
A. Lennie
Faculty of Engineering and Built Environment, Universiti Kebangsaan Malaysia, 43600 UKM Bangi, Selangor, Malaysia
S. Abdullah
Faculty of Engineering and Built Environment, Universiti Kebangsaan Malaysia, 43600 UKM Bangi, Selangor, Malaysia
Z.M. Nopiah
Faculty of Engineering and Built Environment, Universiti Kebangsaan Malaysia, 43600 UKM Bangi, Selangor, Malaysia
M.N. Baharin
Faculty of Engineering and Built Environment, Universiti Kebangsaan Malaysia, 43600 UKM Bangi, Selangor, Malaysia
Journal of Applied Sciences
Year: 2010 | Volume: 10 | Issue: 16 | Page No.: 1714-1722







ABSTRACT
This study presents an analysis on variable amplitude loading strains data by using amplitude probability distribution function, power spectral density function and cross correlation function techniques. The objectives of this study are to observe the capability of these techniques in investigating the time series behaviour in terms of distribution and statistical values and also detecting the similarity of pattern signal. In this study, the data consisting of non-stationary variable amplitude loading strains data exhibiting a random behaviour was used as a set of case study. This random data was collected on the lower suspension arm of an automobile component travelling on pavé and highway route. The data was repetitively measured for 60 sec at the sampling rate of 500 Hz, which provided 30,000 discrete data points. The collected data was then calculated and analysed for the signal distribution, statistics parameter and cross correlation values. Higher calculated cross correlation values were then selected to analyse fatigue damage prediction. From amplitude probability distribution function and power spectral density function diagrams, the result can be concluded that the non-Gaussian distribution can be related to a broad band signal, while for Gaussian distribution for a narrow band signal. The findings from this study are expected to be used in determining the pattern behavior that exists in VA signals.
PDF Abstract XML References Citation
Received: March 08, 2010;
Accepted: May 19, 2010;
Published: June 26, 2010
How to cite this article
A. Lennie, S. Abdullah, Z.M. Nopiah and M.N. Baharin, 2010. Behavioural Investigation of Fatigue Time Series using the Statistical Approach. Journal of Applied Sciences, 10: 1714-1722.
DOI: 10.3923/jas.2010.1714.1722
URL: https://scialert.net/abstract/?doi=jas.2010.1714.1722
DOI: 10.3923/jas.2010.1714.1722
URL: https://scialert.net/abstract/?doi=jas.2010.1714.1722
INTRODUCTION
A time series is a set of observation xt, each one being recorded at a specified time t (Brockwell and Davis, 1991). In statistics and signal processing, a time series is a sequence of data points, measured typically at successive times spaced at uniform time intervals (Pollock, 1999). Methods for time series analysis may be divided into two classes: frequency-domain methods and time-domain methods. The time domain method is suitable for simple structures where only a few hot spots need to be investigated (Wang and Sun, 2005). Fatigue analysis of such structures generally use frequency domain methods. In the frequency domain, fatigue life is calculated from the Power Spectral Density (PSD) of the stress response. Frequency-domain methods include spectral analysis and recently wavelet analysis; time-domain approaches include auto-correlation and cross-correlation analysis.
Fatigue life prediction is important in the design process of vehicle structural components and involves a set of observations of a variable taken at equally spaced intervals of time (Anderson, 1996). Since fatigue is one of the major causes in vehicle component failure, its life prediction or fatigue damage has become a subject of discussion in many texts (Nadot and Denier, 2004). Svenssona et al. (2005) conducted fatigue life prediction based on variable amplitude test-specific applications, while Rahman et al. (2009) conducted the fatigue life behaviour of an Aluminium alloys suspension arm using the strain-life approach. The strain-life (ε-N) approach was used for this analysis as the case study related to low cycle fatigue, which is a suitable approach to analyze random data collected from automotive components.
This study discusses some issues related to the analysis on VA loading strains data behaviour of a lower suspension arm by using amplitude Probability Distribution Function (PDF), Power Spectral Density (PSD) function and the signal statistical parameters which are included the mean, the Root-Mean-Square (RMS), the skewness and the kurtosis values. The signal cross correlation value was then calculated using the Cross Correlation Function (CCF) to determine the similarity of the two signals pattern. Finally, the fatigue life analysis was taken using three models of strain-life method which are Coffin-Manson, Morrow and Smith-Watson-Topper (SWT). Material fatigue properties were obtained through using the Glyphworks® software. The goal of this study is to observe the suitability of these techniques and methods in detecting the pattern behaviour in terms of energy and probability distribution in a strain-based time series. These kinds of signals were collected from a real road test of an automobile component.
Signal statistical analysis: A signal is a series of numbers obtained through measurement, typically obtained using some recording method as a function of time. In the case of fatigue research, the signal consists of a measurement of a cyclic load, i.e., force, strain and stress against time (Meyer, 1993). In actual applications, mechanical signals can be classified to have stationary or non-stationary behaviour. Stationary signal behaviour shows that the statistical property values remained unchanged over time. For non-stationary signals, common in fatigue analysis cases, however, the statistical property values of a signal are dependent on the time of measurement (Bendat and Piersol, 1986).
In mathematics, a Probability Density Function (PDF) represents a probability distribution in terms of integrals. In amplitude probability analysis (Ncode, 2005) the Time at Level analysis is useful as it is more common to represent the data as amplitude PDF. This is simply a way of normalising the time at level plot so it does not change shape when the length of time history changes or the number of bins is changed. Time at level analysis is useful for determining the statistical amplitude content of a signal and can be used to detect anomalies such as signal drift, spikes, clipping, etc.
Frequency analysis data is typically presented in graphical form as a Power Spectral Density (PSD) function. Essentially a PSD displays the amplitude of each sinusoidal wave of a particular frequency. The mean squared amplitude of a sinusoidal wave at any frequency can be determined by finding the area under the PSD over that frequency range. In PSD plot, each frequency step value is characterised by amplitude, Ak, as in the following equation:
| (1) |
where, S(fk) is underlying PSD of the Gaussian signal and fk is the harmonic frequency. The PSDs are useful for detecting resonance in components, aliasing in the data, frequency interference, etc.
The objective of time series analysis is to determine the statistical characteristics of the original function by manipulating the series of discrete numbers. In normal practice, the global signal statistical values are frequently used to classify random signals (Abdullah et al., 2008a). The most commonly used statistical parameters are the mean value, the Root-Mean-Square (RMS) value, the skewness and the kurtosis (Nopiah et al., 2010). For a signal with a number n of data points, the mean value will be:
| (2) |
The Root-Mean-Square (RMS) is the square root of the mean square value (Draper, 2007). The RMS value, which is the 2nd statistical moment, is used to quantify the overall energy content of the signal. For a zero-mean signal the RMS value is equal to the SD value. For discrete data sets the RMS value is defined as:
| (3) |
This measure is also used as a simple quality check on the measured data as any change in mean or range will be reflected in this parameter (Ncode, 2005).
The skewness, the signal 3rd statistical moment, is a measure of the symmetry of the distribution of the data points about the mean value. The skewness for a symmetrical distribution such as a sinusoid or a Gaussian random signal is zero. Negative skewness values indicate probability distributions that are skewed to the left, while a positive skewness value indicates probability distributions that are skewed to the right, with respect to the mean value. The skewness of a signal is given by:
| (4) |
Kurtosis value is mathematically defined in Eq. 5, which is the signal’s 4th statistical moment that highly sensitive to the spikiness of the data. For a Gaussion distribution the kurtosis value is approximately 3.0. Higher kurtosis values indicate the presence of more extreme values than should be found in a Gaussian distribution. Kurtosis is used in engineering for detection of fault symptoms because of its sensitivity to high amplitude events.
| (5) |
Correlation function: Correlation is a mathematical tool used frequently in signal processing for analysing functions or series of values, such as time domain signals. It is a mathematical tool for finding repeating patterns, such as the presence of a periodic signal which has been buried under noise, or identifying the missing fundamental frequency in a signal implied by its harmonic frequencies. Correlation is the mutual relationship between two or more random variables. Autocorrelation is the correlation of a signal with itself (Parr and Phillips, 1999), unlike cross correlation, which is the correlation of two different signals.
The autocorrelation function (ACF) is the plot of autocorrelations and is very useful when examining stationarity and when selecting from among various nonstationary models. Autocorrelation is one of the major tools in time series modeling (Minitab StatGuide, 2007). In autocorrelation, lag is a time periods separating the ordered data and used to calculate the autocorrelation coefficients. The maximum number of lags is roughly n/4 for a series with less than 240 observations or (√n + 45) for a series with more than 240 observations, where, n is the number of observations or for time series the number of data points.
An important guide to the properties of a time series is provided by a series of quantities called sample autocorrelation coefficients, which measure the correlation between observations at different distances apart (Chatfield, 1996). Let the time series of length N be xt , t = 1,...,N. The lagged scatterplot for lag k is a scatterplot of the last N-k observations against the first N-k observations. Eq. 6 can be generalized to give the correlation between observations separated by k time steps:
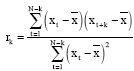 | (6) |
where:
is the overall mean. The quantity rk is called the autocorrelation coefficient at lag k. The plot of the autocorrelation function as a function of lag is also called the correlogram.
The Cross Correlation Function (CCF) is the plot of cross correlations between elements of two time series and is useful in determining if a given series leads another series and by how many periods. The CCF of two time series is the product-moment correlation as a function of lag, or time-offset, between the series. The lags are the time periods separating data in one time series from data in the other time series when calculating the cross correlation coefficients. By default, the lags range from -(√n + 10) to +(√n + 10), where n is the data points of time series.
The following equations are used to calculate the coefficient of cross correlation (rxy) of two time series x and y, each with N data points (Chatfield, 1996):
| (7) |
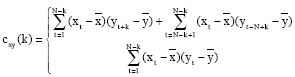 | (8) |
if,
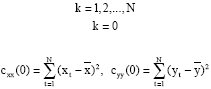 |
where, k is a number indicating a time shift of one signal with respect to the other; k=0 for the original two time series synchronized in time. The correlation rxy(0), calculated from cxy(0), will give an indication of pattern similarity between the two sets of data.
Fatigue life assessment: It is common that the service loads acquired on components of machines, vehicles and structures are analysed for fatigue life using crack growth approaches. This approach is suitable for high capital valued structures, such as large aircraft, space shuttle, pressure vessels and oil rigs (Dowling, 1999). A fatigue life estimation based on the related strain-based approach is usually used in these cases (Dowling, 1999; Wu et al., 1997). The strain-life fatigue model relates the plastic deformation that occurs at a localised region where fatigue cracks begin to effect the durability of the structure. This model is often used for ductile materials at relatively short fatigue lives but can also be used where there is little plasticity at long fatigue lives. Therefore, this is a comprehensive approach that can be used in place of the stress-based approach.
Current industrial practice for fatigue life prediction is to use the Palmgren-Miner (PM) linear damage rule (Draper, 2007). For strain-based fatigue life prediction, this rule is normally applied with strain-life fatigue damage models. The first strain-life model is the Coffin-Manson relationship (Coffin, 1954; Manson, 1965), defined as:
| (9) |
where, E is the material modulus of elasticity, εa is true strain amplitude, 2Nf is the number of cycles to failure, σf’ is the fatigue strength coefficient, b is a fatigue strength exponent, is a fatigue ductility coefficient and c is a fatigue ductility exponent.
Some realistic service situations will involve non-zero mean stresses. Two mean stress effect models are used in the strain-life fatigue damage analysis, i.e., Morrow and SWT strain-life models. Mathematically, the Morrow model (Morrow, 1968) is defined by:
| (10) |
where, σm is the mean stress. The SWT strain-life model (Smith et al., 1970) is mathematically defined by:
| (11) |
where, σmax is the maximum stress for the particular cycle. The fatigue damage caused by each cycle is calculated by reference to material life curves, i.e., stress life (S-N) or strain life (ε-N) curves (Abdullah et al., 2008b). The Nf value for each cycle can be obtained from Eq. 9 to 11 for all three models and the fatigue damage value, D, for one cycle is calculated as:
| (12) |
and therefore fatigue damage values have the range (0, 1) where zero denotes no damage (extremely high or infinite number of cycles to failure) and 1 means total failure (one cycle to failure). Failure occurs when the fatigue damage ∑(n/Nf) = 1, so the fatigue life is the inverse of the damage as expressed below:
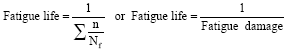 | (13) |
MATERIALS AND METHODS
This study was conducted at field road test on Selangor, Malaysia in November 2009. A Variable Amplitude (VA) strain loading was used in this study as an input signal for the lower suspension arm of mid-sized sedan car. The fatigue data acquisition system, SoMat eDaQ Data Acquisition, was used for the strain data measurements. The strain loading was measured using two strain gauges of 5 mm size which were located at the maximum stress area and the minimum stress area, notated as for channel 1 and 2, respectively.
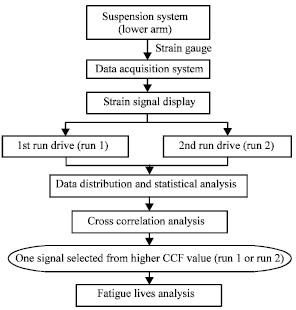 | |
| Fig. 1: | Flowchart of the fatigue road test and fatigue data analysis |
The signal was measured on the right lower suspension arm of a car travelling over a pavé road of 40 km h-1 and a highway route of 70 km h-1. The strain data was collected twice for each road in order to provide a variety of data sets pattern between channel 1 and channel 2. The data was collected in the unit of microstrain (με) for 60 sec at a sampling rate of 500 Hz, which gave 30,000 discrete data points.
A flowchart describing the fatigue road test, analyzing strain data processes using data distribution function, global signal statistic parameters, cross correlation function and fatigue damage calculations is shown in Fig. 1. In first stage, the collected strain signal was then analyzed for the distribution function and global signal statistics parameter using the GlyphWorks® software. Then the distribution pattern and signal statistical parameters will be compared between the pavé road and highway route data sets. The second stage analyzes the strain signal of Run 1 and 2 using the cross correlation method using Minitab 15® software. The purpose of this method is to select the strain signal which had the higher cross correlation function value, which is then used in the final stage. The last stage is the fatigue life analysis which is achieved by calculating the fatigue damage values using three models of strain-life, which are Coffin-Manson, Morrow and Smith-Watson-Topper (SWT) that are contained in the GlyphWorks® software.
RESULTS AND DISCUSSION
Fatigue time series: The data plot in Fig. 2a-d was collected on a straight pavé road at Wilayah Putrajaya and a highway route of Sistem Lingkaran-Lebuhraya Kajang (SILK) of Selangor.
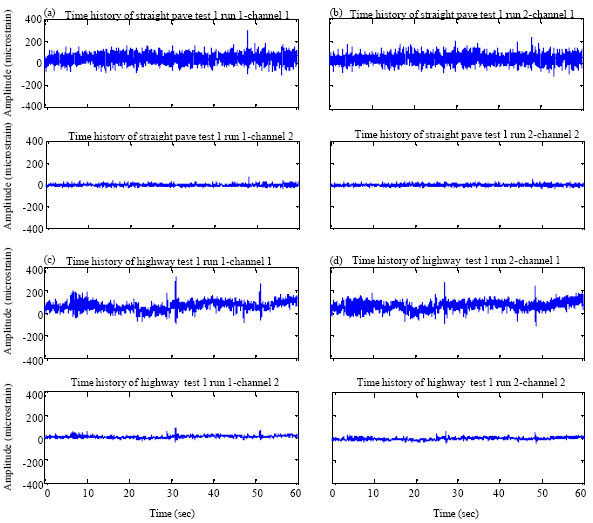 | |
| Fig. 2: | Time history plot of (a, b) straight pavé for Run 1 and 2 and a (c, d)highway route for Run 1 and 2 |
These strain signals, having a VA pattern in the strain format, were measured on the front left lower suspension arm of mid-sized sedan car travelling on public road surface. The road conditions were in the surface type of a stretch of highway road for representing mostly consistent load features and a stretch of brick-pavéd road for representing a noisy but mostly consistent load features.
The captured of non-stationary strain loading data was analyzed in the time domain signal plots. It showed the high strain amplitudes for the pavé road were recorded at 295 and 75 με for channel 1 and 2, respectively. For highway route, high strain amplitudes were recorded at 321 με for channel 1 and 81 με for channel 2. The peak in strain signal or spike, occurs when vehicles is braking or driven on an uneven road.
Global signal statistics: Figure 3a-d show the amplitude PDF diagram for straight pavé and highway route sharing the shape of classic symmetrical bell curve following the Gaussian Normal distribution. This shaped curve is expected for random vibration signals. This PDF diagram of channel 1 has a wide range of bell shaped compared to channel 2. This is related to the amplitude range of it signal, which the range is wider than the similar trend of channel 2. In addition, the signal of channel 1 is more skewed to right side from origin point, but the peak of channel 2 is around origin point. It means that the distribution of channel 1 is found to be a non-Gaussian distribution. For channel 2, the distribution is closely to the Gaussian distribution.
The diagram below shows the PSD produced from pavé and highway route strain signals. The PSD diagram of channel 1 shows a broad band signal while channel 2 shows nearly as narrow band signal. A broad band signal covers a wide range of frequencies and it might consist of a single, wide spike or a number of distinct spikes as shown in the PSD diagram, a narrow band signal only cover a narrow range of frequencies; this occurrence can be seen in Fig. 4a-d.
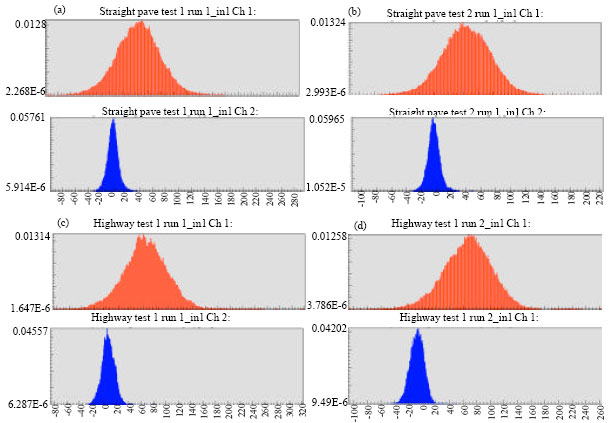 | |
| Fig. 3: | Graph of amplitude PDF of (a, b) straight pave for Run 1 and 2 and a (c, d) highway route for Run 1 and 2 |
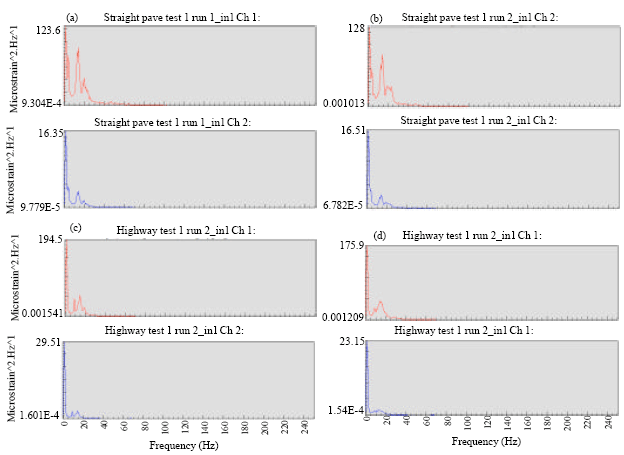 | |
| Fig. 4: | Graph of PSD function of (a, b) straight pavé for Run 1 and 2 and a (c, d) highway route for Run 1 and 2 |
| Table 1: | Global signal statistical parameter |
 | |
This PSD pattern of Fig. 4 represents the texture of surface road that is mostly noisy. The PSD is also used to measure the power of a signal by converting the signal from the time domain to the frequency domain. It shows where the average power is distributed as a function of frequency. In this case, power distribution of channel 1 has a greater range of frequency compared to channel 2. This is related to channel 1 having more vibration compared to channel 2 when the vehicle is moving.
Statistical analysis is concerned with reducing a long time signal into a few numerical values that describe its characteristics, therefore the global statistical parameter values were calculated and the results were shown in Table 1. Generally the mean value is the average value or the centre of area of the PDF about the x-axis. From this table, mean value of channel 1 is significantly larger than channel 2. The mean value represent the point of highest peak in PDF diagram. When the mean value is not equal to zero, it means the distribution is a non-Gaussian distribution. It is clearly seen in Fig. 3, where PDF diagram on channel 1 shows non-Gaussian distribution, but not for the channel 2 signal.
The RMS can be said as the vibration signal energy in a time series and the kurtosis value represented the amplitude range in a time series. The RMS value of channel 1 is higher than channel 2 which means the maximum stress area creates more vibration compared to the minimum stress area. With refering to the PSD diagram in Fig. 4, it was found that the power distribution on channel 1 is wider than for channel 2.
Skewness is a measure of the degree of asymmetry of a distribution. As we can see in Table 1, the skewness value of pavé road and highway route on channel 1 is lower than channel 2. Both channels of pavé road have positive skewness, which means the data distribution is skewed to the right. For highway route, at Run 2 the skewness has a negative value and this describes a data distribution skewed to the left. By skewed left, it means the left tail is long relative to the right tail. Similarly, skewed right means the right tail is long relative to the left tail. This is useful for identifying signal drift, cyclic hardening, etc.
The kurtosis value of channel 1 is lower than channel 2. This is because kurtosis was highly sensitive to the spikiness of the data. The differences of kurtosis value on pavé road is higher than highway because the pavé road surface represent more noisy even mostly consistent load features compared to highway surface.
Cross correlation analysis: This analysis will provide a correlation between two time series or two strain signals. The observations of one series are correlated with the observations of another series at various lags and leads. Cross-correlations help identify variables which are leading indicators of other variables or how much one variable is predicted to change in relation to the other variable. There are three possible outcomes in the Pearson’s Product Moment correlation r; Positive correlation (r = +1), where as one variable rises the other variable is predicted to rise at a similar rate, Zero (r = 0) or no correlation at all, or Negative correlation (r = -1) where as one variable rises the other falls. The cross-correlation test of two time-series data sets involves many calculations of the coefficient r by time-shifting the one data set relative to the other data set. A typical cross-correlation graph shows enough lags in both negative and positive directions, as Fig. 5, to show the cyclical relationship of the two sets of data.
Figure 5a show the cross correlation function (also known as correlogram) graph of pavé road for run 1 and 2 and it shows the correlogram pattern was similar for both runs. While for Fig. 5b, the correlogram shows different pattern for both runs. This might occurs when the driver could not maintain the velocity of vehicle. On pavé road, the r value of run 1 is 0.861 while the value of r at run 2 is 0.850, both at lag 0. These numbers described the strain signals at run 1 is nearly similar pattern compared to run 2. In Fig. 5b, at run 1, the r value is 0.930 while the value of r at run 2 is 0.873, both at lag 0. These numbers also described the strain signals at run 1 is closely for both pattern signal compared to run 2.
In cross-correlation analysis, the signals that alternate are out-of-phase from each other and will have a negative relationship, whereas the signals that are synchronous will be in-phase and have a positive relationship. The strength of the relationship between two signals will be perfect at ±1 and will diminish to a minimum when approaching 0.
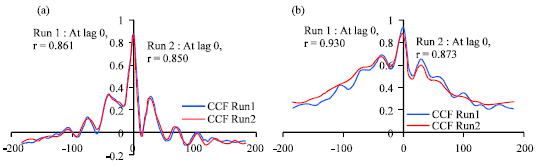 | |
| Fig. 5: | Graph of cross correlation function for: (a) straight pavé road and (b) highway route |
| Table 2: | Result of total fatigue damage and number of cycles |
 | |
| Table 3: | Result of calculated fatigue life |
 | |
A high degree of symmetry or stability along the x-axis indicates a stable relationship between the two signals. However, as the relationship between signals varies, therefore creating decreasing correlation values beyond zero lag, this indicates less stability in the relationship.
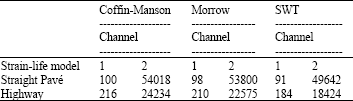
Fatigue life analysis: Table 2 shows the results of the total fatigue damage that based on strain-life models of Coffin-Manson, Morrow and Smith-Watson-Topper (SWT) approaches using GlyphWorks® software. It was found on channel 1 for straight pavé road gave the higher total fatigue damage that is 9.97x10-3, 10.2x10-3 and 11.0x10-3 for Coffin-Manson, Morrow and SWT model, respectively. These values are higher than highway for channel 1. On the other hand, the total fatigue damage for channel 2 is 0.0185x10-3, 0.0186x10-3 and 0.0201x10-3 for Coffin-Manson, Morrow and SWT approaches, respectively. These values are lower than highway on channel 2.
From Table 2, it clearly shows that the number of cycles of channel 1 is lower than channel 2 for both roads, it means that the number of cycles could be less on high stress area of a component and vice versa. In overall, the number of cycles from pavé road is less than highway. This can be related to pattern of surface road where a stretch of highway road represents mostly consistent load features, while a stretch of brick-pavéd road represents noisy and mostly consistent load features.
Predicting fatigue life for variable amplitude signals requires a cumulative damage model to calculate the total damage caused by a series of applied cycles. Miner’s linear damage rule equates the damage caused by one cycle to the inverse of the number of cycles to failure for the given cycle Nf. Miner’s linear damage rule was applied to the variable amplitude test signals by using the average constant amplitude fatigue life, determined experimentally, for each loading condition as the basis for the predicted fatigue lives. By using Eq. 13, the fatigue life could be calculated and concluded as in Table 3 for pavé road and highway of each strain-life models.
Referring to Table 3, the fatigue life of pavé road are lower than highway for channel 1 which is the maximum stress area. On the other hand, the fatigue life for pavé road was higher than highway on channel 2, where stress area is minimum. The lower suspension arm that was driven over the damage-surface road experienced the shortest fatigue life although the velocity of the car was the lowest among the velocity on the other roads. In overall, we can see that the fatigue life from Coffin-Manson model is the highest follows the Morrow model and finally SWT model.
CONCLUSIONS
This study discussed the capability of amplitude PDF and PSD techniques in investigating the pattern behaviour in terms of energy and probability distribution in a signal. The study also presents an analysis on statistical parameters that were contained in VA loading strains data and detecting the similarity of pattern signal using cross correlation method. A set of case study data consisting of non-stationary VA loading strains data that exhibits a random behaviour was used in this study. For non-stationary signal, the engineering-based signal analysis is important to explore the characteristics and behaviour of the signal and the outcomes of these can also be related to the fault detection and analysis. From the analysis, the non-stationary VA strain loading data shows strain amplitude range for the pavé road are smaller compared to highway for channel 1 and 2, respectively. The amplitude PDF diagram illustrated symmetrical bell shaped curve following the Gaussian Normal distribution and this shaped curve is expected for random vibration signals. From PDF and PSD diagrams, the result can be concluded that the non-Gaussian distribution can be related to a broad band signal, while for Gaussian distribution normally for a narrow band signal. From this study, it was found that higher kurtosis values indicate the presence of more extreme values than should be found in a Gaussian distribution. In cross correlation analysis, the r value of run 1 is higher than run 2 for both roads. In fatigue lives analysis, fatigue lives of pavé road are lower than highway for channel 1 but higher than highway on channel 2. The findings from this study are expected to be used to determine the pattern behaviour that exists in non-stationary VA signals.
ACKNOWLEDGMENT
The authors would like to express their gratitude to Universiti Kebangsaan Malaysia (UKM-KK-02-FRGS0129-2009) for supporting these research activities.
REFERENCES
- Abdullah, S., M.D. Ibrahim, Z. Mohd Nopiah and A. Zaharim, 2008. Analysis of a variable amplitude fatigue loading based on the quality statistical approach. J. Applied Sci., 8: 1590-1593.
CrossRefDirect Link - Abdullah, S., S.N. Sahadan, M.Z. Nuawi and Z.M. Nopiah, 2008. Fatigue road signal denoising process using the 4th order of daubechies wavelet transforms. J. Applied Sci., 8: 2496-2509.
CrossRefDirect Link - Anderson, M.R., 1996. Fatigue damage analysis by use of cyclic strain approach. J. Ship Technol. Res., 43: 155-174.
Direct Link - Coffin, L.F., 1954. A study of the effect of cyclic thermal stresses on a ductile metals. Trans. ASME., 76: 931-950.
Direct Link - Manson, S.S., 1965. Fatigue: A complex subject-Some simple approximations. Exp. Mech., 5: 193-226.
CrossRefDirect Link - Nadot, Y. and V. Denier, 2004. Fatigue failure of suspension arm: Experimental analysis and multiaxial criterion. Eng. Failure Anal., 11: 485-499.
Direct Link - Nopiah, Z.M., M.N. Baharin, S. Abdullah and M.I. Khairir, 2010. The detection of abrupt changes for variable amplitude fatigue loading by using running damage extraction method. J. Applied Sci., 10: 544-550.
CrossRefDirect Link - Rahman, M.M., K. Kadirgama, M.M. Noor, M.R.M. Rejab and S.A. Kesulai, 2009. Fatigue life prediction of lower suspension arm using strain-life approach. Eur. J. Sci. Res., 30: 437-450.
Direct Link - Smith, K.N., T.H. Topper and P. Watson, 1970. A stress-strain function for the fatigue of metals. J. Mater., 5: 767-778.
Direct Link - Svenssona, T., P. Johannessona and J. de Marea, 2005. Fatigue life prediction based on variable amplitude tests-specific applications. Int. J. Fatigue, 27: 954-965.
CrossRefDirect Link - Wang, X. and J.Q. Sun, 2005. Multi-stage regression fatigue analysis of non-gaussian stress processes. J. Sound Vib., 280: 455-465.
CrossRef - Wu, W.F., H.Y. Liou and H.C. Tse, 1997. Estimation of fatigue damage and fatigue life of components under random loading. Int. J. Press. Vess. Pip, 72: 243-249.
Direct Link