
A. Bagheri
Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia
Habshah Midi
Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia
A.H.M.R. Imon
Department of Mathematical Sciences, Ball State University, Muncie, IN 47306, USA
Journal of Applied Sciences
Year: 2010 | Volume: 10 | Issue: 18 | Page No.: 2086-2093







ABSTRACT
In this study, the effect of different patterns of high leverages on the classical multicollinearity diagnostics and collinearity-influential measure is investigated. Specifically the investigation is focus on in which situations do these points become collinearity-enhancing or collinearity-reducing observations. Both the empirical and the Monte Carlo simulation results, in collinear data sets indicate that when high leverages exist in just one explanatory variable or when the values of the high leverages are in different positions of the two explanatory variables, these points will be collinearity-reducing observations. On the other hand, these high leverages are collinearity-enhancing observations when their values and positions are the same for the two collinear explanatory variables.
PDF Abstract XML References Citation
Received: March 11, 2010;
Accepted: June 24, 2010;
Published: July 14, 2010
How to cite this article
A. Bagheri, Habshah Midi and A.H.M.R. Imon, 2010. The Effect of Collinearity-influential Observations on Collinear Data Set: A Monte Carlo Simulation Study. Journal of Applied Sciences, 10: 2086-2093.
DOI: 10.3923/jas.2010.2086.2093
URL: https://scialert.net/abstract/?doi=jas.2010.2086.2093
DOI: 10.3923/jas.2010.2086.2093
URL: https://scialert.net/abstract/?doi=jas.2010.2086.2093
INTRODUCTION
Nonorthogonality of explanatory variables or near-linear dependency between two or more explanatory variables is called Multicollinearity. The presence of Multicollinearity has some destructive effects on regression analysis such as prediction inferences and estimations. Consequently, the validity of parameter estimations becomes questionable (Montgomery et al., 2001; Kutner et al., 2004; Chatterjee and Hadi, 2006; Midi et al., 2010). Kamruzzaman and Imon (2002) and Montgomery et al. (2001) pointed out that there are different sources of multicollinearity such as the data collection method employed, constraints on the model or in the population being sampled, model specification such as adding polynomial terms to the regression model and an over determined model which is defined as a model with more explanatory variables than the number of observations. It is important to note that there is no statistical test for the presence of this problem in the data set. Therefore, a diagnostic method can be used to indicate the existence and extent of multicollinearity in a data set. Belsley et al. (1980) proposed Condition Number (CN) of X matrix as a very practical multicollinearity diagnostic method which may be obtained from the singular-value decomposition of the (nxp) X matrix. Belsley (1991) performed some experiments to discover whether the diagnostic methods could identify multicollinearity (or not) and which variables were also involved in the multicollinearity. He aimed to provide guidance on indication of the degree of multicollinearity in the data set. CN for X matrix between 10 and 30 has been recommended by him as an indicator of moderate multicollinearity while more than 30 results as severe multicollinearity. This was the first attempt to give meaning to the value of multicollinearity diagnostic. The author’s rule of thumb has been accepted as the standard in application. Many studies have been devoted to this issue (Mason and Perreault Jr., 1991; Rosen, 1999).
High leverage points, observations not only deviated from the same regression line as the other data but also fall far from the majority of explanatory variables in the data set (Hocking and Pendelton, 1983; Moller et al., 2005) can affect classical multicollineaity diagnostics methods. These points may be a new source of multicollinearity by the usage of classical multicollinearity diagnostics methods which have been introduced by Kamruzzaman and Imon (2002). According to Hadi (1988), the high leverage points or outliers in the X-direction may be collinearity-influential observations. He noted that the collinearity-influential observations are usually points with high leverages while all high leverage points are not collinearity-influential observations. It is worth mentioning that high leverage points can be collinearity- influential observations according to the classical multicollinearity diagnostics methods. Hadi (1988) defined a collinearity-influential measure based on condition number of X matrix. This measure not only suffers from defining a practical cutoff point but also the lack of symmetry which is due to the additive change in condition number of X matrix. Sengupta and Bhimasankaram (1997) pointed out the weakness of Hadi’s measure and proposed a new practical collineaity influential measure.
Yet, little attention has been devoted to the role of individual cases in collinearity of explanatory variables especially in the collinear data sets (Midi et al., 2010). Furthermore, there is a lack of investigation in the literature on high leverage points that cause multicollinearity problems.
It is necessary to study the effect of the high leverage collinearity-influential observations on the most applicable multicollinearity diagnostics such as the Collinearity-Influential Measure (CIM) and CN (Midi et al., 2010). In this way, we can investigate the change in degree of multicollinearity caused by the high leverage points in collinear data set. Unfortunately, there is no direct technique to investigate the effect of high leverage pints on collinearity pattern of a collinear data set. Insight is gained only by simulation experiences and by real data sets (Rosen, 1999; Midi et al., 2010).
Before proceeding to the simulation study, diagnostic methods of high leverage points will be reviewed briefly. Moreover, the effect of high leverage points in colinearity pattern of a real well-known collinear data set will be investigated. In addition, the Monte Carlo simulation study will be carried out to confirm the result of real data.
MATERIALS AND METHODS
Collinearity-influential measures: Let define a regression model as:
| (1) |
where, Y is an (nx1) vector of response or dependent variables, X is an (nxp) matrix of predictors, nxp, β is a (px1) vector of unknown finite parameters to be estimated and ε is an (nx1) vector of random errors. We let the jth column of the X matrix be denoted as Xj, therefore, X = [X1, X2,....,XP]. Additionally, we defined multicollinearity in terms of the linear dependence of the columns of X, i.e., whereby the vectors of X1, X2, …,Xp are linearly dependent if there is a set of constants t1, t2,…,tp, that are not all zero, such as:
| (2) |
We face severe multicollinearity problem, if Eq. 2 holds exactly. If Eq. 2 holds approximately, the problem of moderate multicollinearity is said to exist.
A very practical multicollinearity diagnostic method can be obtained from the singular-value decomposition of the (nxp) X matrix which has been proposed by Belsley et al. (1980). The X matrix can be decomposed as:
| (3) |
where, U is the (nxp) matrix in which the columns that are associated with the p non-zero eigen values of XTX are the eigenvectors, V is the (pxp) matrix of eigen vectors of, XTX, UTU = I, VTV = I and D is a (pxp) diagonal matrix with non-negative diagonal elements kj, j = 1,2,…,p which is called singular-values of X. Furthermore, they defined the condition indices of the X matrix as:
| (4) |
where, λ1, λ2,....,λp are the singular values of X matrix. It is noticeable that the largest value of kj can be defined as Condition Number (CN) of X matrix. The explanatory variables should be scaled to have the same length before calculating the condition indices to make them comparable from one data set to another. Moreover, scaling the independent variables prevents the eigen analysis of X matrix to be dependent on the variables units of measurements.
Furthermore, he defined a measure for the influence of the ith row of X matrix on the condition number as:
| (5) |
where, k(i) can be computed from the eigen values of X(i) when the ith row of X matrix has been deleted. Hadi specified that a large negative value of δi indicates that group i is a collinearity-enhancing observation while a large positive δi value indicates a collinearity-reducing set. Nevertheless, Hadi’s measure is not practical because he did not provide any cutoff points. The decision as to how large the value of δi should be, is solely depend on the researcher’s judgment on the magnitude of this value.
Sengupta and Bhimasankaram (1997) pointed out the weakness of Hadi’s measure is in the lack of symmetry, which is due to the additive change in k. To overcome this problem, they proposed:
| (6) |
As a Collinearity-Influential Measure (CIM) for each row of observations. Although Sengupta and Bhimasankaram (1997) didn’t propose any specific cutoff point for CIM, they introduced some easily computable lower bound and upper bound values for this new collinearity- influential measure. It is important to note that high leverage points can hide and induce multicollinearity pattern in two different situations: when ![]() then
then ![]() . In the first situation, the degree of multicollinearity increases due to the characteristics of high leverages which hide the multicollinearity pattern. Thus, the high leverage points are referred as collinearity-reducing observation. Otherwise, the deletion of high leverage points may reduce the degree of multicollinearity. Hence, in the second situation the high leverage points are referred as collinearity-enhancing observation.
. In the first situation, the degree of multicollinearity increases due to the characteristics of high leverages which hide the multicollinearity pattern. Thus, the high leverage points are referred as collinearity-reducing observation. Otherwise, the deletion of high leverage points may reduce the degree of multicollinearity. Hence, in the second situation the high leverage points are referred as collinearity-enhancing observation.
High leverage diagnostics methods: There are different types of outlier diagnostics methods for univriate and multivariate regression models (Belsley, 1991; Kutner et al., 2004; Wilcox, 2005). One of the practical outlyingness diagnostics methods can be defined as hat matrix. Hat matrix, which is traditionally used as a measure of leverage points in regression analysis, is defined as:
The most widely used cutoff point of the hat matrix is the twice-the-mean-rule (2k/n) by Hoaglin and Welsch (1978). However, Hadi (1992) explained that the hat matrix might fail to identify the high leverage points due to the effect of high leverage points in the leverage structure. So, he introduced another diagnostic tool as follows:
| (7) |
where, ![]() is the diagonal element of W and the ith, diagonal potential pii can be defined as
is the diagonal element of W and the ith, diagonal potential pii can be defined as ![]() where X(i) is the data matrix X without the ith row. He proposed a cutoff point for potential values pii as Median(pii) +c MAD(pii) (MAD-cutoff point) where is normalized Median Absolute Deviation defined by:
where X(i) is the data matrix X without the ith row. He proposed a cutoff point for potential values pii as Median(pii) +c MAD(pii) (MAD-cutoff point) where is normalized Median Absolute Deviation defined by:
and c can be taken as constant values of 2 or 3. Still, this method was unable to detect all of the high leverage points.
Imon (2002) introduced another diagnostic tool as generalized potentials for the whole data set, which is:
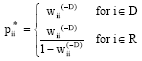 | (8) |
where, D is a deleted set, meaning any observations which is suspected as outliers and R is the remaining set from observations after deleting d<(n-p) therefore containing (n-d) cases. But, since there isn’t any finite upper bound for pii* ’s and the theoretical distribution of them are not easily found, he used a MAD-cutoff point for the generalized potential as well.
Habshah, Habshah et al. (2009) developed a Diagnostic Robust Generalized Potential (DRGP) to determine outlying points in multivariate data set by utilizing the Robust Mahalanobis Distance (RMD) based on Minimum Volume Ellipsoid (MVE) (Bagheri et al., 2009). We refer this method as the DRGP(MVE). The set D (deletion set) in generalized potentials method in Eq. 8 is defined basedon the points which RMD-MVE exceeds Median (RMD-MVE)+3MAD(RMD-MVE). Rousseeuw (1985) introduced RMD-MVE as:
| (9) |
where, TR(X) and CR(X) are robust locations and shape estimates of the MVE. Then, generalized potential statistics with the MAD-cutoff point has been utilized to check whether all members of the deletion set have potentially high leverage or not.
The merit of this method is in swamping less low leverages as high leverage points in the data set. Hence, this method has been utilized in the following chapter as a diagnostic method to define high leverage points.
RESULTS
Body fat data set: Here, the effect of high leverage points on a collinear data set which was introduced by Kutner et al. (2004) has been investigated. Body fat data set is a three explanatory variables data set with 20 observations. Triceps skinfold thickness (X1), thigh circumference (X2) and midarm circumference (X3) are its three explanatory variables. Kutner et al. (2004) mentioned that this data set has multicolinearity problem. Table 1 presents the high leverage points for the body fat data.
| Table 1: | High leverage diagnostics methods for body fat data set |
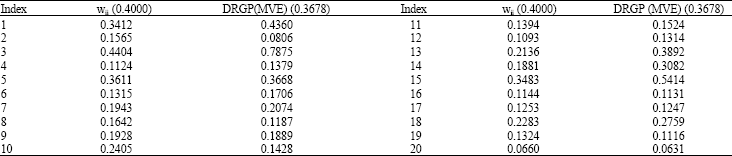 | |
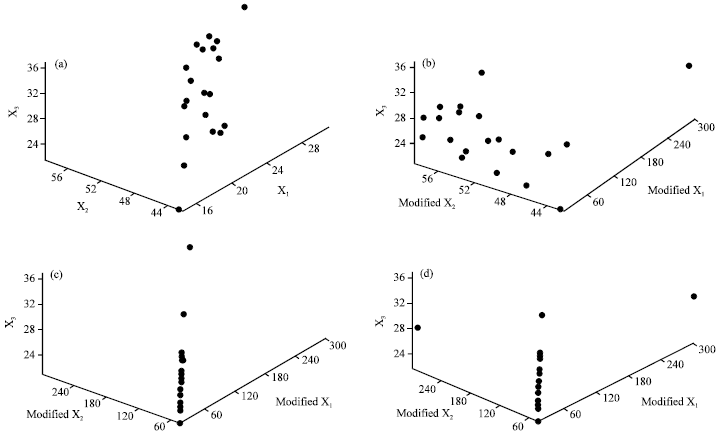 | |
| Fig. 1: | Scatter plot of original and modified body fat data set, (a) original data set, (b) modified X1, (c) modified X1 and X2 in the same positions and (d) modified X1 and X2 in different positions |
Here, the explanatory variables have been scaled to protect the condition number from being dominated by some large explanatory variables. Scaling will prevent the eigen analysis to be dependent on the variables units of measurements.
To compute the condition number of X matrix, the explanatory variables have been scaled following the scaling method by Stewart (1987), in the following form:
| (10) |
For alternative scaling methods one can refer to Stewart (1987) and Hadi (1988).
To study the effect of high leverage points on different collinearity patterns, the original collinear data is modified to have high leverage point just in one explanatory variable, the same values and positions of high leverage points in the two explanatory variables and the same value of high leverage points but in different positions of the two explanatory variables. The first collinearity pattern is created by replacing the first observation of the first explanatory variables with 300. In the second situation, the first observations of X1 and X2 are substituted with the same value equals to 300. Finally, in the third situation, the first observation of X1 and the last observation of X2 are replaced with 300. Figure 1 shows the matrix plot of the original and modified Body fat data set.
Table 2 and 3 exhibit the effect of high leverage points on the OLS estimates in the collinear Body fat data set.
| Table 2: | Parameter estimation for original and modified in X1 data set |
 | |
| Table 3: | Parameter estimation for modified in x1 and x2 in the same positions and modified in x1 and x2 in the different positions |
 | |
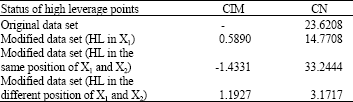
| Table 4: | The effect of different modification on collinearity-influential observation and condition No. for MC = 100 in body fat data set |
 | |
| HL: High leverages | |
Table 4 presents the effect of adding high leverage points on CN and CIM.
Monte Carlo simulation study: Here, we report a Monte Carlo simulation study that is designed to investigate the effect of different sample sizes and different magnitude and percentage of high leverage points on CIM in collinear data sets. Following the idea of Lawrence and Arthur (1990), three explanatory variables were generated as follows:
| (11) |
where, the X, Z are independent standard normal random numbers. The value of ρ2 represents the correlation between the two explanatory variables.
In the simulated data sets, the value of ρ2 was chosen to be equals to 0.95 which results in high collinearity between explanatory variables that created collinear data sets. Different percentage of high leverage points has been added to the explanatory variables. The level of high leverage points (α) is varied from zero to 25 % and four samples of size 20, 60, 100 and 300 were considered. The magnitude of high leverage points has been varied from 20, 50, 100 and 300.
| Table 5: | CN and CIM for different percentage and magnitude of high leverage points and n = 20 |
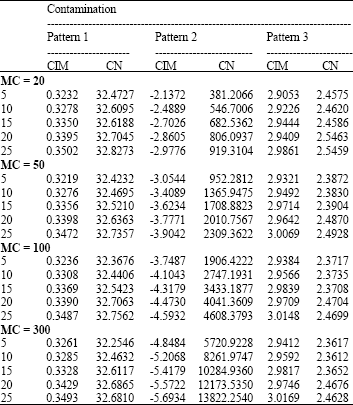 | |
| #: Percentage of high leverage points; MC: Magnitude of high leverage points; CIM: Collinearity-influential measure | |
Three different situations of adding high leverage points to the data set were carried out in the manner described earlier similar to the Body fat data example.
The first and the second contamination patterns were created by replacing the first 100% of the observations of X1 and the first 100% of the observations of X1 and X2 with certain magnitude of high leverage points, respectively.
| Table 6: | CN and CIM for different percentage and magnitude of high leverage points and n = 300 |
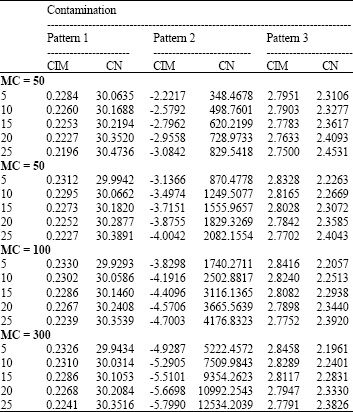 | |
| #: Percentage of high leverage points; MC: Magnitude of high leverage points; CIM: Collinearity-influential measure | |
The last pattern was generated by substituting certain magnitude of high leverage points to the first 100(α/2) percent observations of X1 and to the last 100 (α/2) percent observations of X2 to have high leverage points in different positions of these two explanatory variables. Moreover, to compute the values of CN for X matrix, the generated explanatory variables have been scaled according to equation of Eq. 11. In each simulation run, there were 10,000 replications.
The values of CN and CIM for the three contamination patterns, different magnitude of high leverage points and for small sample (n = 20) and large sample (n = 300) are displayed in Table 5 and 6, respectively.
DISCUSSION
The results that we have obtained in the previous section will be discussed in this section. At first we discuss the results of the numerical examples. The result of Table 1 pointed out that the hat matrix can detect case 3 while DRGP (MVE) indicates three more cases 1, 3 and 15 as high leverage points. To see the effect of these high leverage points on classical diagnostics methods, the CN of X matrix for with and without high leverage points have been calculated.
The CN of X matrix in the presence of high leverage points in the data set is equals to 23.6208. After these high leverage points (1, 3 and 15) are removed from the data set, the CN value is equals to 32.3298 which indicates that this data set has severe multicollinearity problem. This result also pointed out that the leverage points are not the cause of multicollinearity. They only reduce the degree of multicollinearity from severe to moderate.
According to the Fig. 1a, there is an obvious linear relationship between all three explanatory variables (Montgomery et al., 2001; Kutner et al., 2004). By adding high leverage points in just X1, the multicollinearity pattern of the X1 and X2 has been ruined (Fig. 1b) while by adding high leverage point to both X1 and X2 again multicollinearity appeared between these two explanatory variables (Fig. 1c). The plot of Fig. 1d seems to suggest that the multicollinearity pattern of the data is being masked.
If the high leverage points are added in different positions of the explanatory variables, Table 2 and 3 exhibit the effect of high leverage points on the OLS estimates in this collinear data set. It can be observed from Table 2 that when multicollinearity exists in this data set, the p-value of the F-test reveals that there is a linear relationship between the explanatory variables while none of the t-values of the explanatory variables are significant. This is another indicator of the presence of multicollinearity in this data set (Kutner et al., 2004; Chatterjee and Hadi, 2006). When modification is done only on X1, the F-test is still significant but again t-values of X1 and X3 are not significant. Several interesting points can be seen from Table 3. When modifying both X1 and X2 with the same values and positions, the F-value and all the t-values are significant. These results incorrectly indicate that there is no multicollinearity problem in the data where in fact multicollinearity exist. The reason for this misleading result is that the collinearity of the explanatory variables in this data set has been masked by the presence of the high leverage points in the same values and positions of both X1 and X2. In this study, the effect of different pattern of high leverage points on the classical multicollinearity diagnostics and collinearity- influential measure is investigated. On the other hand, in the situation when modification on X1 and X2 are with different positions, the F-test and all of the t-tests are not significant that indicates that there is no linear relationship between the dependent and independent variables in regression model of this data set. Thus the presence of high leverage points on the collinear data set, can sometimes hide or increase the significance of the t-test for parameter estimation of a regression model.
It can be observed from Table 4 that the value of CN of X matrix reveals the presence of moderate multicollinearity problem in the original data set.. It is worth mentioning that this data set suffers from severe multicollinearity (for comprehensive discussion method, refer to Kutner et al. (2004) according to the value of the Variance Inflation Factor (VIF). Since scaling is applied to the explanatory variables in the computation of CN of X matrix for this data set, it removes some of the ill-conditioning problem of the data set (Hadi, 1988; Montgomery et al., 2001; Midi et al., 2010). For the modification only on X1 or in different positions of X1 and X2, these high leverage points are collinearity reducing observations evident by the CIM values which become positive and the smaller values of CN compared with the CN value of the original data set. It is interesting to note that modifying X1 and X2 in the same position, cause these points to be collinearity enhancing observations evident by the negative value of CIM and the larger values of CN compared with the original data. It is worth mentioning that the value of CIM has been computed from in Eq. 7 where i is the observation with high leverage which influence the multicollinearity pattern of the data.
Finally, we discuss the results obtained from the simulations which carried out to investigate whether these results confirm the conclusion of the real data set. Due to space limitations, we do not show all the simulation results and the results for small sample (n = 20) and large sample (n = 300) have been presented. The other results are consistent. The values of CN for X matrix without high leverage points for sample sizes 20 and 300 are equal to 44.3979 and 37.7396, respectively which indicate the existence of severe multicollinearity problem in the simulated data sets. Let us focus our attention to Table 5 and 6 for the contamination pattern 1. The values of CN for contaminated data are smaller than the uncontaminated data. However, it still indicates severe multicollinearity problem. It is worth mentioning that for sample of size 300, at 5% high leverage points and magnitude of contaminations 50, 100 and 300, the values of CN are very close to 30. The positive values of CIM also confirm that when the high leverage points are in only one explanatory variable, they are collinearity- reducing observations for collinear data sets. Nonetheless, for the contamination pattern 3, the scenarios change dramatically. The added high leverage points in different positions of X1 and X2 cause the collinear simulated data sets to be non-collinear as exhibited by small values of CN and positive values of CIM. Thus, the added high leverage points according to contamination pattern 3 are collinearity-reducing observations. On the other hand, when high leverage points are added to the collinear data sets according to the contamination pattern 2, the values of the CN become much larger than the CN of the uncontaminated data. It is evident from Table 5 and 6 that these points become collinearity-enhancing as its CN and CIM values become large and negative large, respectively. Therefore, when the same values of high leverage points are added to the same positions of two explanatory variables for collinear data sets, they will increase the multicollinearity problem of the data sets.
CONCLUSIONS
The main focus of this study is to investigate the effect of different magnitude and different percentage of high leverage points on the Collinearity-Influential Measure (CIM) of a collinear data. This paper also attempts to investigate the effect of high leverage points on the OLS estimates of collinear explanatory variables. The numerical example and Monte Carlo simulation study reveal that high leverage points can induce or reduce the multicollinearity pattern of a collinear data set. Furthermore, sometimes the high leverage points and multicolinearity mask each other’s effects which lead researchers to rely on misleading results. To be high leverage collinearity-influential observations in collinear data set, the magnitude and percentage of high leverage points are essential factors, regardless of the sample size. The high leverage points, which exist in only one collinear explanatory variable, reduce the collinearity between these explanatory variables. The results also signify that when the same values of high leverage points are in the same positions for two collinear explanatory variables, by increasing the magnitude and the percentage of high leverage points, they increase the degree of collinearity among the explanatory variables. Moreover, when the same values of high leverage points are in different positions of the two collinear explanatory variables, these points reduced the collinearity between these explanatory variables.
REFERENCES
- Bagheri, A., H. Midi and A.H.M.R. Imon, 2009. Two-step robust diagnostic method for identification of multiple high leverage points. J. Math. Statist., 5: 97-106.
CrossRefDirect Link - Hadi, A.S., 1988. Diagnosing collineariy-influential observations. Comput. Statist. Data Anal., 7: 143-159.
CrossRef - Hadi, A.S., 1992. A new measure of overall potential influence in linear regression. Comput. Statist. Data Anal., 14: 1-27.
CrossRef - Hoaglin, D.C. and R.E. Welsch, 1978. The hat matrix in regression and ANOVA. Am. Statist. Assoc., 32: 17-22.
Direct Link - Hocking, R.R. and O.J. Pendelton, 1983. The regression dilemma. Comm. Stat. Theory Meth., 12: 497-527.
CrossRefDirect Link - Kamruzzaman, M. and A.H.M.R. Imon, 2002. High leverage point: Another source of multicollinearity. Pak. J. Statist., 18: 435-448.
Direct Link - Mason, C.H. and W.D. Perreault Jr., 1991. Collinearity, power and interpretation of multiple regression analysis. J. Market. Res., 28: 268-280.
Direct Link - Midi, H., A. Bagheri and A.H.M.R. Imon, 2010. The application of robust multicollinearity diagnostic method based on robust coefficient determination to a non-collinear data. J. Applied Sci., 10: 611-619.
CrossRef - Moller, S.F., J.V. Frese and R. Bro, 2005. Robust methods for multivariate data analysis. J. Chemometr., 19: 549-563.
CrossRef - Rousseeuw, P.J., 1985. Multivariate estimation with high breakdown point. Math. Statist. Appl., 13: 283-297.
Direct Link - Sengupta, D. and P. Bhimasankaram, 1997. On the roles of observations in collineariy in the linear model. J. Am. Stat. Assoc., 92: 1024-1032.
Direct Link - Stewart, G.W., 1987. Collinearity and least squares regression. Statist. Sci., 2: 68-84.
CrossRefDirect Link - Habshah, M., M.R. Norazan and A.H.M.R. Imon, 2009. The performance of diagnostic-robust generalized potentials for the identification of multiple high leverage points in linear regression. J. Applied Statist., 36: 507-520.
Direct Link