
Z.M. Nopiah
Faculty of Engineering and Built Environment, Universiti Kebangsaan Malaysia, 43600 UKM Bangi, Selangor, Malaysia
M.N. Baharin
Faculty of Engineering and Built Environment, Universiti Kebangsaan Malaysia, 43600 UKM Bangi, Selangor, Malaysia
S. Abdullah
Faculty of Engineering and Built Environment, Universiti Kebangsaan Malaysia, 43600 UKM Bangi, Selangor, Malaysia
M.I. Khairir
Faculty of Engineering and Built Environment, Universiti Kebangsaan Malaysia, 43600 UKM Bangi, Selangor, Malaysia
Journal of Applied Sciences
Year: 2010 | Volume: 10 | Issue: 7 | Page No.: 544-550







ABSTRACT
Abrupt changes are changes that occur at a time instant at which properties suddenly change, but before and after which properties are constant in some sense. The detection of abrupt changes refers to the determination whether, such a change occurred in the characteristics of the considered subject. Running Damage Extraction (RDE) method is a new technique that was developed based on the fatigue damage calculation in detecting the abrupt changes. The objective of this study was to observe the capability of RDE method in analyzing fatigue data for detection of abrupt changes. For the purpose of this study, a collection of nonstationary data that exhibits a random behavior was used. This random data was measured in the unit of microstrain on the lower suspension arm of a car. Experimentally, the data was collected for 60 sec at a sampling rate of 500 Hz, which gave 30,000 discrete data points. By using RDE algorithm, a running damage plot was constructed in monitoring the damage changes for fatigue data. Global signal statistical value indicated that the data were non Gaussian distribution in nature. The result of the study indicates that RDE technique is applicable in detecting the abrupt changes that exist in fatigue time series data by isolating the high and low amplitude event into different segmentation.
PDF Abstract XML References Citation
How to cite this article
Z.M. Nopiah, M.N. Baharin, S. Abdullah and M.I. Khairir, 2010. The Detection of Abrupt Changes for Variable Amplitude Fatigue Loading by using Running Damage Extraction Method. Journal of Applied Sciences, 10: 544-550.
DOI: 10.3923/jas.2010.544.550
URL: https://scialert.net/abstract/?doi=jas.2010.544.550
DOI: 10.3923/jas.2010.544.550
URL: https://scialert.net/abstract/?doi=jas.2010.544.550
INTRODUCTION
Abrupt changes refers to the mean changes in term of nature behavior that occur very fast with respect to the sampling period of the measurements, if not instantaneously. The detection of abrupt changes on the other hand, refers to tools that help in decide whether such a change occurred in the characteristics of the considered subject. The change detection tools were used in problems that exist in signal processing, time series analysis, automatic control and industrial control (Basseville and Nikirov, 1993). The generic problem of detecting abrupt changes in process parameters has been widely studied. These changes may be due to shifts that exist in the mean value (i.e., edge detection) or a variation in signal dynamics (Nopiah et al., 2008b).
This study is on the development of abrupt changes detection technique that exists in mechanical fatigue signal data. Since, there a large part of the information contained in the measurement lies in their nonstationarities and because of most adaptive estimation algorithms basically can follow only slow changes, a new method are needed to be developed in detecting the abrupt changes that exist in the fatigue data (Basseville and Nikirov, 1993).
In solving this problem, a new technique called Running Damage Extraction (RDE) method was proposed. This method was developed by combining the overlapping window concept and fatigue damage calculation. The objective of this study was to investigate whether, this method can be used accurately to segment the typical fatigue histories by isolating the low and high amplitude event into different segmentation.
A signal is a series of number that come from a measurement, typically obtained using some recording method as a function of time (Nopiah et al., 2008a). In real applications, signals can be classified into two types which are stationary and non-stationary behavior. A signal representing a random phenomenon can be characterised as either stationary or nonstationary behavior. The stationary signals exhibit the statistical properties remain unchanged with the changes in time. On the other hand, statistics of non-stationary signal is dependent on the time of measurement. In the case of fatigue research, the signal consists of a measurement of cyclic loads, i.e. force, strain and stress against time. The observations of a variable were taken at equally spaced intervals of time (Abdullah et al., 2008).
All the data measured from this experiment are recorded as strain time histories. Thus, it is also important to have a better understanding about the behavior of this data before applying the detection of abrupt changes algorithm. The identification of fatigue data behavior is based on the existence of time series component which involves with the identification of trend, cyclical, seasonal and irregular component in time period t.
The method used in the identification of this component is called classical decomposition of time series. This process is used to segregate and to analyse the existence components in a systematic manner. The trend component represents the long-run growth or decline over time. On the other hand, the cyclical component refers to the rises and falls of the series over unspecified period of time. The seasonal component also known as seasonal variation, refers to the characterization of regular fluctuations occurring within a specific period of time. Although, this component is individually identified, they are related to each other in a certain mathematical functional form. The type of relationship that these components have is divided into two; which are multiplicative effect and additive effect. Multiplicative effect refers to the components interaction such, the increase in sizes of the seasonal variation within the level of data. On the other part, additive effect assumed the components of the series are interacted in additive manner (Lazim, 2007).
In normal practice, the global signal statistical values are frequently used to classify random signals. In this study, mean, root mean square (r.m.s.) and kurtosis were used (Nopiah et al., 2008a). For a signal with n data points, the mean value of ![]() is given by:
is given by:
| (1) |
On the other hand, root mean square (rms) value, which is the 2nd statistical moment, is used to quantify the overall energy content of the signal and is defined by the following equation:
| (2) |
where, xj is the jth data and n is the number of data in the signal.
The kurtosis, which is the signal 4th statistical moment, is a global signal statistic which is highly sensitive to the spikeness of the data. It is defined by the following equation:
| (3) |
where, rms is the root mean square as calculated in Eq. 4 and ![]() is the mean value of the signal data. Kurtosis is used in engineering for detection of fault symptoms because of its sensitivity to high amplitude events (Qu and He, 1986).
is the mean value of the signal data. Kurtosis is used in engineering for detection of fault symptoms because of its sensitivity to high amplitude events (Qu and He, 1986).
It is common that the service loadings caused by machines and vehicles is evaluated using a strain-life fatigue damage approach (Abdullah et al., 2005). The strain-life approach considers the plastic deformation that occurs in the localised region where fatigue cracks begin under the influence of a mean stress.
The total strain amplitude, εa is produced by the combination of elastic and plastic amplitudes:
| (4) |
where, εea is the elastic strain amplitude and εpa is the plastic strain amplitude. The elastic strain amplitude is defined by:
| (5) |
while the plastic strain amplitude is given as:
| (6) |
where, σa is the stress amplitude, Nf is the number of cycles to failure, b is the fatigue strength coefficient, b is the fatigue strength exponent, ε'f is the fatigue ductility coefficient, c is the fatigue ductility component and E is the modulus of elasticity.
Combining Eq. 8 and 9 gives the Coffin-Manson relationship, which is mathematically defined as:
| (7) |
which is essentially Eq. 7 above and is the foundation of the strain-life approach. Some realistic service loads involve nonzero mean stresses.
Fatigue damage is derived from the number of cycles to failure where the relationship is:
| (8) |
and therefore fatigue damage values have the range [0, 1] where, zero denotes no damage (extremely high or infinite number of cycles to failure) and 1 means total failure (one cycle to failure).
The RDE plot in this study has many non-parallel lines that contain a significant number of local optima, which can be classified as either peaks or valleys. A peak is defined to be associated with change in the slope from positive to negative, while a valley is associated with a change in the slope from negative to positive (Xiong and Shenoi, 2008). Peaks in a RDE are essentially the local maxima and valleys are the local minima. Depending on the resulting RDE, some points can be classified as neither peaks nor valleys.
Peak-Valley (PV) identification can be used to segment signals so that each segment may contain certain numbers of peaks and/or valleys, according to the needs of the study. This is particularly useful for fatigue time series data, since peaks and valleys feature predominantly in rainflow counting algorithms for fatigue damage calculations (Bigerelle et al., 2008). PV-based techniques are also used in mechanical modeling (Kuroda and Marrow, 2008), quantifying roughness of materials (Kuroda and Marrow, 2008; Hiziroglu et al., 2008; Anderberg et al., 2008) and image segmentation (Zhang et al., 2007).
In signal processing, a segmentation algorithm were used to splits the signal into homogenous segments, the lengths of which are adapted to the local characteristics of the analyzed signal. The homogeneity of a segment can be in terms of the mean level or in terms of the spectral characteristics (Basseville and Nikirov, 1993). This type of application is applied in fatigue life assessment study in which the fatigue signal extraction is described as a method to summarise a fatigue signal.
The first step of summarizing the fatigue signal is to isolate the low and high amplitude events in different segmentation. All the extracted segments (the complete section between the start and the end of the segments) are selected based on peak and valley time location of the running damage values.
MATERIALS AND METHODS
The data that was used in this study is variable fatigue strain loading data. It was collected from an automobile component during vehicle road testing. It was obtained from a fatigue data acquisition experiment using strain gauges and data logging instrumentation. The experiment was conducted in the year 2008 by covering certain road areas in Malaysia.
The collected fatigue data were measured on the car’s front lower arm suspension as, it was subjected to the road load service.
 | |
| Fig. 1: | Main factor for fatigue data road condition |
All the data that were measured from this experiment are recorded as strain time histories.
The strain value from this test was measured using a strain gauge that was connected to a device, a data logger for data acquisition. Experimental parameters that need to be controlled in this test such as sampling frequency and type of output data being measured were specified in data acquisition software.
In order to collect a variety of data, the car was driven on three different road surfaces which are explained in Fig. 1. All data were taken from different road conditions: pave route, highway and campus.
Experimentally, the data was collected for 60 sec at a sampling rate of 500 Hz, which gave 30,000 discrete data points. This frequency was selected for the road test because this value does not cause the essential components of the signal to be lost during measurement. The road load conditions were from a stretch of highway road to represent mostly consistent load features, a stretch of brick-paved road to represent noisy but mostly consistent load features and an in-campus road to represent load features that might include turning and braking, rough road surfaces and speed bumps.
As to fulfill the main purpose of this study, the RDE algorithm is used to identify and extract the abrupt changes for fatigue damaging events. This technique is based on the running concept which the original data are separated by using overlapping window. For a signal with n data points, the numbers of overlapping window is given by xiεX where, X is the signal data, h is the size of overlap and m is the size of the window:
| (9) |
Where:
| i | = | 1, 2, 3, ..... |
| J | = | 1,1+h,1+2h, .... |
| K | = | m,m+h,m+2h, ..... |
A flowchart describing the RDE algorithm is presented in Fig. 2 and it involves with several stages: the input signal and global statistics parameter; classical decomposition analysis for fatigue time series data; calculation of running damage based on the overlapping window; identification of optimized running damage; the identification and extraction of abrupt changes for fatigue damaging events; and decision making process.
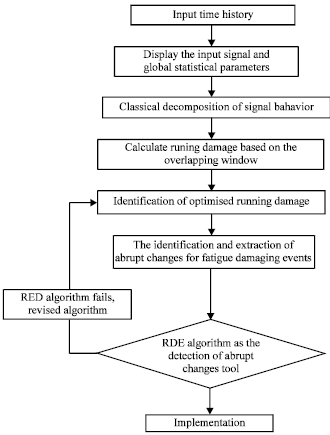 | |
| Fig. 2: | Simplified flowchart of the RDE algorithm technique |
The first stage of RDE algorithm is to display the three different types of fatigue data in times series plot and global statistic parameter. In normal practice, the global signal statistical values are frequently used to classify random signals. In this study, mean, root mean square (rms) and kurtosis were used (Nopiah et al., 2008a).
In the stage of classical decomposition for time series, a few methods has been selected in identify for the whole time series component. The method in detecting the existence of trend, cyclical, seasonal and irregular are by using linear trend line, the residual method, method of seasonal differencing and then also by using linear trend line, respectively. Purpose of using classical decomposition method as a tool in analyzing the fatigue time series data are to identify the variation and to have a better understanding in about the behavior of the data.
The next stage is the most crucial part in the development of RDE algorithm. At first, the data was divided in different window by using the overlapping algorithm. In each window, there are 500 data points. The data points in each window that consist of original data were then overlapped between each other from 10 to 90%. Then, the data that was produced in each window was transferred into Glyphwork software for calculating the value of fatigue damage. The purposed of overlapping in this study was based on the assumption to reduce the possibility of damaged calculation for each window that crosses over the peak values in the original signal and to mitigate the loss at the edges of the window.
The next stage in RDE algorithm is to identify the optimised running damage. Each overlapping window for running damage was plot over time. Then, a trend analysis is used to analyse the variation component in the running damage data. The trend values for the running damage were then compared to the trend values of original signal. In this study, it is proposed that the optimum value for overlapping running damage be based on the minimum values of trend analysis as it represents the removal of the trend component from the actual data.
In the third stages of RDE, abrupt changes which represent the fatigue damaging events or bumps are identified based on wave bump extraction method. In this stage, the RDE was combined with peak and valley calculation so that the decision function for the time series segmentation can be performed.
After the RDE data points were simplified by using peak and valley algorithm, the decision function for the extraction is based on energy enveloping in the original signal, the time points that correspond to valley data points are then identified. Reference about this method of searching can be referred from this article (Abdullah et al., 2005).
The last stage involve with the identification on whether, the RDE algorithm can detect transient events in fatigue data. It is assumed that the RDE algorithm can be used in predicting the abrupt changes that exist in fatigue data.
RESULTS AND DISCUSSION
Referring to Table 1, the pave gives the highest value of mean which are 68.08. On the other hand, campus route shows the highest value of RMS which is 88.22. Kurtosis results showed that all of the data are non-Gaussian distribution since all the kurtosis value exceeds 3. From the findings, the higher kurtosis values also indicate the presence of more extreme values than should be found in a Gaussian distribution (Qu and He, 1986).
Table 2 shows all behavior of the components that exist in the fatigue data except for seasonal component. In this analysis, seasonality component was not considered as important such as the event that occurs in the fatigue data is not the regular fluctuations occurring within a specific period of time. The existence of regular fluctuations which involve with high amplitude events in fatigue data are independent each other. These high amplitude events are recognized as the fatigue damaging events. From the analysis of classical decomposition method, it was found that all the data have positive trend, cyclical and random effect.
| Table 1: | The global statistic |
 | |
| Table 2: | Fatigue time series component table |
 | |
From this study, 80% overlapping window for original data has been chosen as the optimal condition for RDE method. This is because the decision function for data segmentation in change detection produced better results for the whole case study data rather than using different value of overlapping. It also was found that different value of overlapping will produce a different numbers of segmentation.
Using overlapping algorithm and running damage calculation, it was found that the RDE plot shows significant findings in detecting the high amplitude event that exist in the all selected data. Figure 3-5 show the comparison between original RDE plot, RDE plot with peak and valley and time series plot.
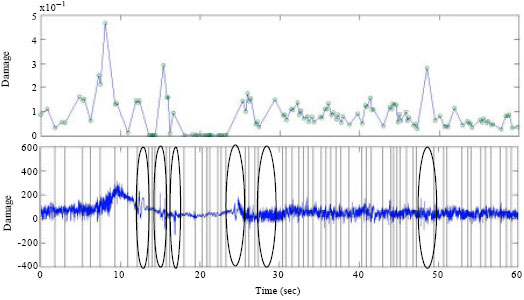 | |
| Fig. 3: | Comparison between RDE and time series plot for pavé route data |
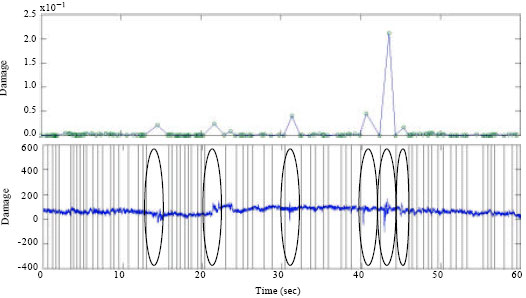 | |
| Fig. 4: | Comparison between RDE and time series plot for highway data |
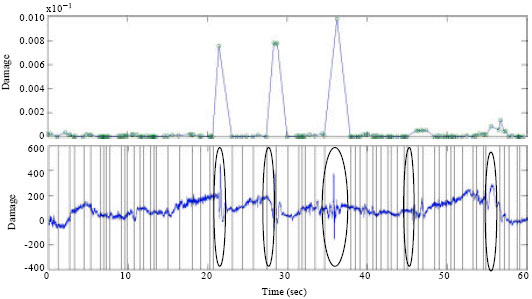 | |
| Fig. 5: | Comparison between RDE and time series plot for UKM Data |
The RDE plot in Fig. 3 shows that each jump, which was related to fatigue damage event was successfully detected. The line in time series plot are drawn as to separate the high amplitude and low amplitude events that exist in the strain data.
In the highway data (Fig. 4), the RDE algorithm shows significant result in detecting the abrupt changes that exist in the data. Each high amplitude event that exists in the highway data was also detected by using the RDE algorithm (by referring to the circled areas). Each existence of abrupt changes in the data was segmented based on the valley value of damage.
Finally, Fig. 5 shows the detection of abrupt changes by using RDE method plot also tends to be very high. Referring Fig. 5, it shows that all the high amplitude data which is related to fatigue damaging events are segmented (by referring to the circled area).
CONCLUSION
The study has demonstrated the use of Running Damage Extraction (RDE) method in the segmentation of time series data for fatigue analysis and classical decomposition method as a tool in analyzing the time series variation for fatigue data. The study showed that the proposed method can solve the problem very well in detecting and isolating the abrupt changes that exist in the fatigue time series.
ACKNOWLEDGMENT
The authors would like to express their gratitude to Universiti Kebangsaan Malaysia through the fund of UKM-GUP-BTT-07-25-152, for supporting these research activities.
REFERENCES
- Basseville, M. and I.V. Nikiforov, 1993. Detection of Abrupt Changes: Theory and Application. 3rd Edn., Prentice-Hall, Englewood Cliffs.
Direct Link - Nopiah, Z.M., M.N. Baharin, S. Abdullah, M.I. Khairir and C.K.E. Nizwan, 2008. Abrupt changes detection in fatigue data using the cum ulative sum method. WSEAS Trans. Math., 7: 708-717.
Direct Link - Abdullah, S., M.D. Ibrahim, Z. Mohd Nopiah and A. Zaharim, 2008. Analysis of a variable amplitude fatigue loading based on the quality statistical approach. J. Applied Sci., 8: 1590-1593.
CrossRefDirect Link - Nopiah, Z.M., M.I. Khairir and S. Abdullah, 2008. Segmentation and scattering of fatigue time series data by kurtosis and root mean square. Proceedings of the 7th WSEAS International Conference on Signal Processing, May 27-30, World Scientific and Engineering Academy and Society (WSEAS) Stevens Point, Wisconsin, USA., pp: 64-68.
Direct Link - Abdullah, S., J.C. Choi, J.A. Giacomin and J.R. Yates, 2006. Bump extraction algorithm for variable amplitude fatigue loading. Int. J. Fatigue, 28: 675-691.
CrossRefDirect Link - Anderberg, C., P. Pawlus, B.G. Rosen and T.R. Thomas, 2008. Alternative descriptions of roughness for cylinder liner production. J. Mater. Proces. Technol., 209: 1936-1942.
CrossRef - Zhang, C.J., C.J. Duanmu and H.Y. Chen, 2007. Typhoon image segmentation by combining curvelet transform with continuous wavelet transform. Proceedings of the International Conference on Wavelet Analysis and Pattern Recognition, Nov. 2-4, Beijing, China, pp: 1512-1517.
CrossRef