
M.R. Mustapha
School of Physics, Universiti Sains Malaysia, 11800 Penang, Malaysia
H.S. Lim
School of Physics, Universiti Sains Malaysia, 11800 Penang, Malaysia
M.Z. Mat Jafri
School of Physics, Universiti Sains Malaysia, 11800 Penang, Malaysia
Journal of Applied Sciences
Year: 2010 | Volume: 10 | Issue: 22 | Page No.: 2847-2854







ABSTRACT
Classification of satellite images with the intent of land cover mapping is one of the remote sensing applications. The objective of this study is to compare the Neural Network and Maximum Likelihood approaches in land cover mapping by using high spatial resolution satellite images in Makkah city which is located in the semi-arid conditions in western of Saudi Arabia. Many algorithms are available for classification of satellite images. Maximum Likelihood classification method is widely used in many remote sensing applications and can be regard as one of the most reliable techniques. Pixels are assigned to the class of highest probability. Neural Network classification is based on training during a training phrase and the proper classification. Its can reduce the speckle or mixed pixel problem in the image. In this paper we were studying the performances of these methods for the purpose of land cover mapping. The experimental results of this work indicated that the Neural Networks algorithm with 89.3% overall accuracy and 0.820 Kappa Coefficient is more reliable than the Maximum Likelihood algorithm with 80.3% and 0.672 overall accuracy and Kappa coefficient, respectively.
PDF Abstract XML References Citation
Received: May 20, 2010;
Accepted: August 30, 2010;
Published: October 11, 2010
How to cite this article
M.R. Mustapha, H.S. Lim and M.Z. Mat Jafri, 2010. Comparison of Neural Network and Maximum Likelihood Approaches in Image Classification. Journal of Applied Sciences, 10: 2847-2854.
DOI: 10.3923/jas.2010.2847.2854
URL: https://scialert.net/abstract/?doi=jas.2010.2847.2854
DOI: 10.3923/jas.2010.2847.2854
URL: https://scialert.net/abstract/?doi=jas.2010.2847.2854
INTRODUCTION
Over the past decade, remote sensing technologies have proven particularly useful in evaluating the distribution of earth’s surface. Remote sensing technology has been used for many years to acquired data such as for land use or land cover application. It provides a useful aid to map and monitor the changing condition of land surfaces. Remote sensing are important tools for natural resource management and environmental monitoring. The traditional method of collecting data for planning is surveying samples at field. Remote sensing technique is a useful method for classifying the image. With processed data available, a quick decision about the area can be made. Satellite remote sensing provides a synoptic view of the earth’s surface, over a number of wavelengths and has been assessed as an alternative means of acquiring such information (McGovern et al., 2000). Thought the data for remote sensing can in the forms of signals and images, our discussion is limited to the remote sensing image data. Image classification is an important part in many remote sensing applications. Classification of land cover is one of the most important task and one of the primary objectives in the analysis of remotely sensed data. Land cover is referred to as natural vegetation, water bodies, rock/soil, artificial cover and others resulting due to land transformation (Roy and Giriraj, 2008).
In this study, two different supervised classification methods were compared for evaluating land cover features in the Makkah area. A Maximum Likelihood classifier, representing a conventional classification method and multilayer perceptron (MLP) Neural Network type, representing supervised artificial neural network algorithms were applied. Maximum Likelihood is one of the most popular supervised classification method used with remote sensing image data. The Maximum Likelihood classification method is well known for the analysis of satellite images (Hagner and Reese, 2007). So far, satellite image interpretation using Maximum Likelihood approach was mostly applied for land cover classification (Huang et al., 2007) and monitoring of land use changes (Shalaby and Tateishi, 2007) showing overall high accuracies (mostly over 80%). This method is based on the probability that a pixel belongs to a particular class. The basic theory assumes that these probabilities are equal for all classes and that the input bands have normal distribution (Ahmadi and Hames, 2009).
Improving land use/cover classification accuracy especially in urban area has been an important issue in remote sensing literature. Much attention has recently been shifted to the development of more advanced classification algorithm including Neural Network approach instead of conventional classification method. Particular attention is given to the role of Artificial Neural Networks in the resolution of some of the problems currently limiting the accuracy with which land cover may be mapped from remotely sensed data. Although, having a wide range of applications in remote sensing, Neural Networks have been used most commonly for supervised image classification (Atkinson and Tatnall, 1997; Wilkinson, 1997). Neural Networks have been found in many studies to produce higher classification accuracies than Maximum Likelihood, although this is not guaranteed to be the case (e.g., if the Gaussian model assumes by Maximum Likelihood classifier is appropriate, then Maximum Likelihood represents an efficient algorithms for classification) (Atkinson and Tate, 1999). Neural networks are increasingly used for the interpretation of remotely sensed data. This success is explained by their high computational efficiency and their ability to accurately approximate complex non-linear functions (Krasnopolsky and Chevallier, 2003). Their estimation performances essentially rely on the training database (distribution of inputs and outputs), their architecture as well as the training process itself. The training consists in learning the intrinsic relationships that connect the inputs to the corresponding outputs (Kimes et al., 1998). Neural Network models have an advantage over the statistical methods that they are distribution-free and no prior knowledge is needed about the statistical distributions of the classes in the data sources in order to apply these methods for classification. Accordingly, Neural Network method takes care of determining how much weight each data source should have in the classification. The aim of this study is to investigate the capabilities and performances of Neural Networks and Maximum Likelihood approaches in order to produce higher degree of classification accuracy from remote sensing data.
MATERIALS AND METHODS
Description of study area: The research was conducted in the Makkah area which is located in the western part of the Saudi Arabia in the year of 2008. Makkah city is an urban area and it is located in the mountainous and desert area. The city is located approximately 80 km (49 mi) inland from the Red Sea in a narrow valley at a height of 277 m (909 ft) above sea level. Location of the study area is between latitude 21°22’N to 21°27’N and longitudes 39°47’E to 39°54’E (Fig. 1).
Materials: The materials used for the classification were ALOS AVNIR-2 satellite data of Makkah, Saudi Arabia and its surrounding areas, which was acquired on June 10, 2008 under clear weather conditions. ALOS AVNIR-2 is a successor to the AVNIR on Advanced Earth Observation Satellite (ADEOS) launched in August 1996. ALOS AVNIR-2 is a visible and near infrared radiometer for observing land and coastal zones. It provides better spatial land-coverage maps and land-use classification maps for monitoring regional environments. The ALOS AVNIR-2 image has four reflective bands with 10 m spatial resolution. In this research, we were used all reflective bands in the processing and image analysis.
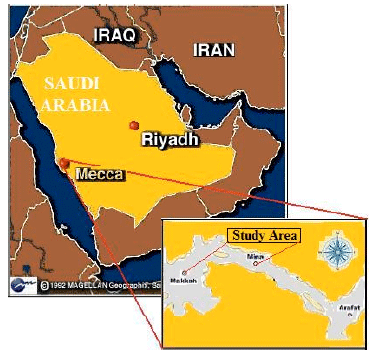 | |
| Fig. 1: | Location of the study area |
This band contain the visible and near infrared band (Band 1: 0.42 μm t 0.50 μm; Band 2: 0.52 μm to 0.60 μm; Band 3: 0.61 μm to 0.69 μm and Band 4: 0.76 μm to 0.89 μm).
Supervised classification: Image classification is the stage of image analysis in which the multivariate quantitative measurement associated with each pixel (usually expressed in 256-grey levels on two or more optical bands) is translated into a label from a pre-defined set (e.g., land use categories). Recall that the intent of the classification process is to assign pixels in an image to several classes of data based on their pixel value. Remote sensing classification is a complex process and requires consideration of many factors. The major steps of image classification may include determination of a suitable classification system, selection of training samples, image preprocessing, feature extraction, selection of suitable classification approaches, post-classification processing and accuracy assessment. Supervised classification means the analyst supervises the selection of spectral classes that represent patterns or land cover features that the analyst can recognize. A supervised classifier employs a priori information of each determined class; this is usually done by means of training sets. These training sets are defined through closed polygons outlined on the image by some interactive procedure. A human analyst attempting to classify features in an image uses the elements of visual interpretation to identify homogeneous groups of pixels which represent various features of interest. Classification process can uses the spectral information (gray value) and spatial information in one or more bands and attempts to classify each individual pixel based on all of existing information. There are many algorithms or methods in supervised classification. Different classification methods have their own capabilities. The question of which classification approach is suitable for a specific study is not easy to answer. But in this study uses two popular supervised classification algorithms that we explain them in brief detail.
Maximum likelihood: Maximum Likelihood classifier is the most common method used in the applications of remote sensing as a parametric statistical method where the analyst supervises the classification by identifying representative areas, called training zones. These zones are then described numerically and presented to the computer algorithm which classifies the pixels of the entire scene into the respective spectral class that appears to be most alike. It is assumed that the distribution training data is Gaussian (normally distributed). The probability density functions are used to classify a pixel by computing the probability of the pixel belonging to each class. During classification all unclassified pixels are assigned class membership based on the relative likelihood of the pixel occurring within each class probability density function (Lillesand et al., 2004). Maximum Likelihood classification is a statistical decision criterion to assist in the classification of overlapping signatures; pixels are assigned to the class of highest probability. Consequently, the Maximum Likelihood classifier may have difficulty distinguishing the pixels that come from different land cover classes but have very similar spectral properties. Traditional per-pixel classifiers may lead to ‘salt and pepper’ effects in classification map especially when many mixed pixel occurred in the image. Usually complex landscape environment will increase the possibility on existing of mixed pixel in the image.
Neural network: A method that uses Artificial Neural Network does not depend on statistical parameters of a particular class. In remote sensing, three types of network are most commonly encountered. There are, multi-layered feed forward (sometimes referred to as multi-layer perceptron networks), Hopfield and Kohonen network. Each type of networks is very different from the others and consequently they vary in their appropriateness for different applications. Feed forward networks have been used widely for supervised image classification (Kanellopoulos et al., 1992). Hopfield networks have been used in studies involving stereo-matching and feature tracking (Nasrabadi and Choo, 1992). Kohonen networks are self organizing and so are particularly attractive for unsupervised and semi supervised classification (Lewis et al., 1992). The most popular Neural Network classifier in remote sensing is the multilayer perceptron. Feed forward or Multilayer perceptrons (MLP) may have one or more hidden layers of neurons between the input and output layers (Fig. 2). They have a simple layer structure in which successive layers of neuron are fully interconnected, with connection weights controlling the strength of the connections. The input to each neuron in the next layer is the sum of all its incoming connection weights multiplied by their connecting input neural activation value (Tedesco et al., 2004). In this study four ALOS AVNIR-2 reflective bands were used as input to the Neural Network. These inputs have been connected to the hidden layer before its came out with five categories as output. The five categories or classes mentioned earlier are Urban, Mountain, Roadway, Vegetation and Ritual Area.
In this study, we used a 4-4-5 Neural Network architecture which represents four neurons in the input layer, four neurons in the hidden layer and five neurons in the output layer.
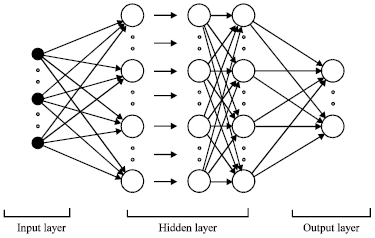 | |
| Fig. 2: | Basic Neural Network architecture |
Only one hidden layer was used in this study. The classification accuracy was evaluated using Kappa coefficient and the confusion matrix.
EXPERIMENTS AND RESULTS
Through this study, observations regarding Neural Networks and Maximum Likelihood techniques were presented and tested. Performances of both algorithms were compared so that the best classifier for the classification purposes can be determined especially in the study areas. This study was based on the satellite image captured from ALOS AVNIR-2 sensor with the resolution of 10 m. The original image is shown in Fig. 3. Supervised method was used for the classification process. The image analysis for supervised classification involved three basic steps which is training stage, classification stage and output stage. Training stage is the most important part in supervised classification because it could influence the final classification results. In this stage, the supervised classification required some training sites and the areas were established using polygon. For the Neural Network approach, we have to create a bitmap layer in order to collect training data whereas no bitmap layer is required for the Maximum Likelihood approach. The amount of the bitmap layer to be created is depending on the amount of the classes that want to be classified. Each layer represents each class. For our study, five classes have been classified so that it is required five bitmap layers for the training stage. On the other hand, all training data were collected in the image raster layer for all classes in the Maximum Likelihood approach. These training data is used to train the system to recognize the classes based on their spectral characteristic. The process of selecting a training area for each of five cover types were undertaken in an area that was not mixed with other cover types, or area that has homogeneous cover types.
 | |
| Fig. 3: | Original Image taken from ALOS AVNIR-2 sensor |
In the classification stage, supervised classification method was used to classify the images. There are many techniques in supervised method. But in this study we only concern with both of the algorithms proposed earlier. In the output stage, the classified images were produced with five different colours which represented five different types of classes. Fig. 4a and b showed the classification results using Neural Network and Maximum Likelihood classifiers, respectively.
The outcome of the classified images should be tested to check the correctness of the classification result. For that reason accuracy assessment was carried out by selecting 300 samples randomly to check the validity of the classified images as well as their performances and capabilities in order to get higher classification accuracy. The percentage of the classification result for both classifiers can be calculated by analyzing the confusion matrix tables (sometimes called error matrix) (Table 1, 2).
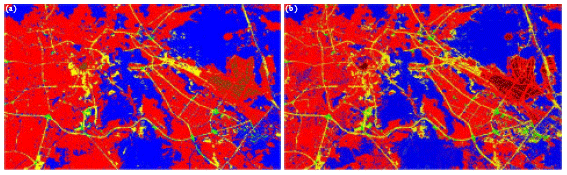 | |
| Fig. 4: | Supervised classification results using (a) Neural Network and (b) Maximum Likelihood. [Color Code: Red = Urban, Blue = Mountain, Yellow = Roadway, Brown = Ritual Area and Green = Vegetation] |
| Table 1: | Confusion matrix result using neural network |
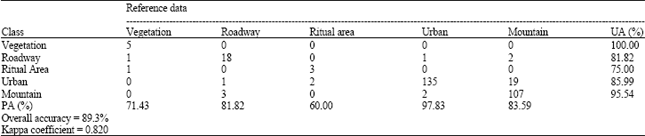 | |
| PA: Producer accuracy, UA: User accuracy | |
| Table 2: | Confusion matrix result using maximum likelihood |
 | |
| PA: Producer accuracy, UA: User accuracy | |
Table 1 showed the confusion matrix result derived from Neural Network whereas confusion matrix result by using Maximum Likelihood classifier is shown in Table 2. Beside this measurement, there are some indicator that always used to show the classification results such as overall accuracy, Kappa coefficient, producer accuracy and user accuracy. Kappa coefficient was generated to describe the proportion of agreement between the classification result and the validation sites after random agreements by chance are removed from consideration these data (Thomas et al., 2002). Kappa Coefficient can be measured by the equation as stated below:
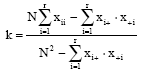 | (1) |
| Xii | = | Sum of diagonal inputs of error matrix |
| Xi+ | = | Sum of row i of error matrix |
| X+i | = | Sum of column i of error matrix |
| N | = | No. of elements in error matrix |
In Kappa coefficient, value zero shows no agreement between classified and ground truth maps, while value one shows a complete agreement between these maps (Mather, 1999). According to Tso and Mather (2001), producer accuracy is calculated by dividing the number of correct objects of a specific class by the actual number of reference data objects for that class. User accuracy is however determined by dividing the number of correct objects of a specific class by the total number of objects assigned to that class. Producer accuracy informs about the proportion of correctly labelled object in the reference data. This is also a measure of commission errors. User accuracy, however, quantifies the proportion of objects assigned to a specific class that agree with objects in the reference data. User accuracy indicates the probability that a specifically labelled object also belongs to that specific class in reality. It reveals commission errors.
To make a comparison, the result from Maximum Likelihood classification and Neural Network approach were compared each other by analysing those indicators (overall accuracy, kappa coefficient, producer accuracy, user accuracy). Neural Network gave the better result rather than Maximum Likelihood classifier. The overall classification accuracy was 89.3% while the Kappa coefficient had a value of 0.820. In addition, the accuracies for each category were as followed: 100.00% for Vegetation, 81.82% for Roadway, 75.00% for Ritual Area, 85.99% for Urban and 95.54% for Mountain. The result obtained from Maximum Likelihood classification in term of classification accuracy and Kappa coefficient were 80.3% and 0.672, respectively. The accuracies for each category using Maximum Likelihood were following: 80.00% for Vegetation, 48.15% for Roadway, 100.00% for Ritual Area, 81.75% for Urban and 84.80% for Mountain. Those results indicated that most of the classes from Neural Network technique had better percentage of accuracy compared to Maximum Likelihood classifier. For instance, in producer accuracy all classes gave higher percentage of accuracy except class Vegetation and Ritual Area whereas only class Ritual Area had lower percentage of accuracy in user accuracy.
DISCUSSION
Present results indicated differences in performance between the two classification methods. The artificial Neural Network performed better than Maximum Likelihood classification as shown by visual interpretation of classified map as well as the percentage of the classification accuracy. This confirms the experience that Neural Networks approach tends to become more accurate than statistical Maximum Likelihood technique (Liu et al., 2003; Joshi et al., 2006). For instance, Joshi et al. (2006) reported that Neural Network approach could be increased the classification accuracy up to approximately 15% compared to Maximum Likelihood technique in their study of forest canopy density. For our study, the classification accuracy could be increased up to 9% when using the Neural Network approach. The increasing of the classification accuracy is due to the ability of Neural Network in handling the mixed pixel problem in the image. As mentioned earlier, the images used in this study were obtained from high spatial resolution satellite data (10 m in spatial resolution) so that much information could be extracted from the images especially in the urban area. This will increase the possibility of mixed pixels to be occurred. By analyzing both classified images, we found that Neural Network approach could overcome the speckle problem in an image. This algorithm can produce smooth images by reducing the speckle pixel that always occurred in the pixel that has many cover types (mixed pixel). Image classification is usually based directly on spectral signatures that are captured by remote sensors. However, complex landscapes with the mixed-pixel problem would lead to the difficulties in classification. As stated by Cracknell (1998) and Fisher (1997) mixed pixels have been recognized as a problem affecting the effective use of remotely sensed data in urban land use/cover classification. The statistical Maximum Likelihood classifier cannot handle this kind of complex images so that many pixels cannot be classified correctly. Moreover, the study area located in the desert terrain in the mountainous area caused the difficulty to differentiate the features around the area due to their spectrally similar. For instance, it is very difficult to differentiate between Urban and Mountain classes due to some of the urban area were located at the mountain area and cause the Urban environment have a very similar spectral value with the Mountain class. This statement can be explained by analysing the confusion matrix tables (Table 1 and 2). Table 1 presents the confusion matrix for the artificial Neural Network classifier. The matrix shows that 135 out of 157 observations had been correctly classified for the Urban category and 19 points were misclassified as Mountain class. In addition, the Maximum Likelihood method correctly classified 112 out of 137 observations for the same class and 21 points were misclassified as Mountain class (Table 2). Both of the classifiers have the difficulty to classify this category, however, Neural Network performed better than Maximum Likelihood approach in term of the classification accuracy. On the other hand, both of the classifiers easily to classify the Vegetation and Ritual Area classes due to the significantly different on their spectral characteristic against other features. However, Neural Network algorithm has a good performance for the Roadway class compared to the Maximum Likelihood algorithm.
From the viewpoint of processing time, the Neural Network was slower than Maximum Likelihood in the training phase. But once the training phrase is completed then it is very fast to classify the images. Period of training phase is depending on the complexity of the image. If the image is more complex then it will take longer time to complete the training phase. However, for our data set, both of classifiers considered were quite fast in the training and classification phases. In term of training data, Neural Network did not required many training set for the classification process as this classifier is not a statistical approach. However, Maximum Likelihood is a statistical classifier so that it needs many training data for the classification process. Therefore, with very large of training sets, it can generate the statistical distribution and used this data for classifying the images.
CONCLUSIONS
Through this study, observations regarding Artificial Neural Networks for classifying remote sensing data were presented and tested. Performances of Neural Network approach were compared with those obtained using the statistical Maximum Likelihood algorithm. Five land cover classes can be successfully classified using high spatial resolution remotely sensed data. The final output indicates that Neural Network approach gave the better results than statistical Maximum Likelihood algorithm up to 9%. This algorithm also could overcome the mixed pixel problem in the image.
ACKNOWLEDGMENTS
This project was carried out using the USM-RU-PRGS grants. Thanks are extended to USM for support and encouragement. This research is conducted under the agreement of JAXA Research Announcement titled >2nd ALOS Research Announcement for the Advanced Land Observation Satellite between the Japan Aerospace Exploration Agency and the Research - The use of ALOS data in studying environmental changes in Malaysia (JAXA B 404).
REFERENCES
- Ahmadi, F.S. and A.S. Hames, 2009. Comparison of four classification methods to extract land use and land cover from raw satellite images for some remote arid area, Kingdom of Saudi Arabia. J. King Abdulaziz Univ., 20: 167-191.
Direct Link - Cracknell, A.P., 1998. Synergy in remote sensing-what's in a pixel. Int. J. Remote Sens., 19: 2025-2047.
Direct Link - Hagner, O. and H. Reese, 2007. A method for calibrated maximum likelihood classification of forest types. Remote Sens. Environ., 110: 438-444.
CrossRef - Huang, H., J. Legarsky and M. Othman, 2007. Land cover classification using Radarsat and Landsat imagery for St. Louis, Missouri. Photogrammetric Eng. Remote Sens., 73: 37-43.
Direct Link - Joshi, C., J.D. Leeuw, A.K. Skidmore, I.C.V. Duren and H.V. Oosten, 2006. Remotely sensed estimation of forest canopy density: A comparison of the performance of four methods. Int. J. Applied Earth Observ. Geoinform., 8: 84-95.
CrossRef - Kanellopoulos, I., A. Varfis, G.G. Wilkinson and J. Meiger, 1992. Land cover discrimination in SPOT HRV imagery using artificial neural network�a 20 class experiment. Int. J. Remote Sens., 13: 917-924.
CrossRef - Kimes, D.S., R.F. Nelson, M.T. Manry and A.K. Fung, 1998. Attributes of neural networks for extracting continuous vegetation variables from optical and radar measurements. Int. J. Remote Sens., 19: 2639-2663.
CrossRef - Krasnopolsky, V.M. and F. Chevallier, 2003. Some neural network applications in environmental sciences. Neural Networks, 16: 335-348.
CrossRef - Liu, X., A.K. Skidmore and H.V. Oosten, 2003. An experimental study on spectral discrimination capability of a backpropagation neural network classifier. Int. J. Remote Sens., 4: 673-688.
CrossRef - McGovern, E.A., N.M. Holden, S.M. Ward and J.F. Collins, 2000. Remote sensed satellite imagery as an information source for industrial peatlands management. Resour. Conserv. Recycl., 28: 67-83.
CrossRef - Nasrabadi, N.M. and Y.C. Choo, 1992. Hopfield network for stereo vision correspondence. IEEE Trans. Neural Network., 3: 5-13.
PubMed - Roy, P.S. and A. Giriraj, 2008. Land use and land cover analysis in indian context. J. Applied Sci., 8: 1346-1353.
CrossRefDirect Link - Shalaby, A. and R. Tateishi, 2007. Remote sensing and GIS for mapping and monitoring land cover and land use changes in the Northwestern coastal zone of Egypt. Applied Geography, 27: 28-41.
CrossRef - Tedesco, M., J. Pulliainen, M. Takala, M. Hallikainen and P. Pampaloni, 2004. Artificial neural network based techniques for the retrieval of SWE and snow depth from SSM/I data. Remote Sens. Environ., 90: 76-85.
CrossRef - Thomas, V., P. Jelinski, D. Miller, J. Lafleur and J.H. McCaughey, 2002. Image classification of a Northern Peatland complex using spectral and plant community data. Remote Sens. Environ., 84: 83-99.
Direct Link - Tso, B. and P.M. Mather, 2001. Classification Methods for Remotely Sensed Data. 1st Edn., Taylor and Francis, London.
Direct Link