
Kouame Kan Benjamin
Groupe Modelisation de l`Information et des Processus, Laboratoire des Procedes Industriels, de Synthese et Environnement, Institut National Polytechnique Houphouet-Boigny, BP 1313 Yamoussoukro, Cote d`Ivoire
Assidjo N. Emmanuel
Groupe Modelisation de l`Information et des Processus, Laboratoire des Procedes Industriels, de Synthese et Environnement, Institut National Polytechnique Houphouet-Boigny, BP 1313 Yamoussoukro, Cote d`Ivoire
Akaki David
Groupe Modelisation de l`Information et des Processus, Laboratoire des Procedes Industriels, de Synthese et Environnement, Institut National Polytechnique Houphouet-Boigny, BP 1313 Yamoussoukro, Cote d`Ivoire
Yao K. Benjamin
Groupe Modelisation de l`Information et des Processus, Laboratoire des Procedes Industriels, de Synthese et Environnement, Institut National Polytechnique Houphouet-Boigny, BP 1313 Yamoussoukro, Cote d`Ivoire
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 12 | Page No.: 2272-2278







ABSTRACT
This study presents the use of genetic algorithm methodology for identification of a micro-organism mixture batch fermentation process. This process is described by complex and nonlinear differential equations according the mass balance. The parameters of the model are estimated using a multi-objective genetic algorithm. Simulations of the model obtained show accuracy in prediction behaviour of the model.
PDF Abstract XML References Citation
How to cite this article
Kouame Kan Benjamin, Assidjo N. Emmanuel, Akaki David and Yao K. Benjamin, 2008. Genetic Algorithms Using for a Batch Fermentation Process Identification. Journal of Applied Sciences, 8: 2272-2278.
DOI: 10.3923/jas.2008.2272.2278
URL: https://scialert.net/abstract/?doi=jas.2008.2272.2278
DOI: 10.3923/jas.2008.2272.2278
URL: https://scialert.net/abstract/?doi=jas.2008.2272.2278
INTRODUCTION
Fermentation processes are very complex and their modelling is rather a challenging task (Assidjo et al., 2006; Coleman et al., 2003; García-Ruiz et al., 2008). Indeed, dynamic models for industrial fermentations processes are difficult to identify because of a wide varieties of reasons e.g., micro-organisms complex dynamics, variables and ill-defined raw materials, varying inocula quality (Assidjo et al., 2006; Coleman et al., 2003; Garcia-Ruiz et al., 2008). However, their study was intensively investigated and different models proposed for control (Moore et al., 2001; Marin, 1999). A good model must take into account the effects of substrate limitation, substrate and products inhibition as well as maintenance energy and cells death on the cell growth and metabolism (Moore et al., 2001).
However, is neither necessary nor desirable to construct comprehensive mechanistic process models that can describe the systems in all possible situations with a high accuracy.
In this intention, many mathematical models have been proposed to predict the influence of fermentation operating parameters on cell growth rate, cell concentration (biomass), substrate utilisation rate (Sarkar and Modak, 2005; Trelea et al., 2004). The use of these models may lead to the development of better strategies for the optimisation of the fermentation process to ensure its economic viability. In fact, few fermentation models have been used for industrial scale fermentation optimisation (Nandasana and Kumar, 2008).
Genetic algorithms have been widely used for opTab2timisation and system identification. They are robust, global and generally more straightforward to apply in situation where there is little or no a priori knowledge about the process to be controlled (Nandasana and Kumar, 2008; Sarkar and Modak, 2005; Goldberg, 1989). They are stochastic search technique for approximating optimal solution within complex search spaces. They are based upon the analogy with biological evolution, in which the fitness of individual determines its ability to survive and reproduce. Their mechanism, as shown in Fig. 1, starts by encoding the problem to produce a list of genes (Yao et al., 2007; Davis, 1991). The genes are represented by either numeric or alphanumeric characters. The genes are randomly combined to give a population of chromosomes, each of which represents a possible solution. Genetic operations are performed on chromosomes that are randomly selected from the population producing therefore offspring (Yao et al., 2007; Polifke et al., 1998). The fitness of these chromosomes is measured and the probability of their survival is determined. In this study, a genetic algorithm has been used for a batch fermentation parameters identification.
MATERIALS AND METHODS
Data collection and treatment: The brewing fermentations were performed using a Brunswick microferm fermentor (New Brunswick Scientific Co. Inc., New Jersey, USA), in batch mode. This micro-fermentor is characterised by a volume of about 15 L. Its vessel internal diameter is 10 cm and its height is 50 cm.
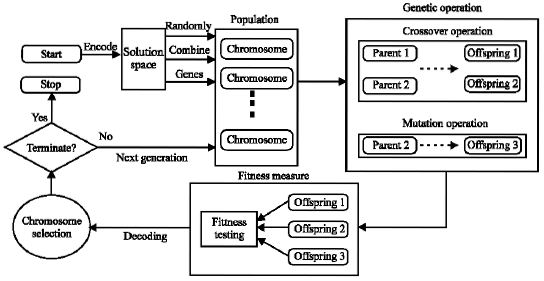 | |
| Fig. 1: | Flowchart of genetic algorithm process |
The wort was produced by crushing the malt into coarse flour, which was then mixed with water. The resulting porridge-like mash was heated to a selected temperature that permitted the malt enzymes to partially solubilize the ground malt. The resulting sugar-rich aqueous extract (wort), was then separated from the solids and boiled. The wort was then clarified, cooled and poured in the vessel of the micro-fermentor for inoculation. Inoculated ferments were traditionally produced by female brewers that use it for a well-known local beer (tchapalo or dolo) making. This ferment is in fact a mixture of micro-organisms containing different species (e.g., Saccharomyces cerevisae and Candida). During the fermentation process (t = 0 to 18 h), different parameters (pH, biomass, substrate, ethanol, carbon dioxide) were measured. The responses concerned in this study (biomass, substrate and alcohol (ethanol)) were determined by gravimetric and refractometric methods and refractometric method after a distillation, respectively (Thonart, 2001).
For the purpose of this study, 30 batches were performed.
Statistical analysis: In order to eliminate eventual outlier fermentations and because of the trilinear form of data (batchesxtimexresponses), a PARAFAC analysis was performed.
PARAFAC is a multi-way decomposition method originating from psychometrics (Rutledge and Bouveresse, 2007; Khayamian, 2007). It is gaining more interest in chemometrics and associated areas for many reasons: simply increased awareness of the method and its possibilities, the increased complexity of the data dealt with in science and industry and increased computational power (Geladi, 1989; Rutledge and Bouveresse, 2007).
PARAFAC decomposes the array into sets of scores and loadings, which describe the data in a more condensed form than the original data array. It conceptually can be compared to bilinear PCA, or rather it is one generalization of bilinear PCA (Smilde, 1992; Bouveresse et al., 2007). This technique is designed to decompose higher order data tables (e.g., cubes), again to reveal the underlying, latent phenomena for the purpose of data analysis and predictions.
The decomposition of the data is made into trilinear components, but instead of one score vector and one loading vector as in bilinear PCA, each component consists of one score vector and two loading vectors (Bouveresse et al., 2007). It is common three-way practice not to distinguish between scores and loadings as these are treated equally numerically.
Therefore, a PARAFAC model of a three-way array is given by three loading matrices, A, B and C with elements aif, bjf and ckf. The trilinear model is found to minimize the sum of squares of the residuals, eijk in the model:
(1) |
The advantage of the PARAFAC model is the uniqueness of the solution, meaning that no restrictions are necessary to identify estimate the model apart from trivial variations of scale and column order (Bouveresse et al., 2007). Therefore the true and estimated models must coincide when the right number of components is chosen.
Leurgans et al. (1993) have shown that unique solutions can be expected if the loading vectors are linear independent in two of the modes and furthermore in the third mode the less restrictive condition is that no two loading vectors are linearly dependent. In PARAFAC, one does not deflate the array, because the trilinear model calculated simultaneously for all components can be shown to fit the array better, than if the components were calculated successively as is possible in PCA (Mortensen and Bro, 2006; Leurgans et al., 1993). As a consequence, extracting too many components does not only mean that noise is being increasingly modeled, but also that the true factors are being modeled by more (correlated) components.
In this study, calculations were performed using Matlab R2007b (MathWorks Inc., Massachusetts, USA) software.
Process description: Batch fermentation refers to a partially closed system in which most of required material for micro-organisms growth and maintenance are loaded before process starts. Conditions during fermentation are continuously changing with time leading the fermentor being an unsteady state system (Roeva et al., 2004).
In alcoholic brewing fermentation, the micro-organisms (biomass) concentration is the central feature affecting the rate of growth, substrate consumption and product formation (Trelea et al., 2004). Growth and alcohol formation rates vary with time due to a dependence on the present state of the batch which is characterised by biomass, substrate and product concentrations, oxygen tension and culture conditions (Roeva et al., 2004; Thonart, 2001).
The model developed herein is based on the assumptions that:
| • | The bioreactor is completely mixed. |
| • | The substrate is consumed mainly oxidatively and its consumption can be described by Monod kinetics. |
| • | The ethanol production is assumed to be directly linked to the biomass formation. |
| • | Variations in the growth rate, ethanol production and substrate consumption do not significantly change the elemental composition of biomass. |
The rates of cells growth, substrate consumption, ethanol formation as well as carbon dioxide concentration in batch fermentation are commonly described according to the mass balance (Thonart, 2001):
(2) |
(3) |
(4) |
(5) |
The specific growth rateμ is generally found to be function of three factors: the limiting concentration of substrate, the maximum growth rateμmax and the substrate specific constant Ks.
If taking account realistic aspects of the process:
| • | Substrate limitation |
| • | Ethanol and substrate inhibition |
| • | Lag phase… |
The model drawn is as follows:
Lag phase
(6) |
(7) |
(8) |
Fermentation phase
(9) |
(10) |
(11) |
(12) |
(13) |
The parameters
(14) |
(15) |
(16) |
(17) |
(18) |
This model was developed by Andres-Toro et al. (2004) who have adjusted it to laboratory scale experimental data. It takes account three components of the biomass: lag, active and dead cells and consider the active cells as the only fermentation agent. The model also includes sugar and ethanol concentrations and two important by-products of the fermentation that degrade beer quality: ethyl acetate and diacetyl.
The system identification is achieved by determining parameters like Km, Ka,μx0,μd0…
RESULTS AND DISCUSSION
Outlier determination: As described earlier, a PARAFAC decomposition was made; scores and loadings, for time, batches and responses, were drawn. Loadings (B) concerning batches are shown in Fig. 2 with the 95% confidence ellipse.
The analysis of Fig. 2 shows that data were regrouped in a set of batches inside the ellipse contour. Unfortunately, 2 batches are isolated from the others and out of this ellipse. These outlier (Johnson and Wichern, 1992) batches were removed from data set prior process identification.
Parameter identification: Identifying parameters represents a very difficult task to elucidate. In general, conventional methods, as simplex, are local optimisation methods based on gradient determination; supposing that functions must be derivable. Moreover, conventional search techniques are often incapable of optimising non-linear multi-modal functions. In such cases, a random and global search method might be required. Genetic algorithms do not use much knowledge about the problem to be optimised. They work with codes, which represent the problem parameters (i.e.,μx0, μs0, Ks,μa0, Ka, μlag, Km,μd0).
The differential (6-13) and parameters (14-18) equations and initial values were implemented in a script under Matlab R2007b (MathWorks Inc., Massachusetts, USA) environment. Differential equations were resolved using Runge-Kutta 4th order algorithm at specified time (e.g., 0, 1, 2, 3, 4, 5 … h).
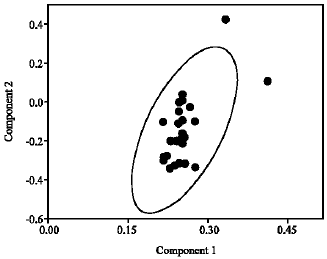 | |
| Fig. 2: | Batches projection on PARAFAC components |
| Table 1: | Initial conditions of genetic algorithms |
 | |
In order to optimise the batch fermentation modelled, another script containing the necessary instructions for the genetic algorithm toolbox has been developed. In this script, some initial parameters needed in the genetic algorithm toolbox were defined, e.g., individual number, generation maximum number, crossover and mutation rates, selection function…
In order to implement the genetic algorithm, the model parameters (e.g., Ks, Km,μlag,μd0…) have to be presented as chromosomes. Decimal numbers ranging from 0 to 20 for the parameters values have been used to represent this principle. Each chromosome corresponds to a possible solution of the objective function. Generally, this function is expressed as the modelling error i.e., the mean square deviation between the model output and the corresponding data obtained during the fermentation. Therefore, the optimisation criteria are as follows:
(19) |
with Yc the calculated value and Yo its corresponding observed one, respectively for biomass, substrate and alcohol.
Initial tests were performed using conditions shown in Table 1.
After several and different runs, the conditions retained are as follows:
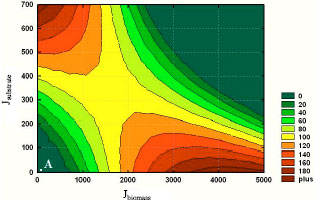 | |
| Fig. 3: | Contour plot of Pareto solutions |
| Table 2: | Values of parameters after identification |
 | |
| • | Population size = 50 |
| • | No. of generations = 100 |
The release R2007b of Matlab integrates in genetic toolbox the possibility of optimising multi-objective function (Mathworks, 2007). The solutions called Pareto solutions for the three functions (JBiomass, JSubstrate and JAlcohol) are shown in Fig. 3 in contour plot.
Glancing at Fig. 3, it appears that two optimal regions are represented concerning the JAlcohol criterion. But if taking account the other criteria (i.e., JBiomass and JSubstrate), the optimal region to consider is the lower green one ranging from 0 to 800 for JBiomass and from 0 to 200 for JSubstrate. The retained point (i.e., point A in the Fig. 3) that is a good compromise of different functions minimum is situated in this zone. This point corresponds to parameters shown in Table 2.
In this case, the values of the criteria are:
JBiomass = 44.982, JSubstrate = 9.724 and JAlcohol = 7.604.
Figure 4 shows the experimental and predicted values of, respectively biomass, substrate (i.e., glucose) and ethanol (alcohol).
These different phases were already extensively described in literature: the lag-phase during where micro-organisms adapt themselves to the culture medium; the active phase or exponential phase during which the yeasts multiply themselves exponentially, consuming sugar and producing alcohol.
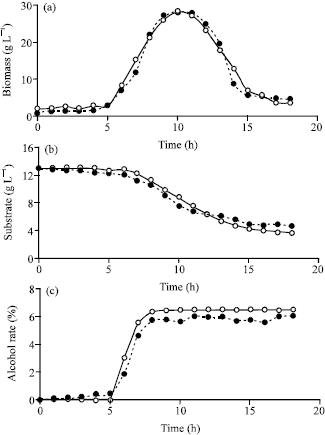 | |
| Fig. 4: | Model (○) and experimental (●) data plot, (a) Biomass, (b) Substrate and (c) Alcohol |
The decrease of yeast number in suspension is due to their fall down in fermentation tank confirming therefore, the lower fermentation type.
The global analysis of prevision shows in Fig. 4a-c) points out the good ability of the model to predict successfully the variation of substrate consumption, biomass concentration and alcohol production. Indeed, the model obtained gives values very close to the observed ones, whatever the response concerned during the fermentation studied.
CONCLUSION
In this research, the model developed by Andrés-Toro et al. (2004) for beer fermentation was proposed to fit a batch fermentation by micro-organism mixture data. The study is accomplished through the formulation of the identification problem as an optimisation problem and the application of multi-objective genetic algorithm in order to estimate the unknown parameters from input-output space.
The simulations operated thereby, concerning the substrate consumption, biomass concentration and the alcohol production, validate the predictions of the genetic algorithm formalism with a good accuracy. Therefore, the multi-objective genetic algorithm methodology presented in this paper offers a cost-effective and relatively simple alternative for process modelling and optimization.
NOMENCLATURE
| μ | : | Specific growth rate (h1) |
| μa | : | Alcohol production rate (h1) |
| μa0 | : | Specific alcohol production rate (h1) |
| μd | : | Yeast settling down rate (h1) |
| μd0 | : | Specific yeast settling down rate (h1) |
| μlag | : | Specific rate of latent formation (h1) |
| μmax | : | Maximum growth rate (h1) |
| μs | : | Substrate consumption rate (h1) |
| μs0 | : | Specific substrate consumption rate (h1) |
| μx | : | Yeast growth rate (h1) |
| μx0 | : | Specific yeast growth rate (h1) |
| e | : | Concentration of the alcohol (g L1) |
| f | : | Fermentation inhibitor factor |
| Ka | : | Alcohol inhibition parameter |
| Km | : | Yeast growth inhibition parameter |
| Ks | : | Sugar inhibition parameter |
| ms | : | Maintenance constant (g g1 h1) |
| P | :: | Concentration of the product (g L1) |
| S | : | Concentration of the substrate (g L1) |
| Si | : | Initial concentration of substrate (g L1) |
| X | : | Concentration of biomass (g L1) |
| xact | : | Concentration of active biomass (g L1) |
| xbot | : | Concentration of bottom biomass (g L1) |
| xi | : | Initial concentration of biomass (g L1) |
| xlag | : | Concentration of latent biomass (g L1) |
| Yp/x | : | Yield coefficient (g g1) |
| Yx/s | : | Yield coefficient (g g1) |
REFERENCES
- Andrés-Toro, B., J.M. Girón-Sierra, P. Fernández-Blanco, J.A. López-Orozco and E. Besada-Portas, 2004. Multiobjective optimization and multivariable control of the beer fermentation process with the use of evolutionary algorithms. J. Zhejiang Univ. Sci., 5: 378-389.
Direct Link - Assidjo, E., B. Yao, D. Amane, G. Ado, C. Azzaro-Pantel and A. Davin, 2006. Industrial brewery modelling by using artificial neural network. J. Applied Sci., 6: 1858-1862.
CrossRefDirect Link - Bouveresse, D.J.R., H. Benabid and D.N. Rutledge, 2007. Independent component analysis as a pretreatment method for parallel factor analysis to eliminate artefacts from multiway data. Anal. Chem. Acta, 589: 216-224.
Direct Link - Coleman, M.C., K.K. Buck and D.E. Block, 2003. An integrated approach to optimization of Escherichia coli fermentations using historical data. Biotechnol. Bioeng., 84: 274-285.
Direct Link - Garcia-Ruiz, A., B. Bartolome, A.J. Martinez-Rodriguez, E. Pueyo, P.J. Martin-Alvarez and M.V. Moreno-Arribas, 2008. Potential of phenolic compounds for controlling lactic acid bacteria growth in wine. Food Control, 19: 835-841.
CrossRefDirect Link - Geladi, P., 1989. Analysis of multi-way (multi-mode) data. Chemomet. Intell. Lab. Syst., 7: 11-30.
CrossRef - Khayamian, T., 2007. Robustness of PARAFAC and N-PLS regression models in relation to homoscedastic and heteroscedastic noise. Chemomet. Intell. Lab. Syst., 88: 35-40.
Direct Link - Leurgans, S., R.T. Ross and R.B. Abel, 1993. A decomposition for three-way arrays. SIAM J. Matrix Anal. Applied, 14: 1064-1083.
CrossRefDirect Link - Marin, M.R., 1999. Alcoholic fermentation modelling: Current state and perspectives. Am. J. Enol. Vitic., 50: 166-178.
Direct Link - Mortensen, P.P. and R. Bro, 2006. Real-time monitoring and chemical profiling of a cultivation process. Chemomet. Intell. Lab. Syst., 84: 106-113.
Direct Link - Nandasana, A.D. and S. Kumar, 2008. Kinetic modelling of lactic acid production from molasses using Enterococcus faecalis RKY1. Biochem. Eng. J., 38: 277-284.
Direct Link - Polifke, W., W. Geng and K. Dobbeling, 1998. Optimization of rate coefficients for simplified reaction mechanisms with genetic algorithms. Combust. Flame, 113: 119-134.
CrossRef - Roeva, O., T. Pencheva, B. Hitzmann and S. Tzonkov, 2004. A genetic Algorithms Based Approach for identification of Escherichia coli Fed-batch fermentation. Bioautomation, 1: 30-41.
Direct Link - Rutledge, D.N. and D.J.R. Bouveresse, 2007. Multi-way analysis of outer product arrays using PARAFAC. Chemomet. Intell. Lab. Syst., 85: 170-178.
Direct Link - Sarkar, D. and J.M. Modak, 2005. Pareto-optimal solutions for multi-objective optimization of fed-batch bioreactors using nondominated sorting genetic algorithm. Chem. Eng. Sci., 60: 481-492.
Direct Link - Smilde, A.K., 1992. Three-way analyses. Problems and prospects. Chemomet. Intell. Lab. Syst., 15: 143-157.
CrossRef - Trelea, I.C., M. Titica and G. Corrieu, 2004. Dynamic optimisation of the aroma production in brewing fermentation. J. Proc. Control, 14: 1-16.
Direct Link - Yao, K.B., N.E. Assidjo, G. Ado, Azzaro-Pantel C. and D. Andre, 2007. Modelling and optimization of M-cresol isopropylation for obtaining N-thymol: Combining a hybrid artificial neural network with a genetic algorithm. Int. J. Chem. Reactor Eng., 5: A870-A870.
Direct Link