
M.L. Othman
Department of Electrical and Electronic Engineering, Faculty of Engineering, Universiti Putra Malaysia, Malaysia
I. Aris
Department of Electrical and Electronic Engineering, Faculty of Engineering, Universiti Putra Malaysia, Malaysia
S.M. Abdullah
Department of Electrical and Electronic Engineering, Faculty of Engineering, Universiti Putra Malaysia, Malaysia
M.L. Ali
Institute of Information and Communication Technology, Bangladesh University of Engineering and Technology, Bangladesh
M.R. Othman
Tenaga Nasional Berhad, Malaysia
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 19 | Page No.: 3433-3453







ABSTRACT
In this study rough-set-based data mining strategy was formulated to discover distance relay decision algorithm from its resident event report. This derived algorithm, aptly known as relay CD-prediction rules, can later be used as a knowledge base in support of a protection system analysis expert system to predict, validate or even diagnose future unknown relay events. Nowadays protection engineers are suffering from very complex implementations of protection system analysis due to massive quantities of data coming from diverse points of intelligent electronic devices. In helping the protection engineers deal with this overwhelming data, this study relied merely on digital protective relay’s recorded event report because, among other intelligent electronic devices, digital protective relay sufficiently provided virtually most attributes needed for data mining process in knowledge discovery in database. The method of discovering the distance relay decision algorithm essentially involved formulating rough set discernibility matrix and function from relay event report, finding reducts of pertinent attributes using genetic algorithm and finally generating relay prediction rules. The classification accuracy and the area under the ROC curve measurements provided an acceptable evaluation of the fact that the discovered relay decision algorithm.
PDF Abstract XML References Citation
How to cite this article
M.L. Othman, I. Aris, S.M. Abdullah, M.L. Ali and M.R. Othman, 2009. Discovering Decision Algorithm from a Distance Relay Event Report. Journal of Applied Sciences, 9: 3433-3453.
DOI: 10.3923/jas.2009.3433.3453
URL: https://scialert.net/abstract/?doi=jas.2009.3433.3453
DOI: 10.3923/jas.2009.3433.3453
URL: https://scialert.net/abstract/?doi=jas.2009.3433.3453
INTRODUCTION
Modern microprocessor-based Intelligent Electronic Devices (IEDs) provide a large amount of data about power system operations and protection schemes. Using suitable data mining and analysis techniques, relevant information from the stored event and fault reports and oscillography and setting files can be analyzed for the purpose of improving utility protection quality. In doing so, protection engineers are nowadays suffering from data overload: more data than can be processed and assimilated for knowledge discovery and decision support in the time available (Kezunovic, 2001). The massive quantities of data coming from diverse points of IEDs in vast array of implementations make analysis of protection system analysis a very complex area of study. Automatically collecting, filing and managing large volumes of IED data is a monumental task (Makki and Makki, 2001). To help the protection engineers come to term with the crucial necessity and benefit of deriving the knowledge of relay decision algorithm without the uneasiness of dealing with overwhelming data, this study presents the application of rough set based data mining onto recorded data resident in Digital Protective Relay (DPR) alone. This study goes to illustrate the unneeded dealing with data from other IEDs to ease the protection analysis task.
Since, the inception of the microprocessor-based protective relay, the protection analysis research has advanced with new developments being pursued involving application of intelligent system technologies with Artificial Intelligence (AI) methods as the main thrusts and utilization of Intelligent Electronic Devices (IEDs) recorded data, inseparably (Kezunovic, 2001). This is due to the fact that problem involving protection system is usually nonlinear, wide-scale and an amalgamation of integral subsystems, where various artificial intelligence techniques in combination with different IEDs have been extensively explored and successfully implemented with (Negnevitsky and Pavlovsky, 2005). Such AIs include Expert Sys tem (ES) for protective relay operation analysis (Kezunovic et al., 1998; Luo and Kezunovic, 2005), Artificial Neural Network (ANN) as a support of protection analysis (Kezunovic and Perunicic, 1996; Kezunovic et al., 1998; Yang et al., 1994; Alves da Silva et al., 1996; Souza et al., 2001; Negnevitsky and Pavlovsky, 2005) and Event Tree Analysis (ETA) technique to implement the transmission protection system analysis (Zhang and Kezunovic, 2004, 2006). Rough Set Theory (RST) has also been successfully used to determine power system conditions in terms of faults and protection system operations (Hor and Crossley, 2005, 2006a, b; Hor et al., 2007).
The following issues related to the previous works have been the motivation in the current work of rough-set-based data mining to discover distance relay decision algorithm from its resident event report:
| • | The primary aim of integrating intelligent techniques with various IEDs such as those implemented by Kezunovic and Perunicic (1996), Kezunovic et al. (1998), Yang et al. (1994), Alves da Silva et al. (1996), Souza et al. (2001), Negnevitsky and Pavlovsky (2005), Zhang and Kezunovic (2004, 2006), Hor and Crossley (2005, 2006a, b), Hor et al. (2007), Xu and Peters (2002) and Magro and Pinccti (2004) is mainly for fault response analysis or protection performance analysis approaches geared towards protection system of a specific scale of power system such as distribution systems or specific span of transmission systems rather than detailed validation and diagnosis of digital protective relay behavior analysis using data from the relays alone |
| • | The most widely referred recording equipments for recorded data retrieval in fault response analysis have been such IEDs as (DFRs), SCADA’s Remote Terminal Units (RTUs), Sequence of Event Recorders (SERs), Cbs, Fault Locators (FLs) and IEDs specially used for variety of monitoring and control applications. These equipments are, unfortunately, prohibitively expensive and most utilities have them installed only in large substations (Kezunovic, 2001). In fact, they hold little information of internal protective relay states (Luo and Kezunovic, 2005) |
Thus, the study will focus on using the recorded relay event report to discover the relay decision algorithm in the form of prediction rules. This so called Knowledge Discovery in Database (KDD) of relay operation characteristics shall be implemented using an intelligent rough-set-based computation. Many of the above works focus on system rather than device in the protection operation analysis. The emphasis of the work in this study is mainly formulating the rough-set-based data mining strategy of relay event report derived from DPR under analysis and see how this strategy makes detailed device-level relay decision algorithm extraction possible. Only protective relays can provide the relay target data which is obviously absent or not fully available in SERs, DFRs and SCADA RTUs (Smith, 2001).
MATERIALS AND METHODS
According to the rough set philosophy, every object of the universe of discourse is assumed to be associated with some information (data, knowledge). For instance, if the sequential times of events in event report of protective relay operation are objects, the measurands of ac voltages and currents and the state of protection elements form information about time (i.e., the behavior or condition of the relay at different time instances).
The basic operations of rough set theory are used to discover fundamental patterns in data. It removes data redundancies and generates the decision rules using an approximation concept. Unlike crisp sets, each rough set has boundary line cases, i.e., objects that cannot be classified with certainty either as members of the set or of its complement. Rough set theory is an alternative tool in intelligent data analysis and data mining that can be employed to handle uncertainty and vagueness (Pawlak, 2002).
The crux of rough set based data analysis is a decision system, which is a tabulated data set of knowledge representation system, whose columns are labeled by attributes, rows are labeled by objects/events of interest and entries of the table are attribute values (Pawlak, 2002). This criterion fits the protective relay event report whose layout is characterized by its sequence of time stamped events versus attributes of relay multifunctional elements. The information system manifested in the protective relay event report is more appropriately referred to as relay decision system which will be recognized as DT for decision table.
It is usually very difficult to select a group of effective attributes to fully reflect relay behavior because of the highly non-linear nature of relay operation analysis. The selected attributes seldom provide adequate knowledge to accurately map the interclass boundary, making the inter-class boundary usually rough. In other words, some cases close to the boundary are practically unclassifiable based on the selected attributes. Therefore, the protective relay operation analysis is actually a rough classification problem where there are small overlaps between the different classes. Of particular interest is the case where upon fault inception, a protective relay picks it up and provides a common combination of tripping conditions in time sequence succession but having two distinct representations (classifications) in tripping decision: one when trip signal has not been asserted immediately after relay pick-up and the other is when trip signal is asserted, after a preset time delay as set by the protection engineer. Thus, rough set theory suits the bill in resolving this conflict.
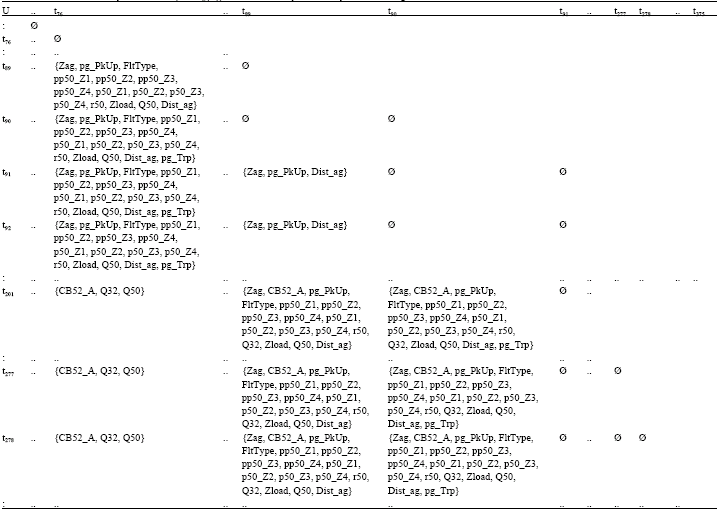
The pre-data-mining decision system DT of a PSCAD/EMTDC-modeled distance protective relay, after having been subjected to zone 1 A-G fault, is shown in Table 1. This relay DT is a representation of the distance relay behavior in relation to its quadrilateral tripping characteristics of phase-ground impedance element (i.e., condition attribute Zag) as shown in Fig. 1. From Table 1, the A-G fault in as far as the modeled distance protection is concerned is more appropriately taken to be related to which zone of protection the relay has acted upon. At event t90, the condition attribute Zag takes on the value of 123. By the nature of the distance relay being a quadrilateral type as shown in Fig. 1, this value is considered to be the concurrent occurrence of the A-G fault in all three zones 1, 2 and 3. In quadrilateral distance relay, the encapsulating nature of its operation characteristic suggests that Zag = 123 would mean that zone 1 is the priority indication of fault occurance for which the relay would refer to function correctly according to the preset time for zone 1 operation (usually instantaneously (Z1onT) or as constrained by digital sampling of data, i.e., immediately after one time step).
The power system upon which the relay is to protect is a 500 kV double-sourced transmission system modeled in the PSCAD/EMTDC as shown in Fig. 2. The top level models of distance relays R1 and R2 protecting the required sections as well as the corresponding models for CTs, CCVTs and the circuit breaker auxiliary contacts are also illustrated.
The relays are modeled based on the commercially available device by AREVA model MiCOM P441 that is used by TNB (a Malaysian utility company) in their transmission line protection (AREVA, 2006). Where design details are not explicitly divulged cross reference is made to the Schweitzer Engineering Laboratories Inc.’s SEL321 relay (SEL, 2007). This integrated approach is merely for academic purpose so that any desired multifunctional elements of distance relay can be reasonably modeled, parameters tuned and simulated results apprehensionably studied. This is simply for the sake of generating desired numerical relay event report suitable for relay operation analysis using an intelligent data analysis process called Knowledge Discovery in Database, KDD.
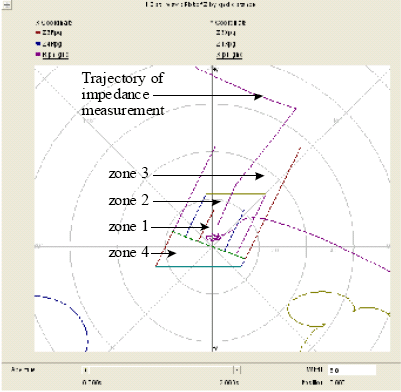 | |
| Fig. 1: | Zone-1-A-G-fault imposed distance relay behavior in relation to its quadrilateral tripping characteristics of a phase-A-to-ground impedance element (i.e., condition attribute Zag) with impedance measurement trajectory |
| Table 1: | Pre-data-mining DT of distance protective relay subjected to zone 1 A-G fault. (“.” denotes data patterns that are similar to events immediately before and after them. Thus, they are not presented in order to reduce the table dimension) |
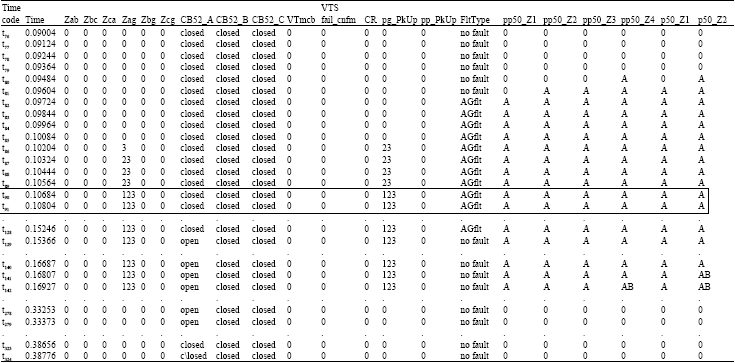 | |
| Table 1: | Continued |
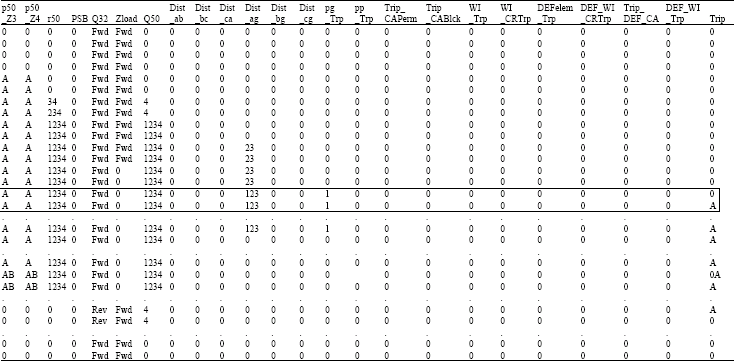 | |
| Block area: Inconsistent decision patterns between these events (i.e., similar condition attributes but the decision attribute Trip goes from 0 to A) that can be immediately recognized to have association with tripping signal assertion for CB | |
This decision system is a 4-tuple structure DT = ⟨U, Q, V, f⟩ where,
| • | U is a finite set of instances/objects (relay events) ti’s, i.e., the universe denoted as U = {t1, t2, t3, …, tm} |
| • | Q = C ∪ D is a non-empty finite union set of condition and decision attributes (condition attributes ci ⊂ C denote the internal multifunctional protective elements, while decision attribute di ⊂ D denotes the trip output of the relay), such that q: U → Vq for every q ε Q |
| • | V = Uq∈Q Vq and Vq, is a domain (set of values) of the attribute q |
| • | f: UxQ → V is a total function, called information function (alternatively denoted ρ) such that f(t,q) ε Vq for every q ε Q, t ε U. Any pair (q,v), where q ε Q and v ε Vq, is called descriptor in DT |
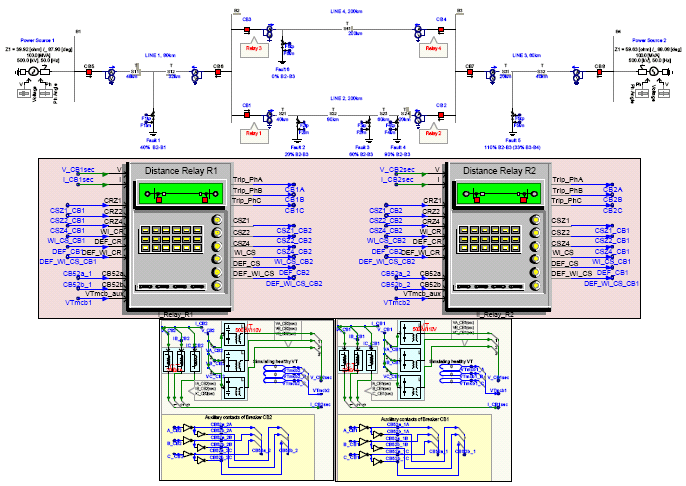 | |
| Fig. 2: | 500 kV double sourced transmission system single line and distance relay models |
The relay decision table DT has been prepared using a strategy involving such processes as data selection, preprocessing and transformation (attribute construction and descritization) of a simulated raw relay event report in IEEE COMTRADE format which are essential in knowledge discovery in relay database. In order to ease up somewhat in handling the data mining strategy, the prepared relay decision system DT has actually been further simplified by removing relay events having repetitive pattern of data without affecting the original relay equivalence relations. For example, relay events t1 to t75 and t325 to t375 which are rows of data patterns prior to fault inception and after CB/trip reset, respectively, are actually repetitive and have been done away with. Some inconsistent patterns are evident in the decision system of which we can recognize to have association with the decision attribute Trip going from 0 to A, inferring tripping signal assertion of CB. This shall be one of a number of aspects that shall be considered when protective relay analysis is done using rough set theory technique.
Data mining in discovering relay CD-decision algorithm: Proceeding ahead in the KDD process in this study, the data mining essentially adopts the computational intelligent techniques of rough set theory and genetic algorithm to discover the behavior of a distance protective relay. The previously prepared discrete database of relay events is skimmed through the computational intelligence in order to discover the useful knowledge of relay operation logic in terms of classifying as well as associating the behavior of its various resident protective elements (conditions) with the resulting trip assertions (decisions). This motivates the exploitation of condition attributes and decision attributes. The eventually captured knowledge known as relay CD-decision algorithm (reeling from the condition-decision attribute relationship) is mainly categorized in what is referred in data mining as dependence model. In principle, all the relay prediction rules or their variant classification rules as well as association rules that are going to be discovered boil down to a mere dependence relationship between rule antecedent and consequent. It can be seen later that this intelligent learning approach of dependence modeling particularly focuses on extracting relay prediction/association rules off the inherent structural patterns of the relay decision system DT (i.e., the previously prepared relay event data).
Different usages of relay CD-decision algorithm: The data mining methods based on rough set theory and genetic algorithm that are employed in the derivation of relay CD-decision algorithm (C⇒D) are targeted at two main purposes:
| • | Generation of relay CD-prediction rules |
for classification and
| • | Generation of relay CD-association rules |
for domain analysis
Since, the generated rules serve the two main purposes of prediction (specifically classification) and domain (association) analysis, there are different constraints on the formats of the two types of rule sets and the methods by which they are generated (Roed, 1999). Our main subject matter in this study is to generate the relay CD-prediction rules
for classification. To allay possible confusion in subsequent sections of this study, the notation of CD-prediction rules
is sometimes denoted as simply CD-decision algorithm C ⇒ D. The generation of relay CD-association rules
for domain analysis of relay operation logic is discussed in a different study.
Generating relay CD-prediction rules ![]() : Relay CD-prediction rules
: Relay CD-prediction rules
are to be generated for use in the prediction of protective relay behavior based on time stamped events. This aims at predicting the outcomes of unseen events. The rules are generated from a set of relay events and then used to predict new future events. For example, prediction rules derived from a relay that has been subjected to various kinds of fault contingencies (supervised learning) can be used in the hypothesization of the relay’s behavior (unsupervised learning) in the unknown future power system conditions. The discovered logical pattern of the relay CD-prediction rules relating descriptions of conditions (attributes for various protective relay multifunctional protection elements) and decision class (attribute for trip assertion status) has the form:
| (1) |
where, {ci (i = 1…k)} ε C is a set of conditional attributes, {d} ⊆ D is the decision attribute, vck ε Vck, domain (set of values) of the conditional attribute ck, vd ε Vd, domain (set of values) of the decision attribute d, ck = vck is called predictor, d = vd is called decision class/descriptor.
As the name suggests, relay CD-prediction rules are in general a representation of dependence modeling between condition attributes and decision attribute. The direction of the dependence can be either way, i.e., can be interpreted as either the value of decision attribute depends on the relevant condition attributes values or the relevant condition attributes values predict the value of decision attribute. The former interpretation is more aptly referred to as CD-classification rules because of the single goal/decision attribute that has to be in a rule consequent and has to be classified by a number of condition attributes (predictors) in the rule antecedent. Classification rule is a special case of prediction rule in a sense that, in the latter, more than one goal attribute can occur in the rule consequent. In fact in prediction rule, these goal attributes can occur either in a rule consequent or in a rule antecedent – but not in both parts of the same rule. Different prediction rules can have different goal attributes in their consequent; unlike the classification task, where all rules have the same attribute in their consequent (Freitas, 2008).
The generated CD-classification rules may not necessarily be on a format that is easily understood by a protection engineer because the rule set is a collection of many rules (Roed, 1999). In other words, the CD-classification rule set may not necessarily be filtered to trim the number of its component rules.
Data mining analysis steps: The important analysis steps in the framework of integrated rough-set-and-genetic-algorithm data mining under the ROSETTA environment (Ohrn, 2000) for deriving the distance relay CD-decision algorithm from the relay event database is shown in Fig. 2. The steps involved are:
| • | Computation of reducts, within which the following decomposed multi steps are executed: |
| • | Computation of the D-discernibility matrix of C (i.e., MC(D)) |
| • | Subsequent derivation of the discernibility function fC(D) in Conjunctive Normal Form (CNF) (also called POS form in Boolean algebra) from MC(D). The CNF is reduced to final form after absorption law and omission of duplicates of disjunctive terms (sums) are applied minus multiplication among each of the disjunctive terms of the final CNF |
| • | In empirical database such as relay event data analysis, calculation towards getting the final Disjunctive Normal Form (DNF) (which is obtained if the above multiplication among each of the disjunctive terms of the final CNF is performed) in order to find the eventual reducts is extremely computationally intensive. In this case the generation of reducts is considered as an NP-hard problem (Hochbaum, 1996). Thus, genetic algorithm is devised to compute approximations of reducts by finding the minimally approximate hitting sets (analogous to reducts) from the sets corresponding to the discernibility function (Ohrn, 1999; Vinterbo and Ohrn, 2000) |
| • | Generation of CD-prediction rules |
of which the above reducts serve as the templates for the rules to be created from. This is principally done by superimposing each reduct in the reduct set over the reduct set’s parent decision table DT = ⟨U, C∪D, V, f ⟩ and reading off the domain values of the condition and decision attributes. The resulting logical patterns of C⇒D relating descriptions of condition and decision classes have the representation shown previously in Eq. 1
Let the set of minimal prediction rules over DT be hereby designated as ALG(DT), i.e.,
| (2) |
Where:
is the set of minimal prediction rules ![]() for an event t ε U, i.e.,
for an event t ε U, i.e.,
| (3) |
(This generation of ALG(DT) is more suitably called pre-pruning in the context of deriving filtered CD-association rules)
The generation of CD-prediction rules will be evaluated as follows:
| • | The entire original relay data set DT is partitioned into training and test sets using k-fold cross validation technique |
| • | Estimating classification performance of relay CD-decision algorithm by rules firing-voting strategies |
Figure 3 shows in detail the data mining using the combined computational techniques of rough set theory and genetic algorithm. Data mining is as an integral process in a Knowledge Discovery in Database (KDD) strategy. The procedure for discovering the CD-association rules
after being filtered (post-pruned) using rule quality measure from the generated CD-prediction rules
is not discussed in this study.
Estimating classification performance of relay CD-decision algorithm by testing: Previously, relay CD-decision algorithm has been defined as a rule-based classifier expressed as:
| (4) |
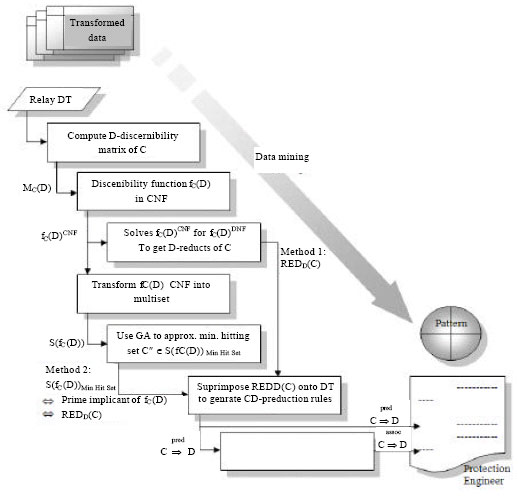 | |
| Fig. 3: | Analysis steps in the framework of rough set data mining |
which when applied to a time-stamped relay event t ε U in a relay decision system DT, it predicts a classification of trip status ![]() of t, i.e.,
of t, i.e.,
| (5) |
The true (actual) classification of trip status of t is denoted as dt.
By testing the set ALG(DT) of relay rules as a classifier upon unknown-class events in an independent test set(s), measures recorded by ![]() and dt for predicted and true trip statuses respectively give us an estimate of the algorithm’s classification performance. If the classification performance estimate in the testing scheme is satisfactory, then the ALG(DT) is ready to be used to predict new unknown future relay events for relay operation correctness analysis, after which yet another classification performance is estimated to validate the algorithm’s generalization ability.
and dt for predicted and true trip statuses respectively give us an estimate of the algorithm’s classification performance. If the classification performance estimate in the testing scheme is satisfactory, then the ALG(DT) is ready to be used to predict new unknown future relay events for relay operation correctness analysis, after which yet another classification performance is estimated to validate the algorithm’s generalization ability.
Relay CD-prediction rules firing and voting in relay event classifications: The generated relay CD-decision algorithm expressed as ALG(DT) is basically a rule-based classifier set which is used to classify new and unseen relay events from test data set or different batches of DT than that used to discover it. Relay event classification strategy involves three main steps, in the following order:
| • | CD-prediction rule firing: Firing a rule if its antecedent matches that of a presented relay event |
| • | CD-prediction rule voting: Casting votes by each firing rule in favour of its trip decision class (i.e., d = vd : vd ε Vd = {0, A, B, C, ABC}) |
| • | Relay event classification: Classifying a relay event to a trip decision class via certainty factor maximization |
Classification algorithm provided by Ohrn (2000) can be used as a framework to carry out the classification strategy. Letting the ALG(DT) be abbreviated as simply ALG which represents the set of relay CD-prediction rules
Fig. 4 summarizes the steps involved in a relay event classification.
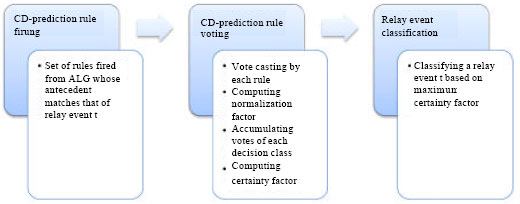 | |
| Fig. 4: | Steps involved in relay event classification |
| Table 2: | Confusion matrix defining performance of the relay CD-decision algorithm |
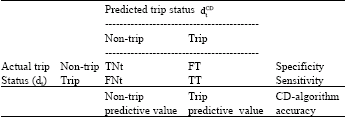 | |
| Vnon-trip = {0}; Vtrip = {A}, {B}, {C}, or {ABC}; TT = True Trip: Number of events satisfying trip criteria in antecedent C and having actual class Trip (i.e., correct classification); FT = False Trip: Number of events satisfying trip criteria in antecedent C but not having actual class Trip (i.e., incorrectly predicted as Trip when it is actually Non-trip); Tnt = True Non-trip: Number of events not satisfying trip criteria in antecedent C nor having actual class, Trip (i.e. correct classification); Fnt = False Non-trip: number of events not satisfying trip criteria in antecedent C but having actual class Trip (i.e., incorrectly predicted as Non-trip when it is actually Trip) | |
Confusion matrix: Hand suggested that the performance of a single classification rule can be summarized by a confusion matrix (Hand, 1997; Weiss and Kulikowski, 1991). However, confusion matrix can also be constructed containing information about the performance of a set of rules (Freitas, 2008) such as in the case of relay CD-decision algorithm.
The 2×2 confusion matrix tailored to the protective relay operation perspective is formulated in Table 2 and 3, based on the concept given by Witten and Frank (2005). In most distance relay trip operations, the generated event reports (decision tables) usually present data patterns with events classified as either one of the two trip states, the so-called negative class Non-trip (= 0) or any one of the types of impending pole trip, that is the so-called positive class Trip (which is represented by A for a single phase-A-pole trip, B for a single phase-B-pole trip, C for a single phase-C-pole trip, or ABC for a three-pole trip). The relay CD-decision algorithm generated from this two-state event report is appropriately called as a binary classifier.
| Table 3: | Interpretation of the relay CD-decision algorithm confusion matrix |
 | |
Each matrix element shows the number of test relay events for which the actual trip status (dt) is the row and the predicted trip status ![]() is the column. Good results correspond to large numbers down the main diagonal and small, ideally zero, off-diagonal elements.
is the column. Good results correspond to large numbers down the main diagonal and small, ideally zero, off-diagonal elements.
RESULTS
The constructed D-discernibility matrix of C (i.e., MC(D)) is shown in Table 4 for some elements. Note that an element of MC(D) is defined as the set of all condition attributes which discern the relay events ti and tj which do not belong to the same equivalence class of the relation U|IND(D). U denotes empty set suggesting indiscernibility between the two corresponding relay events of the universe. U denotes universe of finite set of relay events tn. Shaded elements denote that the symmetricalness of the matrix warrants only the lower diagonal part to be sufficiently considered for formulating discernibility function, fC(D).
| Table 4: | The D-discernibility matrix of C (i.e. MC(D)) for distance relay decision system involving zone 1 A-G fault |
 | |
Formulating discernibility function: The discernibility function, fC(D), in Conjunctive Normal Form (CNF) (i.e., Product of Sum (POS) as normally called in digital electronics) is derived from the D-discernibility matrix of C (i.e., MC(D)) by converting each set of attributes in the non-empty matrix elements as a sum expression of attribute names (hereby called disjunctive terms). Then, all the derived sums (totaling a whopping seventeen thousand seven hundred and eighty three!) are ANDed together to form a complete CNF. Since, we are dealing with Boolean algebra in solving fC(D), in which the attribute names are the Boolean variables, this huge quantity of disjunctive terms can be further simplified by removing duplicate sums and supersets. Duplicate sums can be eliminated using the multiplicative indempotence property of Boolean algebra (Ohrn, 1999), for example:
(CB52_A + FltType + Dist_ag + pg_Trp) * (CB52_A + FltType + Dist_ag + pg_Trp) = (CB52_A + FltType + Dist_ag + pg_Trp)
Sums that are being supersets of other sums in fC(D) can be safely eliminated using absorption property of Boolean algebra, for example:
(CB52_A + FltType + Dist_ag + pg_Trp) * (CB52_A + FltType + p50_Z2 + p50_Z3 + p50_Z4 + Dist_ag + pg_Trp) * (CB52_A + FltType + pp50_Z4 + p50_Z2 + p50_Z3 + p50_Z4 + Dist_ag + pg_Trp) = (CB52_A + FltType + Dist_ag + pg_Trp)
The final CNF form of the discernibility function, after duplicate and superset removal while fully preserving the function’s semantic, is expressed as:
fC(D)CNF = (Zag + CB52_A + pg_PkUp + FltType + pp50_Z3 + pp50_Z4 + p50_Z1 + p50_Z2 + p50_Z3 + p50_Z4) * (Q50) * (Zload) * (Q32) * (pp50_Z4 + p50_Z2 + p50_Z3 + p50_Z4 + r50) * (Zag + pp50_Z4 + r50) * (Zag + pg_PkUp + Dist_ag + pg_Trp) * (Zag + CB52_A + pg_PkUp + FltType + Dist_ag) * (pg_PkUp + pp50_Z1 + pp50_Z2 + pp50_Z3 + pp50_Z4 + p50_Z1 + r50) * (CB52_A + FltType + Dist_ag + pg_Trp)
The disjunctive terms in the above discernibility function fC(D) can be subsequently multiplied among each other to transform into a finally minimal Distunctive Normal Form (DNF) (i.e., Sum of Product (SOP) as normally called in digital electronics). The discernibility function in its minimal DNF form is an alternative depiction of the protective relay decision system DT in terms of prime implicants of fC(D). The prime implicants of fC(D) reveal the minimal subsets of C that are needed to discern all distinct relay events in U from each other (in which dispensable attributes have been removed and yet the indiscernibility relation U|IND(D) of DT is still preserved) (Ohrn, 1999). Thus, all constituents that are in the minimal DNF form of the function fC(D) are all D-reducts of C (REDD(C)) which form the templates for the generation of minimal relay CD-decision algorithm (decision rules). Unfortunately, as evidently shown by the numerous instances of attributes in each constituent of the final CNF form of fC(D) and the appreciable domain dimension (various values) of attributes, calculation towards getting the final DNF in order to find the eventual reducts is extremely computationally unwieldy and thus NP-hard. Thus, a heuristic approach such as genetic algorithm is required to compute approximations of reducts by finding the minimally approximate hitting sets (analogous to reducts) from the multisets corresponding to the discernibility function in CNF form (Ohrn, 1999; Vinterbo and Ohrn, 2000).
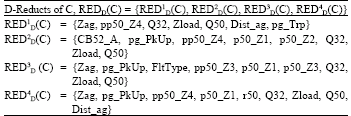
Reducts of protective relay decision system: From the minimal r-approximate hitting set search using genetic algorithm, the deduced sets of D-reducts of C (i.e., REDD(C)) as shown in Table 5 can be used to alternatively reconstruct numerous protective relay DT of exactly the same equivalence relation U|IND(D) (i.e., the same classification of relay trip decision) as that represented by the whole set of attributes C.
As it is known that REDD(C) denotes all the relative D-reducts of C that compose a set of minimal subsets C’ of condition attributes C (i.e., C’ε REDD(C) ⊆ C) of a relay decision system DT (as opposed to a full set of the entire collection of condition attributes C) with which we are still able to discern between relay events belonging to different generalized decisions, i.e., lie in different trip states (VD={Trip} = {0, A, B, C, ABC}).
Thus, formally, [x]RED1D(C) = [x]RED2D(C) = [x]RED3D(C) =[x]RED4D(C)= [x]C in such a way that the DT as in decision system of Table 1 can equivalently as well as alternatively be represented as either one of the decision tables (not shown) corresponding to reduct RED1D(C), RED2D(C), RED3D(C), or RED4D(C) without losing its semantic meaning. In other words, the behavior of the distance protective relay that is being analyzed can be represented by any one of the down-scaled DT’s depicted in the tables. This demonstrates the proof that rough set is capable of reducing the dimension of the decision system without affecting its data structural pattern by completely getting rid of the dispensable attributes namely:
| Table 5: | The D-reducts of C (i.e. REDD(C)) for distance relay decision system involving zone 1 A-G fault |
 | |
Zab, Zbc, Zca, Zbg, Zcg, CB52_B, CB52_C, VTmcb, VTSfail_cnfm, CR, pp_PkUp, pp50_Z1 , pp50_Z2, p50_Z3, p50_Z4, PSB, Dist_ab, Dist_bc, Dist_ca, Dist_bg, Dist_cg, pp_Trp, Trip_CAPerm, Trip_CABlck, WI_Trp, WI_CRTrp, DEFelem_Trp, DEF_WI_CRTrp, Trip_DEF_CA and DEF_WI_Trp
This is a tremendous reduction of superfluous attributes which could help simplify the prediction rules to be derived.
Generating relay cd-decision algorithm using discovered reducts: The above reducts serve as the templates for the CD-prediction rules
to be generated. This is principally done by superimposing each reduct in the reduct set over the reduct set’s parent decision table DT = ⟨U, C∪D, V, f ⟩ and reading off the domain values of the condition and decision attributes.
From all the discovered reduct sets RED1D (C), RED2D(C), RED3D(C) and RED4D(C), any one of them can theoretically be chosen and used as the only template needed to construct the prediction rules. The dilemma is then of wanting to know, whether:
| • | The chosen reduct is good enough to produce the rules in view of relay’s complex operation |
| • | About other attributes (internal relay functional elements) that are relatively important in the overall operation of the relay but are not included in the chosen reduct |
In order to get around this issue an analysis ought to be made, among all the four reducts, according to the following criteria in the stated steps:
| • | Find the concatenation of all the reducts as follows: |
| • | CONCATENATE (RED1D(C), RED2D(C), RED3D(C), RED4D(C)) = { Zag, pp50_Z4, Q32, Zload, Q50, Dist_ag, pg_Trp, CB52_A, pg_PkUp, pp50_Z4, p50_Z1, p50_Z2, Q32, Zload, Q50, Zag, pg_PkUp, FltType, pp50_Z3, p50_Z1, p50_Z3, Q32, Zload, Q50, Zag, pg_PkUp, pp50_Z4, p50_Z1, r50, Q32, Zload, Q50, Dist_ag} |
| • | Find those attributes that exist exactly once in the collection. The attributes are, as highlighted in the above concatenation, i.e., |
pg_Trp, CB52_A, FltType, r50 | |
| • | Next, find the reducts where any one of the attributes is a set member of its corresponding reduct. The reducts are: |
RED1D(C), RED2D(C), RED3D(C), RED4D(C) |
These reducts will then be used as templates for generating CD-decision rules.
The above scheme is mainly to ensure that the final generated CD-decision rules are not deprived of any single attribute that is deemed to be instrumental in the behavior the relay responds to faults. Judging the single-occurring attributes pg_Trp, CB52_A, FltType and r50 (pg_Trp: Ground distance trip. r50: Residual overcurrent supervision in zone. FltType: Fault type. CB52_A: Status of circuit breaker) in the context of distance relay operation, we can see that these attributes are indispensible in shaping the relay response to faults and determining the trip assertion needed. Table 6 shows some of the rules in the generated CD-prediction algorithm
which amounts to a total of one hundred twenty rules.
| Table 6: | Generated CD - prediction algorithm with its numerical measures (only some rules are shown) . As an alternative expression, Trip (A) denotes the positive class Trip and Trip (0) denotes the negative class Non -trip |
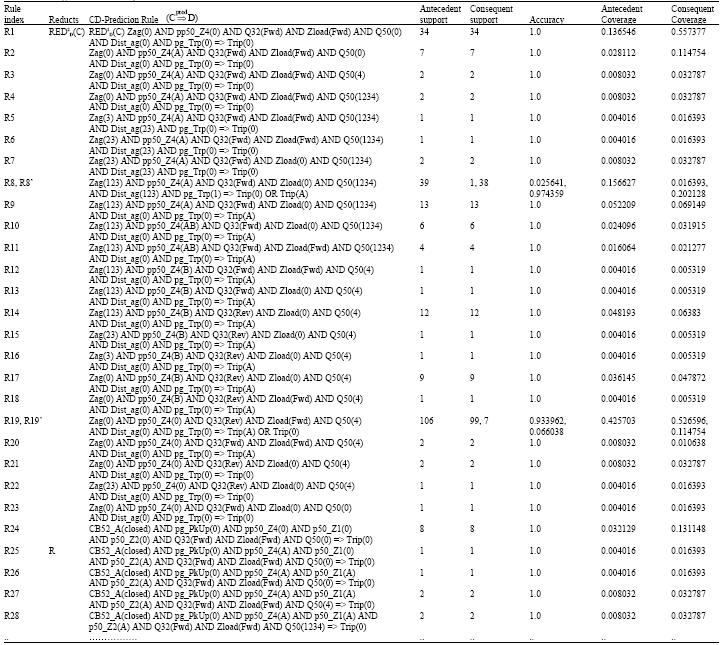 | |
A complete collection of all rules derived from reduct RED1D(C) alone is evident. The numerical measures of each rule are calculated according to a contingency table (not discussed here) and the rule interestingness concept as follows:
| (6) |
| (7) |
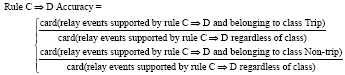 | (8) |
 | (9) |
 | (10) |
DISCUSSION
Evaluating prediction performance of discovered CD-decision algorithm: In order to validate the generalization ability of the discovered predictive knowledge of the distance relay operation (i.e., CD-decision algorithm or ALG(DT)) to predict future unknown-class relay data events - relay events which were not available in the original event report and whose trip status (decision class) is yet to be known, the algorithm ought to be tested.
If we use the full set of events in DT (i.e., the entire rows of the relay event report) as the training set, the induced CD-decision algorithm can be inspected to deduce the kind of hypotheses that explain the relay behavior. Unfortunately, in as far as assessing the performance estimate of the algorithm in an unbiased manner is concerned, no data is left for us to test the CD-decision algorithm. Because the algorithm has been learned from the very same training data, any estimate of its classification performance by testing on that same data will be hopelessly optimistic and over fitting the training data (Witten and Frank, 2005). Therefore, an independent test set is required. Both the training relay data and the test relay data sets have to be representative samples of the underlying relay behavior under analysis. This can only be realized if both the training and test data sets are randomly and systematically partitioned from the same original relay DT.
Since, the decision algorithm ALG(DT) is a complete algorithm that has been discovered from the entire rows of the relay event report, no events have been left for testing it. Assuming no other datasets of relay event report generated from different contingencies of fault occurrences are available from the relay under test, a widely familiar systematic approach called k-fold Cross Validation (k-fold CV) (Witten and Frank, 2005) shall be employed onto the same event report from which the decision algorithm ALG(DT) had been extracted.
A ten-fold CV will be implemented on the original pre-data-mining relay decision system DT, i.e., Table 1, according to the following process. Figure 5 summarizes the entire ten-fold CV pipeline:
| • | In the ROSETTA platform, command scripts are written defining two pipelines, one for training and one for testing: |
The training pipeline is specified with the length of two defining,
| • | Firstly, the commands for reduct generation using genetic algorithm |
| • | Secondly, the relay CD-prediction rules generation |
The testing pipeline defines the classifier command which predicts the classes of the test data using the relay CD-prediction rules implicitly passed from the training pipeline:
| • | Randomly partition two disjoint tables of training set DTtrain and hold-out test set DTtest from the input relay DT. In ROSETTA, this is done implicitly |
| • | Training set is fed into the training pipeline which, after reducts are produced, CD-prediction rules are generated |
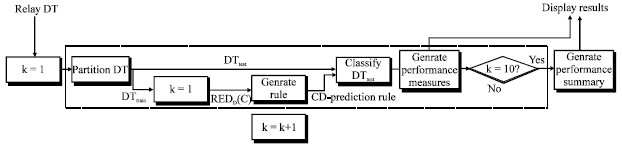 | |
| Fig. 5: | The pipelines of ten-fold CV in relay CD-decision algorithm performance evaluation |
| • | Test set is fed into the testing pipeline for classification in which the set of CD-prediction rules produced by the training pipeline is implicitly applied. In this step, the sequential processes of CD-prediction rule firing CD-prediction rule voting and relay event classification some considerations are made: | |
| • | If the generated prediction rules (classifier) are not able to come up with a decision, a fallback shall be invoked by forcing the classifier to decide the decision attribute Trip = 0 with a certainty factor CERTAINTY(t,vd) = 1 so that the attribute Trip is strongly inclined to value 0 in the certainty ranking of voting. This strategy of fallback is to ensure that only in a perfectly sure situation will the decision Trip be leaned towards the trip assertion value A | |
| • | In the voting process, the decision attribute value d = vd is defined as a negative class Non-trip with value VNon-trip = {0} or a positive class Trip with value VTrip = {A}, {B}, {C}, or {ABC}) | |
| • | Iterate steps 2 to 4 above k = 10 times with the execution of the following operations. Systematically and randomly varying the input DT in step 2. On each iteration’s hold-out test set the following are calculated: | |
| • | The confusion matrix with relevant numerical measures such as classification accuracy, sensitivity, specificity and error rates | |
| • | ROC curve data along with AUC, its standard error, threshold (T) used for ROC point closest to (0, 1(A)) and threshold (T) used for ROC point with highest accuracy | |
| • | At the end of last iteration, all the k = 10 classification accuracy rates, AUC’s and standard errors are averaged out to obtain an unbiased performance estimate | |
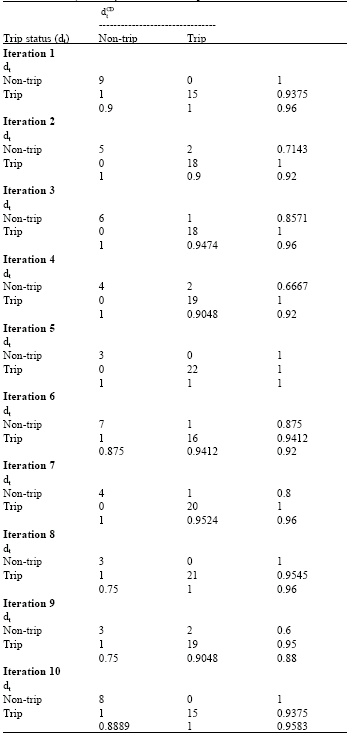
The results for the confusion matrices of the ten-fold CV in the relay CD-decision algorithm performance evaluation are shown for all iterations in Table 7. The calculations for the following measures in each iteration are previously elaborated in Table 2 and 3: Sensitivity (true Trip rate/completeness), specificity (true Non-trip rate), Trip predictive value (consistency/precision/confidence), Non-trip predictive value and CD-decision algorithm accuracy rate.
Among all the iterations, the fifth iteration measures the most accurate classification. The mean of the CD-decision algorithm accuracy rate for the overall ten-fold CV operation, i.e.,
provides us with an acceptable evaluation in the fact that the discovered predictive knowledge of the distance relay operation (i.e., CD-decision algorithm or ALG(DT)) indeed has the generalized ability to predict as well as discriminate future unknown-class relay events. Thus, the discovered relay CD-prediction algorithm ALG(DT) as shown previously in Table 6 can be adopted as a knowledge base in the expert system to be built for distance relay analysis system. Thus, the paper’s aim of discovering relay CD-prediction algorithm has been achieved.
The results for the ROC (Receiver Operating Characteristic) curves (Swets and Pickett, 1982; Provost et al., 1998) of the 10-fold CV analysis in the relay CD-decision algorithm performance evaluation with respect to the positive class Trip (i.e., decision attribute Trip = A) are shown for all iterations in Fig. 6. ROC curves are adopted in this research to be an appropriate depiction of the discriminative performance of the relay CD-decision algorithm without regard to trip decision class distribution across the universe U of relay events. It is important to understand that in each of these curves, each of the data points in the ROC curve is calculated for a particular threshold T using the entirely current hold-out test set of a particularly running fold.
| Table 7: | Confusion matrix defining performance of the relay CD-decision algorithm of each iteration in ten-fold CV. denotes predicted trip status, while dt denotes actual trip status |
 | |
In other words, each curve point is a representation of a particular confusion matrix. Each curve is plotted for a particular decision class of interest (in this case decision attribute Trip = A). The area under the ROC curve (AUC) is then calculated to show how well the binary-classifier nature of the relay CD-decision algorithm is able to discriminate relay events t ε U belonging to either the negative class Non-trip (i.e., VNon-trip = {0}) or the impending pole-trip positive class Trip (i.e., VTrip = {A}, {B}, {C}, or {ABC}). AUC is usually approximated using the trapezoidal rule for integration.
Each iteration’s ROC curve indicates how good, through sensitivity-specificity trading off, the relay CD-decision algorithm is in discriminating that an event (t) is classified as either positive class Trip (=1 (A)) or negative class Non-trip (0). A step function curve, having an AUC of 1, is an ideal case where the relay CD-decision algorithm can perfectly discriminate. This step function passing through point (1-specificity, sensitivity) = (0, 1) determines a perfect discrimination of the algorithm to predict positive class Trip A. It is evident from the AUC that most of the results are close to 1 with a perfect discrimination demonstrated by the fifth iteration (which has been proven to have provided us with the most accurate classification). This suggests that the relay CD-decision algorithm (ALG(DT) indeed has the generalized ability to predict as well as discriminate future unknown-class relay events. The mean of the AUC for the overall ten-fold CV analysis, i.e.,
augments our earlier verification using average accuracy rate that the discovered predictive knowledge of the distance relay operation (i.e., CD-decision algorithm or ALG(DT)) indeed has the generalized ability to predict as well as discriminate future unknown-class relay events. Thus, the discovered relay CD-prediction algorithm ALG(DT) as shown previously in Table 6 can be adopted as a knowledge base in the expert system to be built for distance relay analysis system. This certainly meets the aim of the project.
A sample standard error rate e(AUC) for AUC in the 10th iteration is calculated as follows:
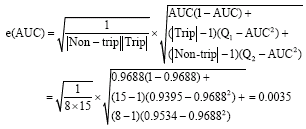 | (11) |
Where:
 |
The average standard error rate Mean e(AUC) for AUC that supports Mean AUC is calculated as follows:
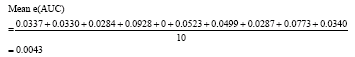 |
In many analyses using computation intelligence, standard error having value less than 0.05 can be considered acceptable.
A part from the above, we can also retrieve from each iteration in Fig. 6 such information as threshold (T) used for ROC point closest to (0, 1(A)) and threshold (T) used for ROC point with the highest accuracy. The threshold (T) used for ROC point closest to (0, 1(A)) only has significance when the test is executed to evaluate the main CD-decision algorithm (ALG(DT)) so that the optimal possible T can later be used in the future classification of relay event report never seen before. In the current scenario the approach in each iteration is merely for illustration purpose on how the ROC curve is usually accompanied by the determination of the threshold (T) used for ROC point closest to (0, 1(A)).
A linear regression plot for calibration measurement is a visual assessment of how well calibrated a relay CD-decision algorithm is as a binary classifier (Ohrn, 1999). A well calibrated relay CD-decision algorithm should have its linear regression line, approximated from some precalculated plot points, closely replicates a y = x line.
The linear regression plots for the calibration assessment of the relay CD-decision algorithm performance in the ten-fold CV analysis are shown for all iterations in Fig. 6. All the test folds of all the iterations are partition into blocks b = 10. Sample calculations of a calibration table CabT having partitions of ten blocks in the 10th iteration is shown in Table 8. The calculations in Table 8 aimed towards getting the calibration plot points are carried out in conjunction with the details for the confusion matrix construction. From the collection of the calculated calibration points, a linear regression line can be approximated as shown in Fig. 7.
Obviously, it is somewhat difficult to visually gauge the calibration measure of all the iterations per se in order to arrive at a common evaluation of whether the relay CD-decision algorithm (ALG(DT)) is well calibrated or otherwise.
| Table 8: | Calibration table CabT that has been partitioned into ten blocks in the tenth iteration. The computed average targeted actual decision class dt and the average CERTAINTY(t,1(“A”)) form the points of the linear regression plot for calibration measurement |
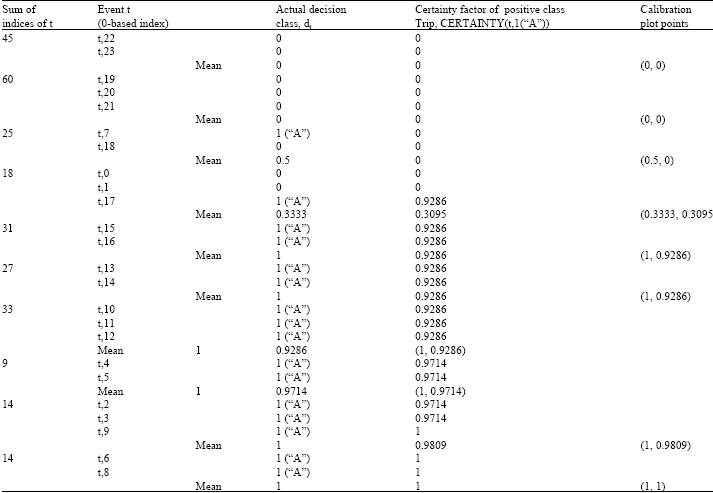 | |
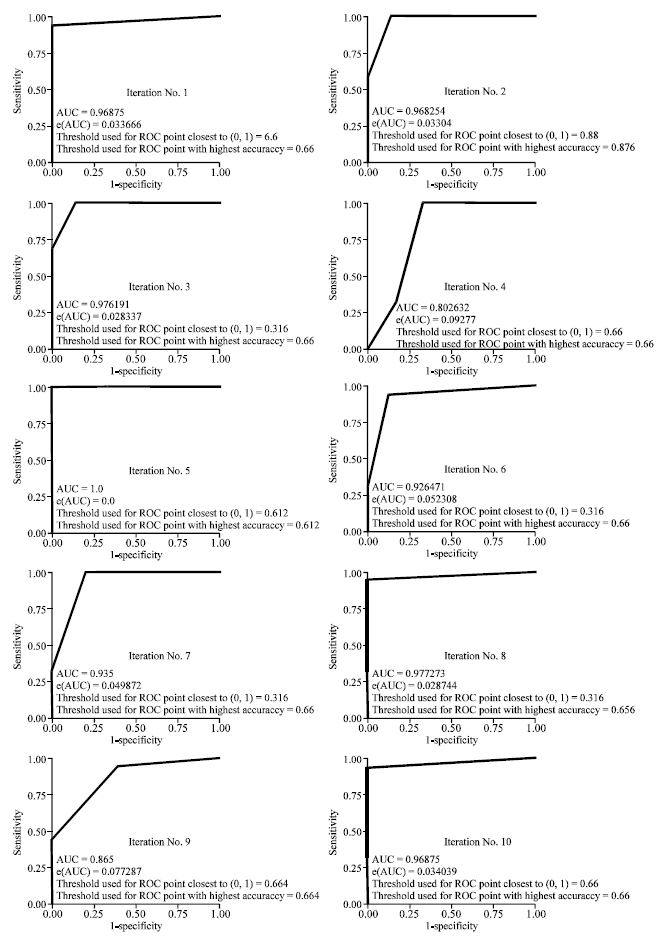 | |
| Fig. 6: | ROC curves defining performance of the relay CD-decision algorithm of each iteration in ten-fold CV |
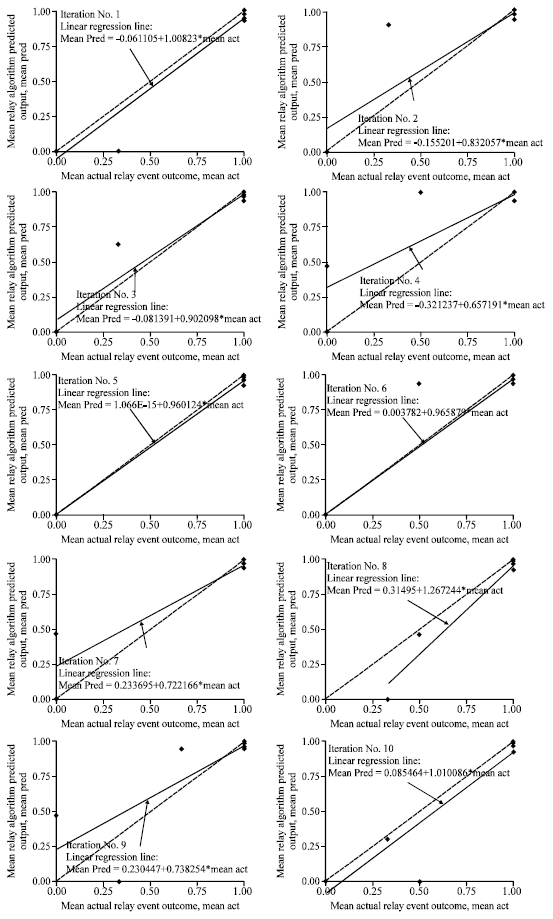 | |
| Fig. 7: | Linear regression plots for calibration measurement defining performance of the relay CD-decision algorithm of each iteration in ten-fold CV |
However, it can be conservatively suggested that in general all the linear regression lines have the tendency of wanting to replicate the psychological y = x line. This is evident in each iteration where the linear regression line either intersects with the y = x line at some points along the latter (as in iterations No. 2, 3, 4, 5, 6, 7 and 9) or tends to run closely parallel with the latter (as in iterations No. 1, 8 and 10). Therefore, it is not too optimistic to suggest that the relay CD-decision algorithm (ALG(DT)) is quite well calibrated. The slight reservation here can be explained as follows.
It can be seen that the closeness to or, otherwise, deviation of each iteration’s linear regression line from the psychological y = x line may not be a reflection of the confusion matrix counterpart in Table 7 as well as the ROC curve (AUC) in Fig. 6. An acceptable resemblance of y = x line in the linear regression lines are only those found in iterations No. 1, 3, 5, 6 and 10, each of which has an accuracy measure of 0.96, 0.96, 1, 0.92 and 0.96, respectively. However, it can also be seen that some iterations, such as iterations No. 7 and 8, have a comparable accuracy measure of 0.96 but their linear regression lines visually deviate from the psychological y = x line. The best closeness is again, as proven previously via confusion matrix and ROC curve (AUC), is that of iteration No. 5. While the worst accuracy of 0.88 belonging to iteration No. 9 cannot be visually evaluated for calibration using the calibration plot since the plot is also quite comparable with some of others (such as those of iterations No. 4 and 8) which conversely have better accuracies.
An interesting revelation from the calibration plots is that plot points that lie away from the y = x line, when cross referenced with the corresponding confusion matrixes, are in fact an exact representation of those relay events that have been falsely predicted either as ![]() = Trip when the actual trip status is dt = Non-trip (i.e., false Trip, abbreviated as FT in the confusion matrix) or as
= Trip when the actual trip status is dt = Non-trip (i.e., false Trip, abbreviated as FT in the confusion matrix) or as ![]() = Non-trip when the actual trip status is dt = Trip (i.e., false Non-trip, abbreviated as FNt in the confusion matrix). So, obviously it is due to these false classifications of trip status that attribute to the linear regression lines swaying away from the psychological y = x line. Otherwise, without false predictions, the relay CD-decision algorithm (ALG(DT)) would have been perfectly calibrated. Again, to augment the final statement in the previous paragraph, having Mean Accuracy = 0.944 as well as Mean AUC = 0.939 means that the relay CD-decision algorithm (ALG(DT)) has been acceptably calibrated with only Mean e(AUC) = 0.043 contributing to a slight miscalibration due to, primarily, false prediction of trip status.
= Non-trip when the actual trip status is dt = Trip (i.e., false Non-trip, abbreviated as FNt in the confusion matrix). So, obviously it is due to these false classifications of trip status that attribute to the linear regression lines swaying away from the psychological y = x line. Otherwise, without false predictions, the relay CD-decision algorithm (ALG(DT)) would have been perfectly calibrated. Again, to augment the final statement in the previous paragraph, having Mean Accuracy = 0.944 as well as Mean AUC = 0.939 means that the relay CD-decision algorithm (ALG(DT)) has been acceptably calibrated with only Mean e(AUC) = 0.043 contributing to a slight miscalibration due to, primarily, false prediction of trip status.
CONCLUSION
In this study rough-set-based data mining strategy has been formulated to discover distance relay decision algorithm from its resident event report. This derived algorithm or appropriately known as relay CD-prediction rules
can later be used as a knowledge base in support of a protection system analysis expert system to predict, validate or even diagnose future unknown relay events. This work relies merely on digital protective relay’s recorded event report in helping the protection engineers deal with complex implementations of protection system analysis due to massive quantities of data coming from diverse points of intelligent electronic devices. Digital protective relay alone can sufficiently provide virtually most attributes needed for data mining process in knowledge discovery in database.
The relay decision algorithm from the resident event report that has been discovered using rough set theory in combination with genetic algorithm in the KDD process will complement some of the computational intelligence techniques that have been implemented in many researches. This study is aspired to support the ongoing researches in the following ways:
| • | Simplify the process of construction and, later, expansion of the knowledge base containing if-then prediction rules in the protection system analysis ES. This shall relieve from having to consult protection engineers’ domain knowledge in protection system each time knowledge base of ES is to be altered. As humans their expertise is subjective and constrained by experience |
| • | Solve the implicitness in the behavior of the relay due to the black box nature of the hidden layer(s) in ANN operation where capturing the behavior of the relay’s internal multifunctional elements is almost impossible |
| • | Relieve the limitations of ANN in handling a large number of inputs for analysis by analyzing only indispensible attributes |
| • | By running relay under analysis in possibly all contingencies can help in keeping complete inventories of decision algorithms. This would help ET analysis deal with any possible initial events and their contingencies |
| • | Assist the decision support system created by Hor et al. (2007) to determine the states of a distribution system (normal/abnormal/emergencies) by using expected trip signals predicted by the relay decision algorithm developed in this study |
| • | Complete the crucial attributes (i.e. triggered internal multifunctional protection elements) that are absent in the population-based decision tree analysis but present in the event-based paradigm of rough set analysis in the derived relay decision algorithm |
The classification accuracy and the area under the ROC curve measurements provide us with a justification in the fact that the discovered relay decision algorithm indeed has the generalized ability to predict as well as discriminate future unknown-class relay events. A linear regression study also provides us with a visual assessment of how well calibrated the discovered relay decision algorithm is as a classifier. Thus, the discovered algorithm can complementarily benefit many ongoing researches that employ different artificial intelligence techniques and in particular it can be adopted as a knowledge base in a protection system expert system.
ACKNOWLEDGMENT
The research project was conducted at the Department of Electrical and Electronic Engineering, Faculty of Engineering, Universiti Putra Malaysia. It was fully sponsored by the Malaysian Ministry of Higher Learning under a Fundamental Research Grant Scheme with grant number 02-01-07-041FR for a period from January 2007 to December 2009.
REFERENCES
- Hor, C.L., P.A. Crossley and S.J. Watson, 2007. Building knowledge for substation-based decision support using rough sets. IEEE Trans. Power Delivery, 22: 1372-1379.
CrossRefDirect Link - Hor, C.L. and P.A. Crossley, 2006. Substation event analysis using information from intelligent electronic devices. Electrical Power Energy Syst., 28: 374-386.
Direct Link - Hor, C.L. and P.A. Crossley, 2006. Unsupervised event extraction within substations using rough classification. IEEE Trans. Power Delivery, 21: 1809-1816.
CrossRefDirect Link - Hor, C.L. and P.A. Crossley, 2005. Extracting knowledge from substations for decision system. IEEE Trans. Power Delivery, 20: 595-602.
CrossRefDirect Link - Kezunovic, M. and B. Perunicic, 1996. Automated transmission line fault analysis using synchronized sampling at two ends. IEEE Trans. Power Syst., 11: 441-447.
CrossRefDirect Link - Negnevitsky, M. and V. Pavlovsky, 2005. Neural networks approach to online identification of multiple failures of protection systems. IEEE Trans. Power Delivery, 20: 588-594.
CrossRefDirect Link - Souza, J.C.S., M.A.P. Rodrigues, M.T. Schilling and M.B. Do Coutto Filho, 2001. Fault location in electrical power systems using intelligent systems techniques. IEEE Trans. Power Delivery, 16: 59-67.
CrossRefDirect Link - Vinterbo, S. and A. Ohrn, 2000. Minimal approximate hitting sets and rule template. Int. J. Approximate Reason., 25: 123-143.
Direct Link - Yang, G.T., W.Y. Chang and C.L. Huang, 1994. A new neural networks approach to on-line fault section estimation using information of protective relays and circuit breakers. IEEE Trans. Power Delivery, 9: 220-230.
CrossRefDirect Link - Zhang, N. and M. Kezunovic, 2006. Improving real-time fault analysis and validating relay operations to prevent or mitigate cascading blackouts. Proceedings of the IEEE PES Transmission and Distribution Conference and Exhibitioin, May 21-24, IEEE Xplore, London, pp: 847-852.
CrossRef - Zhang, N. and M. Kezunovic, 2004. Verifying the protection system operation using an advanced fault analysis tool combined with the event tree analysis. Proceedings of the 36th Annual Northern American Power Symposium, Aug. 9-10, University of Idaho, Moscow, Idaho, pp: 1-6.
Direct Link