
Silvia Golia
Department of Quantitative Methods, University of Brescia, C.da S.Chiara, 50 25122 Brescia, Italy
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 4 | Page No.: 707-712







ABSTRACT
The study aims at evaluating the impact of the questionnaire size on the accuracy and stability of the Rasch measure. The Rasch measurement model is used to obtain a reliable and objective measurement of a latent trait of interest. A simulation study is performed in order to deal with the issue.
PDF Abstract XML References Citation
Received: October 16, 2010;
Accepted: November 13, 2010;
Published: February 12, 2011
How to cite this article
Silvia Golia, 2011. The Impact of Questionnaire Size on the Accuracy of the Rasch Measure. Journal of Applied Sciences, 11: 707-712.
DOI: 10.3923/jas.2011.707.712
URL: https://scialert.net/abstract/?doi=jas.2011.707.712
DOI: 10.3923/jas.2011.707.712
URL: https://scialert.net/abstract/?doi=jas.2011.707.712
INTRODUCTION
The issue of determining a reliable and objective measurement of a complex concept not directly observed, or latent trait, is a crucial problem in the analysis of social and economic phenomena. A latent trait refers to a latent continuum, or dimension, which all individuals are mapped on, based on their pattern of responses on a set of categorical variables. These categorical variables result from the submission of questionnaires with items referring to the different aspects of the concept being measured. Responses usually indicate the degree of agreement with each statement, with higher scores reflecting greater agreement.
A very simple tool to assess subjective attitudes is the summated rating scale, also referred to as raw score. However raw score has little inferential value, is neither interval nor ratio measure and is affected by missing values; this means it cannot be compared for conclusions about subject latent trait. Hence, raw score can only be an indication of a possible measure of the latent trait.
One of the methods proposed to deal with the issue to identify an objective measurement of the latent trait underlying a multiple-item scale is the so-called Rasch model, which allows one to transform ordinal raw scores into interval scale measures. The model has been successfully applied to many contexts which include the psychological, educational, medical and socio-economic (such as the evaluation of customer or job satisfaction) field (Kubinger, 2005; Waugh et al., 2000; Tesio, 2003; King and Bond, 2003; Brentari and Golia, 2008).
The goodness of the obtained measures depends on meeting the model assumptions as well as the quality of the questionnaire used. The present research studies the impact of the questionnaire size on the accuracy and stability of the Rasch measure making use of simulated data. Increasing the questionnaire length, the goodness of the estimated measures increases, as expected. Nevertheless, the improvement is significantly high when the questionnaire size is small and more responsive to the increasing number of response categories than items. In the empirical study, questionnaires of small size are quite common and it is interesting to study the goodness of the estimated measures.
SIMULATION STUDY
The Rasch Model (RM) (Rasch, 1960) is a measurement model which converts raw scores into linear and reproducible measurement. It is built around the idea that the probability of a certain answer when a person is confronted with an item, is described as a function of the person’s position on the latent trait under study and the parameter characterizing that particular item. Under the hypotheses of unidimensionality (all items forming the questionnaire measure only a single construct, i.e., the latent trait under study) and local independence (conditional to the latent trait, the response to a given item is independent from the responses to the other items in the questionnaire) the person and item parameters enter in the response probability as a linear combination. The mathematical form of the RM provides the separation of item and person parameters. A concomitant of separability is minimally sufficient statistics for person as well as item parameters; the person raw score is a sufficient statistic for the unknown person parameter and the item sum score across persons is a sufficient statistic for the unknown item parameter (Wright and Master, 1982). If the data fit the model, then the measures produced applying the RM to the sample data are objective and expressed in logits (logarithm of odds); the logit scale is an interval scale.
The RM introduced by Rasch (1960) can be used to deal with dichotomous data; if data come from polytomously scored items, that is when there are more than two possible ordered response categories for each item, extensions of the RM, such as the Rating Scale Model (RSM) (Andrich, 1978), must be taken into account. Assuming that there are m+1 possible ordered response categories for each item, coded as x = 0, 1,…, m, following the RSM, the probability that the person n answers x to the item i is given by:
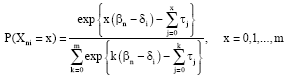 | (1) |
Therefore, it depends on the subject ability, or level of latent trait, βn and how difficult the item is to endorse, identified by its mean difficulty δi and the thresholds τj; τj is the point of equal probability of categories j-1 and j. Thresholds add up to zero, i.e.,
The present simulation study wants to investigate the stability of the measures estimated from simulated data sets involving the RSM defined in Eq. 1 and different items and thresholds sets. The data are generated as follows.
A sample of 1000 abilities was drawn from a standard normal distribution; these abilities are used in the data simulation and represent the target or real abilities βn. The response given by the subject n with ability βn to the item i, which has difficulty δi, is obtained as follows. For each category, the corresponding response probability is computed making use of Eq. 1. Then the response probability cumulative sum is calculated and compared with a random number rn drawn from a uniform distribution on the interval [0,1]. The response category corresponding to the first element of the cumulative sum which is equal or larger than rn is assigned as the response of the subject n to the item i.
| Table 1: | The sets of the item mean difficulties used in the simulation study |
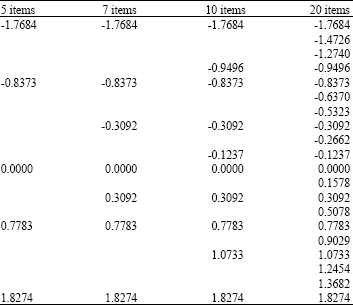 | |
This procedure is repeated for all the items in order to simulate the response record of each of the 1000 subjects forming the simulated sample.
Table 1 reports the sets of the item mean difficulties δi used in the present study. Each set of the difficulty parameters is drawn from a continuous uniform distribution on the interval from -1.9 to 1.9 so that the parameters sum is equal to zero, as required by the calibration procedure and each set includes the previous one.
The two sets of threshold parameters τj utilized are [-0.5 0.5] and [-1 -0.5 0.5 1]; they imply three and five response categories, respectively.
For each combination of item mean difficulties δi and threshold set τj, 200 data sets were simulated and analyzed and 200 sets of estimated abilities and item difficulties were computed.
In the calibration procedure the analysis was performed by setting the mean of item difficulty estimates to 0.0 logits and by using the (unconditional) maximum likelihood estimation method. The data simulation was performed using Matlab 6.5 whereas the Rasch analysis using Winsteps 3.65 (Linacre, 2006).
RESULTS AND DISCUSSION
Table 2 reports the mean value of the person reliability index and the rejection percentages of the null hypothesis underlying the Jarque-Bera test for normality, the two-sample Kolmogorov-Smirnov test and the t-test for zero mean.
The person reliability index (Bond and Fox, 2007) is an estimate of the reproducibility of people placement that can be expected if the same sample of respondents was to be given another set of items measuring the same latent construct. It is bounded by 0 and 1 and can also be computed with missing values.
| Table 2: | The mean value of the person reliability index (standard errors in brackets) and the rejection percentages of the null hypothesis underlying the Jarque-Bera, Kolmogorov-Smirnov and t-tests(significance level 5%) |
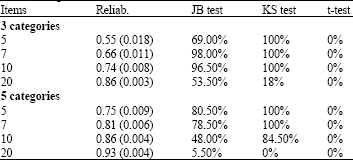 | |
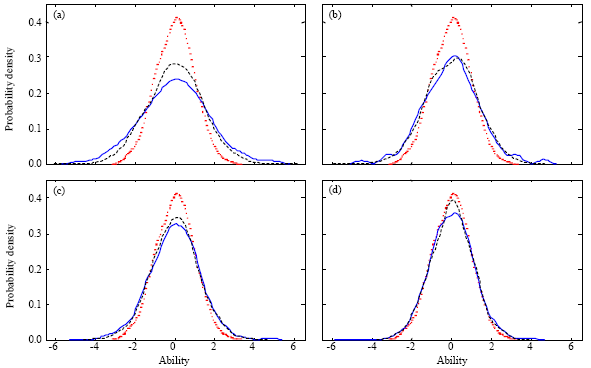 | |
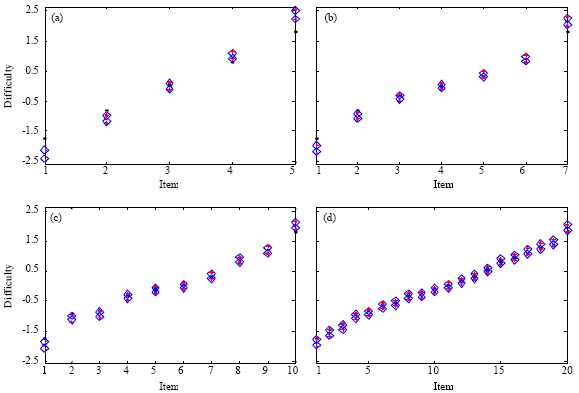
| Fig. 1: | Graph of the kernel probability density of the real (dotted line) and an estimated ability (3 categories: solid line, 5 categories: dashed line). (a) 5 items, (b) 7 items, (c) 10 items and (d) 20 items |
The values of the person reliability index are sufficiently high if there are 20 items with three categories or at least seven items with five categories; increasing the number of items and thresholds, the people placement in the ability scale is more reliable.
The Jarque-Bera test for normality (Bera and Jarque, 1980) has been performed for each estimated ability set to check if the null hypothesis of normality is a reasonable assumption regarding the population distribution. If three response categories are used, the rejection percentage of the null hypothesis is higher than 5% for all the cases; the distribution of the estimated abilities is not normal. If the questionnaire admits five response categories, the rejection percentage of the null hypothesis is consistent with the fixed significant level if 20 items are used.
The two-sample Kolmogorov-Smirnov test (Massey, 1951) is used to verify if two independent random samples (the real and estimated abilities) are drawn from the same underlying continuous population. The rejection percentage of the null hypothesis is consistent with the fixed significant level if five categories and 20 items are used.
The t-test is used to verify if the mean estimated ability is equal to zero. In all the eight cases the null hypothesis is accepted.
We can conclude that all the eight types of questionnaires are able to reproduce ability estimates with zero mean, as the real one, but only one type (five categories and 20 items) is able to produce estimates coming from a normal distribution, as in the real case.
| Table 3: | The mean width of the empirical 95% confidence interval for the ability estimation computed considering the least able, the mid-able and the most able subject (standard errors in brackets) |
 | |
If the probability density function, estimated using a kernel smoothing method based on a normal kernel function, is considered, as shown in Fig. 1a-d, it is possible to observe that the extreme subjects, that is the respondents with higher or lower level of ability, are the most difficult to estimate with accuracy.
Table 3 reports the mean values of the width of the empirical 95% confidence interval for the ability estimation ![]() computed considering the least able (level of estimated ability lower than the first decile), the most able (level of estimated ability higher than the ninth decile) and the mid-able (level of estimated ability bounded by the first and ninth deciles) subjects. The width of the empirical 95% confidence interval for the ability estimation shows an inverse relation with the number of used items and thresholds; increasing this number, the width decreases and the estimation is more stable.
computed considering the least able (level of estimated ability lower than the first decile), the most able (level of estimated ability higher than the ninth decile) and the mid-able (level of estimated ability bounded by the first and ninth deciles) subjects. The width of the empirical 95% confidence interval for the ability estimation shows an inverse relation with the number of used items and thresholds; increasing this number, the width decreases and the estimation is more stable.
 | |
| Fig. 2: | Graph of the real ability (solid line) and the empirical 95% confidence bands smoothed using a cubic spline. Data obtained using 3 (dotted line) and 5 (dashed line) categories. (a) 5 items, (b) 7 items, (c) 10 items and (d) 20 items |
| Table 4: | Variations in the mean width of the empirical 95% confidence interval for the ability estimation between contiguous questionnaire lengths |
 | |
| Table 5: | Mean correlation coefficient between estimated and true measures (standard errors in brackets) |
 | |
Moreover, a larger and asymmetric empirical confidence interval corresponds to the least and the most able subjects; the estimation is more complex for extreme respondents.
Table 4 reports the variations in the mean width of the empirical 95% confidence interval for the ability estimation observed when the questionnaire size is ni instead of ni-1; for example -0.1761 is the variation in the mean width of the least able respondents when a questionnaire with three categories and seven items, instead of one with five items, is used. The reduction of the width is almost constant until 10 items (around 20%). When the questionnaire size doubles, going from 10 to 20 items, the improvement in the reduction of the width is higher but not so high as one could expect doubling the number of items, in comparison with the previous sizes. The impact of increasing the questionnaire size is stronger when this size is small. If mid-able subjects are considered, it can be noted that the number of categories does not affect the magnitude of the improvement.
Table 5 reports the mean correlation coefficients between the true and estimated ability measures. In all cases the values are significantly high, showing a strong linear relation between the measures. The linear link becomes stronger as the length of the questionnaire increases.
Figure 2a-d display the graphs (ability versus respondents) of the empirical 95% confidence bands, smoothed using a cubic spline and the real abilities. The shapes of the confidence intervals are less precise when a small number of items and categories is used and the estimated measures are less stable. In all the cases the estimation procedure underestimates the real abilities βn of the least able subjects and overestimates the real abilities βn of the most able subjects, highlighting difficulties in estimating the ability of extreme respondents. The empirical confidence interval is centred for almost all the non-extreme subjects.
 | |
| Fig. 3: | Graph of the real item mean difficulty (dots) and the empirical 95% confidence intervals obtained using 3 (star) and 5 (diamond) categories. (a) 5 items, (b) 7 items, (c) 10 items and (d) 20 items |
Moreover, the effect on the confidence interval and the stability of the estimated measure ![]() due to the number of the response categories is stronger than the effect obtained increasing the items number. Even if the questionnaire is made by a small number of items, for example 10, a high number of response categories is able to produce estimated measures
due to the number of the response categories is stronger than the effect obtained increasing the items number. Even if the questionnaire is made by a small number of items, for example 10, a high number of response categories is able to produce estimated measures ![]() which are reasonably stable.
which are reasonably stable.
It is interesting to observe if there is an impact of the questionnaire size on the accuracy of the estimated mean difficulties ![]() . It is well-known that the goodness of δi estimates strongly depends on the number of respondents involved in the survey; in this simulation study this number (1000) is fairly high.
. It is well-known that the goodness of δi estimates strongly depends on the number of respondents involved in the survey; in this simulation study this number (1000) is fairly high.
Figure 3a-d display the empirical 95% confidence intervals for the estimated mean difficulties. As the questionnaire length increases, the real mean difficulty δi comes closer to the empirical confidence interval. The estimates of the easiest and most difficult items are the ones which are mostly influenced by the size of the questionnaire; the δi of the easiest items are overestimated whereas the difficult parameters of the most difficult items are underestimated. Moreover, the number of categories slightly affects the goodness of the estimations; the bias is almost the same when three or five response categories are used.
CONCLUSIONS
The study deals with the evaluation of the impact of the questionnaire size on the accuracy and stability of the Rasch measure making use of simulated data. The quality of the obtained measures depends on meeting the hypothesis underlying the RM as well as the quality of the questionnaire used in terms of number of items and response categories.
The results obtained show an inverse relationship between, on one side, the length of the questionnaire and the number of categories and, on the other side, the accuracy and stability of the estimated measures.
All the types of questionnaires considered in the study are able to reproduce ability estimates with zero mean, as the real one, but only one type (five categories and 20 items) is able to produce estimates coming from a normal distribution, as in the real case.
The width of the empirical 95% confidence intervals decreases with the increase of the number of items and response categories, nevertheless the impact of increasing the questionnaire size is stronger when this size is small. Moreover, it is important to underline that the effect on the confidence interval and the stability of the estimated measure due to the number of the response categories is stronger than the effect obtained increasing the items number.
ACKNOWLEDGMENT
The author wishes to thank M. Carpita for useful and valuable discussions and the two anonymous reviewers for their useful comments.
REFERENCES
- Andrich, D., 1978. A rating formulation for ordered response categories. Psychometrika, 43: 561-573.
CrossRef - Bera, A.K. and C.M. Jarque, 1980. Efficient tests for normality, homoscedasticity and serial independence of regression residuals. Econ. Lett., 6: 255-259.
Direct Link - Brentari, E. and S. Golia, 2008. Measuring job satisfaction in the social service sector with the Rasch model. J. Applied Measurement, 9: 45-56.
PubMed - King, J.A. and T.G. Bond, 2003. Measuring client satisfaction with public education I: meeting competing demands in establishing state-wide benchmarks. J. Applied Measurement, 4: 111-123.
PubMed - Kubinger, K.D., 2005. Psychological test calibration using the rasch model-some critical suggestions on traditional approaches. Int. J. Testing, 5: 377-394.
CrossRef - Massey, Jr. F.J., 1951. The kolmogorov-smirnov test for goodness of fit. J. Am. Stat. Assoc., 46: 68-78.
Direct Link - Tesio, L., 2003. Measuring behaviours and perceptions: Rasch analysis as a tool for rehabilitation research. J. Rehab. Med., 35: 105-115.
PubMed - Waugh, R.F., T.K. Hii and A. Islam, 2000. An approach to studying scale for students in higher education: A rasch measurement model analysis. J. Applied Measurement, 1: 44-62.
PubMed