
G. R. Jahanshahloo
Faculty of Mathematical and Computer Sciences, Teacher Training University, 599 Taleghani Avenue, 15618 Tehran, Iran
J. Vakili
Faculty of Mathematical and Computer Sciences, Teacher Training University, 599 Taleghani Avenue, 15618 Tehran, Iran
S. M. Mirdehghan
Faculty of Mathematical and Computer Sciences, Teacher Training University, 599 Taleghani Avenue, 15618 Tehran, Iran
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 3 | Page No.: 450-461







ABSTRACT
Evaluating the performance of Decision-Making Units (DMUs) is a very important subject in Data Envelopment Analysis (DEA) and DEA does this by assigning a relative efficiency score to each DMU. In spite of the great importance of this subject, the majority of the methods presented in the different studies have not attempted to evaluate the performance of the inefficient DMUs beyond the relative efficiency scores attained from the standard DEA models. In this study, the minimum distance of each inefficient DMU from the efficient frontier is obtained by a branch-and-bound algorithm and then these distances are used as a criterion for evaluating the performance of the inefficient DMUs. It is known that using this method for evaluation is more realistic compared to other methods and also this method is able to remove the existing difficulties in some models, say, the CCR and BCC models. Also, this study proposes the use of the minimum distance of an inefficient DMU from the efficient frontier in order to obtain the shortest projection from the evaluated DMU to the efficient frontier, thus allowing an inefficient DMU to find the easiest way to improve its efficiency.
PDF Abstract XML References Citation
Received: September 23, 2010;
Accepted: October 19, 2010;
Published: January 22, 2011
How to cite this article
G. R. Jahanshahloo, J. Vakili and S. M. Mirdehghan, 2011. An Approach using a Branch-and-Bound Algorithm for Evaluating the Performance of Inefficient DMUs in DEA. Journal of Applied Sciences, 11: 450-461.
DOI: 10.3923/jas.2011.450.461
URL: https://scialert.net/abstract/?doi=jas.2011.450.461
DOI: 10.3923/jas.2011.450.461
URL: https://scialert.net/abstract/?doi=jas.2011.450.461
INTRODUCTION
Data Envelopment Analysis (DEA) was initially proposed by Charnes et al. (1978) (the CCR model) and was improved by other scholars, especially Banker et al. (1984) (the BCC model) to evaluate the performance of a homogeneous group of operating decision-making units (DMUs), such as schools, hospitals, or sales outlets, which use a set of resources, referred to as inputs and transform them into a set of outcomes, referred to as outputs. For evaluating the performance of DMUs, DEA successfully divides them into two categories: efficient DMUs and inefficient DMUs. DEA does this by assigning a relative efficiency score to each DMU such that the DMUs in the efficient category have identical relative efficiencies equal to one and the rest have the relative efficiency between zero and one (Cooper et al., 2000). DEA does not provide more information about the efficient DMUs; nevertheless, it is not appropriate to claim that they have identical performance in actual practice. However, there are many methods to rank the efficient DMUs (Adler et al., 2002; Andersen and Petersen, 1993; Li et al., 2007; Jahanshahloo et al., 2008; Liu and Peng, 2008). As regards for the inefficient DMUs, the majority of the methods presented in the different studies have not attempted to evaluate the performance of the inefficient DMUs beyond the relative efficiency scores attained from the standard DEA models. Nevertheless, there are some methods for ranking the inefficient DMUs, (Bardhan et al., 1996; Torgersen et al., 1996; Baek and Lee, 2009; Jahanshahloo and Afzalinejad, 2006), which suggest methods different from the standard DEA models for evaluating the performance of inefficient DMUs. One concept, derived in Bardhan et al. (1996), attempts to rank the inefficient DMUs using a Measure of Inefficiency Dominance (MID) according to their average proportional inefficiency in all inputs and outputs. Moreover, Torgersen et al. (1996) ranked the inefficient DMUs by counting the number of DMUs that need to be removed from the analysis before they are considered efficient. However, a complete ranking cannot be assured since many DMUs may receive the same ranking score. In the method suggested by Jahanshahloo and Afzalinejad (2006), a full-inefficient frontier having been defined, DMUs are ranked based on their distance from this frontier. The method presented by Baek and Lee (2009) proposes the use of the Least-Distance Measure in order to evaluate the performances. By considering these methods and all methods in the literature, the distance between the inefficient DMUs and the efficient frontier of the Production Possibility Set (PPS) is a very important criterion for evaluating the performance of the inefficient DMUs. On the other hand, since the efficient frontier of the PPS contains the efficient DMUs, the less the distance of an inefficient DMU from the efficient frontier, the easier it is to remove its inefficiency by less variations in its inputs and outputs. Hence, the closer the DMU under assessment to the efficient frontier, the better the performance of this DMU. But the majority of the methods do not obtain the distance of the inefficient DMUs from the efficient frontier exactly for evaluating the performance of the DMUs. For example, the CCR and BCC models approximate the distance of the inefficient DMUs from the efficient frontier of the PPS in a manner similar to the methods used for evaluating the performance of the inefficient DMUs. However, since these models do not obtain the distance of an inefficient DMU from the efficient frontier accurately, there exists some difficulties for evaluating the performances in practice.
There are several methods to determine the minimum distance of an inefficient DMU from the efficient frontier (Cherchye and van Puyenbroeck, 2001; Cooper et al., 2000; Frei and Harker, 1999; Gonzalez and Alvarez, 2001; Lozano and Villa, 2005; Silva Portela et al., 2003; Baek and Lee, 2009), but some of them have some difficulties when used in practice. The procedure by Gonzalez and Alvarez (2001) cannot always guarantee to reach the efficient projection that is actually the closest to the assessed DMU; Frei and Harker (1999) proposed an algorithm to obtain all the efficient facets that do not always completely describe the efficient frontier and the approach in Cooper et al. (2000) might lead to a projection that is not an efficient point. The approaches by Cherchye and Van Puyenbroeck (2001) and Silva Portela et al. (2003) do find the solution that is wanted. Nevertheless, they need in a previous stage to identify all the efficient facets of the PPS frontier in order to determine the closest efficient projection. The method presented by Lozano and Villa (2005) finds the sequence of targets ended in the efficient frontier and the efficient projection found in the final stage is generally closer to the original unit than the one-step projection is, but it is not necessarily the closest efficient projection to the original unit. The recently presented method by Baek and Lee (2009) proposes the use of the Least-Distance Measure in order to obtain the shortest projection from the evaluated DMU to the efficient frontier, thus allowing an inefficient DMU to find the easiest way to improve its efficiency. In this paper, first, a method is developed using a branch-and-bound algorithm that is able to determine the minimum distance of the inefficient DMUs from the efficient frontier (by norms || . ||1 and || . ||∝ and then, using these distances, a score is assigned to each inefficient DMU for evaluating the performance of inefficient DMUs such that the less the score of an inefficient DMU, the better its performance. The proposed method has the following advantages:
| • | As is known, obtaining the minimum distance of an inefficient DMU from the efficient frontier is a very important subject in DEA. This method finds these distances by an interesting branch-and-bound algorithm and hence proposes the use of these distances in order to obtain the shortest projection from the evaluated DMU to the efficient frontier, thus allowing an inefficient DMU to find the easiest way to improve its efficiency |
| • | Owing to obtaining the minimum distance of the inefficient DMUs from the efficient frontier exactly and using these distances for evaluation, the method proposed in this paper is more realistic for evaluating the performance of the inefficient DMUs compared to other methods and also it is able to remove the existing difficulties in some models, say, the CCR and BCC models |
DATA ENVELOPMENT ANALYSIS
Consider a set of n DMUs, Ω = {DMU1, DMU2, ..., DMUn}, where, each DMUj (jεJ = {1,2, ..., n}) produces s outputs yrj (r = 1,2, ..., s) using m inputs xij (i = 1,2, ..., m). Define xj = (x1j, x2j,..., xmj)t ![]() and yj = (y1j, y2j,..., ysj)t
and yj = (y1j, y2j,..., ysj)t ![]() as the input and output vectors of DMUj, respectively, all components of vectors xj and yj for all DMUs being non-negative and each DMU having at least one strictly positive input and output, that is: xj≥0, xj ≠ 0 and yj≥0, yj ≠ 0; j ε J. Also, X = [x1, x2,...,xn] and Y = [y1, y2,...,yn] are mxn and sxn matrices of inputs and outputs, respectively. The production possibility set (PPS) T is represented as:
as the input and output vectors of DMUj, respectively, all components of vectors xj and yj for all DMUs being non-negative and each DMU having at least one strictly positive input and output, that is: xj≥0, xj ≠ 0 and yj≥0, yj ≠ 0; j ε J. Also, X = [x1, x2,...,xn] and Y = [y1, y2,...,yn] are mxn and sxn matrices of inputs and outputs, respectively. The production possibility set (PPS) T is represented as:
The definition of the PPS depends on the postulates selected by the manager. Charnes et al. (1978) deduced the following PPS, considering some postulates. This set is denoted by Tc, which signifies the prevalence of constant returns to scale.
Banker et al. (1984) introduced the following PPS by considering some postulates, which is obtained by adding the constraint ![]() to TC, where,1n is a vector in ún with all components equal to one and "." shows the dot or inner product of the two vectors. This set is denoted by Tv, which signifies the prevalence of variable returns to scale.
to TC, where,1n is a vector in ún with all components equal to one and "." shows the dot or inner product of the two vectors. This set is denoted by Tv, which signifies the prevalence of variable returns to scale. ![]() .
.
Definition 1: (xo, yo) εT is called an efficient unit in T if there is no other (x, y) εT such that (x,-y)≤(xo,-yo) and strict inequality holds in at least one component.
By the above definition, (xo, yo)εT is an efficient unit if it is not possible to improve any of its inputs or outputs in T without worsening some other inputs or outputs. The set of all efficient units is a subset of the PPS, which is called the efficient frontier and is denoted by ∂E (T). That is:
If (xo,yo)εT is not an efficient unit, then it is an inefficient unit. This means that it is possible to improve the inputs or outputs of this DMU in the PPS without worsening some other inputs or outputs.
Now, we introduce the input- and output-oriented CCR and BCC models for assessing the relative efficiency of (xo,yo) by the assumption of constant and variable returns to scale and in order to compare these models with our method for evaluating the performance of the inefficient DMUs:
| • | The input-oriented BCC model corresponding to (xo,yo) ε Tv |
| (1) |
| • | The output-oriented BCC model corresponding to (xo,yo) ε Tv |
| (2) |
Also, by replacing Tc with Tv in the constraints of Models 1 and 2, the input- and output-oriented CCR models corresponding to (xo, yo) ε Tc are obtained, respectively, whose optimal values are represented by θc(xo, yo) and φc(xo, yo), respectively. Using these models, the performance of the inefficient DMUs can be evaluated according to the scores that are obtained at the end of the analysis. For the input-oriented CCR/BCC model corresponding to (xo,yo), the more θc(xo, yo)/θv(xo, yo), the better the performance of (xo, yo). But for the output-oriented CCR/BCC model corresponding to (xo, yo), the less φc(xo, yo)/φv (xo, yo), the better the performance of (xo, yo).
DEA was introduced to provide a ranking for all DMUs. For efficient DMUs, there are many methods to do this (Adler et al., 2002; Andersen and Petersen, 1993; Li et al., 2007; Jahanshahloo et al., 2008; Liu and Peng, 2008). For inefficient DMUs, the minimum distance between DMUo and the boundary of the PPS is approximated. Since the PPS frontier contains the efficient DMUs, the less the minimum distance, the more the efficiency. For estimating the minimum distance between DMUo and the boundary of the PPS, DEA models try to decrease/increase the inputs/outputs of DMUo as much as possible. This means that the inputs/outputs of DMUo are decreased/increased until a DMU on the PPS frontier is obtained and this DMU is called the efficient pattern of DMUo. The distance between DMUo and its efficient pattern is considered as an inefficiency score. To achieve efficiency, it is suggested that DMUo decrease/increase its inputs/outputs until the efficient pattern is achieved. Hence, the closer the efficient pattern to DMUo, the easier it is to remove the inefficiency of DMUo by less variations in its inputs and outputs. There are many models in DEA to obtain the efficient pattern for the DMU under assessment, which can be divided into two classes.
| • | Radial models: In these models (for example, the CCR and BCC models), the inputs/outputs of the DMU under assessment are decreased/increased proportionally until we reach the PPS frontier |
| • | Non-radial models: In these models (for example, the Additive model), the inputs/outputs of DMUo are decreased/increased such that the weighted sum of the variations is maximized, in which case the DMU reaches the PPS frontier |
The following example shows the drawbacks of the radial and non-radial models to determine the efficiency score and efficient pattern.
Example 1 (Motivating example): Consider the input-oriented CCR model, one of the famous radial models, as follows:
θc(xo, yo) = min{θ:(θxo, yo)εTc} |
For the above model, (θc(xo,yo)xo,yo) is an efficient pattern and its inefficiency score is:
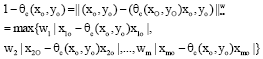 |
where, wi = 1/xio if xio ≠ 0 and wi = 0 if xio = 0, i = 1,2,.., m. There are two drawbacks for Model CCR:
| • | The pattern is not necessarily efficient unit and could be weakly efficient unit |
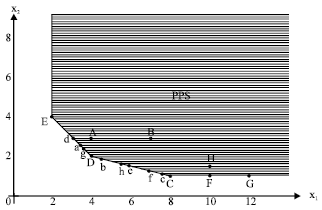 | |
| Fig. 1: | The production possibility set in the illustrative example |
| • | Even if the pattern is efficient unit, it might not necessarily be the closest efficient unit to the DMU under assessment |
Figure 1 demonstrates the intersection of the PPS Tc for DMUA to DMUH and the hyperplane y = 1. Consider DMUo := DMUF as the DMU under assessment. For this DMU, θc(DMUF) = 1. So, its inefficiency score is zero and it is considered as its own efficient pattern, though it is not an efficient unit. Now, let DMUo := DMUB be the DMU under assessment. An efficient pattern for this DMU is
and its inefficiency score is 1-θc(DMUB) = 7/19. However, it can be shown that the closest efficient units to this DMU are f(7, 5/4, 1) and h(28/5, 8/5, 1) by the ||.||1 distance and ||.||∝ distance, respectively. Now, there are three efficient patterns for DMUB, which are obtained by the CCR model and the ||.||1 and ||.||∝ methods. It is evident that DMUB can achieve efficiency more easily (by less variations in its inputs) if it chooses the efficient patterns obtained by the ||.||1 and ||.||∝ methods. In fact, if DMUB chooses the efficient pattern of the CCR model, then its inputs should be decreased by (49/19, 21/19). In this case, the sum of the variation and the maximum variation to attain efficiency are 70/19 and 49/19, respectively. If the efficient pattern by the ||.||1 method is chosen, then the inputs should be decreased by (0, 7/4) and the sum of the variations and the maximum variations are 7/4 and 7/4, respectively. If the efficient pattern by the ||.||∝ method is selected, then the inputs should be decreased by (7/5, 7/5) and the sum of the variations and the maximum variation are 14/5 and 7/5, respectively. Therefore, if the efficient patterns obtained by the ||.||1 and ||.||∝ methods are chosen, then efficiency can be achieved by less variations in its inputs and outputs. In this study, we are going to provide a method which is capable of determining the closest efficient patterns by the ||.||1 and ||.||∝ methods for the DMU under assessment. In what follows, it will be shown that the above-mentioned difficulty of radial models is also present in non-radial models and is even worse.
Consider the Additive model, one of the well known non-radial models, as follows:
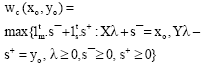 |
In the Additive model, the efficient pattern for DMUo is (xo-s¯*, yo+s+*), (“*" denotes optimality) and the inefficiency score is:
In all optimal solutions of the Additive model, the efficient pattern is efficient and hence Additive Model can be rewritten as follows:
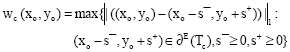 |
The above model reveals that the Additive model chooses the farthest efficient unit (by the ||.||1 distance) among all efficient units dominating DMUo. Thus, not only the efficient pattern of the Additive model is not the closest efficient unit, it is indeed the farthest efficient unit among those dominating DMUo. For example, consider DMUB as the DMU under assessment in Fig. 1 again. The Additive model has proposed (3,3,1) as an efficient pattern and its inefficiency score is 4. So, DMUB should decrease its inputs by (4,0) to achieve efficiency. In this case, the sum of the variations and the maximum variation to attain efficiency is 4. Therefore, for this DMU the Additive efficient pattern is worse than the efficient patterns proposed by the CCR model and the ||.||1 and ||.||∝ methods. Table 1 and 2 show the efficient patterns and the inefficiencies of all DMUs.
Note that we consider the PPS Tv to continue our discussion, but we can have a similar argument for Tc.
| Table 1: | Inefficiency scores and efficient pattern by the CCR and additive models |
 | |
| Table 2: | Inefficiency scores and efficient pattern by the ||.||1 and ||.||∝ methods |
 | |
THE BRANCH-AND-BOUND ALGORITHM FOR EVALUATING THE PERFORMANCE OF INEFFICIENT DMUS AND OBTAINING THE CLOSEST EFFICIENT TARGET
Consider a set of DMUs Ω with the input and output vectors as given in the previous section. In this section, using the branch-and-bound algorithm, we obtain the minimum distance between the inefficient DMUs and the efficient frontier of Tv.
Assume that E is the indices' set of the efficient DMUs in Ω and IE = Ω\E and also consider DMUo = (xo, yo) as the observed inefficient DMU under assessment, that is: oεIE.
Considering an arbitrary norm, say ||.||, the minimum distance of DMUo from ∂E(Tv) can be obtained as:
| (3) |
For the sake of linearization of the problems that will be solved by the branch-and-bound algorithm, we consider ||.||∝ and ||.||1 in Problem Eq. 3. Considering ||.||1, this problem leads to the following problem:
| (4) |
Let (x,y) = (xo-s¯, yo+s+) while s¯ εúm and s+ εús, then Problem Eq. 4 is transformed to the following problem:
| (5) |
Note that ∂E(Tv) is not usually a convex set and hence Problem Eq. 5 is not a convex problem. Also, it is very difficult to determine ∂E(Tv) exactly; therefore, solving Problem Eq. 5 is not simple. But the following theorem shows that Model Eq. 5 is equivalent to a solvable problem.
Theorem 1: The optimal value of Problem Eq. 5 is equal to the optimal value of Problem Eq. 6. That is: ![]() .
.
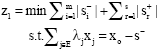 | (6.1) |
| (6.2) |
| (6.3) |
| (6.4) |
| (6.5) |
| (6.6) |
| (6.7) |
Proof: Since, ∂E(Tv) is a nonempty and closed set and the objective function of Problem Eq. 5 is nonegative and continuous, this problem has a finite optimal value and its optimal solution belongs to ∂E(Tv). Suppose that (s¯*, s+*) is an optimal solution of Problem Eq. 5. This means that (xo-s¯*, yo+s+*) ε ∂E(Tv). Hence, the optimal value of Model Eq. 7 must be zero.
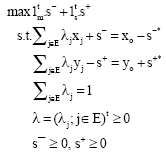 | (7) |
Then, the Karush-Kuhn-Tucker Conditions in linear programming imply that there is ![]() such that:
such that:
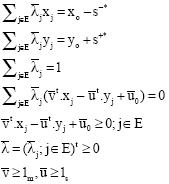 | (8) |
Relation Eq. 8 shows that ![]() is a feasible solution for Problem Eq. 6. Therefore,
is a feasible solution for Problem Eq. 6. Therefore,
Conversely, suppose that ![]() is an optimal solution of Problem Eq. 6. Then the Karush-Kuhn-Tucker Conditions in linear programming imply that the optimal value of Model Eq. 7 must be zero. Thus (xo-s¯*,yo+s+*) ε∂E(Tv). Then (s¯*, s+*) is a feasible solution for Problem Eq. 5. Thus:
is an optimal solution of Problem Eq. 6. Then the Karush-Kuhn-Tucker Conditions in linear programming imply that the optimal value of Model Eq. 7 must be zero. Thus (xo-s¯*,yo+s+*) ε∂E(Tv). Then (s¯*, s+*) is a feasible solution for Problem Eq. 5. Thus:
And this completes the proof.
The objective function of Problem Eq. 6 is nonlinear owing to the presence of the absolute function, but the following theorem shows that it can be linearized.
Theorem 2: Assume that we perform the following change of variables in Problem Eq. 6:
then Problem Eq. 6 is equivalent to the following problem:
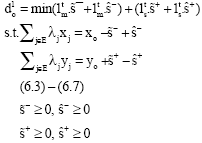 | (9) |
Proof: To prove this theorem, it is sufficient to show that in all optimal solutions of Problem Eq. 6, we have:
The above relation holds if ![]() and
and ![]() for each i and r. By contradiction, assume that for an optimal solution of Problem Eq. 6 there is an index i such that
for each i and r. By contradiction, assume that for an optimal solution of Problem Eq. 6 there is an index i such that ![]() If we replace
If we replace ![]() and
and ![]() by
by ![]() and
and ![]() respectively and the other values of variables remain unchanged, then a new feasible solution is obtained with a smaller objective value, which is a contradiction to the optimality condition.
respectively and the other values of variables remain unchanged, then a new feasible solution is obtained with a smaller objective value, which is a contradiction to the optimality condition.
Now, we extend the above argument for ||.||∞. Suppose that in Problem Eq. 3, ||.||∞ is chosen as the distance function. Then, Problem Eq. 3 leads to the following problem:
| (10) |
If we let (x, y) = (xo-s¯,yo+s+) while s¯εúm and s+ ε ús, then Problem Eq. 10 yields the following problem:
| (11) |
The following theorem shows that Model Eq. 11 is equivalent to a nonlinear problem that is solvable. The proof of this theorem is similar to that of Theorem 1 and hence is omitted.
Theorem 3: The optimal value of Problem Eq. 11 is equal to the optimal value of Problem Eq. 12. That is: ![]()
| (12) |
Proof: The proof of this theorem is similar to that of Theorem 1.
Although, the objective function of Problem Eq. 12 is nonlinear owing to the presence of absolute functions, using the change of variable ![]() Problem Eq. 12 can be converted to Problem Eq. 13 with the linear objective function:
Problem Eq. 12 can be converted to Problem Eq. 13 with the linear objective function:
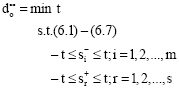 | (13) |
Hence, for obtaining the minimum distance of DMUo from ∂E(Tv) by ||.||1 and ||.||∞, we must solve Problems Eq. 9 and 13, respectively. But notice that these models are nonlinear programming problems because of the existence of the constraint:
| (14) |
Now, in the following we present a branch-and-bound algorithm that solves Problem Eq. 9 by solving some linear programming problems. It is clear that solving Problem Eq. 13 is similar to Problem Eq. 9.
THE BRANCH-AND-BOUND ALGORITHM FOR SOLVING PROBLEM EQ. 9
Problem 9 provides the theoretical foundation for our new algorithm. To elaborate on the following algorithm, it must be stated that the algorithm for solving Problem 9 considers a branch-and-bound tree corresponding to Problem 9. This tree contains some nodes and edges and one linear programming problem has been assigned to each node and one variable has been assigned to each edge. To solve Problem 9, this algorithm moves along the edges and considers some nodes and solves the linear programming problems corresponding to them.
Also, the algorithm uses the leftmost node searching method for traveling to all the nodes of the tree. All nodes of the tree have been coded by vector k and each path in the branch-and-bound tree is determined by this vector and its dimension is the current depth of the tree. The components of vector k are 0 or 1, in which 0 demonstrates moving along the left edge and 1 demonstrates moving along the right edge. Further moving along some paths is stopped if the conditions presented in Steps 1,2,3,4 and 8 hold. By these conditions, it is not necessary to travel to all nodes. In other words, Problem 9 is solved by traveling to only some nodes and solving their linear programming problems, which greatly reduces the computational complexity.
Scalar wk demonstrates whether or not Node k has been visited. That is to say, if wk = 0, then the left and right edges of Node k have not been visited and if wk = 1, then the left edge of Node k has been visited but the right edge has not. If wk = 2, then the left and right edges of Node k have been visited. Wk is the set of remaining indices E that can be added to ![]() or
or ![]() and can develop the depth of the tree. Also, in each node, sets of indices
and can develop the depth of the tree. Also, in each node, sets of indices ![]() and
and ![]() are used for imposing conditions:
are used for imposing conditions:
on Problem (9) without condition Eq. 14.
We consider the branch-and-bound algorithm for solving Problem (9) as follows.
Step 0: Input
(notice that k is a vector) and then go to Step 1.
Step 1: Solve the following problem:
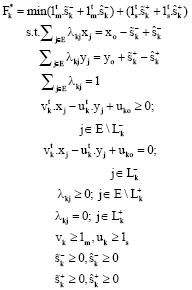 | (15) |
If it is feasible, then go to Step 2, else go to Step 5.
Step 2: If ![]() then go to Step 3, else go to Step 5.
then go to Step 3, else go to Step 5.
Step 3: If ![]() ( "*" shows the optimality) then set:
( "*" shows the optimality) then set:
and go to Step 8, else go to Step 4.
Step 4: If Wk = Ø, then go to Step 5, else go to Step 9.
Step 5: Remove the last component of vector k and save the obtained vector in ![]() . If
. If ![]() then go to step 7, else set
then go to step 7, else set ![]() and go to step 6.
and go to step 6.
Step 6: If k =(0) and wk = 2, then go to step 10, else go to Step 5.
Step 7: First set ![]() and then set wk = 2. Then, add one component 1 to the right-hand side of the components of vector k such that the dimension of this vector is increased by 1. Save this obtained vector in
and then set wk = 2. Then, add one component 1 to the right-hand side of the components of vector k such that the dimension of this vector is increased by 1. Save this obtained vector in ![]() . Then select
. Then select ![]() Also set:
Also set: ![]() ,
, ![]() At last set k =
At last set k = ![]() and then go to Step 1.
and then go to Step 1.
Step 8: If k = (0) then go to Step 10, else go to Step 5.
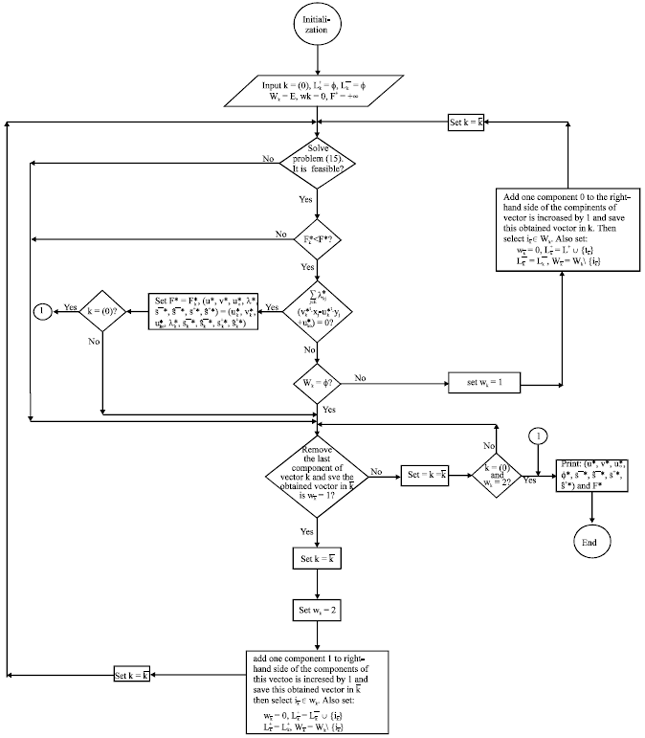 | |
| Fig. 2: | The flowchart of the branch-and bound algorithm for solving problem 9 |
Step 9: First set wk = 1 and then add one component 0 to the right-hand side of the components of vector k, such that the dimension of this vector is increased by 1 and save this obtained vector in ![]() . Then select
. Then select ![]() Also, set:
Also, set: ![]() ,
, ![]() At last set
At last set ![]() and then go to Step 1.
and then go to Step 1.
Step 10: Print ![]() and F*.
and F*.
The flowchart of this algorithm is represented as Fig. 2.
TWO NUMERICAL EXAMPLES
Here, we present two examples to explain the method presented in this study. The first example indicates how to obtain the minimum distance of the inefficient DMUs from the efficient frontier by the branch-and-bound algorithm. Also, this example demonstrates the weakness of the input- and output-oriented BCC models in comparison with our method for evaluating the performance of the inefficient DMUs. We present this simple example to demonstrate the weakness of two input- and output-oriented BCC models in comparison with our method contemporaneously. Also, since the PPS can be shown as a simple graphic in this example, it is possible to check geometrically whether the minimum distances obtained by our method are correct or not. Also, this example is related to the variable returns to scale. But the second example is related to the constant returns to scale and this example compares the results of evaluating the performance of the inefficient DMUs obtained by the our method and the two input- and output-oriented CCR models.
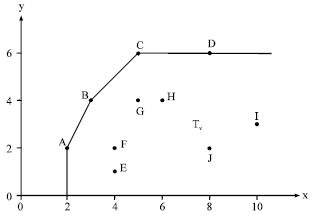
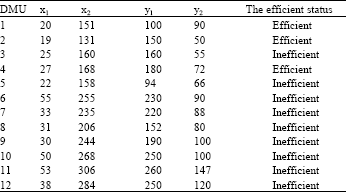
Example 2: Consider set Ω = {DMUA, DMUB, DMUC, DMUD, DMUE, DMUF, DMUG, DMUH, DMUI, DMUJ}, with one input and one output for each DMU as shown in Table 3 as the set of the observed DMUs. Also, Table 3 demonstrates the efficiency status of DMUs and Fig. 3 demonstrates the PPS Tv produced by these DMUs.
Considering Fig. 3, the points on the line segments ![]() and
and ![]() compose the efficient frontier of Tv. Now, we explain how to obtain the minimum distance by ||.||1 of DMUs from the efficient frontier by the branch-and-bound algorithm. Obtaining the minimum distance of other inefficient DMUs from ∂E(Tv) is similar to this. To obtain the minimum distance of DMUI from ∂E(Tv), Steps 0 and 1 imply that first, we must solve the following problem:
compose the efficient frontier of Tv. Now, we explain how to obtain the minimum distance by ||.||1 of DMUs from the efficient frontier by the branch-and-bound algorithm. Obtaining the minimum distance of other inefficient DMUs from ∂E(Tv) is similar to this. To obtain the minimum distance of DMUI from ∂E(Tv), Steps 0 and 1 imply that first, we must solve the following problem:
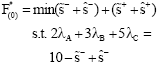 | (16.1) |
| Table 3: | Data and the efficiency status |
 | |
 | |
| Fig. 3: | The production possibility set Tv |
| (16.2) |
| (16.3) |
| (16.4) |
| (16.5) |
| (16.6) |
| (16.7) |
| (16.8) |
| (16.9) |
| (16.10) |
After solving Problem Eq. 16, which is corresponding to the root node, the optimal value
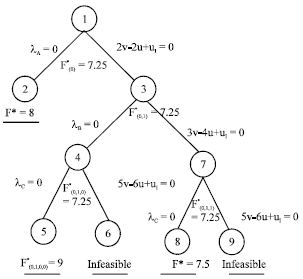 | |
| Fig. 4: | The tree corresponding to DMUI |
are obtained. Since, the optimal solution of Problem (16) does not satisfy condition (14), we move to Node 2 as shown in Fig. 4 and by imposing constraint λA = 0 on Problem (16), solve the following problem:
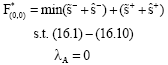 | (17) |
By which the optimal value ![]() and the optimal solution:
and the optimal solution:
are obtained. But since the optimal solution of Problem Eq. 17 satisfies condition (14) and ![]() then we give the new value
then we give the new value ![]() to F*, that is, we set F* = 8. Also, further moving along the left and right edges of Node 2 is stopped. Thus, we return to Node 1 and from Node 1 move to Node 3. The problem corresponding to Node 3 is the following problem which must be solved:
to F*, that is, we set F* = 8. Also, further moving along the left and right edges of Node 2 is stopped. Thus, we return to Node 1 and from Node 1 move to Node 3. The problem corresponding to Node 3 is the following problem which must be solved:
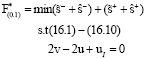 | (18) |
After solving Problem Eq. 18, the optimal value ![]() = 7.25 and the optimal solution:
= 7.25 and the optimal solution:
are obtained. Since, the optimal solution of Problem (18) does not satisfy condition (14) and also since ![]() then further moving from this node is not stopped. Therefore, we go to Node 4. By solving the problem corresponding to Node 4,
then further moving from this node is not stopped. Therefore, we go to Node 4. By solving the problem corresponding to Node 4,![]() and
and
are obtained. Then, we move to Node 5 and solve the following problem:
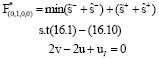 | (19) |
Problem Eq. 19 has the optimal value ![]() and the optimal solution:
and the optimal solution:
Since, Node 5 is the final node, then further moving from this node is impossible and since ![]() , we do not vary the value F*, which is F* = 8. Now, we move to Node 6, whose corresponding problem is Problem Eq. 20 and is infeasible:
, we do not vary the value F*, which is F* = 8. Now, we move to Node 6, whose corresponding problem is Problem Eq. 20 and is infeasible:
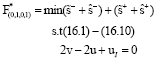 | (20) |
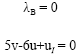 |
Next, we go to Node 7 and solve its corresponding problem. But since the optimal solution and optimal value of the problem corresponding to this node are similar to those of Nodes 3 and 4, hence we move to the new Node 8.
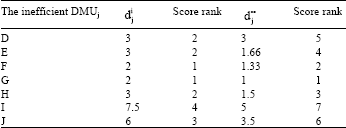
| Table 4: | The results of evaluation by our method |
 | |
| Table 5: | The results of evaluation by the BCC model |
 | |
By solving the problem corresponding to this node, the optimal value and the optimal solution of this problem are obtained as follows.
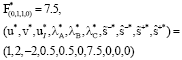 |
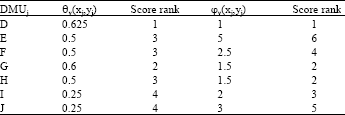
In reality, since this solution satisfies condition (14) and ![]() and the problem related to the next node (Node 9) is infeasible, therefore the minimum distance of DMUl from the efficient frontier is 7.5. If we similarly obtain the minimum distances of the other inefficient DMUs from the efficient frontier by ||.||1 and ||.||∝ and also obtain the optimal value of the input- and output-oriented BCC models for the inefficient DMUs, then Table 4 and 5 are obtained.
and the problem related to the next node (Node 9) is infeasible, therefore the minimum distance of DMUl from the efficient frontier is 7.5. If we similarly obtain the minimum distances of the other inefficient DMUs from the efficient frontier by ||.||1 and ||.||∝ and also obtain the optimal value of the input- and output-oriented BCC models for the inefficient DMUs, then Table 4 and 5 are obtained.
As shown in Table 5, the input-oriented BCC model evaluates the performances of DMUE and DMUF identically, while these DMUs have equal inputs and DMUF has greater output than DMUE. Therefore, DMUF must have a better performance than DMUE. But considering Table 4, our method evaluates their performances correctly by both ||.||1 and ||.||∞ and gives a better rank to DMUF than DMUE. Also, the output-oriented BCC model ranks DMUG and DMUH identically, while these DMUs have equal outputs and the input of DMUG is less than the input of DMUE. However, our method evaluates their performance correctly and gives a better rank to DMUG than DMUH.
Example 3: Consider the DMUs in Table 6 which records behavior intended to serve as a basis for evaluating the performance of the inefficient hospitals in terms of two inputs, number of doctors and number of nurses and two outputs identified as number of outpatients and inpatients (each in units of 100 persons/month).
| Table 6: | Data of the observed DMUs |
 | |
| Table 7: | The results of evaluation of the performances |
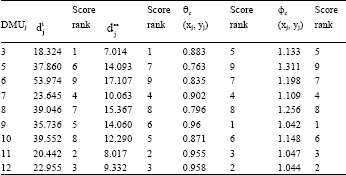 | |
Also, Table 6 demonstrates the efficiency status of these DMUs. The results of evaluation using our method and the input- and output-oriented CCR models are exhibited in Table 7.
CONCLUSION
In this study, a method has been presented for evaluating the performance of the inefficient DMUs, which is based upon the minimum distance of these DMUs from the efficient frontier. This method is different and more realistic compared to the other methods of evaluation of the performances and it is able to remove the existing difficulties in some standard DEA models, say, the CCR and BCC models. We proposed a methodology based on the branch-and-bound algorithm that allows us to obtain the closest targets and the best efficient patterns for the inefficient DMUs by ||.||∞ and ||.||1. These norms are considered for the sake of the linear property and computational advantages. However, other norms and criteria could be regarded as well. The general argument behind this idea is that the closest targets and best efficient patterns suggest directions of improvement for the inputs and outputs of the inefficient units that can help them to achieve efficiency with the least effort.
REFERENCES
- Adler, N., L. Friedman and Z. Sinuany-Stern, 2002. Review of ranking methods in the data envelopment analysis context. Eur. J. Operational Res., 140: 249-265.
Direct Link - Andersen, P. and N.C. Petersen, 1993. A procedure for ranking efficient units in data envelopment. Manage. Sci., 39: 1261-1264.
Direct Link - Baek, C. and J.D. Lee, 2009. The relevance of DEA benchmarking information and the least-distance measure. Math. Comput. Modell., 49: 265-275.
CrossRef - Banker, R.D., A. Charnes and W.W. Cooper, 1984. Some models for estimating technical and scale Inefficiencies in data envelopment analysis. Manage. Sci., 30: 1078-1092.
CrossRefDirect Link - Charnes, A., W.W. Cooper and E. Rhodes, 1978. Measuring the efficiency of decision making units. Eur. J. Operat. Res., 2: 429-444.
CrossRefDirect Link - Cherchye, L. and T. van Puyenbroeck, 2001. A comment on multi-stage DEA methodology. Operat. Res. Lett., 28: 93-98.
CrossRef - Frei, F.X. and P.T. Harker, 1999. Projections onto efficient frontiers: Theoretical and computational extensions to DEA. J. Productivity Anal., 11: 275-300.
CrossRef - Gonzalez, E. and A. Alvarez, 2001. From efficiency measurement to efficiency improvement: The choice of a relevant benchmark. Eur. J. Operat. Res., 133: 512-520.
CrossRef - Jahanshahloo, G.R. and M. Afzalinejad, 2006. A ranking method based on a full-inefficient frontier. Applied Math. Modell., 30: 248-260.
CrossRef - Jahanshahloo, G.R., F.H. Lotfi, F.R. Balf and H.Z. Rezai, 2008. Using monte carlo method for ranking interval data. Applied Math. Comput., 201: 613-620.
CrossRef - Li, S., G.R. Jahanshahloo and M. Khodabakhshi, 2007. A super-efficiency model for ranking efficient units in data envelopment analysis. Eur. J. Operat. Res., 184: 638-648.
CrossRef - Liu, F. and H.H. Peng, 2008. Ranking of units on the DEA frontier with common weights. Comput. Operat. Res., 35: 1624-1637.
CrossRef - Lozano, S. and G. Villa, 2005. Determinining a sequence of targets in DEA. J. Operat. Res. Soc., 56: 1439-1447.
Direct Link - Silva Portela, M.C.A., P.C. Borges and E. Thanassoulis, 2003. Finding closest targets in non-oriented DEA models: The case of convex and non-convex technologies. J. Productivity Anal., 19: 251-269.
CrossRef - Torgersen, A.M., F.R. Forsund and S.A.C. Kittelsen, 1996. Slack-adjusted efficiency measures and ranking of efficient units. J. Prod. Anal., 7: 379-398.
CrossRefDirect Link