
N. Jamil
College of Information and Technology, Universiti of Tenaga Nasional, KM7, Jalan IKRAM-UNITEN, Serdang, 43600 Selangor, Malaysia
R. Mahmod
Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, 43600 Seri Kembangan, Selangor, Malaysia
M.R. Z`aba
Cryptography Lab., MIMOS Berhad, Technology Park Malaysia, 57000 Bukit Jalil, Kuala Lumpur, Malaysia
N.I. Udzir
Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, 43600 Seri Kembangan, Selangor, Malaysia
Z.A. Zukarnain
Faculty of Computer Science and Information Technology, Universiti Putra Malaysia, 43600 Seri Kembangan, Selangor, Malaysia
Journal of Applied Sciences
Year: 2013 | Volume: 13 | Issue: 5 | Page No.: 673-682







ABSTRACT
Hash function is an important cryptographic primitive used in a wide range of applications, for example, for message authentication and in digital signatures. MD 4/5 and SHA-0/1/2 are examples of widely used hash functions, but except for SHA-2 (SHA-224, 256, 384, 512), they were all broken in 2005 after more than a decade of use. Since, then, the structure and components of cryptographic hash functions have been studied and revisited extensively by the cryptographic community. STITCH-256 was introduced to overcome problems faced by the MD- and SHA-family hash functions. STITCH-256 employs the Balanced Feistel network and its step operation runs in four parallel branches. The algorithm was claimed to produce good diffusion and its outputs were claimed to be random. To evaluate its suitability for such purposes, avalanche and empirical statisti- cal tests are commonly employed to show that there is empirical evidence supporting the claims. In this study, we report on the studies that were conducted on the 1000 sample of 256 bit of output from STITCH-256 algorithm. The studies include the study of diffusion and statistical properties of STITCH-256 using avalanche test and nine statistical tests. The results suggest that the claims were true where STITCH-256 produces good avalanche effect, thus good diffusion property and its outputs appear random.
PDF Abstract XML References Citation
Received: March 26, 2013;
Accepted: May 07, 2013;
Published: June 28, 2013
How to cite this article
N. Jamil, R. Mahmod, M.R. Z`aba, N.I. Udzir and Z.A. Zukarnain, 2013. Diffusion and Statistical Analysis of STITCH-256. Journal of Applied Sciences, 13: 673-682.
DOI: 10.3923/jas.2013.673.682
URL: https://scialert.net/abstract/?doi=jas.2013.673.682
DOI: 10.3923/jas.2013.673.682
URL: https://scialert.net/abstract/?doi=jas.2013.673.682
INTRODUCTION
Cryptographic hash function is a function f that accepts arbitrary length of input message m and produces a fixed length of output message h, f [0, 1]*→f [0, 1]n. The length of the input message can be a single byte of an alphabet or hundreds megabytes of a video file. The input message m is sometimes called pre-image and the output message h(m) is called hash value. To be used in cryptographic applications such as digital signatures, the function has to satisfy the following:
| • | Pre-image resistance: Given a hash value h(m), it is infeasible to find any message m which hashes to h(m). This property is also known as one- wayness |
| • | Second pre-image resistance: Given a hash value h(m) and its corresponding message m, it is infeasible to find another message m’ such that h(m) = h(m’) |
| • | Collision resistance: Given a hash value h(m), it is infeasible to find any two distinct messages m and m’, where m ≠ m’ such that h(m) = h(m’) |
Finding a pre-image or a second pre-image by brute force attack would require 2n operations and finding a collision by birthday attack would need approximately 2n/2. Damgard (1990) showed that the strongest property is collision resistance where preservation of collision resistance implies preservation of second pre-image resistance and preservation of second pre-image resistance implies preservation of pre-image resistance. Thus, collision resistance is the most important property for cryptographic hash function and most of the attacks were aimed at breaking this property.
The most popular and widely used hash functions are known as dedicated hash functions, whose design method is a serial successive iteration of step operation. These hash functions include MD5 (Rivest, 1992b), HAVAL (Zheng et al., 1993; FIPS 180, 1993) and SHA-1 (NIST, 1995). These hash functions are also known as MDx-class hash functions since they have some commonalities in their design, i.e., same design principle with MD4 (Rivest, 1992a). In principle, the design of MDx-class hash functions follow Merkle-Damgard iterative construction (Merkle, 1989; Damgard, 1990). In this construction, the security of the hash function H is reduced to the security of the compression function of f. However, most of the compression functions of MDx-class hash functions are light and relatively simple. This has led to the failure of these hash functions to preserve a property of collision resistance. After more than a decade of use, all of these hash functions were broken in series of attacks by Van Rompay et al. (2003), Wang et al. (2004, 2005a, b), Wang and Yu (2005), Biham et al. (2005) and Yu et al. (2006), to name a few. The successful attacks against these hash functions are differential attacks. The attacks aimed at producing zero output difference with non-zero input difference in the input messages (Wang et al., 2005c). The hash function is considered as insecure if one has successfully developed an algorithm that can vanishes such difference in its compression function. As the compression function of MDx-class hash functions is light and relatively simple, it is easy to construct differential characteristic in it that leads to collisions. This could probably due to poor diffusion in the step operation of MDx-class hash function, i.e., did not produce a good avalanche effect.
STITCH-256 (Jamil et al., 2012) was introduced to recommend a new step operation permuted in a so-called stitching permutation. The description of the step operation in STITCH-256 is given in the following section. It was claimed that the outputs of STITCH-256 appear to be random and the step operation produces good avalanche effect. To evaluate its suitability for cryptographic purposes, avalanche and empirical statistical tests are commonly employed to show that there is empirical evidence supporting the claim. In this study, we report on the studies that were conducted on the output bits from STITCH-256 algorithm. The results suggest that the claims were true and STITCH-256 is suitable to be used for cryptographic purposes.
DESCRIPTION OF STITCH-256
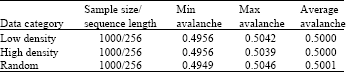
Table 1 shows the basic notation used to describe STITCH-256. STITCH-256 employs Merkle-Damgard iterative construction in order to produce a fixed size of output from arbitrary length of input and a variant of Davies-Meyer mode of operation as depicted in Fig. 1. In this variant mode of operation, it takes a message block M and the previous hash value hi. For the first iteration, the h0 is the IV. The output from left most and right most branch, B1 and B4, are then added with the previous hash value hi and output from B2 and B3. The output from this operation is then XORed together and added once again with hi. The output is hi+1. This process is repeated until all the message blocks M are processed.
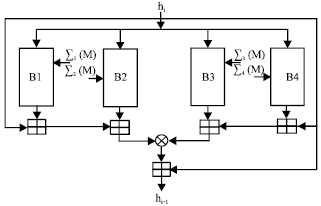 | |
| Fig. 1: | Mode of operation of STITCH-256 |
| Table 1: | Notation and description of symbols used in algorithm equations |
 | |
If the two branches on the right are denoted as a big function E1 and the two branches on the left are denoted as a different big function E2, this variant of Davies-Meyer mode can be formulated as:
| hi+1 = E1⊕E2+hi |
The update can also be seen as the hi is updated to hi+1 by computing:
| hi+1 = [hi+B1(hi, Σj,1 (M))+B2(hi, Σj,2(M ))]⊕[hi+B4 (hi, Σj,3(M))+B3(hi, Σj,4(M))]+hi |
where, Σj,i(M ) for j = 1, 2, 3, 4 and 0 = i = 15, is the sum of sixteen 32 bit message words Wi that has been rearranged according to Fig. 2. Each line needs two Σj,i(M) and they are different in each line. This gives a total of eight different orderings for the compression function.
STITCH-256 processes 512 bit blocks of input message and produces 256 bit block of hash value. The input message is first appended by a single bit 1 to the least significant bit of the input message, followed by as many zero as possible until the length of the message is 448 modulo 512 which is filled up by the 64 bit message length modulo 264.
COMPRESSION FUNCTION OF STITCH-256
The compression function of STITCH-256 runs in parallel of four branches, B1, B2, B3 and B4 as illustrated in Fig. 1. There are three main components in the compression function of STITCH-256 namely, message expansion, step operation and Boolean functions.
Message expansion of STITCH-256: The message expansion of STITCH-256 follows these formulas:
Wt = Mt for 0≤t≤15 |
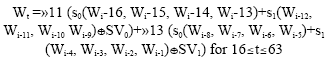 |
where, s0 (w, x, y, z) = w⊕x⊕y⊕z and s1 (w, x, y, z) = w+x+y+ z.
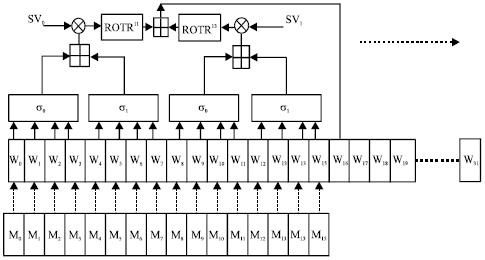
It uses two salt values to support the message expansion of STITCH-256, where SV0 = 67452301 and SV1 = 41083726. The message expansion of STITCH-256 is illustrated as in Fig. 3. In STITCH-256, the 512 bit message input is expanded to 32 bit message words.
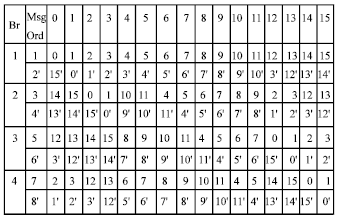 | |
| Fig. 2: | Message orderings for four branches in STITCH-256 |
This gives the output of message expansion as 1024 bits. All the message words Wi…W31 are then reordered to give different message ordering in each line. The compression function of STITCH-256 requires eight Σj (M) for the whole function as described earlier and the orderings are depicted in Fig. 3. It shows the input order of message words M0,…, M15 applied to Bj(1≤j≤4) branches. The number with an asterisk denotes the message words Wi for 16≤i≤31. This means 1’ refers to message words W16, 2’ refers to message word W17, so on and so forth.
Step operation of STITCH-256: Step operation of STITCH-256 is designed as shown in Fig. 4. The step operation of STITCH-256 can be seen as a Balanced Feistel Network where registers A, B, C, D is one half and registers E, F, G, H is the other half. Here, we simply name the division as the left and right wings, respectively. Each wing has different step operation, different Boolean functions and different constants. We divide the step operations in STITCH-256 into two phases; the first phase serves as a heavy step operation and the second phase involves only permutation. We will use the notation of left and right wings throughout this study.
In the step operations of STITCH-256, two distinct Boolean functions F3, F4 are used in the right wing and one Boolean function F2 is used in the left wing. In the right wing, the registers and message words are processed through seven steps whereas for the left wing the registers are processed through six steps, prior to the initial permutation. Registers Ai, Bi, Ci and Di are first processed in the left wing during the first phase, followed by initial permutation and finally processed in the first phase of right wing.
 | |
| Fig. 3: | Message expansion of STITCH-256 |
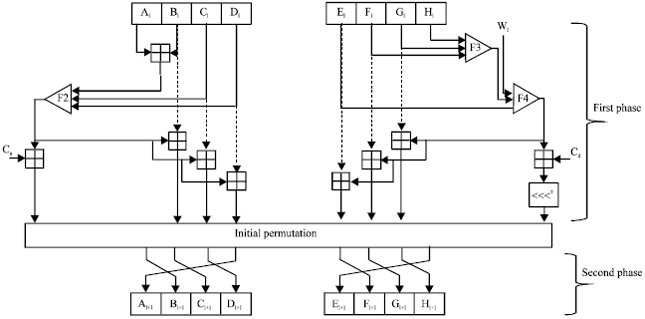 | |
| Fig. 4: | Step operation of STITCH-256 |
This means the registers are processed in two sets of non-overlapping step operations. After being processed in the right wing, registers Ai, Bi, Ci and Di are permuted in the second phase and used to update the values of Ei+1, Fi+1, Gi+1 and Hi+1. This process occurs vice versa and in parallel, for registers Ei, Fi, Gi and Hi, where they finally update the values of Ai+1, Bi+1, Ci+1 and Di+1.
Let the outputs for Ai, Bi, Ci, Di, Ei, Fi, Gi and Hi after the first stage are denoted as A’, B’, C’, D’, E’, F’, G’ and H’, respectively, defined as follows:
| A’i | = | Di+F2((Ai+Bi ), Ci, Di) |
| B’i | = | φi,j+F 2((Ai+Bi), Ci, Di ) |
| C’i | = | Bi+F2((Ai+Bi),Ci, Di) |
| D’i | = | Ci+F2((Ai+Bi), Ci, Di) |
| F’i | = | Ei+F4 (Ei, Wi, F 3(Fi, Gi, Hi)) |
| G’i | = | Fi+F 4(Ei, Wi, F 3(Fi, Gi , Hi)) |
| H’i | = | Gi+F 4(Ei, Wi, F 3(Fi,Gi ,Hi)) |
| E’i | = | «7 (φi,j+F 4(Ei, Wi, F 3(Fi, Gi , Hi)) |
A single step operation in each wing updates its new registers Ai+1, Bi+1, Ci+1, Di+1, Ei+1, Fi+1, Gi+1 and Hi+1 by producing the following outputs:
| Ai+1 | = | F2((Ei+Fi ), Gi, Hi)+Hi |
| Bi+1 | = | φi,j+F 2((Ei+Fi), Gi, Hi) |
| Ci+1 | = | F 2((Ei+Fi), Gi, Hi)+Fi |
| Di+1 | = | F 2((Ei+Fi ), Gi, Hi)+Gi |
| Ei+1 | = | «7 (φi,j,+F 4(Ai, Wi, F 3(Bi, Ci , Di))) |
| Fi+1 | = | Ai+F 4(Ai, Wi, F 3(Bi, Ci, Di)) |
| Gi+1 | = | Bi+F 4(Ai, Wi, F 3(Bi, Ci, Di)) |
| Hi+1 | = | Ci+F 4(Ai, Wi, F 3(Bi, Ci, Di)) |
where, φi,j is different for each branch and the details can be found by Jamil et al. (2012). The step operation of STITCH-256 is illustrated in Fig. 4.
As described earlier, the outputs after initial permutation in the left wing, A’, B’, C’, D’, are processed in the first phase of the right wing. They are not only permuted, but also become the new value for Ei+1, Fi+1, Gi+1, Hi+1 after the permutation in the second phase of the right wing. Then, the new values in registers E, F, G, H are iterated in the first stage of the right wing step operation, permuted and become the new value for Ai+1, Bi+1, Ci+1, Di+1. This happens similarly for the output after initial permutation in the right wing.
Note that the initial permutation is the same as the permutation in the second phase, where it permutes the registers one block to their right. The entire process looks like a stitching permutation when one views it from top. Thus it gives the name as STITCH-256. The stitching permutation is designed to maximize the propagation of intermediate chaining variables, thus lower the probability to construct differential characteristics. The stitching permutation when it is viewed from top is illustrated in Fig. 5. Finally, each wing in a branch processes sixteen message words and this makes each branch in the compression function of STITCH-256 to have only sixteen rounds of step operation.
Boolean Functions in STITCH-256: STITCH-256 derives its Boolean functions from a set of one-dimensional Cellular Automata (CA) rules (Wolfram, 1984). Table 2 shows the CA rules represented as Boolean functions, used in STITCH-256.
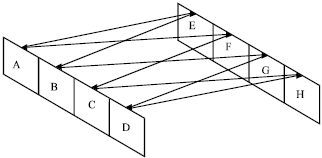 | |
| Fig. 5: | Stitching permutation in STITCH-256 |
| Table 2: | CA rules used in STITCH-256 |
 | |
AVALANCHE EFFECT OF STITCH-256
Having a strong avalanche effect is seen as a continuous effect where small differences are mapped to big differences. However, as we only work on discrete spaces here, all functions are also continuous. Therefore, continuity itself cannot be of any help for quantifying the avalanche effect. In our study, we are interested in the average behavior of the step operations of STITCH-256. Here, we present our empirical results on the effects of inducing small differences. In particular, we study the behavior of the output bits in the full round of step operations in STITCH-256 for various samples.
Experiment: In principle, any cryptographic algorithm must have a property that the redundancies at the input should not leak any information in the output. Based on this understanding, we construct three types of data sets, each having different structures. Then, we observe the avalanche effect in the output bits and observe the structure in some of the test vector samples. The types of data sets are as follows:
| • | Low density message: The low density message is a message formed by binary strings of low weight. In our case, the number of ‘1’s in the binary strings is less or equal to 3 |
| • | High density message: The high density message is a message formed by binary strings of high weight. In other words, the inputs of the low density messages are complemented bitwise |
| • | Random message: The random message is a message formed by a random distribution between bits 0 and 1 in the sequence |
For each of the data type, we prepare 1000 sequences of 512 input bits each which makes up a total of 512000x3 = 1536000 bits tested in the experiments.
Empirical results and analysis: Here, we present our empirical results on the effects of inducing a single bit difference for a full round of STITCH-256 algorithm in three different data categories. For our analysis, we chose the following parameter:
| • | The number of steps s that we consider. In our experiment, we measure the avalanche effect of STITCH-256 algorithm for s = 16 and 32 |
| • | Size δ of the induced input difference is 1. It means that we are mainly interested in a smallest value here to observe the property of Strict Avalanche Criterion (SAC) in STITCH-256 |
The changes or the effects from a single bit flip in the input are calculated and stored. Table 3 describes the breakdowns of the results obtained from the experiment conducted on three data categories.
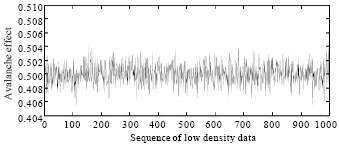
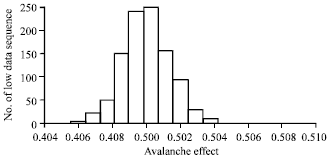
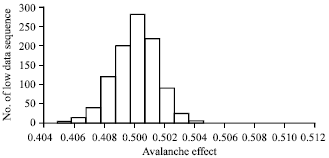
It can be seen from Table 3 the 3000 sequences of 256 bit hash values of STITCH-256 produced the desired avalanche effect and also satisfy Strict Avalanche Criterion (SAC). Figure 6 shows the avalanche effect of a single flip-ping in input bit for low density data. It can be seen that the avalanche effect for 1000 sequences of 256 bit hash values for low density data is well scattered around 0.5. Figure 7 shows the total number of 512 bit output sequences with respect to the avalanche effect. From Fig. 7, it can be seen that the avalanche effects of all the output sequences lie between 0.495-0.504. This shows that on average, half of the output bits were changed with a single input bit flipping.
The similar effect applies to the high density data and random data, where their avalanche effect for the same length of sequences and output bits are well scattered around 0.5. This is depicted in Fig. 8-11. Figure 8 shows the total number of 512 bit output sequences of high density data with respect to its avalanche effect. From Fig. 9 it can be seen that the avalanche effects of all the output sequences lie between 0.496-0.504.
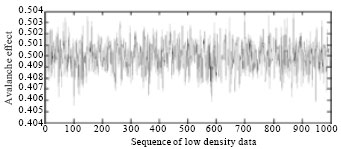 | |
| Fig. 6: | Avalanche effect for 1000 sequences of 512 bit low density data |
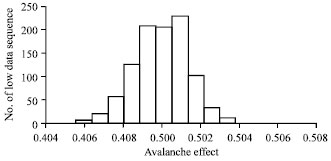 | |
| Fig. 7: | Number of 256 bit output sequences vs. avalanche effect |
 | |
| Fig. 8: | Avalanche effect for 1000 sequences of 512 bit high density data |
| Table 3: | Results from the avalanche experiments for three different data types |
 | |
This shows that, on average, half of the output bits were changed with a single input bit flipping. From Fig. 11, it can be seen that the avalanche effects of all the output sequences lie between 0.495-0.505. This shows that on average, half of the output bits were changed with a single input bit flipping in random data.
From the results of our experiment, it was shown that the output of STITCH-256 algorithm appears to provide Strict Avalanche Criterion for all three data categories.
 | |
| Fig. 9: | Number of 256 bit output sequences vs avalanche effect |
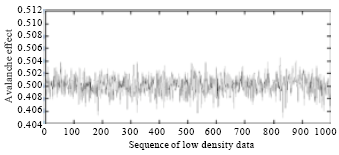 | |
| Fig. 10: | Avalanche effect for 1000 sequences of 512 bit random data |
 | |
| Fig. 11: | Number of 256 bit output sequences vs avalanche effect |
Next, we showed that stitching permutation in STITCH-256 increases the diffusion property of the algorithm. This can be seen from Fig. 12 that the avalanche factor for STITCH-256 if it runs without stitching permutation lies at 0.24-0.26. The main property in stitching permutation is it swaps the intermediate chaining variables from the left wing to the right wing and vice versa, in each iteration. It means that each register has its step operation changed every after a single iteration. This provides high bit propagation through a single iteration.
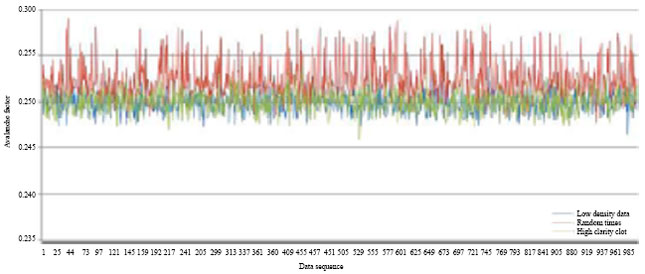 | |
| Fig. 12: | The avalanche factor for STITCH-256 without stitching permutation |
RANDOMNESS OF STITCH-256
For the outputs of the hash function to be indistinguishable from a random oracle, they have to be tested in terms of randomness tests. It means the outputs or the hash value of hash function has to be shown to be random. This evaluation of the randomness can be done by using statistical test. In our case, we consider using NIST statistical test suites that contains 15 tests that, under different data category, can be viewed as 48 statistical tests. The list of the tests are frequency test, block frequency test, runs test, long runs of ones test, rank test, discrete Fourier transform test, non-overlapping template matching test, overlapping template matching test, linear complexity test, universal statistical test, approximate entropy test, cumulative sums test, random excursion test, random excursion variant test and serial test.
Experiments: some of the tests, for example overlapping template matching test, universal statistical test, random excursion test, linear complexity test and random excursions variant test, require the sequence length to be more than 1000000 bits and Rank Test requires the sequence to be minimum 38,912 bits. Due to the hardware constraint, we only provide 768000 bits (3000 sequences of 256 bit) for the entire experiments, i.e., these six tests were not performed. Thus the appropriate NIST tests are only nine which are frequency test, block fre-quency test, runs test, long runs test, cumulative sum test, approximate entropy test, serial test, discrete Fourier transform test and non-overlapping template matching test. Table 4 shows the breakdown of the 9 statistical tests applied during the experiments.
| Table 4: | Test ID for 9 NIST statistical tests |
 | |
We use the same data categories as that used in avalanche test. A full round of STITCH-256 is run and repeated many times. The sequences of 256 bit hash values are concatenated to produce large data input to the statistical test. We follow the same procedure as described by Soto and Bassham (2000). The statistical tests are applied only to the compression functions of STITCH-256. It means that the padding procedure is omitted. The output from the experiments is 9 results for each data category. Statistical tests were performed using the strategies as follows.
Finally, we show the avalanche effect of 32 rounds of STITCH-256. This is depicted in Fig. 13. It is shown in the figure that the avalanche factors for 32 rounds of STITCH-256 have not much different from that of 16 rounds of STITCH-256. As 32 rounds incur more processing and time, STITCH-256 employs only 16 rounds with almost similar avalanche effect with 32 rounds. This provides STITCH-256 with comparable efficiency and security with other hash functions:
| Step 1: | For each data category, all input parameters such the sequence length, sample size and significance level were fixed. They are defined as 256, 256000 and 0.01, respectively. For each binary sequence and each statistical test, a p-value was reported |
| Step 2: | The status of success or failure was made based on whether or not for each p-value exceeded or fell below the pre-selected significance level |
| Step 3: | Two evaluations were made for each statistical test and each sample. Firstly, we calculated the proportion of binary sequences in a sample that passed the statistical test. The p-value for this proportion is equal to the probability of observing a value that is equal to or greater than the calculated proportion. Secondly, we calculated an additional p-value based on a χ2 test (with nine degrees of freedom) applied to the p-values in the entire sample to guarantee uniformity |
| Step 4: | An assessment was made for both steps done in step 3. A sample was considered to pass a statistical test if it satisfied both the proportion and uniformity assessments. If one of the two p-values in step 2 fell below 0.0001, then the sample is labeled as suspect. In this case, then additional samples needed to be evaluated. Otherwise, the sample is said to satisfy the criterion for being random from the perspective of a specific statistical test (Rukhin et al., 2001) |
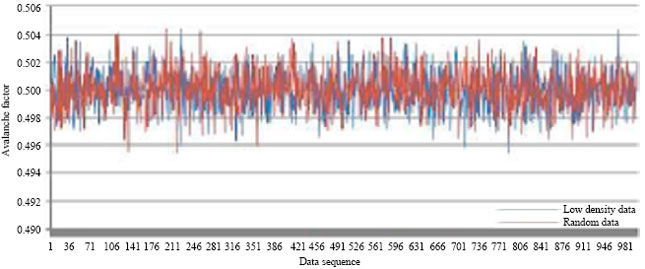 | |
| Fig. 13: | The avalanche factor for 32 rounds of STITCH-256 |
Empirical results and analysis: Given the empirical results for a particular test, we computed the proportion of sequences that pass. In our case, we tested 1000 binary sequences for each data category, i.e., m = 1000. The significance level, σ, for our experiment is set at σ = 0.01. We use the confidence interval formula defined by Soto and Bassham (2000) as:
where p = 1-σ.
 | |
| Fig. 14: | Proportion of low density sequences undergoing 9 statistical tests |
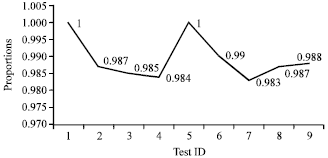 | |
| Fig. 15: | Proportion of high density sequences undergoing 9 statistical tests |
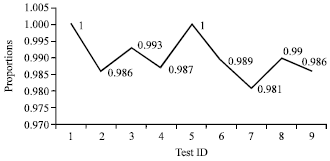
The data is classified as non-random if the calculated proportion is not in this interval. In our case, the confidence interval is 0.99±0.0094392. This means that the proportion should be above 0.980560. The calculated confidence interval is an approximation to the binomial distribution which is reasonably for m = 1000. Figure 14-16 show the proportion of sequences that undergo nine statistical tests for each of data category.
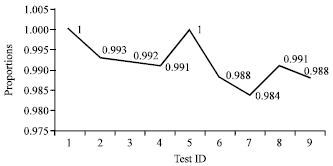 | |
| Fig. 16: | Proportion of random sequences undergoing 9 statistical tests |
From the results of the experiments, it showed that the outputs from the full round of STITCH-256 algorithm appeared to be random for all nine statistical tests.
CONCLUSION
In this study, the avalanche effect of STITCH-256 algorithm was measured by testing 3000 sequences of 256 bit hash values. The empirical results from the avalanche test showed that STITCH-256 exhibits Strict Avalanche Criterion (SAC) which is a desired property in any cryptographic algorithm. The contributing factors to this property are the implementation of different message orderings in each line in the compression function of STITCH-256 and stitching permutation which maximizes the diffusion property of STITCH-256. Finally, 3000 sequences of 256 bit hash values of different data categories were tested with NIST statistical test suites. The tests spanned many well-known cryptographic properties which have to be satisfied by any cryptographic algorithm. One of the properties included the absence of any detectable correlation between input/output pairs and also the absence of any detectable bias resulting from a single bit flip in input. Nine statistical tests were identified from the test suite that are relevant with 256 bit output from any cryptographic algorithm and run the test for three different data categories separately. The proportion of p-values of the data sequences were then computed and compared with the confidence interval. The empirical results showed that the outputs from three different data categories in full round of STITCH-256 passed all the nine tests, i.e., appeared to be random. From the avalanche and statistical tests conducted, we showed that the claim made with regards to high diffusion and random output of STITCH-256 is correct.
REFERENCES
- Rukhin, A., J. Soto, J. Nechvatal, M. Smid and E. Barker et al., 2001. A statistical test suite for random and pseudorandom number generators for cryptographic applications. NIST Special Publication 800-22, May 15, 2001, National Institute of Standards and Technology, U.S. Department of Commerce, Gaithersburg, MD., USA.
- Wang, X., X. Lai, D. Feng, H. Chen and X. Yu, 2005. Cryptanalysis of the hash functions MD4 and RIPEMD. Proceedings of the 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, May 22-26, 2005, Aarhus, Denmark, pp: 1-18.
CrossRef - Wang, X. and H. Yu, 2005. How to break MD5 and other hash functions. Proceedings of the 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, May 22-26, 2005, Aarhus, Denmark, pp: 19-35.
CrossRef - Wang, X., H. Yu and Y.L. Yin, 2005. Efficient collision search attacks on SHA-0. Adv. Cryptol., 3621: 1-16.
CrossRef