
H. Midi
Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia
Z.H. Zamzuri
School of Mathematical Sciences, Faculty of Science and Technology, Universiti Kebangsaan Malaysia, 43600 Bangi, Selangor, Malaysia
Journal of Applied Sciences
Year: 2010 | Volume: 10 | Issue: 18 | Page No.: 2101-2107







ABSTRACT
The commonly used Maximum Likelihood Estimator (MLE) to estimate the parameters of a time series model requires that the process is normally distributed. However, in real situations, many processes are not normal and have a heavy tail distribution. Hence, the aim of this study is to propose using a distribution free bootstrap method for parameter estimations, when the assumption of normality is not met. The performance of the Bootstrap Estimates (BE) and the MLE estimates of the AR (9) process were then investigated using the Malaysian Opening Price for Second Board data and simulation study. The empirical results indicate that the BE is reasonably close to the MLE estimates, hence, can be established as one reliable alternative approach to the MLE estimates.
PDF Abstract XML References Citation
Received: March 10, 2010;
Accepted: June 24, 2010;
Published: July 14, 2010
How to cite this article
H. Midi and Z.H. Zamzuri, 2010. The Performance of Bootstrapping Autoregressive AR (9) Process on the Malaysian Opening Price for Second Board. Journal of Applied Sciences, 10: 2101-2107.
DOI: 10.3923/jas.2010.2101.2107
URL: https://scialert.net/abstract/?doi=jas.2010.2101.2107
DOI: 10.3923/jas.2010.2101.2107
URL: https://scialert.net/abstract/?doi=jas.2010.2101.2107
INTRODUCTION
One important aspect in statistical inference is to acquire the standard errors of the parameter estimates and to construct the T-statistics and confidence intervals for the parameters of a model. The OLS and the MLE techniques are often used to estimate the parameters of a model. The construction of confidence intervals requires that the estimates can be treated as samples from a normal distribution. Nonetheless, many measurements are not normal. In this situation, we may use an alternative method such as the bootstrapping method, which is a distribution free method. There are a considerable amount of written papers relating the bootstrap method (Berkowitz and Kilian, 1997; Bickel and Freedman, 1983; Bose, 1988; Efron and Tibshirani, 1993; Efron and Tibshirani, 1986; Imon and Ali, 2005; Buhlmann, 2002; Hardle et al., 2001). The basic idea of bootstrapping method is to generate a large numbers of sub-samples by randomly drawing observations with replacement from the original dataset. These sub-samples are then being termed as bootstrap samples and are used to recalculate the estimates of the model parameters. This bootstrapping method, which was introduced by Efron (1979) and Brockwell and Davis (2002) has been increasingly popular because it has many interesting properties, for instance, its usage does not rely on the normality assumptions. It enjoys the advantage of not requiring any theoretical calculations to estimate the standard errors of any complicated model. These interesting properties of the bootstrap technique have to be traded off with computational cost and time.
There are two different ways of conducting bootstrapping; the random-x resampling and the fixed-x resampling, which is also referred as bootstrapping the residuals. Time series data is a dependent structured data, whereby they correlate to each other. This is the reason why only the residual bootstrapping technique is appropriate for the time series data. In the residuals bootstrapping technique, the residuals that are obtained from the MLE method are resampled to construct the pseudo time series observations. Bootstrap methods can be applied to many models such as the linear, nonlinear and time series models. Chatterjee (1986) applied bootstrap method on ARMA (p+q) process where he confined his simulation study to p+q≤2. The results of her study indicated that the standard errors of the bootstrap estimates were comparable to the MLE estimates. This result provided evident that the bootstrap estimates are reliable. The interesting properties of bootstrap method have motivated us to employ the bootstrap technique to the Malaysian Opening Price for Second Board data and simulation study.
In this study, the bootstrap technique was applied not only to get standard errors, but also to obtain the parameter estimates, bias, Root Mean Squared Errors (RMSE) and the forecasted estimates of the AR(9) process and then compared to the results of the MLE estimates.
MATERIALS AND METHODS
According to Brownstone and Kazimi (1998) and Efron and Tibshirani (1986), {Xt} is an AR (p) process if {Xt} is stationary and satisfies the Eq. 1.
| (1) |
where, Zt ~ WN (0, σ2) and Zt is uncorrelated with Xs for all s<t and |φ|<1.
For the Forecasting AR process, the h step predictors PnXn+h of an AR process for n > m = max (p, q) and h>1 is given by:
| (2) |
In this study, the MLE is used to estimate the parameters of the AR (9) process. In time series analysis, the fundamental assumption is stationary. Stationary implies that the mean of the data, μx(t) and the covariance between lag of time, γx(t+h, t) are independent of time. Once stationary was achieved, the next step was the model identification followed by the estimation of parameters. Then, the residual analysis was performed to validate the model and finally forecasting was conducted. Assuming that a data had been correctly identified as AR (9) process, the procedures of bootstrapping are as follows:
(1) | Fit in AR model to the stationary data. Order of AR had been identified from identification stage. The residuals, {Zt} and the estimates of parameters φi’s are obtained |
| (2) | Sample with replacement {Zt} to obtain the bootstrap residuals, {Zt*} |
(3) | Construct pseudo time series {Xt*} that being computed recursively based on this equation: |
| (3) |
For better understanding, the construction of pseudo time series are illustrated with example. Let us consider AR (4) process.
| (4) |
Therefore, begin with:
| (5) |
| (6) |
| (7) |
| (8) |
| (9) |
and so on. It can be observed that the pseudo time series {Xt*} contain three types of element. First, X5* constructed from true observations, {X4, X3, X2, X1}. Second type, X7* until X8* constructed from a mixture of true observations and elements from the pseudo series while the last type beginning from X9* uses elements from the pseudo series.
| (4) | Use the constructed {Xt*} to estimate φ1, φ2 and so on. Repeat step (2) and (3) for B times to generate B sets of parameter estimates. B is the number of replications needed in the bootstrapping algorithm |
The performance of the bootstrap estimates are evaluated based on the bias, standard errors and Root Mean Squared Error (RMSE). A good estimator is the one that has bias, standard errors and RMSE which are relatively small. The bootstrap estimates are obtained based on this equation:
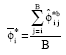 | (10) |
where i = 1, 2, 3,…,p; j = 1, 2, 3,…,B and the standard error,
The absolute bias and the Root Mean Square Error (RMSE) are, respectively given by ![]() and
and ![]() . The asterisk symbols shown in the text represent the values of the bootstrap samples or estimates. When the MLE and the BE of the AR(9) process were obtained, a comparison was made to identifiy whether they were reasonably close to each other and if so, how close the estimates were to the true value. The sample size effect was also evaluated. In this study, the data set was divided to different sizes which were 25, 50, 100 and 200. This was done for the purpose of evaluating whether sample sizes have any effect on the estimates.
. The asterisk symbols shown in the text represent the values of the bootstrap samples or estimates. When the MLE and the BE of the AR(9) process were obtained, a comparison was made to identifiy whether they were reasonably close to each other and if so, how close the estimates were to the true value. The sample size effect was also evaluated. In this study, the data set was divided to different sizes which were 25, 50, 100 and 200. This was done for the purpose of evaluating whether sample sizes have any effect on the estimates.
RESULTS
Numerical example: A numerical example is presented to investigate the performance of the bootstrap and the MLE estimates. A data set consists of 214 observations of the Malaysian Opening Price for Second Board (9) from 13th April 2005 to 24th February 2006, which was obtained from a downloader data base, is used in this study. Only 204 observations were used for model estimations (training data) while the other 10 observations were used for comparisons with the forecasted values of the MLE and the BE. Based on the AICC statistic, the AR (9) is identified as the best model because this model has the smallest AICC followed by the AR (4). The AICC for AR (9) = 398.07 and the AICC for AR (4) = 401.23. The MLE and the bootstrap method were then applied to the data. All computations were done using S-Plus programming language (S-PLUS® 8 Programmer’s Guide) except for the forcasted values, the ITSM 2000 (Brockwell and Davis, 1999, 2002) software were used.
Table 1 illustrates the results of the MLE estimates. The BE estimates are exhibited in Table 2. The results are for B = 100 and B = 400.
The sample size effect on the BE estimates is evaluated at various sample sizes ranging from 25 to 204 observations and is exhibited in Table 3.
The bootstrap method was performed repeatedly with this data by varying the number of B to determine a reasonable number of B, which adequately estimate the parameters of AR (9) process. The B value started at a minimum value of 10 and gradually increased to a maximum value of 1000. The standard error of the estimates for each B was computed to examine the stability of the estimates and the standard errors of the BE. Table 4 shows the parameter estimates and standard errors of the BE for various B.
Forecasted values: Here, the forecasted values of the MLE and the BE were compared to the true values, i.e., the last ten observations that were extracted from the data set. Table 5 displays the forecasted values, the 95% confidence interval of the forecasted values and also the absolute bias from MLE, BE with 100 replications and BE with 400 replications, respectively.
| Table 1: | The maximum likelihood estimates of the real data set |
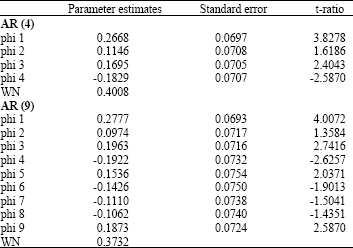 | |
| Table 2: | The bootstrap estimates of the real data set |
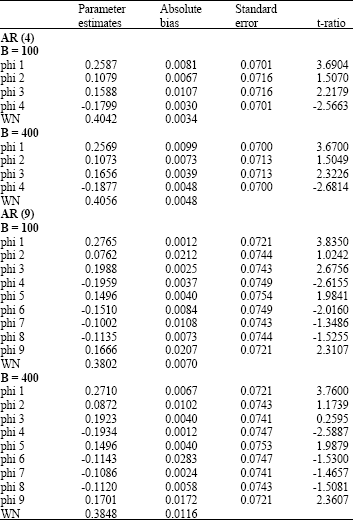 | |
Simulation study: Here, a simulation study was carried out to investigate whether the results of the simulation study confirm the conclusion of the real data set. Three sets of data from selected AR (9) processes were considered. For each data set, 200 observations were generated according to the following AR (9) processes;
| (11) |
| Table 3: | Absolute bias, standard error and RMSE of BE For various sample sizes of real data set |
 | |
| Table 4: | Parameter estimates and standard error of BE for various B |
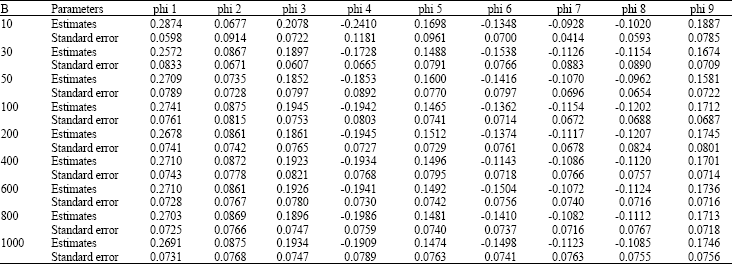 | |
| (12) |
| (13) |
where, {Zt} ~ WN (0,1). The MLE and the bootstrapping procedures were then applied to the data. All computations were done using S-Plus programming language. The three sets of simulated data were generated by using the built-in function in S-Plus, arima.sim. Only Eq. 11 results are presented in this discussion. Other results’ conclusions are consistent and are not presented due to space limitations.
Table 6 shows the results for the estimated parameters using the MLE and the BE compared to the true values of the parameters of Eq. 11 data set.
| Table 5: | Forecasted values, 95% confidence intervals and the absolute bias of the forecasted values |
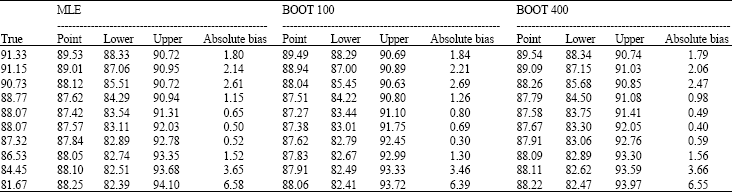 | |
| Table 6: | True value and parameter estimates of MLE and BE for Eq. 11 |
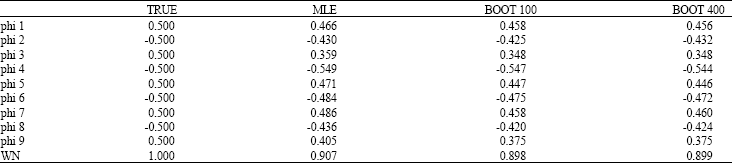 | |
| Table 7: | Absolute bias, standard error and RMSE of MLE and BE for various sample sizes for Eq. 1 |
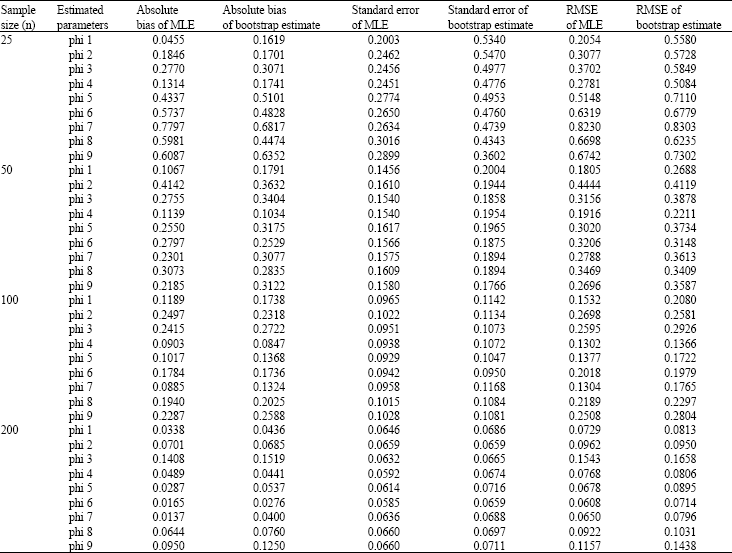 | |
The results are for B = 100 and B = 400. WN in the table represent the estimate of the White Noise variance of the process. White Noise is a process which is a sequence of uncorrelated random variable.
To investigate further the characteristic of the estimates, Table 7 presents the absolute bias, standard error and Root Mean Square Error (RMSE) of the BE and MLE estimates. In this table, there are 4 segmentations representing various sample sizes which are 25, 50, 100 and 200, for the purpose of evaluating the sample size effects on the parameters estimates.
DISCUSSION
We first focus our discussion on the results of the real examples. It can be observed from Table 1 and 2 that the parameter estimates, standard errors and t-ratios of the BE are reasonably closed to the MLE for both processes (AR(4) and AR(9)). This indicates that the BE gives estimates that are as good as the MLE. The results of Table 3 suggested that as the sample sizes increases, the absolute bias of the BE becomes smaller for all the parameters. It can be seen that the RMSE for almost all parameters estimates also show a decreasing pattern.
The results of Table 4 suggest that at B = 400, the values of the estimates and standard errors become almost consistent. Therefore, it is suggested that the number of replications needed in the bootstrapping algorithm to adequately give a fairly good estimate of the BE is equal to 400.
It can be observed from Table 5 that the forecasted values of the MLE and BE are quite similar with minor bias for some of the observations. The results signify that the BE with 400 replications give the smallest bias, followed by the MLE and BE with 100 replications. Thus, we can conclude that the BE forecasted values are as good as the MLE.
Just by observing the results of the real data, we cannot make a general conclusion yet, but a reasonable interpretation up to this stage is that all the BE parameter estimates that are considered in this example are reasonably close to the MLE.
It can be observed from Table 6 that the MLE and BE give close estimates to the true value of parameters in Eq. 11. The properties of these estimates can be seen clearly by observing Fig. 1. The results are consistent with the real data set, whereby the estimates of the BE are reasonably closed to the MLE.
From Table 7, we can observe that the absolute bias, standard error and RMSE for both MLE and BE are small and close to each other. We can see that the absolute bias has an inverse relationship with the sample sizes.
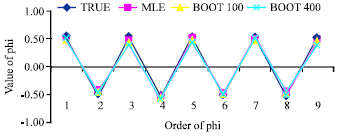 | |
| Fig. 1: | True value and Parameter Estimates of MLE and BE for Eq. 11 |
This is consistent with the results of the real data set which has signified an inverse relationship between absolute bias with the sample size. Both the MLE and the BE show quite similar pattern. However, the BE is slightly larger than the MLE but becomes closer to MLE as the sample size increases.
The same pattern (not shown) can be observed for the standard errors and RMSE of both estimates. The results indicate that the estimation will be more precise as the sample size gets larger. The standard errors of the MLE and the BE for all parameters are reasonably close to each other except for n = 25. This suggests that samples with size 25 might be too small to give a precise estimate. The RMSEs graphs of the MLE and the BE (not shown), also signify a decreasing pattern with respect to the sample sizes. As the sample size gets bigger, the RMSE of the MLE and the BE gets closer to each other.
The results of Eq. 12 and 13 were consistent with Eq. 11 but not reported here due to space limitations. To summarize, the simulation results indicate that the BE and the MLE are reasonably close to each other.
In the present findings, the values of the BE are reasonably closed to the MLE for both real data and simulation study.
CONCLUSIONS
The simulation study has shown that the bootstrap estimates are comparable to the MLE estimates of AR (9) process. The absolute bias, the standard error, the RMSE and the forecasted estimates of the BE are fairly close to the MLE. These estimates reveal a decreasing pattern as sample size increases. The results of the real data agree reasonably well with the results of the simulation study. The study also indicates that B = 400 is the most practical value of B that will give consistent parameter estimates and standard errors. Hence, we can conclude that the bootstrap method can be used as an alternative to estimate the parameters of AR (9) process.
REFERENCES
- Bose, 1988. Edgeworth correction by bootstrap in autoregression. Annal. Stat., 16: 1709-1722.
CrossRef - Efron, B. and R. Tibshirani, 1986. Bootstrap methods for standard errors, confidence intervals and other measures of statistical accuracy. Statist. Sci., 1: 54-75.
CrossRefDirect Link - Imon, A.H.M.R. and M.M. Ali, 2005. Bootstrapping regression residuals. J. Korean Data Inform. Sci. Soc., 16: 665-682.
Direct Link - Chatterjee, S., 1986. Bootstrapping ARMA models: Some simulations. IEEE Trans. Syst. Man Cybernet., 16: 294-298.
CrossRefDirect Link - Efron, B., 1979. Bootstrap methods: Another look at the jackknife. Ann. Stat., 7: 1-26.
CrossRefDirect Link