
Firas B. Ismail Alnaimi
Department of Mechanical Engineering, Universiti Teknologi PETRONAS, 31750 Tronoh, Perak, Malaysia
Hussain H. AL-Kayiem
Department of Mechanical Engineering, Universiti Teknologi PETRONAS, 31750 Tronoh, Perak, Malaysia
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 9 | Page No.: 1566-1572







ABSTRACT
Steam Boilers are important equipment in power plants and the boilers trip may lead to the entire plant shutdown. To maintain performance in normal and safe operation conditions, detecting of the possible boiler trips in critical time is crucial. Artificial Neural network applications for steam boilers trips are developed designed and parameterized. In this present study, the developed systems are a fault detection and diagnosis neural network model. Some priori knowledge of the demands in network topology for specific application cases is required by this approach, so that the infinite search space of the problem is limited to a reasonable degree. Both one-hidden-layer and two-hidden-layers network architectures are explored using neural network with trial and error approach. 32 Boiler parameters are identified for the boiler FDDNN analysis. The power plant experience has been imposed to select the most important parameters related to the superheated monitoring contribution on the boiler trip.
PDF Abstract XML References Citation
Received: October 22, 2010;
Accepted: November 01, 2010;
Published: April 18, 2011
How to cite this article
Firas B. Ismail Alnaimi and Hussain H. AL-Kayiem, 2011. Artificial Intelligent System for Steam Boiler Diagnosis based on Superheater Monitoring. Journal of Applied Sciences, 11: 1566-1572.
DOI: 10.3923/jas.2011.1566.1572
URL: https://scialert.net/abstract/?doi=jas.2011.1566.1572
DOI: 10.3923/jas.2011.1566.1572
URL: https://scialert.net/abstract/?doi=jas.2011.1566.1572
INTRODUCTION
Developing the accuracy for modeling and simulation of components of thermal power plants are very important for training, strategic planning and maintenance, techno-economic decisions as well as continuous monitoring of the operation of the plant. Computational intelligence, mainly in the form of automatic monitoring and control is a major tool of this development. The increasing complexity of thermal power plant boiler operation has led to a transition from supervision by human experts to supervision by computer-based systems and the necessity for increasingly sophisticated management methodologies, particularly for real-time monitoring and supervision.
In existing plants, large number of operational data is captured continuously by the on-line plant’s monitoring system for its proper operation. These are usually stored as database only. Highly developed instrumentation and intelligent control for thermal power plant boiler provides an opportunity to improve the plant performance through the advanced management of all involved processes. An important issue in these highly computerized and automated systems is the quality of information provided by the sensors, as well as the quality of decisions passed to the actuators. Artificial Intelligence (AI) was developed to a degree that it can lead to an intelligent control system capable of self-examination. The combined information of different sensors, through AI methodologies such as: neural networks (NN), genetic algorithms (GA) can lead to quality classification or optimization of isolated derived from specific sensors or actuators. In this way, a fault detection and diagnosis system could eventually be developed, capable of detecting and identifying specific failure in parts (sensors or actuators) of the steam boiler by simply reading the collected measurements of the steam boiler sensors and actuators.
In recent years, many works in science and engineering domains were successfully applied, but still no general method to optimize the neural network inputs. Mellit and Kalogirou (2008) has reported a brief presentation of ANN applications in different energy systems. Romeo and Gareta (2006) designed a NN and applicable for a biomass boiler monitoring and point out the advantages of NN in these situations. A combination of traditional methods aided with a NN structure to monitorize the boiler could completely solve fouling and slagging problems. Rusinowski and Stanek (2007) presented the modeling of neural network for steam boiler using operational measurement data for material and energy balances. Fast and Palme (2010) created an on-line system for condition monitoring and diagnosis using artificial neural networks for each main component of the combined heat and power plant. It is integrated on a power generation information manager server in the computer system of the combined heat and power plant, and the graphical user interface was made available on workstations connected to this server. Sun et al. (2005) have developed a new data preprocessing scheme and a new fault detection scheme designed for Hotelling’s T2 as well as the squared prediction error to boiler water/steam leak detection with real data. Smrekar et al. (2009) have developed an artificial neural network (ANN) models using real plant data for the prediction of fresh steam properties. Initial parameters selection was made on a basis of expert knowledge and previous experience, the final set of input parameters was optimized with a compromise between smaller number of parameters and higher level of accuracy through sensitivity analysis. De et al. (2007) reported a feed forward with back propagation ANN model for the biomass and coal fired CHP plant by training the network with data from this plant to predicate the performance of the plant.
In this study, a neural network fault detection system is developed and trained using real plant data. The main area of concentration is steam boiler trip leading to plant shut down. The motivation was the fact that detection of stressed unit faults is very important for the plant performance. Real data is acquired during boiler trip caused by superheater trip in a coal fired power plant. This data used as material for training and validation of the developed ANN.
This study highlights the procedure of steam boiler trip diagnosis based on superheater parameters observation. This study also presents the sequence of the data preparation to suit the NN code training and validation test.
MATERIALS AND METHODS
Brief description of the steam boiler system: The selected thermal power plant is (3*700 Mwatt/unit). The boilers are sub-critical pressure, single reheat and controlled circulation type. Each boiler is fired with pulverized coal to produce steam for the continuous generation of 700 MW. The boilers are designed to fire coals within the bituminous rank. The combustion circuit consists of single furnace, with direct tangential firing and balanced draught. The coal milling plant consists of 7 vertical bowl mills. Light fuel oil burners are available for boiler start-up and for coal ignition or combustion stabilization. The maximum heat input that can be achieved when firing fuel oil is 40% of the Boiler Maximum Continuous Rate (BMCR).
Consideration for protection of the superheater elements is the predominant factor when determining how rapidly controlled circulation boilers can be brought up to pressure. The superheater and reheater elements should be heated uniformly and the maximum temperature of the flue gases entering the first elements should be carefully monitored and controlled during cold start-up. To ensure that the superheater and the reheater element loops are clear of condensate, provisions must be made to increase progressively the steam flow during the first sets of start-up, particularly when the boiler is depressurized. It is recommended to obtain an adequate flow of steam through the superheater before closing the superheater start-up drains.
The boiler has been designed to comply with the Malaysian environmental requirements. NOx control is achieved with a low NOx combustion burner system including over fire air (OFA) ports. An Electro-Static Precipitator (ESP) removes dust in the flue gas at the boiler outlet and a Flue Gas Desulphurization (FGD) plant, scrubs the flue gas controls the SO2 emission level at the stack. The major auxiliary equipment consists of three boiler circulating pumps, two forced draft fans, two steam air preheaters, one soot blowing equipment, two electrostatic precipitators, one coal milling plant consisting of 7 vertical bowl mills and one wet Flue Gas Desulphurisation plant.
INTELLIGENT FAULT DETECTION METHODOLOGY PHASES
The integrated methodology consists of three execution phases: Plant data acquisition phase, in which real data of steam boiler are captured, identified, clustered and sampled, plant data preparation and parameters selection phase, in which data are tested, checked, normalized. Also, the boiler behavior was studied and the most influencing parameters were decided, accordingly and fault detection and diagnosis neural network model training-validation phase, in which the feed-forward methodology of NNs was used. In the following is a dissection of each phase of the procedure.
Plant data acquisition phase: Large amount of steam boiler data was captured continuously by the on-line plant monitoring and control panel. Extensive data for 32 parameters of the steam boiler for 30 days at interval of 1 min were obtained from the plant. However, for ANN modeling only some of them are sufficient to develop the equivalent model as the rest are interrelated and thus redundant. Before using real data from the plant for FDDNN modeling, integrated preparations are required. This is necessary as there will always be some Faulty and missing data in large real data set. This may either be due to faulty sensors or actuators, human errors, error in data capturing system, etc. As the accuracy of FDDNN model can never be better than that of training data, a critical scrutiny of obtained real data is required to identify and remove these faulty data, called “outliers” and replacing the missing data using the most commonly methods for missed data. Moreover, any data for the off-nominal operation of the plant must be removed from the training data set as it may confuse the FDDNN model. Thus any captured data during the sudden changes, say, rapid increase in unit stress or unit shutdown, should also be removed from the training data set as the conditions during these periods are completely different from the normal operation.
Plant data preparation and parameters selection: All outliers’ removal is very crucial and complex stage in a large real data set. A lot of errors maybe combined in a single captured data and thus, the identification stage becomes difficult at the early of the training. Thus outliers are usually identified and reduced at different stages of the (FDDNN) model development. However, at the beginning, the outliers are usually identified by plotting measured data (each variable behavior) and observing the data points which are quite different from the neighboring data points following a reasonably regular tend. Obviously, experience of the model developer helps to identify possible outliers at this stage. Sampling frequency of measured parameters was 1 min. There were 35,900 rows of data corresponding to approximately 30 days. Identification process of outliers and faulty parameters for steam boiler parameters were carried out accurately with several plots and zooming them in order to study the behavior for each selected parameters as in Fig. 1-4.
Training the NN model by real data set which includes all possible deviations in the operation range is very critical. In this process it learns the relations for all such variations and the trained ANN will be able to classify output according to the NN target as 1 for fault exists and 0 for fault not exist for any real data with acceptable accuracy.
In fact, the successful NN training can be achieved by small number plant parameters which have been selected properly even for complex system leading to computation time saving as a whole. Thus, careful selection of real plant data is more important than the amount of plant real data for NN training. Real steam boiler data were pre-randomized before subdivided into three different groups for NN training; the first 60% of real acquired data were used for training. The following 15% was used for cross-validation and the rest for were used for testing. The randomization process of the real data was applied on each of the three sets.
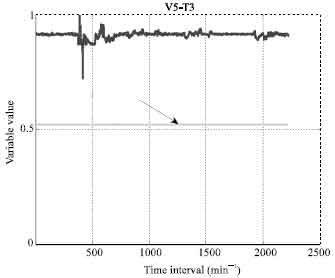 | |
| Fig. 1: | Superheater steam temperature behavior |
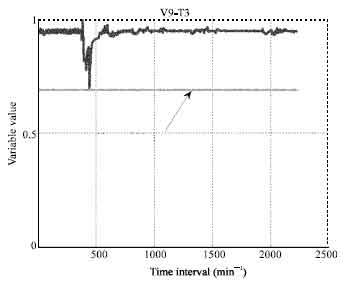 | |
| Fig. 2: | High temperature super heater inlet header metal temperature |
The data for steam boiler superheater trip contains 32 sampled at intervals of 1 min. Within each data set the trip condition is preceded by a period of normal full power operation and the total sampling time for the superheater low temperature. Each one of the raw data files has 5500 data points for each of 93 variables the training patterns are formed by the values of selected variables at each time step. Therefore, there will be about 1200 patterns for superheater low temperature trip. The patterns averaged over several times intervals to reduce the total number of training patterns to 1100 and the variables to 32 without substantial loss of information as in Table 1.
FDDNN model training and validation: The basic methodology used for NN training here was the feed-forward Back-propagation Training Algorithm.
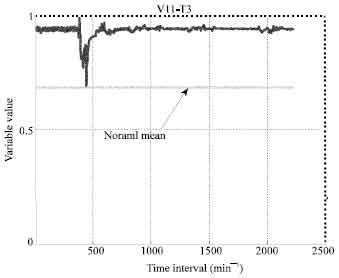 | |
| Fig. 3: | Superheater steam pressure transmitter (control) |
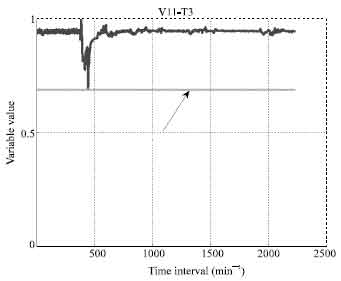 | |
| Fig. 4: | Feed water valve station |
This algorithm has several modifications according to the multidimensional minimization algorithm that it uses to minimize the error estimator. Four different types of minimization algorithms were considered: Rprop, BFGS quasi-Newton, Scaled Conj. Grad. and Levenberg-Marquardt algorithm.
Thirty two NN Inputs (steam boiler variables) were defined in the previous phase. Two NN outputs (one corresponded to a specific trip and the other one corresponded to normal operation) were expected. The values of the outputs used for training the neural network were binary strings
| • | 0 fault not exists-normal operation, or |
| • | 1 fault exists-faulty operation |
| Table 1: | Selected thermal power plant boiler parameters |
 | |
The training outputs from the FDDNN model as Root Mean Square Error (RMSE) were values between 0 and 1. In this way, a decision process was formed to determine the existence of a fault.
The developed (FDDNN) model consist of the type of activation functions (AF), types of training algorithms (Trainbfg, Trainlm, Trainscg and Trainrp), number of hidden layers(1HL, 2HL,….), number of neurons at each hidden Layer (NON), normalization range (0/1), etc. The accuracy of the trained FDDNN model for real plant data application had to be checked by observing the FDDNN model RMSE outputs for a data set which were never “seen” by the NN model before. This procedure is called validation of the developed (FDDNN) model.
The training of FDDNN Model was carried out with commercially available software for this purpose, called MATLAB2009A.
As mentioned before, data were pre-randomized before divided into three different groups for superheater low temperature trip. Randomization of all available real plant data was done in each of these three groups so that probability of representation of plant data for the entire range of operation was increased.
The FDDNN model was thus accepted with input and output parameters as in Fig. 5.
RESULTS AND DISCUSSION
Once the code structure has been decided, the training was commenced using the prepared data. The selected 32 plant variables have been used to train the (FDDNN) model. Many options subjected to trial and error analysis to decide the NN topologies and then the code has been tested using the trip data based on superhear observed parameters
(FDDNN) model training results: The (FDDNN) model was trained with real plant data captured from the thermal power plant boilers, for both normal and faulty situations. The time span of the training and validation data was considered one day before and one after thesuperheater low temperature trip formed. The sampling time of each data point was 1 min. Thus, the training set was based on 1200 entries for each input of the NN, which 70% of the data set.
The NN training process included two major parts: The NN training process included two major parts. The first part was the initial NN training process, which determined the most suitable combination of network structure and training algorithm. This was achieved by training several candidate network topologies (both 1-HL and 2-HL networks) using trial and error approach with all four training algorithms and comparing the training results.
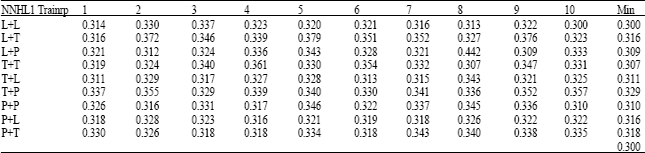
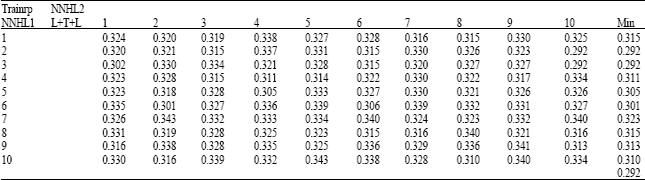
The second part of the training process, which was the basic training process, focused on training the best combination of NN structure and algorithm. Based on the initial training results, the network structure/algorithm combination that gave the best results for Low superheater temperature trip for 1HL and 2HL is shown in Table 2 and 3. The basic training process had a goal to further train the selected NN with the best possible algorithm for this system and structure.
Figure 6 shows the performance of 1HL architecture using four candidate-training algorithms for superheater low temperature trip. Many different random initial network parameters were tested in that training. Also, several values of the coefficient of the penalty term for the regularization, λ, varying by the order of 5, were tested. Logistic, hyperbolic tangent and linear summation activation functions (functions of hidden nodes) were tested. The results of these tests showed that leads to the minimum RMSE was obtained at λ= 0.03 and that the network with logistic and liner summation activation functions performed better than the one with hyperbolic tangent activation functions.
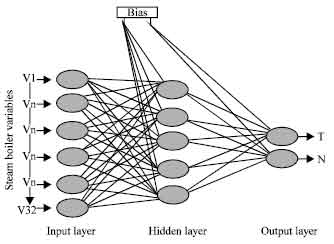 | |
| Fig. 5: | Inputs and outputs of (FDDNN) Model |
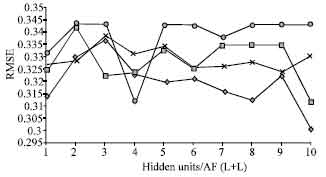 | |
| Fig. 6: | Performance of (1HL) structure of the four candidate training algorithms for super heater low temperature trip |
FDDNN model testing results: Testing consisted of presenting new real plant data to the trained FDDNN model in order to explore its generalization capabilities. The main objective in FDDNN Model is not only detection of the existence of a fault, but also its rapid detection. Especially, when we deal with slowly developing faults, the time steps (time interval) factor becomes more important because these faults are more difficult to detect as they begin. Testing data set were presented to the FDDNN model. Set starts with data of normal operation and specific trip at known time.
The output of the FDDNN model was considered to represent a faulty operation if it had a value close to 1, while for values smaller than 0.55 a normal operation was assumed. For “super heater low temperature” trip, the output of FDDNN model on the data set was introduced at the 69 time steps (min).
| Table 2: | The Most suitable structure using 1HL, for super heater low temperature trip |
 | |
| Table 3: | The Most suitable structure using 2HL, for super heater low temperature trip |
 | |
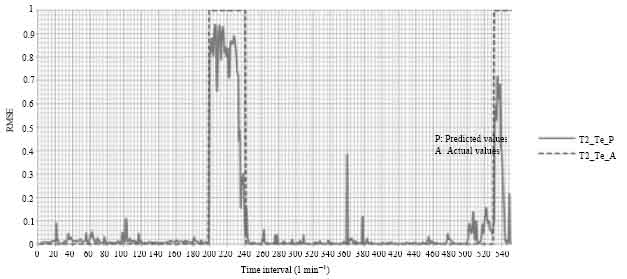 | |
| Fig. 7: | Output of the FDDNN for testing and training data sets (Superheater low temperature trip), fault introduced at time step No. 59 |
The fault was detected by the network at only 59 time steps, meaning that the model predicted the fault 10 min before the plant monitoring system as in Fig. 7.
CONCLUSION
In this study, data preparation, FDDNN model for fault detection and diagnosis design and training plant parameters are presented. The target is to make process of designing ANN is less human depended and more sophisticated. Different plant datasets have been collected, treated, analyzed and scaled. Neural Network MATLAB codes used to obtain the results which proof that the new model can detect and diagnosis the super heater low temperature precisely in time and quickly, subsequently, satisfactory performance.
ACKNOWLEDGMENT
The authors acknowledge Universiti Teknologi PETRONAS for the sponsoring of the project. The facilitating of the selected power station management in the data collection is highly appreciated.
REFERENCES
- De, S., M. Kaiadi, M. Fast and M. Assadi, 2007. Development of an artificial neural network model for the steam process of a coal biomass cofired Combined Heat and Power (CHP) plant in Sweden. Energy, 32: 2099-2109.
CrossRef - Rusinowski, H. and W. Stanek, 2007. Neural modelling of steam boilers. Energy Conversion Manage., 48: 2802-2809.
CrossRef - Mellit, A. and S.A. Kalogirou, 2008. Artificial intelligence techniques for photovoltaic applications: A review. Prog. Energy Combust Sci., 34: 574-632.
CrossRef - Romeo, L.M. and R. Gareta, 2006. Neural network for evaluating boiler behaviour. Applied Thermal Eng., 26: 1530-1536.
CrossRef - Smrekar, J., M. Assadi, M. Fast, I. Kustrin and S. De, 2009. Development of artificial neural network model for a coal-fired boiler using real plant data. Energy, 34: 144-152.
CrossRef - Sun, X., H.J. Marquez and T. Chen and M. Riaz, 2005. An improved PCA method with application to boiler leak detection. ISA Trans., 44: 379-397.
CrossRef