
M.H. Karimi Gavareshki
Department of Industrial Engineering, Amirkabir University of Technology, Tehran, Iran
M.H. Fazel Zarandi
Department of Industrial Engineering, Amirkabir University of Technology, Tehran, Iran
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 6 | Page No.: 992-999







ABSTRACT
This study presents a heuristic approach based on Shifting Bottleneck (SB) for large scale job shop scheduling problems. Subproblem solution procedure and reoptimization are two important factors in SB approach that can increase computational efforts. In large scale problems, we need effective procedures to decrease the computational efforts. This study, first, presents a modified Schrage algorithm for single machine scheduling problems with heads and tails that is an effective subproblem solution procedure. Then we present a heuristic approach for job shop scheduling that resolve reoptimization difficulties in SB. Finally, the proposed algorithm is tested and validated. Experiment results show the superiority of our approach in comparison to SB in large scale problems especially in computational efforts. This approach can be a good initial seed in using search techniques.
PDF Abstract XML References Citation
How to cite this article
M.H. Karimi Gavareshki and M.H. Fazel Zarandi, 2008. A Heuristic Approach for Large Scale Job Shop Scheduling Problems. Journal of Applied Sciences, 8: 992-999.
DOI: 10.3923/jas.2008.992.999
URL: https://scialert.net/abstract/?doi=jas.2008.992.999
DOI: 10.3923/jas.2008.992.999
URL: https://scialert.net/abstract/?doi=jas.2008.992.999
INTRODUCTION
The job-shop problem is regarded as one of the hardest in combinatorial optimization (Brinkkotter and Brucker, 2001). During the past decades, many researchers have been focusing on the job shops and proposed several effective algorithms for them. They can be classified as optimization and approximation algorithms. The optimization algorithms are usually based on the branch and bound scheme (Brucker et al., 1994; Carlier and Pinson, 1994). These algorithms have made considerable achievement; however, their implementation needs high computational cost. On the other hand, approximation algorithms are more effective for large size problem instances. Among the heuristics, a successful approach is the Shifting Bottleneck (SB).
SB was, first, presented by Adams et al. (1988). Later Dauzere-Peres and Lasserre (1993), Applegate and Cook (1991), Balas et al. (1995) and Mukherjee and Chatterjee (2006) have enhanced this method. There have been extensive computational experiments evaluating the performance of several versions of SB routine on different shop configurations (Demirkol et al., 1997; Holtsclaw and Uzsoy, 1996; Uzsoy and Wang, 2000). The general consensus is that the SB performs quite well compared to various dispatching rules on almost all problem types.
The main strategy of the SB lies in relaxing the problem into m single machine subproblems and solving each single machine independently. This approach consists of four functions: problem decomposition, bottleneck identification, subproblem scheduling and reoptimization. On a specified scheduling criterion, the machine having the maximum lower bound is selected as the bottleneck machine and the SB sequences the bottleneck machine first while ignoring the remaining unscheduled machines. After the machine is scheduled, the reoptimization procedure is triggered. The SB algorithm repeats the single machine scheduling procedure until all machines are scheduled (Wu et al., 2006).
Subproblems solution procedures (SSPs) that are single machine problems and reoptimization are two main functions in SB. Holtsclaw and Uzsoy (1996) tested the quality and efficiency of the solution on 12 combinations of machine criticality measures that used for selecting shifting machines and subproblem solution procedures (SSPs). According to their research, the more sophisticated algorithm usually has the better efficiency. Demirkol et al. (1997) found that the better SSPs and reoptimization has higher solution quality. Uzsoy and Wang (2000) modified the testing structure of Demirkol et al. (1997) to distinguish the bottleneck machines from non-bottleneck. They found that a system with more significant bottleneck machines might have higher search efficiency.
In the large scale problems, implementing heuristic approaches for subproblems solution procedure in SB can decrease computational efforts. Although using the exact approaches such as Carlier algorithm (1982) for single machine (subproblems) can improve solution quality of the job shop problems, this increases computational effort in large scale problems. Wenqi and Aihua (2004) presented a heuristic as Schrage algorithm with disturbance for solving subproblems, base on presented improved shifting bottleneck (ISB) and showed that it has a better performance than SB. However, it has some drawbacks. This study tries to resolve some of the drawbacks and present a modified Schrage algorithm that is more effective than previous Schrage algorithm and Schrage algorithm with a disturbance (DS).
Reoptimization is one of the important problems in SB that can increase computational efforts especially in the large scale problems. This study presents a new approach that can omit reoptimization.
Job shop problem: The job shop scheduling problem can be described as follows: There are a set of jobs and a set of machines. Each job consists of a series of operations and each operation with fixed processing time is processed by a certain machine. The problem consists in scheduling the jobs on the machines with the objective to minimize the makespan the time needed to finish all the jobs. Any schedule is subjected to two constraints: (i) the precedence of the operations on each job must be respected; (ii) once a machine starts processing an operation it cannot be interrupted and each machine can process at most one operation at a time.
Let N = {0, 1,…, n} denotes the set of operations (with 0 and n the dummy operations .start. and .finish.), M the set of machines, A the set of pairs of operations constrained by precedence relations and Ek the set of pairs of operations to be performed on machine k and which therefore cannot overlap in time. Further, let pi denote the (fixed) duration (processing time) and ti the (variable) start time of operation i. The job shop problem can then be stated as:
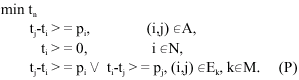 |
Any feasible solution to (P) is called a schedule. It is useful to represent this problem on a disjunctive graph G = (N, A, E), with node set N, ordinary (conjunctive) arc set A and disjunctive arc set E (Balas, 1969). Conjunctive arcs represent precedence relations and pairs of disjunctive arcs correspond to operations that must be processed on the same machine. Figure 1 shows the graph for a problem with 8 operations (on three jobs) and three machines.
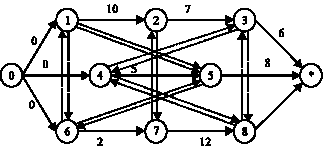 | |
| Fig. 1: | Digraphy an instance |
A selection Sk in Ek contains exactly one member of each disjunctive arc pair of Ek. Actually, determining an acyclic section on Sk is equivalent to sequencing the jobs (operations) on machines k. A complete selection S consists of the union of selection Sk, one in each Ek, k ![]() M. In the language of disjunctive graphs, the problem is to find an acyclic complete selection S ⊂ E that minimizes the length of a longest path in the directed graph DS.
M. In the language of disjunctive graphs, the problem is to find an acyclic complete selection S ⊂ E that minimizes the length of a longest path in the directed graph DS.
Shifting bottleneck: Shifting Bottleneck is a heuristic approach that uses in job shop scheduling problems. The main strategy of the SB lies in relaxing the problem into m single machine subproblems and solving each single machine independently. This approach consists of four functions: problem decomposition, bottleneck identification, subproblem scheduling and reoptimization. On a specified scheduling criterion, the machine having the maximum lower bound is selected as the bottleneck machine and the SB sequences the bottleneck machine first while ignoring the remaining unscheduled machines. After the machine is scheduled, the reoptimization procedure is triggered. The SB algorithm repeats the single machine scheduling procedure until all machines are scheduled (Wu et al., 2006).
Let M0 be the set of machines that have already been sequenced, by choosing selections Sp (p![]() M0). Let (P(k, M0)) be the problem obtained by replacing each arc set Ep (p
M0). Let (P(k, M0)) be the problem obtained by replacing each arc set Ep (p![]() M0) with the corresponding selection Sp and deleting each arc set Ep (p
M0) with the corresponding selection Sp and deleting each arc set Ep (p![]() M/M0-{k}). A bottleneck machine m
M/M0-{k}). A bottleneck machine m![]() M/M0 is such that v(m,M0) = max{v(k,M0): k
M/M0 is such that v(m,M0) = max{v(k,M0): k![]() M/M0}, where v(k,M0) is the value of a good solution to (P(k,M0)) Fig. 2 (Wenqi and Aihua, 2004; Adams et al., 1988).
M/M0}, where v(k,M0) is the value of a good solution to (P(k,M0)) Fig. 2 (Wenqi and Aihua, 2004; Adams et al., 1988).
Let M0 be the set of already sequenced (M0 = Φ at the start).
In step 1, to identify the next bottleneck machine to be sequenced, for each k![]() M/M0 the following problem should be solved:
M/M0 the following problem should be solved:
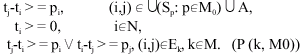 |
Also, to reoptimize in Step 2 the sequence of each critical machine k![]() M0, for each of such machines, a problem of the form (P (k, M`0)) is solved for some subset M`0 ⊂ M0.
M0, for each of such machines, a problem of the form (P (k, M`0)) is solved for some subset M`0 ⊂ M0.
 | |
| Fig. 2: | Shifting bottleneck procedure |
The problem (P(k,M0)) is equivalent to that of finding a sequence for machine k that minimizes the maximum lateness, given that each operation i to be performed on machine k has, besides the processing time Pi, a release time ri and a due date di. Here, ri = L(0, i) and di = L(0, n) L(i,n) + pi, with L(i, j) the length of a longest path from i to j in Dt and T: = ∪(Sp: p![]() M0). This latter problem in turn can be viewed as a minimum makespan problem where each job has to be processed in order by three machines, of which the first and the third have infinite capacity, while the second one (corresponding to machine k in the above model) processes one job at a time and where the processing time of job i is ri on the first machine, pi on the second and qi : = L(0,n) di on the third machine. The numbers ri and qi are sometimes referred to as the head and tail of job i (Wenqi and Aihua, 2004; Adams et al., 1988).
M0). This latter problem in turn can be viewed as a minimum makespan problem where each job has to be processed in order by three machines, of which the first and the third have infinite capacity, while the second one (corresponding to machine k in the above model) processes one job at a time and where the processing time of job i is ri on the first machine, pi on the second and qi : = L(0,n) di on the third machine. The numbers ri and qi are sometimes referred to as the head and tail of job i (Wenqi and Aihua, 2004; Adams et al., 1988).
Thus, the one-machine problems solved during the algorithm are of the following form:
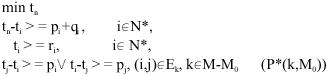 |
Where, ri and qi are defined as above and N* is the set of jobs to be processed on machine k.
The problem (P*(k, M0)), is a single machine problem with head and tail that is denoted the problem 1|rj, qj|Cmax in the literature. Further we present a heuristic for solving this problem.
A new heuristic for single machine: It is shown that the problem 1|rj, qj|Cmax is strongly NP-hard. A number of special cases of this problem are solvable in polynomial time (Vakhania, 2004). The enumerative methods for solving 1|rj, qj|Cmax are studied by Baker and Su (1974), McMahon and Florian (1975), Carlier (1982) and Grabowski et al. (1986). The algorithm proposed by Carlier was successfully tested even for 10000 jobs (Lawler et al., 1982; Grabowski et al., 1986). Shi and Pan (2006) present three improved branch-and-bound algorithms based on Carlier algorithm and other existing techniques that substantially outperform Carlier algorithm in terms of CPU time and robustness.
Schrage algorithm, a heuristic method suggested by Schrage (1971), is an effective algorithm that is used in single machine problem. The algorithms of McMahon and Florian (1975) and Carlier(1982) are based on Schrage algorithm (Lenstra (1977), Carlier (1982) and Potts (1980) for generating a good solution of the 1|rj, qj|Cmax problem). In both methods Schrage heuristic is used at every node of a search tree to generate a complete solution. Thus, a good solution of Schrage heuristic can decrease the space of search in the enumeration approaches such as Carlier algorithm. Also computational efforts of heuristic approaches such as Schrage algorithm is lower than the exact algorithms such as branch and bound (Carlier algorithm) in single machine problem. This can lead to decrease computational efforts in the job shop problems (Wenqi and Aihua, 2004).
In a single machine problem with heads and tails, n independent jobs should be sequenced on a machine: a job i is available for processing by the machine at time ri, has to spend an amount of time pi on the machine and an amount of time qi in the system after its processing by the machine. The objective is to minimize the makespan.
Carlier (1982) shows a sequence, in this problem, with a conjunctive graph G = (X, U). The set X of nodes is obtained by adding two nodes O and * to the set i of jobs: X = I ∪{O,*}, where, O is a job beginning and * a job end. The set U of arcs includes three sets: U = U1∪U2∪U3. Let U1 ={(O,i)| i![]() I}; arc(O,i) is valued by ri so that job i cannot start before the point in time ri. Let U2 = {(i,*)| i
I}; arc(O,i) is valued by ri so that job i cannot start before the point in time ri. Let U2 = {(i,*)| i![]() I}; arc (i,*) is valued by qi+ pi since job i has to spend an amount of time qi+pi in the system after its beginning of processing by the machine. Let U3 = {(i,j)| job i precedes job j in the sequence}; arc(i,j) is valued by pi; these arcs set the sequence. The aim is to find a sequence that minimizes the value of the critical path in the associated conjunctive graph.
I}; arc (i,*) is valued by qi+ pi since job i has to spend an amount of time qi+pi in the system after its beginning of processing by the machine. Let U3 = {(i,j)| job i precedes job j in the sequence}; arc(i,j) is valued by pi; these arcs set the sequence. The aim is to find a sequence that minimizes the value of the critical path in the associated conjunctive graph.
Schrage algorithm (Carlier, 1982): In the Schrage algorithm the job ready with greatest qi is scheduled first. In this algorithm, U is the set of jobs already scheduled and Ū is the set of jobs to be scheduled and t is the time. The steps of this algorithm are shown in Fig. 3.
In Schrage algorithm, presented by Carlier(1982), when ri<rj and qi>qj the algorithm can generate the optimal solution and when ri<rj and qi<qj it may result in weak solution (Wenqi and Aihua, 2004; Carlier, 1982). According to the Step 2 of the Schrage algorithm, in each stage, only the ready jobs, (ri<=t) from set Ū, are sequenced. In the following we denote these jobs by the set R. However, it is possible that there exist a job k (k ![]() Ū) so that rk>t while the tail of job k (i.e., qk) is very larger than the tail of job i ( ∀ i
Ū) so that rk>t while the tail of job k (i.e., qk) is very larger than the tail of job i ( ∀ i ![]() R). In this situation it is logically better to take into account job k in the set R. This problem may lead to increase makespan. Therefore, we need to expand the scope of the set R to all jobs in Ū so that the jobs with large tail that are not ready have chance to be selected.
R). In this situation it is logically better to take into account job k in the set R. This problem may lead to increase makespan. Therefore, we need to expand the scope of the set R to all jobs in Ū so that the jobs with large tail that are not ready have chance to be selected.
 | |
| Fig. 3: | Schrage algorithm |
Schrage algorithm with DS (Wenqi and Aihua, 2004): For solving a single machine problem the Schrage algorithm is easy to be implemented, but the quality of the solution that it produces usually leaves much room for improvement. Wenqi and Aihua (2004) improved the Schrage algorithm and presented a more effective algorithm with a disturbance (DS). They stated that in the Schrage algorithm when the priority of ri, pi, qi not respected strictly, much better solutions are probably obtained. In the situation that the value of r from a job is small while the value of q from this job is not large enough, the algorithm might delay this job. Therefore, they applied a disturbance (DS) on the priority rules based on Schrage algorithm. The steps of Schrage algorithm with DS are shown in Fig. 4.
Here, δ is disturbance coefficient. The degree of disturbance that determines the performance of DS is affected by the value of the coefficient δ. So, the suitable selection of δ in DS is an important issue. The experiments show that if the value of δ is too small or too large, the performance of DS is poor (Wenqi and Aihua, 2004). The former makes the machines idle too frequently to get enough rewards and the latter makes DS degenerate into the Schrage algorithm. DS probably obtains the best solutions when the value of δ is between 1.0 and 6.0 (in their experiments, it is seldom over 6.0) and it tends to obtain the same solution with different values of δ.
The semantic of the Schrage algorithm with disturbance presented is correct, i.e., in the situation that the value of r of a job is small while the value of q of this job is not large enough, the algorithm might delay this job. In this algorithm, in each stage, all of the jobs can be sequenced (i.e. R = Ū) and the tail of the jobs that are not ready (their ready time (ri) is larger than t), is adjusted by δx (ri-t). The decision criterion for sequencing is ui, where, ui = qi-δx (ri - t) for ri > t and ui = qi, for ri < t. But there are three main problems in modeling of DS. First, decision criterion ui can not be sufficient alone for sequencing. For example if we have job 1 with r1 = 10, p1 = 4, q1 = 10 and job 2 with r2 = 15, p2 = 10, q2 = 41, by this algorithm; u1 = 10, u2 = 11 (assumed that δ to be in extreme i.e., 6), then job 2 is sequenced earlier than job1. This result is wrong and can be lead to increase the makespan. Because when r2>r1+p1, there is not any rational reason to delay job 1. Therefore, we need a more comprehensive decision criterion to resolve this important issue. Second, in each stage, all of the unscheduled jobs are checked; this problem increases the computational efforts in the large scale problems. Third, the quality of solution depends on coefficient δ but there is not any semantic for selecting this coefficient. Also, if the coefficient δ varies, then the computational effort will be high.
 | |
| Fig. 4: | Schrage algorithm with DS |
Modified Schrage algorithm: As stated in the previous section, an important area for improvement in the Schrage algorithm is considering the jobs with large tail even if they are not ready. It means that we must expand the set R by adding those jobs to the set. But the main problem rises which jobs can be added? In other words, in Schrage algorithm, if ri < rj and qi > qj, i is earlier sequenced j that is logically true and proved in literature (Carlier, 1982). But if ri < rj and qi < qj we deal with this challenge that which of them must earlier be sequenced. This problem is studied by the following theorem.
Theorem 1: In one machine sequencing problem, if there are two jobs i and j with properties 0<=ri<rj and qi<qj, a necessary condition for sequencing j before i is (qj>m+ qi and pi > m) where, rj-t = m and pi >= 0.
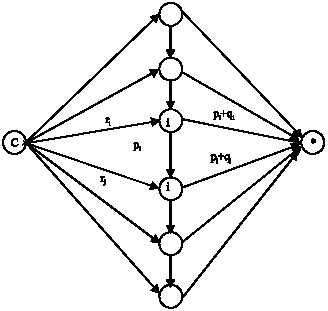 | |
| Fig. 5: | Associated conjunctive graph |
Proof: We demonstrate the sequence of jobs with a conjunctive graph G = (X, U) similar to Carlier algorithm (Fig. 5).
Let U be the set of jobs already scheduled, Ū be the set of all other jobs and ck be the completion time of the jobs belonging to set U in stage k. job i is a job with minimum r in the set Ū. Let t be max (ck, ri). Assume that the Job j is a job with rj so that rj > t and qj > qi. We prove that a necessary condition for sequencing j before i is: q j> m+qi and pi > m, where, rj-t = m and pi > = 0. Here, there exist two options as follows:
Option 1: job i to be scheduled before job j
Let Li1 be the length of path that pass through 0, 1, i, * and Lj1 be the length of path that pass through 0, 1, j, * and L1 = Max (Li1, Lj1). Thus we have:
L1 = Max (t+pi+qi, t+pi+pj+qj) | (1) |
Option 2: job j to be scheduled before job i
Let Li2 be the length of path that pass through 0, 1, i, * and Lj2 be the length of path that pass through 0, 1, j, * and L2 = Max (Li2, Lj2). Then,
L2 = Max (rj+pj+qj, rj+pj+pi+qi) | (2) |
Assume that job j is sequenced earlier than job i thus L2 must be lower than L1 because the aim is to minimize the longest path through 0 to *. Therefore, the formula (3) should be true.
Max (rj+pj+qj, rj+pj+pi+qi)< Max(t+pi+qi, t+pi+pj+qj) | (3) |
This means the formulae (4) or (5) should be true:
Max (rj+pj+qj, rj+pj+pi+qi)< t+pi+qi | (4) |
Max(rj+pj+qj, rj+pj+pi+qi)< t+pi+pj+qj | (5) |
The formula (4) is true if the formulae (6) and (7) both are true.
rj+pj+qj < t+pi+qi | (6) |
rj+pj+pi+qi< t+pi+qi | (7) |
The formula (5) is true if the formulae (8) and (9) both are true.
rj+pj+qj < t+pi+pj+qj | (8) |
rj+pj+pi+qi < t+pi+pj+qj | (9) |
Letrj-t = m ⇒ rj = m +t | (10) |
By replacing (10) in the formulae (6), (7), (8), (9), respectively we have:
m +t+pj+qj < t+pi+qi ⇒ qj < qi + pi -pj-m | (11) |
m +t +pj+pi+qi< t+pi+qi ⇒ m +pj <0 | (12) |
m +t+pj+qj < t+pi+pj+qj ⇒ pj>m | (13) |
m +t+pj+pi+qi < t+pi+pj+qj ⇒ qj>qi+m | (14) |
By the assumption: pj >= 0 and m >= 0, thus, the formula (12) is false. That means the formula (7) is false, then the formula (4) is false all the times. The formulae (10) and (11) by the assumption are true. That means the formulae (8) and (9) are true. So the formula (5) is also true all the times. Thus, the formula (3) is true that means L2<L1 and the theorem is proven.
If the job j to be critical i.e. belonging to critical path then as mentioned above necessary condition for sequencing j before i is (qj > m + qi and pi > m). But if the jobs j is not critical then sequencing it before i can be lead to increase delay (rj-t) and makespan. We define historically a condition for criticality of the job j by following.
| (15) |
Proposition 1: In stage s and k ![]() Ū
Ū
is a lower bound on the optimal makespan.
 | |
| Fig. 6: | Modified Schrage algorithm |
Proof: Carlier (1982) proved that for all I1 ⊆ I,
![]()
is a lower bound on the optimal makespan. Since Ū ⊆ I, therefore h(s) is a lower bound on the optimal makespan.
Now we present a modified Schrage algorithm according to theorem 1. the steps of algorithm are shown in Fig. 6.
In this algorithm, in each stage, both ready jobs and the jobs with large tails (based on theorem 1) can be sequenced. This improves the result of sequencing. Also in spit of DS algorithm, all of the unscheduled jobs are not candidate and are limited by the necessary condition. This can decrease computational effort in each stage especially in large problems. Furthermore, this algorithm does not depend on any coefficient such as δ.
We coded the three algorithms: Schrage Algorithm (SA), Schrage algorithm with disturbance (DS) and Modified Schrage Algorithm (MSA), with MATLAB and have tested 1000 problems. For each problem with n jobs, 3n integers have been generated with uniform distributions between 1 and rmax, pmax, qmax (Carlier, 1982).
We set pmax = 50, rmax = qmax= n.k and examined 50 values for k and 20 values for n = 50, 100 …., 1000. The problems are solved by the above three algorithms and enumerated the best solutions for problems (minimum makespan). Table 1 shows the comparison of the best solution between our algorithm and two others and the CPU time for running 1000 problems for each algorithm.
Of the 1000 problems, MSA gets the best solution in 880 cases. The results show that MSA got better results than SA and DS. The CPU time in SA is less than the other algorithms and DS spent too much CPU time. Since DS algorithm in each stage, computes the measure u for the remaining jobs unscheduled and checks all of them, thus in large scale problems it makes more computing efforts. In the proposed algorithm using the proven theorem, computing the measure u is limited to a few jobs and lead to decreasing CPU time and the complexity. M.A.S gets much better solutions than DS and SA and can be ignored a few increasing in CPU time respect to SA.
| Table 1: | Results of three algorithms on 1000 random problems |
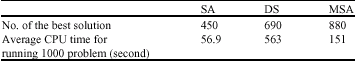 | |
Proposed Approach for job shop scheduling problem: The SB algorithm sequences the bottleneck machine first while ignoring the remaining unscheduled machines. After the machine is scheduled, the reoptimization procedure is triggered. The SB repeats the single machine scheduling procedure until all machines have been scheduled. subproblem solution procedure and reoptimization are two important factor in SB approach. In the previous section, we presented an efficient heuristic for subproblem solution that can decrease computational efforts. This study also presents a new approach for omitting reoptimization in SB procedure.
In the proposed approach, the ready operations are sequenced first while the operations on critical machine should be preferenced. This can omit the reoptimization efforts. In our approach similar to SB, the job shop problem is decomposed to m single machines, but by the deferent way. In this approach, the ready operations on the same machine lie in a block and each of them is a single machine problem. In each stage, the operations in a block should be sequenced by a subproblem solution procedure, while the other unscheduled operations on the machine should be considered in the problem. If the operation on the block has not been prioritized, it would have delayed.
For the sake of simplicity, we define critical machine in each stage as follows:
| (16) |
Subproblem solution procedure is base on modified Schrage algorithm presented in the pervious section. In this procedure, the prioritization is base on the head and tail of the operations (uij), however as sated above, we should prioritize the operations of critical machines. Criticality can be considered as a fuzzy concept. All of the machine can be critical by a membership degree. Membership degree of a machine can be calculated as follows:
 | |
| Fig. 7: | Subproblem solution procedure |
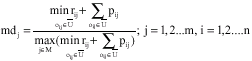 | (17) |
The delay on critical machine can increase makespan but in no critical machine the operations can be delayed. We use this concept in our approach. In the proposed approach, the criticality of machines takes in to account in subproblem solution procedure (Fig. 7). The symbols used in this algorithm are as follows:
| N | = | No. of jobs |
| M | = | No. of machines |
| ji | = | Job i |
| mj | = | Machine j |
| oij | = | Operation related to job i on machine j |
| U | = | Set of scheduled operations |
| â | = | Set of unscheduled operations |
| rij | = | The release time (head) of operation oij |
| qij | = | The delivery time (tail) of operation oij |
| pij | = | The processing time (tail ) of operation oij |
| Vj | = | Set of the ready operations on machine j |
| Ij | = | Set of unscheduled operations on machine j |
| Sij | = | Set of the successor operations of the operation oij |
The proposed algorithm for the job shop problem base on shifting bottleneck is shown in Fig. 8.
Calculations of heads and tails are based on all conjunctive arcs and the fixed disjunctive arcs (Brucker et al., 1994).
For the sake of simplicity, we can define tail of operations as follows:
| (18) |
This approach generates a feasible solution for job shop problem. Then, we can use reoptimization phase of SB approach for improving solutions.
 | |
| Fig. 8: | Proposed approach |
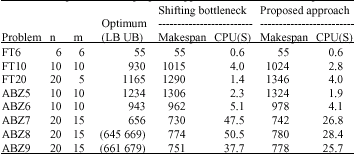
| Table 2: | Comparison of the proposed approach to SB for instance problems |
 | |
EXPERIMENTAL RESULTS
The algorithm is coded in MATLAB. We used a set of job shop scheduling problems from benchmark problems (Fisher and Thompson, 1963; Adams et al., 1988; Wenqi and Aihua, 2004). The proposed approach is compared by SB procedure. Comparisons are base on two main factors; solution quality (makespan), CPU time as computations efforts. The results of experiments are represented in Table 2.
Experimental results show that our method in small size until 6x6 gives us optimal solution. Also in large scale, the algorithm gives us good solutions. CPU time in our method is much lower than SB procedure while the makesapn of the proposed approach is comparable with SB. In sum, Experiment results show the superiority of our approach in comparison to SB in large scale problems especially in computational efforts. This approach can be provided a good seed in the iterative methods as a initial solution. Presenting hybrid approaches by iterative heuristics such as tabu search, simulated annealing and genetic algorithm can be future researches.
CONCLUSION
Subproblem solution procedure and reoptimization are two important factors in SB approach that can increase computational efforts. In large scale problems, we need effective procedures to decrease the computational efforts. This study, first, presents a modified Schrage algorithm for single machine scheduling problems with heads and tails that is an effective subproblem solution procedure. Then, it presents a heuristic approach for job shop scheduling that resolve reoptimization difficulties in SB. Finally, the proposed algorithm is tested and validated. Experiment results show the superiority of our approach in comparison to SB in large scale problems especially in computational efforts. This approach can be a good initial seed in using search techniques. Presenting hybrid approaches by iterative heuristics such as tabu search, simulated annealing and genetic algorithm can be future researches.
REFERENCES
- Adams, J., E. Balas and D. Zawack, 1988. The shifting bottleneck procedure for job shop scheduling. Manage. Sci., 34: 391-401.
CrossRefDirect Link - Baker, K.R. and Z.S. Su, 1974. Sequencing with due dates and early start times to minimize tardiness. Naval Res. Logistics Q., 21: 171-176.
CrossRef - Balas, E., 1969. Machine sequencing via disjunctive graphs: An implicit enumeration algorithm. Operat. Res., 17: 941-957.
CrossRef - Balas, E., J.K. Lenstra and A. Vazacopoulos, 1995. The one-machine problem with delayed precedence constraints and its use in job shop scheduling. Manage. Sci., 41: 94-109.
CrossRefDirect Link - Brinkkotter, W. and P. Brucker, 2001. Solving open benchmark instances for the job shop problem by parallel head-tail adjustments. J. Schedul., 4: 53-64.
Direct Link - Brucker, P., B. Jurisch and B. Sievers, 1994. A branch and bound algorithm for the job-shop scheduling problem. Discrete Applied Math., 49: 107-127.
CrossRefDirect Link - Carlier, J., 1982. The one-machine sequencing problem. Eur. J. Operat. Res., 11: 42-47.
CrossRefDirect Link - Carlier, J. and E. Pinson, 1994. Adjustments of heads and tails for the job-shop problem. Eur. J. Operat. Res., 78: 146-161.
CrossRef - Dauzere-Peres, S. and J.B. Lasserre, 1993. A modified shifting bottleneck procedure for job-shop scheduling. Int. J. Prod. Res., 31: 923-932.
CrossRefDirect Link - Demirkol, E., S.V. Mehta and R. Uzsoy, 1997. A computational study of shifting bottleneck procedures for shop scheduling problems. J. Heuristics, 3: 111-137.
CrossRefDirect Link - Grabowski, J., E. Nowicki and S. Zdrzalka, 1986. A block approach for single-machine scheduling with release dates and due dates. Eur. J. Operat. Res., 26: 278-285.
CrossRefDirect Link - Holtsclaw, H.H. and R. Uzsoy, 1996. Machine criticality measures and subproblem solution procedures in shifting bottleneck methods: A computational study. J. Operat. Res. Soc., 47: 666-677.
Direct Link - Lenstra, J.K., 1977. Sequencing by Enumerative Methods. Mathematical Center Tracts 69, Mathematical Centrum, Amsterdam, Unknown Binding. 1st Edn., Mathematisch Centrum, Germany, pp: 198.
Direct Link - McMahon, G.B. and M. Florian, 1975. On scheduling with ready times and due dates to minimize maximum lateness. Operat. Res., 23: 475-482.
CrossRefDirect Link - Potts, C.N., 1980. Analysis of a heuristic for one machine sequencing with release dates and delivery times. Operat. Res., 28: 1436-1441.
CrossRefDirect Link - Shi, L. and Y. Pan, 2006. Branch-and-bound algorithms for solving hard instances of the one machine sequencing problem. Eur. J. Operat. Res., 168: 1030-1039.
CrossRefDirect Link - Uzsoy, R. and C.S. Wang, 2000. Performance of decomposition procedures for job shop scheduling problems with bottleneck machines. Int. J. Prod. Res., 38: 1271-1286.
Direct Link - Vakhania, N., 2004. Single-machine scheduling with release times and tails. Ann. Operat. Res., 129: 253-271.
Direct Link - Wenqi, H. and Y. Aihua, 2004. An improved shifting bottleneck procedure for the job shop scheduling problem. Comput. Operat. Res., 31: 2093-2110.
CrossRefDirect Link - Wu, C.S., D.C. Li and T.I. Tsai, 2006. Applying the fuzzy ranking method to the shifting bottleneck procedure to solve scheduling problems of uncertainty. Int. J. Adv. Manuf. Technol., 31: 98-106.
CrossRefDirect Link