
O.D. Orodu
Faculty of Resources, China University of Geosciences (Wuhan), Wuhan 430074, People Republic of China
Z. Tang
Faculty of Environmental Studies, China University of Geosciences (Wuhan), Wuhan 430074, People Republic of China
Q. Fei
Faculty of Resources, China University of Geosciences (Wuhan), Wuhan 430074, People Republic of China
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 10 | Page No.: 1801-1816







ABSTRACT
This study analyzes three prediction approaches of the Bayesian method for predicting Hydraulic Unit (HU) and consequently predicts permeability for Block Shen-95. These approaches are intersection of multiple well-logs, independent mulitple well-logs and mutually exclusive multiple well-logs. In this study, HU was delineated to efficiently compute permeability and served as the building block of structural model for enhanced simulation study. HU is defined by the flow zone indicator concept from the modified Kozeny-Carmen equation. The Bayesian method was used to predict HU at uncored wells. This is done by first constructing a probability database through the integration of established HU and well-log responses at cored wells. HU is then inferred from the database using well-log responses. By comparison, estimated permeability from predicted HU gave an overall improved permeability match to that of traditional statistical methods. More so, mutually exclusive multiple well-logs proved more favourable. The highlight is that significant relationship exists by integrating reservoir performance with HU distribution indicating that reasonable prediction was obtained at uncored wells from the use of the mutually exclusive approach. The distribution was made possible by interwell HU correlation using depositional cycles as a framework but with modification. This integration step qualitatively examines prediction accuracy.
PDF Abstract XML References Citation
How to cite this article
O.D. Orodu, Z. Tang and Q. Fei, 2009. Hydraulic (Flow) Unit Determination and Permeability Prediction: A Case Study of Block Shen-95, Liaohe Oilfield, North-East China. Journal of Applied Sciences, 9: 1801-1816.
DOI: 10.3923/jas.2009.1801.1816
URL: https://scialert.net/abstract/?doi=jas.2009.1801.1816
DOI: 10.3923/jas.2009.1801.1816
URL: https://scialert.net/abstract/?doi=jas.2009.1801.1816
INTRODUCTION
Oil recovery in Block Shen-95 is estimated at 11.96% in 2006 based on 1998 volumetric estimate of oil originally in-place. The block is marked by low water injectivity and the inability to properly history match field performance. These are likely due to the high pour point nature of the crude oil in the block. The occurrence of paraffin precipitation at the injection well vicinity is due to cold waterflooding and regions of pressure reduction below bubble-point pressure may cause permeability reduction for this highly compartmentalized block by post-depositional faults.
As a first step, permeability has to be properly characterized towards obtaining a reasonable and acceptable history match against performance forecast and simulation studies of various enhanced oil recovery schemes. Permeability can be estimated to an appreciable degree from the concept of hydraulic (flow) unit at cored and uncored wells with the advantage of over 200 logged wells. Traditional regression based approach results in average permeability with low data scatter compared to core data (Wendt et al., 1986). Permeability prediction from logs tend not to wholly honour permeability trend but is better off with the application of discriminant analysis based on petrological variables such as grain size (Jennings, 1999; Adams, 2005).
Hearn et al. (1984) introduced the concept of flow unit to determine the distribution of rock types that most strongly control fluid flow and defined a flow unit as a reservoir zone that is continuous both laterally and vertically and has similar permeability, porosity and bedding characteristics. In their study, stratigraphic sequence provided the initial framework for flow unit delineation with petrophysical properties and petrographical analysis. Flow unit has evolved from the initial conception by Hearn et al. (1984) with the use of different parameters for delineation which include reservoir process/delivery speed and k/Φ plotted as constant lines on Pickett plot (Aguilera and Aguilera, 2002); stratigraphic modified Lorenz plot (Gunter et al., 1997); R35 (pore throat radius measured at 35% mercury saturation) from Winland’s equation with 4 basic flow units classified by Megaports (R35>10 μm), Macroport (2-10 μm), Mesoport (0.5-2 μm) and Microport (R35<0.5 μm) (Martin et al., 1997) and combined delineation parameters kh/μ (transmissibility), Φcth (storativity) and net-to-gross (Ti et al., 1995). Other flow unit delineation parameters and models are flow zone indicator (FZI) discussed below; a generalized approach by Lawal and Onyekonwu (2005), integrating FZI, R35 and rb (grain size) and statistical zonation based on permeability heterogeneity (Testerman, 1962). All these delineation methods are static based. Flow-based technique exist but static-based are widely used. The short coming of a recent flow-based technique (Schatz and Heinemann, 2007) is the use of upscaled reservoir properties in a geological model. This is unlike the use of core and well log data in static based techniques.
The flow unit discriminator parameter presented by Amaefule et al. (1993) has theoretical footing from the concept of bundle of capillary tubes considered by Kozeny and Carmen. Kozeny and Carmen both cited in Amaefule et al. (1993). This incorporated the Darcy’s and Poiseuille’s laws for flow in a porous media and tubes and the concept of mean hydraulic unit. FZI is applied for flow unit delineation and no distinction shall be made between flow unit and Hydraulic Unit (HU), or hydraulic flow unit. Both flow unit and hydraulic unit shall be used interchangeably.
This study covers the FZI delineation concept from theory to practical application of HU delineation and prediction. Bayesian statistical method is used to predict HU at uncored wells having well-logs by considering different relationships between the well-logs. Furthermore, sensitivity analysis was carried out on different number of HU delineated categories with different combinations of well-log response discretization. The choice of optimal HU delineation and prediction scheme is verified. Verification of predicted HU in uncored wells is with respect to reservoir performance, plan view status map of HU distribution, interwell HU cross-section and perforation thickness linked to HU categories. As well as other traditional verification methods specifically for cored wells.
MATERIALS AND METHODS
HU theory: Amafule et al. (1993) presented the method for the use of hydraulic flow units to divide rock facies as a result of the considerable variation of permeability even in well defined rock type. This method is based on mineralogy and texture which defines similar fluid flow characteristics that is independent of lithofacies. Amafule et al. (1993) used the concept of bundle of capillary tubes and gave an equation which was re-arranged to isolate the variable that is constant within a HU. This presented the optimal use of the equation. The re-arranged Eq. 1 is:
(1) |
where, k is permeability (md); Φe is effective porosity; Fs is shape factor; τ is tortuosity; and Sgv is surface area per unit grain volume (μm).
(2) |
(3) |
(4) |
(5) |
where, RQI is reservoir quality index (μm); Φz is pore volume-to-grain volume ratio and FZI is flow zone indicator (μm).
Equation 2-4 are used to compute the functions for plotting a log-log plot based on (Eq. 5) for RQI versus Φz. All data that have similar FZI will be on a straight line slope equal to one and the value of FZI is determined at the intercept of the slope at Φz=1. Thus, all data on the same straight line can be taken to have similar pore throat attributes (the same hydraulic unit) governing flow. Moreso, from Eq. 6 below, permeability can be computed for all those points on the same straight line with same FZI.
(6) |
FZI incorporates mineralogy and texture to efficiently discriminate rock facies having similar fluid flow attributes as demonstrated by statistical techniques. Particularly, pore geometry attributes that influence zoning was verified with petrographic data, in situ condition on RQI and capillary pressure to characterize pore throat structure.
HU classification, prediction and verification: Classification follows the detailed methodology presented by Abbaszadeh et al. (1996) using graphical analysis of probability and histogram plots of log FZI and Ward’s hierarchical clustering method. This is verified with R35.
The traditional approach at predicting HU at uncored wells that have well-logs relies on the Bayesian method (Abbaszadeh et al., 1996). Other methods are Artificial Neural Network (ANN) (Aminian et al., 2002, 2003) and the recent classification tree concept (Perez et al., 2005). Of all the applications of the classification tree concept to electrofacies, lithofacies and HU prediction from well-logs, HU result was worst off. The Bayesian method is applied to predict HU category from well-log based on established HU from cored wells. It involves inferring the probable HU of a well at a particular depth using well-log responses based on the HU probability database of discretized well-log responses. The database is from the link of established HU at cored wells to their respective well-log responses collectively. A problem of accuracy arises as stated by Abbaszadeh et al. (1996) on the number of bins required from the well-log discretisation exercise. It is an issue for concern since accuracy increases with increase in number of bins but increases computation time. Equation 7 shows the posterior conditional probability p(HUj|x) for each HU category with respect to a well-log response. And Eq. 8 is the corresponding HU probability for independent multiple well-logs given a simplified expression for posterior conditional probability. Equation 9 stands for intersection of multiple well-logs. The application of the Bayesian technique to facies identification similar to HU prediction in uncored wells by the study of Kapur (1998) states a limit for increase of bins as regards to that study. Optimal number of bins is related to the ratio of data size to number of bins. Furthermore, the particular HU chosen is that of the highest probability. The application of Eq. 7 and 8 are clearly stated by Abbaszadeh et al. (1996) and Li and Anderson-Sprecher (2006). While Eq. 9 is shown by Kapur (1998):
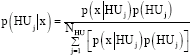 | (7) |
where, p(x|HUj) is the conditional probability of well-log response x, for a particular HU and p(HUj) is prior probability of occurrence of HU from core data classification. The use of Eq. 7 is by the addition of the posterior probability computed for each well-log suggesting mutually exclusive multiple well-logs:
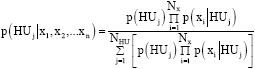 | (8) |
where, xi represents well-log responses x1, x2,…xn; p(HUj| x1, x2,…xn) is posterior HU probability with respect to independent multiple well-log responses; the other variables are similar to Eq. 7:
(9) |
where, P(xi) is p(x1∩x2…….∩xn) the probability of intersection of multiple well-log responses; p(xi|HUj), p(x1∩x2…….∩xi|HUj) prior and conditional probability of intersection of multiple well-log responses for jth HUj; p(HUj|xi), p(HUj| x1∩x2…….∩xn) posterior jth HUj probability considering intersection of multiple well-log responses.
Verification is largely a qualitative process. Optimal HU definition is first of all selected based on statistical analysis. The optimal HU involves the comparison of core permeability and that derived from various HU definitions with different combinations of well-log responses discretization. Secondly, the chosen definition and discretization is applied for prediction in all uncored wells. The accuracy of predicted HU is examined qualitatively by tying reservoir performance to HU distribution from interwell cross-section obtained from interwell HU correlation. This approach was initially applied by Martin et al. (1997) as a process of linking reservoir performance to identify flow unit quality and distribution in the reservoir. It was basically tying performance to the individual delineated flow unit thickness at well locations (Gunter et al., 1997). In this study, the link is tied to performance curves with interwell HU cross-section, connectivity, perforation face HU thickness and nearby injection well influence. Thirdly, the tie of HU to lithology.
GEOLOGICAL SETTING
Block Shen-95 is in Liaohe basin of the Jinganbao oil-bearing structure belt of Damintun depression in Xinmin city, Liaoning Province, North-East China (Fig. 1). The block is faulted, anticline in nature, oil-bearing strata dipping NW, major axis 6.8 km and minor axis 3.3 km, area of 15.8 km2 and structurally above a naturally fractured carbonate reservoir. The block is divided into two main sub-blocks North and South with respect to one of the major sealing faults in the NE direction (Fig. 1). The block has a complex system of faults with sealing, partial sealing and non sealing faults (faults are normal and growth faults). Oil-bearing strata is of the Shahejie formation of the Paleogene period (Eocene) within the subsurface depth of 1800-2230 m and consisting of an average porosity of 19% and low permeability of 3 mD. Reservoir depositional environment is fluviodeltaic (having 12 depositional sedimentary environments) with relatively small sand body and poor connectivity due to its complex depositional structure. Sedimentation took place when the basin was stable prior to depression. From geological model, the reservoir has 3 zones and 17 layers which are heterogeneous with high variation in thickness and poor horizontal connectivity. The top zone is marked by downward fining and the 2 other zones by downward coarsening grain size. Vertical reservoir heterogeneity from Lorenz plot is about 0.8082 from 5 cored wells within the block under study. There is no gas cap but alternating cycles of oil-water interval and edge water with negligible pressure support. Formation water is composed mainly of fresh water.
Oil Originally In-Place (OOIP) estimate stands at 2084x104 t by 1984 and 1440x104 t by 1998 based on volumetric estimates. Exploration of the block commenced in late 1988 and by late 2006 the block had 78 production (47 active producing wells) and 31 injection wells (8 active injection wells) with an average daily injection rate of 33 m3 day-1 and monthly instantaneous Voidage Replacement Ratio (VRR) of 1.04 compared to the peak injection rate of 125 m3 day-1 and VRR of 4.1 with 9 injection wells (7 active injection wells) by early 1991. By late 2006, watercut was 56.98% and cumulative oil production was 172.29x104 t.
RESULTS
Six cored well data are available for analysis (J17, J37-69, J43-67, J49-75, J53 and J74, Fig. 1). J53 is out of the boundary under study and cored zone is not known and has no SP well-log. The other wells have SP, Acoustic-AC (S-Wave) and true formation resistivity (RT) well-logs except J17 with deep resistivity electrical log (RL3D). J37-69, J43-67, J49-75 and J74 are chosen for HU classification. All log data have already been depth shifted and cored data was not filtered to honour vertical resolution with well-log.
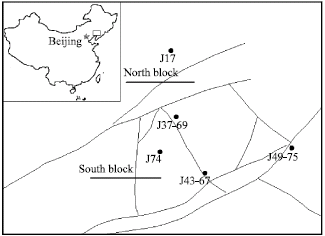 | |
| Fig. 1: | Cored well location with major faults indicated and block location |
This is to preserve reservoir heterogeneity or it may have a negative impact on the inherent pore geometrical attributes related to FZI. Table 1 shows the distribution of core sample points in the 3 zones and available well-logs.
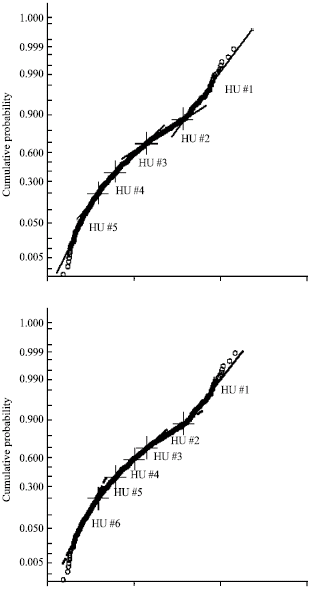
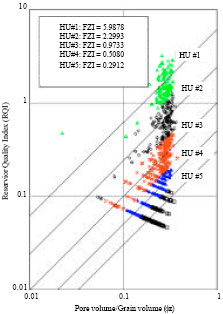
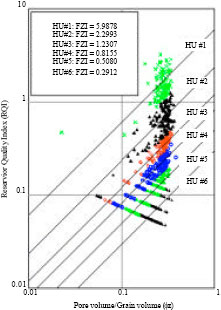
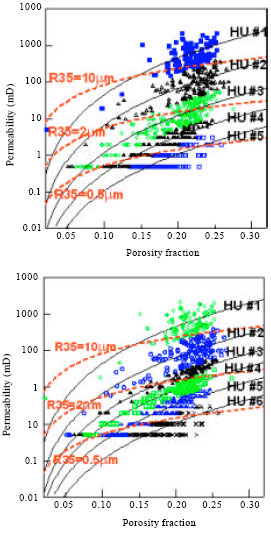
HU classification: Probability plot of FZI for each well shows common division into 4 HU’s apart from that of J17 and J37-69 with 2-3 HU’s by visual observation with a straight line drawn through it (not shown due to space restriction). To encompass the reservoir heterogeneity from the cored wells, J37-69, J43-67, J49-75 and J74 were combined for classification to enable reasonable HU prediction from well-logs. Probability plot from this indicated 4 visually distinguishable HU categories (Fig. 2) and histogram plot of FZI and logarithm of FZI showed superposition of more than 4 log-normal and normal distributions. However, with Ward’s hierarchical cluster analysis on SPSS® optimal number of clusters were selected (5, 6 and 9 HU categories identified as HU5, HU6 and HU9, Fig. 2). The selection process took into account the distribution of sample points to reasonably prevent the domineering or overshadowing of larger data set of a particular HU over another. RQI vs Φz were plotted for the 3 HU definitions (HU5, HU6 and HU9) and for each HU category in the definition straight lines with slope 450 were drawn to Φz = 1 at the mean FZI for that category (Fig. 3). The earlier plot coupled with permeability (k) vs porosity (Φ) (Fig. 4) for each HU definition illustrates the narrowing of data scatter in each HU category with the increase of HU categories from 5 to 9 and the improvement of coefficient of correlation for kHU vs. kcore (HU5 = 0.9590, HU6 = 0.9679 and HU9 = 0.9856) especially for high permeability values. Table 2-4 are summary of core sample point distribution in each HU category for each HU definition. Also, the superposition of pore throat radius (R35) with Winland’s equation on the classical division into 4 flow units shows encouraging results of the clustering process (Fig. 4).
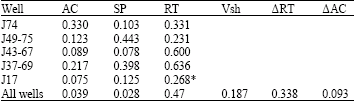
HU prediction: Table 3 shows the Spearman’s rank correlation of 5 cored wells within the boundary of interest with J17 least appreciable compared to others. Both AC and SP logs are quite low.
| Table 1: | Well core data and logs |
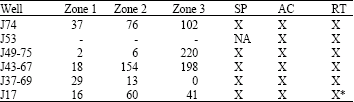 | |
| *RL3D deep resistivity electrical log | |
 | |
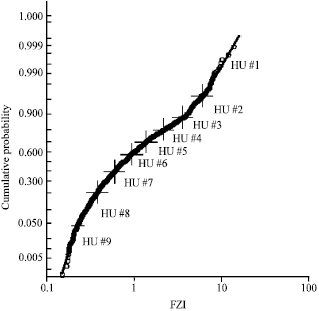 | |
| Fig. 2: | HU classification for HU5, HU6 and HU9 |
 | |
 | |
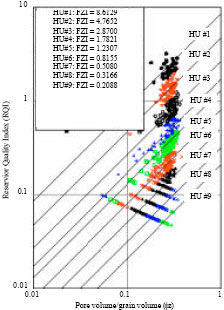 | |
| Fig. 3: | HU delineation for HU5, HU6 and HU9 |
 | |
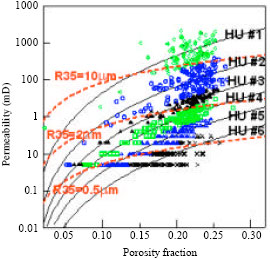 | |
| Fig. 4: | k-Φ delineation and relationship plot with R35 verification |
However, SP and RT logs are used. Firstly, SP was linearly normalized to give shale volume (Vsh) as well-log response range, minimum and maximum values vary considerably. RT and Vsh are used for HU inference.
A database consisting of probability of occurrence for each HU category corresponding to well-log response discretized data range is assigned to all HU definitions of HU5, HU6 and HU9.
| Table 2: | HU5 classification data distribution |
| Table 3: | HU6 classification data distribution |
| Table 4: | HU9 classification data distribution |
This depends on the use of either intersection of multiple well-logs, independent or mutually exclusive multiple well-logs. Different combinations of Vsh and RT number of bins were used. The numbers of bins are RT-A, 6; RT-B, 8; Vsh-A, 3 and Vsh-B, 5. For RT, bin size was based on multiple of 2 and then on logarithm of RT since it is not normally distributed and by observing the distribution of the logarithm of RT for all wells collectively.
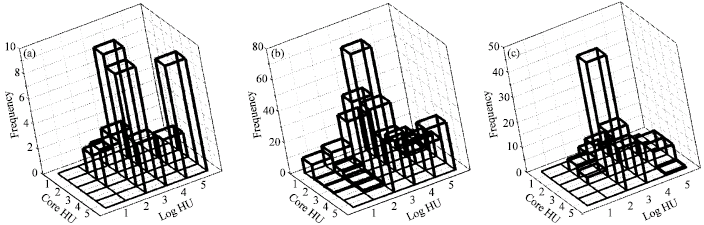
Predicting HU for each HU definition depends on the combination of well-log data discretization based on 1 (Vsh-A and RT-A), 2 (Vsh-A and RT-B) and 3 (Vsh-B and RT-B) for constructing a probability database for HU inference. In other words, HU prediction was carried out on HU5-1 (Vsh-A and RT-A), HU5-2 (Vsh-A and RT-B), HU5-3 (Vsh-B and RT-B); HU6-1 (Vsh-A and RT-A), HU6-2 (Vsh-A and RT-B), HU6-3 (Vsh-B and RT-B) and HU9-1 (Vsh-A and RT-A), HU9-2 (Vsh-A and RT-B) HU9-3 (Vsh-B and RT-B). The outcome of HU prediction leading to k prediction for some wells and application to predict HU and k for well J17 (not included in combined cluster analysis and probability database build-up) and the corresponding k prediction from k-Φ relationship based on each sequence stratigraphy zone is presented in Fig. 5 and 6 for correlation of predicted permeability to core permeability. Figure 5 represents the mutually exclusive concept (from each well-log by Eq. 7) and Fig. 6 that of intersection of multiple well-logs by Eq. 9. Comparing Fig. 5 and 6 give a glaring preference for the mutually exclusive multiple well-logs over that of the intersection of multiple well-logs consideration. Optimal k prediction is obtained with HU5-1 and HU6-3 having the latter as the best combined k prediction. HU histogram for both is shown in Fig. 7. Selection of the best HU definition and combination of well-log responses discretization scheme with the aid of Fig. 5 is highly subjective. The choice of HU definition can be narrowed down to a few but not essentially the best. A good HU prediction fit from HU histogram plot should be a spread of data frequency narrowed to the main diagonal which for the plots shown may be reasonable and acceptable.
The major distribution of the frequency plot is within the vicinity of HU category with high frequency as shown in Table 1-3. HU histogram plot is rather a qualitative means approach.
 | |
| Fig. 5: | Correlation between predicted and core permeability for different HU inference combination (mutually exclusive multiple well-logs case) |
 | |
| Fig. 6: | Correlation between predicted and core permeability for different HU inference combination (intersection of multiple well-logs case) |
 | |
| Fig. 7: | Statistical HU Comparison for cored wells J37-69 and J43-67 including well J17 by HU5-1 and HU6-3. (a) HU5-1: J37-69, (b) HU5-1: J43-67, (c) HU5-1: J17, (d) HU6-3: J43-67, (e) HU6-3: J37-69 and (f) HU6-3: J17 |
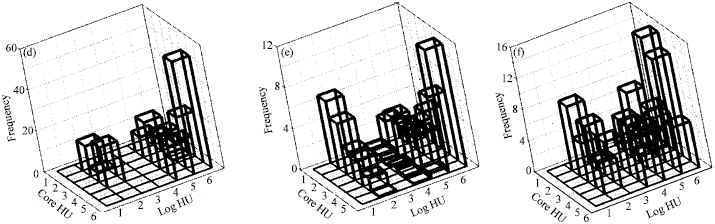
Figure 6 shows the HU histogram for individual wells with HU5-1 and HU6-3. And Fig. 8-10 shows HU prediction, k prediction and correlation plots for some wells including J17 not included in the combined HU classification and probability database construction. Prediction of k for J17 is reasonable considering that it was not included in HU classification and inference build-up, but exhibited less number of HU categories from FZI probability plot discrimination analysis.
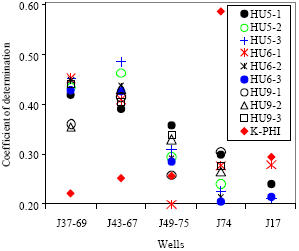
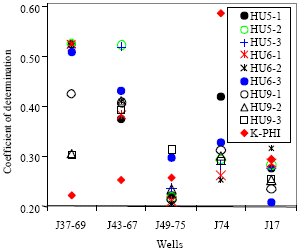
On observation of the statistical HU comparison plot for cored wells and Table 2-4 one can draw a conclusion. The HU distribution (Fig. 7) depends on the core sample point distribution in each HU category for each HU definition as seen in Table 2-4. Also, correlation between predicted k and core k which depicts predicted HU accuracy is hinged on the degree of correlation between well-log responses and either FZI or k. Wells with high correlation coefficient between well-log responses and FZI showed better prediction power as shown in Table 5 and Fig. 5. HU5-1 may be a better predictor from the cluster of histogram to the main diagonal shown in Fig. 7 compared to HU6-3. So, HU5-1 is chosen. Further analysis, prediction and verification are therefore based on this HU definition.
 | |
| Fig. 8: | HU and permeability prediction Well J43-67 by HU5-1 and HU6-3. (a) HU5-1: J43-67, (b) HU5-1: J43-67, (c) HU6-3: J43-67 and (d) HU6-3: J43-67 |
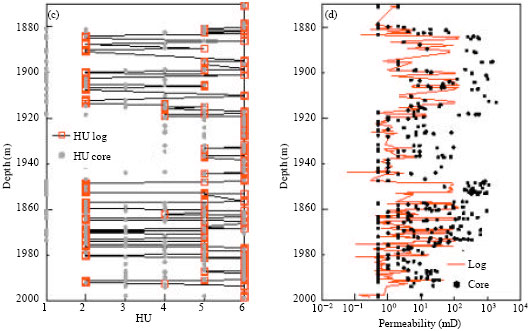
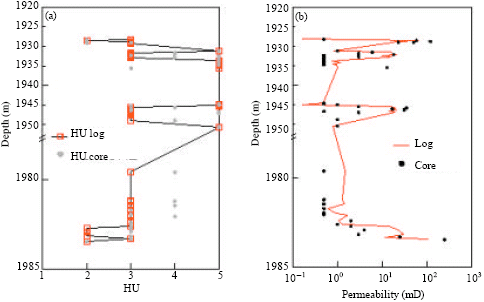 | |
| Fig. 9: | HU and permeability prediction Well J37-69 by HU5-1 and HU6-3. (a) HU5-1: J37-69, (b) HU5-1: J37-69, (c) HU6-3: J37-69 and (d) HU6-3: J37-69 |
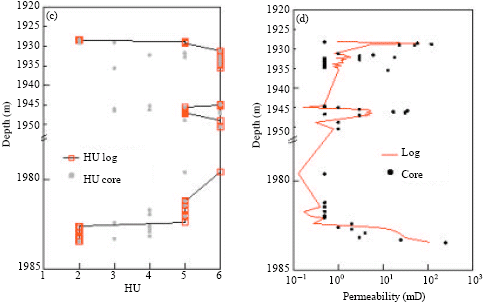
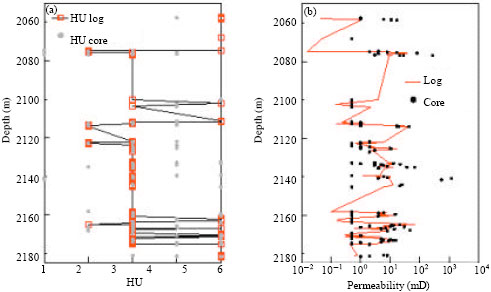 | |
| Fig. 10: | HU and k prediction Well J17 by HU5-1. (a) HU5-1: J17 and (b) HU5-1: J17 |
HU VERIFICATION
The choice of HU definition was based on the predictive power of permeability on cored wells. However, the verification of predicted HU at uncored wells having well-logs and further validation at cored wells relies on the link to dynamic and static data. The use of dynamic data of reservoir performance curves is linked to the perforation thickness in each HU category and interwell HU cross-section. This also takes into cognizance injection well influence based on connectivity to production well. It generally accounts for HU connectivity and distribution. Static based comparison is linked to lithology. This is applicable to only cored wells.
HU is computed for all logged wells numbering over 100 from the probability database for HU inference. In 15 interwell cross-sections covering the entire block, 100 wells were used for HU correlation using the depositional layer structure as a framework which was not entirely honored. A structural model based on this correlation was built consisting of 51 layers. This model serves as the HU model (Fig. 11).
Dynamic HU verification: For the purpose of dynamic HU verification 12 wells were used to correlate reservoir performance to HU. These wells are grouped into H (high productive wells), M (medium productive wells) and L (low productive wells) by qualitative analysis. Classification was basically on initial production rate, cumulative oil production and watercut. This was tied to perforation thickness in each HU category, HU distribution, thickness and connectivity from interwell cross-sections (Fig. 12-14). The classification into H (4 wells), M (4 wells) and L (4 wells) were clearly discernable except that of 2 wells. All apart from 1 well classified into H has relatively high perforation thickness in the highest quality HU that is HU #1.
| Table 5: | Spearman’s rank correlation well log responses with FZI |
 | |
| *RL3D (deep resistivity) | |
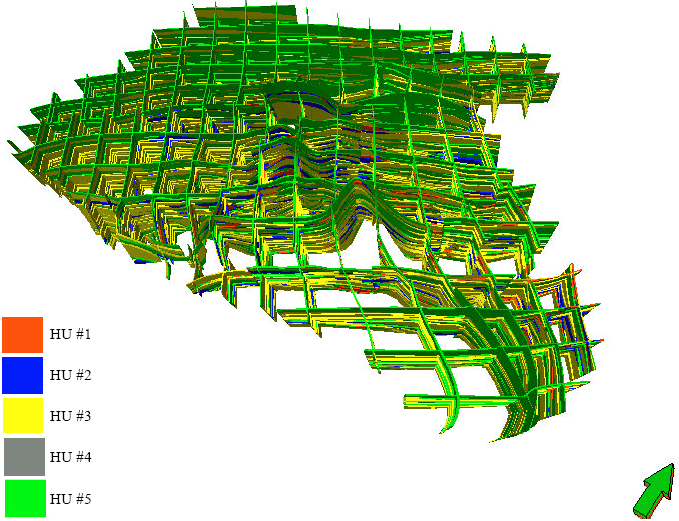 | |
| Fig. 11: | Fence diagram HU model |
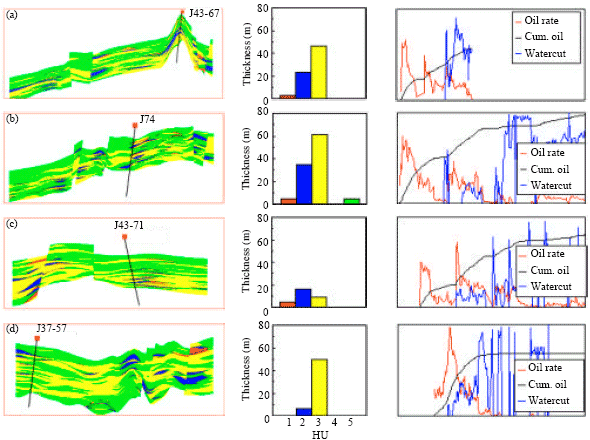 | |
| Fig. 12: | (a-d) Link of reservoir performance to perforation thickness for each HU category and HU distribution for high production wells |
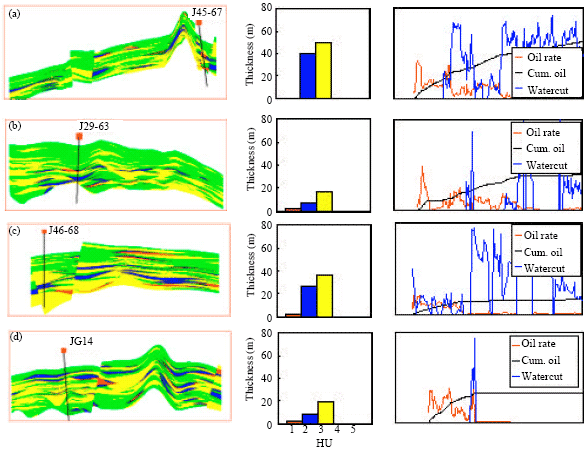 | |
| Fig. 13: | (a-d) Link of reservoir performance to perforation thickness for each HU category and HU distribution for medium production wells |
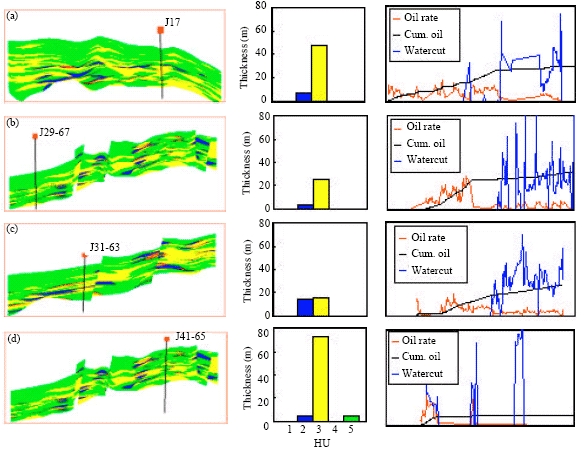 | |
| Fig. 14: | (a-d) Link of reservoir performance to perforation thickness for each HU category and HU distribution for low production wells |
This was due to high connectivity with respect to 3 nearby injection wells. The well in question, J37-57 has no HU #1. This is a good account for verifying prediction, in particular, the influence of interwell connectivity. Classification of wells J45-67 and J46-68 into M does not justify the perforation thickness in each HU category and also HU distribution. However, for well J45-67 with respect to HU distribution, cumulative production and perforation distribution this well may be classified into H. The isolation of this well by the partially sealing faults may account for the low but steady production trend giving rise to a possibly acceptable HU prediction. For J46-68, both HU distribution from cross section and perforation thickness at various HU categories can not explain the inability to tie these to performance. In this case, predicted HU may be questionable.
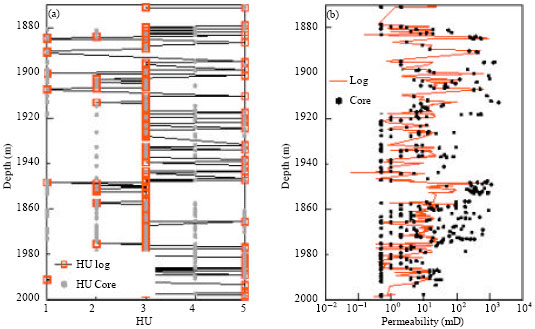
Static HU verification: This seeks to ground truth HU with available lithology from core. The well considered show high correlation to clay, silty clay and silt, specifically with the lowest quality (HU #5) and silt to a lesser degree with HU #3. HU#1 and #2 are rather correlated to gravel and fine sand and to a lesser extent with very fine sand. Considering well J74 shown in Fig. 15, it has significant correlation to lithology. However, HU does not entirely correspond to lithology but the flow characteristic of lithology. In addition, shown in Fig. 15 is the integration of R20 with a good link to HU. R20 is obtained from data local to the block. R20, pore throat radius at 20% mercury saturation was the best fit to 35 sample points from two wells with a correlation of 0.948.
Figure 16 gives a summary of the workflow from HU classification to verification as applied in this study.
DISCUSSION
There is a dearth on the discussion of the Bayesian approach to multiple well-logs and its simplified applications on HU. Most references limit presentation to a well-log without further explanation on application to multiple well-logs. HU inference in this study was largely done by addition of HU probability from individual well-log responses for similar HU category at the same depth. This connotes that HU probability estimation is independent of each well-log as in Tang and White (2008) application to facies, but mutually exclusive.
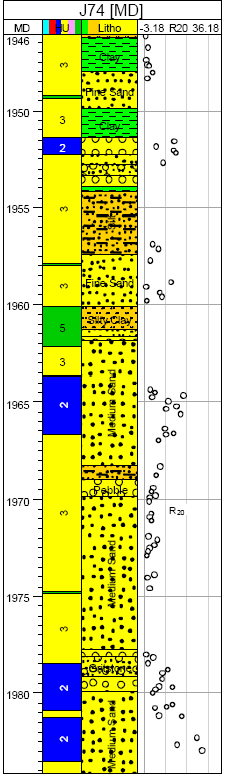 | |
| Fig. 15: | Link of HU to lithology for well J74; Track 1 -HU, Track 2 -Lithology, Track 3 -R20 |
Therefore, each well-log can determine HU at a particular depth irrespective of the fact that HU probability from other well-log might be zero or negligible towards contributing to the sum of probability for a particular HU category. Using the additive rule is a simplified approach. However, in comparison to the intersection of multiple well-logs at the same depth, the simple additive rule was slightly better off.
 | |
| Fig. 16: | Summary of HU classification, prediction and verification workflow |
This is based on permeability prediction. Also, independent multiple well-logs gave higher HU prediction accuracy but with the inability to predict 2 HU categories out of the 5 HU categories from the chosen HU5 definition. Both simplification schemes clearly depicts the success of independent multiple well-logs as applied by Tang and White (2008) and Li and Anderson-Sprecher (2006) to facies prediction.
The increase in the number of bins of well log discretization yields better overall correlation until a certain limit where further increase as in the case of HU6-3 inference gives an overall poor result from predicted permeability correlation with core derived permeability. This is in line with the study of Kapur (1998) for facies prediction by the Bayesian method and the statement by Abbaszadeh et al. (1996). However, the increase in number of bins resulted in remarkable improvement of accuracy for certain HU categories. In particular, that of the highest quality HU category compared to reduction in accuracy for the low quality categories. This may be related to the poor well-log responses correlation to FZI and/or permeability. There is a drift towards the non-discretization of well-log responses with the independent multiple well-logs concept. The application results in successful facies classification by the Bayesian technique in fitting prior probability with probability distribution function (Beta and Gaussian distribution function and Kernel density estimation, Tang and White (2008) and Li and Anderson-Sprecher (2006)).
There remains, the non explanation of the failure to delineate HU #4 with well-logs during HU prediction for the chosen HU definition, HU5-1. The choice of HU5-1 definition over that of same number of categories (HU5-2 and HU5-3) and definitions with 6 and 9 HU categories (HU6-1, HU6-2, HU6-3; HU9-1, HU9-2 and HU9-3) is based on coefficient of determination of core permeability to permeability computed from the respective definitions.
The reasonable link of reservoir performance with HU distribution depicts the relationship of the integration of reservoir performance to quality of flow unit and its distribution. It attests to tying the spatial distribution of data patterns of flow based attributes to similar performance regions by Martins et al. (1997). As such, this significantly serves as a reasonable means of qualitative HU prediction accuracy in uncored wells before the tedious reservoir simulation process. From this point, it can be said that HU prediction is relatively acceptable. However, for lithology, it was not entirely successful. HU #5, the lowest quality hydraulic unit showed the best match with lithology (clay, silty clay and silt). Not surprising, Amaefule et al. (1993) had concluded that multiple flow unit exists within a particular rock type (lithofacies) as pore geometry attributes can efficiently characterize HU. Ebanks (1987) likewise stated that flow unit does not always coincide with lithofacies, while Biniwale and Benhrenbruch (2004) stated that depositional trends and diagenesis are the major factors that control HU quality.
The R20 correlation was suitable for computing pore throat radius using core permeability and porosity for verifying predicted HU. But, its use for verifying the classification of HU based on Ward’s hierarchical cluster analysis was not successful. This was as a result of the capillary data set not encompassing wide variability of reservoir heterogeneity. The situation is due to the low correlation of porosity to pore throat radius. Hence, Winland’s R35 equation was used. It is widely accepted as it contains large data set of varying sandstone particle size. The geological time of the sandstone is within the same range as that of Block Shen-95 making it suitable for use.
The basic verification of the strength of flow unit delineation in uncored wells is by simulation study, examples of case studies are Ti et al. (1995), Gunter et al. (1997) and Svirsky et al. (2004). This is time consuming. Svirsky et al. geostatistically populated HU, stochastically across a reservoir and selected 3 realizations based on P10, P50 and P90% recovery from uncertainty analysis using streamline simulation. It may not be a true representation of HU distribution across the reservoir and likewise it is time consuming. Interwell HU correlation, though subjective as applied in this study seems a better approach to populating the reservoir with further assessment of established HU by well-logs and facies or depositional environment structural model.
CONCLUSIONS
Hydraulic Unit (HU) was delineated, predicted from well logs and validated based on Kozeny-Carmen equation, Bayesian statistical method, reservoir performance, petrophysical properties and lithology. The outcomes are:
| • | The mutually exclusive probability approach proved better than the intersection of multiple well-log responses approach for prediction of HU by the Bayesian technique. Whereas, independent multiple well-log responses had better overall HU category prediction though failed to predict 2 HU categories out of the 5 HU categories |
| • | HU prediction in uncored wells with the aid of well logs is to a larger extent an art based on finding the optimal well-log responses discretization for HU inference and the number of HU categories with its corresponding core sample point distribution |
| • | Permeability estimation may be considered satisfactory by HU with respect to high reservoir heterogeneity, number of cored wells available and poor well-log responses correlation to permeability and flow zone indicator |
| • | The integration of reservoir performance and HU distribution at both well locations and interwell cross-sections showed reasonable and acceptable qualitative match for the wells considered. This is a means of verifying predicted HU at both cored wells and uncored wells having well-log data. The HU distribution was made possible by interwell HU correlation using depositional cycles as a framework |
| • | The validation of HU with lithology was reasonable for high quality HU and had high accuracy for the lowest quality HU which corresponded to R20, pore throat radius at 20% cumulative mercury saturation |
ACKNOWLEDGMENT
The researchers thank Liaohe Oilfield Company for the funding of this research.
REFERENCES
- Abbaszadeh, M., H. Fujii and F. Fujimoto, 1996. Permeability prediction by hydraulic flow units-theory and applications. SPE Format. Evaluat., 11: 263-271.
CrossRef - Adams, S.J., 2005. Core-to-log comparison-what's a good match? Proceedings of the SPE Annual Technical Conference and Exhibition, October 9-12, 2005, Dallas, Texas, pp: 3943-3949.
CrossRef - Aguilera, R. and M.S. Aguilera, 2002. The integration of capillary pressures and Pickett plots for determination of flow units and reservoir containers. SPE Reserv. Evaluat. Eng., 5: 465-471.
CrossRef - Amafule, J.O., M. Altunbay, D. Tiab, D.G. Kersey and D.R. Keelan, 1993. Enhanced reservoir description: Using core and log data to identify hydraulic (flow) units and predict permeability in uncored intervals/wells. Proceedings of the 68th SPE Annual Technical Conference and Exhibition, October 3-6, 1993, Houston, Texas, Society of Petroleum Engineers, pp: 205-220.
- Aminian, K., B. Thomas, S. Ameri and H.I. Bilgesu, 2002. A new approach for reservoir characterization. Proceedings of the SPE Eastern Regional Conference, Lexington, Kentucky, October 23-25, 2002, Society of Petroleum Engineers, pp: 117-126.
CrossRef - Aminian, K., S. Ameri, A. Oyerokun and B. Thomas, 2003. Prediction of flow units and permeability using artificial neural network. Proceedings of the SPE Western Regional Meeting, May 19-24, 2003, California, USA., pp: 297-303.
CrossRef - Lawal, K. and M.O. Onyekonwu, 2005. A robust approach to flow unit zonation. Proceedings of the 29th Annual SPE International Technical Conference and Exhibition, August 1-3, 2005, Society of Petroleum Engineers, pp: 1-1.
CrossRef - Li, Y. and R. Anderson-Sprecher, 2006. Facies identification from well logs: A comparison of discriminant analysis and na�ve Bayes classifier. J. Pet. Sci. Eng., 53: 149-157.
CrossRef - Martin, A.J., S.T. Solomon and D.J. Hartmann, 1997. Characterization of petrophysical flow units in carbonate reservoirs. AAPG. Bull., 81: 734-759.
Direct Link - Perez, H.H., A. Datta-Gupta and S. Mishra, 2005. The role of electrofacies, lithofacies and hydraulic flow units in permeability prediction from well logs: A comparative analysis using classification trees. SPE Reserv. Evaluat. Eng., 8: 143-155.
CrossRef - Schatz, B.M. and Z.E. Heinemann, 2007. Flow-Based determination of hydraulic units. Proceedings of the SPE Europe/EAGE Annual Technical Conference and Exhibition, June 11-14, 2007, Society of Petroleum Engineers, pp: 1030-1037.
CrossRef - Svirsky, D., A. Ryazanoz, M. Pankov, M. Corbett and A. Posysoev, 2004. Hydraulic units resolve reservoir description challenges in a Siberian oil field. Proceedings of the SPE Asia Pacific Conference on Integrated Modelling for Asset Management, March 29-30, 2004, Society of Petroleum Engineers, Kuala Lumpur, Malaysia, pp: 437-452.
Direct Link - Tang, H. and C.D. White, 2008. Multivariate statistical log log-facies classification on a shallow marine reservoir. J. Pet. Sci. Eng., 61: 88-93.
Direct Link - Testerman, J.D., 1962. A statistical reservoir-zonation technique. J. Pet. Technol., 895: 889-892.
CrossRef - Ti, G., D.O. Ogbe, W. Munly and D.G. Hatzignatiou, 1995. Use of flow units as a tool for reservoir description: A case study. SPE Format. Evaluat., 10: 122-128.
CrossRef