
Fatemeh Afghah
Department of Electrical Engineering, KN Toosi University of Technology, P.O. Box 16315-1355, Tehran, Iran
Mehrdad Ardebilipour
Department of Electrical Engineering, KN Toosi University of Technology, P.O. Box 16315-1355, Tehran, Iran
Abolfazl Razi
Department of Electrical Engineering, KN Toosi University of Technology, P.O. Box 16315-1355, Tehran, Iran
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 16 | Page No.: 2867-2873







ABSTRACT
In this study, we investigate a new method for turbo codes which is dividing turbo encoder and decoder into several parallel coding and decoding blocks. These blocks work simultaneously and yield to much faster coding scheme in comparison with classical turbo codes. We compare simulation results of these new turbo codes with classical turbo codes to demonstrate that their performance is comparable with classical turbo codes, albeit they are much faster. Also, we introduce a new system by concatenating this fast turbo coding as outer code with Alamouti`s G2 space-time block coding scheme as inner code to achieve the benefits of both techniques including acceptable diversity and coding gain as well as short coding delay. We consider the performance of this new system in the block Rayleigh fading channel.
PDF Abstract XML References Citation
How to cite this article
Fatemeh Afghah, Mehrdad Ardebilipour and Abolfazl Razi, 2008. Fast Turbo Codes Concatenated With Space-Time Block Codes. Journal of Applied Sciences, 8: 2867-2873.
DOI: 10.3923/jas.2008.2867.2873
URL: https://scialert.net/abstract/?doi=jas.2008.2867.2873
DOI: 10.3923/jas.2008.2867.2873
URL: https://scialert.net/abstract/?doi=jas.2008.2867.2873
INTRODUCTION
Turbo codes that provide near Shannon capacity performance were introduced by Berrou et al. (1993). This astonishing finding attracted many other researchers to follow this issue and further investigations. The main idea of the brilliant performance of turbo codes is iterative decoding technique that causes these codes to be practically implemented as they maintain their alluring performance. Despite of the acceptable complexity and good performance of these codes, decoding delay is a major obstacle of using turbo codes in real time applications; so finding appropriate techniques to reduce the decoding time of turbo codes has become the subject of many researches. Most of them concentrated on some approximations in mathematical calculations of decoding process without any change in decoder structure.
Another approach to reduce the decoding delay is parallel functioning of two Soft-Input Soft-Output (SISO) decoders in turbo decoder (Wang et al., 2005) because, in classical turbo decoder, while the first SISO decoder is working, the second waits for the result of the first one and so whenever one of them stops working, the other one starts to work, using the result of the other. In other words, in all instances just one of the SISO decoder works, therefore if these two SISO decoders work in parallel, the decoding time will be halved.
Another interesting technique is dividing each Recursive Systematic Convolutional (RSC) encoder/ decoder into some similar RSC encoders/decoders, which work in parallel. For this purpose, in each main branch of turbo encoder, the input data frame is divided into several sub frames that each of them is fed to one RSC encoder, all the encoders work simultaneously and the resulted codes are composed to make the RSC encoded frame. This method is done in both main branches of turbo encoder, also the same method is adopted by turbo decoder, we name this solution as multi-branch fast turbo coding that replaces each main RSC encoder/decoder with several parallel RSC encoder/decoders. This method is proposed by Gazi and Yilmaz (2007) and is investigated in AWGN channel to reduce the decoding time.
We applied this technique in turbo codes and concatenated this fast turbo codes with Space-Time Block Codes (STBC) to overcome Rayleigh fading effect of multipath mobile channels.
Afghah et al. (2008) demonstrated that the decoding delay has a direct proportion with the frame length, so long frame length in practical applications, causes long delay which is not acceptable in many cases; therefore in this study, we examine this fast turbo codes in the practical situation like fast and slow fading channels. As mentioned above our proposed system is concatenation of described fast turbo codes with Orthogonal Space-Time Block Codes (OSTBC) that uses the benefits of both codes; so this system has acceptable diversity gain, by using space-time coding and sufficient coding gain and short decoding latency, by using fast turbo codes.
SYSTEM MODEL
The system model is showed in Fig. 1.
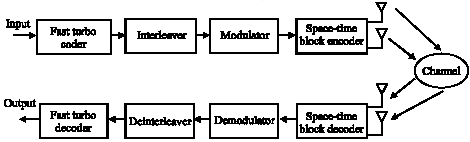 | |
| Fig. 1: | Block diagram of system for 2x2 MIMO channel |
In this system, at the first stage, randomly generated input bits are coded by fast turbo encoder, then these codes are passed through pseudorandom interleaver block to make them strong enough in the presence of burst error and then are mapped into complex symbols by constellation rule to make them ready to broadcast over radio channel by carrier frequency, we simulate the most common type of modulations such as BPSK, QPSK and 16 QAM. These complex symbols are passed to Alamouti`s G2 space-time block encoder to obtain diversity gain and combat multipath propagation fading effects, each two consequent complex symbols are transmitted via two transmitter antennas in two consecutive instances.
At the receiver, the noisy complex signals of two receiver antennas are passed to STB decoder which work based on MAP algorithm; then the soft output results of STB decoder which are logarithmic probability of complex symbols are converted into LLR (Logarithmic Likelihood Ratio) of code bits by taking into consideration the constellation mapping rule and fed to fast turbo decoder to estimate most probable input bits. The details of STB decoder and fast turbo decoder operation are described in next sections.
CLASSICAL TURBO CODES
Classical turbo encoder consist of two or more parallel RSC encoder (Berrou et al., 1993), which are connected with an interleaver; in this encoder the input data bits are fed into first RSC encoder and also after permutation by a random interleaver, are fed to the second RSC encoder. The output bits of two RSC encoders which are mixture of systematic and parity bits are arranged serially and then are punctured to achieve desirable coding rate, usually the systematic bits of one RSC encoder with the selection of parity bits of all RSC encoders with predefined pattern are selected as the output of turbo encoder. In this case, it is selected the odd numbers of first RSC parity bits and even numbers of second RSC encoder in addition to systematic bits, so this turbo code`s rate is ½.
The idea of turbo decoder`s structure was inspired from the encoder configuration and adopting iterative decoding. Turbo decoder is composed of two SISO decoders, which work in parallel. Each SISO decoder can employ wide category of decoding algorithm, most of them are based on MAP algorithm, such as MAP (Bahl et al., 1974), Log-MAP (Robertson et al., 1995), Max-Log-MAP (Erfanian et al., 1994), the other important option is SOVA which is Soft output Viterbi algorithm (Hagenauer and Hoeher, 1989). In this study, we use Log-MAP algorithm because of good quality and acceptable complexity. As mentioned earlier, in Log-MAP decoding algorithm, the received coded frame is fed to the first SISO decoder, in the format of soft bits e.g., LLR, the first decoder analyzes these data and estimates the original systematic bits and then subtract the apriori information from the resulted output bits to form the extrinsic information, which are feed to the other decoder. The second decoder applies the received soft information from the channel and extrinsic information of the other decoder in order to compute the new LLRs and send extrinsic part of them to the first decoder; this cycle is repeated again and again until there is no noticeable change in the soft output or the number of cycles reaches to the predefined limit. Iterative decoding method is lead to a good performance with acceptable level of complexity; but it causes long delay in turbo decoding, because of its iterative nature, Afghah et al. (2008) demonstrate that the latency of turbo decoding has a direct ratio with frame length, so delay of turbo decoding is more considerable for long frames which are used in practical applications.
Turbo decoder consist of several blocks including SISO decoders, interleaver and deinterleaver and so on, but the majority of mathematical calculation is being done in SISO decoders, so we survey the delay time of each SISO decoder which is based on Log-MAP algorithm. Log-MAP is used by applying logarithmic calculation in MAP algorithm to replace product operations by sum operation in order to reduce complexity without notable decrease in performance. In this method the soft info is presented in the format of conditional LLR, which is defined in (1), where uk is systematic transmitted bit in time interval k and![]() is received sequence from channel.
is received sequence from channel.
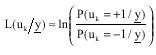 | (1) |
Sign of the LLR determines whether 0 or 1 is more probable for being the transmitted bit and the absolute value of LLR shows the certainty of this decision. In this algorithm the final purpose is calculating the LLR for each systematic bit uk by considering the received sequence; Eq. 1 can be stated as (Robertson et al., 1995):
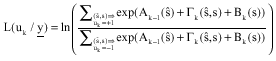 | (2) |
where, Ak−1(Ŝ) is logarithm of the probability that trellis diagram is in state Ŝat time k−1, while the received channel sequence up to this point is yj (j<k) and Bk(s) is logarithm of the probability that future received channel sequence will be yj(j>k), given the trellis is in state s at time k, these parameters is calculated from recursive Equation as in (3, 4).
(3) |
(4) |
Also Γk(Ŝ, s) is the logarithm of the prob ability that received channel sequence for this transition is yk and the transition moves to state s at time k, given the trellis was in state Ŝat time k−1 and is calculated according to Eq. 5:
(5) |
where, C is constant and is obtained from (6).
(6) |
Since in each iteration, these parameters (Ak−1(Ŝ), Bk(s) and Γk(Ŝ,s)) is calculated for each systematic transmitted bit, the required time is in direct proportion with the frame length of data, Afghah et al. (2008) calculate the exact number of operations which is needed for each iteration. This is the inspiration of our study, in this technique, we divide the main frame into some sub frames, in order to decrease the frame length, which is fed to SISO decoders and by adopting parallel processing, we decrease decoding latency without noticeable degradation in performance.
FAST TURBO CODE
Fast turbo coding is one of the best solutions to overcome decoding delay time of turbo codes.
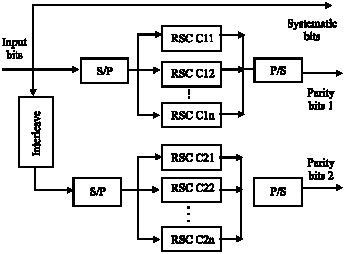 | |
| Fig. 2: | Fast turbo encoder with n sub branches |
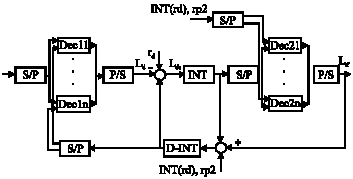 | |
| Fig. 3: | Fast turbo decoder with n sub branches |
In this technique each RSC encoder/decoder is divided into some encoders/decoders with the same properties, which we call them sub branches or sub encoders/decoders, these sub blocks can work simultaneity, therefore by dividing long frames between these parallel branches, encoding and decoding time can be scaled down to reverse of branches number. This issue can be obtained from Fig. 2 and 3, which show block diagram of multi-branches encoder and decoder of fast turbo codes with n sub branches.
As Fig. 2 shows each RSC coder is divided to n similar sub branches, so the data frame is passed to Serial to Parallel(S/P) converter and divided to n parts, then each of these sub frames is fed to one sub branch. After coding, the output of these branches is delivered to Parallel to Serial (P/S) converter to make a single RSC coded frame, then it`s sent to puncturing block to generate the final output of turbo encoder. Also in decoder, each SISO decoder is divided to n sub decoders and each sub decoder operates on one part of received frame. As it was proved in previous section, the decoding time in each SISO decoder has direct proportion with frame length, so the decoding time of each of these sub branches is reduced to 1/n and since they have their own input which are independent from each other, they can function in parallel, so the whole decoding time for SISO decoding in each main branch that is composed of several sub branches is scaled down to 1/n.
ORTHOGONAL SPACE-TIME BLOCK CODES
One of the most significant limitations to increase the data rate and reliability of transmission in wireless communication systems is multipath propagation that causes time varying fading because of destructive superposition of delayed received signals; so finding a suitable technique to reduce this effect is very important.One appropriate solution is to decrease fading effect by adopting diversity techniques including frequency diversity, time diversity, spatial diversity and so on.
Space-time coding benefits of both time and space diversity and includes two main categories: Space-Time Trellis Coding (STTC) (Tarokh et al., 1998) and Space-Time Block Coding (STBC) (Tarokh et al., 1999a, b), STBC is more practical and have easier structure, STTC is generally used to obtain both coding and diversity gain but in our case whereas we get coding gain from turbo codes, we use STB codes because of simple decoding algorithm to concatenate with turbo Codes (Hanzo et al., 2002; Agrawai et al., 1998; Lu et al., 2002; Bauch, 1999).
Here, we describe orthogonal space-time block coding for Alamouti G2 system (Alamouti, 1998) and explain symbol by symbol MAP decoding algorithm which results desirable soft output for applying in fast turbo decoder (Bauch, 1999). The model of the STBC over MIMO Rayliegh fading channel is showed in Fig. 4.
If bi, i = 1,..., n are the interleaved output bits of channel coder (e.g., turbo coder in our case), in the first step they are mapped to codes denoted by c1, ..., cK, where ci ε [0, 1, ..., M−1] and M is the number of modulation symbols and K = n/log2M, then each code is mapped to complex symbol is denoted by x1,..., xk according to constellation mapping rule.
Then these complex symbols are fed to Alamouti`s G2 space-time coder. According to Alamouti`s scheme, each two subsequent symbols s1, s2 are transmitted via two antennas based on the following matrix with orthogonal columns:
(7) |
The row number is denoted by P defines time of transmission and the column number defines transmitter antenna.
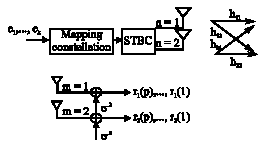 | |
| Fig. 4: | Space-time block coder over Rayleigh flat fading channel with 2 transmitter and 2 receiver antennas |
In other words, the symbols of each row are transmitted simultaneously from two antennas and then passed through 2x2 MIMO system with Rayleigh flat fading and AWGN noise with a two-sided spectral power density of σ2 - N0/2.
In the receiver, the received signal r is composed from the transmitted signals as following:
(8) |
where, rm(t) is the received signal from mth receiver antenna in instant t and H is channel matrix with hij entries, that hij denotes fading channel coefficient between ith transmitter antenna and jth receiver antenna and nm(t) is the Gaussian distributed noise in time t at receiver m.
The following part describes the soft output decoder for space-time block codes and represents its equations, as our case is Alamouti`s 2x2 MIMO system, so in the following equations K = 2, p = 2, nT = 2, nR = 2. The most appropriate decoder which can be used in this receiver is MAP decoder that maximizes the P(c1,..., cK|r1,..., rp), where ci is the transmitted symbol before mapping into complex symbol xi with constellation rule.
For calculating a-posteriori probability P(c1,..., cK|r1,..., rp), we can use Bayes` rule and derive the Eq. 9.
(9) |
By taking into account that the noise is additive white Gaussian, formula (9) can be rewritten as:
(10) |
Since P(c1,..., cK) which is a-priori information for transmitting symbols, is statistically independent, so a-priori term can be rewritten as:
(11) |
In most cases P(ci), i = 1,..., K are the same and equal to 1/log2M and by using the orthogonality property of G, Eq. 10 can lead to relation (12):
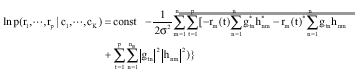 | (12) |
In the given equations, each gm corresponds to a certain symbol ci. Consequently, we can decouple the above a-posteriori probabilities into separate equations for each transmitted symbol ci and obtain them independently by using the Eq. 13.
(13) |
Finally the two transmitted symbols` a-posteriori probabilities can be obtained from (14) and (15) by taking into account p = 2, nT = 2, nR = 2:
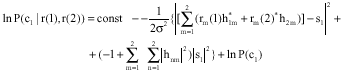 | (14) |
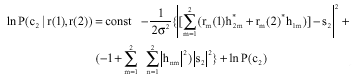 | (15) |
Since, we used the space-time block code as inner code and concatenated it with the outer code, which is based on Turbo coding, we skip hard decision in STC decoder and couple the soft a-posteriori outputs in format of LLR into fast turbo decoder.
RESULTS AND DISCUSSION
Here, we briefly review the simulation result of proposed system and examined all the scenarios in Rayleigh fading channel with AWGN noise otherwise specified. Also to simulate burst errors in affect of slow fading, we choose block fading model with constant fading coefficients over 36 consecutive symbols and the fading coefficients is considered known in the receiver with appropriate channel estimation.
The simulated turbo code`s specification is two RSC encoder with g = [1011; 1101], coding rate ½ and Log-MAP decoding algorithm. All the input data bits are assumed independent and with equal probability of being 0 or 1. Turbo code in this part means classical turbo codes otherwise specified.
 | |
| Fig. 5: | BER performance of uncoded BPSK, 2x2 space-time block codes, turbo codes and turbo codes concatenated with STB codes over block Rayleigh fading channels, (frame size: 576 bits, coding rate: 1/2 and fading coefficients are constant for 36 consecutive symbols) |
In Fig. 5, we show the simulation result of several systems including BPSK transmission without coding, turbo coded, space-time coded and also the combinational system that is serial concatenation of turbo codes and STB codes, which all are experienced over block Rayleigh channel. This Fig. 5 shows that by using turbo coding, BER performance in comparison with uncoded BPSK system is increased a lot and proves that turbo code is one of the best channel coding schemes that yields to BER performance near Shannon limit in presence of noise, also we can conclude from the data by employing STB codes we can get considerable diversity gain in presence of fading, so our proposed system by benefiting advantages of both techniques results very good performance and overcomes both noise and fading effects.
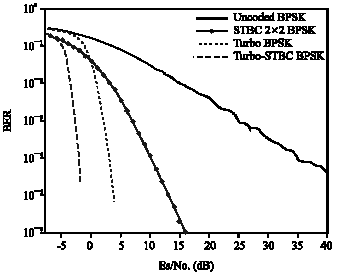
In Fig. 6, we depicted performance of proposed system (serial concatenation of turbo codes with STB codes) for different frame sizes, this figure shows great improvement for bigger frame sizes; so long frame length is very important factor to achieve good performance for the proposed system.
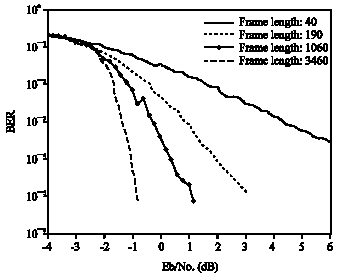
But as stated repeatedly, big frame size increases decoding time which is unacceptable for some applications, so we replaced classical turbo codes with multi-branch turbo codes in the proposed system. It shows simulation result for concatenation of fast multi-branch turbo codes with STB codes for frame size of 2304 over Rayleigh fading channel. As it is shown in Fig. 7, decoding delay is scaled down to reverse of number of branches, despite little degradation in the performance of system.
 | |
| Fig. 6: | BER performance of turbo codes concatenated with STB codes for different frame lengths over block Rayleigh fading channel |
 | |
| Fig. 7: | BER performance of fast turbo codes with different number of sub branches concatenated with STB codes over block Rayleigh fading channels of length:36, frame length is: 2304, coding rate is: 1/2 |
Figure 8 compares the proposed system for different frame sizes for classical turbo codes and introduced fast turbo codes with two sub branches and shows that BER performance degradation is negligible for large frame sizes, for example the difference between the BER performance of classical and fast turbo codes for frame size of 23004 in BER of 10-5 is about 0.2 dB, so we can apply this system (serial concatenation of fast turbo codes with STB codes) over Rayleigh fading channels to obtain suitable BER performance and reasonable decoding time that makes this system very suitable for some practical applications like next generation mobile networks.
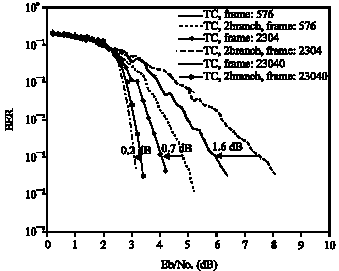 | |
| Fig. 8: | Comparison of BER performance between standard and 2 branch fast turbo codes concatenated with STB codes over block Rayleigh fading channels of length: 36, coding rate is: 1/2 |
CONCLUSION
In this study, we simulated classical turbo codes concatenated with Alamouti`s STB codes to obtain both diversity and coding gain and simulation results shows very good performance for this system in comparison with both of the turbo and STB lonely, also we demonstrated that the performance further is enhanced as the frame size is increased, but long frame size make the system impractical because of unacceptable coding delay, so we replaced classical turbo codes in proposed system by fast turbo codes which decrease decoding time by adopting parallel processing in SISO sub decoders instead of single SISO decoder. The simulation result shows brilliant BER performance for this system with reasonable decoding time over Rayleigh fading channels.
ACKNOWLEDGMENT
The authors would like to thank IRAN Telecommunication Research Center (ITRC) for financial and technical supports of this project with Grant No. 500/9120.
REFERENCES
- Agrawal, D., V. Tarokh, A. Naguib and N. Seshadri, 1998. Space-time coded OFDM for high data-rate wireless communication over wideband channels. Proceedings of the 48th IEEE International Conference on Vehicular Technology, May 18-21, 1998, Ottawa, Canada, pp: 2232-2236.
CrossRef - Alamouti, S., 1998. A simple transmit diversity technique for wireless communications. IEEE J. Sel. Areas Commun., 16: 1451-1458.
CrossRefDirect Link - Bahl, L.R., J. Cocke, F. Jelinek and J. Raviv, 1974. Optimal decoding of linear codes for minimizing symbol error rate. IEEE Trans. Inform. Theory, 20: 284-287.
CrossRef - Erfanian, J., S. Pasupathy and G. Gulak, 1994. Reduced complexity symbol detectors parallel structure for ISI channels. IEEE Trans. Commum., 42: 1661-1671.
Direct Link - Gazi, O. and A.O. Yilmaz, 2007. Fast decodable turbo codes. IEEE Commun. Lett., 11: 173-175.
CrossRefDirect Link - Lu, B., X. Wang and K.R. Narayanan, 2002. LDPC-based space-time coded OFDM systems over correlated fading channels: Performance analysis and receiver design. IEEE Trans. Commun., 50: 74-88.
CrossRefDirect Link - Robertson, P., E. Villebrun and P. Hoeher, 1995. A comparison of optimal and sub-optimal MAP decoding algorithms operating in the log domain. Proceedings of the IEEE International Conference on Communications, Volume 2, June 18-22, 1995, Seattle, WA., USA., pp: 1009-1013.
CrossRef - Tarokh, V., N. Seshadri and A.R. Calderbank, 1998. Space-time codes for high data rate wireless communication: Performance criterion and code construction. IEEE Trans. Inform. Theory, 44: 744-765.
CrossRefDirect Link - Tarokh, V., H. Jafarkhani and A.R. Calderbank, 1999. Space-time block codes from orthogonal designs. IEEE Trans. Inform. Theory, 45: 1456-1467.
CrossRefDirect Link - Tarokh, V., H. Jafarkhani and A.R. Calderbank, 1999. Space time block coding for wireless communications: Performance results. IEEE J. Selected Areas Commun., 17: 451-460.
CrossRefDirect Link - Berrrou, C., A. Glavieux and O. Thitimajshima, 1993. Near Shannon limit error-correcting coding and decoding: Turbo-codes. Proceedings of the IEEE International Conference on Communication, May 23-26, 1993, Geneva, Switzerland, pp: 1064-1070.
CrossRef