
A.R. Bagherieh
Department of Civil Engineering, School of Engineering, Shiraz University, Shiraz, Iran
G. Habibagahi
Department of Civil Engineering, School of Engineering, Shiraz University, Shiraz, Iran
A. Ghahramani
Department of Civil Engineering, School of Engineering, Shiraz University, Shiraz, Iran
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 13 | Page No.: 2387-2395







ABSTRACT
A new technique for measuring the volume change of triaxial soil sample is presented in this research. A digital camera located at a fixed location takes images from the sample during the test. An edge detection procedure based on wavelet transform is introduced. This method can effectively trace the sample boundaries. Refraction of the light in water and plexiglass causes distortion and magnification of the image. Besides, errors induced by improper manufacturing of the lens may also cause image distortion. It is found that the nature of distortion for a triaxial soil sample is very complicated and no theoretical method is available for its calibration. Indeed, conventional regression methods fail for this problem. A feed forward back propagation neural network is used as a pattern recognition tool. The trained network can recognize the pattern of distortion and the corresponding errors are eliminated. This method can be adopted as an easy and inexpensive approach for unsaturated soils, where the soil volume change cannot be determined from the net water flow into or out of the soil specimen. The results of volume changes obtained by this method are in good agreement with the conventional method for saturated soils.
PDF Abstract XML References Citation
How to cite this article
A.R. Bagherieh, G. Habibagahi and A. Ghahramani, 2008. A Novel Approach to Measure the Volume Change of Triaxial Soil Samples Based on Image Processing. Journal of Applied Sciences, 8: 2387-2395.
DOI: 10.3923/jas.2008.2387.2395
URL: https://scialert.net/abstract/?doi=jas.2008.2387.2395
DOI: 10.3923/jas.2008.2387.2395
URL: https://scialert.net/abstract/?doi=jas.2008.2387.2395
INTRODUCTION
Measurement of specimen volume alteration during triaxial tests is valuable for understanding the volumetric compression or dilation characteristics of the soil which is very important when analysing the mechanical behaviour. In a saturated soil, assuming water is incompressible, the total volume change of the soil specimen is commonly assumed to be equal to the change in volume of water leaving or entering the soil specimen and is easily measured using a twin burette or an automatic water volume change system. However, accurate measurement of total volume changes in an unsaturated soil specimen is much more difficult and complicated, where not only pore-water but also pore-air volume may vary.
Geiser et al. (2000) summarized the existing techniques for measuring volume change in unsaturated soil specimens and classified them into three main categories: (i) measurement of the volume of the cell fluid, (ii) measurement of the air and water volumes separately and (iii) direct measurement of the specimen volume.
For the first category, volume change in a soil specimen is recorded by measuring the volume change in the confining cell fluid. Several problems are usually encountered using this method such as expansion- contraction of the cell wall, connecting tubes and cell fluid because of pressure and temperature variations, creep under pressure and possible water leakage (Ng et al., 2002). To minimize the errors caused by expansion or contraction of cell, sorts of double wall cell setup have been proposed by Yin (2003) and Sivakumar et al. (2006).
The second category of measuring systems, is impractical in the triaxial testing of unsaturated soils because measuring the air volume change is somewhat difficult as the volume of air is very sensitive to the factors such as changes in the atmospheric pressure and ambient temperature and undetectable air leakage through the tubes and connections and air diffusion through the rubber membrane (Ng et al., 2002).
Measurements using digital image processing fall into the third category. Macari et al. (1997) used video images to compute the volume change of sand during drained conventional triaxial compression test. The experimental results were compared to the volumetric strains obtained by analysing the front view and side view images. Two video cameras were placed orthogonally to each other to take front and side view images. It was mentioned that the results were in accordance with each other unless irregular shapes occurred. Alshibli and Al-Hamdan (2001) measured the volume change of triaxial soil specimens by locating three cameras at equal distance to capture the entire body of the specimen. In addition to these, more recently Gachet et al. (2007) measured the volume change of unsaturated Sion silt using image processing method. They applied a digital plug and play camera.
A novel approach for volume measurement in triaxial tests based on image processing is proposed in this research. Generally a black background is placed behind the sample which makes it easier to distinguish the sample boundaries. The selection of a suitable method for tracing the sample boundaries is crucial for accurate measurement of specimen volume. The triaxial sample has two vertical edges and two horizontal edges at the Baseline and bottom. The diameter of sample in each level is a function of the number of pixels located between the left and right boundaries. Many methods of edge detection have been developed yet each one has its special advantages and drawbacks. The researches on edge detection methods are still going on. One of the novelties of this research is employing the wavelet transform to detect the sample boundaries. This method is more practical and powerful compared with those applied by Macari et al. (1997), Alshibli and Al-Hamdan (2001) and Gachet et al. (2007).
The presence of water and plexiglass chamber in the line of vision between the camera and sample causes magnification and distortion of the image. Furthermore, lens refraction of light may produce radial distortion. It was found that the pattern of image distortion is complicated such that it cannot be successfully calibrated by the conventional regression approach. Artificial neural network has been used in this research as a successful method to calibrate these effects.
IMAGING EQUIPMENT
Two DV cameras were used for viewing and capturing images from triaxial specimens. Each camera was connected by a USB port to a computer. The software supplied by the manufacturing company enabled the user to send the capturing command from the computer. In this mode, images with a resolution of 2048x1536 pixels were taken. Since the cameras had not the optical zooming feature and in order to increase the number of pixels to the real dimension ratio, the cameras were located at a distance of 20 cm from the centre of sample and 90° from each other. The advantage of using this type of camera in addition to the low price was its remote shooting capability. A simple Visual Basic script was written to execute the picture taking command at certain time intervals. The cameras were fastened to metal bases fixed on triaxial cell. This allowed keeping a constant distance between the cameras and the specimen.
 | |
| Fig. 1: | Digital camera and triaxial cell |
Suitable lightening enhances the quality of images and hence the quality of analyses is improved. Therefore, two florescent lights were employed. The positions of these lights were determined by a trial and error process such that the best quality images were obtained. Figure 1 shows the triaxial and imaging system setup.
EDGE TRACING SCHEME
The simplest edge detection method consists of manual tracing of the edges by a mouse on the computer screen. This method in addition of being tedious could come up with large errors. Therefore, it is necessary to use a proper systematic technique for this purpose. Classical edge detection methods are quite sensitive to noise. In some circumstances they may not be able to distinguish the exact position of sample boundaries. That`s why Macari et al. (1997) used a method which was a combination of both manual and systematic edge detection. Manual tracing was used to trace the edge in regions of uncertainty where the program identified a false edge. Gachet et al. (2007) applied a threshold method. They determined a threshold value for the entire image, the pixels whose intensity were higher than this value were turned white and the pixel with intensities lower than threshold were turned black. Finally, a binary image containing the specimen in white pixels on a black background is obtained. The next stage is image cleaning. In this stage the pixels which are incorrectly set to black or white are corrected. Thus, a manual post processing stage was included in their process.
Classical edge detectors are modified gradient operators. Since an edge is characterized by having a gradient of large magnitude, edge detectors are approximations of gradient operators. This group consists of well-known edge detectors, such as Sobel, Roberts, Prewitt and etc. Their major drawbacks are high sensitivity to noise and disability to discriminate edges versus textures.
Because noise influences the accuracy of the computation of gradients, usually an edge detector is a combination of a smoothing filter and a gradient operator. An image is first smoothed by the smoothing filter and then its gradient is computed by the gradient operator.
Wavelet transform maps a time function into a two dimensional function of α and τ. Parameter α scales the function by compressing or stretching it. Parameter τ corresponds to the translation of the wavelet function along the time axis. A remarkable property of the wavelet transform is its ability to characterize the local regularity of functions. It enables to focus on localized signal structures with a zooming procedure that progressively reduces the scale parameter α. Mallat and Hwang (1992) proved that the maxima of the wavelet transform modulus can locate the irregular structures. Edges in images can be mathematically defined as local singularities. For an image f(i, j), its edges correspond to singularities of f(i, j) and therefore are related to the local maxima of the wavelet transform modulus. Therefore, the wavelet transform is an efficient method for edge detection. In an image, all edges are not created equal. Some are more significant and some are blurred and insignificant. The edges of more significance are usually more important and more likely to be kept intact by wavelet transforms. The insignificant edges are sometimes introduced by noise and preferably removed by wavelet transforms.
In this way, rough and fine signal structures are simultaneously analysed at different scales. Wavelet transform is defined by:
(1) |
where, N stands for the length of signal s(n) and Ψ(t) is so called mother wavelet. Mother wavelet is a prototype wavelet from which all other wavelets are generated. Its characteristic must depend on the properties of signal structures to be detected in a signal (Heric and Zazula, 2007). Here Haar wavelet, Eq. 2, was adopted because it is orthogonal, compact and without spatial shifting in the transform space. Its main property is the ability to present the magnitude variation between adjacent intervals in the signal as a modulus maximum on time-scale plane (Heric and Zazula, 2007). Haar wavelet is defined as:
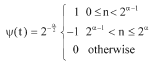 | (2) |
 | |
| Fig. 2: | An image and a line cut from it |
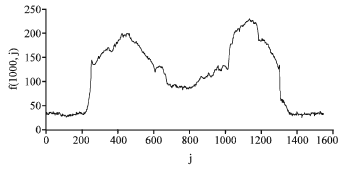 | |
| Fig. 3: | Variation of the discrete function f(i, j) with the j-coordinate at i = 1000 |
Proposed edge detection approach: In the following sections, the proposed approach is described in details. First the acquired RGB images were converted into gray scale. Using an image taken at the beginning of the test, as an example, gray levels were extracted along the line at i =1000 shown in Fig. 2 and the variation of the gray levels with the j-coordinate is shown in Fig. 3. From Fig. 2 it is clear that there exist two major interface points along the i =1000 line. One of them corresponds to the left vertical boundary and the other to the right boundary. The gray level changes abruptly at these two positions as shown in Fig. 3.
The problem of image edge detection was then transformed into a search of sudden amplitude changes in 1D signals representing a row pixel intensities.
Images can be corrupted by the noise which is represented as magnitude variation of the signal s(n). Such noise appears on the time-scale plane as additional edges.
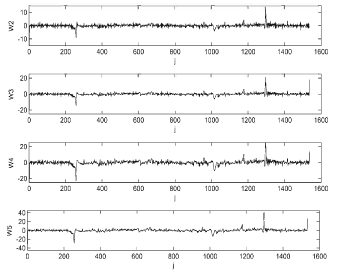 | |
| Fig. 4: | Haar wavelet transform of intensity level along i = 1000 line for different scale values of α = 2, 3, 4 and 5 |
But there are two principal differences between the real edges and noise: (a) edges` modulus maxima are larger than noise modulus maxima if the signal-to-noise ratio (SNR) is low and (b) the influence of noise decreases with progressing toward higher scales if noise is additive with zero mean, because Haar wavelets perform averaging. Hence, the influence of noise is gradually filtered out going toward higher scales and its modulus maxima become negligibly small (Heric and Zazula, 2007).
As an example, the Haar wavelet transform of gray scale along i = 1000 line for different scale values is shown in Fig. 4. In all scale values, there exist two major modulus maxima. The left one corresponds to the left edge of the sample and the other to the right edge. The ratio of edge modulus maxima to the noise modulus maxima increases with increasing scale. The sample edges could then be easily distinguished even at the lowest scale (α = 2). As the modulus maxima at finer scales represent the edge positions more accurately, the position of modulus maxima between j = 1 to j = 750 was determined as the left sample edge and between j = 750 to j = 1500 as the right edge. In order to obtain the entire vertical boundaries, this procedure was performed for all values of i.
Figure 5 shows the typical example of a gray scale image of a barrel shaped sample and its vertical boundaries obtained by the proposed method. It is evident that the edge detection method can efficiently detect the sample boundaries. In cases where a plastic pipe inside the cell covers somewhere the sample boundary, as in Fig. 5, the sample boundary is not visible and consequently the edge detection method fails at the overlap region. In such cases a straight line connecting the sample boundary above the pipe to the sample boundary just underneath the pipe is set as the boundary.
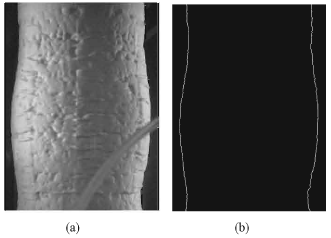 | |
| Fig. 5: | (a) A gray scale image of a barrel shaped sample (b) Sample boundaries determined with the proposed method |
Since the length of the overlap region is very small compared with sample height, such approximation is reasonable.
CALIBRATION
The apparent magnification of the specimen is a result of the presence of water and plexiglass chamber in the line of vision between the camera and the sample. The order of magnification depends upon various indices of refraction of light in the water and the plexiglass chamber wall. An additional phenomenon is image distortion, which causes features in an image to be shifted from their expected location. Distortion is a result of the fact that imaging system is actually a mapping of a three dimensional object inside the cylinder to a two dimensional image. Lens distance from Plexiglass surface can also affect the amount of distortion. Another cause of image distortion is that of radial lens distortion, which is an error associated with lens refraction of light its effect increases with distance from the centre of the lens. Radial lens distortion becomes an increasing difficulty for less costly lenses and most lenses with focal lengths below 8 mm. (Smith and Smith, 2005).
While it is generally preferable to eliminate the source of system errors rather than attempting to compensate for them, this often proves to be hard to accomplish in practice. Specially, in our imaging system, the magnification and distortion effects caused by refraction of light in water and plexiglass were absolutely inevitable.
The challenge for any calibration process is to model the distortion with the intention that its effects can be reduced or eliminated from the image data. One way of achieving this modelling is to use analytical methods. In general terms, analytic techniques based on explicit physical models have a number of significant shortcomings. The fact that in practice unknown contradictions may exist as a result of, for example, randomised manufacturing errors. Hence, these effects cannot be solved for analytically with high precision. The requirement that in order to obtain more accurate results, more accurate modelling is generally necessary and this brings more complex mathematical equations and calibration procedures, often leading to an increased computational burden.
An example of such analytic physical models is that of Macari et al. (1997) which is a theoretical approach using optical laws. The camera is assumed as a pinhole which is a strong hypothesis. The schematic of their model is shown in Fig. 6. The relationship obtained to convert radial pixels to millimetres is not very convenient to use. Furthermore, unknown causes of distortion and magnification, such as randomized manufacturing errors and radial lens distortion are disregarded in this model.
Regression has been used as an approach for detecting and quantifying patterns in vision systems. In a regression analysis of non-linear functions, it is assumed that the form of the data is known and this knowledge is used to inform the choice of transform used (e.g., a quadratic). Unfortunately, however, in practice, the situation is often not this simple, as the overall error is usually formed from a combination of components and their separation is not always practical. As a result, the type of the error is often relatively complex and cannot be accurately modelled in terms of simple curves. In terms of lens distortion this additional complexity can be introduced through effects such as manufacturing errors. Previous efforts that have been done for this error calibration were dominantly on the basis of curve fitting. Works of Gachet et al. (2007) and Alshibli and Al-Hamdan (2001) are some examples of application of simple regression for calibration.
To evaluate the magnification and distortion in our imaging system, four metallic cylinders were put in the cell. Those cylinders had diameters of 4.46, 4.94, 5.72 and 6.26 cm. After the cell was filled with water some pictures were taken. Vertical edges of the cylinders were determined using the approach described in the edge detection section. At each elevation (each row) the number of pixels located between the two edges was counted. The number of pixels between the two edges at different elevations is shown in Fig. 7-10.
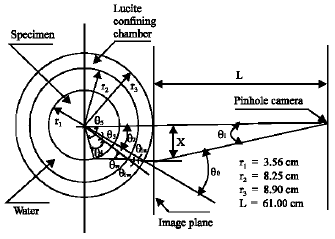 | |
| Fig. 6: | Schematic of two dimensional model used by Macari et al. (1997) |
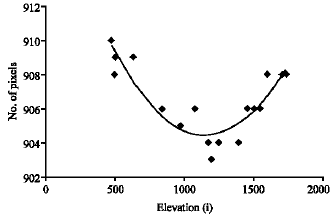 | |
| Fig. 7: | No. of pixels between two edges of cylinder with diameter of 4.46 cm along i axis |
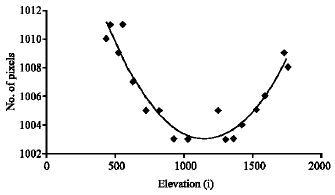 | |
| Fig. 8: | No. of pixels between two edges of cylinder with diameter of 4.94 cm along i axis |
Although the cylinder diameter is constant at all elevations, these figures indicate that the number of pixels increases with distance from the middle elevation. If there had been no distortion in the imaging system the number of pixels at different elevations would have been the same.
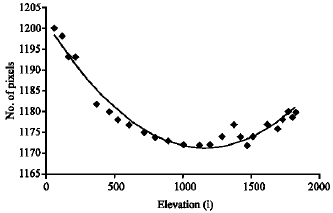 | |
| Fig. 9: | No. of pixels between two edges of cylinder with diameter of 5.72 cm along i axis |
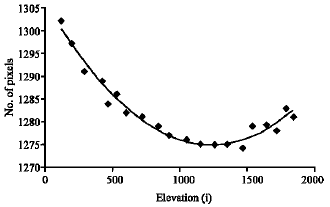 | |
| Fig. 10: | No. of pixels between two edges of cylinder with diameter of 6.26 cm along i axis |
If we consider d as the real diameter of the object or in other words the real distance between the two edges and i as its vertical position in pixel and d´ as the measured diameter in pixels in the image, it can be said that distortion function is as follows:
(3) |
In case, the function f is known, distortion can be calibrated. To achieve this goal, data set was deciphered such that from each image specified elevations (i) were selected and the respective d´ and i values were determined. For each calibration cylinder d was also a constant value. Therefore, in above mentioned data set d had four values of 4.46, 4.94, 5.72 and 6.26 cm. It was first tried to fit the following second order function to the calibration data set.
(4) |
The coefficients of the above function (C1 to C8) were obtained by minimizing the mean absolute error using genetic algorithm. The function obtained could not fit the data set with reasonable accuracy. That is, the mean absolute error of measuring the diameter was about 0.45 millimetres. This was not the order of accuracy needed to follow volume change of specimens during the tests. Considering the complex nature of the problem, neural network algorithm was employed as a suitable alternative. Details are described in the subsequent sections.
Vertical calibration: Parallel horizontal lines with equal distance of 1.70 cm were drawn on all metallic cylinders which were used for calibration. To perform vertical calibration, number of pixels between these lines was determined in all elevations for all cylinders. It is interesting to note that the distance between these lines in all elevations and all cylinders was constant and equal to 291 pixels. Therefore, the vertical calibration is absolutely linear and each pixel represents the height of 1.70/291 centimeter.
CALIBRATION USING ARTIFICIAL NEURAL NETWORK
As stated by Ekpar et al. (2003) the formation of a distorted 2D image from the undistorted 3D real world scene by an imaging system is considered to be an input-output mapping between an undistorted 2D image plane and the distorted 2D image plane. The development of neural network technology has made it possible for a novel approach to imaging system calibration. A neural network approach is presented herein as a pattern recognition method to calibration. This approach does not require a complicated mathematical model be developed nor any prior knowledge about the setup or calibration parameters. Since this is often the case, neural networks can perhaps be considered to be the most appropriate general solution to the error modelling involved.
An artificial neural network is a parallel computing method that provides a simple artificial analogy to biological nervous systems. Since the neural network stores data as patterns in a set of processing elements by adjusting the connection weights, it is possible to realize complex mapping through its characteristics of distributed representations (Bagherieh et al., 2008). The neural network can automatically find the closest match through its content addressable property, even if the data are incomplete or vague. Even in the case that a few processing elements malfunction or fail completely, the network can still function through its fault-tolerance attribute. The neural network has the ability for extracting a generalized correlation (or regularity) from many individual examples (or experiences). The computing abilities of neural networks have been proven in the field of geotechnical engineering (Habibagahi and Bamdad, 2003; Adeli, 2001). The ability of the network to associate a particular output with an input pattern is a result of the training operations, where the weights are adjusted. This is achieved by comparing output and target values a number of times and altering the weights so as to minimise the error. This is recognized as supervised learning. Once trained, a neural network can provide an ability for usefully modelling phenomena that exhibit non-linear behaviour and appreciable noise, as is often the case in image analysis.
Network architecture: The neural network architecture used is a feed-forward back-propagation one. More than 50 neural network models have been devised so far and it has been found that the backpropagation learning algorithm based on the generalized delta rule is one of the most efficient learning procedures for multi-layer neural networks (Bagherieh et al., 2008). This technique generally consists of many sets of nodes arranged in layers (e.g., input, hidden and output layers). The output signals from one layer are transmitted to the subsequent layer through links that amplify or attenuate or inhibit the signals using weighting factors. Except for the nodes in the input layer, the net input to each node is the sum of the weighted outputs of the nodes in the previous layer. An activation function, such as the sigmoid logistic function, is used to calculate the output of the nodes in the hidden and output layers. In the calculation, both input and output are usually normalized to give a value between -1 and 1 incorporating various mapping schemes. This depends on adopted activation functions. The degree of non-linearity can be changed easily by changing the transfer function and the number of hidden layer nodes.
The proposed BPNN had three layers: an input layer, a hidden layer with six neurons and an output layer. The architecture of back-propagation neural network is shown in Fig. 11. In this study, the batch training rule was used to train the network. A set of 79 data obtained from experiments were used for neural network modelling. A total number of 51 sets were used for training the network, 18 sets were used to test the network and the remaining 10 sets were used for validation.
Each epoch was defined as one cycle of presentation of all training data sets to the network. Overtraining (over fitting) may occur if a network is trained excessively, at which point, the network starts to learn noise contained in the training data sets.
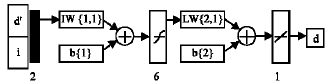 | |
| Fig. 11: | Architecture of back-propagation neural network (BPNN) |
 | |
| Fig. 12: | Predicted vs. Measured diameters using the NN model |
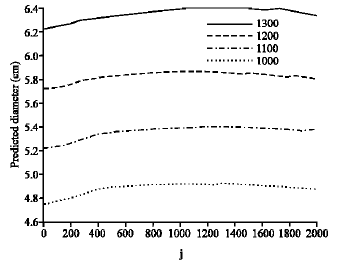 | |
| Fig. 13: | Predicted profile assuming d` = 1000, 1100, 1200 and 1300 pixels along i axis |
Beyond this point, although the network`s training error may continue to decline, the testing error increases rapidly. In order to guard against overtraining, the network was examined during the training process by monitoring the performance for the testing record. Figure 12 represents the prediction of data using proposed BPNN versus actual data. The error rates (mean absolute error) of the proposed network were 0.024, 0.071 and 0.041 millimetres for training data, testing data and validation data, respectively and R2 of proposed network was 0.999, 0.999 and 0.999 for training data, testing data and validation data, respectively.
Parametric study: In order to examine the trained neural network, it was assumed that the distance between two edges is constant at all elevations and then the predicted diameters were plotted along i. Figure 13 shows the predicted diameters assuming d´ = 1000, 1100, 1200 and 1300 pixels. As expected from distortion of the image, the obtained diameter is higher at the middle elevations. It can be concluded that the train network has learned the distortion features.
METHOD OF CALCULATING SAMPLE VOLUME
After the vertical boundaries of the samples were determined using the above mentioned procedure, the uppermost and lowermost limits of the sample were determined. This could be done manually on the computer screen. In order to make the Baseline and down boundaries of the sample more obvious, it is possible to paste a black tape on the membrane on the bottom and Baseline of the sample. Then the position of the tape borders could easily be detected by the edge detection method. In each row (a constant value of i) number of pixels located between the left and right sample boundaries were determined (d´). The actual diameter was calculated by the neural network simulation using the corresponding d´ and i values. As described above, each pixel had a height of Δh = 1.70/291 cm, therefore, each increment of sample volume is:
(5) |
Summing ΔVi from the lowermost to the uppermost limits of the sample yields the total volume of the samples:
(6) |
In cases where the sample remained symmetrical throughout the test, the image from one camera would be enough to calculate the volume but if the diameters obtained by two cameras did not agree which each other, the averaged diameters were used.
COMPARISON WITH CONVENTIONAL METHOD
To verify the accuracy of the proposed approach an isotropic compression test on saturated specimens of Shiraz silty clay are presented.
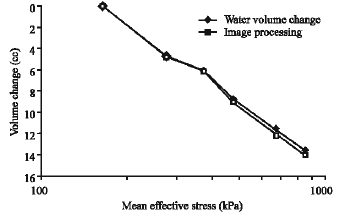 | |
| Fig. 14: | Volume change results from image processing and conventional method (isotropic compression test on Shiraz silty clay) |
The sample was 5 cm in diameter and its height was 10 cm. At the beginning of the test the sample was saturated. The initial cell pressure was 200 kPa and the pore water pressure was 50 kPa throughout the test. The cell pressure was increased by a stepped loading procedure. After each increment of cell pressure, the sample was allowed to complete its primary consolidation. The amount of water expelled from the sample was recorded throughout the test. The sample volume change was also measured with the proposed image processing technique. Figure 14 shows the volume change of the sample obtained using the two procedures. The results of both methods match with a good degree of accuracy. Therefore, the proposed method can successfully be applied for unsaturated soils in which the amount of water expelled from the sample is not equal to the sample volume change.
CONCLUSION
In this study, a new technique for measuring the volume change of soil samples in a triaxial test was presented. This method is especially useful for unsaturated soil tests in which the conventional method of using the pore-water volume exchange cannot be used to determine the total volume change. One of the major challenges in image processing technique is the accurate detection of the edges of the specimen. The proposed method, based on Haar wavelet transform, could accurately trace the sample boundaries. In comparison with conventional edge detection methods, this method can effectively distinguish the real edges from noise or texture. Refraction of light in water and plexiglass causes magnification and distortion of the image. In this paper it was found that the pattern of distortion is completely complex such that it could not be calibrated by conventional regression models. The proposed approach using neural network model could be employed to account for this effect with a good degree of accuracy and hence the corresponding errors are eliminated from the test results. The results of volume change measurements with this method showed good agreement with the amount of water exchange in saturated samples.
REFERENCES
- Adeli, H., 2001. Neural networks in civil engineering: 1989-2000. Comput-Aided Civ. Infrastruct., 16: 126-142.
Direct Link - Alshibli, K.A. and M.Z. Al-Hamdan, 2001. Estimating volume change of triaxial soil specimens from planar images. Comput-Aided Civ. Infrastruct., 16: 415-421.
Direct Link - Bagherieh, A.H., J.C. Hower, A.R. Bagherieh and E. Jorjani, 2008. Studies of the relationship between petrography and grindability for Kentucky coals using artificial neural network. Int. J. Coal Geol., 73: 130-138.
Direct Link - Ekpar, F., M. Yoneda and H. Hase, 2003. Correcting distortion in panoramic images using constructive neural networks. Int. J. Neural Syst., 13: 239-250.
CrossRefDirect Link - Gachet, P., F. Geiser, L. Laloui and L. Vulliet, 2007. Automated digital image processing for volume change measurement in triaxial cells. Geotech. Test. J., 30: 98-103.
CrossRefDirect Link - Habibagahi, G. and A. Bamdad, 2003. A neural network framework for mechanical behavior of unsaturated soils. Can. Geotech. J., 40: 684-693.
CrossRefDirect Link - Heric, D. and D. Zazula, 2007. Combined edge detection using wavelet transform and signal registration. Image Vision Comput., 25: 652-662.
CrossRefDirect Link - Macari, E.M., J.K. Parker and N.C. Costes, 1997. Measurement of volume changes in triaxial tests using digital imaging techniques. Geotech. Test. J., 20: 103-109.
Direct Link - Mallat, S. and W.L. Hwang, 1992. Singularity detection and processing with wavelets. IEEE. Trans. Inform. Theor., 38: 617-643.
CrossRef - Ng, C.W.W., L.T. Zhan and Y.J. Cui, 2002. A new simple system for measuring volume changes in unsaturated soils. Can. Geotech. J., 39: 757-764.
Direct Link - Sivakumar, R., V. Sivakumar, J. Blatz and J. Vimalan, 2006. Twin-cell stress path apparatus for testing unsaturated soils. Geotech. Test. J., 29: 175-179.
Direct Link - Smith, L.N. and M.L. Smith, 2005. Automatic machine vision calibration using statistical and neural network methods. Image Vision Comput., 23: 887-899.
Direct Link - Yin, Y., 2003. A double cell triaxial system for continuous measurement of volume changes of an unsaturated or saturated soil specimen in triaxial testing. Geotech. Test. J., 26: 353-358.
Direct Link