
Xiaoming Wang
School of Information Engineering, Southern Yangtze University, Wuxi, China
Shitong Wang
School of Information Engineering, Southern Yangtze University, Wuxi, China
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 6 | Page No.: 1014-1024







ABSTRACT
This study deals with how to efficiently rank features of datasets. As we may know well, reducing the dimensionality of datasets (i.e., feature reduction) is an important step in pattern recognition tasks and exploratory data analysis. Quite often, feature ranking is required before completing feature reduction. In this study, a novel classifier-free feature ranking approach based on the combination of both weighting features and ISE (Integrated Squared Error) criterion is proposed. ISE is measured in terms of the modified non-parametric Parzen window density estimator in this study. The advantage of the proposed approach is that it allows us to make an efficient and effective non-parametric implementation and requires no prior assumption. The experimental results demonstrate that the proposed approach here is very promising.
PDF Abstract XML References Citation
How to cite this article
Xiaoming Wang and Shitong Wang, 2009. Feature Ranking by Weighting and ISE Criterion of Nonparametric Density Estimation. Journal of Applied Sciences, 9: 1014-1024.
DOI: 10.3923/jas.2009.1014.1024
URL: https://scialert.net/abstract/?doi=jas.2009.1014.1024
DOI: 10.3923/jas.2009.1014.1024
URL: https://scialert.net/abstract/?doi=jas.2009.1014.1024
INTRODUCTION
Dimensionality reduction is essential to improve the accuracy, efficiency and scalability of a classification process in pattern recognition tasks and exploratory data analysis. In order to realize an effective dimensionality reduction, feature ranking is quite often required. There are two categories of feature ranking strategies: The wrapper strategy and the filter strategy (Wang et al., 1999; Guyon and Elisseeff, 2003; Song et al., 2005). In the wrapper strategy, feature ranking associated with a particular classifier can be done by evaluating the classification accuracy. The huge computation burden is the major drawback of this strategy. The filter strategy is to rank features by evaluating some criterion. Such a criterion may be the classifier-parameter-based criterion (Basak et al., 1998; Wang et al., 1999; Andonie and Cataron, 2005) and the classifier-free criterion (Dash et al., 1997; Morita et al., 2003; Torkkola, 2003; Dy and Bradley, 2004; Biesiada et al., 2005). The latter is our concern in this study.
In general, most of the classifier-free criteria (Morita et al., 2003; Torkkola, 2003; Dy and Bradley, 2004; Biesiada et al., 2005) are based on the first-order or second-order statistics computed from the empirical distributions. However, these criteria based on the first-order statistics are sensitive to noise in datasets, whereas, these criteria based on the second-order statistics are sensitive to data transformation. In order to circumvent these drawbacks and enhance the robustness to noise and data transformation, MI (mutual information) as the high order statistics has been introduced into the classifier-free criteria. However, this poses great difficulties as it requires prior knowledge of the underlying probability density functions of datasets and the numerical integration of these functions, which leads to a high computational complexity. Moreover, MI-based criteria often fail in higher dimensions (Kononenko, 1994; Torkkola, 2003; Andonie and Cataron, 2005). In the latest advance of MI-based criteria, Torkkola (2003) proposed the non-parametric MI criterion based on Parzen-window density estimation (Bishop, 1995) and applied it to feature transformation. Similar studies are also described by Principe et al. (2000), Guyon and Elisseeff (2003) and Huang and Chow (2003).
As pointed out, this study deals with feature ranking (as the first step of feature extraction). In this study, a novel feature ranking approach is proposed. The core of the proposed approach here can be stated in brief as follows. First, a weight with one as its initial value is assigned to every feature. The weight of each feature reflects its importance in the data space. Thus, with the help of the concept of feature transform (Torkkola, 2003), two data spaces are generated. One is associated with all the original features and the other is associated with all the weighted features. Second, we use the Parzen window density estimator to derive two underlying probability density functions of the datasets, respectively, in these two data spaces. In order to keep more information in the datasets, we adopt the more precise Parzen window density estimator generated by using the fuzzy C-means algorithm (FCM) (Dunn, 1973; Bezdek, 1981) and then computing the variances of the corresponding different clusters (i.e., classes). Algorithm FCM realizes clustering by minimizing its objective function which induces the corresponding fuzzy membership functions. It was first developed by Dunn (1973) and then improved by Bezdek (1981). It has been frequently used in pattern recognition, data mining and so on. Third, we use ISE (Integrated Squared Error) criterion to measure the global error between the density estimates of these two data spaces. ISE is a robust criterion for the presence of noise and outliers in datasets (Girolami and Chao, 2003; Wang et al., 2008). Finally, by using the gradient descent method for ISE, we derive the iterative learning rules for the used weights and final weights will also be accordingly obtained.
The proposed approach seems to be very much related with Torkkola (2003) study. However, the distinctive characteristics of the proposed approach here should be emphasized: First, the proposed approach is the classifier-free one, i.e., no prior knowledge about the class labels in datasets is assumed, whereas, Torkkola’s approach is oriented to such datasets where the class labels of all the data in datasets are known. This indicates the big discrepancy between the proposed approach and his study. The used MI criterion in his study is only related to the low-dimensional weighted data space, whereas, the used ISE in the proposed approach deals with the global error measure between the original data space and the weighted data space with the same dimension. Moreover, from the pure viewpoint of the computational complexity, ISE may have less computational burden than MI criterion, we will explain the reason later. Second, the proposed approach adapts FCM to partition the dataset to be analysed and then calculate the variance of every cluster obtained. Thus, the underlying probability density function computed by the modified Parzen window density estimator will make use of more information in datasets.
THE PARZEN WINDOW DENSITY ESTIMATOR AND ISE CRITERION
The modified parzen window density estimator in the proposed approach: The traditional Parzen window density estimator is in particular attractive when no a prior information is available to guide the choice of the precise form of the density of a dataset to be analysed. A probability density estimate ![]() can be obtained from the finite d-dimensional data points (x1,x2,…,xN ε Xd) by employing the following Parzen window density estimator:
can be obtained from the finite d-dimensional data points (x1,x2,…,xN ε Xd) by employing the following Parzen window density estimator:
(1) |
where, xi ε Xd, N is the number of all the data points in the dataset, φ(·) is a kernel window function and hN is the window’s width and VN is the window’s volume.
In this study,
in Eq. 1 is taken as the following Gaussian kernel function:
(2) |
where, Σ’ is the covariance matrix, h is the window’s width. Let Σ = h2Σ’, since
so, we have:
(3) |
Thus, we have
(4) |
In most cases, in order to ease the computational complexity, one adopts the unified variance, i.e., Σ = σ2I where, I is the identity matrix, σ2 is the variance of the dataset. However, when the dataset contains several classes where the compactness of every class is different, which actually implies that the variance of every class is different from others, this assumption may pose a serious issue, i.e., the obtained density estimate loses much useful information contained in the dataset.
In particular, due to high dimensionality, all the data points in a dataset are more sparsely distributed in a high dimensional data space such that the compactness of all the projected data points along every dimension may perhaps be different from others. Therefore, we should compute Σ in Eq. 4 based on the variance of every dimension.
Next, let us state the modified Parzen window density estimator used in the proposed approach.
Given the dataset DX = {xl,…,xN}, xi = (xil, xi2,…,xid)T ε Xd, i = 1,2,…, N, suppose there are Nc classes in Dx and there are Jc data points in the cth class, then we can estimate the probability P(c) of the cth class as:
(5) |
We employ Eq. 4 to estimate the conditional probability function of the cth class as:
(6) |
where, xci is the value of the ith data point in the cth class; Σc denotes the diagonal covariance matrix of the cth class and it is defined as:
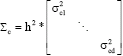 | (7) |
where, h is the window’s width, * denotes the multiplication operator, ![]() is the variance of all the data points in the cth class along the kth dimension, which is approximately calculated using:
is the variance of all the data points in the cth class along the kth dimension, which is approximately calculated using:
(8) |
(9) |
Thus, the density function p(x) for the data DX can be estimated as:
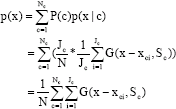 | (10) |
ISE criterion in the proposed approach: In order to evaluate the importance of every dimension (feature), we utilize the following weighting strategy, i.e., imposing a linear dimension-keeping transformation y = w ![]() x = (w1x1,w2x2,…,wdxd)T to x, where, w = (w1,w2,…,wd)T,
x = (w1x1,w2x2,…,wdxd)T to x, where, w = (w1,w2,…,wd)T,
wi > 0, i = 1,2,…,d. The bigger wi is, the more important the corresponding ith feature will be. With this linear transformation, the original dataset DX becomes a transformed dataset DY.
For this transformed dataset DY, we can estimate its probability density function q(x) using Eq. 10 as:
(11) |
where, ![]() takes a diagonal covariance matrix for ease of the computational complexity, which is defined as:
takes a diagonal covariance matrix for ease of the computational complexity, which is defined as:
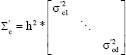 | (12) |
where, h is the window’s width, ![]() is the variance of all the data points in the cth class along the kth transformed dimension, which can be estimated as:
is the variance of all the data points in the cth class along the kth transformed dimension, which can be estimated as:
(13) |
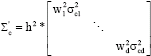 | (14) |
From the intuitive viewpoint, a good w should make q(x) for the transformed dataset Dy to approximate p(x) for the original dataset DX as well as possible. Therefore, we require a criterion to evaluate w. ISE criterion (Girolami and Chao, 2003; Wang, 2008) has been investigated as an error criterion which will be less influenced by the presence of noise and outliers in the dataset. ISE criterion is a measure of the global accuracy of a density estimate, which converges to the mean squared error asymptotically. For the above two density estimates, w which provides the minimum of ISE is as follows:
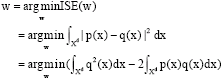 | (15) |
where, the term ![]() has been dropped from the above since it is not dependent on the weight vector w. We should keep in mind that when we attempt to use ISE criterion for unsupervised feature ranking, MI criterion used in the Torkkola’s work about supervised feature extraction (Torkkola, 2003) actually provides us alternative possible choice. However, in terms of the framework of the Torkkola’s (2003) study, except for
has been dropped from the above since it is not dependent on the weight vector w. We should keep in mind that when we attempt to use ISE criterion for unsupervised feature ranking, MI criterion used in the Torkkola’s work about supervised feature extraction (Torkkola, 2003) actually provides us alternative possible choice. However, in terms of the framework of the Torkkola’s (2003) study, except for ![]() the term
the term ![]() still needs to be computed in MI criterion. Therefore, using ISE criterion here may result in further reducing the computational burden, compared with Torkkola (2003). In other words, the computational merit motivates us to use ISE criterion instead of MI criterion in this study.
still needs to be computed in MI criterion. Therefore, using ISE criterion here may result in further reducing the computational burden, compared with Torkkola (2003). In other words, the computational merit motivates us to use ISE criterion instead of MI criterion in this study.
Let us derive ![]() now (Dash et al., 1997; Torkkola, 2003):
now (Dash et al., 1997; Torkkola, 2003):
(16) |
we have
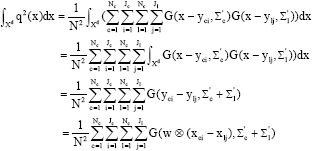 | (17) |
Similarly, we have:
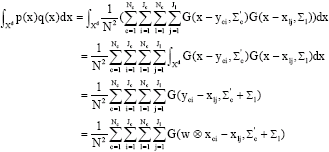 | (18) |
THE DETAILS OF THE PROPOSED APPROACH
Since, the weight vector w reflects the importance of every feature in the dataset, thus, the corresponding feature ranking can be achieved using the obtained w. Presentgoal is to find out w such that:
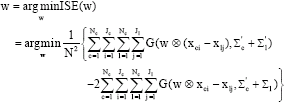 | (19) |
Where:
The gradient descent method is adopted in the proposed approach. First, we need the derivatives of ISE(w), which are computed as follows.
Since,
(20) |
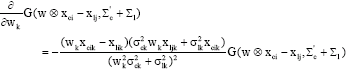 | (21) |
in terms of Eq. 19-21, we immediately have:
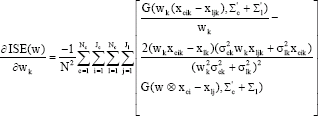 | (22) |
Thus, we further have the following learning rule for w:
(23) |
where, α is the learning rate which is taken as 0.1 in our study.
Before giving the complete description of the proposed approach, we must discuss a particular implementation detail. As is seen before, when weighting all the features, we employ the constraint:
Such a constraint will pose a subtle issue, i.e., solving
with this constraint will yield all the same wi(i = 1,2,…,d), i.e., w1 = w2 = … =wd = 1/d. There are two strategies which can be used to circumvent this trouble. Suppose we have prior knowledge about the least important feature (e.g., the ith feature), the first strategy is to force wi = 0 during the whole running period of the proposed approach. If we do not have such prior knowledge, the second strategy will start to work. We first take an arbitrary feature (e.g., the ith feature) and let wi = 0 during the whole running period and then run the proposed approach. Accordingly, we choose the least important feature (e.g., the jth feature) and let wj = 0 during the whole running period, then run the proposed approach again. In this way, we can easily obtain the final feature ranking for the dataset to be analysed. Please note, since we are interested in important features instead of the least important ones in feature ranking, such an arrangement based on the second strategy has almost no impact on the final feature ranking.
For the sake of the space of the paper, assume the first strategy is taken, let us state the proposed approach as follows:
| Step 1: | Given the dataset D, initialize w = (w1,w2,…,wd)T and let wi corresponding to the least important feature be zero; t = 0 |
| Step 2: | If all the data points in D have been classified with their class labels, skip this step. Otherwise, determine the number of classes and use the fuzzy clustering algorithm FCM (Dunn, 1973; Bezdek, 1981) to partition D such that the modified Parzen window density estimator in (10) can be employed |
| Step 3: | Compute ISE using Eq. 19 |
| Step 4: | Compute wk (t+1) using Eq. 23 |
| Step 5: | t ← t+1 |
| Step 6: | If ISE reaches its minimum or t achieves the predefined maximum, then go to step 7, otherwise go to step 3 |
| Step 7: | Output the ranking result of features, according to the obtained w |
EXPERIMENTAL RESULTS
We present the experimental results for eleven benchmarking datasets to validate the effectiveness of the proposed approach. It should be emphasized that we do not claim that the experimental results of present approach here are superior to current feature-ranking approaches. They show its power as a classifier-free approach by (1) comparing it with another classifier-free approach based on the traditional Parzen window density estimator and (2) experimentally proving it to be comparable to other supervised ranking approach.
Three groups of experiments were carried out with MATLAB 6.0 on the computer of Pentium IV with 2.66 GHz CPU and 512 MB memory. The first group of experiments deals with eleven datasets where algorithm FCM was first used to partition these datasets and then the proposed approach was executed to obtain the corresponding ranking results of features contained in these datasets. We verified the obtained ranking results using the k-fold cross-validation test (Richard, 2000) and the LIBSVM tool (Chang and Lin, 2001) and did a comparative study with other approaches. In k-fold cross-validation test, a dataset is divided into k subsets. Each time, one of the k subsets is used as the test set and all other k-1 subsets are put together to form a training set. Then the average accuracy or error across all trials is computed. In the second group of experiments, three datasets are involved, where the datasets Pipeline and Landsat contain their test data and the dataset WBC (Wisconsin Diagnostic Breast Cancer) does not have the test data. For the former, the classification accuracy, as the performance index, is used to evaluate the proposed approach. For the latter, the cross-validation test is adopted. In the third group of experiments, we presented a comparative result for the dataset Vowel with the latest advance (Andonie and Cataron, 2005).
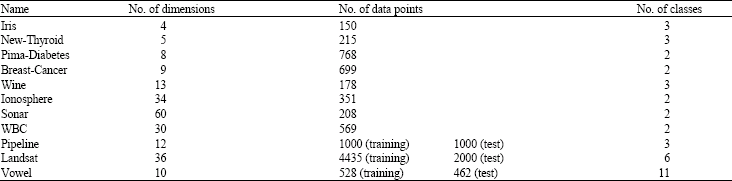
Group A: This group of experiments deals with eleven UCI (Blake and Merz, 1998) datasets, as shown in Table 1. For the datasets Iris, New-Thyroid, Pima-Diabetes, Breast-Cancer, Wine, Ionosphere and Sonar, Table 2 shows the obtained feature ranks using the proposed approach and SUD approach (Dash et al., 1997), RELIEF approach (Kira and Rendell, 1992; Kononenko, 1994; Dash et al., 1997). Table 3 demonstrates the obtained feature ranks for the dataset Pima-Diabetes using the above three approaches and K-means-based approach (Girolami and Chao, 2003). The obtained feature ranks for the dataset wine is reported in Table 4 using both the above four approaches and FSM approach (Law et al., 2002). Table 5 demonstrates the feature ranks for the dataset Sonar using the proposed approach and RELIEF approach. Please note, in these tables, the relevant results of SUD and RELIEF are drawn (Dash et al., 1997), those of K-means-based approach are (Girolami and Chao, 2003) and those of FSM are from Law et al. (2002).
Here, let us briefly introduce the basic ideas of these approaches. SUD is based on the observation that removing an irrelevant feature from the feature set may not change the underlying concept of the data, but not so otherwise.
| Table 1: | Eleven UCI datasets |
 | |
| Table 2: | Feature ranks using three approaches |
 | |
| Table 3: | Feature ranks using four approaches for Pima-Diabetes |
| Table 4: | Feature ranks using five approaches for Wine |
| Table 5: | Feature ranks using the proposed approach and RELIEF-F for Sonar |
 | |
Each time a relatively unimportant feature is removed from the feature set by using the entropy index (Dash et al., 1997). The adopted RELIEF-F is a modification of the original RELIEF (Kononenko, 1994; Dash et al., 1997), a key idea of which is to estimate the quality of features according to how well their values distinguish between data points that are near to each other. The original RELIEF can deal with nominal and numerical features. However, it cannot deal with incomplete data and is limited to two-class problems. Its extended version RELIEF-F solves these problems. The feature ranking approach based on K-means clustering involves classification capabilities of feature vectors and correlation analysis between two features. It can rank the features by using the correlation index between two features (Girolami and Chao, 2003). FSM approach is based on a feature saliency measure which is obtained by an EM algorithm. However, it assumes that the features are conditionally independent, given the components. It ranks the features in descending order of saliency (Law et al., 2002).
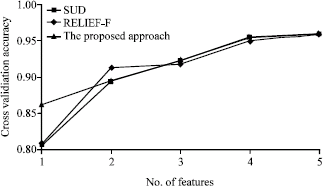 | |
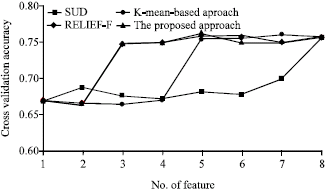
| Fig. 1: | Cross-validation for the dataset New-Thyroid |
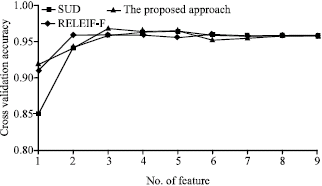
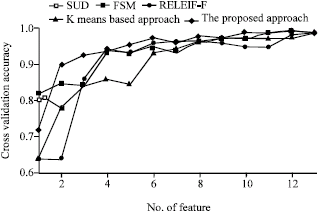
As we may know well, the most important features in Iris dataset are of the third and fourth. Just like SUD, RELIEF-F, the proposed approach yielded the same ranking result. Figure 1-6 demonstrate the 5-fold cross-validation accuracies for other datasets New-Thyroid, Pima-Diabetes, Breast-Cancer, Wine, Ionosphere and Sonar, which clearly indicate that in most cases, the proposed approach is comparativelycompetitive to other approaches.
 | |
| Fig. 2: | Cross-validation for the dataset Pima-Diabetes |
 | |
| Fig. 3: | Cross-validation for the dataset Breast-Cancer |
 | |
| Fig. 4: | Cross-validation for the dataset Wine |
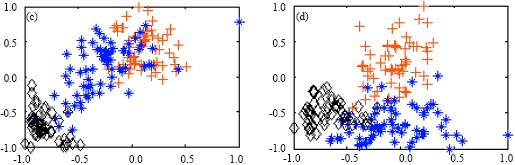
Figure 7a-d shows the visualization results for two most important features of the dataset Wine using these approaches. It is clear that the proposed approach had better visualization capability than other approaches, (Fig. 7d).
Of course, since the combinational computation of Gaussian functions is involved in the proposed approach, its computational time is still comparatively high. For example, it requires 4.438 sec for Iris dataset and 4.406 sec for New-Thyroid dataset, however, 39.453 for Pima-Diabetes dataset, 38.922 sec for Breast-Cancer dataset and 34.141 sec for Ionosphere dataset.
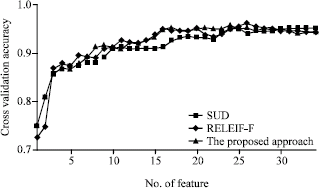 | |
| Fig. 5: | Cross-validation for the dataset Ionosphere |
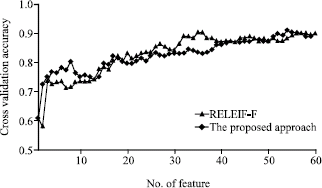 | |
| Fig. 6: | Cross-validation for the dataset Sonar |
This actually poses a noting-worthy issue, i.e., we should manage to further reduce its computational burden in near future.
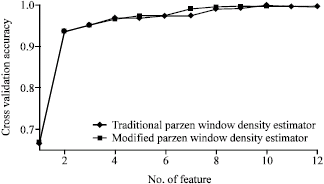
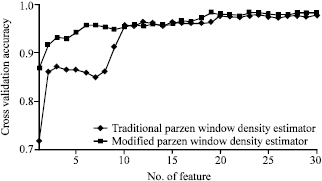
Group B: This group of experiments deals with three datasets: Pipeline, Landsat and WBC, as shown in Table 1. All the data in these three datasets have been classified using the class labels. Table 6 demonstrates the feature ranks for these three datasets using the proposed approach. For the datasets Pipeline and Landsat, we employed LIBSVM (Chang and Lin, 2001) to their training data according to the obtained feature ranks and then obtained the classification accuracies for their test data, (Fig. 8-9). Figure 10 demonstrates the 5-fold cross-validation accuracies for the dataset WBC. In Fig. 10 and Table 6, a comparison for this dataset between the modified Parzen window density estimator and the traditional one is also included. In particular, two very different feature ranking are generated by traditional Parzen window density estimator and the modified Parzen window density estimator, Table 6. This just show the inappropriateness of the traditional Parzen window density estimator. We can see the effectiveness of the proposed approach from these Fig. 10 and Table 6. That is to say, with the proposed approach, only a small number of the ranked features are taken, the corresponding comparatively high classification/cross-validation accuracies for these three datasets were obtained.
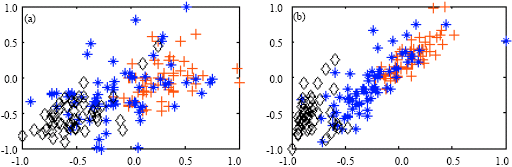 | |
| Fig. 7: | Visualization results using the five approaches for the two most important features of the dataset Wine, (a) RELIEF-F approach, (b) SUD approach and K-means-based approach, (c) FSM approach and (d) The proposed approach |
 | |
| Fig. 8: | Classification for the dataset Pipeline using LIBSVM |
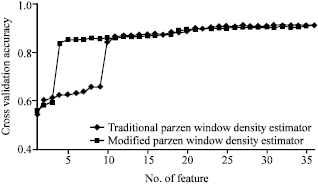 | |
| Fig. 9: | Classification for the dataset Landsat using LIBSVM |
 | |
| Fig. 10: | Cross-validation for the dataset WBC using LIBSVM |
For example, we presented 2-5 ranked features from the dataset Pipeline obtained by the proposed approach, to LIBSVM, the obtained classification accuracies for the test data are 93.4, 94.9, 96.3 and 97.1.
Group C: Only the data set Vowel is involved here to exhibit the comparative study between the proposed approach and other feature ranking approaches RLVQ, GRLVQ, SRNG, ERLVQ and ESRNG in the latest literature (Andonie and Cataron, 2005). As we may know well, Standard Learning Vector Quantization (LVQ) does not discriminate between more or less informative features: their influence on the distance function is equal. On the contrary, Relevance LVQ (RLVQ) in (Bojer et al., 2001; Andonie and Cataron, 2005) holds a changeable relevance value for every feature and employs a weighted distance function for classification. An iterative heuristic training process is used to tune the weight values for a specific problem: the influence of features which frequently contribute to misclassifications of the system is reduced while the influence of very reliable features is increased. Generalized RLVQ (GRLVQ) is the modification of RLVQ. This approach modifies RLVQ by using an adaptive metric and leads to a more powerful classifier with little extra cost compared with RLVQ. The Supervised Relevance Neural Gas (SRNG) approach combines the neural-gas (NG) algorithm (Hammer et al., 2005) and GRLVQ. The idea was to incorporate neighborhood cooperation of NG into GRLVQ to speedup the convergence and make initialization less crucial. Energy SRNG (ESRNG) approach uses the maximization of the informational energy (IE) as a criterion for computing the relevancies of input features. This adaptive relevance determination is used in combination with the SNG model. Energy Generalized Relevance LVQ (EGRLVQ) approach uses the estimation of the Informational Energy (IE) as a maximization criterion for computing the feature relevance. Both ESRNG and EGRLVQ measure the informational energy using Onicescu’s informational energy (Cataron and Andonie, 2004).
| Table 6: | Feature ranks using the proposed approach for Pipeline, Landsat, WBC |
 | |
| Table 7: | Feature ranks using seven approaches for Vowel |
| Table 8: | Classification accuracies using LIBSVM for test data of Vowel (%) |
 | |
Table 7 demonstrates the experimental results using both the above approaches and the proposed approach here. We directly draw the results of all other methods except the proposed approach from (Andonie and Cataron, 2005) into this Table 7. Based on the obtained feature ranks, LIBSVM is first applied to the training data of this dataset and then to its test data. As seen in the Table 8, when 2-5 ranked features are taken, the obtained classification performance using the proposed approach is comparable to ESRNG and a little less than ERLVQ. For other cases except one or six feature cases, the proposed approach is generally comparable to other approaches. However, please let us keep in mind the fact that the proposed approach attains these comparable results in the case where it is classifier-free while other approaches here are supervised. What is more, since all approaches yield very low classification accuracies (much less than 50%) for one feature case, it is unnecessary for us to analyze this case. For the six feature case in Table 8, although the proposed approach obtains the lowest classification accuracy, it is still a little bigger than 50% (i.e., 51.3%). In summary, the proposed approach is effective in most cases for the dataset Vowel.
CONCLUSIONS
This study describes a novel feature ranking approach which may be attractive for pattern recognition tasks on high-dimensional datasets. The proposed approach provides three major contributions. First, the proposed Parzen window density estimator takes non-uniform distribution contained in the datasets into account, so the proposed estimator can make use of more information of the datasets than the conventional Parzen window density estimator. Second, instead of the commonly used MI based criterion, the novel ISE criterion, as an alternative way, is adopted in our study. Present experimental results demonstrate that the proposed approach based on ISE criterion has as least the same or comparable performance as current feature ranking approaches. Third, the proposed approach requires no prior knowledge of the datasets to be analyzed and it can be easily realized by using the corresponding gradient descent method.
Although the proposed approach is based on ISE criterion rather than MI criterion, it still has comparatively high computational burden due to the existence of the combinational computation of Gaussian functions. We will study how to further reduce its computational time, possibly using the random sampling method, in near future. Further research may include theoretical research on the proposed approach and explore more practical applications.
ACKNOWLEDGMENTS
This research is supported by 2007 National 863 project (Grant No. 2007AA1Z158), 2007 two grants (No. 60773206, 60704047) from National Science Foundation of China, New_century Outstanding Young Scholar Grant of Ministry of Education of China (NCET-04-0496), National KeySoft Lab. at Nanjing University, The Key Lab. of Computer Information Technologies at JiangSu Province, the 2004 key project of Ministry of Education of China and National Key Lab. of Pattern Recognition at Institute of Automation, CAS, China.
REFERENCES
- Andonie, R. and A. Cataron, 2005. Feature ranking using supervised neural gas and informational energy. Proceedings of the International Joint Conference on Neural Networks, July 31-August 4, 2005, Montreal, Canada, pp: 1269-1273.
CrossRefDirect Link - Basak, J., R.K. De and S.K. Pal, 1998. Unsupervised feature selection usinga neuro fuzzy approach. Pattern Recognition Lett., 19: 997-1006.
CrossRefDirect Link - Biesiada, J., W. Duch, A. Kachel, K. Maczka and S. Palucha, 2005. Feature ranking methods based on information entropy with parzen windows. Proceedings of the 9th International Conference on Res. in Electrotechnology and Applied Informatics (REI), August 31-September 3, 2005, Katowice-Krakow, Poland, pp: 109-119.
Direct Link - Bishop, C.M., 1995. Neural Networks for Pattern Recognition. 1st Edn., Oxford University Press, USA., ISBN-13: 978-0198538646,.
Direct Link - Blake, C.L. and C.J. Merz, 1998. UCI Repository of Machine Learning Databases. 1st Edn., University of California, Irvine, CA.
Direct Link - Bojer, T., B. Hammer, D. Schunk and K.T.V. Toschanowitz, 2001. Relevance determination in learning vector quantization. Proceedings of the European Symposium on Artificial Neural Networks (ESANN), April 25-27, 2001, D-Side Publications, pp: 271-276.
Direct Link - Cataron, A. and R. Andonie, 2004. Energy generalized LVQ with relevance factors. Proceedings of the IEEE International Joint Conference on Neural Networks IJCNN, Volume 2, July 25-29, 2004, IEEE Computer Society, pp: 1421-1426.
CrossRefDirect Link - Dash, M., H. Liu and J. Yao, 1997. Dimensionality reduction of unsupervised data. Proceedings of the 9th International Conference Tools with Artificial Intelligence, November 3-8, 1997, Newport Beach, CA., pp: 532-539.
CrossRefDirect Link - Dy, J.G. and C.E. Bradley, 2004. Feature selection for unsupervised learning. J. Mach. Learn. Res., 5: 845-889.
Direct Link - Girolami, M. and H. Chao, 2003. Probability density estimation from optimally condensed data samples. Probability density estimation from optimally condensed data samples. IEEE Trans. Pattern Anal. Mach. Intell., 25: 1253-1264.
CrossRefDirect Link - Guyon, I. and A. Elisseeff, 2003. An introduction to variable and feature selection. J. Mach. Learn. Res., 3: 1157-1182.
Direct Link - Hammer, B., C. Information, M. Strickert and T. Villmann, 2005. Supervised neural gas with general similarity measure. Neural Process. Lett., 21: 21-44.
CrossRefDirect Link - Huang, D. and T. Chow, 2003. Searching optimal feature subset using mutual information. Proceedings of the European Symposium on Artificial Neural Networks (ESANN), August 23-25, 2003, D-Side Publications, pp: 161-166.
Direct Link - Kononenko, I., 1994. Estimating attributes: Analysis and extension of RELIEF. Proceedings of the European Conference on Machine Learning, August 19-23, 1994, Springer Berlin, pp: 171-182.
CrossRefDirect Link - Morita, M., R. Sabourin, F. Bortolozzi and C.Y. Suen, 2003. Unsupervised feature selection using multi objective genetic algorithms for handwritten word recognition. Proceedings of the 7th International Conference on Document Analysis and Recognition, (ICDAR), August 3-6, 2003, IEEE Computer Society, pp: 666-671.
CrossRef - Torkkola, K., 2003. Feature extraction by non-parametric mutual information maximization. J. Mach. Learning Res., 3: 1415-1438.
Direct Link - Wang, H., D. Bell and F. Murtagh, 1999. Axiomatic approach to feature subset selection based on relevance. IEEE Trans. Pattern Anal. Mach. Intell., 21: 271-277.
CrossRefDirect Link - Wang, S.T., F.L. Chung and F.S. Xiong, 2008. A novel image thresholding method based on Parzen window estimate. Pattern Recognit., 41: 117-129.
CrossRefDirect Link - Dunn, J.C., 1973. A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters. J. Cybernet., 3: 32-57.
CrossRefDirect Link