
T. Niknam
Department of Electronic and Electrical, Shiraz University of Technology,Modars Blvd. Shiraz, Iran
J. Olamaei
Islamic Azad University, South Tehran-Barnch, Tehran, Iran
B. Amiri
Department of Information Technology and Computer Engineering,
Fars Science and Research Branch of Islamic Azad University, Shiraz, Iran
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 15 | Page No.: 2695-2702







ABSTRACT
This study presents an efficient hybrid evolutionary optimization algorithm based on combining Ant Colony Optimization (ACO) and Simulated Annealing (SA), called ACO-SA, for optimal clustering N object into K clusters. The new ACO-SA algorithm is tested on several data sets and its performance is compared with those of ACO, SA and K-means clustering. The simulation results show that the proposed evolutionary optimization algorithm is robust and suitable for data clustering.
PDF Abstract XML References Citation
How to cite this article
T. Niknam, J. Olamaei and B. Amiri, 2008. A Hybrid Evolutionary Algorithm Based on ACO and SA for Cluster Analysis. Journal of Applied Sciences, 8: 2695-2702.
DOI: 10.3923/jas.2008.2695.2702
URL: https://scialert.net/abstract/?doi=jas.2008.2695.2702
DOI: 10.3923/jas.2008.2695.2702
URL: https://scialert.net/abstract/?doi=jas.2008.2695.2702
INTRODUCTION
Data mining uses a variety of data analysis tools to discover patterns and relationships of physical variables in different data sets. This technique is used in multidisciplinary fields. Clustering is one of many powerful data mining techniques that can discover intentional structures in data (Kao et al., 2008). It groups instances which have similar features and builds a concept hierarchy. As a result, it often extracts new knowledge from a database. Because of the ability to find the intentional descriptions, it is one of the very important techniques in managing databases (Lu et al., 2008). Clustering problems arise in many different applications such as knowledge discovery, data compression and vector quantization and pattern recognition and classification. There are many methods in clustering. The existing methods can be roughly divided into hierarchical, iterative and optimization methods. Iterative methods are usually based on the K-means algorithm, which applies two optimization steps iteratively (Amir and Lipika, 2007): (i) calculate optimal partitions for the given codebook and (ii) calculate a new codebook as the cluster centroids. K-means has two shortcomings: dependency on the initial state and convergence to local optima and also global solutions of large problems cannot find with reasonable amount of computation effort (Fathian et al., 2007). In order to overcome local optima problem lots of studies have done in clustering. In these studies, researchers have used meta-heuristic algorithms like genetic algorithm, simulated annealing and tabu search. Over the last decade, modeling the behavior of social insects, such as ants and bees, for the purpose of search and problem solving has been the context of the emerging area of swarm intelligence.
The ant colony optimization (ACO) paradigm was first proposed by Dorigo (2006). Since then, a number of studies based on ant colony algorithm have been carried out in order to solve some optimization problems such as the traveling salesman problem, unit commitment, etc. (Ho et al., 2006; Huang, 2001; Merkle et al., 2002; Kwang and Sun, 2003); however, in these studies, the search domains are in discrete form. In addition, a number of methods based on ant colony have been presented to solve the optimization problem in both continuous and discrete search domains such as economic dispatch, reactive power pricing in restructured networks (Niknam et al., 2005a, b). The main problem associated with these methods is that the time of convergence increases drastically when the number of variables is increased. In this study, a new hybrid algorithm based on the ant colony algorithm and simulated annealing is presented to solve optimization problems in continuous and discrete domains simultaneously. Since the SA is a good local search algorithm, in the proposed hybrid algorithm we use SA as a local search in ACO. The proposed hybrid algorithm is applied for optimal clustering N object into K clusters. The simulation results show that this algorithm not only has a better response but also converges more quickly than ordinary evolutionary methods like ACO, SA and K-means.
CLUSTER ANALYSIS PROBLEM
Cluster analysis is an effective tool in scientific or managerial inquiry. The k-means clustering method is one of the simplest unsupervised learning algorithms for solving the well-known clustering problem. The goal is to divide the data points in a data set into K clusters fixed a priori such that some metric relative to the centroids of the clusters (called the fitness function) is minimized. The algorithm consists of two stages: an initial stage and an iterative stage. The initial stage involves defining K initial centroids, one for each cluster. These centroids must be selected carefully because of differing initial centroids causes differing results. One policy for selecting the initial centroids is to place them as far as possible from each other. The second, iterative stage repeats the assignment of each data point to the nearest centroid and K new centroids are recalculated according to the new assignments. This iteration stops when a certain criterion is met, for example, when there is no further change in the assignment of the data points. Given a set of n data samples, suppose that we want to classify the data into K groups, the algorithm aims to minimize a fitness function, such as a squared error function defined as:
(1) |
where, ||xi(j)-cj||2 is a chosen distance measure between the ith data point of the data sample xi(j) (which was classified into the jth group) and the jth cluster center cj, 1≤ i≤ n, 1≤= j≤K and is an indicator of the distance of the n data samples from their respective cluster centroids. The k-means clustering algorithm is summarized in the following steps (Fathian et al., 2007):
Step 1: Place K points into the space represented by the objects that are being clustered. These points represent the initial group centroids.
Step 2: Assign each object to the group that has the closest centroid.
Step 3: When all objects have been assigned, recalculate the positions of the K centroids.
Step 4: Repeat steps 2 and 3 until a certain criterion is met, such as the centroids no longer moving or a preset number of iterations have been performed.
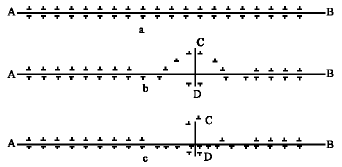 | |
| Fig. 1: | An example of finding the shortest path by ants |
This results in the separation of objects into groups for which the score of the fitness function is minimized.
Ant colony algorithm: Ants are insects which live together. Since they are blind animals, they find the shortest path from their nest to food with the aid of pheromone. Pheromone is the chemical material deposited by the ants, which serves as critical communication medium among ants, thereby guiding the determination of the next movement. On the other hand, ants find the shortest path based on intensity of pheromone deposited on different paths 15-23. Assume that ants want to move from point A to B (Fig. 1).
At first, if there is no obstacle, all of them will move along the straight path (AB) (Fig. 1a). At the next stage, assume that there is an obstacle; in this case, ants will not be able to follow the original trail in their movement. Therefore, randomly, they turn to the left (ACB) or to the right (ADB) (Fig. 1b). Since ADB path is shorter than ACB, the intensity of pheromone deposited on ADB is more than the other path. So ants will be increasingly guided to move on the shorter path (Fig. 1c). This behavior forms the fundamental paradigm of the ant colony system.
As was indicated in Fig. 1, the intensity of deposited pheromone is one of the most important factors for ants to find the shortest path. Generally, the intensity of pheromone and path length are two important factors that should be used to simulate the ant system. To select the next path, the state transition probability is defined as follows:
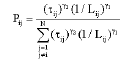 | (2) |
where, ![]() and Lij are the intensity of pheromone and the length of path between nodes j and i, respectively. γ1 and γ2 are the control parameters for determining the weight of trail intensity and length of path, respectively. N is the number of ants.
and Lij are the intensity of pheromone and the length of path between nodes j and i, respectively. γ1 and γ2 are the control parameters for determining the weight of trail intensity and length of path, respectively. N is the number of ants.
After selecting the next path, the trail intensity of pheromone is updated as:
(3) |
In the above equation, ρ is a coefficient such that (1-ρ) represents the evaporation of the trail between time k and k+1 and ![]() is the amount of pheromone trail added to
is the amount of pheromone trail added to ![]() by ants.
by ants.
To apply the ACO algorithm for clustering, the following steps have to be taken:
Step 1: Generate the initial population and trail intensity
Step 2: Generate the initial population and trail intensity for ants in each colony (local search)
Step 3: Determine the next position
Step 4: Check the convergence condition
Simulated annealing algorithm: Simulated annealing is a generalization of a Monte Carlo method for examining the equations of state and frozen states of n-body systems. The concept is based on the manner in which liquids freeze or metals recrystalize in the process of annealing. In an annealing process, a melt is initially at high temperature and disordered and is slowly cooled so that the system at any time is approximately in thermodynamic equilibrium. As cooling proceeds, the system becomes more ordered and approaches a frozen ground state at zero temperature. Hence, the process can be thought of as an adiabatic approach to the lowest energy state. If the initial temperature of the system is too low, the system may become quenched (Tai-Hsi et al., 2008).
The original Metropolis scheme was that an initial state of a thermodynamic system was chosen at energy E and temperature T. Holding T constant, the initial configuration is perturbed and the change in energy, ΔE, is computed. If the change in energy is negative, the new configuration is accepted. If the change in energy is positive, it is accepted with a probability factor exp(-ΔE/T). This process is then repeated sufficient times to give good sampling statistics for the current temperature and then the temperature is decremented and the entire process repeated until a frozen state is achieved at T = 0.
The general procedure for the SA algorithm can be summarized as follows (Christober et al., 2007):
Step 1: Select an initial solution X and an initial temperature T.
Step 2: Find another solution, namely Xnext, by modifying the last answer X.
Step 3: Calculate the energy differential ΔE = f(Xnext)-f(X)
Step 4: If ΔE< 0 go to Step 9.
Step 5: Generate a random number, namely R, between 0 and 1.
Step 6: If R<exp(-ΔE/T) go to Step 9.
Step 7: Repeat Steps 2-6 for a number of optimization steps for the given temperature.
Step 8: If no new solution, Xnext is accepted and go to Step 10.
Step 9: Decrease the temperature T, replace X with Xnext and go to Step 2.
Step 10: Reheat the environment with setting T to a higher value.
Step 11: Repeat Steps 1 through 10 until no further improvement obtained.
APPLICATION OF ACO-SA TO CLUSTERING
This section presents a new hybrid approach based on combining the ant colony optimization and simulated annealing algorithms for the clustering problem. To apply the hybrid algorithm, named ACO-SA, on the clustering the following steps should be repeated:
Step 1: Generate an initial population: An initial population is randomly generated as follows:
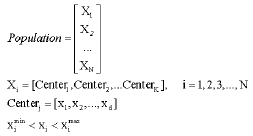 | (4) |
where, Centerj is the jth cluster center for the ith individual. Xi is position of the ith individual. d is the dimension of each cluster center. Ximax and ximin (each feature of center) are the maximum and minimum value of each point belonging to the jth cluster center, respectively.
Step 2: Generate an initial trail intensity: At initialization phase, it is assumed that the trail intensity between each pair of ants is the same and is generated as follows:
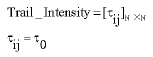 | (5) |
where, ![]() are trail intensity between the ith and jth ants and initial trail intensity, respectively.
are trail intensity between the ith and jth ants and initial trail intensity, respectively.
Step 3: Determination of the next path: To determine the next path, at first, for each Xi a set Ai is defined by:
(6) |
where D(k) is visibility. ||.|| is defined by:
(7) |
For determination of the next path, there are 2 cases:
Case 1: Ai is empty: In this case, the best solution (Y) is determined in the neighborhood of Xi by SA.
The neighborhood is defined as follows:
(8) |
where α is a positive parameter between 0 and 1.
The neighborhood of Xi is determined by simulated annealing as follows:
Step 1: Select an initial solution X and an initial temperature T.
Step 2: Find another solution, namely Xnext, by modifying the last answer X.
Step 3: Calculate the energy differential ΔE = f(Xnext)-f(X)
Step 4: If ΔE< 0 go to step 9.
Step 5: Generate a random number, namely R, between 0 and 1.
Step 6: If R<exp(-ΔE/T) go to step 9.
Step 7: Repeat steps 2-6 for a number of optimization steps for the given temperature.
Step 8: If no new solution, Xnext is accepted and go to step 10.
Step 9: Decrease the temperature T, replace X with Xnext and go to step 2.
Step 10: Reheat the environment with setting T to a higher value.
Step 11: Repeat Steps 1 through 10 until no further improvement obtained.
After that SA finds the best local solution (Y), Xi is replaced by Y and then the trail intensity matrix is updated as follows:
(9) |
where r is a positive parameter between 0 and 1.
Case 2: Ai is not empty: In this case, selection of the next path is based on Eq. 2. Since in some optimization problems, Lij is not known, we can define the inverse of Lij as follows:
(10) |
In this algorithm, we consider Xi as a selection. In this case φii and ![]() are defined by:
are defined by:
(11) |
where m is the number of elements of Ai.
The transition probabilities are defined as:
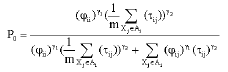 | (12) |
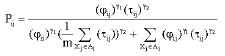 | (13) |
where γ1 and γ2 are the control parameters.
The roulette wheel is used for the stochastic selection. If the selection result is Pij, then:
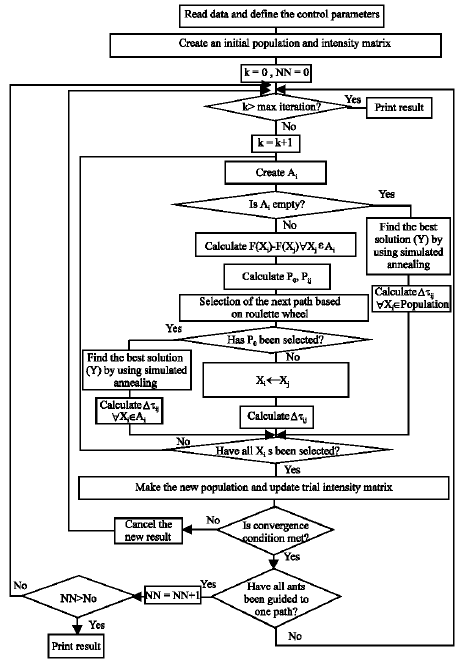 | |
| Fig. 2: | Flowchart of the hybrid algorithm |
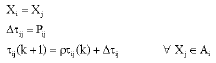 | (14) |
If the selection result is P0, the best solution (Y) is found in the neighborhood of Xi by simulated annealing as mentioned in case 1(Ai is empty). After that Xi is replaced by Y and then the trail intensity matrix is updated as follows:
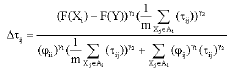 | (15) |
(16) |
Step 4: Check of the convergence condition: After all ant colonies (Xi) find the next path, the convergence condition is checked by:
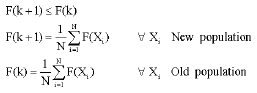 | (17) |
If the convergence condition is not satisfied, cancel the new results and then go to step 3. If all ants are guided to one path after NN iterations, stop and print the results. If the results are not changed after NNN iterations, increase the visibility (D(k)) and neighborhood of search (α). Here NN, NNN are coefficients. Figure 2 shows the flowchart of the hybrid algorithm.
RESULTS AND DISCUSSION
Experimental results comparing the ACO-SA clustering algorithm with several typical stochastic algorithms including the ACO, SA and K-means algorithms are provided for six real-life data sets (Iris, Wine, Vowel, Contraceptive Method Choice(CMC), Wisconsin breast cancer and Ripley`s glass), which are described as follows: Iris data (N = 150, d = 4, K = 3): This is the iris data set. These data set with 150 random samples of flowers from the iris species setosa, versicolor and virginica collected by Anderson. From each species there are 50 observations for sepal length, sepal width, petal length and petal width in cm. This data set was used by Fisher in his initiation of the linear-discriminant-function technique.
Wine data (N = 178, d = 13, K = 3): This is the wine data set, which also taken from MCI laboratory. These data are the results of a chemical analysis of wines grown in the same region in Italy but derived from three different cultivars. The analysis determined the quantities of 13 constituents found in each of the three types of wines. There are 178 instances with 13 numeric attributes in wine data set. All attributes are continuous. There is no missing attribute value.
Contraceptive method choice (N = 1473, d = 10, K = 3): This data set is a subset of the 1987 National Indonesia Contraceptive Prevalence Survey. The samples are married women who were either not pregnant or do not know if they were at the time of interview. The problem is to predict the current contraceptive method choice (no use, long-term methods, or short-term methods) of a woman based on her demographic and socio-economic characteristics.
Vowel data set (N = 871, d = 3, K= 6): This data set consists of 871 patterns. There are six overlapping vowel classes and three input features.
Wisconsin breast cancer (N = 683, d = 9, K = 2), which consists of 683 objects characterized by nine features: clump thickness, cell size uniformity, cell shape uniformity, marginal adhesion, single epithelial cell size, bare nuclei, bland chromatin, normal nucleoli and mitoses. There are two categories in the data: malignant (444 objects) and benign (239 objects).
Ripley`s glass (N = 214, d = 9, K = 6), for which data were sampled from six different types of glass: building windows float processed (70 objects), building windows non-float processed (76 objects), vehicle windows float processed (17 objects), containers (13 objects), tableware (9 objects) and headlamps (29 objects), each with nine features, which are refractive index, sodium, magnesium, aluminum, silicon, potassium, calcium, barium and iron.
The algorithms are implemented by using Matlab 7.1 on a Pentium IV, 2.8 GHz, 512 GB RAM computer. The parameters required for implementation of the ACO-SA algorithm are γ1, γ2, ρ, D0 and T. In this study, the best values for the aforementioned parameters are γ1 = γ2 = 1.0, ρ = 0.99, D0 = 10 and T = 100 determined by 10 runs of the algorithm.
Table 1-6 present a comparison among the results of ACO-SA, ACO (Fathian et al., 2007; Shelokar et al., 2004), SA (Fathian et al., 2007) and K-means (Kao et al., 2008) for 100 random tails on the mentioned data sets.
For Iris data (Table 1) it is found that the ACO-SA clustering algorithm provides the optimal value of 96.6602, most of the times. The ACO, SA and K-means algorithms attain 96.753, 97.4573 and 97.333 respectively. The standard deviation of the fitness function for ACO-SA clustering algorithm is 0.12196, which it significantly is smaller than other methods. The number of function evaluations of ACO-SA, ACO, SA and K-means are 3,629, 4,931, 5314 and 120, respectively. The best value obtained by ACO-SA clustering algorithm for Wine data (Table 2) is 16,298.628 (which is obtained in 90% of the total runs). The ACO, SA and K-means algorithms, on the other hand, fail to attain this value in any of their runs. From Table 3 for CMC data, it is found that the ACO-SA was able to find the optimum in most of runs. The ACO-SA clustering algorithm attains 5,696.6075 that it is better than the best value of ACO, SA and K-means algorithms (5,701.923, 5,849.038 and 5,842.20). For the vowel data set (Table 4), the best global solution, the worst global solution, the average and the standard deviation of the ACO-SA are 148,978.6294, 149,183.1834, 149,057.8251and 75.539868, respectively. In terms of the number of function evaluations, K-means needs the least number of function evaluations. The results for Wisconsin breast cancer data are shown in Table 5. The best value that the ACO-SA attains is 2,965.97 and the worst is 2,969.01, both of which are better than those obtained by ACO, SA and K-means algorithms. For Ripley`s glass Data, the ACO-SA algorithm attains the best value of 199.89. The results of other algorithms are inferior to that of ACO-SA. The number of function evaluations of ACO-SA is less than ACO and SA but it is greater than K-means algorithm.
| Table 1: | Results obtained by the five algorithms for 100 different runs on Iris data |
 | |
| Table 2: | Results obtained by the five algorithms for 100 different runs on Wine data |
 | |
| Table 3: | Results obtained by the five algorithms for 100 different runs on CMC data |
 | |
| Table 4: | Results obtained by the five algorithms for 100 different runs on Vowel data |
 | |
| Table 5: | Results obtained by the five algorithms for 100 different runs on Wisconsin breast cancer |
 | |
| Table 6: | Results obtained by the five algorithms for 100 different runs on Ripley`s glass |
 | |
The simulation results in the Table 6 demonstrate that the proposed hybrid evolutionary algorithm converges to global optimum with a smaller standard deviation and less function evaluations and leads naturally to the conclusion that the ACO-SA algorithm is a viable and robust technique for data clustering.
CONCLUSION
In this study a new hybrid evolutionary algorithm is proposed to find optimal or near optimal solutions for clustering problems of allocating N objects to k clusters. The proposed algorithm is based on a combination of ACO and SA algorithms. The ACO-SA algorithm is tested on several well known real life datasets. The experimental results indicate that the proposed optimization algorithm is at least comparable to the other algorithms in terms of function evaluations and standard deviations. Regardless of robustness and efficiency of ACO-SA algorithm, it is applicable when the number of clusters is known a priori. The results illustrate that the proposed ACO-SA optimization algorithm can be considered as a viable and an efficient heuristic.
REFERENCES
- Amir, A. and D. Lipika, 2007. A k-mean clustering algorithm for mixed numeric and categorical data. Data Knowledge Eng., 63: 503-527.
CrossRef - Christober C., A. Rajan and M.R. Mohan, 2007. An evolutionary programming based simulated annealing method for solving the unit commitment problem. Int. J. Elect. Power Energy Syst., 29: 540-550.
CrossRef - Fathian, M., B. Amiri and A. Maroosi, 2007. Application of honey-bee mating optimization algorithm on clustering. Applied Math. Comput., 190: 1502-1513.
CrossRef - Dorigo, M., M. Birattari and T. Stutzle, 2006. Ant colony optimization. IEEE Comput. Intell. Mag., 1: 28-39.
CrossRefDirect Link - Ho, S.L., Y. Shiyou, N. Guangzheng and J.M. Machado, 2006. A modified ant colony optimization algorithm modeled on tabu-search methods. IEEE Trans. Magnet., 4: 1195-1198.
CrossRefDirect Link - Huang, S.J., 2001. Enhancement of hydroelectric generation scheduling using ant colony system based optimization approaches. IEEE Trans. Energy Convers., 16: 296-301.
CrossRefDirect Link - Kao, Y.T., E. Zahara and I.W. Kao, 2008. A hybridized approach to data clustering. Expert Syst. Applic., 34: 1754-1762.
CrossRefDirect Link - Sim, K.M. and W.H. Sun, 2003. Ant colony optimization for routing and load-balancing: Survey and new directions. IEEE Trans. Syst. Man Cybernetics, Part A, 33: 560-572.
CrossRefDirect Link - Lu, J.F., J.B. Tang, Z.M. Tang and J.Y. Yang, 2008. Hierarchical initialization approaches for K-Means clustering. Pattern Recogn. Lett., 29: 787-795.
CrossRef - Merkle, D., M. Middendorf and H. Schmech, 2002. Ant colony optimization for resource-constrained project scheduling. IEEE Trans. Evolut. Comput., 6: 333-346.
CrossRefDirect Link - Niknam, T., A.M. Ranjbar and A.R. Shirani, 2005. A new approach for distribution state estimation based on ant colony algorithm with regard to distributed generation. J. Intell. Fuzzy Syst., 16: 119-131.
Direct Link - Niknam, T., A.M. Ranjbar and A.R. Shirani, 2005. A new approach based on ant algorithm for Volt/Var control in distribution network considering distributed generation. Iran. J. Sci. Technol. Trans. B, 29: 1-15.
Direct Link - Shelokar, P.S., V.K. Jayaraman and B.D. Kulkarni, 2004. An ant colony approach for clustering. Anal. Chim. Acta, 509: 187-195.
CrossRef - Tai-Hsi, W., C. Chin-Chih and C. Shu-Hsing, 2008. A simulated annealing algorithm for manufacturing cell formation problems. Expert Syst. Applic., 34: 1609-1617.
CrossRef