
G.C. Hapsari
Department of Mechanical Engineering and Mechatronics, Hochschule Karlsruhe Technik und Wirtschaft, Moltkestr, 30, 76133 Karlsruhe, Germany
A.S. Prabuwono
Faculty of Information Science and Technology, Universiti Kebangsaan Malaysia, 43600 UKM Bangi, Selangor D.E., Malaysia
Journal of Applied Sciences
Year: 2010 | Volume: 10 | Issue: 22 | Page No.: 2793-2798







ABSTRACT
Human detection is being developed as a support in surveillance system for security purpose. The interest of this particular surveillance system is to detect people and tracking their activities in a designated environment. Detecting and tracking human motion in real-time is the essential goal to understand its activities, where the result of interpreting this image will feed another system to invoke necessary security precaution or action. Knowing that in public places such as airport, train station and shopping mall the security surveillance system has been installed, there is a need to develop a system suitable to gather enough information to serve the goal. In this study, a review of human motion analysis, the methodologies of human motion surveillance, choice of system and how they work will be explained. Human motion recognition will be developed more than just a surveillance system but can also took part in lots of application such as home appliance for fire alarm system and remote robotic surgery.
PDF Abstract XML References Citation
Received: June 05, 2010;
Accepted: July 18, 2010;
Published: October 11, 2010
How to cite this article
G.C. Hapsari and A.S. Prabuwono, 2010. Human Motion Recognition in Real-time Surveillance System: A Review. Journal of Applied Sciences, 10: 2793-2798.
DOI: 10.3923/jas.2010.2793.2798
URL: https://scialert.net/abstract/?doi=jas.2010.2793.2798
DOI: 10.3923/jas.2010.2793.2798
URL: https://scialert.net/abstract/?doi=jas.2010.2793.2798
INTRODUCTION
For so many reasons, surveillance system has been developed from time to time to serve various needs. In conventional surveillance system, human holds the significant judgment to the event happening which was a dull activity where human has to watch monitors continuously for a long period of time which result in negligence.
A long leap has been taken to replace human surveillance into an automatic system where the system is expected to be able to help justify, based on some predetermined norms, such as unattended package in a public spot for a certain amount of time is considered to be suspicious. The judgment of whether it is suspicious or not will be determined by human, however it is considerably practical to have surveillance system to support these judgments.
When a judgment has been called for the matter of security because an unauthorized activity happens, all focus is on object and prevention or countermeasure should be done immediately. Such short response time is extremely critical thus a real-time system is suitable (Meng et al., 2004). This surveillance system works by capturing images, detecting whether human is present in the frame then analyzing its activities. There are different approaches to reach these goals.
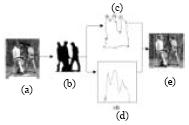
Surveillance system: Surveillance systems generally are operated on video taken from stationary camera as they are being installed on public places. In images captured contains mixed information; there are noise, the background images (such as hotel lobby or park), people with their activities (e.g., people running or carrying a package) and other object (such as a car passing by). Segmentation is required in order to separate background image from the rest or foreground (Prabuwono et al., 2004). After the segmentation, several methods can be used to recognize human in the foreground. Figure 1 shows the image processing steps in real-time surveillance system.
Image acquisition: There are many choices of video camera to capture the moving image (Akbar and Prabuwono, 2008). A way to choose which type of camera suitable for the system depends on its requirement of captured image to be processed in order to give a good result of model for human recognition. For indoor application, a fixed camera or even mobile camera is possible (Cai et al., 1995; Cai and Aggarwal, 1996).
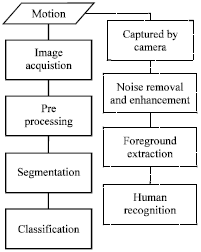 | |
| Fig. 1: | Real-time surveillance system |
While, for outdoor application where the quality of image captured depends on the light level, therefore an infrared camera is also an excellent suggestion. Most of the surveillance systems take advantage from the already installed fixed camera on the spot.
Pre-processing: To be able to extract the image wanted, pre processes are done with noise cleaning and image enhancement (Akbar et al., 2008). Some of system use region-based noise cleaning to eliminate small regions by binary connected-component (Haritaoglu et al., 1998a). Others use blob-like entities by group together the atomic parts of a scene to form it (Wren et al., 1997) and some other use edge detection and 2D line extraction (Cai et al., 1995).
Segmentation: There are two manners to segment the foreground from the background. First is to record the pure background, which is the scene without people or activity in it (as reference). So in normal condition, any differences from the reference will be acknowledged as its foreground (Haritaoglu et al., 1998a). Another way to segment is to dynamically update background. By updating the scene from time to time, the system observes two consecutive frames and decides the background is the one who has a relatively smaller velocity (negligible motion) for a fixed camera. While for mobile camera, it is important to separate the movement of the camera and the foreground object. The separation is based on tracking the motion of geometrical features correspondence as they belong to the background. It is assumed that the foreground is anything that moves relatively to the camera’s motion (Cai et al., 1995; Cai and Aggarwal, 1996).
RECOGNITION MODEL
General appearance model: When a foreground has been extracted, the object is modeled to confirm a human presence in the frame which permits its tracking.
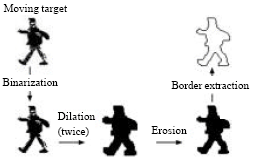 | |
| Fig. 2: | Target of pre-processing: border extraction |
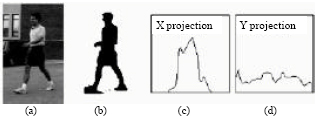 | |
| Fig. 3: | Silhouette based shape features (a) input image, (b) binary image, (c) x projection and (d) y projection |
There are three ways to model human in the foreground: first is to use silhouette boundary (Haritaoglu et al., 1998a; Fujiyoshi and Lipton, 1998), second is by creating dynamic template and third is by using the histogram of binary image projection (Haritaoglu et al., 1998b, 1999a, b). To obtain a silhouette boundary, the image should undergo the process of binarization. After binarization the image is dilated then eroded. From the eroded image the border is extracted as shown in Fig. 2 (Fujiyoshi and Lipton, 1998).
For dynamic template so called temporal texture template, is a series of body movement registered as an identity of a subject. This identity will be used to confirm a re-appearance of the subject whether it is the same as before. Dynamic template overcomes the problem of missing subject such as people passing by a tree. The histogram of binary image is the result of binary image projected in pixels, where the number of black pixel is counted on every line for the x projection and every column for the y projection as shown in Fig. 3a-d (Haritaoglu et al., 1998a).
Specific appearance model: By using the silhouettes extracted, there are further advantages can be done because the image captured does not always contain a single subject without any accessories or abnormalities. These conditions are considered to be outside of general appearance model because accessories are part of their silhouettes. When capturing an image of human, it is more likely that human are doing other activities than just standing alone. They might be crawling (Haritaoglu et al., 1998b), carrying a package (Haritaoglu et al., 1999b) or walking together with other human (Haritaoglu et al., 1999b). By understanding these conditions, the system will reach an overall comprehension upon its subject.
Model with body part: The interest of understanding human activities started from understanding what activities they are doing as their images captured. Different silhouette posture will be understood as different activities. By silhouette’s border extraction the main axis and the median point of the body will be determine, then the hull vertices will try to help to locate the primary body parts such as head, shoulder, hand, hip, foot etc. These body parts considered to be the outer extreme point of the silhouette.
From each point taken, the analysis will find a possible area for head. This possible area can be found by taking two non mirroring points (such as right/left shoulder) than draw their lines to the median point. The approximate position of head shall be within this area and near the main axis as shown in Fig. 4a-d.
Head is the reference to find other body part because it is considered easier to be found. One of the feet can be found by analyzing the lowest y coordinate, when more than one exists than it should be choose to be the one who has the lowest x coordinate as well. Then the torso will be located along the main axis between the median point and the head.
Object carrying model: Starting from the assumption that human body shape is considerably symmetric around its axis. However, this symmetrical constrain might be violated by its body part or an object carried. There are two ways to be sure whether the violation caused by an object or not.
First, violation by body parts (such as swinging hands when people walking) are periodically while violation of the object carried is continuously.
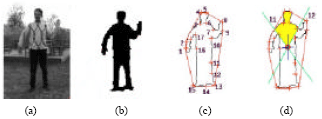 | |
| Fig. 4: | Possible head area: (a) input image, (b) silhouette, extracted to (c) border image with hull vertices and (d) possible head area |
Using temporal template, the density of pixel from its silhouette shows the difference where the violation area with periodic motion has less density than other violated area as shown in Fig. 5a-f (Haritaoglu et al., 1999b).
Pixels from non symmetric area are grouped into regions where each periodicity will be further analyzed using horizontal projection histogram. The non symmetric area that has different periodic motion to the body will be considered as object as shown in Fig. 6 (Haritaoglu et al., 1999b).
Multiple model: Most of the systems assume that the subject is alone in its detected region. However, it is possible also that multiple people found in one frame. It is necessary to differentiate who is who in the silhouette though they are occluded, while in surveillance they might exchange object.
The basic to be able to determine number of people exist in the frame is to do the head count. To have the correct number of head, first is to extract the boundary of silhouette, second is to define the hull vertices on it and third is to use the vertical projection histogram of the silhouette. From silhouette boundary, hull vertices are employed to find candidates of extreme points of body parts (such as head, shoulders, hands and feet). Each vertex is analyzed whether it has similar shape as expected head shape or not.
 | |
| Fig. 5: | Example of temporal template on symmetry violations: (c, d) shape and intensity of body and (e, f) non symmetric area |
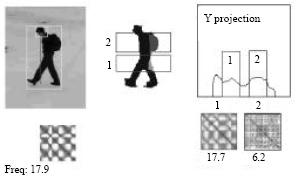 | |
| Fig. 6: | Comparison of non symmetrical area: (1) body part, (2) object |
The rest who has no shape similarity will be excluded from further analysis. Then the possible heads’ shapes are analyzed with the vertical histogram projection. In the projection, heads are potentially has the highest value considering it is located on the top extremity. By locating the head, it is more likely to be able to place each torso below each head as shown in Fig. 7a-e (Haritaoglu et al., 1999a).
The main interest of tracking multiple people is to follow people before, when and after occlusion using the following steps:
| • | Estimate the displacement of the foreground median so the observed space is narrowed down |
| • | Silhouette boundary is segmented where each small segment is assigned to a person in the group according to the previous frame |
| • | Motion of the head is estimated using a search window will determined the predicted location of the body in the next frame |
When an exchange of object or a crime happens during occlusions, the system is most likely to be able to determine who is doing what to whom by understanding their displacement as shown in Fig. 8a-f (http://www.umiacs.umd.edu/~hismail).
 | |
| Fig. 7: | Multiple people tracking: (a) input image, (b) silhouette, (c) locating heads (boundary extraction and hull vertices analysis), (d) possible head analyzed with vertical projection histogram, (e) locating each torso |
 | |
| Fig. 8: | Detecting displacement of multiple people before, during and after occlusions (from left to right and from top to bottom) |
OBJECT TRACKING
When the foreground object has been determined into categories such as single/multiple person, with/without object then it is also important to continuously follow the subject to understand what is its present activity and what might be the future activity. Therefore it is favorable to match their features on sequential frames.
In order to follow its movement, human are modeled as using a priori model such as cardboard model (Haritaoglu et al., 1998a) or blob (Wren et al., 1997). However, it is also possible to do without using a priori model (Fujiyoshi and Lipton, 1998). Their general framework is based on the feature extraction, feature correspondence and level of processing (Aggrawal and Cai, 1999).
The system that works without a priori model has its own advantage that it does not require large number of pixels on target. Once the image extracted into skeleton, it does not require lots of computation to estimate the series of motion because it is easier to establish correspondence between sequences of image. For example, once the skeleton is applied, less computation required to differentiate the type of motion such as walking or running as shown in Fig. 9a and b (Fujiyoshi and Lipton, 1998).
The system that used a priori model was based on the fact that the real object has more complex features than skeleton. When more feature needed to determine the type of motion such as a subject leaving an empty backpack and another subject load something into it, then one must choose a suitable model where these feature are well represented in the model. By demanding such requirements, the system should be supported by powerful computation engine.
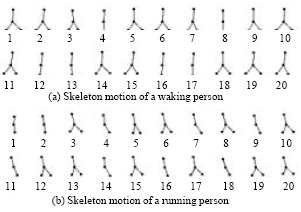 | |
| Fig. 9: | Motion recognition between sequential images by analyzing the leaning angle of the body: (a) walking, (b) running |
It is also possible that regardless the use of a priori model or not, number of camera working for one scene plays a role on tracking subject. Single camera will need more computation when an occlusion appeared. However multiple perspective concerns the matching between images captured from one device to another.
DISCUSSION
The W4 system (Haritaoglu et al., 1998a) with its accompanying system: Ghost (Haritaoglu et al., 1998b), Backpack (Haritaoglu et al., 1999b) and Hydra (Haritaoglu et al., 1999b) works as a complete system to determine a moving object as human and also define the gesture, object carried and existence of multiple person. However, it still needs to recognize activities as well instead of defining two people walking towards each other, it needs to determine whether they change object.
While for Pfinder (Wren et al., 1997) although it claims that no problem will occur for multiple people however there might be some ambiguities to define gesture recognition because it explains blob as single human but the recognition of human is simple and therefore needs not so complicated computation to generate the model.
As for the indoor applications, it only serves using single camera and unable to track multiple people, however it defines well the background using geometrical features regardless the camera used (fixed or mobile).
For skeletonization method, as it used a very simple model which gives advantages that it can work well with simple computation but it is lack of details required to be able to define what kind of activities happening in the screen.
Potential application: The discussion of real time surveillance system is not limited only to security application. There are numbers of field of application possible such as pedestrian detection for driver assistance and/or vehicle control, battlefield awareness and when incorporated to other type of sensors such as heat sensors, it can be applied for fire safety system in the building. To increase the system’s capability it is more likely to combine multiple sensors (Besari et al., 2008; Gavrilla, 1999).
CONCLUSION
When building a surveillance system, it is important to determine what kind of model result from image processing because the following process will depend on its result. In image processed the possibility to find complex image such as unordinary posture, an object included or even more than one subject needs to be investigated. However it is also important to relate these processes to the desired analysis where simple representation of subject might not be adequate to provide further analysis.
The vast choice of system and equipment has opened the gate to even more application beyond security purposes when possible to reach the medical application for remote surgery by robotic arm or even house appliances support system such as potential fire safety system. When fire happens, fireman squad will be able to focus on saving the human or animal by locating their exact position. To realize more application using real-time surveillance system as its support, combination of multiple sensors as well as good communication among systems is required.
ACKNOWLEDGMENTS
The authors would like to thank Hochschule Karlsruhe and European Commission for providing facilities and Erasmus Mundus Scholarship as well as Universiti Kebangsaan Malaysia for providing financial support under Research University Operation Project No. UKM-OUP-ICT-36-186/2010 and Arus Perdana Project No. UKM-AP-ICT-17-2009.
REFERENCES
- Aggrawal, J. and Q. Cai, 1999. Human motion analysis: A review. Comput. Vision Image Understand., 3: 428-440.
CrossRef - Cai, Q., A. Mitiche and J.K. Aggarwal, 1995. Tracking human motion in an indoor environment. Proc. Int. Conf. Image Process., 1: 215-218.
CrossRef - Cai, Q. and J.K. Aggarwal, 1996. Tracking human motion using multiple cameras. Proc. Int. Conf. Pattern Recognition, 3: 68-72.
CrossRef - Fujiyoshi, H. and A.J. Lipton, 1998. Real-time human motion analysis by image skeletonization. Proceedings of the 4th IEEE Workshop on Applications of Computer Vision, Oct. 19-21, IEEE Computer Society, Princeton, New Jersey, pp: 15-21.
CrossRef - Gavrilla, D.M., 1999. The analysis of human motion and its application for visual surveillance. Proceedings of the 2nd IEEE Workshop on Visual Surveillance, June 26, IEEE Computer Society, Fort Collins, pp: 3-5.
CrossRef - Haritaoglu, I., D. Harwood and L.S. Davis, 1998. W4: Who, when, where, what, a real time system for detecting and tracking people. Proceedings of the 3rd IEEE International Confrence on Automatic Face and Gesture Recognition, April 14-16, IEEE Comput. Soc, Nara, Japan, pp: 222-227.
CrossRef - Haritaoglu, I., D. Harwood and L.S. Davis, 1998. Ghost: A human body part labeling system using silhouettes. Proc. 14th Int. Conf. Pattern Recogn.,, 1: 77-82.
CrossRef - Haritaoglu, I., D. Harwood and L. Davis, 1999. Hydra: Multiple people detection and tracking using silhouettes. Proceedings of the International Conference on Image Analysis and Processing, Sept. 27-29, IEEE Computer Society, Venice, pp: 280-285.
CrossRef - Haritaoglu, I., R. Cutler, D. Harwood and L.S. Davis, 1999. Backpack: Detection of people carrying objects using silhouettes. Proc. the 7th IEEE Int. Conf. Comput. Vision, 1: 102-107.
CrossRef - Wren, C.R., A. Azarbayejani, T. Darrell and A.P. Pentland, 1997. Pfinder: Real-time tracking of the human body. IEEE Trans. Pattern Anal. Mach. Intel., 19: 780-785.
CrossRefDirect Link