
M. Abomhara
Faculty of Computer Science and Information Technology, University of Malaysia,50603, Kuala Lumpur, Malaysia
O.O. Khalifa
Department of Electrical and Computer Engineering, Faculty of Engineering,International Islamic University Malaysia, 53100 Gombak, Kuala Lumpur, Malaysia
O. Zakaria
Faculty of Computer Science and Information Technology, University of Malaysia,50603, Kuala Lumpur, Malaysia
A.A. Zaidan
Faculty of Engineering, Multimedia University, 63100 Cyberjaya, Selangor Darul Ehsan, Malaysia
B.B. Zaidan
Faculty of Engineering, Multimedia University, 63100 Cyberjaya, Selangor Darul Ehsan, Malaysia
A. Rame
Faculty of Computer Science and Information Technology, University of Malaysia,50603, Kuala Lumpur, Malaysia
Journal of Applied Sciences
Year: 2010 | Volume: 10 | Issue: 16 | Page No.: 1834-1840







ABSTRACT
In this study, a new comparative study of video compression techniques was presented. Due to the rapid developments in internet technology and computers, popularity of video streaming applications is rapidly growing. Therefore today, storing and transmitting uncompressed raw video requires large storage space and network bandwidth. Special algorithms which take these characteristics of the video into account can compress the video with high compression ratios. This study demonstrates the representative efforts on video compression and presents the properties and limitations of: H.261, H.263, MPEG-1, MPEG-2, MPEG-4, MPEG-7 and H.264. However, we show that H.264 entails significant improvements in coding efficiency, latency, complexity and robustness. It provides new possibilities for creating better video encoders and decoders that provide higher quality video streams at maintained bit-rates (compared to previous standards), or, conversely, the same quality video at a lower bit-rate Hence, appropriate video compression techniques that meet video applications requirements have to be selected.
PDF Abstract XML References Citation
Received: January 28, 2010;
Accepted: April 04, 2010;
Published: June 26, 2010
How to cite this article
M. Abomhara, O.O. Khalifa, O. Zakaria, A.A. Zaidan, B.B. Zaidan and A. Rame, 2010. Video Compression Techniques: An Overview. Journal of Applied Sciences, 10: 1834-1840.
DOI: 10.3923/jas.2010.1834.1840
URL: https://scialert.net/abstract/?doi=jas.2010.1834.1840
DOI: 10.3923/jas.2010.1834.1840
URL: https://scialert.net/abstract/?doi=jas.2010.1834.1840
INTRODUCTION
Digital video communication is a rapidly developing field, especially with the progress made in video coding techniques. This progress has led to a high number of video applications, such as High-Definition Television (HDTV), videoconferencing and real-time video transmission over multimedia. Due to the advent of multimedia computing, the demand for these video has increased, their storage and manipulation in their raw form is very expensive and it significantly increases the transmission time and makes storage costly (Khalifa and Dlay, 1998). When an ordinary analog video sequence is digitized, it can consume up to 165 Mbps (Jeremiah, 2004; Sullivan and Wiegand, 2005; White Paper, 2008). With most surveillance applications infrequently having to share the network with other data intensive applications and data transfer of uncompressed video over digital networks requires very high bandwidth (Khalifa, 2003). To circumvent this problem, a series of techniques called video compression techniques have been derived to reduce the number of bits required to represent a digital Video data while maintaining an acceptable fidelity or Video quality. Their ability to perform this task is quantified by the compression ratio. The higher the compression ratio is the smaller the bandwidth consumption is.
Data compression is possible because images are extremely data intensive and contain a large amount of redundancy which can be removed by accomplishing some kind of transform, with a reversible linear phase to de-correlate the image data pixels (Khalifa and Dlay, 1998).
To understand the video formats, the characteristics of the video and how these characteristics are used in defining the format need to be understood. Video is a sequence of images which are displayed in order. Each of these images is called a frame. Since, we cannot notice small changes in the frames like a slight difference of colour, video compression standards do not encode all the details in the video; some of the details are actually lost (Abomhara et al., 2010). This is called lossy compression. It is possible to get very high compression ratios when lossy compression is used. Whereas there are some compressions techniques are reversible or non destructive compression (Haseeb and Khalifa, 2006). It is guaranteed that the decompression image is identical to the original image. This is an important requirement for some applications where’ high quality is demanded. This called lossless compression (Khalifa and Dlay, 1998, 1999). Typically, 30 frames are displayed on the screen every second. There will be lots of information repeated in the consecutive frames. If a tree is displayed for one second then 30 frames are used for that tree. This information can be used in the compression and the frames can be defined based upon previous frames. Frames can be compressed using only the information in that frame (intraframe) or using information in other frames as well (intraframe). Intraframe coding allows random access operations like fast forwarding and provides fault tolerance. If a part of a frame is lost, the next intraframe and the frames after that can be displayed because they only depend on the intraframe. Every color can be represented as a combination of red, green and blue. Images can also be represented using this colour space. However, this colour space called RGB is not suitable for compression since it does not consider the perception of humans.
However, the human eye is more sensitive to changes is Y which is part of the YUV colour space where only Y gives the greyscale image. Thus this is used in compression. The Compression ratio is the ratio of the size of the original video to the size of the compressed video. To get better compression ratios pixels are predicted based on other pixels. In spatial prediction, a pixel can be obtained from pixels of the same image while in temporal prediction; the prediction of a pixel is obtained from a previously transmitted image. Hybrid coding is applied if a prediction in the temporal dimension with a suitable decorrelation technique in the spatial domain is used. Motion compensation establishes a correspondence between elements of nearby images in the video sequence. The main application of motion compensation is providing a useful prediction for a given image from a reference image.
DCT (Discrete Cosine Transform) is used in almost all of the standardized video coding algorithms. The DCT is typically done on each 8x8 block (Xiang-Wei et al., 2008, 2009). When DCT is performed, the top left corner has the highest coefficients and the bottom right has the lowest thus making compression easier (Ali, 1999). The coefficients are numbered in a zigzag order from the top left to the bottom right so that there will be many small coefficients at the end. The DCT coefficients are then divided by the integer quantization value to reduce precision. After this division it is possible to lose the lower coefficients if they are much smaller than the quantization.
VIDEO COMPRESSION/DECOMPRESSION TECHNIQUES
When used to convey multimedia transmissions, video streams contain a huge amount of data that requires a large bandwidth and subsequent storage space. As a result of the huge bandwidth and storage requirements, digital video is compressed in order to reduce its storage or transmitting capacity. This technology (video compression) reduces redundancies in spatial and temporal directions. Spatial reduction physically reduces the size of the video data by selectively discarding up to a fourth or more of unneeded parts of the original data in a frame. Temporal reduction, Inter-frame delta compression or motion compression, significantly reduces the amount of data needed to store a video frame by encoding only the pixels that change between consecutive frames in a sequence. Several important standards like Moving Picture Experts Group (MPEG) standard, H.261, 263 and 264 standards are the most commonly used techniques for video compression.
H.261: It was developed in 1990 by the International Telecommunication Union (ITU) developed the H.261 standard for data rates that are multiples of 64 Kbps. H.261 standard uses motion compensated temporal prediction. It supports two resolutions, namely, Common Interface Format (CIF) with a frame size of 352x288 and quarter CIF (QCIF) with a frame size of 172x144 (Girod et al., 1995; Roden, 1996; Choi et al., 1998). The coding algorithm is a hybrid of the following:
Inter-picture prediction: It removes temporal redundancy transform coding, removes spatial redundancy motion compensation and uses motion vectors to compensate.
A macro block, the basic unit of temporal coding, is used to represent a 16x16 pixel region. Each macro block is encoded using intra (I-coding) or predictive) P-coding. Motion prediction uses only the previous picture to minimize delay (Marcel et al., 1997). H.261 is intended for carrying video over ISDN in teleconferencing applications such as videoconferencing and videophone conversations. H.261 is not suitable for usage in general digital video coding.
H.263: It was developed by the International Telecommunication Union (ITU) in 1996. It uses an encoding algorithm called test model (TMN), which is similar to that used by H.261 but with improved performance and error recovery leading to higher efficiency. It is optimized for coding at low bit rates (Nilsson and Naylor, 2003; Raja and Mirza, 2004). H.263 provides the same quality as H.261 but with half the number of bits. A block motion-compensated structure is used for encoding each picture into macroblocks (Ashraf and Chong, 1997). The functionality of H.263 is enhanced by features like: bi-directionally encoded B-frames, overlapped-block motion compensation on 8x8 blocks instead of 16x16 macroblocks, unrestricted motion vector range outside the picture boundary, arithmetic encoding and fractional-pixel motion-vector accuracy (Rijkse, 1996). H.263 supports three other resolutions in addition to QCIF and CIF:
| • | SQCIF: Approximately half the resolution of QCIF |
| • | 4CIF and 16CIF: 4 and 16 times the resolution of CIF |
H.263 is like H.261, is not suitable for usage in general digital video coding. However, H.261 and 263 are a bit contradictory since they both lack some of the more advanced techniques to really provide efficient bandwidth use (Girod et al., 1995; Ashraf and Chong, 1997).
H.263+: It is an extension of H.263 with higher efficiency, improved error resilience and reduced delay. It allows negotiable additional modes, spatial and temporal scalability (Berna et al., 1998; Raja and Mirza, 2004). H.263+ has enhanced features like:
| • | Reference picture re-sampling motion compensation and picture prediction |
| • | Reduced resolution update mode that permits a high frame rate during rapid motion |
| • | Independent segment decoding mode that prevents the propagation of errors from corrupt frames |
| • | Modified quantization mode improves bit rate control by controlling step size to detect errors and reduce decoding complexity |
MPEG-1: The first public standard for the Moving Picture Experts Group (MPEG) committee was the MPEG-1. MPEG-1 was approved in November 1991 and its first parts were released in 1993 (Morris, 1995). It has no direct provision for interlaced video applications (Sikora, 1999) (Roden, 1996). MPEG frames are encoded in three different ways (White Paper, 2008):
| • | Intra-coded (I-frames): Encoded as discrete frames (still frames), independent of adjacent frames |
| • | Predictive-coded (P-frames): Encoded by prediction from a past I-frame or P-frame, resulting in a better compression ratio (smaller frame) |
| • | Bi-directional-predictive-coded (B-frame): Encoded by prediction using a previous and a future frame of either I-frames or P-frames; offer the highest degree of compression |
MPEG-1 decoding can be done in real time using a 350 MHz Pentium processor. It is also suitable for playback from CD-ROM (Ali, 1999).
MPEG-2: The MPEG-2 project was approved in November 1994, focused on extending the compression technique of MPEG-1 to cover larger pictures and higher quality at the expense of higher bandwidth usage. MPEG-2 is designed for digital television broadcasting applications that require a bit rate typically between 4 and 15 Mbps (up to 100 Mbps), such as Digital high definition TV (HDTV), Interactive Storage Media (ISM) and cable TV (CATV) (Sikora, 1997; Ali, 1999). Profiles and levels were introduced in MPEG-2 (Morris, 1995). The profile defines the bit-stream scalability and the color space resolution. With scalability, it is possible to extract a lower bit stream to get a lower resolution or frame rate. The level defines the image resolution, the Y (Luminance) samples/sec, the number of video and audio layers for scalable profiles and the maximum bit-rate per profile. The MPEG compatibilities include upward (decode from lower resolution), downward (decode from higher resolution), forward (decode from previous generation encoding) and backward (decode from new generation encoding). The MPEG-2 input data is interlaced making it compatible with the television scanning pattern that is interlaced.
The MPEG-2 is suitable for TV broadcast applications and high-quality archiving applications. It is not however designed for the internet, as it requires too much bandwidth (Puri et al., 2004).
MPEG-4: It was approved in October 1998 and it enables multimedia in low bit-rate networks and allows the user to interact with the objects (Puri and Eleftheriadis, 1998; (ISO/IEC JTC1/SC29/WG11 N4668, 2002). The objects represent aural, visual or audiovisual content that can be synthetic like interactive graphics applications or natural like in digital television. These objects can then be combined to form compound objects and multiplexed and synchronized to provide QoS during transmission. Media objects can be in any place in the coordinate system. Streamed data can be applied to media objects to change their attributes (Nemcic et al., 2007).
The MPEG-4 compression methods are used for texture mapping of 2-D and 3-D meshes, compression of time-varying streams and algorithms for spatial, temporal and quality scalability, images and video. Scalability is required for video transmission over heterogeneous networks so that the receiver obtains a full resolution display. The MPEG-4 provides a high coding efficiency for storage and transmission of audio-visual data at very low bit-rates (Ali, 1999). About 5-64 Kbps is used for mobile or PSTN video applications and up to 2 Mbps for TV/film applications (Puri et al., 2004).
MPEG-7: It was approved in July 2001 (Chang et al., 2001) to standardize a language to specify description schemes. The MPEG-7 is a different kind of standard as it is a multimedia content description standard and does not deal with the actual encoding of moving pictures and audio. With MPEG- 7, the content of the video is described and associated with the content itself, for example to allow fast and efficient searching in the material.
The MPEG-7 uses XML to store metadata and it can be attached to a timecode in order to tag particular events in a stream. Although, MPEG-7 is independent of the actual encoding technique of the multimedia, the representation that is defined within MPEG-4, i.e., the representation of audio-visual data in terms of objects, is very well suited to the MPEG-7 standard. The MPEG-7 is relevant for video surveillance since it could be used for example to tag the contents and events of video streams for more intelligent processing in video management software or video analytics applications (Avaro and Salembier, 2001; Martinez, 2002).
H.264/AVC: In early 1998, the Video Coding Experts Group (VCEG) ITU-T issued a call for proposals on a project called H.26L, with a target of doubling the coding efficiency in comparison to any other existing video coding standards for various applications. The Moving Picture Expert Group (MPEG) and the Video Coding Expert Group (VCEG) have developed a new and outstanding standard that promises to outperform the earlier MPEG-4 and H.263 standard. Even though the first draft design for the new standard was adopted in October 1999, it provides the most current balance between the coding efficiency, cost and implementation complexity. It has been finalized by the Joint Video Team (JVT) as the draft of the new coding standard for formal approval submission referred to as H.264/AVC and was approved by ITU-T in March 2003 (known also as MPEG-4 part 10) (Wiegand et al., 2003; Nukhet and Turhan, 2005; Jian-Wen et al., 2006). The standard is further designed to give lower latency as well as better quality for higher latency. In addition, all these improvements compared to previous standards were to come without increasing the complexity of design so much that it would be impractical or expensive to build applications and systems. An additional goal was to provide enough flexibility to allow the standard to be applied to a wide variety of applications: for both low and high bit rates, for low and high resolution video and with high and low demands on latency. The main features that improve coding efficiency are the following (Ostermann et al., 2004):
| • | Variable block-size motion compensation with the block size as small as 4x4 pixels |
| • | Quarter-sample motion vector accuracy |
| • | Motion vectors over picture boundaries |
| • | Multiple reference picture motion compensation |
| • | In-the-loop deblocking filtering |
| • | Small block-size transformation (4x4 block transform) |
| • | Enhanced entropy coding methods (Context- Adaptive Variable-Length Coding (CAVLC) and Context Adaptive Binary Arithmetic Coding (CABAC)) |
COMPARISON OF VIDEO COMPRESSION METHODS
Video compression standards provide a number of benefits, of which the foremost is ensuring interoperability, or communication between encoders and decoders made by different people or different companies. In this way standards lower the risk for both consumer and manufacturer and this can lead to quicker acceptance and widespread use. In addition, these standards are designed for a large variety of applications and the resulting economies of scale lead to reduced cost and further widespread use. The well known families of video compression standards, are shown in Table 1 (Current and Emerging Video Compression Standards) performed under the auspices of the International Telecommunications Union-Telecommunications (ITU-T, formerly the International Telegraph and Telephone Consultative Committee, CCITT), the International Organization for Standardization (ISO) and the Moving Pictures Expert Group (MPEG) which was established by the ISO in 1988 to develop a standard for compressing moving pictures (video) and associated audio on digital storage media. The first video compression standard to gain widespread acceptance was the H.261 standard. The H.261 and 263 standards are suitable for carrying video over ISDN. They are used for video delivery over low bandwidths (Marcel et al., 1997). The MPEG standards provide a range of compression formats that are suitable for applications that require higher bit rates. The MPEG-1 provides compression for standard VHS quality video compression.
| Table 1: | Current and emerging video compression standards |
 | |
| Table 2: | Comparison of main coding tools in MPEG-2, MPEG-4 Part 2 and H.264/ AVC (Puri et al., 2004) |
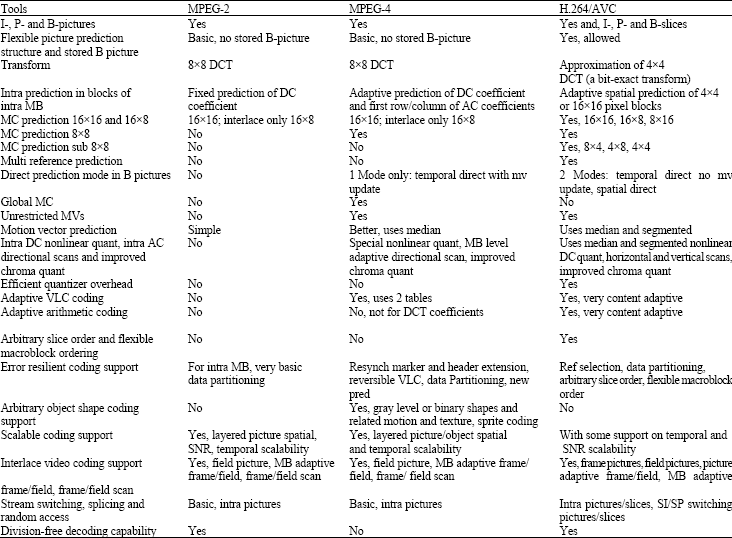 | |
The MPEG-2 meets the requirements of applications with bit rates up to 100 Mbps and can easily cater for digital television broadcasting applications. MPEG-1 and 2 are used for broadcast and CD-ROM applications, but unsuitable for the Internet (Jane et al., 1997; Ali, 1999; White Paper, 2008). The MPEG-4 is suitable for low bit-rate applications such as video conferencing as it provides a high coding efficiency for storage and transmission. The MPEG-4 applications include Internet multimedia, interactive video, video conferencing, videophone, wireless multimedia and database services over ATM networks. H.263 and MPEG-4 are used for video delivery over low bandwidths. To cater for the high bandwidth requirements for the Internet, codes must have high bandwidth scalability, lower complexity and tolerance to losses, as well as lower latency for interactive applications. MPEG-7 addresses this problem as it caters for both real-time and non-real time applications and enables retrieval of multimedia data files from the Internet. If the available network bandwidth is limited, or if a video is to be recorded at a high frame rate and there are storage space restraints, MPEG may be the preferred option. It provides a relatively high image quality at a lower bit-rate (bandwidth usage). Still, the lower bandwidth demands come at the cost of higher complexity in encoding and decoding, which in turn contributes to a higher latency when compared to motion H.264/AVC (Sullivan et al., 2004). H.264/AVC is now a widely adopted standard and represents the first time that the ITU, ISO and IEC have come together on a common, international standard for video compression. H.264 entails significant improvements in coding efficiency, latency, complexity and robustness. It provides new possibilities for creating better video encoders and decoders that provide higher quality video streams at maintained bit-rates (compared to previous standards), or, conversely, the same quality video at a lower bit-rate. Table 2 shows a comparison of the main coding tools in MPEG-2, MPEG-4 Part 2 and H.264/ AVC.
CONCLUSIONS
Video compression is gaining popularity since storage and network bandwidth requirements are able to be reduced with compression. Many algorithms for video compression which are designed with a different target in mind have been proposed. This study explained the standardization efforts for video compression such as H.261, 263 and 263+, MPEG-1, 2, 4, 7 and H.264. Most recent efforts on video compression for video have focused on scalable video coding. The primary objectives of on-going research on scalable video coding are to achieve high compression efficiency high flexibility (bandwidth scalability) and/or low complexity. Due to the conflicting nature of efficiency, flexibility and complexity, each scalable video coding scheme seeks tradeoffs on the three factors. Designers of video services need to choose an appropriate scalable video coding scheme, which meets the target efficiency and flexibility at an affordable cost and complexity.
REFERENCES
- Abomhara, M., O. Zakaria, O.O. Khalifa, A.A. Zaidan and B.B. Zaidan, 2010. Enhancing selective encryption for H.264/AVC using advance encryption standard. Int. J. Comput. Electr. Eng., 2: 1793-8201.
Direct Link - Ashraf, G. and M.N. Chong, 1997. Performance analysis of H.261 and H.263 video coding algorithms. Proceedings of the 1997 IEEE International Symposium on Consumer Electronics, Dec. 2-4, Sch. of Applied Science, Nanyang Technology Institute, pp: 153-156.
CrossRef - Puri, A. and A. Eleftheriadis, 1998. MPEG-4: An object-based multimedia coding standard supporting mobile applications. Mobile Networks Applications, 3: 5-32.
Direct Link - Puri, A., X. Chen and A. Luthra, 2004. Video coding using the H.264/MPEG-4 AVC compression standard. Signal Process. Image Commun., 19: 793-849.
CrossRef - Berna, E., G. Michael, C. Guy and K. Faouzi, 1998. The H.263+ video coding standard: Complexity and performance. Proceedings of the Data Compression Conference, March 30-April 01, University of British Columbia, pp: 259-268.
Direct Link - Girod, B., E. Steinbach, N. F�rber, E. Steinbach and N. Farber, 1995. Comparison of the H.263 and H.261 video compression standards. SPIE Proc. Standards Common Interfaces Video Inform. Syst., CR60: 233-251.
Direct Link - Chang, S.F., T. Sikora and A, Purl, 2001. Overview of the MPEG-7 standard. IEEE. Trans. Circ. Syst. Video Technol., 11: 688-695.
CrossRef - Raja, G. and M.J. Mirza, 2004. Performance comparison of advanced video coding h.264 standard with baseline H.263 and H.263+ standards. IEEE Int. Symp. Commun. Inform. Technol., 2: 743-746.
Direct Link - Jeremiah, G., 2004. Comparing media codecs for video content. Proceedings of the Embedded Systems Conference, (ESC`04), San Francisco, pp: 1-18.
Direct Link - Jian-Wen, C., K. Chao-Yang and L. Youn-Long, 2006. Introduction to H.264 advanced video coding. Proceedings of the Asia and South Pacific Conference on Design Automation, Jan. 24-27, IEEE Press Piscataway, New Jersey, USA., pp: 736-741.
Direct Link - Rijkse, K., 1996. H.263: Video coding for low-bit-rate communication. IEEE Commun. Manage., 34: 42-45.
Direct Link - Khalifa, O.O., 2003. Image data compression in wavelet transform domain using modified LBG algorithm. ACM Int. Conf. Proc. Ser., 49: 88-93.
Direct Link - Khalifa, O.O. and S.S. Dlay, 1999. Medical image lossless compression for transmission of cross limited bandwidth channels. Proc. SPIE., 3662: 342-348.
Direct Link - Nilsson, M. and M. Naylor, 2003. Comparison of H.263 and H.26L video compression performance with web-cams. Electronics Lett., 39: 277-278.
CrossRefDirect Link - Morris, O., 1995. MPEG-2: where did it come from and what is it?. Proceedings of the IEE Colloquium on MPEG-2- What it is and What it isn`t, Jan. 24, London, pp: 1-5.
Direct Link - Nukhet, O. and T. Turhan, 2005. A survey on the H.264/AVC standard. Turk. J. Electrical Eng. 13: 287-302.
Direct Link - Ostermann, J., J. Bormans, L. Peter, M. Detlev, N. Matthias and P. Fernando, et al., 2004. Video coding with H.264/AVC: Tools, performance and complexity. IEEE Circuits Syst. Magazine, 4: 7-28.
Direct Link - Roden, T.V., 1996. H.261 and MPEG1-a comparison. Proceedings of the IEEE 15th Annual International Conference, March 27-29, Phoenix, pp: 65-71.
CrossRef - Haseeb, S. and O.O. Khalifa, 2006. Comparative performance analysis of image compression by JPEG 2000: A case study on medical images. Inform. Technol. J., 5: 35-39.
CrossRefDirect Link - Sikora, T., 1999. Digital Video Coding Standards and Their Role in Video Communications. In: Signal Processing for Multimedia, Byrnes, J.S. (Ed.). IOS Press, USA., pp: 225.
Direct Link - Sullivan, G.J. and T. Wiegand, 2005. Video compression - from concepts to the H.264/AVC standard. Proc. IEEE, 93: 18-31.
CrossRefDirect Link - Sikora, T., 1997. MPEG digital video-coding standards. MPEG Digital Video-Coding Standards, 14: 82-100.
CrossRef - Wiegand, T., G.J. Sullivan, G. Bjontegaard and A. Luthra, 2003. Overview of the H.264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol., 13: 560-576.
CrossRefDirect Link - Xiang-Wei, L., L. Zhan-Ming, Z. Ming-Xin, W. Zhe and Z. Guo-Quan, 2008. A novel rough sets based key frame extraction algorithm in compressed-domain. Inform. Technol. J., 7: 1043-1048.
CrossRefDirect Link - Xiang-Wei, L., L. Zhan-Ming, Z. Ming-Xin, Z. Ya-Lln and W. Wei-Yi, 2009. Rapid shot boundary detection algorithm based on rough sets in video compressed domain. Res. J. Inform. Technol., 1: 70-78.
CrossRefDirect Link