
R. Furferi
Dipartimento di Meccanica e Tecnologie Industriali, Universit� degli Studi di Firenze, Via di Santa Marta 3, 50139, Firenze, Italy
M. Carfagni
Dipartimento di Meccanica e Tecnologie Industriali, Universit� degli Studi di Firenze, Via di Santa Marta 3, 50139, Firenze, Italy
Journal of Applied Sciences
Year: 2010 | Volume: 10 | Issue: 18 | Page No.: 2108-2114







ABSTRACT
Color match prediction is one of the most important aspects to be considered by industries dealing with colorants. Several generally applicable theoretical models have been proposed so far for helping the colorists in achieving an exact color match. Such approaches, often based on extensive experimental tests and provided of exhaustive results, are differentiated by a specific range of application (textiles, study, paintings, etc.). Therefore, the results are subjected to restrictions or constraints (number of colorants, reliability of the prediction, etc.). The present paper describes, into a mathematical form, three widely known techniques adopted in the scientific literature for evaluating the spectrophotometric color match prediction of a target shade: Kubelka-Munch, Stearns-Noechel and Artificial Neural Networks. The proposed method starts from such wide known methodologies and by means of mathematical assessment provides some useful equations to be straightforwardly used for color matching. Moreover an Artificial Neural Network based formulation is provided. The results of the work shows that the expected color distance between the predicted the real color of a shade is less than 0.8, in terms of CIE L*a*b* distance.
PDF Abstract XML References Citation
Received: February 13, 2010;
Accepted: April 23, 2010;
Published: July 14, 2010
How to cite this article
R. Furferi and M. Carfagni, 2010. An As-Short-as-Possible Mathematical Assessment of Spectrophotometric Color Matching. Journal of Applied Sciences, 10: 2108-2114.
DOI: 10.3923/jas.2010.2108.2114
URL: https://scialert.net/abstract/?doi=jas.2010.2108.2114
DOI: 10.3923/jas.2010.2108.2114
URL: https://scialert.net/abstract/?doi=jas.2010.2108.2114
INTRODUCTION
One of the main efforts of the industries dealing with colorants is to find the correct proportion of the colorants required to achieve an exact color match. This process, called color match prediction consists in generating, usually by means of trial and error techniques, a recipe to match a desired or target shade and is often performed by a trained colorist. Computer Color Matching (CCM) is a widely known technology for the color match prediction (Zhang and Li, 2008). This method overcomes the lacks of the experimental color matching approach thus resulting more convenient, accurate and time saving (Agahian, 2008). Spectrophotometric and colorimetric color matching are two methods that are conventionally used. Colorimetric algorithms aim to minimize the color differences (usually expressed in tristimulus values) between a target and a color sample. Spectrophotometric color matching is a technique able to achieve a sample with spectrophotometric curve similar to target reflectance curve. Referring to spectrophotometric approaches, the most commonly adopted are based on the Kubelka-Munk theory (Kubelka, 1954) that is widely used for describing the colour properties of a fabric.
The Kubelka-Munk (K-M) theory is generally used for the analysis of diffuse reflectance spectra obtained from weakly absorbing samples. It provides a correlation between reflectance and concentration.
As widely known (Burlone, 1990), K-M establishes that internal reflectance of a colorant composing a shade, p(λ, α1), depends on absorption, Kλ and scattering, Sλ according to the following equation:
| (1) |
where, λ is the wavelength in the visible range (300-700 nm). p(λ) is the spectral response (reflectance) of a generic colorant composing the reference shade. (K/S)λ is the ratio between the absorption and the scattering coefficients for a given wavelength.
Equation 1 is valid for a single wavelength (or monochromatic light). The values of Kλ and Sλ need to be computed from measurements of the reflectance of the mixture composing the shade. More in detail the (K/S) ratio of a mixture is an additive combination of each colorant’s unit absorptivity, Kλ and unit scattering Sλ, scaled by effective concentration, c, plus the absorption and scattering of the substrate (notated by subscript t) as described in the following Equation:
| (2) |
where, (K/S)λ,mix is the (K/S) ratio of a mixture, αi is the proportion of the ith component composing the mixture. Kλ, i and Sλ, i are, respectively, the absorptivity and the scattering coefficient of the ith component composing the mixture.
For each component in the mixture, both the absorption and scattering properties need to be known. For opaque materials, where the colorants do not scatter in comparison to the substrate, the mixing equation may be simplified as follows (Westland et al., 2000):
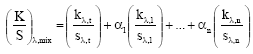 | (3) |
Stearns and Noechel worked with fine wool fibers blended in the form of slubbing with the help of a draw frame. In their approach, called S-N approach, they assumed that the reflectance value of the blend lies between the reflectance values of the constitutive fibers and is different from the mean of the primary reflectances weighted by the relative mass percentages. Several studies, related to the tristimulus-matching algorithm based on the approach firstly proposed by Stearns and Noechel (1944) and its implementations (Thompson and Hammersley, 1978; Kazmi et al., 1996), allows a reliable prediction of the formula for matching a given colour standard. The S-N based approach estimates the spectrum of a blend (i.e., the term f(R(λ)) in Eq. 4) obtained by mixing differently colored once known the empiric constant b, according to the following relationship:
| (4) |
where, R(λ) is the reflectance and b is a dimensionless constant that can be determined by means of several experimental tests (Banyard et al., 2006; Rong and Feng, 2006). F(R(λ)) represents the mixture function (Westland et al., 2002).
Artificial Neural Networks (ANNs) are able to provide alternative mappings between colorant concentrations and spectral reflectances (Furferi and Carfagni, 2010; Bishop et al., 1991) and, more generally, determine non-linear transforms between colour spaces.
The FFBP ANNs are known to be suitable for applications in the pattern classification field, especially where the limits of classification are not exactly defined (Furferi and Governi, 2008). A properly trained FFBP ANN is capable of generalizing the shape of a spectrophotometric response on the basis of the information acquired during the training phase. In order to properly teach the network to respect the classification made by the picker, a proper target set is required.
In all the previously mentioned cases, computer recipe prediction systems require a mathematical model able to obtain an accurate color matching. In other words such a model, called color recipe mapping, is required to process colorant concentrations and spectral responses, in input, so as to provide, as output, the spectral response of a desired shade obtained by mixing the colorants.
Starting from well known relationships acknowledged at the state of the art, the main objective of the work is to provide three different formulations for the assessment of the color recipe mapping. These formulations, based respectively on K-M, Stearns Noechel and ANN techniques, may be adopted by researchers and practitioners in order to assess the exact color matching once they know the concentrations and the spectral response of the colorants composing a particular recipe.
MATERIALS AND METHODS
Definitions: Let pi(λ) be the spectral response in the visible wavelength of the ith of the n colorants composing the desired shade (called reference): I = 1,2,…,n. The colour spectrum R(λ, αi) obtained by a linear combination of the spectra of each component, called Weighted Average Spectrum (WAS), can be stated as follows:
| (5) |
As λ indicates the wavelength, in the range (400-700 nm), the size of vectors pi(λ) and R(λ, αi) is 1 x 31.
Of course, the following equation must be satisfied:
| (6) |
The WAS may be related to the real spectral response of the reference RS(λ) measured by means of a spectrophotometer.
In other words, the color recipe mapping id defined by a transfer function F that state the functional connection between R(λ, αi) and RS(λ):
| (7) |
Once known the transfer function Φ(λ, αi), it is possible to give a reliable estimation of the reference spectral response starting from the spectral response and the proportion of each colorant i.e., it is possible to assess the exact color matching.
As previously mentioned, the present work aims to state three different formulations for mathematically defining the mapping function F:
| • | K-M based formulation |
| • | Stearns-Noechel based formulation |
| • | ANN based formulation |
These formulations are based on the assumption that a function Φ(λ, αi) exists such that:
| (8) |
In other words if RSj (λ) is the jth element of RS (λ), Rj (λ, αi) the jth element of R (λ, αi) and φj (λ, αi) is the jth element of Φ(λ, αi), with j = 1, 2, …, 31, Eq. 8 can be written, element by element, as follows:
| (9) |
This transfer function can be considered applicable for any variation of the parameters αi as long as the Eq. 2 is respected:
K-M based formulation: A first mathematical definition of the transfer function φj(λ, αi) may be afforded by means of the K-M formulation. Combining Eq. 1 with Eq. 9 it is possible to write:
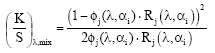 | (10) |
Thus obtaining:
| (11) |
Finally, solving for φj (λ, λi):
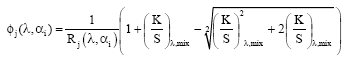 | (12) |
This equation reassumes the studies conducted by Allen (1966) and cited by McDonald (1997) and Berns (2000).
Stearns-noechel based formulation: According to Allen (1966), if the degree of metamerism between the target and the prediction is not too great it can be written the following equation (Philips-Invernizzi et al., 2002):
| (13) |
By combining Eq. 13 and 9 it can be demonstrated that:
| (14) |
According to Eq. 4 the term ![]() in Eq. 13 can be rewritten as follows:
in Eq. 13 can be rewritten as follows:
| (15) |
Finally, combining Eq. 15 with Eq. 14 it is possible to state that:
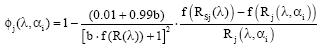 | (16) |
ANN based formulation: Let suppose that:
| • | An ANN has been structured as follows (Furferi and Carfagni, 2010): | |
| • | Three layers: input, hidden and output layer | |
| • | Hidden layer made of logistic neurons followed by an output layer of logistic neurons again | |
| • | 31 input, h hidden and 31 output units | |
| • | The ANN has been trained using, as input, the spectral responses of the colorants composing the shade and, as output, the spectral factors of the reference | |
| • | The training was performed using a back-propagation algorithm (Allen, 1980) until the MSE reach a value equal to, at least, 0.01 | |
Accordingly it is possible to define the following terms (Ghwanmeh et al., 2006):
| • | W1 (size n x 2n) and W2 (size 2n x 1), respectively, the weight matrices of the hidden and of the output layer of the trained ANN |
| • | b1 (size 1 x 2n) and b2 (size 1 x 1), respectively, the bias vector of the hidden layer and the scalar bias value of the output layer of the trained ANN |
| • | H, vector containing the 2 x n hidden neurons of the hidden layer of the ANN |
| • | F and G, transfer functions between, respectively, input and hidden layer and hidden and output layer (Bouzenada et al., 2007) |
| • | O (size 1 x 31), the output vector of the ANN |
| • | ε (size 1 x 31), the output error vector of the net |
As a result, for each wavelength in the range 400-700 nm it is possible to write the following equations:
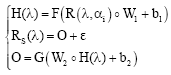 | (17) |
Finally it is possible to evaluate the spectral response RS(λ) given the n reflectance factors R(λ,αi) and the proportions αi:
| (18) |
From Eq. 17 it is possible to derive the expression for the transfer function φj (λ, αi):
| (19) |
Equation 18 demonstrates that the color recipe mapping depends upon the transfer functions F and G. If, for instance, both function may be considered linear and the term ε is neglected (being the network error, in a proper training this term tends to zero) it can be written:
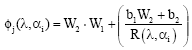 | (20) |
If G is linear and F is a log-sigmoid function (these functions are, typically, adopted for mapping functions with ANNs) and the term ε is neglected, Eq. 18 becomes:
| (21) |
RESULTS
The three formulations expressed by Eq. 12, 16 and 20 provide a mathematical assessment of the color recipe mapping on the basis of three different, well recognized, methods. On the basis of the results provided in scientific literature, each of the three formulas may be adopted under specific restriction and in a different field of application. In order to understand the differences between the proposed approaches, thus analyzing their performances an experimental test may be assessed.
In detail, 80 differently colored fabrics were collected during an extensive experimental campaign conducted in 2009 by the colourists working in the company New Mill S.p.A. of Prato, Italy. Each blend is composed by a certain number of raw materials each one characterized by a different color (e.g., by a different spectrophotometric response). In Table 1 three examples of the 30 fabrics chosen for validating the approach are listed.
The validation was carried out according to the following tasks:
| • | Spectrophotometric measurement of the colorants. |
| • | Evaluation of the transfer function by using equations 12, 16 and 20 respectively |
| • | Prediction of the transformed spectral reflectance factors of the blend |
| • | Measurement of CIE L*a*b* colour distance (DE CIEL*a*b*) between the predicted spectrophotometric response and the measured one (Mridula et al., 2008) |
The results of the whole validation, depicted in the last row of Table 2, shows that the color prediction, in terms of CIE L*a*b* colour distance, is less than 0.8 for all the three approaches. The K-M and the S-N based formulations prediction error, in terms of color distance, increase when the number of colorants is greater than 8. This can be easily viewed in Table 2: the mean values of the three approaches are quite similar for fabrics with Id.
| Table 1: | Three examples of the 30 fabrics chosen for validating the approach |
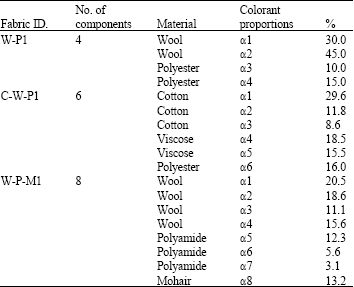 | |
| Table 2: | Results of the validation test. For each Fabric Id. The CIE L*a*b* colorimetric distance between the predicted values and the measured one is provided |
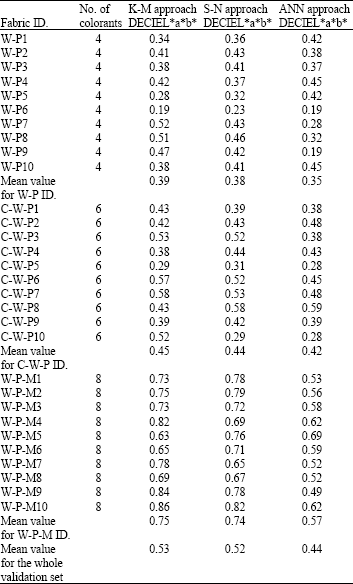 | |
W-P and C-W-P, whose shade is composed by 4 or 6 colorants.
In detail the K-M approach provides a prediction with a color distance averagely equal to 0.39 for 4 colorants and of 0.45 for 6 colorants. The S-N approach, considering a constant b equal to 0.15, provides a colour distance equal to 0.38 and to 0.44 for, respectively, 4 and 6 colorants. For fabrics composed by 8 materials (i.e., 8 colorants, having every material a different color) the color distances evaluated for the K-M and the S-N approaches are higher than the ANN based one. In detail the K-M and S-N based approaches provides value, respectively, of 0.75 and 0.74 while the ANN based approach give an average distance equal to 0.57. On the basis of this validation task, it is evident that the K-M and the S-N based approaches, proposed in the present work, may be adopted when the number of colorants is less than 6. Otherwise, the ANN based formulation may be considered more affordable.
DISCUSSION
Starting from the literature, the present paper provided in as-a-short-as-possible manner, three different mathematical formulations for performing the color matching. The provided equations, useful for establishing a functional mapping between colorant concentrations and spectrophotometric response of the reference shade, are, in particular, based on three widely known techniques: K-M, S-N and ANNs. On the basis of validation task and of literature analysis it may be affirmed that the K-M based equation (Eq. 12) is suitable for assessing the color recipe mapping of textiles, papers, wood, paints, inks and plastics once the absorption and scattering coefficients are evaluated. Accordingly, it requires a database to compute both Kλ and Sλ. Moreover, for materials such as textiles (where the colorants do not scatter in comparison to the substrate) the mixing equation is simplified (Eq. 3). The performance of this method is well established in literature since 1980 as demonstrated by Allen (1980), Nobbs (1997), Berns (2000) and Zhao and Berns (2009). Such researchers showed that the color prediction, in terms of CIE L*a*b* colour distance, is less than 0.8 and the maximum allowable number of colorants composing the desired shape is 6. This is in accordance with the validation task proposed in the present study.
The S-N based Eq. 16 provides good results for color recipe prediction of textile and woven fabrics. This mathematical formulation requires the determination of constant b (Yang and Miklaveic, 2005). Once properly defined such a constant, the S-N based equation provides results, in terms of CIE L*a*b* colour distance less than 0.8 with a maximum number of colorants equal to 5-6. The method has been developed for a higher number of components by Rong and Feng (2006) with good results: the maximum color difference was 4.48 CIE L*a*b* units and the average color difference was 1.02 CIE L*a*b* units for four-components fiber blends under D65 illuminant.
These results are in accordance with the one proposed in the present study. Anyway for different materials composing a fabric (e.g., a carded cloth) the constant value is hard to be computed; as a consequence this method is useful especially for textiles composed by a single, differently colored, material.
The ANN based approach (Eq. 19) that authors propose in this work may be, probably, suitable for assessing the color recipe mapping of papers, wood, paints, inks and plastics whose shade is composed by any number of colorants, accordingly to Darko et al. (2008). Moreover the approach is suitable also for shades composed by different materials (e.g., textiles composed by a mixture of wool, cotton, polyester etc.). Although, this approach does not need the assessment of constants or coefficients, it requires a training phase by means of a database of spectral responses. Once properly trained the ANN-based approach allows results, in terms of CIE L*a*b* colour distance, less than 0.8. Finally, while the training phase may be computationally expensive, the simulation phase, i.e., the determination of the transfer function, may be performed in few seconds. The authors aimed to provide such techniques into a mathematical form in order to help researchers and practitioners (colorists), to easily evaluate the color of a shade given the spectral factors of the colorants. Therefore, the authors want to encourage other researchers working in the field of colorimetry and spectrophotometry to provide a large number of results of their experimentations using the provided equations.
ACKNOWLEDGMENTS
The proposed approach is part of a FIT Project financed by the Italian Ministry of Economic Development. The project was conducted by the Department of Mechanical and Industrial Engineering of University of Florence (Italy) during the period 2007-2008. The devised method was applied in an important textile Company, New Mill S.p.A., working in Prato (Italy).
REFERENCES
- Allen, E., 1966. Basic equations used in computer color matching. J. Opt. Soc. Am., 56: 1256-1257.
CrossRef - Agahian, F., 2008. A new matching strategy: trial of the principal component coordinates. CRA, 33: 10-18.
CrossRef - Banyard, G.D., T. Cassidy, S. Westland and S.A. Grishanov, 2006. A comparison of various methods for establishing the relationship between structure and colour for fibre blends in yarn. Proceedings of the International Colour Association Interim Meeting: Colour in Culture and Colour in Fashion, Oct. 24-27, Johannesburg, South Africa, pp: 171-175.
- Bishop, J.M., M.J. Bushnell and S. Westland, 1991. Application of neural networks to computer recipe prediction. CRA, 16: 3-9.
CrossRef - Burlone, D.A., 1990. Effect of fiber translucency on the color of blends of precolored fibers. TRJ, 60: 162-167.
CrossRef - Darko, G., O.D. Parac and Z. Jure, 2008. Determination of pigment combinations for textile printing using artificial neural networks. Fibres Textiles Eastern Eur., 3: 93-98.
Direct Link - Furferi, R. and M. Carfagni, 2010. Prediction of the colour and of the colour solidity of a jigger-dyed cellulose-based fabric: A cascade neural network approach. Textile Res. J.
CrossRef - Furferi, R. and L. Governi, 2008. The recycling of wool clothes: An artificial neural network colour classification tool. IJAMT., 37: 722-731.
CrossRef - Kazmi, S.Z., P.L. Grady, G.N. Mock and G.L. Hodge, 1996. On-line color monitoring in continuous textile dyeing. ISA Trans., 35: 33-43.
CrossRef - Kubelka, P., 1954. New contributions to the optics of intensely light-scattering materials part II: Nonhomogeneous layers. JOSA, 44: 330-335.
CrossRefDirect Link - Philips-Invernizzi, B., D. Dupont and C. Caze, 2002. Formulation of colored fiber blends from Frieles theoretical model. CRA, 27: 191-198.
CrossRef - Rong, L.I. and G.U. Feng, 2006. Tristimulus algorithm of colour matching for precoloured fibre blends based on the Stearns-Noechel model. Coloration Technol., 122: 74-81.
CrossRef - Thompson, B. and M.J. Hammersley, 1978. Prediction of the colour of scoured-wool blends. J. Text. Inst., 69: 1-7.
CrossRef - Westland, S., J. Shaw and H. Owens, 2000. Colour statistics of natural and man-made surfaces. Sensor Rev., 20: 50-55.
CrossRef - Yang, L. and S.M. Miklavcic, 2005. Revised kubelka-munk theory: III. A general theory of light propagation in scattering and absorptive media. JOSA A, 22: 1866-1873.
CrossRef - Zhao, Y. and R.S. Berns, 2009. Predicting the spectral reflectance factor of translucent paints using Kubelka-Munk turbid media theory: Review and evaluation. CRA, 34: 417-431.
CrossRef - Mridula, D., R.K. Goyal and M.R. Manikantan, 2008. Effect of roasting on texture, colour and acceptability of pearl millet (Pennisetum glaucum) for making sattu. Int. J. Agric. Res., 3: 61-68.
CrossRefDirect Link - Ghwanmeh, S., R. Al-Shalabi, G. Kanan and L. Alnemi, 2006. Enhanced neural networks model based on a single layer linear counterpropagation for prediction and function approximation. Inform. Technol. J., 5: 45-50.
CrossRefDirect Link - Bouzenada, M., M.C. Batouche and Z. Telli, 2007. Neural network for object tracking. Inform. Technol. J., 6: 526-533.
CrossRefDirect Link