
M. Mohammadi
Institute for Mathematical Research, Universiti Putra Malaysia, 43400 UPM Serdang, Selangor, Malaysia
H. Midi
Institute for Mathematical Research, Universiti Putra Malaysia, 43400 UPM Serdang, Selangor, Malaysia
J. Arasan
Institute for Mathematical Research, Universiti Putra Malaysia, 43400 UPM Serdang, Selangor, Malaysia
B. Al Talib
Department of Statistics and Informatics, Faculty of Computer Sciences and Mathematics, University of Mosul, Mosul, Iraq
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 3 | Page No.: 503-511







ABSTRACT
Control chart is a statistical process control tool that is used to monitor the changes in a process. Hotelling's T2 chart is one of the most popular control charts for monitoring independently and identically distributed random vectors. This chart detects many types of out-of-control signals, but it is not sensitive to small shifts in the mean vector. This study propose a more efficient T2 control charts based on the re-weigted robust estimators of location and dispersion. The proposed control charts are attained by substituting the classical estimators of the mean vector and covariance matrix in the Hotelling's T2 by the re-weighted MCD and re-weighted MVE estimators. In this study, Monte Carlo simulations were carried out to establish the proposed robust control limit. Following that, we suggested suitable estimators for each condition. Our advice in this study is replacing the classical mean vector and covariance matrix of the data in the Hotelling's T2 statistic by there weighted MCD and Re-weighted MVE estimators.
PDF Abstract XML References Citation
Received: September 21, 2010;
Accepted: October 24, 2010;
Published: January 22, 2011
How to cite this article
M. Mohammadi, H. Midi, J. Arasan and B. Al Talib, 2011. High Breakdown Estimators to Robustify Phase II Multivariate Control Charts. Journal of Applied Sciences, 11: 503-511.
DOI: 10.3923/jas.2011.503.511
URL: https://scialert.net/abstract/?doi=jas.2011.503.511
DOI: 10.3923/jas.2011.503.511
URL: https://scialert.net/abstract/?doi=jas.2011.503.511
INTRODUCTION
One of the most popular tools used to construct a multivariate control chart using individual observations is the Hotelling’s T2 control chart. The main aim of a multivariate control chart is detecting the cause of the process change. In the literature, construction of this control chart is carried out in two distinct phases. In phase I operation, Hotelling's T2 chart is often used to purge outliers whereas signal detection is done in the phase II operation. In the first phase, Historical Data Set (HDS) is used to establish the control limits in order to detect outliers. If one or more of these initial observations in HDS is out of control, the phase I control limits are recomputed based on the remaining observations. This step is repeated until the process comes to the state of control and the in-control parameters of the process are estimated. Then clean, phase I data is used to set control limits for monitoring future (phase II) data. Generally, for a retrospective phase I analysis of a Historical Data Set (HDS) our objective is defined in two steps.
In the first step, mean shifts that might result to ruins the estimation of the in-control mean vector and variance-covariance matrix are discovered. In the second step, after identification and elimination of multivariate outliers, the in-control parameters estimates which are established in the control subset of the HDS, to be used.
In the computation of the Hotelling's T2 the classical mean and covariance are utilized, hence the results can be heavily influenced by outliers. In recent years, several multivariate statistical process control techniques have been proposed to analyze and monitor multivariate data (Tracy et al., 1992; Sullivan and Woodall, 1996; Vargas, 2003). In this study, in order to decrease the impact of outliers we propose the use of the re-weighted robust estimator instead of the classical estimator in the computation of Hotelling's T2.
HOTELLING’S T2
Hotelling et al. (1974) introduced a statistic that combines information from the dispersion and mean of several variables. The T2 statistic may be computed using a single observation from p components, or it may be computed using the mean from a sample of size n. In this study, a subgroup of size 1 (i.e., a single observation) will be assumed for the T2 computations. The T2 statistic for a px1 multivariate normal vector, X = (X1,..., XP) is defined as:
| (1) |
Where:
and
are the common estimators of the mean vector and covariance matrix obtained from the historical data set. Usually, we assume that the Xi’s are independent multivariate normal, MVNp(μ, Σ) with μ and covariance matrix Σ. In order to detect any possible signal, for each individual observation, we compare the T2 with control limits.
Hotelling’s T2 statistic can be described by different distribution based on different situations. Suppose the parameters of the MVN distribution, μ and Σ are known. The T2 statistic for an individual observation vector X follows the chi-square distribution:
| (2) |
Assuming the parameters of the MVN distribution are unknown, the estimators ![]() and S must be used. These values are calculated from HDS, consisting of n observations. The distribution of the T2 statistic for an individual observation vector X, independent of
and S must be used. These values are calculated from HDS, consisting of n observations. The distribution of the T2 statistic for an individual observation vector X, independent of ![]() and S is:
and S is:
| (3) |
where, F is distributed as F distribution with p and (n-p) degrees of freedom. In another case, let us say the observation vector X is not independent of the estimators ![]() and S but is included in their computation. Then the distribution of the T2 statistic is given as follows (Tracy et al., 1992):
and S but is included in their computation. Then the distribution of the T2 statistic is given as follows (Tracy et al., 1992):
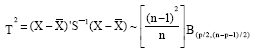 | (4) |
where, B is distributed as Beta distribution with parameters p/2 and (n-p-1)/2. In the computation of Hotelling's T2 the classical estimators of location and dispersion have been used to estimate the population mean vector and covariance matrix. However, this classical estimators are affected by outliers in the phase I data. Therefore, we construct an alternative estimator based on Re-weighted Minimum Covariance Determinant (RMCD) and Re-weighted Minimum Volume Ellipsoid Estimators (RMVE) which have a higher efficiency and reduce the influence of outlying observations. Vargas (2003) and Jensen et al. (2007) recommended using the Minimum Covariance Determinants (MCD) and Minimum Volume Ellipsoid (MVE) estimators of mean vector and covariance matrix in the Hotelling's T2 charts (Wisnowski et al., 2002; Chenouri et al., 2009). The exact distribution of the T2 based on the RMCD and RMVE are not tractable, so we used Monte Carlo method to obtain the appropriate control limits.
ROBUST ESTIMATORS
Modified version of the MCD and MVE estimators are RMCD and RMVE. Reweighting step that is included in the computation of RMCD and RMVE, greatly increase the finite-sample efficiency of these estimators.
RMCD estimators inherit the good properties of MCD estimators such as affine equivariance, the maximal asymptotic breakdown point and asymptotic normality. In addition, a fast and efficient approximate algorithm to compute Re-weighted Minimum Covariance Determinant (RMCD) is available. The above mentioned estimators, have been studied by several authors (Rousseeuw and Van Zomeren, 1990; Lopuhaa and Rousseeuw, 1991; Willems et al., 2002). In contrast, the re-weighted MVE estimators of mean vector and covariance matrix with ordinary MVE, re-weighted MVE estimators are more efficient, akin to the re-weighted MCDs. So, we expect that the new robust control charts (re-weighted MVE) outperforms those based on the ordinary MVEs.
RMCD ESTIMATOR
Rousseeuw (1985) introduced the Minimum Covariance Determinant (MCD) estimator that has finite sample and asymptotic breakdown points 1/2, which is based on the subset of h = ⌊nγ⌋ (where 0.5<γ<1) data points whose covariance matrix has the smallest possible determinant, where 1-γ is the asymptotic breakdown point. The MCD location estimate ![]() is defined as the average of these h data points and the MCD scatter estimate is given by SMCD = aCMCD where, CMCD is the covariance matrix of the subset of h points and a is the multiple of the consistency and the finite sample correction factors (Willems et al., 2002; Chenouri et al., 2009). The MCD estimators have the highest finite sample breakdown point when h = ⌊(n+p+1)/2⌋ (Rousseeuw and Leroy, 1987). In order to estimate the RMCD estimator, for each individual observation we computed the weight based on the robust distance:
is defined as the average of these h data points and the MCD scatter estimate is given by SMCD = aCMCD where, CMCD is the covariance matrix of the subset of h points and a is the multiple of the consistency and the finite sample correction factors (Willems et al., 2002; Chenouri et al., 2009). The MCD estimators have the highest finite sample breakdown point when h = ⌊(n+p+1)/2⌋ (Rousseeuw and Leroy, 1987). In order to estimate the RMCD estimator, for each individual observation we computed the weight based on the robust distance:
| (5) |
The weight (wt) equals 1 when the squared robust distance D(Xi)2 is smaller than the cutoff value χ2ρ,η (we use the value η = 0.975 which was advocated and used by Rousseeuw and Van Driessen (1999). Otherwise the weight equals zero. Afterward we can compute the ![]() and SRMCD:
and SRMCD:
| (6) |
| (7) |
Here, cη,p = η/p (χ2(p+2)≤qη), makes SRMCD consistent under the multivariate normal distribution and yields more reliable outlier identification. The factor ![]() is a finite sample correction given by Pison et al. (2002). The most commonly used algorithm for computational purposes is FAST-MCD algorithm (Rousseeuw and Van Driessen, 1999) which has been used in this study.
is a finite sample correction given by Pison et al. (2002). The most commonly used algorithm for computational purposes is FAST-MCD algorithm (Rousseeuw and Van Driessen, 1999) which has been used in this study.
RMVE ESTIMATOR
In addition to the MCD, Rousseeuw (1985) introduced the minimum volume ellipsoid (MVE) as affine equivariant and high breakdown estimators of location and dispersion. The MVE estimators are based on the smallest volume ellipsoid that covers at least h = ⌊nγ⌋ (where 0.5<γ<1) observations. The MVE location estimator t∈Rp and dispersion estimator C minimize the determinant of positive definite symmetric matrix C of size p, subject to the condition:
| (8) |
The constant c determines the magnitude of C and is usually chosen to make C, a consistent estimator of the covariance matrix under multivariate normal model, i.e., ![]() . Davies (1992) has shown that the MVE location estimator has a slow n-1/3 rate of convergence and a non-normal asymptotic distribution. This low rate of convergence implies that the asymptotic efficiency of the MVE estimators is 0%. Therefore, to increase the efficiency of MVE, we propose to employ the re-weighted MVE (RMVE) similarly with the re-weighted MCD. For more details on MVE and RMVE estimators refer to the Van Aelst and Rousseeuw (2009).
. Davies (1992) has shown that the MVE location estimator has a slow n-1/3 rate of convergence and a non-normal asymptotic distribution. This low rate of convergence implies that the asymptotic efficiency of the MVE estimators is 0%. Therefore, to increase the efficiency of MVE, we propose to employ the re-weighted MVE (RMVE) similarly with the re-weighted MCD. For more details on MVE and RMVE estimators refer to the Van Aelst and Rousseeuw (2009).
DESIGNING THE ROBUST T2 CONTROL LIMITS
As mentioned before, in phase I analysis the usual control charts use standard mean and covariance matrix estimators, which are sensitive to outliers. It is known that the Mahalanobis distance based on the classical estimators is effective in detection of a single outlier, but is not appropriate in the case of multiple outliers.
This is due to the fact that, outliers mask each other and estimator fails to detect them, which is described as the masking effect. In the literature, a variety of robust estimators have been proposed to overcome this problem and minimize the impact of outliers. To this end, we constructed a new statistic by substituting the classical estimators in the Hotelling's T2 by the reweighted MCD and reweighted MVE estimators.
Consider that the phase I historical data set consists of n time-ordered vectors that are independent of each other. Each vector is of dimension p and there are no subsamples in the observations, the re-weighted MCD based Hotelling T2 statistic for phase II observation Xf∉{X1,..., Xn} is define as follows:
| (9) |
The finite-sample distributions of the T2RMCD (f) is unknown, therefore, we computed the control limits based on the empirical distributions of respective robust T2 charts. Several studies have been investigated the asymptotic properties of these estimators (Lopuhaa and Rousseeuw, 1991; Butler et al., 1993; Croux and Haesbroec, 1999). It should be noted that the ![]() and SRMCD are a good approximation to the parameters μ and Σ and Xf~MVNp (μ, Σ). In this case, if we use the Slutsky theorem, as n→4 the asymptotic distribution of robust T2 is χ2p. This asymptotic distribution is only applicable when n is large. In the case of small sample size, we apply Monte Carlo simulations to estimate the quantiles of the T2RMCD(f), for several combinations of sample sizes and dimensions. The robust T2 statistic based on the reweighted MVE estimators of location and dispersion is defined as:
and SRMCD are a good approximation to the parameters μ and Σ and Xf~MVNp (μ, Σ). In this case, if we use the Slutsky theorem, as n→4 the asymptotic distribution of robust T2 is χ2p. This asymptotic distribution is only applicable when n is large. In the case of small sample size, we apply Monte Carlo simulations to estimate the quantiles of the T2RMCD(f), for several combinations of sample sizes and dimensions. The robust T2 statistic based on the reweighted MVE estimators of location and dispersion is defined as:
| (10) |
where, ![]() and SRMVE are the re-weighted MVE estimates of mean vector and covariance matrix of phase I process, respectively. Since, the distribution or even asymptotic distribution of T2RMCD(f) is not known, so, we obtain the quantiles of the T2RMVE(f) for different combination of dimensions and sample sizes.
and SRMVE are the re-weighted MVE estimates of mean vector and covariance matrix of phase I process, respectively. Since, the distribution or even asymptotic distribution of T2RMCD(f) is not known, so, we obtain the quantiles of the T2RMVE(f) for different combination of dimensions and sample sizes.
SIMULATION
We generated 5000 samples of size n from a p-multivariate standard normal distribution MVNp(0, Ip). Our simulation process in phase I and phase II was constructed as follows:
Phase I: We computed the re-weighted MCD and MVE mean vector and covariance matrix estimates ( ![]() and SRMCD, SRMVE) for each data set of size n.
and SRMCD, SRMVE) for each data set of size n.
Phase II: In addition, as phase II observation, for each data set we randomly generated a new observation Xf from MVNp(0, Ip) and calculated the respective T2RMCD and T2RMVE value as given by Eq. 9, 10. Scatter plots of the empirical 99% quantiles of T2RMCD and T2RMVE versus the sample size n for different dimensions are presented in Fig. 1 and 2.
Since, the creation of control limits for each sample size is weariful and time consuming, it would be preferable to have a formula for the calculating of control limits.
Then we sketched the graph of the simulated quantiles for the T2RMCD(f) and T2RMVE(f) estimators versus the size of the data set n. A regression curve was fitted to smoothly predict the control limits for any phase I sample size n, dimensions p = 2, 6, 10 and confidence level 1-α = 0.99. With respect to the graph, we utilized the regression equation f(n) = β1+β2/nβ3 for the quantiles. As mentioned earlier, since the T2RMCD(f) is asymptotically distributed as χ2p, it is reasonable to use the χ2(p,1-α) instead of the β1,p,1-α,γ in Eq. 11:
| (11) |
where, χ2(p,1-α) is the 1-α quantile of the χ2p distribution with p degrees of freedom and β2,p,1-α,γ and β3,p,1-α,γ are constants. Three parameter curves give better fit for control limits of RMVE estimators based on T2 charts.
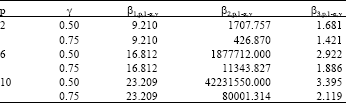
| Table 1: | The least square estimates of the regression parameters β1,p,1-α,γ and β2,p,1-α,γ and β3,p,1-α,γ for p = 2, 6, 10 confidence levels 1-" = 0.99 and breakdown points ( = 0.5, 0.75 for RMCD estimators |
 | |
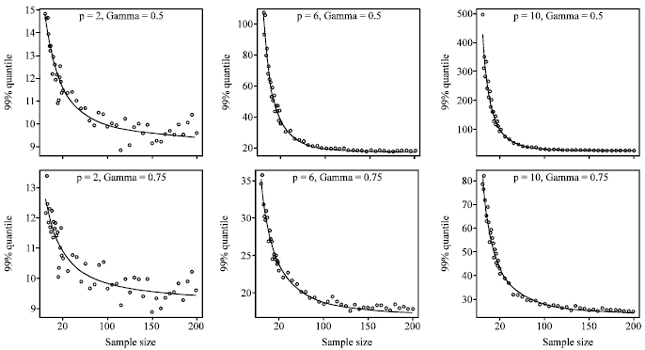 | |
| Fig. 1: | The 99% simulated quantiles of T2RMCD and the fitted curves for p = 2; 6; 10, γ = 0.5 (upper panel) and γ = 0.75 (lower panel) |
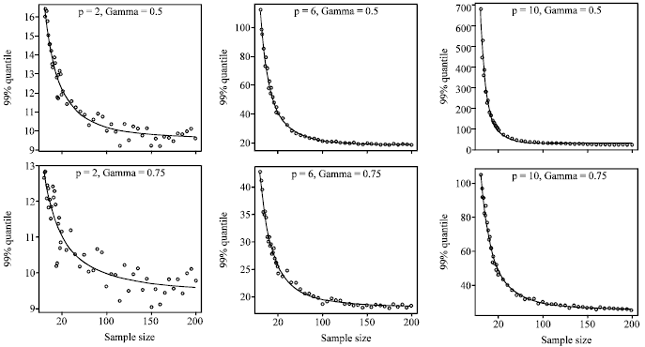 | |
| Fig. 2: | The 99% simulated quantiles of T2RMVE and the fitted curves for p = 2; 6; 10, γ = 0.5 (upper panel) and γ = 0.75 (lower panel) |
| Table 2: | The least square estimates of the regression parameters β1,p,1-α,γ and β2,p,1-α,γ and β3,p,1-α,γ for p = 2, 6, 10 confidence levels 1-α = 0.99 and breakdown points γ = 0.5, 0.75 RMVE estimators |
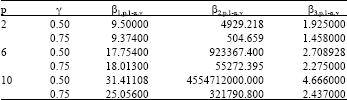 | |
Non linear least squares method was applied to estimate the parameters β1,p,1-α,γ, β2,p,1-α,γ and β3,p,1-α,γ which is shown in Table 1 and 2. Finally, in order to compute the robust control limits for p = 2, 6, 10 with varying sample size n, Table 1, 2 and Eq. 9 and 10 were used.
PERFORMANCE COMPARISON
Here, we designed a simulation study to assess the performance of our proposed methods. We considered different number of variables (p = 2, 6, 10) and the number of observations (n = 50, 150), breakdown point (γ = 0.5, 0.75), the proportion of outliers (π = 0.10, 0.20) and the amount of the shift in the process mean (δ = 3, 5). Our simulation studies include a no-outlier pattern and a pattern with multiple outliers. We can decide about the performance of the control chart by computing the probability of changes detection based on the Phase II data. The efficiency of control chart is determined by probability of signal that is the proportion of the T2RMCD and T2RMVE that is located over the control limit, using 1500 replications. We let δ2 = (μ-μA)'Σ-1 (μ-μA) be the non centrality parameter that measures the severity of a shift of the out of control mean vector μA compared to the in control mean vector μ. We can without loss of generality, use a zero mean vector as μ and the identity covariance matrix as Σ, due to affine equivariance property. To simulate changes in the process mean, the following cases are considered:
| • | In phase I we generated clean data set (no outlier) from the standard multivariate normal distribution MVNp(0, Ip), π of them are random data points generated from the out-of-control distribution (MVNp(μI, Ip)) and the other 1-π observations were generated from the in-control distribution (MVNp(0, Ip)) |
| • | Phase II data were generated from MVNp(0, μII) where, δ2II = ||μII||2. To evaluate the performance of various methods in each simulation, we generated a sample of size n and computed the T2RMCD(f) and T2RMVE(f) for breakdown points of γ = 0.5, 0.75 from Eq. 9 and 10, for each observation in phase II data. Then, we compared the T2RMCD(f) and T2RMVE(f) to the approximate control limits |
The purpose of this study is to compare the proposed method with other techniques such as standard T2 chart, robust T2MCD and T2MVE estimators discussed in Vargas (2003) and Jensen et al. (2007).
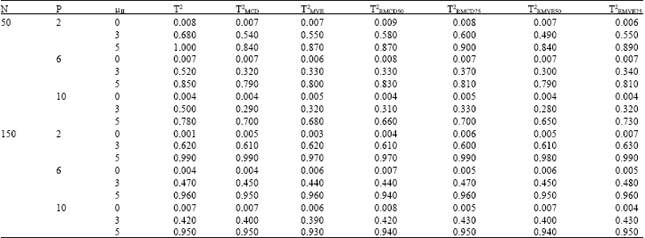
| Table 3: | Probability of signal in phase II, when phase I data is outlier free, for p =2, 6, 10 and sample size n = 50, 150 with different values of shift in phase II process mean vector μII |
 | |
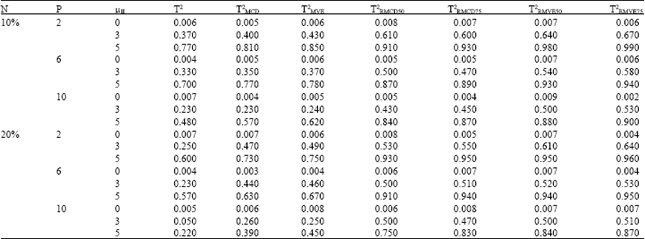
| Table 4: | Probability of signal in phase II, when there is a slight shift in phase I process mean vector (μI = 5), for p = 2, 6, 10 and sample size n = 50 with different values of shift in phase II process mean vector (μII) |
 | |
The probability of signal on the same data sets is computed. The MCD and MVE techniques are applied in phase I to detect outliers. Then we made the standard T2 chart based on the clean phase I data set and compared the corresponding T2 with an appropriate quantile of F distribution to monitor phase II data. The probability of signal for detecting outliers for different phase II process shifts in the mean vector are depicted in Table 3-7
δI = 0 (there was no outliers in the phase I): In all cases, from Table 3-7, it is visible, by increasing the non-centrality parameter the probability of signal increases as well.
In the case of small sample sizes, we observed that the best estimator was the standard T2, which is also supported by the previous studies (Wisnowski et al., 2002; Vargas, 2003; Jensen et al., 2007; Chenouri et al., 2009). Conversely, as the sample size increased to 150, the performance of all robust control charts are similar to the standard T2 chart and the performance was satisfactory.
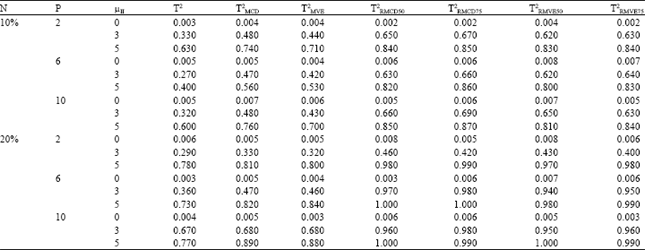
δI = 5 (small proportion of outlier in phase I): As shown in Table 4 and 5, when there was a slight shift in the phase I process mean vector, for small sample sizes T2RMVE slightly outperformed the T2RMCD and they perform better than the classical T2 and ordinary MCD and MVE. On the other hand, as the sample size increased, the performance of T2RMCD is slightly more superior to T2RMVE and other methods.
δI = 30 (large proportion of outlier in phase I): Based on Table 6 and 7, when the non-centrality parameter in phase I was large (δI = 30), the Re-weighted robust control charts for the breakdown point of γ = 0.5 and 0.75 surpassed the MCD, MVE and the classical T2 charts. In the case of small sample size, the performance of the T2RMVE based chart was the best. Conversely as the sample size increased T2RMCD slightly outperformed the T2RMVE.
| Table 5: | Probability of signal in phase II, when there is a slight shift in phase I process mean vector (μI = 5), for p = 2, 6, 10 and sample size n =150 with different values of shift in phase II process mean vector (μII) |
 | |
| Table 6: | Probability of signal in phase II, when there is a large amount of shift in phase I process mean vector (μI = 30), for p = 2, 6, 10 and sample size n =50 with different values of shift in phase II process mean vector (μII) |
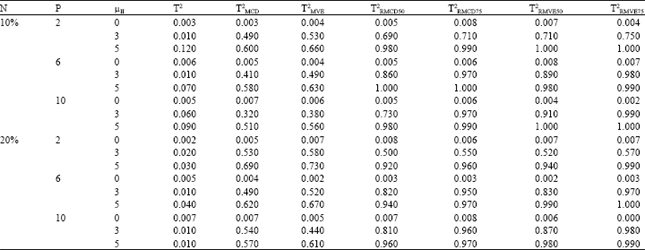 | |
| Table 7: | Probability of signal in phase II, when there is a large amount of shift in phase I process mean vector (μI = 30), for p = 2, 6, 10 and sample size n =150 with different values of shift in phase II process mean vector μII |
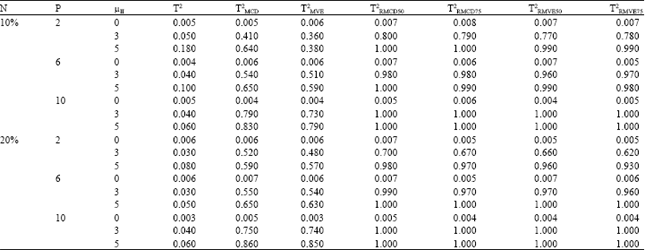 | |
The T2 did not work well, even for small sample size. In order to clarify the performance of the re-weighted robust control chart for different breakdown points of γ = 0.5 and 0.75 we classify the result based on the sample sizes.
Small sample size: Re-weighted robust control chart with γ = 0.75 worked better than γ = 0.5 in high dimensions.
Large sample size: For the small proportion of outlier, the Re-weighted robust control chart for both amount of γ = 0.5 and 0.75 worked almost similarly. However, if the percentage of outlier in data set was increased the Re-weighted robust control chart with γ = 0.5 outperformed the other methods. It is worthwhile noting that, when the phase I sample contained higher proportion of outliers, higher value of breakdown point was preferred. This is the main reason for the failure of robust control charts with γ = 0.75 when there are large numbers of outliers in phase I with large δ2.
CONCLUSIONS
Standard control charts are widely used in industry to detect the special causes of variation. The common out-of-control status is the occurrence of several outliers in the process. It is well known that the usual parameters estimations are sensitive to the presence of outliers, so the T2 chart based on these estimators performs poorly. Our advice in this study is replacing the classical mean vector and covariance matrix of the data in the Hotelling's T2 statistic by the Re-weighted MCD and Re-weighted MVE estimators. These estimators have many advantages, like affine equivariance and better efficiency than the ordinary MCD and MVE estimators used in Vargas (2003), Hardin and Rock (2004) and Jensen et al. (2007).
We also recommend generating the T2RMCD and T2RMVE control limit for combination of different sample size and dimension via Monte Carlo simulation. Our simulation studies showed that when the process was in-control and the sample size was small, the best estimator was the standard T2, as noted in the literatures. Nonetheless for large sample size the T2RMCD and the T2RMVE performed similar to the classical T2, chart. On the other hand, when there was outlier in phase I, T2RMCD and T2RMVE were more effective than the standard T2 and ordinary MCD and MVE charts.
In summary, we suggest that when phase I sample has outliers, the RMVE chart is suitable for small sample size and the RMCD chart is the best in the case of large sample size. Moreover, it is better to use γ = 0.5 with a large sample size (at least 10 times greater than p) to ensure better and consistent performance.
ACKNOWLEDGMENTS
We are grateful to Dr. Chenouri at University of Waterloo, Canada for his constructive comments.
REFERENCES
- Butler, R.W., P.L. Davies and M. Jhun, 1993. Asymptotics for the minimum covariance determinant estimator. Ann. Stat., 21: 1385-1400.
CrossRef - Croux, C. and G. Haesbroeck, 1999. Influence function and efficiency of the minimum covariance determinant scatter matrix estimator. J. Multivariate Anal., 71: 161-190.
CrossRef - Davies, L., 1992. The asymptotics of Rousseeuw`s minimum volume ellipsoid estimator. Ann. Statist., 20: 1828-1843.
CrossRef - Hardin, J. and D.M. Rocke, 2004. Outlier detection in the multiple cluster setting using the minimum covariance determinant estimator. Comput. Stat. Data Anal., 44: 625-638.
Direct Link - Jensen, W.A., J.B. Birch and W.H. Woodall, 2007. High breakdown estimation methods for phase I multivariate control charts. Qual. Reliabil. Eng. Int., 23: 615-629.
CrossRef - Lopuhaa, H.P. and P.J. Rousseeuw, 1991. Breakdown points of affine equivariant estimators of multivariate location and covariance matrices. Ann. Stat., 19: 229-248.
CrossRefDirect Link - Rousseeuw, P.J., 1985. Multivariate estimation with high breakdown point. Math. Statist. Appl., 13: 283-297.
Direct Link - Rousseeuw, P.J. and B.C. van Zomeren, 1990. Unmasking multivariate outliers and leverage points. J. Am. Stat. Assoc., 85: 633-639.
CrossRefDirect Link - Rousseeuw, P. and K. Van Driessen, 1999. A fast algorithm for the minimum variance determinant estimator. Technometrics, 41: 212-223.
CrossRef - Pison, G., S. van Alest and G. Willems, 2002. Small sample corrections for LTS and MCD. Metrika, 55: 111-123.
CrossRef - Tracy, N.D., J.C. Young and R.L. Mason, 1992. Multivariate control charts for individual observations. J. Qual. Technol., 24: 88-95.
Direct Link - Van Aelst, S. and P.J. Rousseeuw, 2009. Minimum volume ellipsoid. Wiley Interdisciplinary Rev. Comput. Stat., 1: 71-82.
CrossRef - Vargas, N.J.A., 2003. Robust estimation in multivariate control charts for individual observations. J. Qual. Technol., 35: 367-376.
Direct Link - Willems, G., G. Pison, P.J. Rousseeuw and S. van Alest, 2002. A robust hotelling test. Metrika, 55: 125-138.
CrossRef - Wisnowski, J.W., J.R. Simpson and D.C. Montgomery, 2002. A performance study for multivariate location and shape estimators. Qual. Reliability Eng. Int., 18: 117-129.
CrossRef