
Mohammad Nurul Azam
Department of Quantitative Analysis, College of Business Administration, King Saud University, Riyadh 11451, Kingdom of Saudi Arabia
Mahbuba Yeasmin
EKRA Institute, Melbourne, Victoria 3166, Australia
Gazi Mahabubul Alam
Academic Performance Enhancement Unit, University of Malaya, 50603 Kuala Lumpur, Malaysia
Journal of Applied Sciences
Year: 2013 | Volume: 13 | Issue: 3 | Page No.: 503-507







ABSTRACT
This study considers the problem of testing for a structural change of unknown timing in a regression coefficient in the linear regression model. This is a non-standard testing problem and practical important situation facing applied modelers. Simulation methods were used to generate a range of exact critical values of the Likelihood Ratio (LR) type test for different sample sizes, numbers of regressors and types of regressors. We found that the critical values depend on sample size, the number of regressors and to a less extend on the type of explanatory variables. We recommend using the LR type test statistic for testing structural change of unknown timing with our critical value.
PDF Abstract XML References Citation
Received: January 12, 2013;
Accepted: March 08, 2013;
Published: April 22, 2013
How to cite this article
Mohammad Nurul Azam, Mahbuba Yeasmin and Gazi Mahabubul Alam, 2013. Likelihood Ratio Type Test and its Critical Values for Structural Change of Unknown Changepoint. Journal of Applied Sciences, 13: 503-507.
DOI: 10.3923/jas.2013.503.507
URL: https://scialert.net/abstract/?doi=jas.2013.503.507
DOI: 10.3923/jas.2013.503.507
URL: https://scialert.net/abstract/?doi=jas.2013.503.507
INTRODUCTION
The presence of a structural change in data that is not detected is a hazard for applied researchers, with serious consequences for model performance and forecasting. The structural Changepoint problems have been studied by many authors (Chernoff and Zacks, 1964; Sen and Srivastava, 1975; Hawkins, 1977; Yao and Davis, 1984; Worsley, 1986; Singh and Pandey, 2011; Jothilakshmi et al., 2011; Kamurzzaman and Takeya, 2008). It is helpful to have a test for structural change when the changepoint is unknown. Andrews (1990) compared the Likelihood Ratio (LR) test with tests such as the CUSUM and CUSUM of squares tests and the fluctuation test of Sen (1980) and Ploberger et al. (1989) in terms of power. Andrews (1993) determined the asymptotic distributions of the LR test statistics under the null hypothesis of parameter stability. In modern times the likelihood ratio test studied for the simple linear regression models, such as Kim and Siegmund (1989) and Kim (1994). The asymptotic results on likelihood approach for linear models applied (Csorgo and Horvath, 1997). Guan (2004) used empirical likelihood method which was applied to detect the changepoint. There have also been extensive studies on LR test problems those can found (Koroto, 2009; Aziz et al., 2011; Midi et al., 2011).
In this study, we propose a new approach which is based on likelihood ratio type method to test the change in regression coefficient for linear model in the presence of an unknown changepoint. There are so many ways one can develop a test statistic to test for the presence of structural change when there is a possible unknown changepoint in the data. Since LR test does not have a known distribution for finite sample sizes, we estimate exact critical values for the test by simulation for different sample sizes, numbers of regressors and types of regressors.
THE MODEL
We consider the linear regression model for t = 1,…,n, with a possible change of unknown timing in one coefficient:
| (1) |
where, yt is the dependent variable at time t, xt is a kx1 vector of regressors at time t, wt is a scalar variable that is of interest, β0 is a kx1 vector of regression coefficients and γ and δ are unknown scalar parameters. ut~N(0, σ2). Model (1) can be written jointly as:
| (2) |
where, zt is a dummy variable defined as:
| (3) |
Denoting:
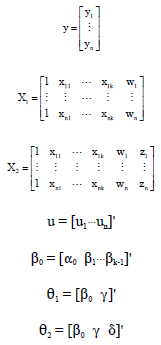 |
Model (2) can be rewritten in matrix form as:
| (4) |
Where:
TEST STATISTICS
The null hypothesis of interest is:
and the alternative hypothesis is:
The loglikelihood function of the sample under the alternative hypothesis that there is a changepoint in the data after period n1 is:
| (5) |
The loglikelihood function under the null hypothesis of no changepoint in the data is:
| (6) |
Differentiating (5) with respect to the parameters β0, γ, δ and σ22 and equating the resultant equations to zero, we obtain the conditional Maximum Likelihood (ML) estimates of β0, γ, δ and σ22 under the alternative hypothesis that there is a changepoint in the data after period n1 as:
| (7) |
Differentiating (6) with respect to the parameters β0, γ and σ21 and equating the resultant equations to zero, we obtain the ML estimates of β0, γ and σ21 under the null hypothesis that there is no changepoint in the data as:
| (8) |
Substituting the estimates of (7) into (5), we obtain the concentrated log-likelihood function under the alternative hypothesis of the sample given a changepoint in the data after period n1 as:
| (9) |
Substituting the estimated values from (8) into (6), we obtain the maximized log-likelihood function under the null hypothesis of no changepoint:
| (10) |
When the changepoint n1 is unknown, a naturally, intuitive approach would be to estimate n1 and then apply the LR test at that estimate of n1. Given n1, (9) is maximized by substituting in the estimated value of σ22 from (7). Maximizing (9) with respect to n1 is equivalent to finding the n1 for which ![]() is minimum. The LR test statistic can be obtained by substituting minimum values of
is minimum. The LR test statistic can be obtained by substituting minimum values of ![]() in (9) which we will denote by
in (9) which we will denote by ![]() and then taking twice the difference between it and the log-likelihood of (10) that is,
and then taking twice the difference between it and the log-likelihood of (10) that is, ![]() .
.
SIMULATIONS
The data yt were generated from the following equation:
where, ut~N(0,1), wt is a scalar variable, β0 is a kx1 vector of regression coefficients and γ is a constant coefficient. The kx1 independent variables are generated following (Watson and Engle, 1985). Monte Carlo experimental design; that is explanatory variables (excluding the constant term) were generated from the first order autoregressive process xit = φxit-1+eit with eit~IN (0,1) for t = 1,…,n, where φ takes values 0, 0.7, 1.0 and 1.02 which covers white noise, autoregressive, random walk and explosive processes, respectively. The number of regressors k was allowed to range from 1 to 15 in turn with φ being the same for each regressor and wt was generated from the uniform distribution with range from 0 to 1. Four different sample sizes of 25, 50, 75 and 100 were used. We generated 50,000 LR test statistics for each set of φ’s, s, k and n, then ordered the calculated LR from the lowest to the highest values and obtained the 90th, 95th, 97th and 99th percentiles which are the required critical values for the 10, 5, 2.5 and 1% level of significance, respectively. Throughout, we use the GAUSS for Windows Version 3.2.35 software to estimate the parameters of the model by the method of ML estimation. In the model, error terms were simulated using pseudo random numbers from the GAUSS function RNDNS that generates standard normal variate for regression errors. The seed for the random number generator for each experiment was 1786.
RESULTS OF THE SIMULATION
Table 1 report the critical value calculation results of the Monte Carlo simulations. We discuss the overall trends in the critical values in four stages.
| Table 1: | Empirical critical values of the LR test for different numbers of regressors and φ |
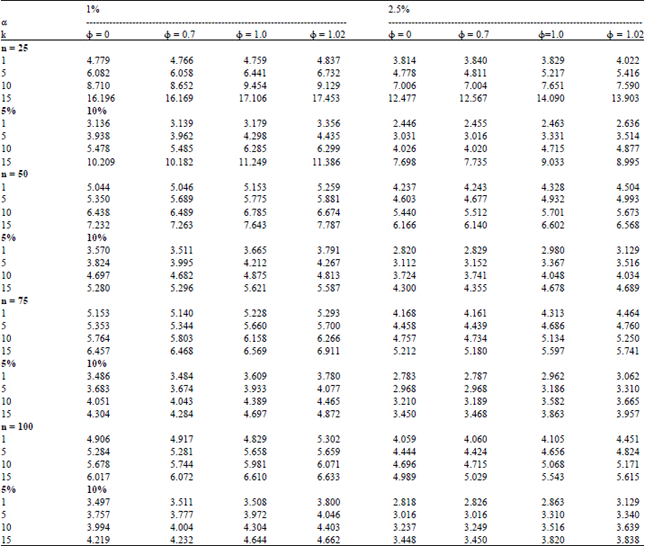 | |
The first stage involves the patterns or trends with respect to sample size variation, the second involves patterns as the number of regressors in the model changes, the third considers changes in the type of autoregressive regressors and the fourth discusses some general patterns with regard to the significance level.
A noticeable feature is that the simulated critical values of the LR test increase as the sample size increases from 25 to 75 for small k = 1 and 2 and it decreases as the sample size increases from 75 to 100 at the 1% level of significance for different values of φ considered. At the 2.5, 5 and 10% levels of significance, critical values of the LR test increase as the sample size increases from 25 to 50 and they decrease as the sample size increases from 50 to 75. They decrease as n increases from 75 to 100 for the different values of φ considered. The critical values of the LR test increase as the sample size increases for k = 3 or more at different levels of significance for different values of φ.
The largest calculated critical value of the test occurs at the 1% level of significance when φ = 1.02 and n = 25 and takes the value 17.453 whereas, when n = 100 it takes the value 6.633 The largest critical values of the test at the 2.5, 5 and 10% levels of significance occur when φ = 1.02 and n = 25 and are 13.903, 11.386 and 8.995, respectively, whereas, when n = 100, the critical values are respectively, 5.615, 4.662 and 3.838. The minimum critical values of the test statistic at the 1, 2.5, 5 and 10% levels of significance occur when φ = 0 and n = 25 and are, respectively, 4.779, 3.814, 3.136 and 2.446, whereas, when n = 100 these critical values are respectively, 4.906, 4.059, 3.497 and 2.818.
The critical values of the test almost always increase with an increase in the number of regressors k. The largest increases occur for small n and for small φ. The smallest increases occur for n = 100 and for large levels of significance. For a large number of regressors in the model when φ = 0 and k = 15 at the 1, 2.5, 5 and 10% levels of significance, the maximum value of the critical values are 16.196, 12.477, 10.209 and 7.698, respectively.
The simulated critical values of the LR type test statistic appear to be practically unchanged as the type of autoregressive regressors change with everything else held constant. The critical values are typically the same for φ = 0 and for φ = 0.70 at different levels of significance and are also roughly the same for φ = 1.0 and φ = 1.02. The latter are almost always slightly bigger than the former. Obviously the critical values decrease as the level of significance increases. This decrease is largest for large k. This variation in critical values with n, k, φ and α suggests the need for formulae for critical values of the test statistic which will be developed in the next section.
CONCLUSION
While there are so many ways to develop a test statistic to test for the presence of structural change when there is a possible unknown changepoint in the data, we recommend the use of the LR test. Since this test does not have a known distribution for finite sample sizes, we estimated exact critical values for the test by simulation using 50,000 replications for different sample sizes, numbers of regressors and types of regressors. We found that the critical values clearly depend on sample size, the number of regressors and to a less extend on the type of explanatory variables. Further research direction is how to make inference about the changepoint n1 when parameters of the models have to be estimated.
REFERENCES
- Aziz, D., S.S. Siraj, S.K. Daud, J.M. Panandam and M.F. Othman, 2011. Genetic diversity of wild and cultured populations of Panaeus monodon using microsatellite markers. J. Fish. Aquat. Sci., 6: 614-623.
CrossRefDirect Link - Andrews, D.W.K., 1993. Tests for parameter instability and structural change with unknown change point. Econometrica, 61: 821-856.
Direct Link - Chernoff, H. and S. Zacks, 1964. Estimating the current mean of a normal distribution which is subjected to changes in time. Ann. Math. Stat., 35: 999-1018.
Direct Link - Hawkins, D.M., 1977. Testing a sequence of observations for a shift in location. J. Am. Statist. Assoc., 72: 180-186.
CrossRef - Jothilakshmi, M., D. Thirunavukkarasu and N.K. Sudeepkumar, 2011. Structural changes in livestock service delivery system: A case study of India. Asian J. Agric. Res., 5: 98-108.
CrossRefDirect Link - Kamurzzaman, M. and H. Takeya, 2008. Importance, structural change and factors affecting production of vegetables in Bangladesh. Int. J. Agric. Res., 3: 397-406.
CrossRefDirect Link - Kim, H.J., 1994. Likelihood ratio and cumulative sum tests for a change-point in linear regression. J. Multivariate Anal., 51: 54-70.
CrossRefDirect Link - Kim, H.J. and D. Siegmund, 1989. The likelihood ratio test for a change-point in simple linear regression. Biometrika, 76: 409-423.
Direct Link - Koroto, T., 2009. An approximate likelihood ratio method for testing equality of two dependent proportions. Asian J. Math. Stat., 2: 15-19.
CrossRefDirect Link - Ploberger, W., W. Kramer and K. Kontrus, 1989. A new test for structural stability in the linear regression model. J. Econ., 40: 307-318.
CrossRef - Sen, P.K., 1980. Asymptotic theory of some tests for a possible change in the regression slope occurring at an unknown time point. Zeitschrift fur Wahrscheinlichkeitstheorie und verwandte Gebeite, 52: 203-218.
CrossRefDirect Link - Sen, A.K. and M.S. Srivastava, 1975. On tests for detecting changes in mean. Ann. Statist., 3: 98-108.
Direct Link - Singh, N.J. and R.K. Pandey, 2011. Rehydration characteristics and structural changes of sweet potato cubes after dehydration. Am. J. Food Technol., 6: 709-716.
CrossRefDirect Link - Watson, M.W. and R.F. Engle, 1985. Testing for regression coefficient stability with a stationary AR1 alternative. Rev. Econ. Statist., 67: 341-346.
Direct Link - Worsley, K.J., 1986. Confidence regions and tests for a change-point in a sequence of exponential family random variables. Biometrika, 73: 91-104.
Direct Link - Yao, Y.C. and R.A. Davis, 1984. The asymptotic behavior of the likelihood ratio statistic for testing a shift in mean in a sequence of independent normal variates. Sankhya Ser. A, 48: 339 -353.
Direct Link