
H. Midi
1Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia
S. Rana
Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia
A.H.M.R. Imon
Department of Mathematical Sciences, Ball State University, Muncie, IN 47306, USA
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 22 | Page No.: 4013-4019







ABSTRACT
In this study, we propose a Leverage Based Near-Neighbor (LBNN) method where prior information on the structure of the heteroscedastic error is not required. In the proposed LBNN method, weights are determined not from the near-neighbor values of the explanatory variables, but from their corresponding leverage values so that it can be readily applied to a multiple regression model. Both the empirical and Monte Carlo simulation results show that the LBNN method offers substantial improvement over the existing methods. The LBNN has significantly reduced the standard errors of the estimates and also the standard errors of residuals for both simple and multiple linear regression models. Hence, the LBNN can be established as one reliable alternative approach to other existing methods that deal with heteroscedastic errors when the form of heteroscedasticity is unknown.
PDF Abstract XML References Citation
How to cite this article
H. Midi, S. Rana and A.H.M.R. Imon, 2009. Estimation of Parameters in Heteroscedastic Multiple Regression Model using Leverage Based Near-Neighbors. Journal of Applied Sciences, 9: 4013-4019.
DOI: 10.3923/jas.2009.4013.4019
URL: https://scialert.net/abstract/?doi=jas.2009.4013.4019
DOI: 10.3923/jas.2009.4013.4019
URL: https://scialert.net/abstract/?doi=jas.2009.4013.4019
INTRODUCTION
One of the crucial assumptions in the linear model is that the variance of the errors is constant. The Ordinary Least Squares (OLS) method is very popular with statistics practitioners as it provides efficient and unbiased estimates of the parameters when the assumptions, especially the assumption of homoscedastic error variances are met. But in many real applications, variances of the errors vary across observations. Since, homoscedasticity is often an unrealistic assumption, researchers should consider how the results are affected by heteroscedasticity. Eventhough the OLS estimates retain unbiasedness in the presence of heteroscedasticity, its estimates become inefficient. Heteroscedasticity yield hypothesis tests that fail to keep false rejections at the nominal level, or estimated standard errors as well as confidence intervals that are either too narrow or too large. As heteroscedasticity is a common problem in cross-sectional data analysis, it is very important to find a reliable method that can correct such problem for prudent data analysis.
A good number of works is now available in the literatures (Carroll and Ruppert, 1982, 1988; Robinson, 1987; Montgomery et al., 2001; Gujarati, 2003; Chatterjee and Hadi, 2006; Greene, 2008) for correcting the problem of heteroscedasticity. When the form and magnitude of heteroscedasticity are known, the correction for heteroscedasticity is very simple by means of the weighted least squares. The WLS is equivalent to performing OLS on transformed variables. Nevertheless, in real situation it is not easy to get a suitable transformation, especially for multiple regression, where some predictors may require transformations and others may not. If the form of heteroscedasticity involves a small number of unknown parameters, the variance of each residual can be estimated first and these estimates can be used as weights in a second step. Nevertheless, in practice, the form of heteroscedasticity is unknown, which makes the weighting approach impractical. When heteroscedasticity is caused by an incorrect functional form, it can be corrected by making variance-stabilizing transformations of the dependent variables (Welsberg, 1980) or by transforming both sides (Carroll and Ruppert, 1988). Although, these approaches can provide an efficient and elegant solution to the problems caused by heteroscedasticity, when the results need to be interpreted in the original scale of the variables, nonparametric methods may be necessary (Carroll and Ruppert, 1988). As noted by Emerson and Stoto (1983), re-expression moves us into a scale that is often less familiar. Furthermore, if there are theoretical reasons to believe that errors are heteroscedastic around the correct functional form, transforming the dependent variable is inappropriate.
Consider the general multiple linear regression model:
| (1) |
where, yi is the ith observed response, xi is a px1 vector of predictors including the intercept, β is a px1 vector of unknown finite parameters and ε are uncorrelated random errors with mean 0 and variance σ2. Writing y = (y1,y2,…,yn)T, X = (x1,x2,…,xn)T and ε = (ε 1,ε 2,…,ε n)T, model (1) can be written as:
| (2) |
Inferences about β may be based on the fact that ![]() has mean zero and covariance matrix:
has mean zero and covariance matrix:
| (3) |
where, E(εεT), a positive definite matrix. If the errors are homoscedastic, that is, Ω = σ2In, Eq. 3 simplifies to:
| (4) |
and ![]() is an unbiased and consistent estimator of β. If the errors are heteroscedastic, that is, Ω = σ2 V, Eq. 3 becomes:
is an unbiased and consistent estimator of β. If the errors are heteroscedastic, that is, Ω = σ2 V, Eq. 3 becomes:
| (5) |
The above problem can be solved by transforming the model to a new set of observations that satisfy the standard least squares assumptions. Then the OLS is applied on the transformed data. Since, σ2 is the covariance matrix of the errors, V must be nonsingular and positive definite and:
| (6) |
is the Generalized Least Squares (GLS) estimates of β. When the errors ε are uncorrelated but have unequal variances, the covariance matrix of ε is written as:
σ2 V = Diag [1/wi], i = 1, 2, …, n
Consequently, the GLS is the solution of the heteroscedastic model. If we define W = V-1, W becomes a diagonal matrix with diagonal elements or weights w1,w2,…,wn. From Eq. 6, the weighted least squares estimator is ![]() and
and ![]() .
.
Where:
If the heteroscedastic error structure of the regression model is known, it is easy to compute the weights of W matrix and consequently the WLS would be a good solution of heteroscedastic regression model.
Unfortunately, in practice, the structure of the heteroscedastic error is unknown. In the presence of heteroscedasticity, as there is no biasness problem of the OLS estimator, a Heteroscedasticity Consistent Covariance Matrix (HCCM) proposed by White (1980), is used to solve the consistency problem of the estimator. Defining the residuals, ![]() , where, xi is the ith row of X, the OLS covariance matrix (OLSCM) of estimates of the regression parameters is:
, where, xi is the ith row of X, the OLS covariance matrix (OLSCM) of estimates of the regression parameters is:
| (7) |
The OLSCM is appropriate for hypothesis testing and also for computing confidence intervals when the standard assumptions of the regression model, including homoscedasticity, hold. When there is heteroscedasticity, tests based on the OLSCM are likely to be misleading since the Eq. 4 will not generally be equal to the Eq. 3. Equation 3 can be used to correct for heteroscedasticity, if the errors are heteroscedastic and Ω is known. In many applications, the form of the heteroscedasticity is unknown and the HCCM may be an alternative method.
However, there is no general agreement among statisticians about which of the four estimators of the HCCM (HC0, HC1, HC2, HC3) should be used (Judge et al., 1988; MacKinnon and White, 1985; Davidson and MacKinnon, 1993; Long and Ervin, 2000; Gujarati, 2003; Greene, 2008).
MATERIALS AND METHODS
The leverage based near-neighbor method: Several attempts have been made in the literature other than the HCCM to obtain consistent estimators when the form of heteroscedasticity is unknown. A good review of these methods is available in Montgomery et al. (2001) and Chatterjee and Hadi (2006). Moreover, Montgomery et al. (2001) and Chatterjee and Hadi (2006) proposed several WLS methods to solve this problem by developing weighting techniques that are later used for estimating the parameters of a heteroscedastic model. Instead of fitting regression with all the data, Montgomery et al. (2001) suggested finding several near-neighbor groups in the explanatory variable. We refer to this method as the Montgomery, Peck and Vining (MPV) method. The group means would now represent the explanatory variables (X). The groups in the response variable Y is formed in accordance with the groups formed in X. The sample variance of each groups of Y and the mean of each group of X are then computed. These group variances in Y are then regressed on the corresponding group mean of X. In the presence of heteroscedasticity we expect variations in errors among these groups. Hence the inverse of the fitted response can be used as weights for stabilizing variance heterogeneity. The values of X are first sorted to form near neighbor groups. The main limitation of this method is that it cannot be applied to multiple linear regression model as we are not able to sort the values of X for more than one explanatory variables and we are unable to make group means and group variances for a multiple linear regression model. In this situation, it is quite impossible to find near neighbors of the X’s. Chatterjee and Hadi (2006) propose a two step estimation technique that can be used for multiple regression model. We refer to this method as the Chatterjee and Hadi (CH) method. In this method we need some known data that are grouped in a natural way. It is assume that there is a unique residual variance associated with each of the group. Let us consider we have g known groups and the variances are denoted as (cjσ)2, j = 1,2,3,… …,g, where the residual standard error, σ is the common part and cj’s are unique to the groups. According to the principle of weighted least squares, the regression coefficients should be determined by:
![]()
where:
| (8) |
The factors 1/c2j are the weights that determine how much influence each observation has in estimating the regression coefficients. The estimate of c2j is define as:
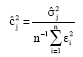 |
The main advantage of this method is that it can be employed to multiple regression model. But its main limitation is that it can be applied only in situations where we definitely know the heteroscedastic groups. Nevertheless, this method requires prior information about the heteroscedastic structures. Without this information, it is not possible to construct the near neighbor groups of the X’s.
In this study we refer the works of Montgomery et al. (2001) and Chatterjee and Hadi (2006) as MPV and CH methods, respectively. However, their works have motivated us to develop a new method in multiple linear regression to obtain consistent estimators when the form of heteroscedasticity is unknown. As already been mentioned the MPV can only be applied to simple linear regression when nothing is known about the form of heteroscedasticity. On the other hand, the CH can be applied to the multiple linear regression but this method requires prior information on the structures of the heteroscedastic errors. An attempt has been made to make a compromise between these two approaches. Hence, in this study a Leverage Based Near-Neighbor (LBNN) method similar to that of MPV method is proposed. We extend the idea of Montgomery et al. (2001) in multiple linear regression when the structure of heteroscedasticity is unknown. We propose using the leverage values of the explanatory variables as a basis of finding the “near- neighbor” groups. Specifically, the weights of the LBNN are determined not from the near-neighbor values of the explanatory variables, but from their corresponding leverage values so that it can be readily applied to a multiple regression model. We observe that the ith leverage value, denoted as hii = xi(XTX)-1xTi, i = 1, 2, …, n, is the standardized measure of the distance of the ith observation from the centre (or centroid) of the x-space. Thus, we can form the near neighbor groups of X by using the leverage values and this method can be used not only for a single explanatory variable as proposed by Montgomery et al. (2001), but also for multiple explanatory variables. The main attraction of this method is that it can be implemented regardless of whether the prior information about the structure of heteroscedasticity is known or not. The proposed LBNN algorithm consists of the following steps:
Step 1: Finding near-neighbor groups
| • | Compute the diagonal elements hii of the hat matrix. Corresponding to each hii, there are yi and xij, where i = 1, 2, …, n; j = 1, 2, …, p |
| • | Arrange hii’s in increasing order, carrying along the yi and the xij. Then determine the near-neighbor groups of the explanatory variables X’s according to the sorted diagonal elements of the hat matrix H. A number of clustering methods is available in the literature for finding near-neighbor groups. We suggest using the clustering method proposed by Struyf et al. (1997) because it is very popular and effective technique and as a result is used as a default in S-PLUS. If our data set contains g groups of leverages, we obtain Y(i)k and X(i)jk where, (i) = 1, 2, …, g, j = 1, 2, …, p, where, p is the number of parameters and k = 1, 2, …,ni, where ni is the number of observations in each near neighbor group |
Step 2: Determining weights for near-neighbor groups
| • | Compute variances of all groups of the response variable, denoted as var(y(i)k), corresponding to the near-neighbor groups of X. Also compute the mean of each g groups for each explanatory variables, denoted as |
| • | Regress var (y(i)k) on the mean ( |
| • | Obtain the linear regression line of y on x’s by using the parameter estimates computed in step 4. Calculate the fitted values of y based on the values of the variables X’s |
| • | The inverse of these absolute fitted values denoted by wi will be reasonable estimates of the weights |
Step 3: Heteroscedasticity correction
| • | Finally perform a WLS regression using weights wi. The regression coefficients obtained from this WLS regression are the desired estimate of the heteroscedastic model |
RESULTS
Numerical examples: In order to evaluate performance of the LBNN method, two real data sets are considered.
Restaurant food sales data: Our first example presents the average monthly income (y) corresponding to one predictor variables of 30 restaurants taken from Montgomery et al. (2001). Here we wanted to show that our proposed method can also be applied to a single predictor variable. We apply the proposed LBNN methods to this data and compare its performance with the traditionally used OLS and recently developed MPV methods. To apply the MPV to the data, we first need to determine the near neighbor groups. By examining the Restaurant Food Sales Data, we observe that there are several sets of x values that are near-neighbors, that is, observations which have approximate repeat points of x. We will assume that these near neighbors are close enough to be considered as repeat points. Once the near neighbors are identified, the variance of the response at those considered repeat points are computed and then we observe how var(y) changes with x.
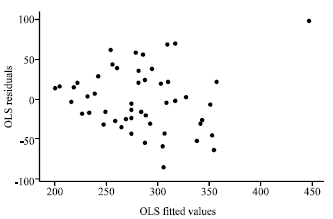
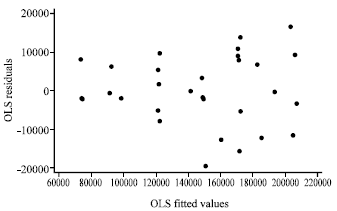 | |
| Fig. 1: | Plot of OLS residuals versus fitted values for the restaurant food sales data |
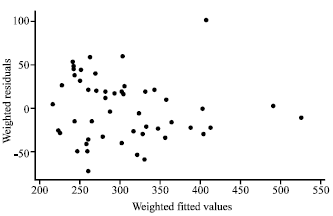
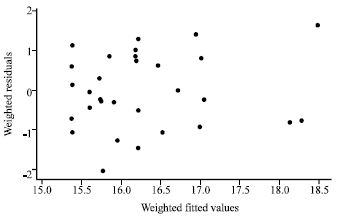 | |
| Fig. 2: | Plot of MPV residuals versus fitted values for the restaurant food sales data |
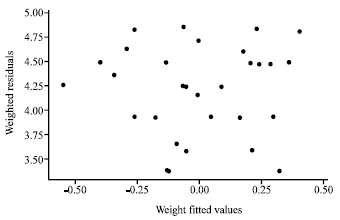 | |
| Fig. 3: | Plot of LBNN residuals versus fitted values for the restaurant food sales data |
The weights, wi are obtained according to the MPV algorithm. The residuals from the OLS fit are plotted against ŷ in Fig. 1.
The MPV residuals are plotted against the weighted fitted values of ŷ in Fig. 2.
Figure 3 displays the residuals of the LBNN estimates against the LBNN fitted values of ŷ.
| Table 1: | Summary statistics for the restaurant food sales data |
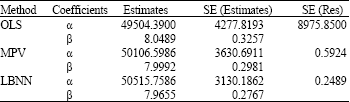 | |
| Table 2: | Summary statistics for the education expenditure data |
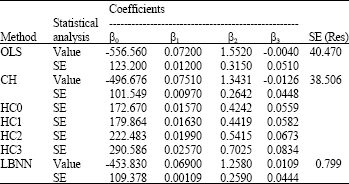 | |
The standard errors of the parameters estimates and residual standard errors for the three methods are exhibited in Table 1.
Education expenditure data: This data is taken from Chatterjee and Hadi (2006). It represents the relationship between response variable and three independent variables for all 30 states in USA. It is worth mentioning here that the structure of the heteroscedasticity of this data is known since the states are grouped according to geographical regions. The variables names are as follows:
| Y | : | Per capita income on education projected for 1975 |
| X1 | : | Per capita income in 1973 |
| X2 | : | Number of residents per thousand under 18 years of age in 1974 |
| X3 | : | Number of residents per thousand under 18 years of age in 1974 |
The states are grouped according to geographical regions based on the pre-assumption that there exists a sense of regional homogeneity. The four geographic regions, (1) Northeast, (2) North centre, (3) South and (4) West, are used to define the groups. It is important to point out that since this data set contains three explanatory variables, we cannot apply the MPV method here. Figure 4 presents the OLS residual versus fitted plot for this data.
Figure 5 and 6 show the residuals versus the fitted plots for the CH and the LBNN methods, respectively.
Table 2 presents the summary statistics of different estimation techniques for the education expenditure data.
 | |
| Fig. 4: | Plot of OLS residuals versus fitted values for the education expenditure data |
 | |
| Fig. 5: | Plot of CH residuals versus fitted values for the education expenditure data |
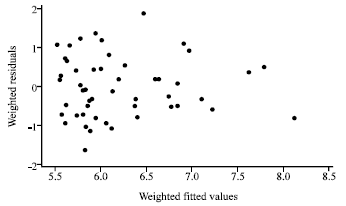 | |
| Fig. 6: | Plot of LBNN residuals versus fitted values for the education expenditure data |
Monte carlo simulation: Here, we report a Monte Carlo simulation study that is designed to investigate different heteroscedasticity correction methods under a variety of situations. In this experiment we consider a true multiple regression model:
| (9) |
where, X1i is uniformly distributed on [0,1], X2i is also normally distributed on [0,1] and X3i is distributes as X21df.
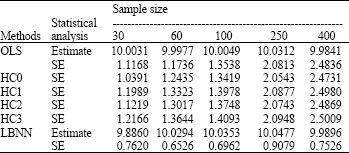
| Table 3: | Simulated summary statistics for coefficient β0 (True value = 10) |
 | |
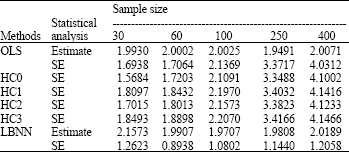
| Table 4: | Simulated summary statistics for coefficient β1 (True value = 2) |
 | |
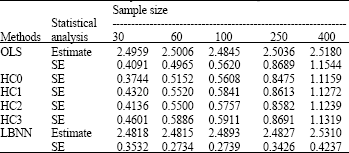
| Table 5: | Simulated summary statistics for coefficient β2 (True value = 2.5) |
 | |
In order to generate heteroscedastic errors, the random errors εi’s are drawn from normal distribution, i.e., εij∼N(0, σ2j, I = 1, 2, …, n and j=1,2,…, g where, g is the number of error groups in each sample. Each error group consists of 10 random errors. The value of σ2j in each error group corresponds to j. Here we consider five different sample sizes 30, 60, 100, 250 and 400 which are kept fixed over repeated samples. We assign different random errors for different sample sizes. For example, for generating 30 random errors we take the first 10 random errors from N(0,1), the second 10 from N(0,2) and the third 10 random errors from N(0,3). For these 30 random errors, it is obvious that although the mean of the errors are zero but their variances are not constant. Similarly, for generating 60 random errors, the first 10 random errors are generated from N(0,1), the second 10 from N(0,2), the third 10 from N(0,3), … and the last 10 random errors from N(0,6). The random errors for other sample sizes are generated in the manner describe earlier. The OLS, HC0, HC1, HC2, HC3 and LBNN are then applied to these data. In each simulation run, there were 10,000 replications.
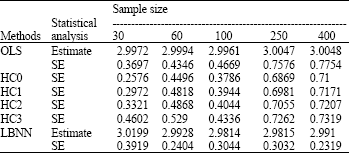
| Table 6: | Simulated summary statistics for coefficient β3 (True value = 3) |
 | |
| Table 7: | Simulated residuals standard error |
 | |
Table 3-6 illustrate the average measures of the regression coefficients and their corresponding standard errors while Table 7 displays the simulated residuals standard errors.
DISCUSSION
At first we discuss results of the numerical examples. The plot as shown in Fig. 1 for the restaurant food sales data signifies that the OLS fit is inappropriate as there is a clear indication of heterogeneous error variances. It can be observed from Fig. 2 that the MPV residuals plot versus the fitted values indicates much improvement when compared to the OLS fit. We can see from Fig. 3 that, the LBNN transformation helps in producing a constant error variance. The summary statistics exemplified in this table show that the LBNN method does a superb job. The LBNN method outperforms the OLS and the MPV by possessing the lowest residual standard errors and lowest standard errors of the parameter estimates.
The OLS residual plot for the education expenditure data as displayed in Fig. 4 shows a funnel shape indicating heteroscedasticity. By looking at Fig. 5, we observe that all points are reasonably randomly distributed around zero, indicating that the CH has become successful in solving the problem of heteroscedasticity. For this particular example, the four geographical regions are used to define the near neighbor groups in order to compute the weights of the CH method. However, in practice we seldom get this kind of information. We employ the LBNN method for this data as if we did not know these four geographical regions. Figure 6 shows that the LBNN corrections work very well and we get a picture very similar to that produced by the CH method. We observe from Table 2 that the CH and the LBNN produce standard errors of estimates which are much less than those obtained by the OLS and the HCCM. Even without any prior information about the heteroscedastic structure, the proposed LBNN method performs very well for this data.
Finally we discuss the results obtained from the simulations. Several interesting points emerge from these results as reported in Table 3-7. We observe that the LBNN and the OLS give close estimates in terms of the true value of the parameters. These results do not report any biasness problem of the regression parameters and also suggest that these estimates get even closer to the true value as the sample sizes get larger. It confirms the standard theory assumption that the presence of heteroscedasticity retains the unbiasedness property of the OLS estimates. The main interest here is to investigate the standard errors of the regression coefficients in the presence of heteroscedasticity. The results presented in Table 3-6 clearly show that the LBNN possesses the least value of the standard errors in comparison with other estimators. The values of the standard errors of the LBNN estimator are consistently the smallest for all sample sizes. It is also interesting to note that the residual standard errors based on the LBNN as presented in Table 7 are substantially smaller than the OLS. The results are consistent for each sample sizes.
The present findings contradicted by White (1980), Long and Ervin (2000), Montgomery et al. (2001) and Chatterjee and Hadi (2006), since their standard error of the parameters are relatively larger than our proposed LBNN method. It is important to point out; the proposed LBNN method can be used when the form of heteroscedasticity is unknown. Thus, it can be concluded that the LBNN method provides the best estimates in the presence of heteroscedasticity.
CONCLUSION
The main focus of this study was to develop a reliable alternative approach for correcting the problem of heteroscedastic errors with unknown structures. We have considered several estimators in this regard. The OLS based HCCM is not efficient at all and the other versions are not any better either. The MPV is a good method but it can be applied only to simple linear regression model. The performance of the CH is good and it can be applied to more than one predictor variables but this technique requires prior information on the structures of heteroscedastic errors. In this study we proposed a leverage-based near neighbor method where we do not require any prior information on the structures of heteroscedastic errors and it can be easily applied to multiple regression models. The empirical studies and simulation experiments show that the LBNN method offers a substantial improvement over the other existing methods. The LBNN can significantly reduce standard errors of estimates and standard error of residuals for both simple and multiple regression models. Thus we can consider the LBNN as a better estimation method and strongly recommend using this method especially when heteroscedasticity occurs in the data.
REFERENCES
- Carroll, R.J. and D. Ruppert, 1982. Robust estimation in Heteroscedastic Linear models. Annal. Stat., 10: 429-441.
CrossRefDirect Link - Gujarati, D.N., 2003. Basic Econometrics. 4th Edn., McGraw-Hill, United States, ISBN-10: 0-07-112342-3, Pages: 1002.
Direct Link - Long, J.S. and L. Ervin, 2000. Using heteroscedasticity-consistent standard errors in the linear regression model. Amer. Statis., 54: 217-224.
Direct Link - MacKinnon, J.G. and H. White, 1985. Some heteroskedasticity consistent covariance matrix estimators with improved finite sample properties. J. Economet., 29: 305-325.
CrossRefDirect Link - Robinson, P.M., 1987. Asymptotically efficient estimation in the presence of heteroscedasticity of unknown form. Econometrica, 55: 875-891.
Direct Link - Struyf, A., M. Hubert and P.J. Rousseeuw, 1997. Integrating robust clustering techniques in S-PLUS. Computat. Statis. Data Analy., 26: 17-37.
CrossRefDirect Link - White, H., 1980. A heteroskedasticity-consistent covariance matrix estimator and a direct test for heteroskedasticity. Econometrica, 48: 817-838.
CrossRefDirect Link