
M. Zandieh
Department of Industrial Management, Faculty of Management and Accounting, Shahid Beheshti University, G.C., Tehran, Iran
A. Azadeh
Department of Industrial Engineering, Faculty of Engineering, University of Tehran, Tehran, Iran
B. Hadadi
Department of Industrial Engineering, Faculty of Mechanical and Industrial Engineering, Qazvin Azad University of Ghazvin, Iran
M. Saberi
Department of Industrial Engineering, University of Tafresh, Tafresh, Iran
Journal of Applied Sciences
Year: 2009 | Volume: 9 | Issue: 6 | Page No.: 1001-1013







ABSTRACT
This study presents an integrated Artificial Neural Networks (ANN) to estimate and predict airline number of passenger in Iran. All type of ANN-Multi Layer Perceptron (MLP) is examined to this estimation. The ANN models are implemented on MATLAB software. Auto-Correlation Function (ACF) is utilized to define input variables. Finally, the best type of ANN-MLP is determined with Data Envelopment Analysis (DEA). Kruskal-Wallis test is used for asses the impact of raw data, preprocessed data and post process method on ANN performance. Monthly airline number of passenger of Iran airline from 1993 to 2005 is considered as the case of this study.
PDF Abstract XML References Citation
How to cite this article
M. Zandieh, A. Azadeh, B. Hadadi and M. Saberi, 2009. Application of Artificial Neural Networks for Airline Number of Passenger Estimation in Time Series State. Journal of Applied Sciences, 9: 1001-1013.
DOI: 10.3923/jas.2009.1001.1013
URL: https://scialert.net/abstract/?doi=jas.2009.1001.1013
DOI: 10.3923/jas.2009.1001.1013
URL: https://scialert.net/abstract/?doi=jas.2009.1001.1013
INTRODUCTION
There have been many studies on ANN models in different cases. An ANN is configured for a specific application, such as pattern recognition, function approximation, data classification and so on in different areas of science. Time series modeling is one of the main applications. Many researchers showed ANN’s comparability and superiority to conventional methods for estimating functions (Hill et al., 1996; Kohzadi et al., 1996; Stern, 1996; Chiang et al., 1996; Indro et al., 1999; Hwarng, 2001; Azadeh et al., 2007a, b).
The main aim of this research is to combine conventional time series concepts with ANN. We show these concepts are more useful in improving ANN performance. These concepts are preprocessing (for madding process, covariance stationary), post processing (to access main data) and principle component analysis (for input selection). Exploring the literature reveals that combination of traditional concepts with ANN to model time series has been rarely done. Although data preprocessing concept is considered in some literature, but the covariance stationary concept in data preprocessing is ignored (Nayak et al., 2004; Karunasinghe and Liong, 2006; Tseng et al., 2002; Niska et al., 2004; Aznarte et al., 2007; Gareta et al., 2006; Jain and Kumar, 2007).
ARTIFICIAL NEURAL NETWORKS
Artificial neural networks are a promising alternative to econometric models. An ANN is an information processing paradigm that is inspired by the biological nervous systems, such as the brain, process information. ANNs, like people, learn by example. An ANN is configured for a specific application, such as pattern recognition, function approximation or data classification, through a learning process. Learning in biological systems involves adjustments to the synaptic connections that exist between the neurons. This is true for ANNs as well. They are made up simple processing units which are linked by weighted connections to form structures that are able to learn relationships between sets of variables. This heuristic method can be useful for nonlinear processes that have unknown functional forms (Enders, 2004). There have been many studies of ANN models in time series forecasting (Hill et al., 1996; Kohzadi et al., 1996; Hawrng, 2001; Tseng et al., 2002; Niska et al., 2004; Jain and Kumar, 2007; Palmer et al., 2006; Zhang, 2001), but traditional concepts such as covariance stationary and input selection are ignored. In this study, we show that using these concepts improves the performance of ANN model. Then, the best ANN architecture is selected for airline number of passenger consumption estimation.
Among the different networks, the feed forward neural networks or Multi Layer Perceptron (MLP) are the most commonly used in engineering. MLP networks are normally arranged in three layers of neurons, the input layer and output layer represent the input and output variables of the model and between them lay one or more hidden layers which hold the networks ability to learn non-linear relationships.
Architecture selection is one major issue with implications on the empirical results and consists of:
| • | Input and output variables number |
| • | Hidden layers’ number |
| • | Hidden and output activation functions |
| • | Learning algorithm |
All of the above issues are open questions today and there are several answers to each one. The hidden units number is determined by a trial-error process. Few neurons in hidden layers (hidden units) can lead to under fitting. However, too many neurons can cause over fitting. The actual number of neurons required in the hidden layer must be found by trial and error. Moreover, the inputs are used by the network must be effective on the value of output(s), in fact the input and output variables should be identified carefully, because enable the network to learn relationships quicker and use fewer hidden units.
All networks have a single hidden layer because the single hidden layer network is found to be sufficient to model any function (Cybenko, 1989). To find the appropriate number of hidden nodes, networks with one to q nodes in their hidden layer are constructed. The value of q is optional and should be changed if the goal error has not met.
Learning algorithms: Famous type of different back-propagation algorithms is explained in following.
Batch training with weight and bias learning rules (Trainb): Trainb trains a network with weight and bias learning rules with batch updates. The weights and biases are updated at the end of an entire pass through the input data.
BFGS quasi-Newton back-propagation (Trainbfg): Trainbfg is a network training function that updates weight and bias values according to the BFGS quasi-Newton method.
Bayesian regularization back-propagation (Trainbr): Trainbr is a network training function that updates the weight and bias values according to Levenberg-Marquardt optimization. It minimizes a combination of squared errors and weights and then determines the correct combination so as to produce a network that generalizes well. The process is called Bayesian regularization (Powell, 1977).
Cyclical order incremental training with learning functions (Trainc): Trainc trains a network with weight and bias learning rules with incremental updates after each presentation of an input. Inputs are presented in cyclic order.
Conjugate gradient back propagation with Powell-Beale restarts (Traincgb): Traincgb is a network training function that updates weight and bias values according to the conjugate gradient back propagation with Powell-Beale restarts (Powell, 1977).
Conjugate gradient back-propagation with Fletcher-Reeves updates (Traincgf): Traincgf is a network training function that updates weight and bias values according to the conjugate gradient back-propagation with Fletcher-Reeves updates.
Conjugate gradient back-propagation with Polak-Ribiere updates (Traincgp): Traincgp is a network training function that updates weight and bias values according to the conjugate gradient back-propagation with Polak-Ribiere updates.
Gradient descent back-propagation (Traingd): Traingd is a network training function that updates weight and bias values according to gradient descent.
Gradient descent with adaptive learning rate back-propagation (Traingda): Traingda is a network training function that updates weight and bias values according to gradient descent with adaptive learning rate.
Gradient descent with momentum back-propagation (Traingdm): Traingdm is a network training function that updates weight and bias values according to gradient descent with momentum.
Gradient descent with momentum and adaptive learning rate back-propagation (Traingdx): Traingdx is a network training function that updates weight and bias values according to gradient descent momentum and an adaptive learning rate.
Levenberg-Marquardt back-propagation (Trainlm): Trainlm is a network training function that updates weight and bias values according to Levenberg-Marquardt optimization.
One step secant back-propagation (Trainoss): Trainoss is a network training function that updates weight and bias values according to the one step secant method.
Random order incremental training with learning functions (Trainr): For each epoch, all training vectors (or sequences) are each presented once in a different random order, with the network and weight and bias values updated after each individual presentation.
Resilient back-propagation (Trainrp): Trainrp is a network training function that updates weight and bias values according to the resilient back-propagation algorithm (Rprop).
Sequential order incremental training with learning functions (Trains): Trains trains a network with weight and bias learning rules with sequential updates. The sequence of inputs is presented to the network with updates occurring after each time step.
Scaled conjugate gradient back-propagation (Trainscg): Trainscg is a network training function that updates weight and bias values according to the scaled conjugate gradient method.
Cross Validation Test Technique (CVTT): In CVTT the data set is first split into several parts. Then, one part is utilized for testing and the rest are saved for training purpose. These steps are repeated until all parts used as testing set. The final product of CVTT is the mean accuracy of total runs.
DATA PRE-PROCESSING
Covariance stationary is one of the basic assumptions in time-series and should be studied for the models. Moreover, using preprocessed data is more useful in most heuristic methods (Zhang and Qi, 2005). If the models are not covariance stationary, the most suitable preprocessed method should be defined and applied.
The first Difference method: As mentioned, the first step in the Box-Jenkins method is to transform the data so as to make it stationary. The difference method was proposed by Box and Jenkins (1976).
Tseng et al. (2002) also used this method in their article in which the estimation of time series functions using heuristic approach is done. In this method, the following transformation should be applied:
yt = xt - xt-1 | (1) |
With a bit change in 1 the first difference of the logarithm is:
yt = log (xt)-log (xt-1) | (2) |
RESEARCH METHODOLOGY
This algorithm has the following basic steps
Step 1: Divide data into two sets, one for estimating the models called train data set and the other one for evaluating the validity of the estimated model called test data set. Usually, train data set contains 70 or 90% of all data and the remaining data are used in test data set (Aznarte et al., 2007).
Step 2: The stationary assumption should be studied for all type of ANN model. If the process is not covariance stationary, the most suitable preprocessing method should be selected and applied to the model.Box
Step 3: Determination of input variables for each model should be done. input variables can be selected using autocorrelation function (ACF) in most heuristic methods, selection of input variables is experimental or based on the trial and error method (Hwarng et al., 2001; Nayak et al., 2004; Karunasinghe et al., 2006; Tseng et al., 2002; Zhang and Qi, 2005; Zhang and Hu, 1998; Palmer et al., 2006; Kim et al., 2004; Zhang, 2001).
Step 4: Running and estimating of all models are done in this step.
The plausible architecture of ANN is constructed in this step.
Step 5: The predicting ability for each model is evaluated in this step. Furthermore, the comparison of each model with actual data is done and error of each model is calculated. MAPE is used to compare the models.
CASE STUDY
The proposed algorithm is applied to 130 data, which are the monthly consumption values from April 1993 to February 2005.
Step 1: All of 129 pre-processing data divided into 117 training data and 12 test data.
Step 2: It can be shown in Fig. 1a in that raw data have a trend. As removing the trend is needed for more precise estimation and also for studying the impact of preprocessing on ANN, preprocessing methods are applied on data. Finally, the best preprocessing method for our data which can make the model covariance stationary is selected. The results of applying preprocessing methods for given data are as follows:
The first difference method: The preprocessed data using this method are shown in Fig. 1b. Although, the first difference of the series seems to have a constant mean, the variance is an increasing function of time. So, this method is not covariance stationary and can not be used for data preprocessing.
It can be shown in Fig. 1c, which shows the first difference of the logarithm of consumption data, that this method is the most likely candidate to be covariance stationary.
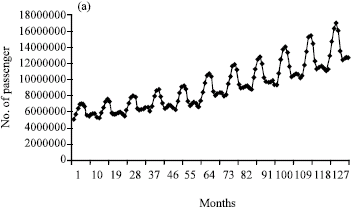 | |
| Fig. 1: | (a) Raw data, (b) Proposed data by first differences method and (c) Proposed data by first differences of the Logarithm methods |
So, it is the most applicable preprocessing method for our data.
Step 3: For all ANN models, ACF approach is used to select input variables. Figure 2 shows that yt is the function of consumption in the 1st, 11th and 12th lags in preprocessed data.
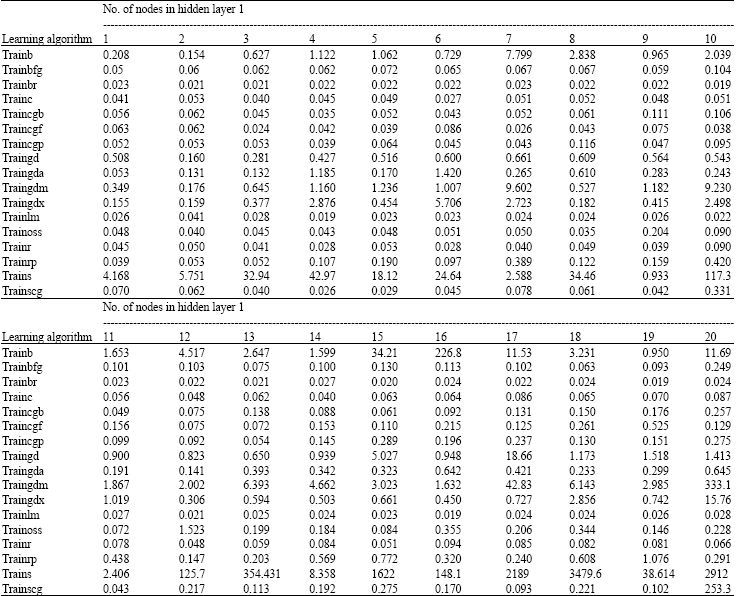
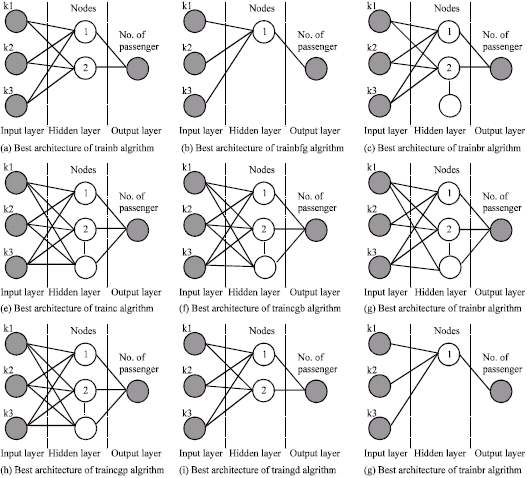
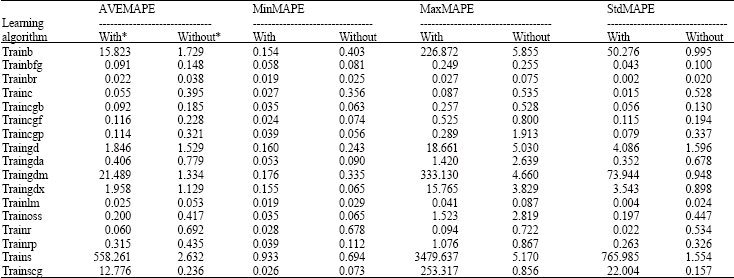
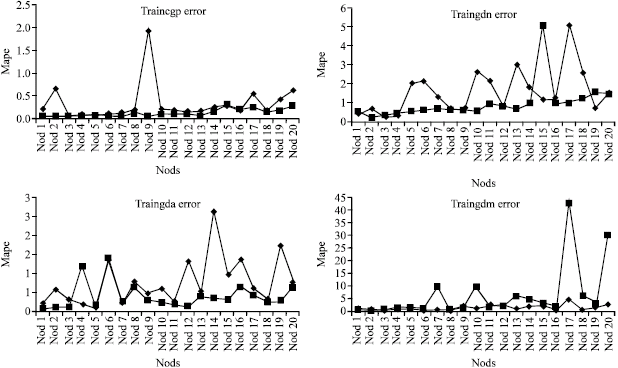
Step 4: (Estimation of airline number of passenger by ANN-MLP): In order to get the best ANN, 17 MLP models are tested to find the best architecture. Three parts of train data are constructed for test in different running; the final product of CVTT is the mean accuracy of total runs. Table 1 shows the MAPE value of 340 ANN-MLP models. Truly, for each learning algorithm, networks with having 1 to 20 nodes is constructed and implemented. Best architectures of train algorithms are shown in Fig. 3. In Table 2 statistic variable related to Table 1 is showed.
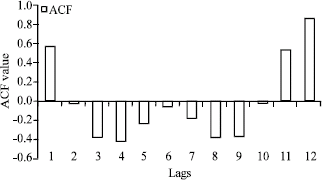 | |
| Fig. 2: | ACF charts for select input variable |
| Table 1: | MAPE value of learning algorithms in ANN-MLP mode |
 | |
 | |
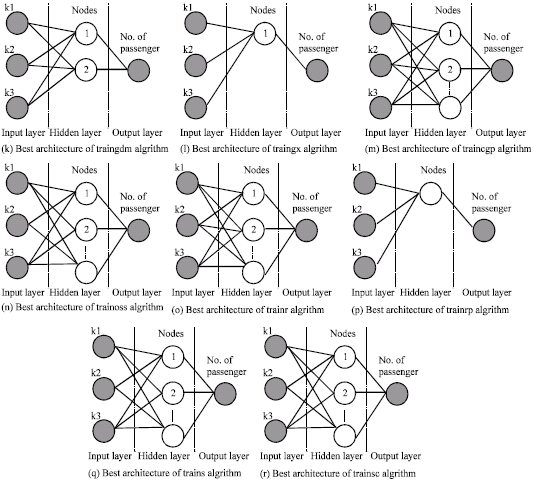 | |
| Fig. 3: | The best architecture of the selected ANN-MLP Learning algorithm |
| Table 2: | Statistical variable related to ANN-MLP models |
 | |
RESULT ANALYSIS
Comparison of ANN models by data envelopment analysis: DEA is a non-parametric method that uses linear programming to calculate the efficiency in a given set of Decision-Making Units (DMUs) (Charnes et al., 1978; Zhu, 1998). The DMUs that make up a frontier envelop, the less efficient firms and the relative efficiency of the firms is calculated in terms of scores on a scale of 0 to 1, with the frontier firms receiving a score of 1. DEA models can be input or output oriented and can be specified as constant returns to scale (CRS) or variable returns to scale (VRS).
We have utilized DEA method to comprise ANN models. Since MAPE alone may not be appropriate in comparison process thus we need to utilize other variables, involving AVEMAPE, MinMAPE, MaxMAPE and StdMAPE for each ANN models.
Where:| • | Variable MAPEjk is defined as: | |
| Mean Absolute Percentage Error of ANN, with regard to kth part of data, used as test data and j node in hidden layer. | ||
| • | Variable AVEMAPEj is defined as: | |
| AVEMAPEj = Average {MAPEjk: k = 1, 2, …} or average of MAPE in all constructed ANN with regard to j node in hidden layer. | ||
| • | AVEMAPE is defined as: | |
| AVE = Average (AVEMAPEj) | ||
| • | StdMAPE is defined as: | |
| StdMAPE = std (AVEMAPEj) | ||
| • | MaxMAPE is defined as: | |
| MaxMAPE = Max (AVEMAPEj) | ||
| MinMAPE is defined as: | ||
| MinMAPE = Min (AVEMAPEj) | ||
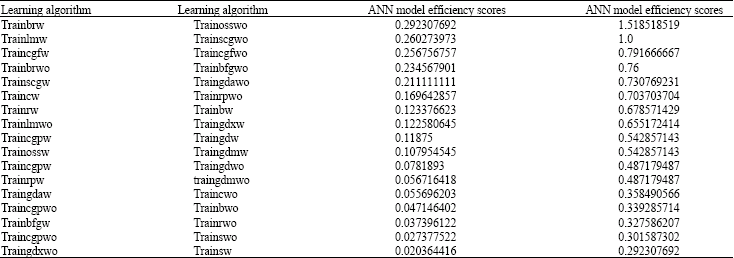
Error variables are shown in Table 2. DEA method will effectively take into account the values of these variables to Study the performance of ANN models. We treated value of MAPE, MIN, MAX and STD for each model as inputs with the specific output of 1 of each reduction. Calculated full rank efficiency scores along with ANN performance ranks are shown in Table 3. Examination of Table 3 shows that ANNs with Levenberg-Marquardt back-propagation and Bayesian regularization back-propagation algorithms and preprocessed data are the best. Also, examination of Table 3 shows that 12 of initial 17 learning algorithm use pre process and post process method. So five learning algorithm have good performance even without using preprocessed data. These are: Trainbr, trainlm, traingdx, traincgp and traincgb.
Comparison of ANN models by Kruskal-Wallis test: Here, Kruskal-Wallis test as a strong statistical tool is used in comparison process again. Failing the hypothesis of normality (non sufficient number of data) is the reason of using Kruskal-Wallis test instead of parametric version of ANOVA. The assumption behind this test is that the measurements come from a continuous distribution, but not necessarily a normal distribution. The test is based on an analysis of variance using the ranks of the data values.
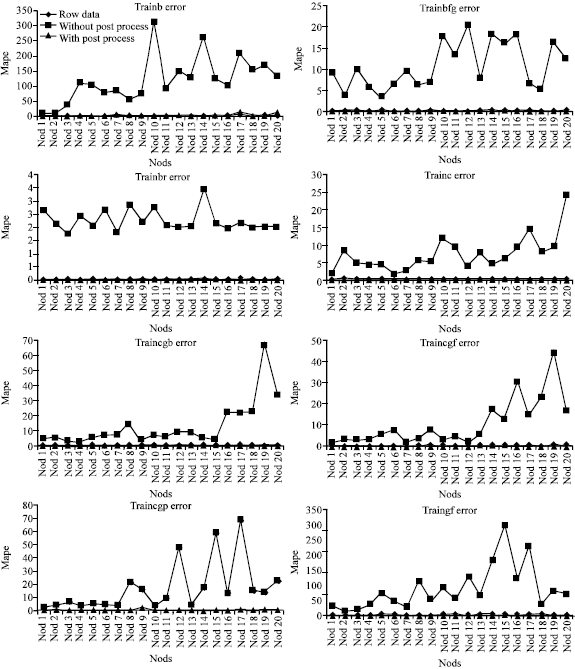
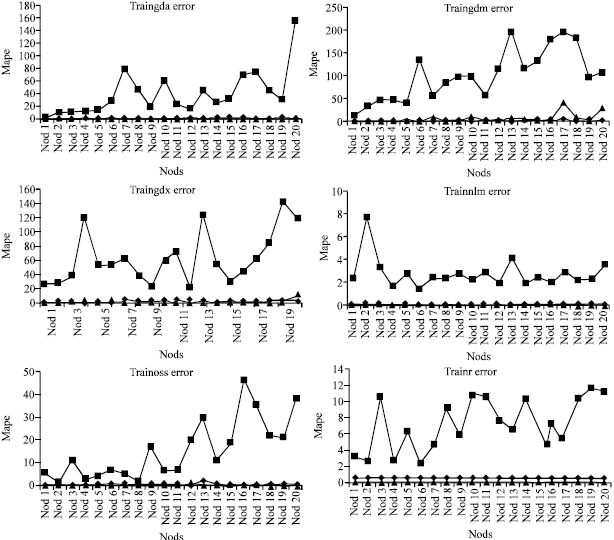
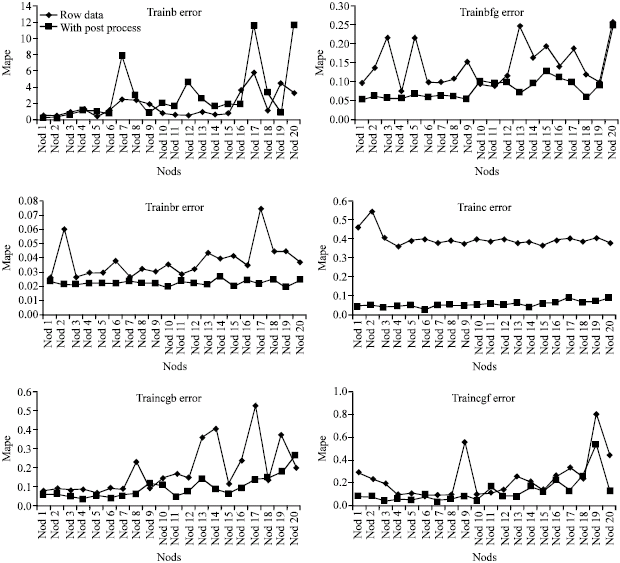
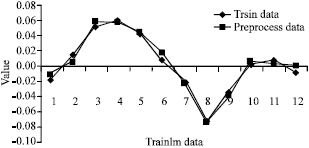
Examinations of Fig. 4-6 shows post processed data have positive affect on ANN performance.
Examinations of Fig. 7 shows post process of ANN result after preprocess is vital.
Necessity to Use Post process method: Table 4 and Fig. 8 shows the Output of one ANN that uses preprocessed data. Examination Table 4 and the Fig. 8 shows that ANN model had acceptable performance but if the out of ANN do not post process that value of MAPE is 279%.
| Table 3: | Full rank efficiency of ANN-MLP model |
 | |
 | |
 | |
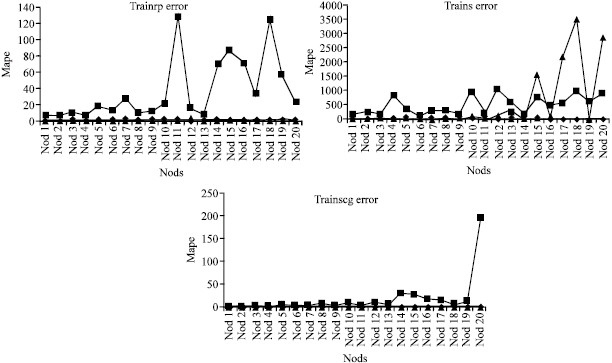 | |
| Fig. 4: | MAPE values for each learning algorithm row data, with post process and without post process result |
 | |
 | |
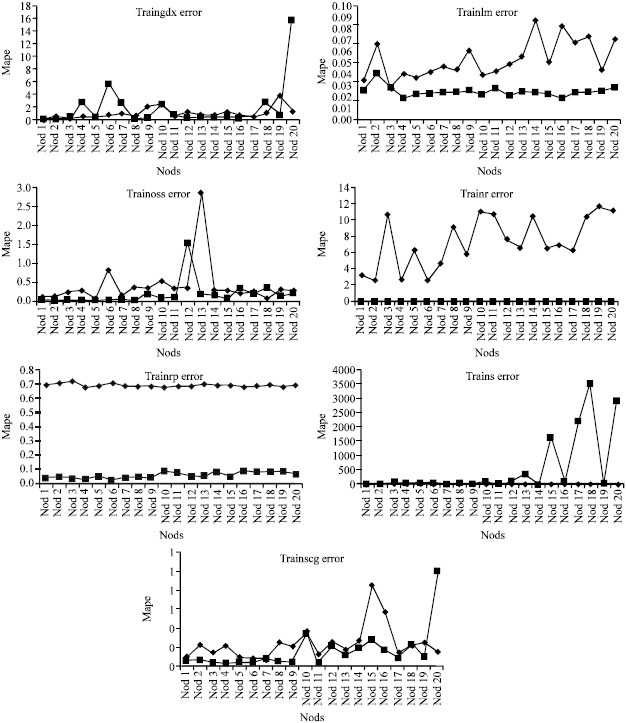 | |
| Fig. 5: | MAPE values for each learning algorithm before post processing and after post processing result |
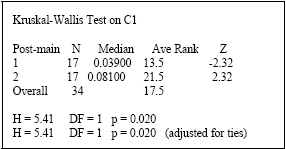 | |
| Fig. 6: | Kruskal-Wallis test versus row data-with post process |
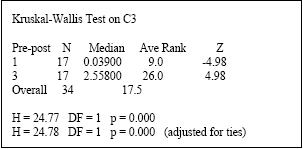 | |
| Fig. 7: | Kruskal-Wallis test versus without post process-with post process |
| Table 4: | Trainlm train algorithm data with one node |
 | |
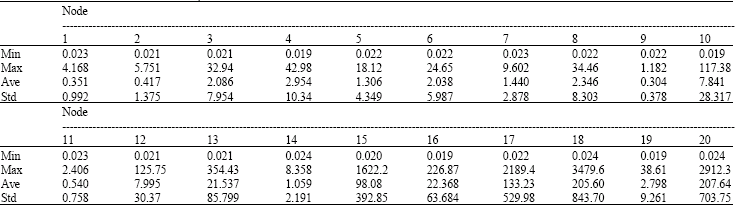
| Table 5: | Min MAPE value of 20 nodes implemented in 17 train functions |
 | |
 | |
| Fig. 8: | Comparison of ANNW output with actual data |
This value shows the necessity of ANN post process after using preprocessed data. Truly, if ANN results do not post process, the original ANN performance is ignored. The value of MAPE after ANN result post process is 2.5%.
Table 5 is yield from value in column of Table 1. Truly, in Table 5, we focused on performance of each node. With regard to Table 5 and Min variable, nodes 4, 10, 16 and 19 are the best among other nodes. As nodes 4 Max variable is less than others, is the best. With regard to our expected too many nodes suffer from over fitting problem.
CONCLUSION
In this study, all type of ANN-MLP models is examined to predicting airline number of passenger. A non-covariance stationary process was converted to covariance stationary process by a suitable data preprocessing method. Then, ACF method was used for input selection. We compared all models of ANN modeling by using DEA method. The result of DEA showed that ANNs with Levenberg-Marquardt back-propagation and Bayesian regularization back-propagation algorithms and preprocessed data are the best. So, with regard to our data, preprocessed data has positive impact on ANN performance. The result of Kruskal-Wallis Test approves yield result. Also the result of Kruskal-Wallis Test shows post process of ANN output is vital.
In order to extend the proposed model, the impact of data preprocessing and post processing in another method (such as fuzzy regression, neuro-fuzzy, particle swarm, ant colony, genetic algorithm) can also be studied.
REFERENCES
- Azadeh, A., S.F. Ghaderi and S. Sohrabkhani, 2007. Forecasting electrical consumption by integration of neural network, time series and ANOVA. Applied Math. Comput., 186: 1753-1761.
CrossRef - Azadeh, A., S.F. Ghaderi, S. Tarverdian and M. Saberi, 2007. Integration of artificial neural networks and genetic algorithm to predict electrical energy consumption. Applied Math. Comput., 186: 1731-1741.
CrossRef - Aznarte, J.L., J.M.B. Sanchez, D.N. Lugilde, C.D.L. Fernandez, C.D. Guardia and F.A. Sanchez, 2007. Forecasting airborne pollen concentration time series with neural and neuro-fuzzy models. Expert Syst. Applied, 32: 1218-1225.
CrossRef - Charnes, A., W.W. Cooper and E. Rhodes, 1978. Measuring the efficiency of decision making units. Eur. J. Operat. Res., 2: 429-444.
CrossRefDirect Link - Chiang, W.C., T.L. Urban and G.W. Baldridge, 1996. A neural network approach to mutual fund net asset value forecasting. Omega, 24: 205-215.
CrossRefDirect Link - Cybenko, G., 1989. Approximation by superpositions of a sigmoidal function. Mathe Control Signals Syst., 2: 303-314.
CrossRefDirect Link - Gareta, R., L.M. Romeo and A. Gil, 2006. Forecasting of electricity prices with neural networks. Energy Convers. Manage., 47: 1770-1778.
CrossRef - Hill, T., M. O'Connor and W. Remus, 1996. Neural network models for time series forecasts. Manage. Sci., 42: 1082-1092.
Direct Link - Hwarng, H.B., 2001. Insights into neural-network forecasting of time series corresponding to ARMA (p,q) structures. Omega, 29: 273-289.
CrossRef - Indro, D.C., C.X. Jiang, B.E. Patuwo and G.P. Zhang, 1999. Predicting mutual fund performance using artificial neural networks. Omega, 27: 373-380.
CrossRefDirect Link - Jain, A. and A.M. Kumar, 2007. Hybrid neural network models for hydrologic time series forecasting. Applied Soft Comput., 7: 585-592.
CrossRef - Karunasinghe, D.S.K. and S.Y. Liong, 2006. Chaotic time series prediction with a global model artificial neural network. J. Hydrol., 323: 92-105.
CrossRef - Kim, T.Y., K.J. Oh, C. Kim and J.D. Do, 2004. Artificial neural networks for non-stationary time series. Neurocomputing, 61: 439-447.
CrossRef - Kohzadi, N., M.S. Boyd, B. Kermanshahi and I. Kaastra, 1996. A comparison of artificial neural network and time series models for forecasting commodity prices. Neurocomputing, 10: 169-181.
CrossRefDirect Link - Nayak, P.C., K.P. Sudheer, D.M. Rangan and K.S. Ramasastri, 2004. A neuro-fuzzy computing technique for modeling hydrological time series. J. Hydrol., 291: 52-66.
CrossRef - Niska, H., T. Hiltunen, A. Karppinen, J. Ruuskanen and M. Kolehmainena, 2004. Evolving the neural network model for forecasting air pollution time series. Eng. Applied Artif. Intel., 17: 159-167.
CrossRef - Palmer, A., J.J. Montano and A. Sese, 2006. Designing an artificial neural network for forecasting tourism time series. Tourism Manage., 27: 781-790.
CrossRef - Powell, M.J.D., 1977. Restart procedures for the conjugate gradient method. Mathe. Program., 12: 241-254.
CrossRef - Stern, H.S., 1996. Neural networks in applied statistics. Technometrics, 38: 205-214.
CrossRefDirect Link - Tseng, F.M., H.C. Yu and G.H. Tzeng, 2002. Combining neural network model with seasonal time series ARIMA model. Technol. Forecast. Soc. Change, 69: 71-87.
CrossRef - Zhang, G.P. and M. Qi, 2005. Neural network forecasting for seasonal and trend time series. Eur. J. Operat. Res., 160: 501-514.
CrossRef - Zhang, G. and M.Y. Hu, 1998. Neural network forecasting of the British pound/US dollar exchange rate. Omega, 26: 495-506.
CrossRef - Zhang, G.P., 2001. An investigation of neural networks for linear time-series forecasting. Comput. Operat. Res., 28: 1183-1202.
CrossRef - Zhu, J., 1998. Data envelopment analysis vs. Principal component analysis: An illustrative study of economic performance of Chinese cities. Eur. J. Operat. Res., 111: 50-61.
CrossRef