
S.M.H. Mojtahedi
Department of Industrial Engineering, Graduate School, Islamic Azad University, South Tehran Branch, Member of Young Researchers Club, No. 209, North Iranshahr Street, P.O. Box 11365/4435, Tehran, Iran
S.M. Mousavi
Department of Industrial Engineering, Graduate School, Islamic Azad University, South Tehran Branch, Member of Young Researchers Club, No. 209, North Iranshahr Street, P.O. Box 11365/4435, Tehran, Iran
A. Aminian
Department of Industrial Engineering, Islamic Azad University, Gachsaran Branch, P.O. Box 1694913445, Gachsaran, Iran
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 1 | Page No.: 113-120







ABSTRACT
The aim of this study is to propose one practical approach to use non-parametric bootstrap technique in risk management processes especially for analyzing risk factor data, because of the fact that in most decision making cases data sizes and expert`s comments are too small for analyzing risk factor data or often there are no parametric distributions on which significance can be estimated; therefore, standard statistical techniques do not always provide answers to complex risks questions. The non-parametric bootstrap is a powerful technique for assessing the accuracy of a parameter estimator in situations where conventional techniques are not valid and also non-parametric bootstrap technique is extremely valuable in situations where data sizes are too small. Bootstrap technique for decreasing the SD of risk factor data is described as well. Confidence intervals for risk factors are also obtained by means of bootstrap resampling technique. To make it more understandable, an application example is also provided. It can be concluded from the example that bootstrap will produce more accurate results in comparison with conventional techniques.
PDF Abstract XML References Citation
How to cite this article
S.M.H. Mojtahedi, S.M. Mousavi and A. Aminian, 2009. A Non-Parametric Statistical Approach for Analyzing Risk Factor Data in Risk Management Process. Journal of Applied Sciences, 9: 113-120.
DOI: 10.3923/jas.2009.113.120
URL: https://scialert.net/abstract/?doi=jas.2009.113.120
DOI: 10.3923/jas.2009.113.120
URL: https://scialert.net/abstract/?doi=jas.2009.113.120
INTRODUCTION
Risk is a concept that denotes a potential negative impact to some characteristic of value that may arise from a future event, or we can say that risks are events or conditions that may occur and whose occurrence, if it does take place, has a harmful or negative effect. Exposure to the consequences of uncertainty constitutes a risk. In everyday usage, risk is often used synonymously with the probability of a known loss. Risk communication and risk perception are essential factors foe all human decision making (Cooper et al., 2005).
A systematic process of risk management is divided into risk identification, risk analysis and risk response (Li and Liao, 2007; Duijne et al., 2008). Risk identification requires recognizing and documenting the associated risk. Risk analysis examines each identified risk issue, refines the description of the risk and assesses the associated impact. Finally, risk response identifies, evaluates, selects and implements strategies in order to reduce the likelihood of occurrence or impact of risk events.
Risk analysis has several objectives (Cooper et al., 2005):
| • | It gives an overview of the general level and pattern of risk facing the project |
| • | It focuses management attention on the high-risk items in the list |
| • | It helps to decide where action is needed immediately and where action plans should be developed for future activities; and it facilitates the allocation of resources to support management’s action decisions |
Depending on the available data, risk analysis can be performed qualitatively or quantitatively or semi quantitatively (Chapman and Ward, 2004; Groen et al., 2006). Chun and Ahn (1992) and Smith (1999) are trying to propose risk analysis techniques in various environments. Risks are prioritized according to their potential implications for meeting the stakeholders’ objectives. The typical approach to prioritizing risks is to use a look-up table or a probability and impact matrix. The better results emerge in the cost and time planning fields, in which the causal distribution of random events is analyzed to improve predictions. Although numerous techniques are at present available to practitioners for risk assessment (Dikmen et al., 2008) sophisticated simulation techniques or statistical techniques can be with difficulty adapted to technical risk multidimensionality.
Risk management has been developed mostly on the basis of cost and time risk, while technical risk analysis has not yet aroused wide interest on non-quality risk. Risk management is becoming an important management method in the planning of a reliable, suitable, adequate and subsequently more efficient real system, as it plays a key role in the quality management field toward a suitable, adequate and subsequently more efficient quality system for building in conformity to specifications (Kerzner, 2006). Quality planning, environmental control and safety planning require holistic approaches in process representation and a basic qualitative risk assessment. The Failure Mode and Effects Analysis (FMEA) (Hu et al., 2008), plays an effective role for a qualitative failure process analysis and provides a systematic, indexed order of technical risks.
Resampling techniques have been conventionally used as a means of tackling problems which are too complicated to be solved analytically. Over the past 30 years, the theoretical foundations for this technique have been expanded and substantiated (Efron and Tibshirani, 1993). These techniques are particularly suitable for hypothesis testing and for determining the accuracy of non-parametric or complex statistics for which closed-form formulae, if they exist, depend on extensive assumptions.
On the other hand, risk data analysis often encounters situations in which:
| • | It cannot be answered in a parametric framework for which closed-form formulae for accuracy exist |
| • | It may need to be examined by standard, existing tools, but the results exhibit a bias that influences inference |
| • | It can only be assessed by specially tailored algorithms or procedures that, in turn, require objective validation. As the occurrence and impact of risks are random; therefore, statistical approaches are required for analyzing risks effectively |
For these reasons, as well as due to the availability of fast computers, in this paper bootstrap resampling approach is proposed to use for analyzing risks. This approach is flexible, easy to implement, applicable in non-parametric settings and requires a minimal set of assumptions (Tak, 2004). In this study we hope to contribute to this area by providing a comprehensive framework for the application of bootstrap technique to data obtained from experts’ judgments. Reduction of SD for risks is shown in this study significantly by using non-parametric bootstrap technique. Moreover, the non-parametric bootstrap has been applied to estimate confidence intervals for the Risk Factors (RFs) in risk management process.
The normal (Gaussian) distribution is characterized by two parameters; the mean and SD. Statistical techniques that assume the Gaussian distribution of data are called parametric. Nonparametric or distribution-free statistical techniques are used to analyze data that do not assume a particular family of probability distributions. It is in this latter category of data that bootstrap techniques are valuable (Efron and Tibshirani, 1993; Henderson, 2005).
The bootstrap resampling technique developed by Efron (1979) has been used widely in statistical problems. It can be used where standard techniques cannot be applied, for instance in situations in which few data are available, so that approximate large sample techniques are not applicable. The bootstrap has subsequently been used to solve many other problems that would be too complicated for traditional statistical analysis (Ait-Sahalia and Duarte, 2003; Stark and Abeles, 2005). In simple words, the bootstrap does with the computer what the experimenter would do in practice, if it was possible, he or she would repeat the experiment (Modarres et al., 2006; Walters and Campbell, 2005). The main advantage of using the bootstrap resampling technique is that good estimates can be obtained, regardless of the complexity of the data processing. In this study, we show that the bootstrap resampling technique is well suited for estimating and decreasing SD for risk data.
PROPOSED APPROACH
Risk data sizes are always too small and also there are no parametric distributions on which significance can be estimated for risks data; therefore, non-parametric bootstrap technique is extremely valuable in situations where data sizes are too small. Moreover, the bootstrap is a powerful tool for assessing the accuracy of a parameter estimator in situations where conventional techniques are not valid (Armitage et al., 2002; Heiermann et al., 2005; William and Joseph, 2005).
Having considered all above mentioned reasons, here one practical approach is proposed to use in risk management process in three steps. In first step, principle of non-parametric bootstrap is described in order to resample risks data from original observed risks data. In second step, the bootstrap principle for estimating the SD of RFs is demonstrated in order to compare bootstrap resampled risk data with original observed risks data and finally in third step, the bootstrap principle for calculating a confidence interval for the mean of RFs is presented for better decision making in risk management process.
The non-parametric bootstrap principle (Step 1): Based on the first step of proposed approach, the bootstrap technique is a tool for uncertainty analysis based on resampling of experimentally observed data. Application of the bootstrap is justified by the so-called plug-in principle, which means to take statistical properties of experimental results (= sample) as representative for the parent population. The main advantage of the bootstrap is that it is completely automatic. It is described best by setting two Worlds, a Real World where the data is obtained and a Bootstrap World where statistical inference is performed, as shown in Fig. 1.
The non-parametric bootstrap principle is as follows:
| • | Conduct the experiment to obtain the random sample |
| • | Construct the empirical distribution, |
| • | From the selected |
| • | Approximate the distribution of |
The bootstrap principle for estimating the SD of RF (Step 2): Based on the second step of proposed approach, the bootstrap principle for estimating the SD of RFs is as follows:
| • | Experiment. Conduct the experiment and collect the random data into the sample x = {X1, X2,…,Xn} |
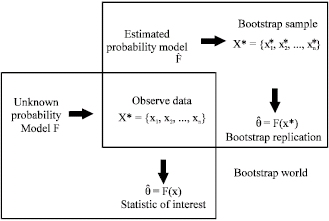 | |
| Fig. 1: | Schematic diagram of the bootstrap technique according to Efron and Tibshirani (1993) |
| • | Resampling. Draw a sample of size n, with replacement, from x |
| • | Calculation of the bootstrap estimate. Evaluate the bootstrap estimate |
| • | Repetition. Repeat steps 1 and 2 many times to obtain the total B bootstrap estimates |
| • | SD estimation of |
| | (1) |
The bootstrap principle for calculating a confidence interval for the mean of RF (step 3): In accordance with third step of proposed approach, the bootstrap principle for calculating a confidence interval for the mean of RFs is as follows:
| • | Experiment. Conduct the experiment. Suppose present sample is x = {X1, X2, …, Xn} with |
| • | Resampling. The bootstrap principle |
| • | Calculation of the bootstrap estimate. Calculate the mean of all values in x* |
| • | Repetition. Repeat steps 2 and 3 a large number of times to obtain a total of n bootstrap estimates |
| • | Approximation of the distribution of |
| • | Confidence interval. The desired (1-α) 100% bootstrap confidence interval is |
Finally, for better understanding, Fig. 2 shows the proposed approach. As it is evident, the approach for risk analysis consists of two main steps; risk observation data or original samples and non-parametric bootstrap. It is highly appropriated to mention that this approach is iterative, this means that we have to resample original samples with different B until SD for risks will be decreased, typical value for B are between 25 to 200. For instance B can be selected from B = {m1 = 25, m2 = 35, …., mi = 200} or any other similar set.
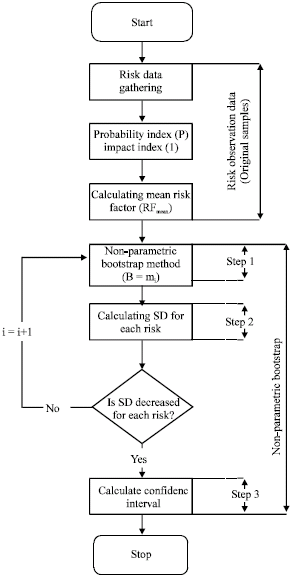 | |
| Fig. 2: | Proposed non-parametric statistical approach for risk evaluation (Iterative Process) |
APPLICATION EXAMPLE
Risk management process can be applied in various fields such as financial, insurance, project, operational, business, market, Health, safety, environment and so forth. Here, proposed approach based on non-parametric bootstrap is applied in project field. A project, as defined in the field of project management, consists of a temporary endeavor undertaken to create a unique product, service or result (Cooper et al., 2005). Project management tries to gain control over project’s variables such as risk; therefore, risk analysis is essential for all projects.
Apply the proposed approach in project risk analysis: The risk management process aims to analyze risks in order to enable them to be understood clearly and managed effectively (Han et al., 2008).
| Table 1: | Risk observed data |
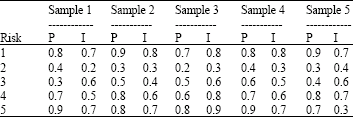 | |
There are many commonly used techniques for risk analysis (Cho et al., 2002; Majdara and Nematollahi, 2008; Duijne et al., 2008), these techniques generate list of risks that often do not directly assist the manager in knowing where to focus risk management attention. Quantitative assessment can help to prioritize identified risks by estimating their probability and impacts, exposing the most significant risks. In this section, an application example which can analyze project risks in non-parametric environment is introduced. Here, we show how the proposed approach can be used in risk analysis according to lack of risk sample data and periodic features of the projects. Hence, the comparison of the mean and the SD between the original sample distribution and the bootstrap resampled distribution can produce a better result.
In risk analysis two indexes, i.e., probability and impact, are considered. The probability of a risk is a number between 0-1 but the impact of a risk is qualitative. Though, it must be changed to quantitative number, just like probability, a number between 0-1.
The RFij for ith risk in jth observation is calculated as the follow (Wang and Elhag, 2006, 2007):
| RFij = PijxIij | (2) |
Five different risks have been assumed for which we contemplate five probabilities and five impacts each that form our sample. It means that according to (2) we have Pij which is the probability of the ith risk in jth observation and Iij which is the impact of the ith risk in jth observation. The assumed data is presented in Table 1.
A sampling distribution is based on many random samples from the population. In place of many samples, from the population, create many resamples by repeatedly sampling with replacement from this one random sample. Each resample is the same size as the original random sample. Sampling with replacement means that after we randomly draw an observation from the original sample, we put it back before drawing the next observation. Think of drawing a number from a hat, then putting it back before drawing again. As a result, any number can be drawn more than once, or not at all. If we sampled without replacement, we would get the same set of numbers we started with, though in a different order. In practice, we draw hundreds or thousands of resamples, not just five.
The sampling distribution of a statistic collects the values of the statistic from many samples. The bootstrap distribution of a statistic collects its values from many resamples. The bootstrap distribution gives information about the sampling distribution.
The true value of the population characteristic is denoted by RF. A set of n values are randomly sampled from the population. The sample estimate ![]() is based on the 5 values (P1, P2, …, P5) and (I1, I2, …, I5). Sampling 5 values with replacement from the set (P1, P2, …, P5) and (I1, I2, …, I5) provides a bootstrap sample
is based on the 5 values (P1, P2, …, P5) and (I1, I2, …, I5). Sampling 5 values with replacement from the set (P1, P2, …, P5) and (I1, I2, …, I5) provides a bootstrap sample ![]() and
and ![]() . Observe that not all values may appear in the bootstrap sample. The bootstrap sample estimate RF* is based on the 5 bootstrap values
. Observe that not all values may appear in the bootstrap sample. The bootstrap sample estimate RF* is based on the 5 bootstrap values ![]() and
and ![]() . The sampling of (P1, P2, …, P5) and (I1, I2, …, I5) with replacement is repeated many times (say B times), each time producing a bootstrap estimate RF*.
. The sampling of (P1, P2, …, P5) and (I1, I2, …, I5) with replacement is repeated many times (say B times), each time producing a bootstrap estimate RF*.
Call the means of these resamples ![]() in order to distinguish them from the mean
in order to distinguish them from the mean ![]() of the original sample. Find the mean and SD of the
of the original sample. Find the mean and SD of the ![]() ’s in the usual way. To make clear that these are the mean and SD of the means of the B resamples rather than the mean
’s in the usual way. To make clear that these are the mean and SD of the means of the B resamples rather than the mean ![]() and SD of the original sample, we use a distinct notation:
and SD of the original sample, we use a distinct notation:
| | (3) |
| | (4) |
The Bias can also be calculated for all the resamples population which is the difference between the mean of the resample mean and the original sample. This delineates that the resampled mean is not far from the original sample and it will not deviate from the original sample. The data for this resamples are available in Table 3-5, respectively for resample size 50, 100 and, 200.
Due to the fact that a sample consists of few observed samples, which is the nature of the projects, we use bootstrap resampling technique to ameliorate the accuracy of the calculation of the mean, SD and confidence interval for the RF of the risks which may occur in a project.
RESULTS AND DISCUSSION
To do the resampling replications, we used resampling Stat Add-in of Excel. We compare the original sample and the bootstrap resample of 50, 100 and 200 population of the data provided by the Excel Add-in to see what differences it makes.
| Table 2: | Statistical data of the original sample |
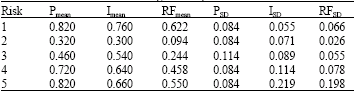 | |
| Table 3: | Statistical data of the 50 resample |
 | |
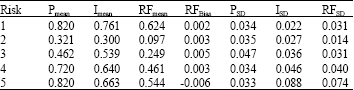
| Table 4: | Statistical data of the 100 resample |
 | |
| Table 5: | Statistical data of the 200 resample |
 | |
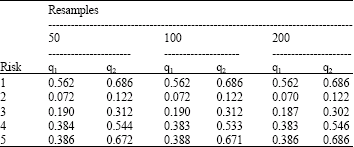
| Table 6: | Confidence intervals for the three resamples |
 | |
In Table 2, the statistical data of the original sample is presented.
After 50, 100 and 200 resampling replications, we obtain the mean for P, I and RF and then the SD for them. Moreover, we calculate RFBizs to show the mean provided by the resampling is not far from the original sample mean. The data are reported in Table 3, 4 and 5 as follows.
The confidence interval of the resamples with 50, 100 and 200 replications are calculated with α = 5%. The q1 and q2 are presented for each of the risks in Table 6.
We analyze risks using proposed approach bases on non-parametric bootstrap technique in project. The inference of results is applicably feasible, appealing and interesting in risk management.
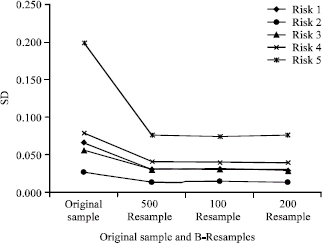 | |
| Fig. 3: | SD Comparison between Original Sample and B-Resample (B = 50, 100 and 200) for Project RFs |
We calculate SD for RFs of each risk for original sample and B-resample (B = 50, 100, 200), as shown in Fig. 3. As it is clear the SDs are reduced remarkably and it shows the efficiency of non-parametric bootstrap technique in risk analysis. The results show that the proposed approach is reasonable for estimating the SD.
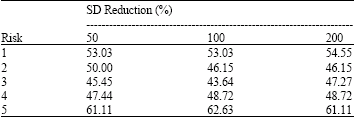
SD Reduction Rate: Comparison between the SD of the original sample and the three resampled SD with 50, 100 and 200 replications show that SD for each risk has been reduced remarkably through non-parametric bootstrap technique, for instance the SD of risk 1 of the original sample is 0.066 where the SD of the same risk with 200 resample is 0.030, can depict that the bootstrap technique is making a better result in accuracy of the RF for each risk. And then, SD reduction rate is calculated as follows:
| | (5) |
where, SDRed (%) denotes the rate of SD reduction through non-parametric bootstrap technique, SDOrg represents SD for original risk factor data sample and SDB indicates SD for B size bootstrap. Rate of SD reduction is presented in Table 7 for each risk.
For instance, the comparison between original risk factor data sample and B-resample (B = 50) as SD reduction point of view is shown in Fig. 4.
Moreover, the span of the confidence interval of the risks is calculated, although the confidence interval between the resamples with 50, 100 and, 200 replications are not different by far. For the risks with smaller SD, the confidence interval is smaller too. So the results are more precise for the resampled data.
| Table 7: | Rate of SD reduction for each risk |
 | |
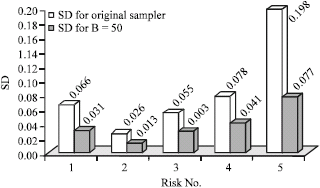 | |
| Fig. 4: | SD Comparison between Original Sample and B-Resample (B = 50) for Project RFs |
We have shown that resampling-based procedures can be easily applied to lots of different types of problems yielding meaningful results, results that often cannot be obtained using conventional approaches. Routines for implementing the procedures described in this paper were calculated in Stat Add-in of Excel.
It is firmly recommended to take advantage of this proposed approach in large projects; because of the fact that mega projects have following characteristics:
| • | They are unique |
| • | They are contemporary |
| • | They have elaborative progress |
| • | Investment and financing are main issues |
| • | They are being managed in risky environment |
| • | Projects’ data and samples are too small |
| • | Distribution of projects’ data and samples are not always definite |
Having considered all different aspects involved in projects’ characteristics, non-parametric statistical approach particularly bootstrap is very useful for risk analysis in each project, because it provides accurate calculation.
CONCLUSION AND FURTHER RESEARCH
Non-parametric statistical approach was presented to use in risk management process, proposed approach had two specific sections; first risk observation data or original risk data was evaluated, then in second step non-parametric bootstrap was applied for original risk data. On the other hand, section two had three main steps including; non-parametric bootstrap technique, SD calculation for each risk and calculation of confidence interval for each risk. We found that bootstrap has greater accuracy for estimating SD of RFs and greater accuracy in terms of level of significance than analyzing original risks data. SDs for RFs were remarkably reduced when non-parametric bootstrap was applied. In application example section, SD reduction rate was calculated and acceptable results were conducted, for instance the reduction rate for risk 5 in B = 50 resampling process was about 60%. Moreover, RFBias was calculated to show the mean provided by the resampling is not far from the original sample mean.
The bootstrap is extremely an attractive tool because it requires very little assumptions in the way of modeling, assumptions, or analysis and it can be applied in an automatic way. Further, bootstrap technique is extremely valuable in situations where data sizes are too small, which is often the real case in risk analysis applications.
In the future work, we may work on the topic that considers the non-parametric regression model for project RFs and we may compare different non-parametric resampling techniques for choosing the best way for analyzing RFs.
ACKNOWLEDGMENT
The authors thank Mr. M. Heydar for his helpful comments and suggestions, which helped to improve the work.
REFERENCES
- Ait-Sahalia, Y. and J. Duarte, 2003. Nonparametric option pricing under shape restrictions. J. Econ., 116: 9-47.
CrossRef - Cho, H.N., H.H. Choi and Y.B. Kim, 2002. A risk assessment methodology for incorporating uncertainties using fuzzy concepts. Reliab. Eng. Syst. Safety, 78: 173-183.
CrossRef - Chun, M. and K. Ahn, 1992. Assessment of the potential application of fuzzy set theory to accident progression event trees with phenomenological uncertainties. Reliab. Eng. Syst. Safety, 37: 237-252.
CrossRef - Dikmen, I., M.T. Birgonul, C. Anac, J.H.M. Tah and G. Aouad, 2008. Learning from risks: A tool for post-project risk assessment. Autom. Construct., 18: 42-50.
CrossRef - Duijne, F.H.V., D.V. Aken and E.G. Schouten, 2008. Considerations in developing complete and quantified methods for risk assessment. Safety Sci., 46: 245-254.
CrossRef - Efron, B., 1979. Bootstrap methods: Another look at the jackknife. Ann. Stat., 7: 1-26.
CrossRefDirect Link - Groen, F.J., C. Smidts and A. Mosleh, 2006. QRAS-the quantitative risk assessment system. Reliab. Eng. Syst. Safety, 91: 292-304.
CrossRef - Han, S.H., D.Y. Kim, H. Kim and W.S. Jang, 2008. A web-based integrated system for international project risk management. Autom. Construct., 17: 342-356.
CrossRef - Hu, A.H., C.W. Hsu, T.C. Kuo and W.C. Wu, 2008. Risk evaluation of green components to hazardous substance using FMEA and FAHP. Exp. Syst. Applied.
CrossRefDirect Link - Li, Y. and X. Liao, 2007. Decision support for risk analysis on dynamic alliance. Decis. Support Syst., 42: 2043-2059.
CrossRef - Majdara, A. and M.R. Nematollahi, 2008. Development and application of a risk assessment tool. Reliab. Eng. Syst. Safety, 93: 1130-1137.
CrossRef - Stark, E. and M. Abeles, 2005. Applying resampling methods to neurophysiological data. J. Neurosci. Meth., 145: 133-144.
CrossRef - Tak, K.M., 2004. Estimating variances for all sample sizes by the bootstrap. Comput. State Data Anal., 46: 459-467.
CrossRef - Walters, S.J. and M.J. Campbell, 2005. The use of bootstrap methods for estimating sample size and analyzing health-related quality of life outcomes. State Med., 24: 1075-1102.
CrossRef - Wang, Y.M. and T.M.S. Elhag, 2006. Fuzzy tOPSIS method based on alpha level sets with an application to bridge risk assessment. Exp. Syst. Applied, 31: 309-319.
CrossRef - Wang, Y.M. and T.M.S. Elhag, 2007. A fuzzy group decision making approach for bridge risk assessment. Comput. Ind. Eng., 53: 137-148.
CrossRef - William, A.C. and A.P. Joseph, 2005. Analysis of histamine release assays using the Bootstrap. J. Immunol. Meth., 296: 103-114.
CrossRef