
Samruam Chongcharoen
School of Applied Statistics, National Institute of Development Administration, Bangkapi, Bangkok 10240, Thailand
F.T. Wright
Department of Statistics, 146 Middlebush Building, 904 University Avenue, Columbia, MO 65211-6100, USA
Journal of Applied Sciences
Year: 2012 | Volume: 12 | Issue: 13 | Page No.: 1390-1395







ABSTRACT
Suppose X1, X2, …, Xn is a random sample from the Np(θ, V) distribution. Consider H0: θ1 = θ2 = … = θp = 0 and H1: θi>0 for i = 1, 2, …, p, let H1-H0 denote the hypothesis that H1 holds but H0 does not and let~H0 denote the hypothesis that H0 does not hold. Because the Likelihood Ratio Test (LRT) of H0 versus H1-H0 is complicated, several ad hoc tests have been proposed. The proposed test is a permutation and scale invariant test statistic which includes information about the correlation structure in the sum of the sample mean. The simulation study showed that it maintain type I error rate level very well and it also give good powers. The proposed test also is compared with the existing one with these invariance properties.
PDF Abstract XML References Citation
Received: April 11, 2012;
Accepted: May 31, 2012;
Published: July 27, 2012
How to cite this article
Samruam Chongcharoen and F.T. Wright, 2012. Scale Invariant Follmann-type Tests. Journal of Applied Sciences, 12: 1390-1395.
DOI: 10.3923/jas.2012.1390.1395
URL: https://scialert.net/abstract/?doi=jas.2012.1390.1395
DOI: 10.3923/jas.2012.1390.1395
URL: https://scialert.net/abstract/?doi=jas.2012.1390.1395
INTRODUCTION
Consider a matched-pair design with p-dimensional responses. With θ = (θ1, θ2, …, θp)’ the difference, treatment one minus treatment two, of the mean responses, one may test the null hypothesis, H0: θ1 = θ2 = … = θp = 0, to determine if there is a significant difference in the two treatments. If one believes that, for each coordinate, the mean response for treatment one is at least as large as the mean response for treatment two, then the alternative can be constrained by H1: θi≥0 for i = 1, 2, …, p. Follmann (1996) discussed other situations in which these order-restricted hypotheses are of interest.
Let H1-H0 denote the hypothesis that H1 holds but H0 does not and let ~H0 denote the hypothesis that H0 does not hold. Let X1, X2, …, Xn be a random sample from the p-dimensional multivariate normal distribution with unknown mean θ = (θ1, θ2, …, θp)’ and positive definite covariance matrix V. The sample mean and unbiased sample covariance are:
It is well known that Ŝ is positive definite with probability one for n>p. Kudo (1963), Shorack (1967) and Perlman (1969) derive the Likelihood Ratio Test (LRT) of H0 versus H1-H0 if V is known, known up to a multiplicative constant or completely unknown, respectively. By V known up to a multiplicative constant, we mean V = σ2V0 with V0 known and σ unknown.
Tang et al. (1989) proposed approximate LRTs and Follmann (1996) studied one-sided modifications of the non-directional χ2 and Hotelling’s T2 tests of H0 versus ~H0. Follmann’s tests reject H0 if the appropriate non-directional ones do with significance level 2α and:
| (1) |
The tests that use (Eq. 1) or a variant of it are called Follmann-type tests and they include those in Chongcharoen et al. (2002) which incorporate information about the off-diagonal elements of V in Eq. 1. The latter kind of Follmann-type tests is called the new tests. All three of these procedures, approximate LRTs, Follmann’s tests and new tests, are easier to implement than the LRTs but the two Follmann-type tests are easier to use than the approximate LRT. In particular, the Follmann-type tests utilize chi-square or F critical values but the null distributions of the approximate LRT statistics are mixtures of chi-square or beta distributions.
It is clear that for most matched-pair designs, one wants the test to be invariant under changes in the units of measurement for any or all of the response variables as well as changes in the order of the response variables. The likelihood function and the constraint region, H1, are invariant under permutations of the indices of the response variables and under scale changes for the response variables. Thus, the LRTs are permutation and scale invariant. Chongcharoen and Wright (2007) give modified approximate LRTs that are permutation and scale invariant. In this note, Follmann-type tests that have these invariance properties are considered.
Focused on V that are known up to a multiplicative constant, i.e., V = σ2V0 or that are completely unknown but it is briefly described as permutation and scale invariant versions of the Follmann-type tests for the case of a known covariance matrix. A scale matrix is a diagonal matrix with positive diagonal elements. The versions of the Follmann-type tests of H0 versus H1-H0 that reject H0 for Xj, j = 1, 2, …, n and covariance V if and only if they reject H0 for Yj = DXj, j = 1, 2, …, n and covariance DVD’ with D either a permutation matrix or a scale matrix are considered.
In this setting, the usual χ2 and Hotelling’s T2 tests are permutation and scale invariant. Thus, Follmann’s tests have the desired invariance properties if one scales the sample means in Eq. 1, i.e., if one divides ![]() by the square root of Vi,i, (V0)i,i, or Ŝi,i when V is known, known up to a multiplicative constant or unknown, respectively. These tests are called the invariant Follmann tests. Because the first two are Follmann’s test applied to a fixed, non-singular transformation of the Xj, they have the desired significance levels; see Follmann (1996) and Chongcharoen et al. (2002), respectively. Theorem 3 shows that the one based on Ŝ also does.
by the square root of Vi,i, (V0)i,i, or Ŝi,i when V is known, known up to a multiplicative constant or unknown, respectively. These tests are called the invariant Follmann tests. Because the first two are Follmann’s test applied to a fixed, non-singular transformation of the Xj, they have the desired significance levels; see Follmann (1996) and Chongcharoen et al. (2002), respectively. Theorem 3 shows that the one based on Ŝ also does.
Two permutation and scale invariant versions of the new tests that have significance level α are considered. In both cases (Eq. 1) is modified. For the first invariant new tests, the sample mean vector is scaled as above, then pre-multiplied by the symmetric square root of the inverse of the correlation or sample correlation matrix and finally summed. For the second invariant new tests, the ith sample mean is scaled by multiplying by the square root of the ith diagonal element of the inverse of V, V0, or Ŝ then summed. It should be noted that in the second case, the scaling factors contain information about the off-diagonal elements of V.
The second approach is showed that it is equivalent to using the orthogonal transformation of the Cholesky factor proposed by Tang et al. (1989) in the test of Chongcharoen et al. (2002). In the Monte Carlo study, it is shown that the second invariant new tests have better powers than the first invariant new tests if one is concerned about all of θ = (θ1, θ2, …, θp)’ with θi = 0 or c, i = 1, 2, …, p with c>0.
The powers of all of these permutation and scale invariant tests including the LRTs will be compared by Monte Carlo simulation elsewhere. There it will be noted that for p = 3, there is little difference in the powers of the invariant Follmann’s tests and the second invariant new tests. However, for p≥4, if one is concerned about the entire alternative region, then the second invariant new tests have better powers than the invariant Follmann’s tests.
By taking the appropriate differences, the hypotheses H0 and H1 arise when testing homogeneity of normal means in the one-way analysis of variance with an order-restricted alternative (Robertson et al., 1988). Let ni denote the size of the ith sample and σi2 the variance of the ith population. If the weights wi = ni/σi2 are equal, then the following correlation matrices are of interest for a simple order restriction and a simple tree restriction, respectively:
| (2) |
where, I(A) denotes the indicator of A.
The new tests: The permutation and scale invariant versions of the Follmann-type tests that incorporate information about the off-diagonal elements of V in condition (Eq. 1), i.e., the new tests are presented. For the three types of covariance matrices considered here, define:
| (3) |
For the non-directional tests of H0 versus ~H0 in these three cases, one may use the test statistics:
| (4) |
For V known up to a multiplicative constant, Chongcharoen et al. (2002) discussed a version of Follmann’s test, a version of the new test and the statistic F1. The Follmann-type one-sided modifications of these tests are considered. If Yj = DXj with D nonsingular, then Yj has covariance DVD’, = D and χ2 which is not changed by this transformation, is permutation and scale invariant. Similarly, F1 and F2 are shown to be permutation and scale invariant.
V known up to a multiplicative constant: Suppose V = σ2V0 with V0 known. For an arbitrary symmetric, nonsingular matrix B, let B-1/2 denote the symmetric square root of B-1. Following Tang et al. (1989), let C denote the Cholesky factor of V0-1 i.e., the unique upper triangular matrix C with C’C = V0-1 With F2α;p(n-1)p the (1-2α)th quantile of the F distribution with degrees of freedom p and (n-1)p, respectively, let N1R (N1C) reject H0 if F1>F2α;p(n-1)p and:
| (5) |
The example in the appendix shows that N1R which was studied by Chongcharoen et al. (2002), is not scale invariant and N1C is not permutation invariant. (Incidentally, the proofs of Theorems 1 and 2 by Chongcharoen and Wright (2007) show that N1C is scale invariant and N1R is permutation invariant).
To obtain a permutation and scale invariant test, the scaling the components of ![]() is considered first and then premultiplying by the symmetric square root of R-1, with R = M1V0M1 the correlation matrix of an observation and M1 defined as in Eq. 3. Thus, let N1S reject H0 if:
is considered first and then premultiplying by the symmetric square root of R-1, with R = M1V0M1 the correlation matrix of an observation and M1 defined as in Eq. 3. Thus, let N1S reject H0 if:
| (6) |
Clearly N1S is scale invariant and Theorem 1, shows that it is permutation invariant.
Another way to scale the sample means is to multiply by the square root of the diagonal elements of the inverse of V0 which incorporates information about the off-diagonal elements of V. Thus the second invariant version of the new test, denoted by N1T, rejects H0 if:
| (7) |
It is straightforward to show that U1T and consequently N1T, is permutation and scale invariant. Because N1R, N1C, N1S and N1T are the Follmann test developed by Chongcharoen et al. (2002) applied to non-singular transformations of the Xj, they all have significance level α.
Let Co be the orthogonal transformation of C recommended by Tang et al. (1989) and U1Co be the sum of (Co)i. Theorem 2, shows that U1T>0 if and only if U1Co>0. Thus, the Follmann-type tests based on U1T and U1Co are equivalent.
The powers of N1S and N1T are compared. If one considers the entire alternative region, based on the Monte Carlo study described there, N1T seems to have better powers.
Unknown V: For V completely unknown, the analogues of N1S and N1T are considered. With M2 as in Eq. 3 and ![]() the sample correlation matrix, let N2S reject H0 if:
the sample correlation matrix, let N2S reject H0 if:
| (8) |
Since U2S is scale invariant, so is N2S. Furthermore, a proof, like the one given for Theorem 1, shows that N2S is permutation invariant. The test N2T rejects H0 if:
| (9) |
Clearly, U2T and N2T are permutation and scale invariant. One could base a test on U2R or U2C which are defined like U1R and U1C but use Ŝ-1 rather than V0-1 The former is not scale invariant and the latter is not permutation invariant.
For the following result, whose proof is straightforward, Rk denotes the k-dimensional reals.
Theorem 1: N1S, defined by Eq. 6, is permutation invariant.
Proof: We only need to show that U1S, given in Eq. 6, is permutation invariant. Let π be a permutation of {1, 2, …, p} and D be the corresponding matrix, i.e., Di,j = I(π(i) = j) for 1≤i, j≤p. Note that for B an arbitrary pxp matrix (DBD’)i,j = Bπ(i),π(j). With M1 defined in Eq. 3, recall that Xj has covariance and correlation matrices σ2V0 and R = M1V0M1, respectively. Of course, DD’ = D’D = I, DXj has covariance and correlation matrices σ2DV0D’ and R* = DRD’, respectively. Corresponding to M1, let ![]() . But M1* = DM1D’.
. But M1* = DM1D’.
The symmetric square root of R is O’E-1/2O, where O is orthogonal and E = ORO’ is a diagonal matrix with the eigenvalues of R on the diagonal. Now O* = DOD’ is orthogonal. With E* = O*R*O*’ = DED’, E* is diagonal and its diagonal is a permutation of the diagonal of E. Thus:
E*-1/2 = DE-1/2 D’, R*-1/2 = O*’E*-1/2O* = DR-1/2D’ R*-1/2 = M1*D = DR-1/2M1 |
and therefore, U1S is permutation invariant.
Theorem 2: With U1T and U1Co defined in Eq. 7 and after Eq. 7, U1T>0 if and only if U1Co>0.
Proof: Let C be the Cholesky factor of the inverse of V0, dC be defined as:
in equation of Tang et al. (1989) and J, e1, e2, …, ep be p-dimensional vectors with Jj = 1 (ei)j = I(i = j) for 1≤i, j≤p. Let r be the permutation of {1, 2, …, p} given by Tang et al. (1989) that is based on the columns of the inverse of V0. (The proof given is valid for any permutation of {1, 2, …, p}). Let Q2 be the orthogonal matrix determined by the Gram-Schmidt orthogonalization process applied to J, e2, e3, …, ep in the order listed which we denote by Q2 = GS(J, e2, e3, …, ep). Similarly, define Q1 = GS(dc, Cer(1), Cer(2), …, Cer(p-1)). Then Co = Q2Q1’C is the orthogonal transformation of the Cholesky factor by Tang et al. (1989) and U1Co is the sum of Co By the definition of dC, for i = 1, 2, …, p.
Writing the ith column of C as Cei, the following algebra completes the proof:
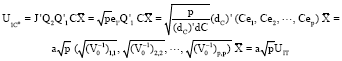 |
![]()
Theorem 3: Let Q and L be real valued functions defined on Rnp, with Q even and L odd, let c be real and let X be an np dimensional random vector with X and-X identically distributed. If:
The np-dimensional data vector is symmetric under H0 and as a function of the data vector, F2 is even and U2S and U2T are odd. Thus, N2S and N2T have significance level α. As mentioned earlier, based on the Monte Carlo study described, if one considers the entire alternative region, then N2T seems to have better powers than N2S.
Known V: Based on the results of the last two subsections, when V is known, the new test, N0T, is recommended that, with χ2 defined in Eq. 4 and χ22α,p the (1-2α)th quantile of the chi-square distribution with p degrees of freedom, rejects the null hypothesis if:
| (10) |
Power comparisons: Monte Carlo techniques are used to compare N1S and N1T as well as N2S and N2T. Following Chongcharoen et al. (2002), with p = 3 and 6, we simulate multivariate normal random vectors with covariance V = R for the following correlation matrices, R = (ρi, j):
| • | Rp, 1 = RS, Rp, 2 = RT with RS and RT given in Eq. 2, R3,3 (R6,3) with ρi,j = -0.4 (-0.1) for i≠j | |
| • | R3,4 with ρ1,2 = ρ2,3 = -0.4 and ρ1,3 = 0.4, R3,5 with ρ1,2 = ρ2,3 = 0.4 and ρ1,3 = -0.4 | |
| • | R6,4 with ρ1,2 = ρ1,4 = ρ2,5 = ρ2,6 = ρ3,5 = ρ3,6 = ρ4,5 = ρ4,6 = -0.4 and ρi,j = 0.4 for other i≠j | (11) |
Because the scale invariant tests is studied, so Vi,i = 1 for i = 1, 2, …, p is set. As expected, for each of the tests N1S, N1T, N2S and N2T, there is little difference in its power function for the correlation matrix with ρ1,2 = ρ1,3 = ρ2,3 = 0.4 and for R3,2 (ρ1,2 = ρ1,3 = ρ2,3 = 0.5). The former R is not discussed any further. Because the tests are permutation invariant, their overall performances for R3,4 (R3,5) are the same as those for R with |ρ1,2| = |ρ1,3| = |ρ2,3| = 0.4 and exactly one (two) of the three positive.
Sample sizes are n = 6, 20 and 100, except n = 6 is replaced by n = 10 for p = 6. The mean vectors of the form, θ = cυ with c a constant and υ a vector are considered. The vector υ' is called the direction and c is chosen so that the usual F test based on F1 or F2 has power equal to 0.70 provided υ is non-null, i.e., υ≠0. The directions of the form (v1, v2, …, vp)' with vi = 0 or 1 for 1≤i≤p are considered. With 10,000 iterations, the proportion of times each test rejects the null hypothesis is recorded. Throughout, the level of significance is α = 0.05.
All of the tests considered are exact. For all of these tests, all n and all the correlation structures considered, the power estimates under the null hypothesis range from 0.046 to 0.053.
Now the two tests N1S and N1T are compared. Chongcharoen et al. (2002) noted that if Vi,i = 1 and Vi,j have the same value for 1≤i≠j≤p, then with U1S defined in Eq. 6, 1 holds if and only if U1S>0. For such V, the diagonals elements of V-1 are the same and thus with U1T defined in Eq. 7, 1 holds if and only if U1T>0. For such V, Follmann’s test, N1S and N1T are identical. It is noted that R3,2, R3,3, R6,2 and R6,3 are of this type. For a given R and a given Ψ, a test of H0 versus H1-H0, let a(Ψ) and m(Ψ) be the average and minimum, respectively, of the power estimates of Ψ over the 2p-1 non-null directions considered here.
First, p = 3 is considered. For R3,1 and R3,4 with n = 6, 20 and 100, a(N1T)-a(N1S) ranges from -0.002 to 0.000 and m(N1T)-m(N1S) ranges from -0.001 to 0.005. The differences in the two tests are more noticeable for R3,5. For p = 3, R3,5, n = 6 and 100 and the seven non-null directions considered, Table 1 gives the power estimates for N1S and N1,T. (It also gives some power estimates for N2S and N2T for this R.) As n ranges from 6 to 100 for R3,5, a(N1T)-a(N1S) ranges from -0.006 to -0.003 and m(N1T)-m(N1S) ranges from 0.149 to 0.155. N1T is recommended over N1S for this R. Using N1T rather than N1S may result in a slight loss in “average” power but will provide some protection against the low power of N1S in the direction (0, 1, 0).
As in study of Chongcharoen and Wright (2007), with p = 3 we also consider correlation matrices for which the elements above the diagonal have different magnitudes and can be positive or negative.
| Table 1: | For p = 3, α = 0.05, R3,5, n = 6 and n = 100, the values of c, estimates of the powers of N1S and N1T are given for several directions |
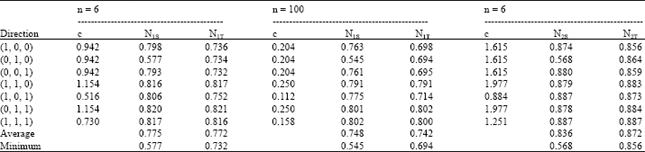 | |
| c is chosen to make the power of the usual F test equal 0.70. The corresponding values for N2S and N2T are given for n = 6. For n = 100, the estimates for N1S (N1T) do not differ from those for N2S (N2T) by more than 0.006 | |
If they are all negative with large magnitudes, then the correlation matrix will be singular. Thus, |ρ1,2| = 0.3, |ρ1,3| = 0.4 and |ρ2,3| = 0.5 are considered.
For these eight correlation matrices with different magnitudes for the elements above the diagonal, N1S and N1T perform as they do for R3j with 1≤ j≤5. In particular, for the four of the eight matrices with at most one of the three correlations being positive, N1S and N1T perform as they do for R31 and R34, i.e., there is little difference in the power estimates of N1S and N1T. For the three matrices with two positive elements above the diagonal, N1S and N1T perform as they do for R35. For these three matrices, as n ranges from 6 to 100, a(N1T)-a(N1S) ranges from -0.009 to -0.002 and m(N1T)-m(N1S) ranges from 0.143 to 0.157. Finally, for the matrix with all three correlations positive and n = 6, 20 and 100, a(N1T) and a(N1S) agree to three decimal places and m(N1T)-m(N1S) ranges from 0.020 to 0.024. Recall, if ρ1,2 = ρ1,3 = ρ2,3, then N1S and N1T are identical but for the matrix with different positive correlations, N1T is slightly preferred over N1S. Based on the correlation matrices studied here, N1T is recommended over N1S for p = 3. For the non-null directions considered, it is believed that the possible loss in average power is offset by the possible gain in minimum power.
Next, p = 6 is considered and recall that N1S and N1T are identical for both R6,2 and R6,3. For R6,1, there is little difference in the power estimates of the two tests. As n ranges from 10 to 100, a(N1T)-a(N1S) = 0 to three decimal places and m(N1T)-m(N1S) ranges from 0.000 to 0.002. For R6,4, as n ranges from 10 to 100, a(N1T)-a(N1S) ranges from -0.053 to -0.007 and m(N1T)-m(N1S) ranges from -0.002 to 0.019. There is not a substantial difference in the powers of these two tests in this case and one’s choice would depend on whether average power or minimum power is to be maximized. However, in the next paragraph, we study cases in which there is a substantial difference in the powers of the two tests.
To study the effect of the pattern of positive and negative correlations on the powers of these two tests, we consider all 215 cases with ρi,j = ±0.35 for i<j.
| Table 2: | With p = 6, n = 10, Vi,i = 1.0 and |Vi,j| = 0.35 for 1≤i≠j≤p and the number of Vi,j with i<j that are negative fixed in column 1, the number of such matrices that are positive definite and the minimum and maximum of a(N1T)-a(N1S) as well as m(N1T)-m(N1S) over all such positive definite correlation matrices and all non-null directions of the form (v1, v2, …, vp)' with vi = 0 or 1 for 1≤i≤p are given |
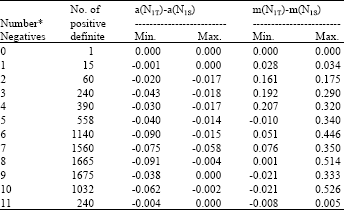 | |
| *If the number of negatives exceeds 11, the correlation matrix is not positive definite | |
Of course, not all such symmetric matrices with ones on the diagonal are positive definite. In fact, the magnitude of the correlations is chosen to be 0.35 rather than 0.40 which is used in R6,4, because it yields more positive definite matrices. With l the number of negative correlations with i<j, 0≤l≤11 and n = 10, Table 2 gives the number of such matrices that are positive definite, the minimum and maximum of both a(N1T)-a(N1S) and m(N1T)-m(N1s) over all such matrices and all non-null directions considered here. Estimates for n = 10 are given because the difference in the two tests are more pronounced for small n. For l>11, there are no such positive definite matrices. For l = 0 and 11, there is little difference in the estimated powers of the two tests and for 2≤l≤10, it appears that the average of the power estimates for N1T are somewhat smaller than for N1S but the minimum of the power estimates for N1T may be substantially larger than those of N1S.
To further explore the last conclusion, l = 8 is considered because it has the greatest loss in average power from using N1T rather than N1S and (about) the greatest gain in minimum power from using N1T. Of the 1,665 positive definite correlation matrices with l = 8, the following has the greatest loss in average power from using N1T rather than N1S: R6,5 = (ρi,j) with | ρi,j| = 0.35 for i≠j and ρ1,2 = ρ1,5 = ρ2,3 = ρ2,4 = ρ2,5 = ρ3,5 = ρ4,5 = ρ5,6 = -0.35. For this R with n = 10 and n = 100, a(N1T)-a(N1S) = -0.091 for both sample sizes and m(N1T)-m(N1s) = 0.508 and 0.487, respectively. For this correlation matrix, we recommend N1T because, even though it has smaller average power than N1S, it will provide some protection against the low power in the direction (0, 0, 0, 0, 0, 1)'. Based on the results for all of the correlation matrices we have studied with p = 3 and 6, N1T is recommended over N1S. However, it should be noted that for some correlation matrices and some directions, its power is smaller than the usual F test that does not incorporate the information that the θi are nonnegative.
Now briefly comparison between N2T and N2S is considered, that is, the new tests for unknown V. For p = 3, the powers of the two tests for the same correlation structures are considered with the same directions considered earlier. The largest differences in the tests due to the fact that V is unknown should occur for small n. For n = 6, R3,1 through R3,5, a(N2T)-a(N2S) and m(N2T)-m(N2S) are both positive but these differences do not exceed 0.032 for the first four R. The power estimates for the two tests with R3,5 are given in Table 1. For n = 6 and this R, the average power of N2T is 0.036 larger than for N2S and the minimum power of N2T is 0.287 larger than for N2S. As n increases, the results are more like those for N1T and N1S. For instance, for n = 100 and R3,5, the power estimates for N1T and N2T do not differ by more than 0.006. The same is true for N1S and N2S. Based on these results, N2T is recommended over N2S for p = 3.
For p = 6 and n = 10, the powers of the two tests for the same correlation matrices are considered with the same directions considered earlier. For R6,1, R6,2 and R6,3, N2T has the larger average power estimate and the larger minimum power estimate. For R6,4, a(N2T)-a(N2S) = -0.001 and m(N2T)-m(N2S) = 0.120 and N2T is preferred over N2S. For R6,5, a(N2T)-a(N2S) = -0.013 and m(N2T)-m(N2S) = 0.700. As with the comparison of N1S and N1T, for the latter R, the loss in average power resulting from using N2T rather than N2S is more than offset by the protection against the extremely low power of N2S in the direction (0, 0, 0, 0, 0, 1). N2T is recommended over N2S.
APPENDIX
Example 1: (N1R is not scale invariant and N1C is not permutation invariant) For both examples, let p = 2, V0 = RT and V* = DV0D’ with D a scale or a permutation matrix. To show that NIR, defined by (5), is not scale invariant, let D = diag(1.0, 2.0) and = (1.0, -1.1)’. The needed symmetric square roots, transformed mean vectors and sums are:
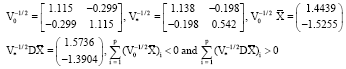 |
Thus, N1R is not scale invariant.
To show that N1C, defined by Eq. 5, is not permutation invariant, let D correspond to the permutation that interchanges the two indices and = (1.0, -1.0)’ Clearly, V* = V0 which has Cholesky factor C given below. The common Cholesky factor and sums are:
Thus, N1C is not permutation invariant.
ACKNOWLEDGMENT
The research of the first author was sponsored by the Thailand Research Fund.
REFERENCES
- Chongcharoen, S., B. Singh and F.T. Wright, 2002. Powers of some one-sided multivariate tests with the population covariance matrix known up to a multiplicative constant. J. Stat. Plann. Inference, 107: 103-121.
CrossRef - Chongcharoen, S. and F.T. Wright, 2007. Permutation and scale invariant one-sided approximate likelihood ratio tests. Stat. Probabil. Lett., 77: 774-781.
CrossRef - Follmann, D., 1996. A simple multivariate test for one-sided alternatives. J. Am. Stat. Assoc., 91: 854-861.
CrossRef - Shorack, G.R., 1967. Testing against ordered alternatives in model I analysis of variance: Normal theory and nonparametrics. Ann. Mathe. Stat., 38: 1740-1752.
Direct Link