
R. F. Olanrewaju
International Islamic University Malaysia (IIUM), P.O. Box 10, 50728, Kuala Lumpur, Malaysia
O. O. Khalifa
International Islamic University Malaysia (IIUM), P.O. Box 10, 50728, Kuala Lumpur, Malaysia
Aisha Abdulla
International Islamic University Malaysia (IIUM), P.O. Box 10, 50728, Kuala Lumpur, Malaysia
A. A. Aburas
International Islamic University Malaysia (IIUM), P.O. Box 10, 50728, Kuala Lumpur, Malaysia
A. M. Zeki
International Islamic University Malaysia (IIUM), P.O. Box 10, 50728, Kuala Lumpur, Malaysia
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 16 | Page No.: 2907-2915







ABSTRACT
The requirements needed for an effective and proficient watermarking system is application dependent. However, robustness and image quality (imperceptibility) are fundamental requirements for applications that deal with image watermarking. The major factor that affects the robustness and imperceptibility is the watermark embedding strength. In this study, a CVNN based adaptive technique of estimating watermark embedding strength for a digital image is presented. Experimental results indicated that CVNN based method can estimate the watermarking strength, gives a better correlation and an improved imperceptibility of the watermarked image. It also demonstrates that the detection is enhanced. The use of this new method in watermarking achieved content authentication and helps overcome the problem of visual artifacts and distortions created during watermark embedding.
PDF Abstract XML References Citation
Received: April 26, 2011;
Accepted: June 09, 2011;
Published: July 22, 2011
How to cite this article
R. F. Olanrewaju, O. O. Khalifa, Aisha Abdulla, A. A. Aburas and A. M. Zeki, 2011. Determining Watermark Embedding Strength using Complex Valued Neural Network. Journal of Applied Sciences, 11: 2907-2915.
DOI: 10.3923/jas.2011.2907.2915
URL: https://scialert.net/abstract/?doi=jas.2011.2907.2915
DOI: 10.3923/jas.2011.2907.2915
URL: https://scialert.net/abstract/?doi=jas.2011.2907.2915
INTRODUCTION
The effectiveness of a digital watermarking process is appraised according to the properties of imperceptibility, robustness, computational cost, capacity/strength, false positive rate, recovery of the watermark, the speed of embedding and retrieval process (Cox et al., 1997; Jin and Wang, 2007; Koz and Alatan, 2002; Zeki and Manaf, 2011). These evaluation criteria are application dependent, given that diverse application will have different requirements, therefore there is no unique set of requirements that all watermarking technique must satisfied (Swanson et al., 1998). On the other hand, researchers have highlighted that the principal requirements for an effective watermark are imperceptibility, robustness to attacks and strength/capacity of watermark. Hence, good watermarking algorithm should reach a balance among these requirements (Jin and Wang, 2007).
Visual quality (imperceptibility) of watermarked media is most important requirement in watermarking (Katzenbeisser and Petitcolas, 2000). It refers to the perceptual transparency (also known as fidelity) of the watermark (El-Gayyar and Von Zur Gathen, 2006; Wu et al., 2011), that is, the watermarked media is indistinguishable from the original signal. A watermark embedding procedure is truly imperceptible if Human Visual System (HVS) cannot distinguish the original data from the watermarked counterpart (Yang et al., 2008; Abdulfetah et al., 2009; Phadikar et al., 2007). In this case, a translucent image is overlaid on the primary image which allows the primary image to be viewed, but the watermark is hidden to human eye but can be detected algorithmically.
Robustness of watermark is the ability of the watermark to be resilience to distortion. That is, to detect the watermark, after the watermarked data has passed through some signal manipulations (Olanrewaju et al., 2010). The signal processing operations, for which the watermarking scheme should be robust, varies from application to application as well. The exact level of robustness an algorithm must possess cannot be specified without considering the application situation (Cox, 2008).
Watermarking embedding strength is to analyze the limit of watermark information that a host signal can accommodate while satisfying the imperceptibility and robustness of watermarking (Wong and Au, 2003).
Most of the previous works on watermark embedding capacity/strength (Barni et al., 2002; Moulin and O'sullivan, 2003; Ramkumar and Akansu, 2001; Servetto et al., 1998; Priya and Stuwart, 2010; Abdulfetah et al., 2010) focused on either directly application of Shannon (2001) or Costa (1983) a well-known channel capacity bound.
Recently, the use of Artificial Neural Network (ANN) in estimating the watermark payload has improved the previous studies. Zhang and Zhang (2005) studied the bounds of embedding capacity in a blind watermarking algorithm based on Hopfield neural network.
They found that the basin attractor of neural network attractor and hamming distance can be use to determine the maximum watermark payload. Mei et al. (2002) modelled Human Visual System (HVS) using Feed forward ANN-based image-adaptive method in order to decide the watermark strength of DCT coefficient. Their technique allows selection of the biggest coefficient to determine the watermark strength. Jin and Wang (2007) indicated that in using ANN, different textural features of each DCT block and luminance of an image can be implored to decide adaptively the watermarking embedding strength. Similarly Zhi-Ming et al. (2003) defined a RBF neural networks based algorithm that control and create the maximum image-adaptive strength watermark.
In general, ANN-based capacity/strength estimators are well suited for either phase or magnitude of the image, that is, real-valued neural network RVNN which does not work well with complex values. However, to preserve loss of information during embedding, both phase and magnitude of the image is used and this requires a complex valued neural network. Hence, a new CVNN algorithm that determines the embedding strength in order to improve the watermarked image imperceptibility is developed.
MATERIALS AND METHODS
When a watermark is applied at equal strength throughout an image, it will tend to be more visible in texturally flat regions and less visible in densely textured regions. In order for the embedded watermark to be more robust against different types of attacks as well as avoid visual artifacts created due to uneven embedding, it is essential to embed watermark in a Safe Region (SR) (Olanrewaju et al., 2010). In other words, users would like to insert the watermark with maximum strength to avoid being conspicuous to the Human Visual System (HVS). In this case, local frequency content is use to determine the texture of the image for identification of embedding region while CVNN is used to decide adaptively different watermark embedding strength according to diverse textural features of each block and luminance in the host image. Figure 1 shows the block diagram of the proposed CVNN strength estimate. It consists of a four stage cascade system.
Local frequency content: Spectra analysis is use to express the correlation of the spatial location and the frequency distribution of the image. From it, the local variation of the frequency contents of each block can be known which in turn enables to identify the changes in the frequencies of the image as a whole. Frequency domain, such as Fourier Transform contains information from all parts of the image.
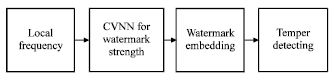 | |
| Fig. 1: | Block diagram of CVNN base strength estimate |
When the image is segmented into non-overlapping blocks, the local frequency content of each block can be defined by computing its Fourier Transform. The general model for obtaining the local frequencies from an image I (x, y) of size M by N for example (8x8) using the fast version of Discrete Fourier Transform (DFT) is represented by F (u, v):
| (1) |
for x = 0, 1…M-1, y = 0, 1…N-1,
Thus given F (u, v), I (x, y) can be obtained back by means of the Inverse 2D DFT (2D IDFT);
| (2) |
where u, v are frequency variables and x, y are spatial variables.
Moving from one textured region to another, the frequency contents of each block changes. The difference in the frequency content of each block is then used as a means of segmentation. Though there is still needs to refine the Fourier descriptors from the frequency content of each block. In this case, the mean of DC component or zero frequency term F (0, 0) is compute using Eq. 3:
| (3) |
where, F (0, 0) is the zero term (DC coefficient) of kth FFT block, N is the number of blocks in the host image.
Complex valued neural network (CVNN): CVNN is use to process Complex Valued Data (CVD). It is made up of Complex-Valued Feed Forward (CVFF) and Complex Back-Propagation (CBP) algorithm. The block diagram of CVFF and CBP is as shown in Fig. 2. CVNN has been studied and developed by authors in solving various problems (Aibinu et al., 2010; Hanna and Mandic, 2003; Hirose, 1992; Kim and Adali, 2001, 2000; Leung and Haykin, 1991; Amin and Murase, 2009).
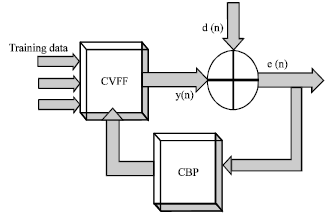 | |
| Fig. 2: | Complex Valued Feed Forward (CVFF) and Complex Back-propagation (CBP) algorithm |
The CVFF begins by summing up the weighted complex-valued inputs in order to obtain the threshold value which will be used to represent the internal state of a given input pattern. All the complex input are computed based on the complex algebra which results into a complex output through complex weights. While the CBP algorithm performs an approximation to the global minimization achieved by the method of steepest descent (Leung and Haykin, 1991). The net input/output relationship is characterized by nonlinear recursive difference equation given by:
| (4) |
where, Wj1 is the complex synaptic weight connecting complex-valued neuron j in input layer to hidden layer, Xj is the complex input signal from input layer, j is the No. of neuron in input layer and bi is a bias value (complex-valued) of neuron i.
It is applied to fully complex multilayer perceptron consisting of many adaptive neurons, that are capable of universally approximating any complex mapping with arbitrary accuracy and they converge almost everywhere in a bounded domain of interest (Kim and Adali, 2003, 2000).
The CVNN error to be propagated backward is defined as the difference between the desired response d (n) and the actual output y (n):
| (5) |
where, [dR (n) + idI (n)] the desired complex is valued data and [yR (n) + iyI (n)] is the output of the CVNN. The CBP algorithm minimises the error function e (n) by recursively adjust the weights and threshold values based on gradient search techniques. Therefore, the global instantaneous squared error is E (n) is given as:
| (6) |
where, e* (n) = eR (n)-ieI (n) is the complex conjugate of the error function. If the error between the probe pattern and the trained pattern is less than the goal (defined by user) or epoch, the CVNN will converse to the trained pattern. Once the pattern is well trained, the CVNN can reconstruct the original pattern from the degraded or incomplete pattern.
Bounds of the watermark: In order to keep the visual distortion to minimum and to optimize the watermarking methods, it is essential to consider the HVS when developing a watermarking system. The HVS can be modelled with three different properties; frequency sensitivity, luminance sensitivity and contrast masking (Mei et al., 2002). The sensitivity of human eye to various spatial frequencies is determined by the frequency sensitivity. These frequencies are modelled by CVNN to determine the maximum strength of the Fast Fourier Transform (FFT) coefficients, that is, the coefficients to embed watermark. The strength estimator is a CVNN block base. Each block has a maximum level to be altered; this is accomplished by choosing appropriate α value during training phase of the CVNN. The α is a multiplicative factor that control imperceptibility and PSNR value of the watermarked image. If altered too much it will affect the imperceptibility of the watermarked image. Figure 3 shows the architecture of the strength estimator depicting the watermark strength while Fig. 4 indicates the steps in the strength estimation.
The above CVNN watermarking strength model shown in Fig. 3 is use during embedding to decide subjectively or objectively the embedding strength of each block. For subjective adaptive strength estimating option, user is allowed to choose the embedding strength for each block. The CVNN strength estimate for each block individually, using features of the block such as the texture, background and each block will have its own strength which indicates how much such block will be altered. This technique enables the establishment of watermarking capacity/strength bound as well as enables the achievement of imperceptibility of watermark without degradation. If no strength is allocated for any block during embedding, the estimator will automatically set such block strength to the default α value. This is due to the pre-defined threshold setting. For any block beyond the threshold, the block will be skipped to the next block. This is an indication that it is not all the block that will be watermarked. If no strength is chosen, the estimator assigns the entire block a default embedding capacity of α.
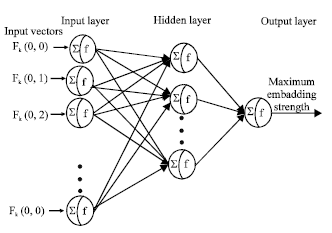 | |
| Fig. 3: | The structure of CVNN based watermarking strength |
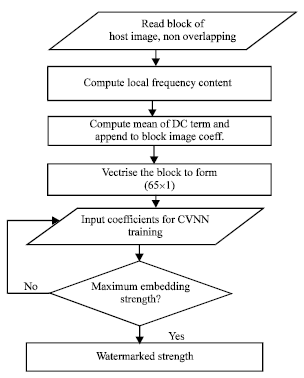 | |
| Fig. 4: | Watermarking strength steps flowchart |
For the objective option, α is a multiplicative factor that control PSNR of the watermarked image just like the subjective estimate. However, the training is model based on Eq. 7 to decide the α values:
| (7) |
Any block which gets CVNN output equal to 0 will be excluded and this way not all blocks are modified which also fulfil the idea of selecting blocks based on model.
The main idea in objective training is that those blocks which have more features data (e.g., eye, nose) should have more α and plain blocks having only background or one colour should have less α value. That is, modifications will be less in image with fewer features. This type of training is basically called the adaptive watermarking strength. Adaptive training is of advantage in detector module. This is because the watermark detector will not be disturbed even if some blocks are with α = 0 since most of the blocks have α>0, therefore the watermark will be detected. In this way one is distributing/spreading the watermark according to CVNN model so that during embedding similar blocks will acquire similar α value for embedding. The α value restricts the number of points that can be modified in an image, therefore, limit the capacity of watermarking and subsequently, decides the watermark embedding strength.
Watermark embedding: This watermark is embedded into the FFT coefficients, an 8x8 blocks of a host image. It is a multiplicative embedding defined as:
| (8) |
where, M (m, n) and P (m, n) are the sequences of data from the transformed magnitude and phase of the original image, W (m, n) is the watermark sequence, α is a the CVNN corresponding CVNN factor controlling the embedding strength and M’ (m, n) is the sequence of watermarked. The watermark is generated a pseudorandom number generator using an integer as a seed. This seed serve as a unique secret key for each watermarked image which can be use as a detection key.
The watermark is embedded in SR by defining the watermark as:
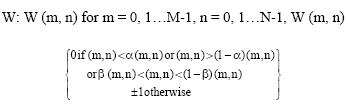 |
where, α and β are the controlling parameters of frequency regions to embed the watermark. After embedding using Eq. 8, the inverse of DFT is applied in order to obtain the watermarked image.
Watermark detection: The detection is a blind detection which does not requires the host image.
The detector model is as shown in Fig. 5. The modified blind optimum decoding and detection as in study of Barni et al. (2002) and Khelifi et al. (2006) where adopted in this study. The detector extracts the hidden information without knowing it in advance.
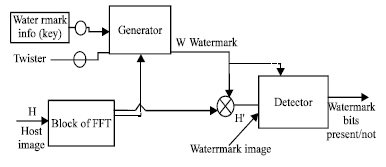 | |
| Fig. 5: | Watermark detector |
The detector hypotheses as follows:
| dt0: | No watermark information is embedded into the received image |
| dt1: | Forged watermark information is embedded into the received image |
| dt2: | Correct watermark information is embedded into the received image |
The above detector analysis may be induced into a binary hypothesis test (Briassouli and Strintzis, 2004) where the two hypotheses concern the existence of a watermark. Given a watermarked image Ik, the detector aims at deciding whether Ik contains a certain watermark wk or not. The watermark detection can be expressed as a hypothesis test where two hypotheses are possible:
| H1: | Signal Ik, host a watermark wk |
| H0: | Signal Ik, does not host a watermark wk |
It should be noted that hypothesis (H0) can take two case; either in the case that the host image Ik is not watermarked (hypothesis (dt0)) or in the case that the signal Ik is watermarked by forged watermark wk where wk = wk (hypothesis (dt1)). Therefore, (dt0) and (dt1) are mutually exclusive and their union produces the hypothesis (H0).
The detector is validated using Eq. 9:
| (9) |
It is important to set the appropriate threshold that minimizes the number of false negative and false positive alarms. In order to set an appropriate threshold, the extracted watermark is correlated with a large number (in this study 1200) random watermarks and the embedded watermark.
RESULTS AND DISCUSSION
Watermark was created by embedding a unique bits string sequence generated from each host image as a message in the host image (image-dependent watermark).
 | |
| Fig. 6(a-b): | Host image Lena (a) and watermarked Lena and (b) using randomly generated seed from the host image |
Each host image has a unique watermark, that is, image features were embedded into itself as an authentication stamp. The colour and chrominance information based features of the image were extracted for the generation of the watermark. The use of image dependent watermark provides better security against fraud especially in tamper detection system as compared to traditional (Fridrich and Goljan, 1999).
In CVNN based embedding, two distinct features are considered; the adaptive strength of the block and the combination of both real and imaginary component for the embedding. These features enable achievement of highly imperceptible and a robust watermarking system especially against conceivable attacks such as Wiener filter, Gaussian noise and JPEG compression. The image of Lena is shown in Fig. 6a and corresponding watermarked Lena in Fig. 6b. The Peak Signal-to-noise ration PSNR is 68.18 dB. It was observed that depending upon the frequency variation of each block, the system provides suitable imperceptible alterations according to the frequency distribution of the block content. This indicates that CVNN based embedding is adaptive in which the embedding strength is based on the frequency component of the block, hence a better imperceptible watermarked image is achieved. Furthermore the retaining of both real and imaginary component information during embedding result in high quality of watermarked image without visual distortion.
| Table 1: | Comparison of watermark imperceptibility measure |
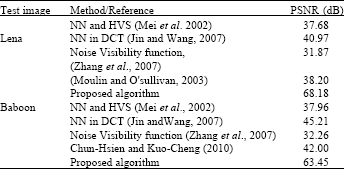 | |
Table 1 shows the comparison results of the proposed CVNN based strength estimate and other algorithms in terms of imperceptibility of the watermarked image. This is accomplished by using PSNR value between the original and the watermarked image expressed in dB indicating the energy of inserted watermark.
| • | PSNR is defined as: |
| (10) |
Higher value of PSNR indicates that the two images are similar.
Table 1 shows comparison results of the proposed CVNN strength estimate and other algorithms for test image Lena and Baboon. It can be seen that for both test images, the proposed CVNN based algorithm outperforms other algorithms with a PSNR value of 68.18 dB for Lena while other algorithms only recorded between 31-40 dB. As for Baboon, CVNN based algorithm scored 63.45 while others scored between 32-42 dB. This performance shows that CVNN based method is about 40% superior to other algorithms. It can therefore be deduce that the newly proposed CVNN algorithm has significant improvement over other algorithms in terms of imperceptibility measure.
Effect of varying watermark strength on imperceptibility: The effect of varying watermark strength on imperceptibility is also considered. Varying the watermark strength, as well as host image used can significantly affect the visual quality of the watermarked image. This is supported by the result obtained in Fig. 7. Imperceptibility decreases as the watermark embedding strength is increased.
For example, when α = 0.1, the PSNR for Lena is observed at 68.18 dB as the increase to 0.5, the PSNR decreased to 54.23 dB and finally reduced to 47.10 dB when the strength soar to 1. Meanwhile, using same embedding condition as the Lena above, however, changing the host image to fruits, it is also observed that as the strength increased, the PSNR valued decreases.
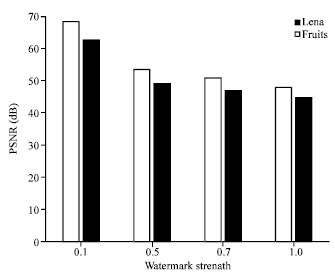 | |
| Fig. 7: | Various watermarking strength showing Watermarked Lena and Fruits using randomly generated noise from host image as watermark |
As shown; when α = 0.1, PSNR is observed at 62.69 dB, as α increased from 0.5 to 1, the PSNR decreased from 49.23 to 44.82 dB. The two comparisons indicated that the PSNR obtained for Lena is higher than that of fruits for different level of watermarking strength however same trend is noticed in the increase of α. The higher PSNR of Lena could be due to the composition and complexity of images at each block which may differ from image to image. In view of this, each block of each image will require different embedding strengths and the embedding time vary as well. For Lena; as shown in Fig. 6, a mixture of characteristics such as smooth background, composition of her eyes while the hat has complex textures and big curves which makes a great difference from ordinary image with all at region. These characteristics concealed the watermark bits better than at flat regions. It was also noticed that for both fruits and Lena, as the watermarking strength increases, there was a decrease in the PSNR value. This is an indication that small watermarking strength such as 0.1 produces best visual quality of watermarked images; 68.18 and 62:69 dB for Lena and Fruits, respectively. Based on the above results, it can be concluded that 0.1 is the best for batch trained strength selection. Furthermore, using host image generated watermark will ensure that each image has a unique watermark for detection.
Effect of watermark strength on various attacks: Figure 8-10 shows the detector response for watermarked pepper after Weiner filter, Gaussian noise and JPEG compression attacks. Figure 8 shows the detector response for 1300 watermark keys where only one seed relates to the correct watermark.
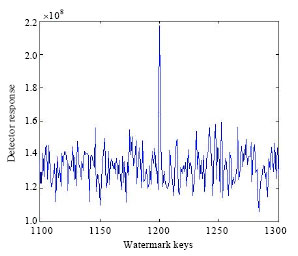 | |
| Fig. 8: | Wiener-Attack resistance detector |
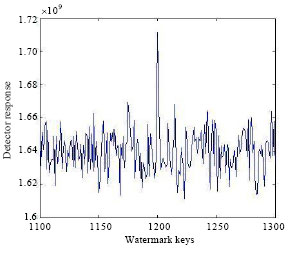 | |
| Fig. 9: | Gaussian noise-attack resistance detector |
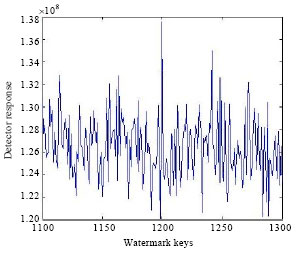 | |
| Fig. 10: | JPEG compression-attack resistance detector |
It is obvious that the response to the true watermark is the largest and highest peak at 1200. As for Gaussian noise attack resistance, shown in Fig. 9, even though the received image may be perceptually corrupted, the decoder was still able to select a key at 1200 as a possible match with the one found and detect it. From Fig. 10, it is observed that despite the compression, the central peak obtained is important enough to conclude that the identified key is the one that is sort for. It means that the decoder is able to detect, upon the reception of the watermarked image. This is an indication that the algorithm is robust to JPEG compression hence the system is JPEG-resistant. Consequently, the robustness requirement is met. It can be concluded that the detector was able to detect the watermark even after the attack; therefore the system is robust against Wiener filter attack, Gaussian noise and JPEG compression. For this reason, the system resistivity against the conceivable attacks can be concluded that the strength used for embedding are adaptive hence imperceptibly and robust system is achieved.
CONCLUSIONS
This study presented a blind watermarking algorithm based on FFT-CVNN and discussed the watermark embedding strength. We argue CVNN is an adaptive watermark strength estimator which enables a decisive amount of watermark to be safely embedded in host image without causing visual distortions, this claim is supported by simulation results. The superiority of the CVNN based strength estimator is verified among other compared algorithms, simulations showed that the newly proposed CVNN based yields superior performance (over other algorithms). It is also pertinent to note that, watermark imperceptibility was highly influenced by the type of image, frequency components, training parameters and strength of the watermark. The smaller the CVNN alpha (α) controlling value the better the watermark imperceptibility. When the alpha value becomes bigger the CVNN watermark strength goes out of bound hence Network cannot retrieve the original image correctly. Therefore, the CVNN alpha value restricts the number of points that can be modified in an image. Furthermore, the performance of the algorithm under various conceivable attacks indicated that the proposed algorithm is robust to conceivable attacks.
REFERENCES
- Abdulfetah, A.A., X. Sun, H. Yang and N. Mohammad, 2010. Robust adaptive image watermarking using visual models in DWT and DCT domain. Inform. Technol. J., 9: 460-466.
CrossRefDirect Link - Abdulfetah, A., X. Sun and H. Yang, 2009. Quantization based robust image watermarking in DCT-SVD domain. Res. J. Inform. Technol., 1: 107-114.
CrossRefDirect Link - Amin, M.F. and K. Murase, 2009. Single-layered complex-valued neural network for real-valued classification problems. Neurocomputing, 72: 945-955.
CrossRef - Barni, M., F. Bartolini, A. De Rosa and A. Piva, 2002. Capacity of full frame DCT image watermarks. IEEE Trans. Image Process., 9: 1450-1455.
CrossRef - Briassouli, A. and M.G. Strintzis, 2004. Locally optimum nonlinearities for DCT watermark detection. IEEE Trans. Image Proces., 13: 1604-1617.
CrossRef - Chun-Hsien, C. and L. Kuo-Cheng, 2010. A perceptually tuned watermarking scheme for color images. IEEE Trans. Image Proces., 19: 2966-2982.
CrossRef - Costa, M.H.M., 1983. Writing on dirty paper (Corresp.). IEEE Trans. Inform. Theory, 29: 439-441.
CrossRef - Cox, I.J., J. Kilian, F.T. Leighton and T. Shamoon, 1997. Secure spread spectrum watermarking for multimedia. IEEE Trans. Image Process., 6: 1673-1687.
CrossRefDirect Link - Hanna, A. and D. Mandic, 2003. A data-reusing nonlinear gradient descent algorithm for a class of complex-valued neural adaptive filters. Neural Process. Lett., 17: 85-91.
CrossRef - Hirose, A., 1992. Dynamics of fully complex-valued neural networks. Electr. Lett., 28: 1492-1494.
CrossRef - Kim, T. and T. Adali, 2001. Complex backpropagation neural network using elementary transcendental activation functions. IEEE Proc. Acoustics Speech Signal Process., 2: 1281-1284.
CrossRef - Kim, T. and T. Adali, 2000. Fully complex backpropagation for constant envelope signal processing. Proc. IEEE Signal Process. Soc. Workshop, Neural Networks Signal Process., 1: 231-240.
CrossRef - Jin, C. and S. Wang, 2007. Applications of a neural network to estimate watermark embedding strength. Proceeding of the 8th International Workshop on Image Analysis for Multimedia Interactive Services, June 6-8, Santorini, pp: 68-68.
CrossRef - Khelifi, F., A. Bouridane and F. Kurugollu, 2006. On the optimum multiplicative watermark detection in the transform domain. Proceedings of the International Conference on Image Processing, Oct. 8-11, Atlanta, GA, pp: 1373-1376.
CrossRef - Kim, T. and T. Adali, 2003. Approximation by fully complex multilayer perceptrons. Neural Comput., 7: 1641-1666.
PubMed - Koz, A. and A. Alatan, 2002. Foveated image watermarking. IEEE Int. Conf. Image Process., 3: 657-660.
CrossRefDirect Link - Leung, H. and S. Haykin, 1991. The complex backpropagation algorithm. Signal Process. IEEE Trans., 39: 2101-2104.
CrossRefDirect Link - Phadikar, A., B. Verma and S. Jain, 2007. Region splitting approach to robust color image watermarking scheme in wavelet domain. Asian J. Inform. Manage., 1: 27-42.
CrossRefDirect Link - Ramkumar, M. and A. Akansu, 2001. Capacity estimates for data hiding in compressed images. IEEE Trans. Image Process., 10: 1252-1263.
PubMed - Servetto, S.D., C.I. Podilchuk and K. Ramchandran, 1998. Capacity issues in digital image watermarking. Proc. Int. Conf. Image Process., 1: 445-449.
CrossRef - Shannon, C.E., 2001. A mathematical theory of communication. ACM SIGMOBILE Mobile Comput. Commun. Rev., 5: 3-55.
CrossRef - Swanson, M.D., M. Kobayashi and A.H. Tewfik, 1998. Multimedia data embedding and watermarking technologies. Proc. IEEE, 86: 1064-1087.
CrossRefDirect Link - Wong, P.H.W. and O.C. Au, 2003. A capacity estimation technique for JPEG-To-JPEG image watermarking. IEEE Trans. Circuits Syst. Video Technol., 13: 746-752.
CrossRef - Wu, C.H., Y. Zheng, W.H. Ip, Z.M. Lu, C.Y. Chan and K.L. Yung, 2011. Effective hill climbing algorithm for optimality of robust watermarking in digital images. Inform. Technol. J., 10: 246-256.
CrossRefDirect Link - Zeki, A.M. and A.A. Manaf, 2011. ISB watermarking embedding: A block based model. Inform. Technol. J., 10: 841-848.
CrossRefDirect Link - Zhang, F. and H. Zhang, 2005. Applications of a neural network to watermarking capacity of digital image. Neurocomputing, 67: 345-349.
CrossRef - Zhang, F., X. Zhang and H. Zhang, 2007. Digital image watermarking capacity and detection error rate. Pattern Recognit. Lett., 28: 1-10.
CrossRef - Zhi-Ming, Z., L. Rong-Yan and W. Lei, 2003. Adaptive watermark scheme with RBF neural networks. Neural Networks Signal Process., 2: 1517-1520.
CrossRef