
A. Akbari
Department of Civil Engineering, University of Malaya, 50603 Kuala Lumpur, Malaysia
A. Abu Samah
Department of Civil Engineering, University of Malaya, 50603 Kuala Lumpur, Malaysia
F. Othman
Department of Civil Engineering, University of Malaya, 50603 Kuala Lumpur, Malaysia
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 20 | Page No.: 3707-3714







ABSTRACT
Several factors influence the interpolation accuracy of point source rainfall data during storms. Types of storm, network density and interpolation method are the most significant factors. Usually, random distributed point source data is converted into regular distributed grids, through the appropriate method. Kriging is a stochastic method that simulates the spatial surface using sample points, based on best-fit Semi-Variogram (SV) models. This study assesses the effect of pixel size on the performance of Kriging interpolation using the Gaussian SV model. Twenty eight rainfall stations located at the upper part of the Klang River Basin (KRB), Malaysia are selected and three storm events are investigated. Simple Kriging interpolation is applied using different pixel size ranges from 50 to 3000 m. This study shows that pixel size is important issue when explaining the spatial pattern of rainfall. Optimal pixel size depends on the variance, minimum distance of pair points or rainfall network density and the visualization requirement. It is difficult to maintain a certain pixel size but based on the drawn result, it can be concluded that a pixel size at the range of 200 to 500 m is more appropriate for this region.
PDF Abstract XML References Citation
How to cite this article
A. Akbari, A. Abu Samah and F. Othman, 2009. Effect of Pixel Size on the Areal Storm Pattern Analysis using Kriging. Journal of Applied Sciences, 9: 3707-3714.
DOI: 10.3923/jas.2009.3707.3714
URL: https://scialert.net/abstract/?doi=jas.2009.3707.3714
DOI: 10.3923/jas.2009.3707.3714
URL: https://scialert.net/abstract/?doi=jas.2009.3707.3714
INTRODUCTION
Representing geo-spatial data in a raster data model requires grid cells definition. The cell size is sensitive to map scale, computer processing power, positional accuracy, point density, spatial autocorrelation structure and complexity of terrain (Hengl, 2006). It also depends on the desired quality of the output map. Pixel size and its impacts on the spatial analysis particularly in rainfall runoff modeling are the focus of several studies. The majority of research focuses on the influence of grid size of Digital Elevation Models (DEMs) for the calculation of the topographic indices (Cai and Wang, 2006) and watershed runoff simulation (Molnar and Julien, 2000). Hengl (2006) showed that using resolution coarser than the coarsest legible resolution means that we are either not respecting the scale of work, positional accuracy, inspection density, size of objects being mapped or the complexity of terrain. Hydrological modeling employs rainfall data as an important variable. As stated by Earls and Dixon (2007), the representation of rainfall data and its accuracy are controlled by the spatial distribution of the rainfall stations and the spatial interpolation methods used which may or may not reflect the reality. Several factors may affect the accuracy of point source rainfall data interpolation such as type of storm, network/gauge density and interpolation methods are important factors. A number of studies on characterizing of rainfall has been carried out in Klang River Basin (KRB) (Niemczynowicz, 1987; Bacchi and Kottegoda, 1995). The results indicate that generally, the spatial correlation of rainfall decreases with distance and different correlation structures are observed during different rainfall events. The spatial extension of thunderstorms, which create most floods, is limited and there are no routines to account for this in design of rainfall (Desa and Niemczynowicz, 1996). There are also errors attached to estimating localized rainfall due to the effects of inadequate temporal resolution, inadequate spatial coverage or network configuration, inadequate gauge density and instrument error (Peters-Lidard and Wood, 1994).
KRIGING THEORY AND APPLICATIONS
Kriging is named after D.G. Krige, a South African mining engineer and pioneer in the application of statistical techniques to mine evaluation. The Kriging technique is derived from the theory of regionalized variables which is the invent of Matheron (1971). This theory is formed based on the observation that the variabilities of all regionalized variables have a particular structure (Journel and Huijbregts, 1978). As an example, a storm event can be characterized by the spatial distribution of a certain number of measurements. More details on the geo-statistical theory, Kriging and its algorithm can be found in (Matheron, 1971; Journel and Huijbregts, 1978; Cressie, 1993; Isaaks and Srivastava, 1990; Webster and Oliver, 2007). Here, some important elements of this theory are presented, according to the Journel and Huijbregts (1978):
Regionalized variable (ReV): When a variable is distributed in space, it is said to be ReV and the phnomeno that the ReV is used to represent is called regionalization (Journel and Huijbregts, 1978). This definition can be extended to almost; all geo-referenced data or spatial variables such as population density, canopy density, water quality, air pollution and so on. In mathematic language, a ReV is a function f (x) which takes a value at every point x, in space. ReV takes two contradictory characteristics, which are a Random Variable (RV) and a certain functional representation. A RV is a variable, which takes a certain number of numerical values according to a certain probability distribution (Journel and Huijbregts, 1978).
Random function (RF): Random function expresses the random and structured aspects of a ReV. These aspects are as follows:
| • | In each point x1,Z(x) is the RV |
| • | Z(x) is also a RF in the sense that for each pair of points x1 and x1+h, the corresponding RFs Z(x1) and Z(x1+h) are not, in general, dependent but are related by a correlation expressing the spatial structure of the initial ReV Z(x) |
Mathematical expectation (first order moment): Consider a random function Z(x) at point x. if the distribution function of Z(x) has an expectation then, this expectation is generally a function of x and is written as:
| (1) |
Second order moments: The three second-order moments considered in geostatistic are as follows:
| • | The variance of Z(x). when this variance exists, it is defined as the second-order moment about the expectation m (x) of the RV Z(x), i.e., |
| (2) |
As with the expectation m(x), the variance is generally a function of x.
| • | The covariance. It can be shown that if the two RVs Z(x1) and Z(x2) have variances at the point x1 and x2, then they also have a covariance which is a function of two locations x1 and x2 and is written as: |
| (3) |
| • | The variogram. The variogram function is defined as the variance of the increment [Z(x1)-Z(x2)] and is written as: |
| (4) |
The function γ( x1 , x2 ) is then the semi-variogram (SV). When the RF is stationary of order 2, mathematical expectation exists and does not depend on the support point x, thus, E {Z(x)} = m. For each pair of RV {Z(x1), Z(x1+h)} the covariance exists and depends on the separation distance h. according to the Eq. 2 and 3 can be drive as follow:
| (5) |
where, h represent vector of coordinates.
The stationarity of the covariance implies the stationarity of the variance and the variogram. The following relations are immediately evident:
| (6) |
| (7) |
The Eq. 4 indicate that under the hypothesis of second-order stationarity, the covariance and the variogram are two equal tools for characterizing the auto-correlations between two variable Z(x+h) and Z(x) separated by a distance h.
Covariance and correlation are measures of the similarity between two different variables, where the data pairs represent measurements of the same variable made some distance apart from each other. The separation distance is usually referred to as lag. The correlation versus lag is referred to as the correlogram and the semi-variance versus lag is the SV. Kriging employs SV model (Bohling, 2005).
In GIS environment, Kriging can be seen as a point interpolation, which requires a point map as input and returns a raster map with estimations and optionally an error map. The estimations are weighted averaged input point values. The weight factors in Kriging are determined by using a user-specified SV model. The estimated values are thus a linear combination of the input values and have a minimum estimation error. The optional error map contains the standard errors of the estimates.
Characteristics of the typical SV are shown in Fig. 1. Sill is the semi-variance value at which the variogram levels off. Range is the lag distance at which the reaches the sill value. Presumably, autocorrelation is essentially zero beyond the range. Nugget is, in theory, the value at the origin (0 lag) should be zero. If it is significantly different from zero for lags very close to zero, then this value is referred to as the nugget, which represents variability at distances smaller than the typical sample spacing, including measurement error. For the sake of it is necessary to replace the empirical SV with an acceptable SV model. Part of the reason for this is that the Kriging algorithm will need access to SV values for lag distances other than those used in the empirical SV. More importantly, the SV models used in the Kriging process need to obey certain numerical properties in order for the Kriging equations to be solvable. Most frequently used models are spherical, exponential, Gaussian and power model.
Barancourt et al. (1992) have provided a comparison of rainfall assessments by a global Kriging and geo-statistical model. The prediction performance is compared by using cross validation. It is found that ordinary Kriging yields more accurate predictions than linear regression when the correlation between rainfall and elevation is reasonable. Karamouz and Araghinejad (2005) applied the Kriging method to evaluate monthly regional rainfall in the central part of Iran. Thavorntam et al. (2007) studied spatial interpolation of mean annual rainfall in a 29 year period using interpolation methods such as Inverse Distance Weighting (IDW), radial basis function and ordinary Kriging.
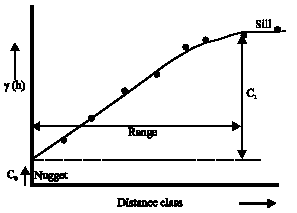 | |
| Fig. 1: | Characteristics of the typical SVSemi-variogram |
They indicated that ordinary Kriging with IDW a spherical model has better performance for interpolation of rainfall within the region of Thailand. However, Dirks et al. (1998) studied interpolation of rainfall data on the Norfolk Island, Australia. Thirteen rain gauges on the area of 35 km2 are used. They found that Kriging did not provide a significant improvement over simple methods like the IDW, the Thiessen and the area mean methods because of the demanding on computations.
MATERIALS AND METHOD
Study area: This study is conducted at University Malaya as a part of postgraduate research project within 6 month started from November, 2008. The study is carried out on the upper parts of the Klang River Basin located in Kuala Lumpur/Malaysia. The Klang Valley is located between 10l° 30’- 10l° 55’ longitude and 3°- 3° 30’ latitude. It falls largely within the state of Selangor and encompasses the entire Federal Territory of Kuala Lumpur (Fig. 2). The basin area at the outlet is about 675 km2. The mean annual rainfall based on the Association of Southeast Asian Nations Climate Atlas for Peninsular Malaysia is about 2400 mm (Tick and Samah, 2004). The elevation above sea level ranges from 20 m at the outlet to 1420 m upstream.
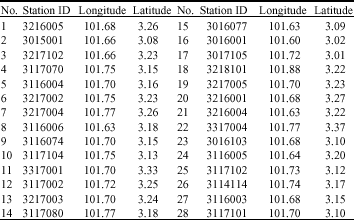
Data set used: Rainfall data for 28 stations located at the upper Klang river basin are collected form Department of Irrigation and Drainage (DID) of Malaysia. General characteristics of the rainfall stations such as ID that is the key code indicated by DID and geographic coordinates of stations are provided in Table 1.
Software used: The Integrated Land and Water Information System (ILWIS) which is free raster-GIS software, developed by International Institute for Geo-Information Science and Earth Observation (ITC), The Netherlands (Koolhoven et al., 2007) is used for this study.
| Table 1: | General information of rainfall stations used in this study |
 | |
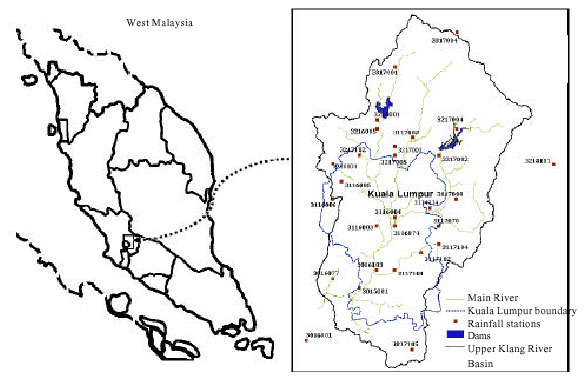 | |
| Fig. 2: | Study area and rainfall stations network at upper Klang River Basin |
Available at http://www.itc.nl/ilwis/default.asp.
RESULTS AND DISCUSSION
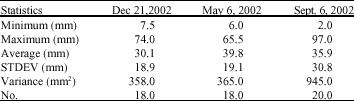
The three random rainfall events occurred on May 6, Sep. 6 and Dec. 21 in the year 2002, are selected. General statistics such as minimum, maximum, average, standard derivation and variance are calculated for the selected events (Table 2). A point map is generated based on available rainfall stations shown in Fig. 2. Total recorded rainfall in each station for that particular date is then linked to the point map as attribute. Spatial autocorrelation (Odland, 1988) applied to estimate the Kriging parameters included nugget, sill and range effects (Borgan and Vizzaccaro, 1997). As shown in Fig. 3, Gaussian SV model fits through the experimental SV, resulted from spatial autocorrelation as better model compared to the exponential and spherical model (Akbari et al., 2008). Simple Kriging is used, because no certain direction can be found in the storm propagation in this region (Desa and Niemczynowicz, 1996). Kriging interpolation technique is then applied to the selected storms. Different Pixel size range from 50 to 3000 m is examined for all storms. Kriging interpolation using point map in ILWIS provides raster map with predefined pixel size.
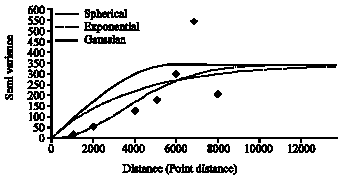 | |
| Fig. 3: | Experimental and empirical SVs for the event of 21 December, 2002 |
| Table 2: | Statistical summaries of investigated storm events |
 | |
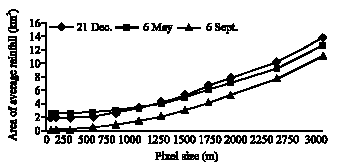
A histogram is made for the raster map including pixel values and the corresponding number of pixels, the fraction of total pixels, the area and statistical summaries including minimum, maximum, average, standard deviation and summation of cell values. Table 3 is provided as an example for derived statistical summaries of rainfall event of Dec 21, 2002. This table does not provide for the two o ther events. However, a comparison is presented to show the variation of pixel size with the estimated average rainfall (Fig. 3, 4), standard deviation (Fig. 5), area allocated by average rainfall (Fig. 6).
| Table 3: | Statistical summaries of raster map showing Kriging interpolation based on different pixel size for the Storm Dec 21 2002 |
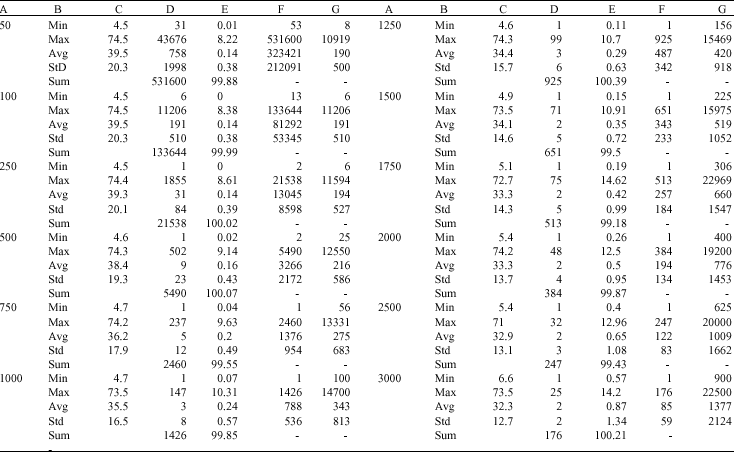 | |
| A: Pixel size (m), B: Statistical terms, C: Total rainfall during the storm (mm), D: The number of pixels with a certain value or meaning (pixel frequencies), E: The cumulative percentage of pixels with this value or a smaller value (%), F: The relative cumulative numbers of pixels with this value or a smaller value as a percentage of the total number of pixels in the map, G: The area of pixels with a certain value or meaning as D* pixel size *pixel size (m2) | |
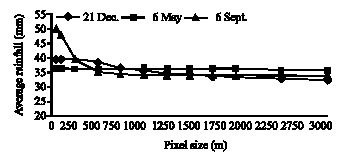 | |
| Fig. 4: | Variations of average rainfall vs. pixel size |
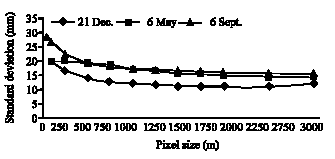 | |
| Fig. 5: | Standard deviation of cell values vs. pixel size |
One can see the variation of pixel size with the total number of pixels assigned by maximum value in that particular pixel size in Fig. 7 and file size, which is important in computer processing and allocating memory in Fig. 8.
 | |
| Fig. 6: | Variation of area representing the average rainfall vs. pixel size |
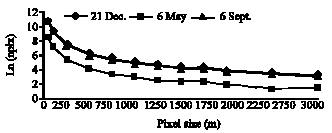 | |
| Fig. 7: | Variation of number of pixel assigned by maximum value vs. pixel size |
Finally, we examined the effect of pixel size on the visualization, which is shown in Fig. 9a and b and 10. These maps are based on the storm event of Dec 21, 2002.
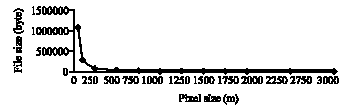 | |
| Fig. 8: | Variation of file size vs. pixel size |
Rainfall distribution in space can be explained by the standard deviation and variance of samples. Statistical analysis for the recorded rainfall at the rainfall stations indicates the high variance for the event of Sept. 6, 2002 compare to the 2 other investigated events. Based on the results of the interpolations, it is possible to interpret the spatial variation of rainfall based on the investigated pixel size and its effect on the statistical terms such as average, standard deviation and area related to the maximum value in each map. As shown in Fig. 4, the average rainfall is sensitive to the pixel sizes at about 50-750 m. Almost in three tested storms, average rainfall does not change by taking the pixel size larger than 750 m. Based on the variance of the events; different trends can be seen for each event. For example, for the event of Sept. 6, 2002 that is the highest variance (945) among the samples, average value is more sensitive to the pixel size. However, for the storm event on the Dec. 21, 2002 that has the lowest variance, variation of the average value is not sensitive to the pixel size. That means the enlargement of grid resolution leads to aggregation or up scaling and the decrease of grid resolution leads to disaggregation or down scaling (Hengl, 2006). As the grid becomes coarser, the overall information content in the map decreases progressively and vice versa (Hengl, 2006). Figure 5 shows almost the same trend for the variaton of pixle size with standard deviation. The trends shown in this figure imply on the sensitivity of the standard deviation to the pixel size from 50 to 750 m. The number of pixels in the raster map also expresses the surface values. Figure 6 shows the variation of pixel size in relation to the area coreponding to the mean value for three storms. It can be seen that the area related to the mean value increases by selecting coarser pixel size at an exponential rate. This is due to the smoothing effect of a mean value increases by selecting coarser pixel size at an exponential rate. This is due to the smoothing effect of a larger pixel size. The smoothing effect is confirmed by Fig. 7, which illustrates the variation of the number of pixeles assigned by the maximum value for different pixel size in three investigated events. High sensitivity can be found for the pixel sizes at about 50 to 500 m. Figure 8 shows clearly the effect of the pixel size on the size of file.
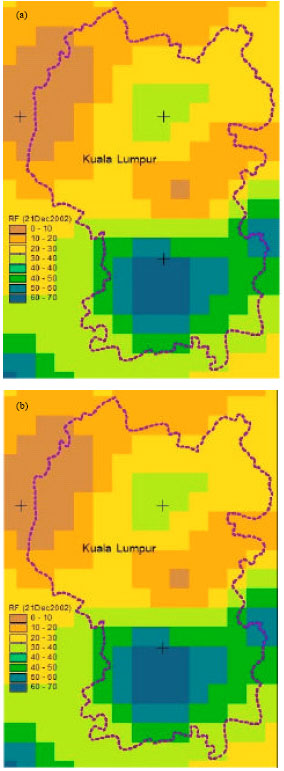 | |
| Fig. 9: | Storm distribution based on the Kriging interpolation for different pixel size (a) (1250 m) and (b) (50 m) |
This become important issue when working with database and transfering and analyzing raster data. Selection of the optimal pixel size facilitates the easier transfer and processing.
 | |
| Fig. 10: | Isorain lines derived from the Kriging interpolation for different pixel size (1250 m), left, (50 m), right |
Eventually, a comparison is made to show the performance of pixel size on the spatial distribution of rainfall derived from kriging interpolation (Fig. 9). These two maps emphesize the effect of pixel size on the visualization especially when isoline is derived (Fig. 10).
CONCLUSION
This study shows clearly that pixel size has a significant influence on storm pattern analysis. Variance of the rainfall over the area has a meaningful effect on the selection of the legible pixel size and therefore, on the result of points interpolation. In fact, variance is comparable with the complexity of terrain when Digital Elevation Model (DEM) is generated from the points or contour lines. It can be concluded that the rainfall variance over the space is important factor in selecting appropriate pixel size when using Kriging interpolation. High variance leads to take the small pixel sizes and low variance leads to take larger pixel size. It is because of the fact that small pixel size is more able to explain the rainfall variation. No ideal pixel size exists, but rather a range of suitable pixel size. Optimal pixel size will depend on the variance, minimum distance and the visualization requirement. It is recommended to select a smaller pixel size when the variance of the source point values is high. Small pixel size provide better visualization but generates larger file size. Raster maps in Fig. 9, results from Kriging interpolation for the rainfall event of 21 Dec. 2002. As shown in Fig. 10, small grid size is more advisable when contour line drawing is required from the raster map. Hence, one can report that variation of average rainfall to the pixel size illasterates sensitivity of the pixel size to the rainfall variance and recommended range of pixel size at 200 to 500 m scale in this region. Pixel size has a cosiderble effect on the visualization and the file size.
ACKNOWLEDGMENTS
Financial support of this study is provided by University of Malaya through the research fund project number PS017/2007B. Rainfall data provided by DID Malaysia. We would like to appreciate to all DID staffs of hydrologic section for kindly communication. We also appreciate ITC for providing free GIS software. Valuable contribution of Professor Azizan Abu Samah is appreciated.
REFERENCES
- Bacchi, B. and A.N.T. Kottegoda, 1995. Identification and calibration of spatial correlation patterns of rainfall. J. Hydrol., 165: 311-348.
CrossRefDirect Link - Barancourt, C., J.D. Creutin and J. Rivoirard, 1992. A method for delineating and estimating rainfall fields. Water Resour. Res., 28: 1133-1144.
Direct Link - Borgan, M. and A. Vizzaccara, 1997. On the interpolation of hydrologic variables: Formal equivalence of multi quadratic surface fitting and kriging. J. Hydrol., 195: 160-171.
Direct Link - Desa, M.N. and J. Niemczynowicz, 1996. Spatial variability of rainfall in Kuala Lumpur, Malaysia: Long and short term characteristics. Hydrol. Sci. J., 41: 345-362.
Direct Link - Dirks, K.N., J.E. Hay, C.D. Stow and D. Harris, 1998. High-resolution studies of rainfall on Norfolk Island: Part II: Interpolation of rainfall data. J. Hydrol., 208: 187-193.
CrossRefDirect Link - Molnar, D.K. and P.Y. Julien, 2000. Grid-size effects on surface runoff modeling. J. Hydrol. Eng., 5: 8-16.
Direct Link - Obled, C., J. Wendling and K. Beven, 1994. The sensitivity of hydrological models to spatial rainfall patterns: An evaluation using observed data. J. Hydrol., 159: 305-333.
Direct Link - Peters-Lidard, C.D. and E. Wood, 1994. Estimating storm areal average rainfall intensity in field experiments. Water Resour. Res., 30: 2119-2131.
Direct Link - Cai, X. and D. Wang, 2006. Spatial autocorrelation of topographic index in catchments. J. Hydrol., 328: 581-591.
CrossRefDirect Link