
P. Haghighat Jou
Department of Hydrology and Water Resources, Faculty of Water Sciences Engineering, Shahid Chamran University, Ahwaz, Iran
A.M. Akhoond-Ali
Faculty of Water Sciences Engineering, Shahid Chamran University, Ahwaz, Iran
A. Behnia
Faculty of Water Sciences Engineering, Shahid Chamran University, Ahwaz, Iran
R. Chinipardaz
Department of Statistics, Faculty of Mathematical Sciences and Computer, Shahid Chamran University, Ahwaz, Iran
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 18 | Page No.: 3242-3248







ABSTRACT
This study is devoted to compare the goodness of fitting of the monthly precipitation for five old raingauge stations (Bushehr, Isfahan, Meshed, Tehran and Jask) in Iran using parametric and nonparametric methods. The parametric methods include normal, two and three parameter log-normal, two parameter gamma, Pearson and log-Pearson type III and Gumbel extreme value type I distributions. The nonparametric approach is Gaussian (normal) kernel function. The smoothing parameter were calculated by four methods including rule of thumb, Adamowski criterion, least squares cross-validation and Sheater and Jones plug-in. Results from the least squares cross-validation were better comparing to other methods due to goodness of fit tests applied in this study. The results of this study showed that the monthly precipitation data fitted to the parametric methods much better than nonparametric method.
PDF Abstract XML References Citation
How to cite this article
P. Haghighat Jou, A.M. Akhoond-Ali, A. Behnia and R. Chinipardaz, 2008. Parametric and Nonparametric Frequency Analysis of Monthly Precipitation in Iran. Journal of Applied Sciences, 8: 3242-3248.
DOI: 10.3923/jas.2008.3242.3248
URL: https://scialert.net/abstract/?doi=jas.2008.3242.3248
DOI: 10.3923/jas.2008.3242.3248
URL: https://scialert.net/abstract/?doi=jas.2008.3242.3248
INTRODUCTION
The estimation of monthly precipitation is essential in the water resources and water supply planning, irrigation and drainage system design, in agriculture, crop water requirements and monitoring climate change. Precipitation in Iran is mostly occurred between November and April, with annual mean equal to 250 mm. The climate of Iran is arid and semi-arid. Precipitation frequency analysis is generally carried out using parametric methods in which a statistical distribution such as normal (N), two parameter log-normal (LN2), three parameter log-normal (LN3), two parameter gamma (G2), Pearson type III (P3), log-Pearson type III (LP3) and Gumbel extreme value type I (G) are used to fit the available data for frequency analysis and estimation of rare events. These methods have been successfully applied in many cases, but have some disadvantages because of not fitting to the observed data very well, or diverting from the extreme tails. Some other conditions that may cause problems with parametric methods are involved in difficulties of estimation of the best parameters for these approaches particularly for skewed data.
To estimate the probability density function and distribution function of hydrologic events, several nonparametric methods such as variable kernel method (Lall et al., 1993) have been introduced in recent years. Guo (1991) proposed a nonparametric variable kernel estimation model which provides an alternative way in flood quantile estimation when historical floods data are available. It is shown that the nonparametric kernel estimator fitted the real data points closer than its parametric counterparts. Gingras and Adamowski (1992) applied both L-moments and nonparametric frequency analysis on the annual maximum floods. By coupling nonparametric frequency analysis with L-moment analysis, it is possible to confirm the L-moment selection of unimodal distribution, or to determine that the sample is actually from a mixed distribution. Thus, the nonparametric method helps to identify the underlying probability distribution, particularly when samples arise from a mixed distribution. Moon et al. (1993) compared selected techniques for estimating exceedance frequencies of annual maximum flood events at a gaged site. They applied four tail probability and a variable kernel distribution function estimators and concluded that the variable kernel estimator appears useful because it automatically gives stable and accurate flood frequency estimates without requiring a distributional assumption. Adamowski (1996) developed a nonparametric method for low-flow frequency analysis and compared with two commonly used parametric methods, namely, log-Pearson Type III and Weibull distributions. The numerical analysis indicates that the nonparametric method better fits the data and gives more accurate results than currently used parametric methods. Adamowski (2000) applied a Gaussian (normal) kernel function for regional analysis of annual maximum (AM) and partial duration (PD) flood data by nonparametric and L-moment methods. The results pointed out deficiencies in currently used parametric approaches for both AM and PD series, since traditional regional flood frequency analysis procedures assume that all floods within a homogeneous region are generated by the same, often unimodal distribution, while this is not always true and the data series may be multimodal. Also, Kim and Heo (2002) employed this nonparametric Gaussian (normal) kernel function, however for their comparative study of flood quantiles estimation by applying seven bandwidth selectors of Rule of thumb (ROT), Least squares cross-validation (LSCV), Jones, Marron and Park cross-validation (JMP), Smoothed cross-validation (SCV), Biased cross-validation (BCV), Park and Marron plug-in (PM) and Sheater and Jones plug-in (SJ). They concluded that among seven bandwidth selectors, the relative biases of SJ were the smallest in most cases. Faucher et al. (2002) compared the performance of parametric and nonparametric methods in estimation of flood quantiles. The log-Pearson type III, two parameter lognormal and generalized extreme value distributions were used to fit the simulated samples. It was found that nonparametric methods perform quite similarly to the parametric methods. They compared six different kernel functions include biweight, normal, Epanechnikov, extreme value type I, rectangular and Cauchy. They found no major differences between the first four above mentioned kernels. Behnia and Jou (2007) applied Fourier series to estimate annual flood probability of the Great Karoun river flowing southwest of Iran. Then, the predicted results from the application of this method were compared to results of seven parametric methods include normal, two and three parameter log- normal, two parameter gamma, Pearson and log-Pearson type III and Gumbel extreme value type I distributions. Results of this comparison showed a better ability for Fourier series method. Karmakar and Simonovic (2008) used nonparametric methods based on kernel density estimation and orthonormal series to determine the nonparametric distribution functions for peak flow, volume and duration. They selected the subset of the Fourier series consisting of cosine functions as orthonormal series. They found that nonparametric method based on orthonormal series is more appropriate than kernel estimation for determining marginal distributions of flood characteristics as it can estimate the probability distribution function over the whole range of possible values.
In the current study a Gaussian (normal) kernel function is performed on a series of monthly precipitation from five old raingauge stations in Iran. Results of the performance of this proposed nonparametric method will be then compared to the seven above mentioned parametric treatments to illustrate which method fit better to the data.
MATERIALS AND METHODS
This study was started from October 2007 at the Department of Hydrology and Water Resources, Faculty of Water Sciences Engineering, Shahid Chamran University, Ahwaz, Iran.
Sources of precipitation over Iran: There are five distinct sources of precipitation over Iran which includes westerly winds blowing from Mediterranean Sea, southwesterly winds flow from the Horn of Africa and northern winds which flow from Siberia. These winds produce rainfall on northwestern, western and southwestern parts of the country in winter. Southeasterly Monsoon winds blowing from Indian Ocean, which produce scanty and scattered rainfalls on southeast in summer and northerly winds blowing from Caspian sea which only produce relatively heavy rainfall on littoral provinces i.e., Gilan, Mazandaran and Golestan throughout the year.
Sources of data: The monthly precipitation data from five old raingauge stations in Iran were selected to be analyzed. These stations include Bushehr, Isfahan, Meshed, Tehran and Jask. Figure 1 shows geographical location of the stations on the map of Iran. There are many Synoptic and Meteorological stations in Iran, but the mentioned stations were selected because they have long length records. The record lengths of these stations range between 84 to 113 years. The data were collected from two sources including World Weather Records and Meteorological year books of Iran which are published by Iranian Meteorological Organization. Data up to year 1960 were collected from the first source and the rest of them up to year 2004 were collected from the second source. The sample sizes of data and date of establishment for each of the stations are given in Table 1 and the geographical characteristics of the stations are shown in Table 2.
| Table 1: | The sample sizes and date of establishment of stations |
| Table 2: | Geographical characteristics of the stations |
 | |
 | |
| Fig. 1: | Geographical location of rain gauge stations on the map of Iran |
| Table 3: | Mean monthly precipitation (mm) for the old stations |
 | |
The statistical characteristics of monthly precipitation data for the 5 stations are shown in Table 3 to be used in proposed methods.
A description of the distributions and parameter estimation methods are not presented in this study, because they are available in other publications such as (Kite, 1988; Haan, 1977; Rao and Hamed, 1999). Therefore, only nonparametric kernel density function estimation is described here.
The kernel method: In the kernel method, a function k(x) is associated with each observation in a sample. The main requirement to k is:
(1) |
The nonparametric density function is constructed from the set of kernels as:
(2) |
where, n is the sample size, k is the kernel function and h is a parameter that determines the degree of smoothing and is called bandwidth or smoothing parameter. The kernel may be interpreted as a weight function that represents the weight of each observation in the estimation of the density at x. The kernel distribution function is the integration of the density function (Eq. 2) as:
(3) |
Where:
(4) |
The kernel distribution function may serve to estimate quantiles corresponding to a given probability of exceedance. For example, in the hydrological context, one may be interested in determining the flood with a return period of T years, that is:
(5) |
where, F-1 represents the inverse of distribution function, F. In practice the value of x must be determined by solving Eq. 5 numerically.
In principle, all classical probability density functions like the Gaussian (normal) or the Cauchy distributions are candidates for kernel functions. Other types of functions subject to certain constraints could also be considered. Some authors have argued that the kernel choice is not critical compared to the choice of smoothing parameter.
In this study, a Gaussian or normal kernel (Gingras and Adamowski, 1992) has been used and is given by:
(6) |
Choosing the smoothing parameter: The problem of choosing the value of smoothing parameter is of crucial in density estimation. One strategy for selecting the smoothing parameter is to begin with a large bandwidth and to decrease the amount of smoothing until the fluctuations start to appear. Too large an h value will lead to a unimodal nonparametric density regardless of the multimodality of the data while too small one will lead to distorted multimodal density shape regardless of the unimodality of the data. This approach is viable but there are also many cases where it is beneficial to have the bandwidth automatically selected from the data. In this study, four bandwidth selectors such as rule of thumb (ROT), Adamowski criterion (AC), least squares cross-validation (LSCV), Sheater and Jones plug-in (SJ) are employed. The optimal bandwidth for a kernel density estimate is typically calculated based on an estimate for the integrated square error (ISE) as follow:
(7) |
And its expected value, the MISE is given by:
(8) |
(9) |
where, the first integral is integrated variance (IV) and the second integral is integrated squared bias (IB). Hence the optimal bandwidths depend on the unknown density for deriving of f.
Rule of thumb: The ROT was proposed to minimize the asymptotic mean integrated square error (AMISE) (Silverman, 1986). The best trade-off between asymptotic variance and bias is given by:
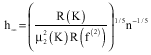 | (10) |
where, h is the minimizer of the AMISE and R(f(2)) is the only unknown. Assuming the unknown distribution to be normal with parameter μ (population mean) and σ (standard deviation of values), the estimate of h– for a Gaussian kernel was done as:
(11) |
The advantage of ROT is that it provides a very practical method of bandwidth selection while the disadvantage is that the bandwidth is wrong if the population is not normally distributed.
Adamowski criterion for bandwidth selection: Adamowski (1989) proposed the following formula for computing the smoothing parameter
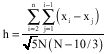 | (12) |
where, xi and xj are order statistics of observation and N is sample size.
Least square cross-validation: The Least square cross-validation function is defined by Rudemo (1982) and Bowman (1985) as:
(13) |
where, ![]() is the density estimate based on the entire data set except for the ith observation.
is the density estimate based on the entire data set except for the ith observation.
Sheater and Jones plug-in: Sheater and Jones (1991) reconsidered the problem of estimating R(f(2)). They used the same idea as Park and Marron (1990) but with bandwidth as follow:
(14) |
where, R(f(2)) and R(f(3)) can be estimated by ![]() and
and ![]() and both bandwidth g1 and g2 are determined by asymptotic optimal values and only in this step the normal probable density function (PDF) is used as a reference probability model. This improves the method of Park and Marron (1990) but is not the best achievable rate yet. In this study for comparison of the parametric and nonparametric methods, the mean relative deviation (MRD) and the mean square relative deviation (MSRD) were used to measure the goodness of fit of above mentioned methods, these statistical terms are defined as follows:
and both bandwidth g1 and g2 are determined by asymptotic optimal values and only in this step the normal probable density function (PDF) is used as a reference probability model. This improves the method of Park and Marron (1990) but is not the best achievable rate yet. In this study for comparison of the parametric and nonparametric methods, the mean relative deviation (MRD) and the mean square relative deviation (MSRD) were used to measure the goodness of fit of above mentioned methods, these statistical terms are defined as follows:
(15) |
(16) |
where, x and ![]() are the observed and calculated monthly precipitation and n is sample size. In addition, observed and estimated data will be compared graphically as well.
are the observed and calculated monthly precipitation and n is sample size. In addition, observed and estimated data will be compared graphically as well.
Data analysis: One of the most common characteristics of the monthly precipitation data from the mentioned raingauge stations is the character of their positive skewness. Histogram of January precipitation for Boushehr station during 114 years is shown in Fig. 2 as an example.
Monthly precipitation data from five old raingauge stations in Iran were fitted to the mentioned parametric and nonparametric methods to compare the performance results of these various approaches.
For analysis of data by the nonparametric kernel function, the values of smoothing parameter (h) for all months and all stations were calculated by the mentioned four methods explained in the previous section at which the LSCV method resulted in the minimum values for this parameter. Therefore, the results of this method were selected to calculate MRD and MSRD values for analysis of data by the nonparametric kernel function. Table 4 shows all of the smoothing parameter (h) values for Boushehr station as an example and the selected minimum values resulted from LSCV method are shown in Table 5-9 under the parameter h for Boushehr, Isfahan, Meshed, Tehran and Jask stations respectively to be used for calculation of MRD and MSRD for kernel function.
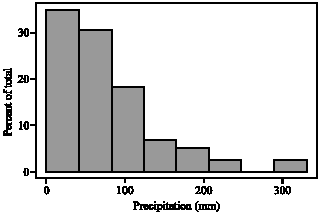 | |
| Fig. 2: | Histogram of January precipitation over Boushehr station during 114 years showing its positive skewness |
| Table 4: | Values of smoothing parameter, h for various months resulted from various bandwidth selector methods for Boushehr station |
 | |
| Table 5: | Values of MRD and MSRD for best parametric method and nonparametric normal kernel for Boushehr station |
 | |
| Table 6: | Values of MRD and MSRD for best parametric method and nonparametric normal kernel for Isfahan station |
 | |
| Table 7: | Values of MRD and MSRD for best parametric method and nonparametric normal kernel for Meshed station |
 | |
| Table 8: | Values of MRD and MSRD for best parametric method and nonparametric normal kernel for Tehran station |
 | |
| Table 9: | Values of MRD and MSRD for best parametric method and nonparametric normal kernel for Jask station |
 | |
For analysis of data by the parametric methods first, their parameters were calculated by both the methods of moments and maximum likelihood procedure then, MRD and MSRD were calculated for all months and all stations. HYFA program was used for all calculations. Table 5 through Table 9 shows the minimum values of MRD and MSRD for the best parametric methods (which are the methods with lowest MRD and MSRD values).
RESULTS AND DISCUSSION
According to Table 4 and comparing the values of smoothing parameter calculated from four methods, i.e., ROT, AC, LSCV, SJ for Boushehr station, it is evident that the least values of bandwith results obtained by LSCV evolve the least values of MRD and MSRD. Also, the results for other stations in all months are similar to Boushehr. In general, for all stations, in 82.7%, the least values of bandwidth resulted from LSCV method, in 15.4% resulted from AC and in 1.9% resulted from SJ. These results differ from the results of Kim and Heo (2002) because they obtained the smallest values of the relative bias for SJ smoothing parameter in most cases as mentioned in the introduction. However, it should be mentioned that their conclusion was for flood quantiles estimation not for precipitation.
Due to the positive skewness character of monthly precipitation data for all raingauge stations (see Fig. 2 as an example) and regarding to the Table 5-9 and comparing the values of MRD and MSRD for all methods, the best fitted distributions to the data obtained. In accordance to this comparison, log-pearson type III in 61.5% of cases, two parameter gamma in 25% of cases and three parameter log-normal in 13.5% of cases resulted the first three best fitness to the data. Other approaches including normal, two parameter log-normal, Pearson type III, Gumbel extreme value type I and Gaussian (normal) kernel function could not fit the data. In all cases the values of MRD and MSRD for parametric methods are lower than the tabulated values for the nonparametric normal kernel and hence the latter method is not a good approach for frequency analysis of monthly precipitation in Iran.
CONCLUSION
One of the most common characteristics of the monthly precipitation in Iran is the character of positive skewness. In general, for all stations, the least values of the smoothing parameter (h) or bandwidth resulted from LSCV method (in 82.7%). However, comparing the values of MRD and MSRD for parametric methods and non parametric normal kernel function concluded that the best approach to give the best fitness to the data is log-pearson type III. These results obtained from the long length periods of monthly precipitation for the first time in the country and therefore, are the unique findings of this study.
REFERENCES
- Adamowski, K., 1989. A monte carlo comparison of parametric and nonparametric estimation of flood frequencies. J. Hydrol., 108: 295-308.
CrossRefDirect Link - Adamowski, K., 1996. Nonparametric estimation of low-flow frequencies. J. Hydraulic Eng., 122: 46-50.
CrossRefDirect Link - Adamowski, K., 2000. Regional analysis of annual maximum and partial duration flood data by nonparametric and L-moment methods. J. Hydrol., 229: 219-231.
CrossRef - Behnia, A.K. and P.H. Jou, 2007. Estimating Karoun annual flood probabilities using fourier series method. Proceeding of the 7th International River Engineering Conference, February 13-15, 2007, Shahid Chamran University, Ahwaz, Iran, pp: 1-7.
Direct Link - Bowman, A., 1985. A Comparative study of some Kernel-based nonparametric density estimators. J. Stat. Comput. Simulat., 21: 313-327.
CrossRefDirect Link - Faucher, D., P.F. Rasmussen and B. Bobee, 2002. Nonparametric estimation of quantiles by the kernel method (In French). J. Water Sci., 15: 515-541.
Direct Link - Gingras, D. and K. Adamowski, 1992. Coupling of nonparametric frequency and L-moment analyses for mixed distribution identification. J. Am. Water Resourc. Associat., 28: 263-272.
Direct Link - Guo, S.L., 1991. Nonparametric variable kernel estimation with historical floods and paleoflood information. Water Resourc. Res., 27: 91-98.
CrossRefDirect Link - Haan, C.T., 1977. Statistical Methods in Hydrology. 1st Edn., Iowa State University Press, Ames. Iowa, ISBN: 0-8138-1510-X, pp: 378.
Direct Link - Karmakar, S. and S.P. Simonovic, 2008. Bivariate flood frequency analysis using copula with parametric and nonparametric marginals. Proceedings of the 4th International Symposium on Flood Defence: Managing Flood Risk, Reliability and Vulnerability, May 6-8, 2008, Toronto, Ontario, Canada, pp: 1-50.
Direct Link - Kim, K.D. and J.H. Heo, 2002. Comparative study of flood quantiles estimation by nonparametric models. J. Hydrol., 260: 176-193.
CrossRef - Lall, U., Y.I. Moon and K. Bosworth, 1993. Kernel flood frequency estimators: Bandwidth selection and Kernel choice. Water Resourc. Res., 29: 1003-1016.
CrossRefDirect Link - Moon, Y.I., U. Lall and K. Bosworth, 1993. A comparison of tail probability estimators for flood frequency analysis. J. Hydrol., 151: 343-363.
CrossRefDirect Link - Park, B.U. and J.S. Marron, 1990. Comparison of data driven bandwidth selectors. J. Am. Statist. Assoc., 85: 66-72.
Direct Link - Rudemo, M., 1982. Empirical choice of histograms and kernel density estimators. Scandinavian J. Stat., 9: 65-78.
Direct Link - Sheater, S.J. and M.C. Jones, 1991. A reliable data-based bandwidth selection method for kernel density estimation. J. Royal Stat. Soc. Series B (Methodological), 53: 683-690.
Direct Link - Silverman, B.W., 1986. Density Estimation for Statistics and Data Analysis. 1st Edn., Chapman and Hall, London, ISBN: 0-412-24620-1.
Direct Link