
M. Rezaei
Reservoir Engineer, NIOC, Pars Oil and Gas Compoany, North Pars Branch, Parvin Street, Fatemi Blv., Tehran, Iran
B. Movahed
Department of Petrophysic, NIOC, Pars Oil and Gas Company, Parvin Street, Fatemi Blv., Tehran, Iran
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 12 | Page No.: 2201-2217







ABSTRACT
The aim of this study is to approach the problems of estimating permeability values and identifying lithofacies from some conventional well logs through the use of a proposed method based on fuzzy logic inference. Fuzzy logic is inherently well suited to characterizing vague and imperfectly defined knowledge, a situation encountered in most geological data. It can thus yield models that are simpler and more robust than those based on crisp logic. The method is simple, easy to comprehend and robust which could be perfectly suitable for analyzing lithologies and permeability values of horizontal wells, which are almost never cored, especially if core data is available for nearby vertical wells. In this study, core analysis of some wells and the established fuzzy relations are used to get the lithofacies description and permeability values in wells having only log data. In addition, a sensitivity analysis assigned to the capability of the model to predict lithotypes correctly when describing from the most basic lithology (sand or shale), to the most detailed seven core derived categories. The method is also able to calculate, for each analysis, confidence measures that are indicative of how well the analysis procedure can identify those facies given uncertainties in the data. The problem with permeability is rather complex as it relates more to aperture of pore throats rather than pore size. In addition, determining permeability from well logs is further complicated by the problem of scale. The proposed fuzzy technique has advantages when contrasted with other techniques that rely on multivariate statistics and neural networks. This method is simpler, easier to retrain, more reproducible, noniterative and more computer efficient which uses much basic log data sets rather than depending on new logging technology. Moreover, we can apply constraints derived from human experience and geologic principles to guide the inference process.
PDF Abstract XML References Citation
How to cite this article
M. Rezaei and B. Movahed, 2009. New Approach of Fuzzy Logic Applied to Lithofacies Forecasting and Permeability Values Estimation. Journal of Applied Sciences, 9: 2201-2217.
DOI: 10.3923/jas.2009.2201.2217
URL: https://scialert.net/abstract/?doi=jas.2009.2201.2217
DOI: 10.3923/jas.2009.2201.2217
URL: https://scialert.net/abstract/?doi=jas.2009.2201.2217
INTRODUCTION
Lithofacies determination and permeability values estimation have presented challenges for cases whenever no direct measurements of permeability or rock types are available. The direct determination of these parameters will be carried out though the core analysis. Typically, the wells with available core data are not sufficient to drive an accurate property distribution model. This is might due to various reasons such as, time and cost associated with coring operation and or impractical coring in many situations, such as in horizontal wells.
On the other hand, almost every vertical or horizontal well may have electronic logs data. Thus, the challenge is to establish an explicit relation between log behavior and core data of those wells that contain both types of information. Then, describe those reservoir features of wells with log information only which commonly have much more complete coverage of the field. This could be a key to achieve much more precise three-dimensional model either by implementing any interpolation techniques or by incorporating further sources of information such as seismic data.
Fuzzy mathematical techniques have been applied to solve various petroleum engineering and geological problems in the past, involving mainly classification, identification, or clustering. Toumani et al. (1994) used fuzzy clustering to determine lithology from well logs in Upper Carboniferous coal deposits of the Ruhr basin. Cuddy (1997, 2000) used fuzzy logic to predict permeability and lithofacies in uncored wells to improve well-to-well log correlations and 3-D geological model building. In 2003, Hambalek and Gonzalez (2003) made some modification to the Cuddy’s works in a more or less similar study. In addition, Saggaf and Nebrija (2003) used fuzzy logic approach for the estimation of facies from wire-line logs in a field in Saudi Arabia. Taghavi (2005) also applied fuzzy logic to improve permeability estimation in a complex carbonate reservoir in southwest of Iran.
In this study we apply the fuzzy logic inference method to identify the kind of lithofacies and determine the permeability values in uncored wells based on data from wire-line logs in a heterogeneous sandy oil-bearing reservoir in North Field. In this study we introduced fuzzy logic to be inherently well suited to characterizing vague and imperfectly defined knowledge, a situation encountered in most geological data. It can thus yield models that are simpler and more robust than those based on crisp logic. The method is simple, easy to comprehend and robust.
Another advantage in applying fuzzy logic theory is the implicit consideration of the inherent error associated to any physical measurement. Far from minimizing or ignoring the error, fuzzy logic takes into account that useful information exists in the error that can be used to improve the possibilities of prediction. During this study, this concept moved us towards generating several confidence measures that can be used to assess the quality of the analysis by quantifying the uncertainty of predictions (Lim and Kim, 2004; Mohaghegh, 2000).
In addition, the method has advantages when contrasted with other techniques that rely on multivariate statistics and neural networks. Compared to those techniques, this method is simpler, easier to retrain, more reproducible, non-iterative and much computer efficient. Therefore, employing fuzzy logic inference allows new information to be simply added to the existing data set without actually retrieving the old data (Lim and Kim, 2004; Mohaghegh, 2000).
Furthermore, fuzzy algorithm made it possible to organize the rules based on previous knowledge and background. So, one may change the rules in a specific case according to its properties in that area of study.
Before going further, let’s have a brief to fuzzy logic concept. It is so obvious that the reality does not work in black and white, but in shades of gray. Once the reality of the gray scale has been accepted, a system is required to cope with the multitude of possibilities. Not only does truth exist on a sliding scale, but also because of the uncertainty in measurements and interpretations, a gray scale can be a more useful explanation than two endpoints.
Fuzzy logic is an extension of conventional Boolean logic (zeros and ones) developed to handle the concept of partial truth values between completely true and completely false. In contrast to binary-valued (bivalent) logic, truth is ascribed either 0 or 1, multivalent logic can ascribe any number in the interval [0, 1] to represent the degree of truth of a statement. This is a normal extension of bivalent logic and it is a form of logic that humans practice naturally. Zadeh (1965) introduced as a means to model uncertainty.
More common use of fuzzy logic is to describe the logic of fuzzy sets (Zadeh, 1965). These are sets that have no crisp, well-defined boundaries and which may have elements of partial instead of full membership. For fuzzy sets, elements are characterized by a membership function that describes the extent of membership (or the degree of fit) of each element to the set. Such a membership function maps the entire domain universe to the interval [0, 1].
Early investigators of natural science noticed that many seemingly random events fell into a pattern with a degree of regularity in the variation of an observation about its mean or average value. These patterns or distributions were closely approximated by continuous curves. These curves are now called normal or Gaussian curves which are frequently used to describe random situations. Normal distribution curve has a bell shape characteristic and its distribution is the cornerstone of modern statistical theory.
Let’s remind us that the normal distribution is completely determined by two parameters: its mean and its variance. The variance (the standard deviation squared) depends on the hidden factors and measurement errors, and it can be seen like the fuzziness (spread) about a most probably value of occurrence (the mean). This interpretation is key to the method because it allows to consider the possibility of observing any particular value of the analyzed variable but equally to accept that some observations are more probable than others.
It should be pointed out that fuzzy logic does not demand a normal distribution to work (any kind of distribution can be used). In addition, it is obvious that the fuzzy logic inference is not just a simple probabilistic method. It is based on measured data.
The objective here is to infer the lithological categories and calculating permeability values from some selected conventional well-logs in a complex oil reservoir. Fundamentally, in this study we used the mathematics just same as those of Cuddy (2000) and Hambalek and Gonzalez (2003) applied, but there are some modifications to achieve much more precise predictions. In addition, to justify and optimize the capability of the model, some sensitivity analysis were put into practice in both cases of permeability and lithofacies. Furthermore, we considered the concept of fuzzy possibility as a key parameter towards Confidence measures that provides some degree of precision for either predicted lithofacies or permeability values.
MATHEMATICS OF FUZZY INFERENCE
First, we begin with a brief background of the mathematics behind the fuzzy inference and then we apply the model to predict the lithofacies and calculate permeability values in a typical complicated sandy oil bearing reservoir. Let’s describes the mathematics of the fuzzy inference model with a simple example.
Mathematics of fuzzy inference-lithofacies prediction: If a lithofacies type has a porosity distribution with a mean μΦ and standard deviation σΦ the fuzzy possibility that a well-log porosity value Φeff...,x is measured in this lithofacies type can be estimated using the analytical expression of the probability density for a normal distribution Eq. 1:
(1) |
where, P (Φeff.,x) is the fuzzy possibility of an effective porosity log value Φeff.,x belonging to a specific lithofacies type with mean μΦc and standard deviation value of σΦc. Φeff.,x is the effective well log porosity value. μΦc is the mean value of the porosity distribution values for a specific lithofacies type derived from core analysis. σΦc is the standard deviation value of the porosity distribution for a specific lithofacies type derived from core analysis.
When there are N lithofacies types describe with N pairs of μΦi and σΦi (1≤i≤N), the fuzzy possibility of the effective porosity value Φeff.,x belonging to each lithofacies type could be similarly determined using Eq. 1 by substituting μΦi and σΦi.Unfortunately, these fuzzy possibilities refer only to particular lithofacies fi and cannot be compared directly, as they are not additive and do not add up to 1. We would like to know the ratio of the fuzzy possibility for each lithofacies with the fuzzy possibility of the most likely observation. This would be achieved by de-normalizing Eq. 1 when dividing it by the fuzzy possibility of the mean or most likely observation value.
(2) |
where, R(x) is the relative fuzzy possibility of porosity Φeff.,x belonging to the fi th lithofacies. Each fuzzy possibility is now self-referenced to possible lithofacies types. To compare these fuzzy possibilities between lithofacies, the relative occurrence of each lithofacies type in the well must be taken into account as a weighting factor. This could be achieved by multiplying Eq. 2 with square root of the expected occurrence of lithofacies fi. If this is denoted by nfi, the fuzzy possibility of measured effective porosity φeff.,x belonging to lithofacies type fi is:
(3) |
This fuzzy possibility Ffi, φeff. (φeff.,x) is based on the effective porosity logs alone. For a specific horizon with the reading log values of (ρbx, Nphi, ΔTx, GRx), this process should be repeated similarly for all parameters to yield Ffi, ρb (ρbx), Ffi, Nphi (Nphix), Ffi, ΔT (ΔTx), Ffi, GR (GRx), respectively. At this point, we have several fuzzy possibilities Ffi, j (jx) based on the fuzzy possibilities from different parameters measurements jx which are predicting that lithofacies type fi is most probable. Cuddy (2000) proposes to combine harmonically these weighted fuzzy possibilities in order to give a definitive fuzzy indicator associated with fith particular lithofacies.
(4) |
where, 1≤i≤No. of lithofacies, j is the No. of well logs implemented.
This process is repeated N times for each of the fi lithofacies types. Finally lithofacies corresponding to the maximum value of Ffi, T will be the most probable lithofacies for that interval, although this could be belong to each lithofacies by its specific combined fuzzy possibility membership function. In the other words, by a fuzzy interpretation all lithofacies could be possible for these reading log values but the lithofacies corresponding to the value of maximum Ffi, T is most probable lithofacies for that interval. In addition, in this study the lithofacies associated with the next biggest combined fuzzy possibility is suggested to be the probable facies for those log reading values. The model also generates confidence measurements that can be used to assess the quality of the analysis.
Mathematics of fuzzy inference-permeability forecasting: Permeability is a very difficult rock parameter to measure directly from electrical logs because it is related more to the aperture of pore throats rather than size. Determining permeability from logs is further complicated by the problem of scale; many well logs have a vertical resolution of, typically 2 ft., compared to the 2 inch of core plugs. In addition to these issues, there are measurement errors on both the logs and core. When you add these problems together, it is surprising that predictions can be made at all. The mathematics of fuzzy logic provides a way of not only dealing with errors but also using them to improve the prediction.
Fuzzy logic is used for lithofacies prediction by assigning a data bin to each litho-type. The challenge for permeability determination in how to define bins and which characteristics will the bin boundaries have.
Cuddy (2000) defined the boundaries so that the number of core permeabilities in Bin i represents the 10xith percentile boundary of the permeability data. So, there were 10 divisions in the permeability data of his study. But he mentioned that there is no reason why there could not be 20 or more. In addition, in a similar study by Hambalek and Gonzalez (2003), the permeabilities range divided into eight categories using the p-fractil concept. Hence, both studies employed the permeability categorizes of the same bin sized which having directly the same number of sample points in each class interval.
Evidently, in a typical well the frequency of the values representing the for example very low permeability category are not necessarily the same with that of the representing for example very high permeability category. Hence, during this study the permeability bins of not equally in sized have been considered and the petrophysical specifications of the cased study areas has been taken into account in bin classification. Finally, each distribution will be normalized by multiplying the expected occurrence of each permeability category in the equation of relative fuzzy possibilities, as it was assigned in lithofacies determination. Note that, this is an advantage of the fuzzy logic based systems which allow the interpreters to incorporate their previous knowledge and experience, as well as general geological principles and notions.
Fuzzy logic asserts that particular log readings can be associated with any permeability, but some are more likely than others. An additional consideration should be also taken into account. How can a discrete approach (discrete bins considered as a specific geo-category) be used to simulate permeability values (a continuous variable)? As it was mentioned, the permeability spectrum of sample values is first divided into geo-categories (bins). Within each permeability category, a value is chosen as the representative permeability for that category.
For a specific depth, the fuzzy possibilities should be determined separately for each of measured logs. Their fuzzy possibilities are combined to calculate the combined fuzzy possibility for a specific bin (let say permeability geo-category). This process is then repeated similarly for other defined geo-categories. The two highest fuzzy possibilities are taken as the most probable categories for that log measurements. The simulated horizontal permeability value is proposed as a weighted mean of the representative values of the two most probable permeability geo-categories (Hambalek and Gonzalez, 2003).
(5) |
where, KH (h)Simulated is simulated horizontal permeability value for specific log measurements in depth h. ![]() ,
, ![]() are respectively representative horizontal permeability values of the first and second most probable predicted ith geo-category. FT, i, (1) (h), FT, i, (2) (h) are respectively combined fuzzy possibilities associated with the first and second most probable predicted ith geo-category calculated for a specific depth h.
are respectively representative horizontal permeability values of the first and second most probable predicted ith geo-category. FT, i, (1) (h), FT, i, (2) (h) are respectively combined fuzzy possibilities associated with the first and second most probable predicted ith geo-category calculated for a specific depth h.
This formula guaranties that the most probable permeability geo-category receives the heaviest weight. Evidently, a finer categorization of the permeability range provides a better possibility of simulating efficiently their values. However, any classification must be sure of having enough sample observations inside each class for guarantying the statistical robustness of the results. A reasonable statistical sample size is around 30. The program uses any number of permeability bins (geo-categories) with any number of input curves.
Another consideration should be also taken into account in which the representative permeability values corresponded to each permeability bin defines. Cuddy (2000) proposed the average value for each permeability bin as representative value whereas Hambalek and Gonzalez (2003) proposed the minimum value after testing each mean, median, maximum and minimum of each permeability geo-categories.
In this study, we took into practice different issues to propose a method for enhancing the precision of the permeability values predicted by fuzzy inference model. We carried out a sensitivity analysis on representative values of permeability bins due to lower amount of error when applied to the fuzzy model. Finally, we proposed an optimized case referred as mixed case which caused the lowest amount of simulated values.
FUZZY LOGIC APPLIED TO LITHOFACIES PREDICTION IN ALWYN NORTH FIELD
In this study, fuzzy logic theory is applied in order to establish a narrow relation between five selected well logs and the seven rock types of the sedimentological model that describes a complex reservoir in North Sea. At least seven major lithofacies have been recognized from the core studies in Alwyn North Field which are described as follow:
| • | Clean Sandstone (CS): Consist of clean, coarse to very coarse grained sandstone (micro conglomeratic); good porosity and permeability (about 12% and 412 md) and poor clay Content (3%). The sedimentological features of this lithofacies are related to high-energy depositional conditions |
| • | Radioactive Sandstone (RS): Very coarse to coarse grained sandstone, (micro-conglomerate) with the best porosity values of 15% but due average more clay content (4%) associated permeability value for this lithofacies type is less than that of for clean sandstone type (about 312 md). This lithofacies shows more or less radioactive responses due to thorium and uranium content. This class obeys to the same environment conditions of CS |
| • | Micaceous Sandstone (MS): Coarse grained sandstone contaminated by sheet liked mica minerals, with a good porosity and permeability values (12% and 318 md, respectively) but the clay content is high in comparison with the previous lithofacies (about 27%). Energy environment conditions of this facies are lower than conditions of lithofacies CS and RS |
| • | Shaly Sandstone (ShS): Lithofacies associated with laminated sandstone with very fine grained particles; low porosity and permeability (about 8% and 80 md) and regular clay content (32%) |
| • | Silty Clays (SCl): Lithofacies correspond with inter-laminated sandstones and claystones which is strongly bioturbated. This lithofacies is associated with very low porosity and permeability values (about 8% and 86 md) and high clay content (54%). Transitional conditions environment (high to low energy) |
| • | Clay (Cl): Very low energy environment conditions with the highest clay content percentage (76%) |
| • | Coal (C): Thin laminations of coal are present at the top of fining upward sequences, irregular porosity and permeability values which are about 20% and 38 md in average (Notice that because of low amount of presence of clay these values are not a correct descriptive values for this lithofacies) and high clay content (about 51%). This is act as non-reservoir features in sedimentological sequence |
The fuzzy algorithm was established from five selected logs and core-derived lithofacies in two cored-wells. In addition, a control well with both data types (core and log) was used to quantify the prediction success. This success was quantified by counting the number of coincidences between core-derived lithofacies and fuzzy-predicted lithofacies divided by the total number of possible predictions. It was expressed in terms of percentages. Density, Neutron, Gamma ray, Sonic and Deep Induction laterolog were applied in this study.
Furthermore, a sensitivity analysis was made to measure capability of this fuzzy logic algorithm to discriminate between coarser or finer sedimentological descriptions. When describe much coarser lithotypes towards reservoir pay zone or Net to Gross determination (Table 1).
When the log reading values of the test well passes through the fuzzy logic system, the model suggests a lithofacies as the most probable lithofacies (First track in Fig. 1). It also gives another probable lithofacies for those reading values (Second track in Fig. 1) with a confidence factor. These lithofacies are respectively associated with the two first maximum combined fuzzy possibilities. The confidence measured value (Graph of middle track in Fig. 1) could be an indicator that represents the prediction confidence of the most probable lithofacies in comparison with the next probable suggested facies in that specific depth. In fact the most probable lithofacies is the automatic predicted facies for each horizon without any user interferences.
The core-derived rock types from well n1 are displayed in the last track of Fig. 1 while the automatic fuzzy predicted ones are in the track of most probable lithofacies. The global success of prediction was about 71% when the results compared to core reported facies (Fig. 1, Table 1). It shows that the determination of rock type based on the fuzzy logic is in agreement with the result from core analysis. Figure 2 shows a comparison between the real presence percentage that each lithofacies has at the control well and the presence percentage derived from most probable lithofacies simulated by fuzzy model. Certainly, the proportions for these seven geo-categories are very similar.
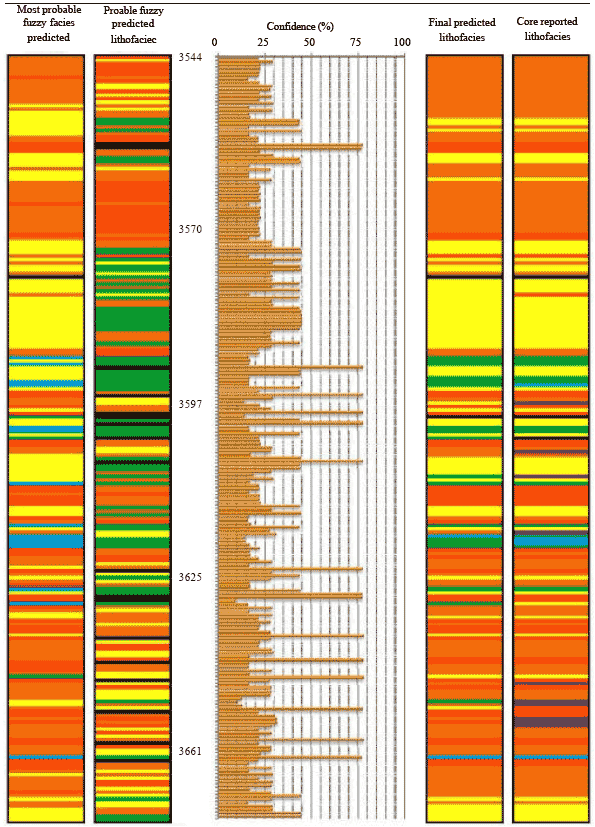 | |
| Fig. 1: | Comparison between core-derived lithofacies and fuzzy-predicted lithofacies (control well n1). The most probable lithofacies are the automatic predicted facies by the model. Final predicted lithofacies will be determined after considering the second suggested facies of probable lithofacies with their degree of confidence |
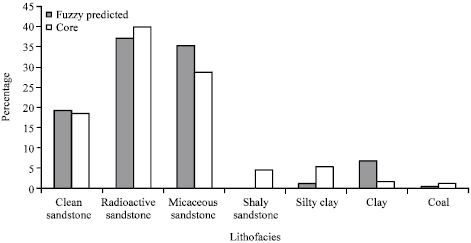 | |
| Fig. 2: | Presence percentages per lithofacies for seven lithofacies (control well n1) |
| Table 1: | Sensitivity analysis results for different Sedimentological categorizations |
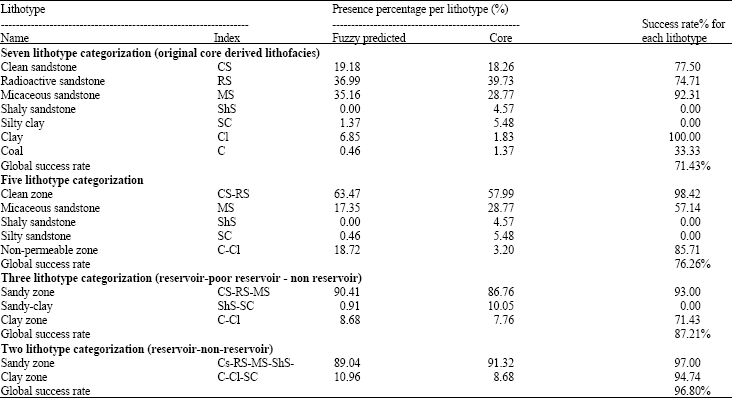 | |
| Data indicates the Presence percentages per lithotype in each geo-category and the total success rate for each categorization (control well n1) | |
Sensitivity analysis on sedimentological categorization: Finding the net to gross ratio and defining the net pay intervals in a typical oil well is a common logging study. Here we are going to test the capability of the model when coarser or finer lithotypes categorizations were applied. In this study, four different kinds of sedimentological categorization were defined depending on the number of included lithofacies in each new defined lithotype geo-category. All predictions were applied to the test well n1. Table 1 shows the results associated with this analysis.
First categorization (seven litho-types): This category is the original sedimentological model which has been derived from core analysis. The model can predict the lithofacies either in very cleaned formations or very fined grains lithotypes by almost high values of global success, 71.43%. The highest success rates are belonging to predictions of clays and micaceous sandstone, respectively, but the model also has high rates of success in two most cleaned facies; clean and radioactive sandstone which are almost 75% in average.
One source of errors comes from the wrongly prediction of CS instead of RS and vice versa which are both potentially reservoir features. But the main error occurs in highly fined grained formations with a very low potentially reservoir chance, i.e., shaly sandstone and Silty clays horizons.
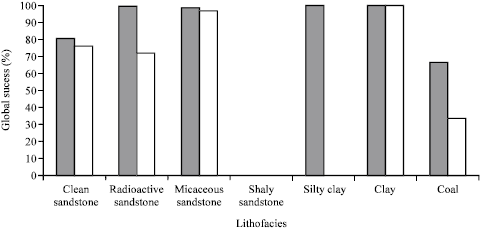 | |
| Fig. 3: | Global success per each lithofacies with and without confidence measure consideration. The white bars are related to the automatic facies prediction (Most probable lithofacies) whereas the black bars are associated with the final manual facies predictions considering the confidence measures. The total global success would reach to excellent value of 91.87% after considering confidence measures |
The results show that the model tends to fail by incorrect prediction of mostly CS or RS instead of shaly sandstone, whereas, silty clay horizons completely predicted wrongly as clay geo-category (which are both acts as non reservoir features).
Figure 2 shows a comparison between the real presence percentages that each lithofacies has at the control well and the presence percentage derived from simulated lithofacies.
When the confidence measures implemented to lithofacies (Fig. 1) the prediction error reduced sharply and the global success reached up to excellent value of 91.87%. Figure 3 compares the global success per each lithofacies without and with confidence measure consideration. For other lithotype categorizations the error reached almost zero when the confidence measure were took into consideration. And the model predicted all the lithotypes almost correctly. So, in this sensitivity analysis we just tested the capability of fuzzy logic mathematic algorithm itself towards net pay determination without any more consideration.
Second categorization (five litho-types): In this categorization which is almost coarser, the classification is done in such way that just coincides with the original sedimentological core based model except in two classes. The clean and radioactive sandstone were combined together as a new lithotype denoted by clean zone category. These are both indicators of clean zones in sedimentological logs. In addition lithofacies of clay and coal types were also combined to be an indicator of non-permeable formations. The global success rates for either very clean or non-permeable horizons showed perfected predictions whereas the model fails in prediction of shaly sandstone and silty clays.
The major error comes from miss-predicting of lithofacies ShS and SCl. All the Silty clays sections and major part of the Shaly Sandstone were wrongly predicted as non-permeable lithotype which will actually cause no errors when determining the oil pay zone intervals. All in all, the model results a good prediction by the total global success of 76.26%.
Third categorization (three litho-types): By continuing sensibility analysis on the coarser or finer classification of the lithotypes, in this categorization three lithotypes defined from the reservoir geology point of view as; Good Reservoir lithofacies, very low porosity and permeability formations and non reservoir horizons, which are combined, respectively by lithofacies (CS, RS, Ms), (ShS, SCl) and (Cl, C). These lithotypes are denoted by sand, sandy clay and clay, respectively. The global prediction success was 87.21%. The results show that although the model fails in prediction of sandy-clay lithotype but shows a perfect efficiency rates associated with the sand and clay lithotypes. This is a very convenient result because sand is the category with the best rock quality whereas clay is the worst one. The very fine-sandstones class sandy-clay, which is a combination of shaly sandstone and silty clays, presents inconsistent success percentages which model actually fails in prediction of this lithotype. We think this erratic behavior is due to grouping the two shaly sandstone and silty clays lithofacies. Although they are both act as very low porosity and permeability layers in sedimentological column but they are classified in two generally different headline classes, i.e., sand and clay.
Forth categorization (Two lithotypes): The coarsest classification will be considered for this sensitivity when lithofacies CS, RS, Ms and ShS, were grouped like the sandstone class (denoted by SAND) and lithofacies Scl, Cl and coal constituted the clay class which is denoted by CLAY. This category is the same as those that reservoir geologists used to use in reading the sedimentological logs for the purpose of reservoir pay zone or Net to Gross determination. It can be seen that the global success is 96.80%. Consequently, the capability of fuzzy logic model to differentiate between sands and clays lithotypes is more accurate.
Confidence measures: Fuzzy logic is a powerful method in describing vagueness and measuring the degree of confidence in the analysis. As a virtual intelligent technique it describes confidence qualitatively just in a natural way that humans do. For instance, during the interpretation of a particular section of the well a petrophysicist may say that there is a lot of confidence that an interval consists of a particular lithofacies Or in other section there might be some degree of suspicion between two probable rock types.
This is because of the fact that there are rarely any pure lithofacies in a typical geological section. Thus, it is always common to have some degree of confidence in perditions or having some similarity in log behavior corresponding to different lithofacies.
Saggaf and Nebrija (2000, 2003) proposed some techniques to consider the confidence measures by introducing three types of confidence measures: individual possibility, overall possibility and distinction. Using the fundamentals of the study by Saggaf and Nebrija (2000, 2003) we are going to propose another technique for measuring the confidence degree of the predicted lithofacies from fuzzy logic inference method in this study.
The applied fuzzy inference method in this study is based on the fuzzy possibility concept. When the log reading values for a specific horizon pass through the program, the combined fuzzy possibilities corresponding to each lithofacies will be determined. The fuzzy algorithm expresses that those log reading values could predict as any lithofacies with the confidence degree of its corresponded combined fuzzy possibility. On the other hand, the model suggests the lithofacies associated with the biggest combined fuzzy possibility as the most probable lithofacies in that interval. The lithofacies related to the next biggest combined fuzzy possibility is also proposed by the model as the probable facies in that specific horizon. In addition, we introduced an index which represents the confidence of the most probable lithofacies in each horizon in comparison with the other probable lithofacies. This is simply derived from:
(6) |
where, FT, i (h), FT, j (h) are the combined fuzzy possibilities associated respectively with the most probable (i) and probable (j) facies after analyzing the log reading values of specific horizon h.
The high confidence factor for specific interval means that the predicted facies by the fuzzy inference method is so confident in comparison with the next more probable suggested facies. This means that the logs have quite distinct characteristics and very similar to the behavior of the representative facies class in that zone. These intervals could be interpreted easily by geologist to assign a confident facies.
When a facies predicted with a mid to low confidence range in comparison with the next probable one, it means that although the predicted facies by model is correct but the log reading values have also some characteristic of the second representative class. This occurs in the cases where the predicted facies is much resembled (in characteristics) to the next suggested facies but it is yet distinguishable.
Furthermore, low confidence measures indicate that the location could be ascribed to two different facies equally well such that the model might predict the most probable lithofacies wrongly. But in most of the cases the next probable suggested facies by the model would be the correct facies for that log reading values. These types of error were the most common errors caused by fuzzy model in this study. These are also the common situations that usually petrophysicists are carefully facing with.
Very low confidence measures are usually corresponding to the intervals that the model fails to predict lithofacies correctly such that even the next probable facies could not be a correct substitute. This occurs when the logs are inconclusive. This could happen also by an interpreter when deals with inclusive log sections. On the other hand, taking this error into consideration could result some benefits. This could happen by identification of the intervals that the predicted facies are highly ambiguous.
Let’s remind us again that the fuzzy logic inference system is a powerful tool that allows an engineer or geologist to incorporate his basis and previous knowledge and experience, as well as general engineering principles and notions, into the inference process. One common place to use the biases and previous knowledge is after evaluating the confidence measures, just prior to identifying the final identified facies.
We analyzed the lithofacies identification once more by implementing the confidence measures during prediction algorithm. That was resulted in the total global success of 71.43% to reach up to 91.87% (Fig. 1, 3). Figure 4 shows a section of the well (Depth 3585-3606 m). Note that how efficiently the confidence measures could increase precision of predictions.
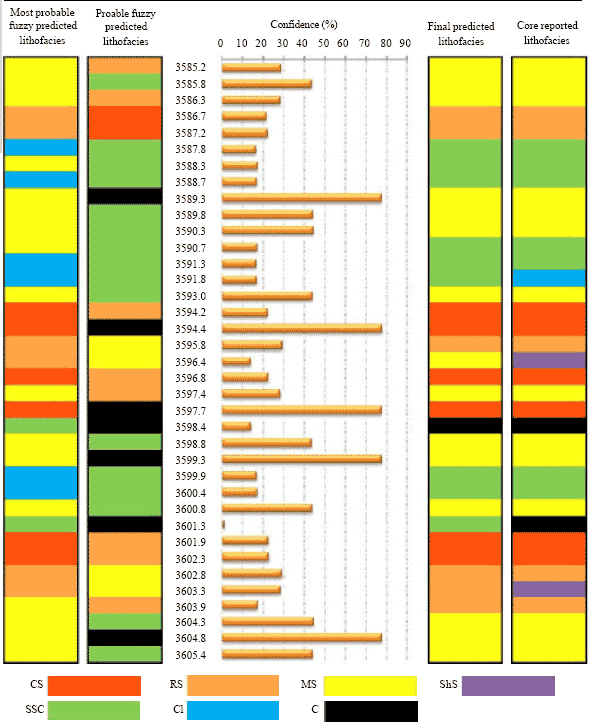 | |
| Fig. 4: | Manual facies prediction applying confidence measures and considering second suggested probable facies by the fuzzy model. A highly complicated section of the well is presented as sample |
Finally, when analyzing the confidence values, by comparing the predicted facies with the referenced core derived ones, it could be possible to suggest some cut-off confidence values for the different situation described above. Evidently, these values are the specifications of the studied case which could be simply applied in other uncored wells to increase the prediction precision. For instance, after analyzing the testing case one may suggest these comments: The most Probable facies predicted by fuzzy model with the confidence value between (10-25%), should be substituted by the probable lithofacies to report the final prediction. On the other hand, the lithofacies corresponding to the confidence bigger than 35% have been correctly predicted by the most probable lithofacies, whereas, there is high possibility that the model fail to predict the facies with less than 8% confidence.
This is the same as the common cut-off analysis which typically petrophysicists use when dealing with some porosity logs or gamma ray.
In this study, we define these threshold values as:
| • | For Confidence greater than 21%, the most probable predicted lithofacies is the correct prediction |
| • | For confidence between 15 and 20%, probable lithofacies is the correct prediction. However, the characteristics of the probable lithofacies are very similar to the most probable predicted facies |
| • | None of the most probable or probable facies could be the correct facies for confidence below 8%. In the other words, the model fails to predict correctly in these intervals |
Now we can simply implement these confidence measures threshold values in other uncored wells to enhance the prediction (Just same as the cut-off analysis by petrophysicists). There are other ways for enhancing the predictions of the fuzzy inference. Saggaf and Nebrija (2003) described some dynamic and static constrains in details that could help in this subject. But in this study we applied no other enhancement for our fuzzy model. Evidently, any enhancement could be resulted in much precise predictions.
FUZZY LOGIC APPLIED TO PERMEABILITY DETERMINATION IN ALWYN NORTH FIELD
As it was explained, defining the number of permeability bins is directly related to the amount of the available data. As it was mentioned, there should be at least 30 data in each bin to avoid any coherent statistical errors. In addition, the number of bins is highly in touch with the accuracy of the prediction, i.e., the finer the bins, the more flexible will be the model to predict correct values. It is behind the theory that during defuzzification stage a value should be assign to the proceeded fuzzified input values. These values are directly related to the number of bins. Therefore, as the number of bins increased the more values would be possible to assign to each fuzzified output processed value and consequently the model will be more flexible to predict an accurate result value and the results would occur in the wider range close to reality.
As it was mentioned, in this work spatial averaging between values of the two most probable permeability bins will be proposed as predicted permeability value for that log measurement. This will result a model with much better and flexible prediction characteristics (Fig. 5, 6).
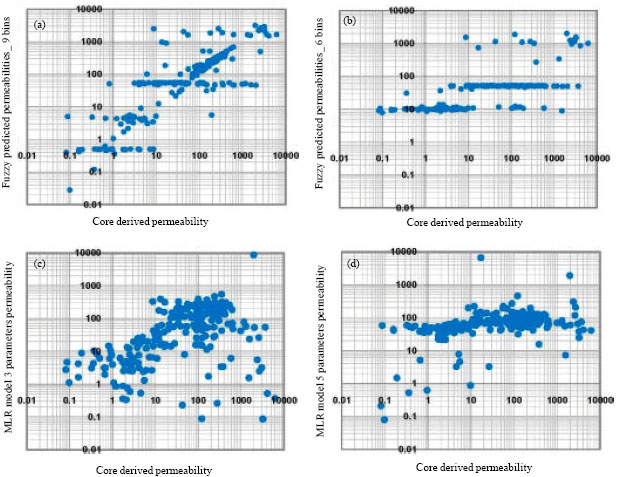
In this study there was a limitation on the number of permeability bins because of low amount of available core data to derive a fuzzy model. But to see how this factor is important and how much the result would be affected by changing this parameter, a sensitivity analysis on this factor had been assigned in this study by considering two possible permeability bins (six and nine). The result shows that considering finer bins will result much better match. The predicted values occur in the actual range of core derived ones whereas the result from coarser bins definition will occur in a narrower range (Fig. 5, 6).
Relative Absolute Error (RAE): To quantify each point error in permeability determination Hambalek and Gonzales (2003) introduced the relative absolute error concept, denoted by RAE. The RAE is defined by the difference between the simulated value and the core reported one divided by the core derived referenced value in each specific depth. This value could be presented as percentage. Before going further, it is important to make some considerations about the meaning of RAE.
In a very low permeability horizon, consider that the model predicts a simulated value of 0.1 md whereas it has a core reported permeability of 0.001 md. The calculated value of REA is 99 which is a high value mathematically. But from the geological viewpoint the simulated value has indicated a very poor permeability which is compatible with the core permeability value. In a high permeability valued interval of 1300 md, on the other hand, the RAE for a predicted value of 1400 md would be 0.076. This is a low value but a difference of 100 md could be an important difference in terms of reservoir production. To overcome this behavior, in this study we tabulated the core reported permeability values at different intervals in terms of increasing potencies of 10.
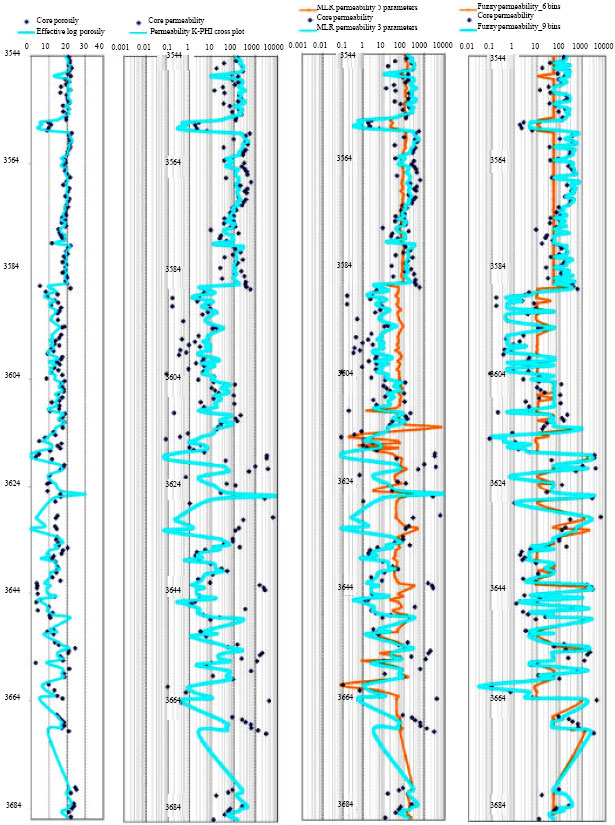 | |
| Fig. 5: | Simulated permeability values from different applied techniques versus depth: K-PHI cross plot, multi-linear regression and fuzzy logic method. For comparison the core reported permeabilities have also been plotted. Note that, applying fuzzy logic algorithm results much more perfect matches in almost all parts of the well sections. The results of fuzzy logic simulations represent the high dependency of fuzzy model precision with the number of permeability geo-categories (Permeability bins) |
 | |
 | |
| Fig. 6: | Simulated permeability values versus core reported ones for each applied technique. (a-c) Results from the optimum fuzzy model occur in a wider range just close to core reported range. Fuzzy algorithm could be a useful technique even in very high or very low permeability values |
Then, the RAE in each interval was calculated. This could give some idea about RAE in each permeability increments which could also be reported as percentage (Table 3, 4).
Sensitivity analysis on the representative value determination: Cuddy (2000) utilized the average value like the representative value of each permeability class. To find out the best performance, we tried out different representative values per geo-category in this reservoir case. We tested each of the minimum, median, average and the maximum value (Same as the study by Hambalek and Gonzales, 2003). In addition, we introduced and tested a case by a simple mixing rule (referred as mixed case). This could be applied by dividing permeability geo-categories into three different classes in ascending order (low K, average K and high K).
| Table 2: | RAE percentages per each permeability interval class for each tested representative values of permeability geo-categories |
 | |
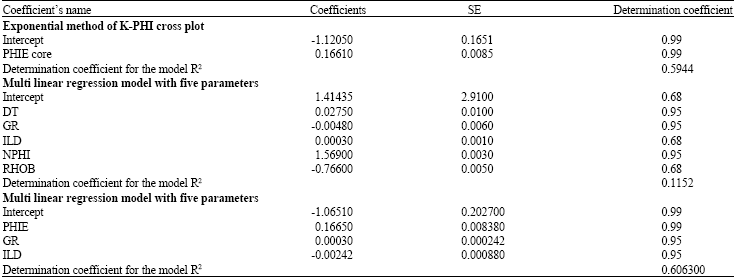
| Table 3: | Statistical analysis for two permeability simulator techniques |
 | |
| Table 4: | RAE percentages of each technique per defined permeability classes |
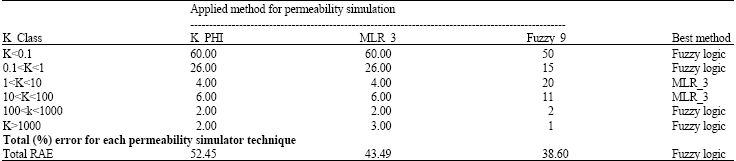 | |
| Total error of each applied techniques is also mentioned | |
We considered the minimum values of each geo-category in the first class (low permeability class) as their representative permeability values. Similarly, the Mean and the Maximum values are respectively assigned as the representative values of the geo-categories located in the second and last class. The idea comes from the results of the earlier studies that their fuzzy model had some problems in simulating both very high and very low permeability values. Results are presented in Table 2 and analyzed in the next paragraph.
As it can be seen, the first column reports the results associated with the simulation by implementing the mixed case procedure for the representative values. This column is eloquent. When it is compared with the remaining columns, it presents the highest percentages of RAE within the two first permeability classes (the intervals of lowest amount of errors). Additionally, when it is compared with the results associated to the remaining columns, it also reports the lowest percentages within the intervals of larger error. These two conditions make this procedure the best option to simulate permeability in this field.
Certainly, from the quantitative viewpoint the algorithm fails predicting the actual permeability (no one can do it!). Nevertheless, the simulated values are useful anyway because they can reveal the kind of permeability qualitative (very high, high, modest, poor, etc.) present at the considered depth. Its efficiency from this qualitative viewpoint is indubitable. This is a very important fact when we predict reservoir quality in exploration areas.
Finally, the last track of Fig. 5 shows the comparison between core-derived and fuzzy-simulated permeabilities at the control well n1. From the tendency viewpoint, the comparison is perfect enough.
Permeability prediction using exponential method and multilinear regression approache: To simulate permeability values we had applied two other techniques on this field before. Which were: (1) Exponential method or K-PHI cross plot and (2) multi linear regression technique. These methods are usually quiet accurate when applying in sandy reservoirs (Mohaghegh et al., 1997; Badarinadh et al., 2002; Babadagli and Al-Salmi, 2003; Carlos, 2004). Note that the focus of this article is on the proficiencies of the fuzzy inference in simulating permeability values. So, we are not going to express all details for these applied methods. We just mention a summery of the each method and present their simulated results. This can help us to compare the results of fuzzy logic with other similar purposes techniques applied in this reservoir studied case.
RESULTS
The exponential method is a tradition but still useful and common technique for permeability calculation, especially in sandy reservoirs. This is based on the exponential relationship between permeability and effective porosity derived from some cored wells. Then, one can apply this model for other uncored wells with knowing effective porosity.
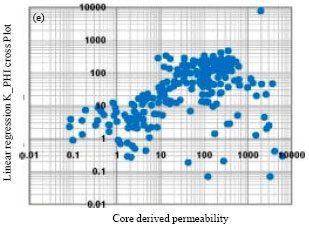
On the other hand, multi linear regression approach as a statistical method establishes a multi linear relationship between cores reported permeabilities and some selected well logs. Then, it could apply in other wells with just electrical well logs to simulate permeability values. The simulated values by each method would be reliable with a degree of confidence that is represented by determination coefficient of the model. Table 3 shows a summery of each method with their corresponded determination coefficients.
The exponential model’s determination coefficient shows a quiet good linear regression analysis and therefore relies that permeability is highly relates to porosity in this well. Another consideration should be also taken into account in which the values of core porosity substituted by effective porosity in the equation. There is a very good relationship between cores derived permeability values with those of predicted by porosity loges by an approximation angle of 45 degrees. So, substituting effective log derived porosity in the equation will not cause any significant problems.
For multi linear regression approach first we consider all five available logs (density, neutron, sonic, gamma ray, effective porosity and deep induction laterolog). The determination coefficient was about 0.12 which confirmed not a good relationship between input well logs and the associated permeabilities. This is also confirmed by low values of determination coefficients and high standard error related to each coefficient. Evidently, the simulated permeability values would not show a good match with core reported ones. This might because the input parameters are so dispersive individually when plotted against logarithm of permeabilities. Therefore the regression analysis through these highly dispersive parameters would not result a perfect match (Fig. 5, the red line in third track).
To face with this problem and enhancing the results, it was tried to re-estimate permeability by substituting effective porosity instead of three porosity logs (Density, Neutron and Sonic). That was because of the good individually relationship between permeability and effective porosity in this field. Consequently, the multiple linear regressions repeated based on three independent parameters; (effective porosity, gamma ray and deep induction laterolog). The results showed that the accuracy of the simulated permeabilities highly increased (Fig. 5, the blue line in third track).
DISCUSSION
The permeability was calculated by three different techniques in a heterogeneous sandy oil reservoir. The first simple model was relating permeability to porosity by calibration core porosity and permeability values. This simple method resulted in overestimated permeability in low values and underestimated in high values intervals compared with measured core values. The multilinear regression model was an extension of the first model with difference in input values. This model leads to an equation relating permeability to log values; gamma ray, density, sonic, neutron and resistivity measurements. The permeability values were in narrow range but the results were better than the first model. It is because in this method the permeability is estimated on the basis of average values of independent log values and core permeability (Fig. 5, 6).
We made an error analyzing for each applied technique per different permeability classes. This could results achieving the best technique in each permeability interval. In addition, the Total RAE associated with each technique in testing well n1 determined to show the best technique on the whole (Table 4). Note that the total RAE for an applied technique in a specific interval of the well, can be determined when dividing the summation of all RAEs by the number of simulated points in that interval.The results confirm that applied fuzzy logic is the best technique for predicting permeability in this study. The results of simulated permeability values by fuzzy logic model show an acceptable correspondence with measured core permeability. In addition, finer classification on permeability bins will increase significantly the accuracy of the predicted values (Fig. 5, 6). This expresses the high dependency of the fuzzy inference accuracy with the number of permeability geo-categories.
In comparioson with statistical techniques that tennds always towards average, fuzzy logic consideres each point individually. So, unlike the two other techniques it could be useful technique even in very high or very low permeability intervals. For example, note the interval of (3590-3605 m) and the dispersive point of high permeability values below the depth 3640 m in Fig. 5. The error analysis on Table 4 also confirms this fact. Therefor, this results the simulated permeability values occur in a wider range just close to the actual core reported ones.
Although the error analysis in Table 4 confirms the capability of the fuzzy algorthim, but it causes some benefits in this studied case which were uniques. For instance, look at the depth (3630-3635 m), there is a significant error in effective porosity when compare to core values. This may occur because of some common resolution difference problems between core and logs in that section. In this study, because the high dependency of the exponential and Muti regression algorinthms on effective porosity, these model fail to simulate correctly. However, fuzzy algorithm could be a powerful method in these situations.
Considering the high acuracy tendency of fuzzy algorithm with the number of permeability bins, we anticipate that increasing number of data when deriving the model and finally a finer bin categorization will cause the acuracy of predictions to increase significantly.
CONCLUSIONS
In this study we applied a fuzzy based method to identify lithological facies and simulate permeability values from wire-line logs. The method simply uses some basic selected well log data sets such as GR and Porosity Logs rather than depending on new complicated logging technologies. Furthermore, we introduced some confidence measurements to enhance the facies predictions. All in all, the model is simple, more accurate, easy to retrain, more reproducible, non-iterative and more computer efficient.
Concerning lithofacies prediction, fuzzy logic methodology is a powerful tool to predict lithofacies at wells without core information. These simulated lithofacies can be used in a process of geostatistical characterization of geometry and reservoir attributes. In addition, the model has high capability towards net pay zone determination. Such that, it presents an excellent degree of success (about 95%) when applied to the coarsest lithofacies categorization of sandstones and clays (same way geologists do!). Furthermore, when the fuzzy algorithm is applied to the finest categorization (the original core reported described facies), a very good global efficiency is reported (about 71%). The success rate could easily reach up to excellent value of 92% when the confidence measures were considered. Furthermore, the fuzzy algorithm always recognizes very efficiently both extreme lithofacies qualities: the sandstones and the Clay lithofacies. This is a very convenient result because it allows an easy discrimination between extreme rock qualities.
On the other hand, permeability simulation is really troublesome work. Many factors attempt against the simulation efficiency of the fuzzy algorithm. The main one is that the entering with a discrete approach to simulate a continuous variable is really a philosophical crash! Other more manageable factors are: the proposed way of categorization; the approximated distribution models; the proposed way of the representative value per category; how to formulate the definitive simulated value; the existence of error measurements on both the logs and core data and the fact that core permeability is related to the plug scale whereas well logs have very different volume resolution. Seen this discouraging list, it is almost a miracle to find an efficient permeability predictor. However, we think that the mathematics of fuzzy logic can provide ways of dealing with most of these factors and really help to improve the efficiency of the permeability predictions.
From a qualitative point of view, the simulated permeabilities copy exactly the actual permeability tendency. This feature constitutes a powerful tool for the exploration business. In addition, it shows some benefits qualitatively.
We also applied two other permeability simulator techniques in that studied case with acceptable prediction efficiency. Moreover, we introduced the concept of Relative Absolute Error (RAE) to analysis errors. That helped to compare different techniques as well analyzing the errors of each technique separately. Unlike the K-Phi Cross plot or Multi linear regression which tends usually towards average, fuzzy logic considers each point separately. So, this method could find a way for simulating intervals corresponded to either very high or very low permeability values. The simulated values shows a quiet good coincide with the referenced core reported ones.
In this study, we used a spatial algorithm for assigning representative value to each permeability geo-category, in which permeability geo-categories sorted in ascending order and classified into three groups. Minimum occurred permeability in each category is considered as the representative permeability value for one-third of first k-categories whereas mean and maximum values respectively assigned to the k-categories in second and last groups.
Furthermore, we showed that the model is highly dependent to the number of permeability geo-categories such that, much finer permeability bin categorization will significantly increase the precision of predictions.
ACKNOWLEDGMENTS
This article was prepared under the supervision and permission of NIOC (National Iranian Oil Company) and by cooperation with Petroleum University of Technology (PUT). The authors would like to thank the staffs of Petroleum University of Technology for their help and close cooperation. Our special thanks should go to the Pars Oil and Gas Company’s Research Department for their kind help and supports during this study. We also appreciate the critical reading by arbitration committee and we will be acknowledging our gratitude for enlightening suggestion and insightful comments.
REFERENCES
- Babadagli, T. and S. Al-Salmi, 2003. A review of permeability prediction methods for carbonate reservoirs using well-log data. SPE Format. Evaluat. Eng., 7: 75-88.
Direct Link - Badarinadh, V., K. Suryanarayana, F.Z. Youssef, K. Sahouh and A. Valle, 2002. Log-derived permeability in a heterogeneous carbonate reservoir of the Middle East Abu Dhabi, Using artificial neural network. Proceedings of the SPE 78487, 2002 Abu Dhabi International Petroleum Exhibition and Conference, October 13-16, 2002, Dhabi, United Arab Emirates, pp: 13-13.
Direct Link - Carlos, F.H., 2004. The perfect permeability transform using logs and cores. Proceedings of the SPE 89516, 2004 SPE Annual Technical Conference and Exhibition in Houston, September 26-29, 2004, Texas, USA, pp: 17-17.
Direct Link - Cuddy, S.J., 2000. Litho-facies and permeability prediction from electrical logs using fuzzy logic. SPE Reserv. Evalu. Eng., 3: 319-324.
CrossRefDirect Link - Hambalek, N. and R. Gonzalez, 2003. Fuzzy logic applied to lithofacies and permeability forecasting. Proceedings of the SPE-81078 Latin American and Caribbean Petroleum Engineering Conference, April 27-30, 2003, Trinidad, West Indies, pp: 1-10.
Direct Link - Lim, J.S. and J. Kim, 2004. Reservoir porosity and permeability estimation from well logs using fuzzy logic ad neural network. Proceedings of the SPE 88476-MS, 2004 SPE Asia Pacific Oil and Gas Conference and Exhibition, October 18-20, 2004, Perth, Australia, pp: 9-9.
Direct Link - Mohagheh, S., B. Balan and S. Ameri, 1997. Permeability determination from well log data. SPE Format. Evalut. Eng., 12: 170-174.
Direct Link - Mohaghegh, S., 2000. Virual intelligence and its applications in petroleum engineering 3-Fuzzy logic. J. Petroleum Technol., 52: 82-87.
CrossRefDirect Link - Saggaf, M.M. and E.L. Nebrija, 2003. A fuzzy logic approach for the estimation of Facies from Wire-Line logs. AAPG. Bull., 87: 1223-1240.
Direct Link - Saggaf, M.M. and E.L. Nebrija, 2000. Estimation of lithologies and depositional Facies from wire-line logs. AAPG. Bull., 84: 1633-1646.
Direct Link - Taghavi, A.A., 2005. Improved permeability estimation through use of fuzzy logic in a carbonate reservoir from Southwest Iran, SPE 93269. Proceedings of the 14th SPE Middle East Oil and Gas Show Conference, March 12-15, 2005, Bahrain International Exhibition Centre, Bahrain, pp: 1-9.
Direct Link