahalanobis distances of the observations. Todorov et al. (2011) investigated and compared many different methods based on robust estimators for detecting multivariate outliers. Jayakumar and Thomas (2013) used the Mahalanobis distance to obtain an iterative procedure for a clustering method based on multivariate outlier detection.
A Multivariate Multiple Regression (MMR) model generalizes the multiple regression model for where the prediction of several dependent variables is required from the same set of independent variables in other words, it is the extension of univariate multiple regression to various dependent variables. The MMR model is:
| (1) |
where, Y is a dependent variable matrix of size nxp, X is an independent variable matrix of size nx(q+1), B is a parameter matrix of size (q+1)xp and E is an error matrix of size nxp. Each row of Y contains the values of the p dependent variables measured on a subject. Each column of Y consists of n observations on one of the p variables. It is assumed that X is fixed from sample to sample, i.e., in MMR each response is assumed to follow its own univariate regression model (with the same set of explanatory variables) and that the errors associated with the dependent variables may be correlated (Rencher, 2002). Outlier detection in the MMR model is of interest since in real condition, there may be data containing correlated variables, especially the correlation between dependent variables which may lead to incorrectly detecting the observations as the outliers in the direction of the dependent variables.
Hence, in this study we focus on an alternative method that contemplates the covariance matrix of the dependent variables which also includes correlation information in order to detect the outliers in Y-direction of the MMR model for the sample data based on the basic fundamental assumptions of the MMR model denoted by (A1) E(Y) = XB or E(E) = O, (A2) cov(yi ) = Σ for all i = 1, 2,..., n, where y΄i is the ith row of Y and (A3) cov(yi , yj) = O for all i ≠ j (Rencher, 2002).
A simulation study was carried out to compare the proposed method to MD, MCD and MVE method in detecting Y-outliers in the case of different correlation matrices, covariance matrices, sample sizes and dimensions.
CONSIDERED OUTLIER DETECTION METHODS
Outlier detection is one of the substantial studies in multivariate data analysis. In order to identify multivariate outliers, there are plenty of outlier detection methods found on projection pursuit, which is to project the multivariate data to the univariate data and the methods found on the estimation of the covariance structure used to establish a distance to each observation indicating how far the observation is from the center of the data affecting the covariance structure. The outlier detection methods considered in this study are Mahalanobis Distance (MD) method, Minimum Covariance Determinant (MCD) method and Minimum Volume Ellipsoid (MVE) method.
MD is a multivariate outlier detection method which uses the classical mean and classical covariance matrix to calculate Mahalanobis distances. The MD method is very vulnerable to outliers because the classical mean and classical covariance matrix cannot account for all of the actual real values when data contain outliers. Rocke and Woodruff (1996) stated that the MD method is very useful for identifying scattered outliers but in data with clustered outliers, it does not work as well outliers. Since the MD method is very vulnerable to the existence of outliers, Rousseeuw et al. (1990) used robust distances for multivariate outlier detection by using the robust estimators of location and scatter.
MCD method of Rousseeuw (1984, 1985) is the robust (resistant) estimation of multivariate location and scatter. This method is defined by minimizing the determinant of the covariance matrix computed from h points or observations (out of n) whose classical covariance matrix has the lowest possible determinant. The MCD estimate of location is the average of these h points, whereas the MCD estimate of scatter is a multiple of their covariance matrix (Hubert et al., 2008).
Rousseeuw (1984, 1985) also introduced MVE estimator looking for the minimal volume ellipsoid which covers at least half of the data points, the MVE can be used to find a robust location and a robust covariance matrix that can be used for constructing confidence regions, detecting multivariate outliers and leverage points, but the MVE has zero efficiency because of its low rate of convergence.
With all three of these methods, an observation can be declared as a candidate outlier if the squared distance for the observation is larger than χ2p,0.975 for a p-dimensional multivariate sample. However, finding an MCD or MVE sample can be time consuming and difficult in the case of a large sample size. In the case of finding the MCD estimator, we have to study every half sample and calculate the determinant of the covariance matrix of that sample. For a sample size of 20, the study would require the computation of about 184,756 determinants and for a sample size of 60, the study would require the computation of about 118, 264, 581, 564, 861, 000 determinants. It is obvious that finding the exact MCD is not easy. The best subset for the MCD and MVE methods could be overlooked because of the random resampling of the data set, thus the the errors in detecting outliers may occurred or some genuine data points could be erroneously labeled as outliers. To solve the resampling problem in the MCD and MVE method, we try to find an attempt is made to find the robust distances based on robust estimates of the location and covariance matrices in the proposed method that use less computation time for applying the algorithm and then use the obtained robust distances to detect the outliers in the Y-direction.
PROPOSED METHOD
In the MMR, each response is assumed to result in its own univariate regression model (with the same set of explanatory variables) and the errors linked to the dependent variables may be correlated. To detect the multivariate outliers in the Y-direction for the MMR model, a useful algorithm is sought by considering the residuals, so that the residual matrix (R) containing ri' of size 1xp (for i = 1, …, n) can be expressed in terms of H and Y and subsequently the matrix R can be in terms of E as shown below:
![]()
It is also possible to obtain,
E(R) = E[(1-H)Y] = (I-H)E(Y) = (I-H)XB = 0 since
(I-H)X = 0
where, the H matrix is known as a projection matrix called the hat matrix which is equal to X(X'X)-1X'. The hat matrix H can be used to express ![]() and describes the residuals as to be linear combinations of Y, furthermore, it can also be used to find the covariance matrix of the residuals. The idea based on the squared distances of the residuals is used in detecting the outliers in the Y-direction for the MMR data containing correlated variables, especially the correlation between the dependent variables. The squared distances of the residuals
and describes the residuals as to be linear combinations of Y, furthermore, it can also be used to find the covariance matrix of the residuals. The idea based on the squared distances of the residuals is used in detecting the outliers in the Y-direction for the MMR data containing correlated variables, especially the correlation between the dependent variables. The squared distances of the residuals ![]() for all observation i = 1,..., n are found and then (at least) half of the data set having small values of the squared distances of the residuals are selected for finding the robust estimates of the location and covariance matrices, which are used to calculate the squared distances of Y in detecting Y-outliers for the MMR data. Only half of the data are selected since the maximum allowable percentage of contaminated data is determined by the concept of the breakdown point. The MVE method finds out the ellipsoid with the smallest volume which contains (at least) 50% of all the points and uses its center as a location estimate, whereas the MCD method uses 50% of all data points for which the lowest determinant of covariance matrix is obtained. The general idea of the breakdown point is the smallest proportion of the observations which can make an estimator meaningless (Hampel et al., 1986; Rousseeuw and Leroy, 1987). Often it is 50%, so that this portion of the dataset can set aside allow for any contaminated group of data.
for all observation i = 1,..., n are found and then (at least) half of the data set having small values of the squared distances of the residuals are selected for finding the robust estimates of the location and covariance matrices, which are used to calculate the squared distances of Y in detecting Y-outliers for the MMR data. Only half of the data are selected since the maximum allowable percentage of contaminated data is determined by the concept of the breakdown point. The MVE method finds out the ellipsoid with the smallest volume which contains (at least) 50% of all the points and uses its center as a location estimate, whereas the MCD method uses 50% of all data points for which the lowest determinant of covariance matrix is obtained. The general idea of the breakdown point is the smallest proportion of the observations which can make an estimator meaningless (Hampel et al., 1986; Rousseeuw and Leroy, 1987). Often it is 50%, so that this portion of the dataset can set aside allow for any contaminated group of data.
In the resampling algorithms of the MCD and MVE methods, the best subset of data method could be overlooked because of the random resampling of the data set, thus a fault in detecting outliers could occur and furthermore, it takes a lot of computation time in the case of a large sample size. To use less time in finding the robust estimates of the location and covariance matrices, our consideration was based on the squared distances of the residuals ![]() so that found the robust distances of Y are found by using the obtained robust estimates of the location and covariance matrices for detecting the outliers in the Y-direction of the MMR data. r'i is the ith row element of the matrix of the residuals R that is:
so that found the robust distances of Y are found by using the obtained robust estimates of the location and covariance matrices for detecting the outliers in the Y-direction of the MMR data. r'i is the ith row element of the matrix of the residuals R that is:
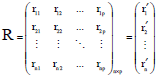
We obtained the distribution of ![]() exhibited in the following theorems.
exhibited in the following theorems.
Theorem 1: If yi-Np(μi, Σ) where μi = B'xi then ![]() asymptotic χ2p for all i = 1,..., n provided that:
asymptotic χ2p for all i = 1,..., n provided that:
![]()
is an unbiased estimator of Σ
And we obtained the expectation and variance of ![]() .
.
Theorem 2: The asymptotic expectation and the asymptotic variance of the squared distances of the residuals are p and 2p, respectively, i.e.:
![]()
proofs of both theorems are in Appendix.
From the above results, we applied the squared distances of the residuals in the proposed algorithm for detecting Y-outliers in the MMR data such that in the multivariate case, not only the stretch of an observation from the centroid of the data but also the spread of the data must be considered. Recognizing the multivariate cutoff value which tallies with the distance of the outliers is very difficult since there is no discernible basis to suppose that the fixed cutoff value will be suitable for every data set. Garrett (1989) used the chi-square plot to find the cutoff value by plotting the robust squared Mahalanobis distances against the quantiles of χ2p, where the most extreme points are deleted until the remaining points keep the track of a straight line and the deleted points are the identified outliers. Altering the cutoff value to the data set is a better procedure than using a fixed cutoff value. This idea is supported by Reimann et al. (2005), who proposed that the cutoff value has to be adjusted to the sample size. For the reasons above, in the proposed algorithm we used cIQR to be our cutoff value which can be flexible based on the sample size and the quantity of outliers in the data, where c is an arbitrary constant and IQR is the interquartile range of the robust squared distances of yi' for all i = 1,..., n. When the data contain a large number of Y-outliers, we used the cutoff value cIQR such that c is an arbitrary constant having a small value in order to detect such a large number of Y-outliers. On the other hand, we used the cutoff value cIQR where c is an arbitrary constant having a large value when the data contained few Y-outliers. We concluded the proposed algorithm in detecting Y-outliers in the MMR data, as shown in the following six steps:
Algorithm for the proposed method of detecting Y-outliers in MMR:
| • | Calculate the residual matrix (R) by: |
![]()
That is, the obtained residual matrix has size nxp.
| • | Calculate the estimate of covariance matrix of the error: |
![]()
which is an unbiased estimator of Σ size pxp , where q is the number of the independent variables
| • | Calculate the matrix of the squared distances of the residuals, then we obtain |
| • | For reducing the influence of the observations that are far from the centroid of the data, we will delete such observations. That is, we select (at least) 50% of the data to obtain the observations having the squared distances of the residuals (which has the chi-squared distribution) less than or equal to χ2p,0.50 or |
| • | Use the selected y'i to calculate the robust estimate of location |
| • | Use |
We investigated the proposed algorithm by comparing it to MD, MCD and MVE method with different correlation matrices, covariance matrices, sample sizes and dimensions.
SIMULATION STUDY
Simulation procedure: Consider the MMR model Y = XB+E defined in Eq. 1. In simulation procedure, the values of the dependent variables and the errors were generated from the multivariate normal distribution corresponding to the Assumption (A1)-(A3) and varied according to different variances and correlations. The values of the independent variables were generated from the different distributions based on uniform distribution, such that it is assumed that X is fixed from sample to sample. The sample sizes (n) were 20 and 60. The numbers of independent variables (q) were the same as the numbers of dependent variables (p) which were 2 and 3. The process was repeated 1,000 times to obtain 1,000 independent samples containing 10, 20 and 30% outliers in Y-direction. From each sample obtained, we compared the proposed method to the MD, MCD and MVE method. It was expected regarding the compared methods that only about a 2.5% quantile of the dataset drawn from the multivariate normal distribution would be detected as outliers, that is, they detected the outliers by considering the observations having squared distances of y'i exceeding χ2p,0.975. For the proposed method, we declared the observations as Y-outliers by using 3IQR as the cutoff value in the case of data containing 10% outliers, 1.5IQR as the cutoff value in the case of data containing 20% outliers and IQR as the cutoff value in the case of data containing 30% outliers, where IQR is the interquartile range of the robust squared distances of y'i all i = 1, …,n.
Results of the simulation study: Findings are shown in Table 1-3 in which the percentages of the correction correctly in detecting the observations declared as Y-outliers are given by using the proposed method and the other 3 methods, namely, MD, MCD and MVE methods.
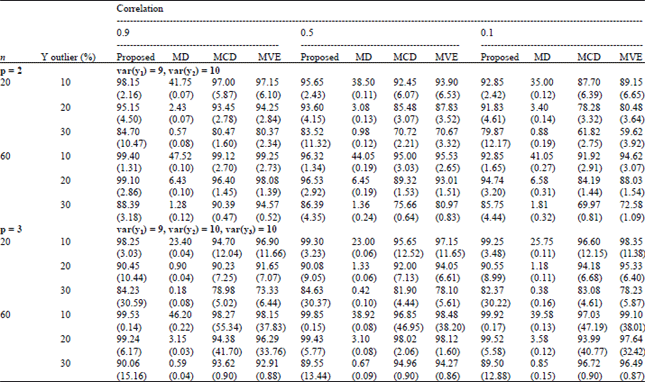
| Table 1: | Percentages of correctly detecting Y-outliers in the case of data having high variances and correlations of 0.9, 0.5 and 0.1 |
 | |
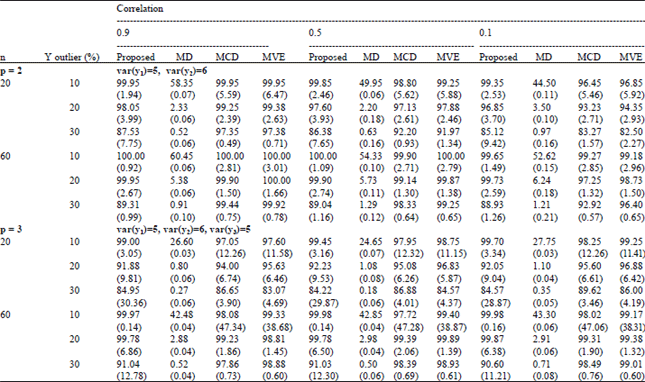
| Table 2: | Percentages of correctly detecting Y-outliers in the case of data having medium variances and correlations of 0.9, 0.5 and 0.1 |
 | |
| Table 3: | Percentages of correctly detecting Y-outliers in the case of data having low variances and correlations of 0.9, 0.5 and 0.1 |
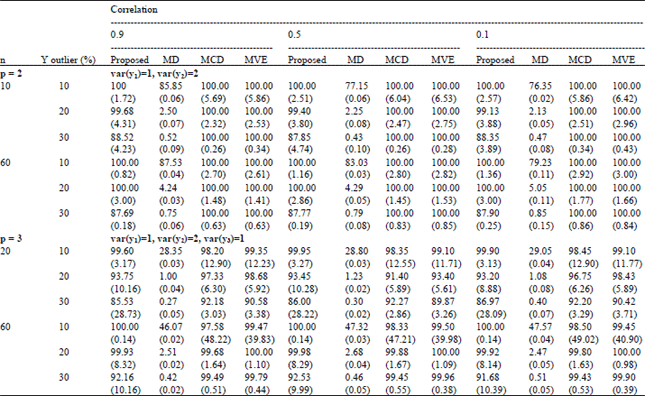 | |
The values in parentheses are the percentages of detecting observations incorrectly, that is, they are the percentages of declaring observations as Y-outliers which they are not to be Y-outliers. In the case of the correlation between the dependent variables of 0.1, the percentages of correction correct detection decreased when the variances of dependent variables increased, whereas the results were the same for the case of the correlations between the dependent variables equal of 0.5 and 0.9. Higher percentages of correct detection were obtained in the case of data having smaller variances in the direction of the dependent variables. Furthermore, in the case of low variance, the percentages of correct detection increased while the correlations between dependent variables increased and the results were the same for the cases of medium and high variance.
For most of the cases, the proposed method could detect Y-outliers with higher percentages of correct detection and lower percentages of incorrect detection, especially in the cases of 10 and 20% Y-outliers. However, in the case of 30% Y-outliers, the proposed method obtained lower percentages of correct detection than some of the other compared methods but the percentages of correct detection increased as sample sizes increased.
DISCUSSION
It can be seen that the MD method was very vulnerable to outliers because of the classical mean and the classical covariance matrix affected by those outliers. When sample data contained Y-outliers, the multivariate outlier detection method seemed to be moredifficult since correlations between the dependent variables were also of concern. This study attempted to derive an alternative algorithm for multivariate multiple regression data by applying the squared distances of the residuals in obtaining the robust estimates of the location and covariance matrices which were used to calculate the robust distances of Y in order to detect Y-outliers. The proposed method also reduced the steps of the resampling algorithm of the Minimum Covariance Determinant method and the Minimum Volume Ellipsoid method for which a lot of time is spent on finding the best subset containing approximately 50% of data for using in the calculation of the robust estimates of the location and covariance matrices. Here, the proposed method could be used to alleviate the more complicated steps of the MCD and MVE methods and yielded higher percentages of correct detection for a not very high percentage of outliers. For a higher percentage of outliers, e.g. 30%, the percentages of correct detection of the proposed method were slightly less than those two methods but they increased as the sample sizes increased. However, the drawback of the proposed method was the necessity of plotting all points of data for investigating observations that deviate highly from the data cluster so much from the cluster of data.
CONCLUSION
Outlier detection in the Y-direction for multivariate multiple regression data is of interest since there are correlations between the dependent variables which are one cause of difficulty in detecting multivariate outliers, furthermore, the existence of the outliers can randomly change the values of the estimators. Having an alternative method that can detect those outliers is necessary so that more trustworthy results can be obtained. It started by emphasizing the previous study in the literature and covered the multivariate outlier detection methods that have been developed by many researchers. But in this study, the Mahalanobis Distance method, the Minimum Covariance Determinant method and the Minimum Volume Ellipsoid method were considered and compared with the proposed method which tried to solve the outlier detection problem when data contained the correlated dependent variables. The proposed method was based on the squared distances of the residuals used to find the robust estimates of the location and covariance matrices for calculating the robust distances of Y in detecting Y-outliers. The principal advantage of the proposed algorithm is to solve the complicated problem of a resampling algorithm which occurs when the sample size is large. The behavior of the proposed method was evaluated through Monte Carlo simulation studies. It was demonstrated that the proposed method could be an alternative method used to detect outliers in the cases of low, medium and high correlations/variances of the dependent variables. Specifically, simulations with contaminated datasets indicated that the proposed method could be applied efficiently in the case of data having large sample sizes.
ACKNOWLEDGMENT
Authors are grateful to Rajamangala University of Technology Tawan-ok, Thailand, for financial support throughout this study.
APPENDIX
Proof of Theorem 1: Let Y be an nxp matrix of p dependent variables, μ denote the center and describes the location of the distribution and Σ be the covariance matrix of the data which describes the scale of the distribution:
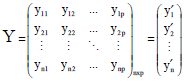
If yi is distributed as Np(μi, Σ), then (yi-μi)΄Σ-1 (yi-μi) has a chi-squared distribution with p degrees of freedom (Srivastava, 2002).
Denote R = ![]() be an nxp matrix of residuals containing r΄i for each observation i = 1, ..., n.
be an nxp matrix of residuals containing r΄i for each observation i = 1, ..., n.
Then:
R = ![]() = Y-HY = (I-H) Y
= Y-HY = (I-H) Y
Where:
H = X(X΄X)-1X΄
That is, R is a linear function of Y and we obtain:
E(R) = (I-H)E(Y) = (I-H) XB = 0
since (I-H)X = 0.
Recall that yi~Np(μi, Σ). It is easily seen that ri~Np (0, Σ) and hence ri΄Σ-1ri~χ2p.
And we have:
![]()
thus:
![]()
is an unbiased estimator of Σ (Rencher, 2002).
Now let us replace the population parameter μ and Σ by their unbiased estimators, then we obtain the squared distance of the residuals, ![]() for each observation i = 1,…, n, is asymptotically distributed as chi-squared distribution with p degrees of freedom that is
for each observation i = 1,…, n, is asymptotically distributed as chi-squared distribution with p degrees of freedom that is ![]() - asymptotic χp2.
- asymptotic χp2.
Where:
![]()
Proof of Theorem 2: Let ui = ![]() for i = 1, …, n.
for i = 1, …, n.
Since ![]() ~ asympatotic χ2p, we obtain the moments of order k for each ui as follows:
~ asympatotic χ2p, we obtain the moments of order k for each ui as follows:
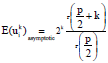
Thus:
![]()
and:
![]()
REFERENCES
- Atkinson, A.C., 1994. Fast very robust methods for the detection of multiple outliers. J. Am. Stat. Assoc., 89: 1329-1339.
Direct Link - Becker, C. and U. Gather, 1999. The masking breakdown point of multivariate outlier identification rules. J. Am. Stat. Assoc., 94: 947-955.
Direct Link - Billor, N., A.S. Hadi and P.F. Velleman, 2000. BACON: Blocked adaptive computationally efficient outlier nominators. Comput. Stat. Data Anal., 34: 279-298.
CrossRef - Cerioli, A., 2010. Multivariate outlier detection with high-breakdown estimators. J. Am. Stat. Assoc., 105: 147-156.
CrossRef - Cook, R.D., D.M. Hawkins and S. Weisberg, 1993. Exact iterative computation of the robust multivariate minimum volume ellipsoid estimator. Stat. Probab. Lett., 16: 213-218.
CrossRef - Jayakumar, G.S.D.S. and B.J. Thomas, 2013. A new procedure of clustering based on multivariate outlier detection. J. Data Sci., 11: 69-84.
Direct Link - Filzmoser, P. and K. Hron, 2008. Outlier detection for compositional data using robust methods. Math. Geosci., 40: 233-248.
CrossRef - Garrett, R.G., 1989. The chi-square plot: A tool for multivariate outlier recognition. J. Geochem. Explor., 32: 319-341.
CrossRef - Gnanadesikan, R. and J.R. Kettenring, 1972. Robust estimates, residuals and outlier detection with multiresponse data. Biometrics, 28: 81-124.
Direct Link - Hardin, J. and D.M. Rocke, 2004. Outlier detection in the multiple cluster setting using the minimum covariance determinant estimator. Comput. Stat. Data Anal., 44: 625-638.
Direct Link - Hawkins, D.M. and D.J. Olive, 1999. Improved feasible solution algorithms for high breakdown estimation. Comput. Stat. Data Anal., 30: 1-11.
CrossRef - Hubert, M., P.J. Rousseeuw and S. van Aelst, 2008. High-breakdown robust multivariate methods. Stat. Sci., 23: 92-119.
CrossRefDirect Link - Maronna, R.A. and V.J. Yohai, 1995. The behavior of the Stahel-Donoho robust multivariate estimator. J. Am. Stat. Assoc., 90: 330-341.
CrossRef - Noorossana, R., M. Eyvazian, A. Amiri and M.A. Mahmoud, 2010. Statistical monitoring of multivariate multiple linear regression profiles in phase I with calibration application. Qual. Reliab. Eng. Int., 26: 291-303.
CrossRef - Oyeyemi, G.M. and R.A. Ipinyomi, 2010. A robust method of estimating covariance matrix in multivariate data analysis. Afr. J. Math. Comput. Sci. Res., 3: 1-18.
Direct Link - Pena, D. and F.J. Prieto, 2001. Multivariate outlier detection and robust covariance matrix estimation. Technometrics, 43: 286-310.
CrossRef - Quintano, C., R. Castellano and A. Rocca, 2010. Influence of outliers on some multiple imputation methods. Adv. Methodol. Stat., 7: 1-16.
Direct Link - Reimann, C., P. Filzmoser and R.G. Garrett, 2005. Background and threshold: Critical comparison of methods of determination. Sci. Total Environ., 346: 1-16.
CrossRef - Riani, M., A.C. Atkinson and A. Cerioli, 2009. Finding an unknown number of multivariate outliers. J. R. Stat. Soc.: Ser. B (Stat. Methodol.), 71: 447-466.
CrossRef - Rocke, D.M. and D.L. Woodruff, 1993. Computation of robust estimates of multivariate location and shape. Statistica Neerlandica, 47: 27-42.
CrossRef - Rocke, D.M. and D.L. Woodruff, 1996. Identification of outliers in multivariate data. J. Am. Stat. Assoc., 91: 1047-1061.
CrossRef - Rousseeuw, P.J., 1984. Least median of squares regression. J. Am. Stat. Assoc., 79: 871-880.
CrossRefDirect Link - Rousseeuw, P.J. and K. van Driessen, 1999. A fast algorithm for the minimum covariance determinant estimator. Technometrics, 41: 212-223.
CrossRefDirect Link - Rousseeuw, P.J. and B.C. van Zomeren, 1990. Unmasking multivariate outliers and leverage points. J. Am. Stat. Assoc., 85: 633-639.
CrossRefDirect Link - Rousseeuw, P.J., M. Debruyne, S. Engelen and M. Hubert, 2006. Robustness and outlier detection in chemometrics. Crit. Rev. Anal. Chem., 36: 221-242.
CrossRef - Todorov, V., M. Temp and P. Filzmoser, 2011. Software for multivariate outlier detection in survey data. Proceedings of the Conference of European Statisticians, Work Session on Statistical Data Editing, May 9-11, 2011, Ljubljana, Slovenia, pp: 1-16.
Direct Link - Hawkins, D.M., 1993. The feasible solution algorithm for the minimum covariance determinant estimator in multivariate data. Comput. Statist. Data Anal., 17: 197-210.
CrossRefDirect Link - Hadi, A.S., 1992. Identifying multiple outliers in multivariate data. J. R. Statist. Soc. Ser. B (Methodological), 54: 761-771.
Direct Link - Hadi, A.S., 1994. A modification of a method for the detection of outliers in multivariate samples. J. R. Statist. Soc. Ser. B (Methodological), 56: 393-396.
Direct Link - Hadi, A.S. and J.S. Simonoff, 1993. Procedures for the identification of multiple outliers in linear models. J. Am. Statist. Assoc., 88: 1264-1272.
Direct Link