
Habshah Midi
Department of Mathematics, Faculty of Science, Universiti Putra Malaysia, 43400 Serdang, Selangor, Malaysia
Syaiba Balqish Ariffin
Department of Mathematics, Faculty of Science, Universiti Putra Malaysia, 43400 Serdang, Selangor, Malaysia
Journal of Applied Sciences
Year: 2013 | Volume: 13 | Issue: 6 | Page No.: 828-836







ABSTRACT
Detection of outlier based on standardized Pearson residuals has gained widespread use in logistic regression model in the presence of a single outlier. An innovation attempts in the same direction but dealing for a group of outliers have been made using generalized standardized Pearson residual which requires a graphical or a robust estimator to find suspected outliers to form a group deletion. In this study, an alternative measure namely modified standardized Pearson residual is derived from the robust logistic diagnostic. The weakness of standardized Pearson residuals and the usefulness of generalized standardized Pearson residual and modified standardized Pearson residual are examined through several real examples and Monte Carlo simulation study. The results of this study signify that the generalized standardized Pearson residual and the modified standardized Pearson residual perform equally good in identifying a group of outliers.
PDF Abstract XML References Citation
Received: October 11, 2012;
Accepted: May 02, 2013;
Published: July 19, 2013
How to cite this article
Habshah Midi and Syaiba Balqish Ariffin, 2013. Modified Standardized Pearson Residual for the Identification of Outliers in Logistic Regression Model. Journal of Applied Sciences, 13: 828-836.
DOI: 10.3923/jas.2013.828.836
URL: https://scialert.net/abstract/?doi=jas.2013.828.836
DOI: 10.3923/jas.2013.828.836
URL: https://scialert.net/abstract/?doi=jas.2013.828.836
INTRODUCTION
The popularity of the logistic regression model stem from its wider acceptance in research studies that rely on the binary response. Traditionally, the Maximum Likelihood Estimator (MLE) is used to fit the logistic regression model and it has good optimally properties in ideals settings. Unfortunately, it is enormously sensitive to outliers and high leverage points (Pregibon, 1981; Hao, 1992; Victoria-Feser, 2002; Croux et al., 2002; Croux and Haesbroeck, 2003; Rousseeuw and Christmann, 2003; Imon, 2006; Cizek, 2007; Imon and Hadi, 2008; Habshah and Syaiba, 2012).
The term of outliers have very close ties with high leverage points. The outliers which are severely outlying in the response as well as in covariate space produce large residuals with respect to the fitted values can be classified as one type of high leverage points called bad leverages (Croux and Haesbroeck, 2003). In addition, Hao (1992) illuminated that outlier need not to be outlying (in space of Y or X) in the sense of having large influence to model fit by departing away from the fitted pattern set by rest of data. Therefore, the outliers have similar adverse effect with the high leverage points on parameter estimates and the error variances of the logistic regression line to some degrees, consequently their presence can mislead the model fit and interpretation.
Logistic regression model is a special case of generalized linear model, where usual approach to outlier detection is based on deviances, Pearson residuals and standardized Pearson residuals. There are a number of diagnostic tools based on these measures can be found in the literatures (Pregibon, 1981, 1982; Jennings, 1986; Pierce and Schafer, 1986; William and Aelst, 2005; McCullagh and Nelder, 1989; Bedrick and Hill, 1990; Ryan, 1997; Hosmer and Lemeshow, 2000; Sarkar et al., 2011). These methods, however, are successful only if the data contain a single outlier. Hampel et al. (1986) claimed that real data normally contains about 1-10% outliers and even the highest quality of real data is not free from outliers. Therefore, similar approaches for single case detection to be applied to a group case detection are faulty due to masking and swamping effects. The effect of masking can be seen when the diagnostic methods fail to detect all outliers correctly. In contrast to masking effect, swamping effect occurs when good points are wrongly detected as outliers (Hadi and Simonoff, 1993; Imon, 2006; Imon and Apu, 2007; Imon and Hadi, 2008; Nurunnabi et al., 2010; Habshah et al., 2009; Syaiba and Habshah, 2010).
Recently, the Generalized Standardized Pearson Residual (GSPR) appears to be the most efficient method in identifying the outliers in logistic regression model. The GSPR proposed by Imon and Hadi (2008) gives very promising results if an initial deletion set include all the suspected outliers. In order to perform the initial deletion set, one might suggest to apply robust estimator or to use graphical method. Croux and Haesbroeck (2003) noted that robust estimators for logistic regression are computationally expensive. Meanwhile, the outliers are more difficult to detect especially when the number of covariates is high in the model (Nurunnabi et al., 2010; Syaiba and Habshah, 2010).
In this study, the Robust Logistic Diagnostic (RLGD) method proposed by Syaiba and Habshah (2010) is employed to detect the high leverage points in logistic regression model. The RLGD is applied at the beginning of analysis to detect all the suspected outliers which hold same behaviour with the high leverage points and to assign new weights for the outliers in constructing alternative version of the GSPR method, namely the Modified Standardized Pearson Residual (MSPR).
MATERIALS AND METHODS
Logistic regression model: In this model, we would like to predict the probabilities that the response Y takes either value 0 or 1. Let π denote the probability of occurrence that Y = 1 when X = x. The probability is modelled as:
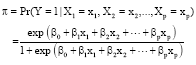 | (1) |
The Eq. 1 is called the logistic regression function where the range of values of π is 0≤π≤1. The function is nonlinear in the parameters β0, β1, β2, …, βp. However, it can be linearized by the logit transformation. Since:
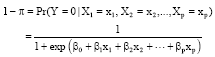 | (2) |
Then, the odds ratio or the probability of non-occurrence is:
| (3) |
Taking the natural logarithm of both sides of Eq. 3, we obtain:
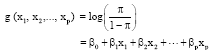 | (4) |
The logarithm of the odds ratio is called the logit where the range of values of is logit (π) is -∝≤logit (π)≤∝.
Suppose we have a sample of n observations with k = p+1 regression coefficients. Let the model in Eq. 1 is written in terms of Y as:
| (5) |
Here, Y is an n×1 vector of responses, X is an nxk matrix of covariates, βT = (β0, β1, β2, …, βp) is the vector of regression coefficients and ε is an n×1 vector of unobserved random errors. The fitted values in logistic regression model are calculated for each covariate which depend on the estimated probability for that covariates, denoted as ![]() . Thus, the ith residuals are defined as:
. Thus, the ith residuals are defined as:
| (6) |
In logistic regression, the fitting is carried out by working with the logit. The widely used method estimation is the maximum likelihood method. The maximum likelihood estimates are obtained numerically using iterative procedure. The iterative estimates of ![]() are obtained as:
are obtained as:
| (7) |
where, V is a diagonal matrix with elements of ![]() .
.
Identification of single outlier: In this section, we will briefly review the identification methods for a single outlier. We begin with hat matrix for logistic regression derived by Pregibon (1981) from linear approximation to the fitted values which is:
| (8) |
where, V is an n×n diagonal matrix with elements of ![]() . Leverage values are diagonal elements of the hat matrix, H are defined as:
. Leverage values are diagonal elements of the hat matrix, H are defined as:
| (9) |
where, xTi = (1, x1i, x2i, …, xpi) is the 1xk vector of observations corresponding to ith case.
Commonly, the residuals as defined in Eq. 6 are purposely used to measure the extent of ill-fitted of covariate patterns by examining any observation that possesses large residual to be suspected as outlier. However, the residuals are not appropriate to be used since they are unscaled. Since the response take only the values 0 and 1, the residual may assume one of the two possible values, if yi = 1 then ![]() = 1-
= 1-![]() with probability
with probability ![]() and if yi = 0 then
and if yi = 0 then ![]() = -
= -![]() with probability 1-
with probability 1-![]() . Moreover, the distribution of residuals is not well determined. A scaled version of the residuals is Pearson residuals which are elements of the Pearson chi-square goodness-of-fit statistic. In logistic regression, there are binomial errors which mean, the error variance
. Moreover, the distribution of residuals is not well determined. A scaled version of the residuals is Pearson residuals which are elements of the Pearson chi-square goodness-of-fit statistic. In logistic regression, there are binomial errors which mean, the error variance ![]() is a function of the conditional mean. The Pearson residuals for ith covariate pattern are given by:
is a function of the conditional mean. The Pearson residuals for ith covariate pattern are given by:
| (10) |
Any observation which correspond to Pearson residual exceeds |ri|>c is called an outlier. Perhaps c = 3 could be a reasonable choice that matches with 3σ distance rule used in the normal theory as mentioned by Ryan (1997). Imon and Hadi (2008) pointed out that the cut-off point c = 3 identify too many observations as outliers as they suggested to follow Chen and Liu (1993) by considering c as a constant from 3 to 5. The Pearson residuals do not have variance equal to 1. A better approach is to use a standardized version of the residuals, called Standardized Pearson Residuals (SPR) which are defined as:
| (11) |
with |rsi|>3 as a cut-off point to declare that the ith observation as an outlier.
Generalized standardized pearson residual: Imon and Hadi (2008) proved that the GSPR method is successful method in handling outliers compared to the current methods and this method is also free from the effect of masking and swamping. The GSPR is a group-deleted version of the residuals. Assume that d observations among a set of n observations are omitted before the fitting of the model. Denote a set of cases ‘remaining’ by R and a set of cases ‘deleted’ by D. Hence, R contains (n-d) cases with good observations after d cases with suspected outliers in D are deleted. Set D are allocated at the last of d rows of X, Y and V, yielding:
We estimate the coefficients, ![]() after all the suspected outliers in set D is excluded. Thus, the fitted values can be written as:
after all the suspected outliers in set D is excluded. Thus, the fitted values can be written as:
| | (12) |
Then, the respective ith deletion of residuals ![]() (-D) = yi-
(-D) = yi-![]() (-D), variances vi(-D) =
(-D), variances vi(-D) = ![]() (-D)(1-
(-D)(1-![]() (-D)) and leverages hi(-D) =
(-D)) and leverages hi(-D) = ![]() (-D)(1-
(-D)(1-![]() (-D))xTi (XTRVRXR)-1 xi for the entire data are computed. The residuals that are used for fitting the model should be computed differently. This idea was pointed out for linear regression model by Hadi and Simonoff (1993). They recommended to use scaled residuals as follows:
(-D))xTi (XTRVRXR)-1 xi for the entire data are computed. The residuals that are used for fitting the model should be computed differently. This idea was pointed out for linear regression model by Hadi and Simonoff (1993). They recommended to use scaled residuals as follows:
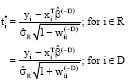 | (13) |
This type of scaled residuals is extensively used in regression diagnostics (Atkinson, 1994; Munier, 1999; Imon, 2005). Using the above scaled residuals and also by using linear regression model approximation, Imon and Hadi (2008) defined the GSPR as:
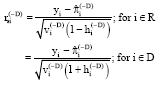 | (14) |
The declaration of an observation as outlier is when its corresponding GSPR value exceed the cut-off point of |rsi(-D)|>3.
In the initial detection process to perform on set D, it is very important to ensure that none of suspected outliers remain in set R. The GSPR may not work properly if this condition fails. Many approaches have been considered for initial detection. Cook and Hawkins (1990) noted that robust methods prone to swamp inliers as outliers. Imon and Hadi (2008) suggested to apply robust methods e.g. Least Median Squares (LMS), Least Trimmed Squares (LTS), the Block Adaptive Computationally Efficient Outlier Nominator (BACON) or best omitted from the ordinary least squares techniques (BOFOL). Imon and Hadi (2008) declared the observations as outliers when |rsi(-Do)|>3.
Robust logistic diagnostic: As already mentioned, Imon and Hadi (2008) developed a generalized version of standard Pearson residuals based on group deletion for identifying of outliers. They have shown through some real examples that the GSPR values correctly identify all the outliers and not affected by the masking and swamping problems. They also highlighted an important issue that need to be considered before performing the GSPR method. As an alternative procedure to robust method or graphical technique used in the GSPR, we propose to use the robust logistic diagnostic (RLGD) by Syaiba and Habshah (2010) as initial detection process to form deleted set D.
Let:
Thus, group deleted distance from mean based on group deleted cases D is:
| (15) |
The value of Eq. 15 is computed using ![]() after completing the first stage of the RLGD method and xiT = [1, x1i, x2i, …, xpi] is the 1xk vector of observations corresponding to the ith case. The relationship between potential values proposed by Hadi (1992) and Eq. 1 gives:
after completing the first stage of the RLGD method and xiT = [1, x1i, x2i, …, xpi] is the 1xk vector of observations corresponding to the ith case. The relationship between potential values proposed by Hadi (1992) and Eq. 1 gives:
| (16) |
Then, the group deleted potential is defined by:
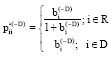 | (17) |
Since the distribution of pii·(-D) is not determined, we apply cut-off point based on median and Median Absolute Deviation (MAD) for pii·(-D) as suggested by Hadi (1992). The MAD for pii·(-D) is computed by:
| (18) |
and the cut-off point with the constant c = 3 is given as:
| (19) |
Hence, any observation corresponding to excessively large potential values with above cut-off point, shall be declared as high leverage points. The step of RLGD method is summarized as follows:
| Step 1: | For each ith point, compute Robust Mahalanobis Distance (RMD) either using Minimum Covariance Determinant (MCD) or Minimum Volume Ellipsoid (MVE) estimators |
| Step 2: | An ith point with RMDi>Median(RMDi)+ cMAD(RMDi), are suspected as high leverage points and will be included in the deleted set D |
| Step 3: | Based on the remaining points in set R, compute the pii·(-D) |
| Step 4: | Any deleted points with pii·(-D)>Median(pii·(-D))+ cMAD(pii·(-D)) are finalized and declared as high leverage points |
Modified standardized pearson residual: Our proposed method is called the Modified Standardized Pearson Residual (MSPR). The MSPR serves as an alternative method to the GSPR. Firstly, the RLGD is utilized to identify the suspected high leverage points. Then, we form a deletion set and estimate ![]() of the MLE. Thus, the MSPR for group deleted residual is computed as follows:
of the MLE. Thus, the MSPR for group deleted residual is computed as follows:
| (20) |
We shall call the above new measure as MSPR1. The RLGD also used to determine weights for the Weighted Maximum Likelihood Estimator (WMLE). We define the weight as:
| (21) |
where, p is the number of parameter excluding the intercept terms. The Eq. 21 was first introduced by Hubert and Rousseeuw (1997). They computed positive weights wi = min{1, p/RMD(xi)2} based on the RMD. Thus, iterative estimates of ![]() are then obtained as follow:
are then obtained as follow:
| (22) |
Now, the MSPR for WMLE is computed as follows:
| (23) |
We shall call the above new measure as MSPR2. Therefore, for the MSPR1 value and MSPR2 value, the cut-off point to declare the ith observation as outliers are |rsiMLE(-D)|>3 and |rsiWMLE|>3.
Detail steps of the MSPR1 method are described as follows:
| Step 1: | For each ith point, compute pii·(-D) |
| Step 2: | Suspected high leverage points are included in the set D. The remaining points are put into the set R |
| Step 3: | Based on set R, estimate |
| Step 4: | Any points with |
Meanwhile for the MSPR2 method:
| Step 1: | For each ith point, compute pii·(-D) |
| Step 2: | Based on pii·(-D), compute weight wiRLGD |
| Step 3: | Estimate |
| Step 4: | Any points with |rsiWMLE|>3 are finalized and declared as outliers |
RESULTS AND DISCUSSION
The usefulness of the proposed MSPR1 and MSPR2 methods is investigated on two well-known data sets and their performance is compared to the SPR and the GSPR methods. The evaluation is based on number of outliers that can be correctly detected by these identification methods.
The modified prostate cancer data: We first consider the modified prostate cancer data with a single regressor given by Imon and Hadi (2008). Here, we are interested to determine whether an elevated level of Acid Phosphate (AP) in the blood serum would contribute for predicting whether prostate cancer patients had Lymph Nodes Involvement (LNI). Ryan (1997) pointed out that the original data set on 53 cancer patients contain a single outlier at observation 24, Z24(y,x) = (0,186). Imon and Hadi (2008) modified this data by putting two more outliers in variables AP for observation 54, Z54(y,x) = (0,200) and observation 55, Z55(y,x) = (0,220).
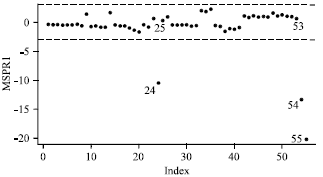
Many authors claimed that modified prostate cancer data contains three outliers for cases (24, 54 and 55). The index plot of AP for modified prostate cancer data (Fig. 1) clearly reveals those observations 24, 54 and 55 are outlying in both Y and X spaces and may severely break the covariate pattern. Hence, we consider these three points as outliers. From the RLGD(MCD) method, we manage to detect observations 24, 25, 53, 54 and 55 as high leverage points. Our initial detection result includes observations 24, 25, 53, 54 and 55 as illustrated by Fig. 1. Then, we apply the MSPR1 and the MSPR2 to identify the outliers. We also compared the results with the GSPR and the SPR methods.
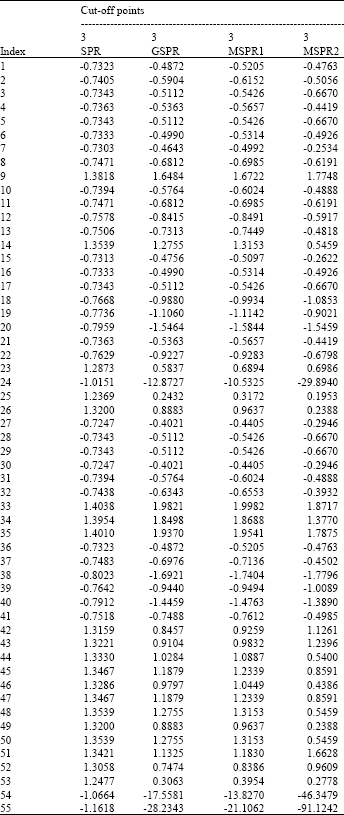
Table 1 present the outliers diagnostic for the modified prostate cancer data. Setting the cut-off point as 3 in absolute terms for detection methods, we observe that from this table, the single detection of classical SPR failed to identify even a single outlier.
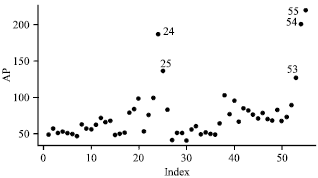 | |
| Fig. 1: | Index plot of AP for modified prostate cancer data |
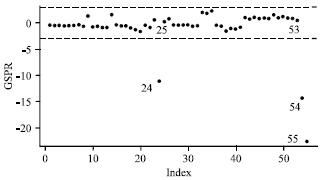 | |
| Fig. 2: | Index plot of GSPR for modified prostate cancer data |
 | |
| Fig. 3: | Index plot of MSPR1 for modified prostate cancer data |
As to be expected, our alternative method of the MSPR1 and the MSPR2 and the GSPR method give similar results and successfully detect three outliers (cases 24, 54 and 55).
Similar conclusions may be drawn from the index plot of the GSPR (Fig. 2) and the MSPR1 (Fig. 3). All three suspected cases are clearly separated from the rest of the data and correctly identified as outliers. From the initial detection by RLGD(MCD), we also identify case 25 and case 53 in order to perform initial deletion set, but these cases do not appear as outliers after applying the MSPR1, the MSPR2 and the GSPR methods. We suspect that cases 25 and 53 as high leverage points but having small influence to model fit.
| Table 1: | Outliers diagnostics for modified prostate cancer data |
 | |
| SPR: Standardized Pearson residuals, GSPR: Generalized standardized Pearson residual, MSPR: Modified standardized Pearson residual | |
The modified vaso-constriction skin digits data: We now consider the modified vaso-constriction skin digits data given by Imon and Hadi (2008). The original data set were obtained to study the effect of the rate (RATE) and volume of air inspired (VOL) on the occurrence or non occurrence of vaso-constriction skin digits after air inspiration.
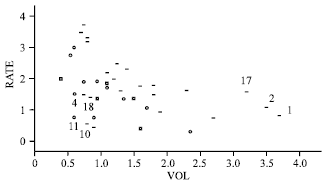 | |
| Fig. 4: | Scatter plot of RATE vs. VOL for modified vaso-constriction skin digits data |
This data is difficult to handle due to the presence of outliers which are not outlying in the Y space. At the same time, existence of estimation is highly dependent on these points. Pregibon (1981) pointed out that the original data might contain two outliers, namely observation 4, ![]() and observation 18,
and observation 18, ![]() . Croux and Haesbroeck (2003) detected the same observations as outliers in their study. They noted that observation 4 and 18 can be classified as influential observations for the MLE, therefore, deleting these points may leads to a data set whose overlap relies only on these observations. Imon and Hadi (2008) modified this data by putting two more outliers for observation 10,
. Croux and Haesbroeck (2003) detected the same observations as outliers in their study. They noted that observation 4 and 18 can be classified as influential observations for the MLE, therefore, deleting these points may leads to a data set whose overlap relies only on these observations. Imon and Hadi (2008) modified this data by putting two more outliers for observation 10, ![]() and observation 11,
and observation 11, ![]() , where the non-occurrences are replaced by occurrences.
, where the non-occurrences are replaced by occurrences.
Figure 4 presents the character plot of the modified vaso-constriction skin digits data where RATE is plotted against VOL and the character corresponding to occurrence Y = 1 and non-occurrences Y = 0 are denoted by symbols of triangle and circle, respectively. Looking at the pattern of occurrence and non-occurrence in relation to RATE and VOL, we observe that observations 4, 10, 11 and 18 are suspected as outliers and observations 1, 2 and 17 are suspected high leverage points by the RLGD(MCD) at the initial detection stage. Then we perform the deletion set, that consist of cases 1, 2, 4, 10, 11, 17 and 18.
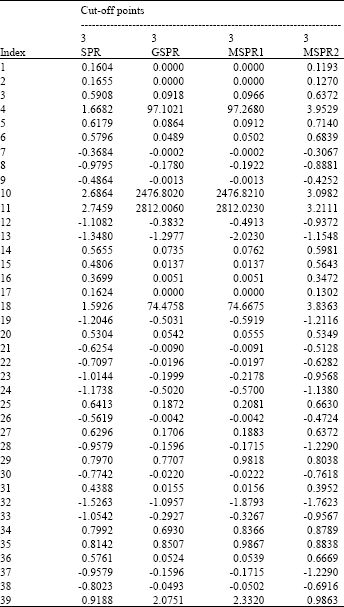
Table 2 presents the outliers diagnostic for the modified vaso-constriction skin digits data. We observe from this table, that the classical SPR failed to identify even a single outlier. As to be expected, our alternative method of the MSPR1, the MSPR2 and the GSPR proposed by Imon and Hadi (2008) perform similar results and successfully detect four outliers (cases 4, 10, 11 and 18). We observed that the MSPR1 performs better compared to MSPR2 for the modified vaso-constriction skin digits data by looking at the MSPR2 values which are closer to the cut-off point 3.
| Table 2: | Outliers diagnostics for modified vaso-constriction skin digits data |
 | |
| SPR: Standardized Pearson residuals, GSPR: Generalized standardized Pearson residual, MSPR: Modified standardized Pearson residual | |
It is evident that down weighting scheme for the high leverage points are less efficient for influential observations (Nurunnabi et al., 2010). These four observations (cases 4, 10, 11 and 18) are not outlying in covariate space but are considered as outliers as mentioned by Croux and Haesbroeck (2003).
Similar conclusion may be drawn from the index plot of the GSPR (Fig. 5) and the MSPR1 (Fig. 6). All four suspected cases are clearly separated from the rest of the data and correctly identified as outliers. At the initial detection by RLGD(MCD), we omit cases (1, 2, 4, 10, 11, 17 and 18) in order to perform initial deletion set. Then, after applying the GSPR and the MSPR1 methods, we observe that case 10 and case 11 are highly influential to fitted values by looking at the GSPR and the MSPR1 values which are far from the cut-off points 3 while case 4 and case 18 are less influential to fitted values.
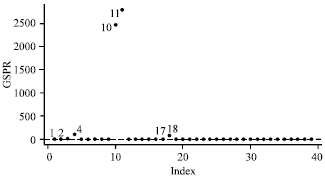 | |
| Fig. 5: | Index plot of GSPR for modified vaso-constriction skin digits data |
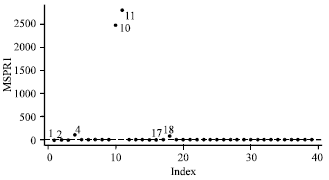 | |
| Fig. 6: | Index plot of MSPR1 for modified vaso-constriction skin digits data |
It seems that cases 1, 2 and 17 are the suspected high leverage points but may not be the outliers.
Monte Carlo simulation study: A simulation study is carried out in order to further assess the performance of GSPR, MSPR1 and MSPR2 with the cut-off points 3 in absolute terms. The performance of these methods is evaluated based on probability of the Detection Capability (DC) and probability of the False Alarm Rate (FAR) (Kudus et al., 2008). We conducted a similar simulation study to the RLGD method as discussed in Syaiba and Habshah (2010). The RLGD method is applied with the 50% breakdown point of MCD estimator and median and MAD cut-off point, setting c as 3. The choice for sample size starting with n = 100 is to ensure the existence and stability of the MLE as recommended by Victoria-Feser (2002). We considered different percentage of contaminations denoted as s, such that s = (50, 10, 15, 20%). In Type 1 data (uncontaminated), x are generated according to a standard normal distribution, x1~N(0, 1) and x2~N(0, 1) with the error terms is generated according to logistic distribution, εi~∧(0, 1).
| Table 3: | The measures of performance on the diagnostic methods on moderate contamination |
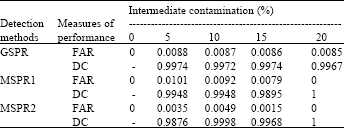 | |
| GSPR: Generalized standardized Pearson residual, MSPR: Modified standardized Pearson residual, FAR: Probability of false alarm rate, DC: Probability of detection capability | |
The response y is generated in the following manner:
| (24) |
Meanwhile, for Type 2 (5% intermediate contamination), z are generated according to a same standard normal distribution, z1~N(0, 1) and z2~N(0, 1) with magnitude of outlying shift distance in X-space is taken as δ = 5, respectively. Now, new contaminated data, x* are written as x*1 = z1+δ and x*2 = z2-δ with the error εi~∧(0, 4). The response is defined as the following model equations:
| (25) |
The last Type 3 (5% extreme contamination) followed Type II procedure with magnitude of outlying shift distance in X-space is given as δ = 10. We set the true parameters as β = (β0, β1, β2)T = (0.5, 1, -1)T. The simulation for each detection method is computed over M = 1000 replications. The FAR gives probabilities of swamping occur, meanwhile the DC gives probabilities of masking occur for the GSPR, MSPR and MSPR2 methods. For every repetition, these detection methods assigned the outliers with weights wi = 1 and wi = 0 for good observations. Then, ![]() is denoted as average for weights of the uncontaminated
is denoted as average for weights of the uncontaminated ![]() and
and ![]() is average for weights of the contaminated,
is average for weights of the contaminated, ![]() . Hence, the probabilities of FAR and DC can be computed as
. Hence, the probabilities of FAR and DC can be computed as ![]() and
and ![]() . A criterion for ‘good’ diagnostic method is based on which detection method has probability of the FAR closest to 0 and the DC closest to 1. Result on the simulation study in the identification of the outliers for the GSPR, MSPR1 and MSPR2 are shown as follows:
. A criterion for ‘good’ diagnostic method is based on which detection method has probability of the FAR closest to 0 and the DC closest to 1. Result on the simulation study in the identification of the outliers for the GSPR, MSPR1 and MSPR2 are shown as follows:
A ‘good’ method of identifying the outliers is the method which performs the probability of DC closer or exactly 1 and the probability of FAR closer or exactly 0. In this simulation study, we consider two covariates in the model. Refer to Table 3 and Table 4, all detection methods give good results.
| Table 4: | The measures of performance on the diagnostic methods on extreme contamination |
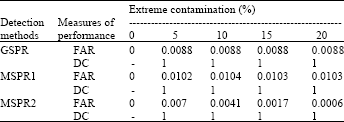 | |
| GSPR: Generalized standardized Pearson residual, MSPR: Modified standardized Pearson residual, FAR: Probability of false alarm rate, DC: Probability of detection capability | |
In the 20% of intermediate contamination, the MSPR1 and the MSPR2 performs slightly better compared to the GSPR with DC value exactly 1 and FAR value exactly 0. In the extreme outliers, the MSPR2 is the best detection method followed by the GSPR and the MSPR1. It is important to note here, our simulation results are different compared to real data results regarding on the MSPR1 and MSPR2. From real examples, the MSPR1 shows better performance compared to MSPR2. Meanwhile, in simulation examples, we intended to investigate the usefulness of down weighting scheme in the MSPR2 by generating the outliers which are outlying in X space and highly influential to fitted values. Therefore, in simulation examples, down weighting scheme in the MSPR2 method works better compared to the MSPR1 method.
CONCLUSION
The main focus of this study was to develop an alternative method for identification of outliers in logistic regression model. The commonly used SPR only good for identification of single outlier but failed to detect multiple outliers. The GSPR successfully identify multiple outliers in a data, but the accomplishment of the GSPR depends on the initial deleted set. In this study, two alternative methods were proposed namely the MSPR1 and MSPR2 based on the RLGD. From the numerical examples on modified prostate cancer data and modified vaso-constriction skin digits data, the GSPR, MSPR1 and MSPR2 identify all the outliers correctly. The simulation results indicate that the MSPR2 have slightly better detection probability and have false alarm rate up to 20% of contamination data set for two covariates in the model. Generally, the GSPR, MSPR1 and MSPR2 perform equally good in identifying the outliers in logistic regression model.
REFERENCES
- Atkinson, A.C., 1994. Fast very robust methods for the detection of multiple outliers. J. Am. Stat. Assoc., 89: 1329-1339.
Direct Link - Bedrick, E.J. and J.R. Hill, 1990. Outlier tests for logistic regression: A conditional approach. Biometrika, 77: 815-827.
CrossRefDirect Link - Chen, C. and L.M. Liu, 1993. Joint estimation of model parameter and outliers effect in time series. J. Am. Stat. Assoc., 88: 284-297.
Direct Link - Cook, R.D. and D.M. Hawkins, 1990. Unmasking multivariate outliers and leverage points: Comment. J. Am. Stat. Assoc., 85: 640-644.
Direct Link - Croux, C., C. Flandre and G. Haesbroeck, 2002. The breakdown behaviour of the maximum likelihood estimator in the logistic regression model. Stat. Probab. Lett., 60: 377-386.
CrossRef - Croux, C. and G. Haesbroeck, 2003. Implementing the bianco and yohai estimator for logistic regression. Comput. Statist. Data Anal., 44: 273-295.
CrossRef - Habshah, M., M.R. Norazan and A.H.M.R. Imon, 2009. The performance of diagnostic-robust generalized potentials for the identification of multiple high leverage points in linear regression. J. Applied Statist., 36: 507-520.
Direct Link - Hadi, A.S., 1992. A new measure of overall potential influence in linear regression. Comput. Statist. Data Anal., 14: 1-27.
CrossRef - Hadi, A.S. and J.S. Simonoff, 1993. Procedure for the identification of multiple outliers in linear models. J. Am. Statistical Assoc., 88: 1264-1272.
Direct Link - Hubert, M. and P.J. Rousseeuw, 1997. Robust regression with both continuous and binary regressors. J. statist. Plann. inference, 57: 153-163.
Direct Link - Imon, A.H.M.R., 2005. Identifying multiple influential observations in linear regression. J. Applied Statist., 32: 929-946.
CrossRef - Imon, A.H.M.R. and A.S. Hadi, 2008. Identification of multiple outliers in logistic regression. Commun. Statist. Theory Meth., 37: 1697-1709.
CrossRef - Jennings, D.E., 1986. Outliers and residual distributions in logistic regression. J. Am. Statist. Assoc., 81: 987-990.
Direct Link - Nurunnabi, A.A.M., A.H.M.R. Imon and M. Nasser, 2010. Identification of multiple influential observations in logistic regression. J. Applied Stat., 37: 1605-1624.
Direct Link - Pierce, D.A. and D.W. Schafer, 1986. Residuals in generalized linear models. J. Am. Stat. Assoc., 81: 977-986.
Direct Link - Pregibon, D., 1982. Resistants fits for some commonly used logistic regression models with medical applications. Biometrics, 38: 485-498.
PubMed - Rousseeuw, P.J. and A. Christmann, 2003. Robustness against separation and outliers in logistic regression. J. Comput. Stat. Data Anal., 43: 315-332.
CrossRef - Sarkar, S.K., H. Midi and S. Rana, 2011. Detection of outliers and influential observations in binary logistic regression: An empirical study. J. Applied Sci., 11: 26-35.
CrossRefDirect Link - Syaiba, B.A. and M. Habshah, 2010. Robust logistic diagnostic for the identification of high leverage points in logistic regression model. J. Applied Sci., 10: 3042-3050.
CrossRef - William, G. and S.V. Aelst, 2005. Fast and robust boostrap for LTS. Comput. Stat. Data Anal., 48: 703-715.
CrossRef