
S.J. Sadjadi
Iran University of Science and Technology, Tehran, Iran
J.L. Bouquard
University François-Rabelais, Tours, France
M. Ziaee
Iran University of Science and Technology, Tehran, Iran
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 21 | Page No.: 3938-3944







ABSTRACT
In this study, we considered the flowshop scheduling problem with the objectives of the makespan (F//Cmax) and the total flowtime (F//Σfi) separately. The permutation case of the problem was first solved by an Ant Colony Optimization (ACO) algorithm. The permutation solutions of this ACO algorithm were then improved by a non-permutation local search. In order to evaluate the performance of the proposed metaheuristic, computational experiments were performed using the well-known benchmark problems. A comparison with Rajendran solutions and the best metaheuristic solutions known for Taillard benchmark problems was carried out, show that the proposed ACO algorithm was clearly superior to the above metaheuristics.
PDF Abstract XML References Citation
How to cite this article
S.J. Sadjadi, J.L. Bouquard and M. Ziaee, 2008. An Ant Colony Algorithm for the Flowshop Scheduling Problem. Journal of Applied Sciences, 8: 3938-3944.
DOI: 10.3923/jas.2008.3938.3944
URL: https://scialert.net/abstract/?doi=jas.2008.3938.3944
DOI: 10.3923/jas.2008.3938.3944
URL: https://scialert.net/abstract/?doi=jas.2008.3938.3944
INTRODUCTION
In a flowshop problem, a set of jobs must be processed on a number of sequential machines, each job has to be processed on all machines and the processing routes of all jobs are the same. In the general (non-permutation) case of the flowshop scheduling problem, the sequence of jobs on each machine may be different from the sequence of jobs on another machine. In the permutation case, these sequences are the same for all machines.
It is proved that the permutation flow shop does not necessarily provide an optimal solution (Liao et al., 2006). These people show that the performance of nonpermutation schedules is better than that of permutation schedules. In general, when there are more than three machines, permutation schedules are no longer dominant (Koulamas, 1998). In comparison with the permutation schedules, the performance of non-permutation schedules may be considerable if the problems have nonregular performance measures like maximum tardiness or weighted mean tardiness (Liao et al., 2006). The non-permutation schedules may provide much better solutions in such situations. However, almost all existing researches have focused on permutation schedules and there is a lack of sufficient analysis on non-permutation scheduling problems in the literature (Cheng et al., 2000).
As the problem size grows bigger, identifying the best permutation schedule itself becomes quite difficult. Obviously, finding an optimal solution when sequence changes are permitted is more complex and difficult (Pugazhendhi et al., 2002). In the literature, heuristic methods have usually been used to solve the non-permutation flowshop scheduling problems. Some of them are Jain and Meeran (2002) and Koulamas (1998).
Two widely used objectives in the literature are the makespan and the total flowtime, which are based on the completion times. The literature abounds with numerous and very different techniques for the permutation flowshop scheduling problem with these objectives. Ruiz and Maroto (2005) have presented an extensive review and evaluation of many heuristics and metaheuristics for the permutation flowshop scheduling problem with the makespan criterion. Varadharajan and Chandrasekharan (2005) consider the bicriteria permutation flowshop scheduling problem with the objectives of minimizing the makespan and total flowtime of jobs and present a Multi-Objective Simulated-annealing Algorithm (MOSA) for solving the problem. Rajendran and Hans (2004) have recently presented two ant colony algorithms (M-MMAS and PACO) for solving the permutation flowshop scheduling problem with the objectives of makespan and total flowtime. The solutions of their methods are the best results obtained so far on only one mainframe. We show that the method proposed in this paper can obtain better solutions than the M-MMAS and PACO. A similar work has been done by Vallada and Ruben (2008) for the makespan criterion. Their research is a state of the art on the literature about the permutation flowshop scheduling problem with makespan. They propose cooperative metaheuristic methods for the problem. They use the island model where each island runs an instance of the algorithm. We compare our method with the best solutions of this cooperative metaheuristic (with 12 islands) and show that our solutions are close to those reported by Vallada and Ruben (2008) but they have used simultaneously 12 processors.
In this study, we consider the m-machine n-job flowshop scheduling problem with the objective functions of the makespan and the total flowtime separately. We assume that the ready times of all the jobs are equal to zero. Therefore, the total flowtime is equal to the total completion time. We develop an ACO algorithm to solve the permutation case of the problem. The permutation solution of the proposed ACO algorithm is then improved by a non-permutation local search. Therefore, the end solution of the method may be a non-permutation schedule. In order to evaluate the performance of the proposed metaheuristic, we implement the method for the benchmark problems of Taillard (1993) and present the results of the computational experiments. Finally, the conclusion remarks of this study are presented at the end to summarize the contribution of the study.
AN ACO ALGORITHM FOR SOLVING THE PROBLEM
Liao et al. (2006) show that there is little improvement made by non-permutation schedules over permutation schedules with respect to the completion-time based criteria such as makespan and total flowtime. Therefore, the proposed ACO algorithm is designed for generating only the permutation sequences. However, we store n` best permutation solutions of the ant colony procedure and then improve all of them by a rapid non-permutation local search. Storing best solutions for improving them may have an important role to increase the performance of the method. The steps of the proposed ant colony algorithm are as follows. Let z* be the objective function of the best sequence obtained so far (BS). I, K are the number of jobs and the number of machines respectively.
Step 1 (finding a seed permutation schedule): The algorithm uses a constructive method to find an initial permutation schedule. We use the NEH heuristic (Nawaz et al., 1983) to generate an initial permutation sequence for the objective of minimizing the makespan and a heuristic proposed by Woo and Yim (1998) to generate an initial permutation sequence for the objective of minimizing the total flowtime of jobs. These heuristics are powerful methods for solving a permutation flowshop scheduling problem (Ruiz and Concepcion, 2005; Woo and Yim, 1998).
Step 2 (first local search): The first local search is done using the pair-wise exchanges (Allahverdi, 2003), on the sequence as follows. We keep n-1 best solutions.
| 2-1) | Let: counter = 1, n = 1, |
| 2-2) | Imprv = 0, |
| 2-3) | For y1 = 1 (1) (I-1) : For y2 = (y1+1) (1) I : |
Replace the job in the position y1 with the job in the position y2 without changing the positions of the other jobs. If the objective function of the resulted permutation sequence is less than or equal to z*, do the following settings:
| • | Set the resulted sequence to δn and its objective function to z* |
| • | n = n+1, |
| • | Imprv = 1, |
Otherwise, replace again the job in the position y1 with the job in the position y2.
| 2-4) | counter = counter+1, |
| 2-5) | If counter = C1 and Imprv=1, go to step 2-2, |
| Else go to step 3 |
Step 3 (second local search): All of n sequences obtained from the previous section are improved by the second local search. This search is done based on the shift neighborhood method (Osman and Potts, 1989), which is defined by removing a job at one position and putting it to another position. The local search continues until no new improvement occurs. Let n0 = max (0, n-1001). The steps of this local search are as follows:
| 3-1) | Let: counter = 1, |
| 3-2) | Imprv = 0, |
| 3-3) | For y1 = 1 (1) I : |
| For y2 = 1 (1) I (y2 ≠ y1): |
Remove the job at the position y1 and put it to the position y2 in the sequence ![]() . If the objective function of the resulted permutation sequence is less than or equal to z*, do the following settings:
. If the objective function of the resulted permutation sequence is less than or equal to z*, do the following settings:
| • | Set the resulted sequence to δ* and its objective function to z*, |
| • | Imprv = 1, |
Otherwise, put again the job in its first position (y1),
| 3-4) | counter = counter+1, |
| 3-5) | If counter = C2 and Imprv=1, go to step 3-2, |
| Else go to step 3-6, | |
| 3-6) | n0 = n0+1, |
| 3-7) | If n0<n go to step 3-1. |
The best permutation sequence obtained from this step is now considered as a seed sequence for the ant colony algorithm which is started from the next step.
Step 4 (setting pheromones): Let fij be the pheromone trail intensity (or desire) of setting job i in position j in a sequence. Initially fij`s are calculated as follows:
We consider also Fij as the sum of the pheromones from position 1 to position j (Rajendran and Ziegler, 2004). It may be interpreted as the desire of setting job i at a position less than or equal to j and calculated as follows:
Step 5 (construction of an ant sequence): Different methods were tested to generate an ant sequence (AS) from the values of the pheromones (Dorigo and Stützle, 2004). Finally, we chose the following method for it provided better performance.
For j = 1 (1) I do:
| • | Select the following job for the j`th position of the ant sequence, if it is not scheduled so far, |
| • | The job with the biggest Fij with the probability α1, | |
| • | The job with the second biggest Fij with the probability α2, | |
| • | The job with the third biggest Fij with the probability α3, | |
| • | The job with the fourth biggest Fij with the probability α4, |
| • | If no job has selected for j`th position of the ant sequence, among non-scheduled jobs, select one with maximum Fij. |
We chose the αi`s such that αi = 2 αi+1 and obviously, Σαi = 1. That is, α1 = 8/15, α2 = 4/15, α3 = 2/15 and α4 = 1/15.
Step 6 (local searches): Use local search procedures of steps 2 and 3 for n0 = n-1.
Step 7 (updating pheromones and best sequence): BS is updated if the objective value of AS is less than that of BS. The pheromones are also updated as follows to take into account the new best solution.
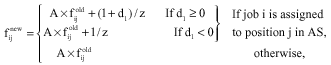 |
In the above relation, A is the evaporation rate (we set A = 0.9), z is the objective value of AS and d1 is calculated from the following relation:
B is a parameter which sets the importance of the improvement (we set B = 2). Fij`s are also updated as follows:
To explain the above pheromone settings, suppose that job i is assigned to position j in BS and fij is set to 1+3/z*. Non-promising ant sequences get pheromone value of 1/z in each iteration and therefore, missing randomly BS in the pheromone settings may occur after at least three iterations. The lower pheromones instead of 1+3/z*, for example 1+2/z*, may increase the probability of missing randomly BS and higher pheromones may lead to cumulate the pheromones in BS and so the promissing sequences may not be considered, even if we contact with them in some ants. However we have used d1 parameter for decreasing the probability of occurring this situation. It means that if we find a sequence AS which is better than BS, the phromones of that AS will be increased in comparison with the regular increment of phromones. The value of this increment is proportional to the amount of difference between the objectives of AS and BS.
Step 8 (stop criterion): Stop criterion can be defined either by an upper bound on the number of iterations (ants), or by an upper bound on the computational time. Stop if selected stopping criterion is met, otherwise go to step 5.
Step 9 (non-permutation local search): Several best permutation schedules are kept for the non-permutation local search. In this step, all of them are subjected to the following improvement algorithm:
A better solution is searched in the neighborhood of the current solution and the process stops when no improvement is found. A neighbor of a solution is obtained by a pairwise exchange of two jobs on the k first machines or on the k last machines, for k = 1 to K. The pairs consists of two jobs, the positions of which are not further than 2: A job of rank j is tested for an exchange with the job of rank (j+1) and the job of rank (j+2).
In the above local search, each job can violate the permutation condition in the amount of at most 2 positions, i.e. if yij, j = 1, 2, …, K is the position of j`th operation of job i on machine j, then we have:
The first reason for the above choice is that, intuitively, the permutation violation of more than 2 jobs may not be very promising. The second one is that the purpose of this algorithm is to improve a permutation solution rapidly. This can help us to improve a larger number of solutions. For example, if we have the pair (1, 2) and 4 machines, the following replacements are tested:
 |
Description of the algorithm: The above algorithm starts with an initial permutation schedule. This initial schedule is then improved by two local searches to obtain a seed sequence for starting the ant colony procedure. The first local search is based on the pair-wise exchanges and it can generate and store n-1 sequences which are denoted by δs; s = 1, 2, …., n-1 and subscript s demonstrates the rank of the corresponding sequence with respect to the value of objective function. So if we have two sequences: δs1 and δs2 and s1<s2, then the objective value of δs1 is greater than or equal to the objective value of δs2. This local search continues until counter reaches to its upper bound (C1+1) or no improvement occurs in the current search. Therefore, the search will be repeated at most C1 times. In step 3, at most 1000 best sequences [starting from n0 = max(0, n-1001)] among n sequences obtained from step 2 are selected and improved by the second local search. This local search is based on the shift neighborhood. The value of n may be very large and the memory error may be occurred, because the program should store n sequences. To prevent this error, we can consider an upper bound (say UP) for n by adding the following condition before the statement n = n+1:
If n = UP, then n = 0
The second local search continues until counter reaches to its upper bound (C2+1) or no improvement occurs in the current search.
COMPUTATIONAL EXPERIMENTS
Here, we describe the computational experiments used in order to evaluate the effectiveness of the proposed metaheuristic method. The programs have been coded in C++. The platform of our experiments is a personal computer with a Pentium-IV 1700 MHZ CPU and 512 MB RAM. The maximum number of ants for each problem, is 10000 and maximum running time of ACO algorithm for each problem is I(K/2)90 m sec (Vallada and Ruiz, 2008). The maximum running time of non-permutation local search is set to 10 sec for all problems. We have also considered C1 = C2 = 50 for consideration of the computational time. To compare the solutions of the proposed method with some other methods, we have used the standard benchmark problems of Taillard (1993). We have compared our solutions with the solutions of two recent works which are Rajendran and Hans (2004) and Vallada and Ruben (2008). The numerical results are shown in Table 1-3. We have reported both of the permutation solutions obtained from the ACO algorithm (in the column of PRMUT in the Table) and the non-permutation solutions obtained from the non-permutation local search (in the column of NONPRMUT in the Tables).
| Table 1: | The results of the computational experiments for the objective of makespan |
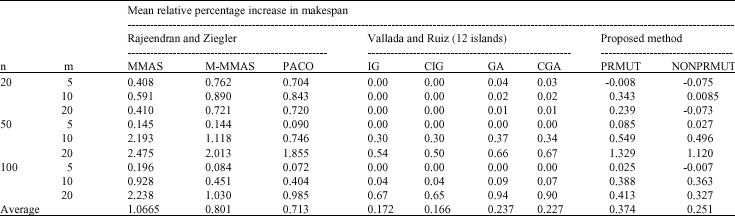 | |
| Table 2: | The results of the computational experiments for the objective of total flowtime |
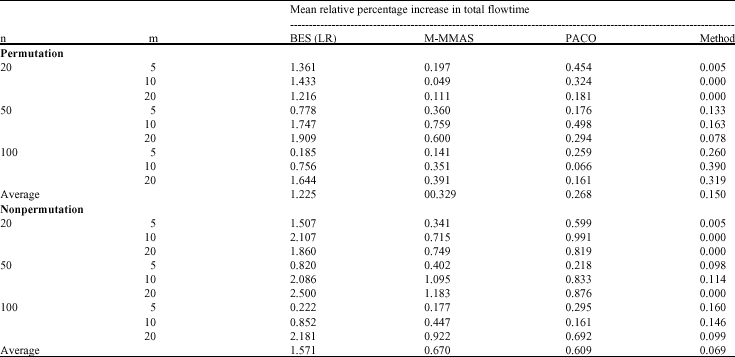 | |
| Table 3: | The results of the computational experiments for the objective of the total flowtime (end solutions) |
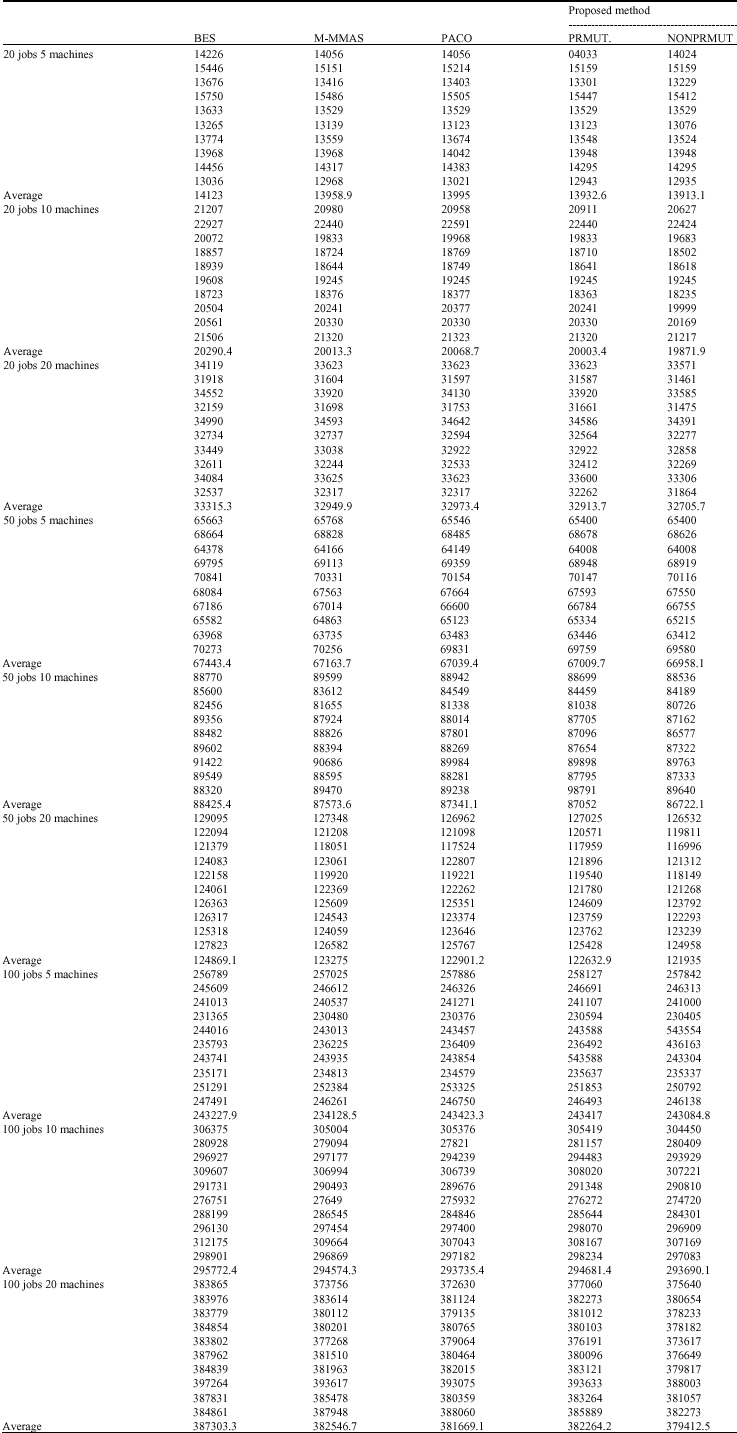 | |
To calculate the mean relative percentage increase in total flowtime, shown in Table 2, we have considered the best solution among those of four methods (BES), (LR), M-MMAS, PACO and our method) as the best upper bound for the corresponding problem. From the results, it can be seen that the proposed ant colony method demonstrates better performance than the other methods for both objectives.
CONCLUSION
In this study, we have developed an effective ACO algorithm to solve the permutation flowshop scheduling problem. The permutation solutions of this ACO algorithm are then improved by a non-permutation local search. Numerical experiments have been designed and performed to demonstrate the potential applicability of the proposed method. The results have shown that the proposed metaheuristic algorithm is clearly superior to the other proposed metaheuristics.
REFERENCES
- Allahverdi, A., 2003. The two-and m-machine flowshop scheduling problems with bicriteria of makespan and mean flowtime. Eur. J. Operat. Res., 147: 373-396.
CrossRefDirect Link - Cheng, T.C.E., J.N.D. Gupta and W. Guoqing, 2000. A review of flowshop scheduling research with setup times. Prod. Operat. Manage., 9: 262-282.
Direct Link - Jain, A.S. and S. Meeran, 2002. A multi-level hybrid framework applied to the general flow-shop scheduling problem. Comput. Operat. Res., 29: 1873-1901.
CrossRefDirect Link - Koulamas, C., 1998. A new constructive heuristic for the flowshop scheduling problem. Eur. J. Operat. Res., 105: 66-71.
CrossRefDirect Link - Liao, C.J., L.M. Liao and C.T. Tseng, 2006. A performance evaluation of permutation vs. non-permutation schedules in a flowshop. Int. J. Prod. Res., 44: 4297-4309.
CrossRefDirect Link - Nawaz, M., E.E. Enscore Jr. and I. Ham, 1983. A heuristic algorithm for the m-machine, n-job flowshop sequencing problem. Omega, 11: 91-95.
CrossRefDirect Link - Osman, I. and C. Potts, 1989. Simulated annealing for permutation flowshop scheduling. Omega, 17: 551-557.
CrossRefDirect Link - Pugazhendhi, S., S. Thiagarajan, C. Rajendran and N. Anantharaman, 2002. Anantharaman performance enhancement by using nonpermutation schedules in flowline-based manufacturing systems. Comput. Ind. Eng., 44: 133-157.
CrossRefDirect Link - Rajendran, R.C. and Z. Hans, 2004. Ant-colony algorithms for permutation flowshop scheduling to minimize makespan/total flowtime of jobs. Eur. J. Operat. Res., 155: 426-438.
CrossRefDirect Link - Ruiz, R. and M. Concepcion, 2005. A comprehensive review and evaluation of permutation flowshop heuristics. Eur. J. Operat. Res., 165: 479-494.
CrossRefDirect Link - Taillard, E., 1993. Benchmarks for basic scheduling problems. Eur. J. Operat. Res., 47: 278-285.
CrossRefDirect Link - Vallada, E. and R. Ruben, 2008. Cooperative metaheuristics for the permutation flowshop scheduling problem. Eur. J. Operat. Res.
CrossRefDirect Link - Varadharajan, T.K. and R. Chandrasekharan, 2005. A multi-objective simulated-annealing algorithm for scheduling in flowshops to minimize the makespan and total flowtime of jobs. Eur. J. Operat. Res., 167: 772-795.
CrossRefDirect Link - Woo, H.S. and D.S. Yim, 1998. A heuristic algorithm for mean flowtime objective in flowshop scheduling. Comput. Operat. Res., 25: 175-182.
CrossRefDirect Link