
M. Mohammadi
No. 424, Hafez Ave, Department of Electrical Engineering,
Amirkabir University of Technology, 15914, Tehran, Iran
G.B. Gharehpetian
No. 424, Hafez Ave, Department of Electrical Engineering,
Amirkabir University of Technology, 15914, Tehran, Iran
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 12 | Page No.: 2226-2233







ABSTRACT
This study presents a multi-class Support Vector Machine (SVM) based method for on-line static security assessment of power systems. To classify the system security status, a group of binary SVMs have been trained. The multi-class Fisher score has been used for feature selection algorithm and the data selection has been done based on the confidence measure, to reduce the problem size and consequently to reduce the training time. The proposed method has been applied to New England 39-bus power system. The simulation results demonstrate the effectiveness and stability of the proposed method for on-line static security assessment procedure of large scale power systems.
PDF Abstract XML References Citation
How to cite this article
M. Mohammadi and G.B. Gharehpetian, 2008. Power System On-Line Static Security Assessment by Using Multi-Class Support Vector Machines. Journal of Applied Sciences, 8: 2226-2233.
DOI: 10.3923/jas.2008.2226.2233
URL: https://scialert.net/abstract/?doi=jas.2008.2226.2233
DOI: 10.3923/jas.2008.2226.2233
URL: https://scialert.net/abstract/?doi=jas.2008.2226.2233
INTRODUCTION
The present trend towards deregulation has forced modern electric utilities to operate their systems under stressed operating conditions closer to their security limits. Under these conditions, any disturbance could endanger the system security. The static security of the power system is defined as the ability of the system, following a contingency, to reach an operating state within the specified safety and supply quality (Kirschen, 2002). As a result, the security evaluation is a major concern in the operation of modern power systems and there is a pressing need to develop fast on-line security monitoring method which could analyze the level of security and forewarn the system operators to take necessary preventive actions.
The evaluation of the present status of the power system and the impact of possible line or generator outage on the system security can be determined by solving the nonlinear load flow equations for all possible contingencies or for those ranked as the most important cases (Kirschen, 2002). These numerical methods are time consuming and therefore are not suitable for on-line applications.
The application of machine learning methods for on-line security assessment has been proposed by many researchers. For fast static security assessment Artificial Neural Networks (ANN) (Neibur and Germond, 1991; Shanti, 2008; Zhou et al., 1994; Wehenkel, 1998), Decision Trees (DT) (Wehenkel, 1998; Hatziargyriou et al., 1994) and Bayesian classifiers (Kim and Singh, 2005) have been suggested.
The most popular method is ANN, because of its ability to classify patterns and its good accuracy in comparison with other machine learning methods. Its disadvantages can be listed as follows:
| • | It requires an extensive training process and a complicated design procedure |
| • | If some components of the pattern vector are strongly correlated, the methods become inaccurate and an accurate feature extraction must be performed to hopefully yield an uncorrelated set of components |
| • | Although neural networks are good in interpolation but not good in extrapolation. Training sets have to represent the different states of the power system. This means that they need to comprise the complete pattern space of the secure and insecure power system operation. A large training set of input data is necessary, to provide the best results in the output. |
Recently, Support Vector Machines (SVM), based on statistical learning theory, have been used in the different areas of machine learning, computer vision and pattern recognition, because of their high accuracy and good generalization capability (Vapnik, 1999; Platt, 1998). The main difference between ANN and SVM is in the principle of risk minimization (Scholkopf, 1998). In the case of SVM, Structural Risk Minimization (SRM) principle is used to minimize an upper bound on the expected risk. But for ANN, traditional Empirical Risk Minimization (ERM) is used to minimize the error on the training data. This difference leads to a better generalization performance for SVM. The SVM has following advantages, too:
| • | The global optimum can be derived |
| • | The over-fitting problem can be easily controlled by the choice of a suitable data separation margin |
| • | The SVM algorithm is less sensitive to the size of input features and does not need to extract signal features |
| • | SVM only needs a small quantity of samples to train the classifier |
The application of SVM for dynamic security assessment has been reported by Moulin et al. (2004) and Wahab et al. (2007). In these references, the superior performance of SVM over ANN in terms of accuracy, speed and distribution of high-risk cases has been presented for a large scale power system transient stability.
In this study, different status for system security levels such as normal (class A), alert (class B), emergency 1 (class C), emergency 2 or system splitting status (class D); have been considered and a multi-class SVM has been used to classify the power system security.
The feature selection is one of the important steps in the classification problem. In this study, Fisher-like criterion (F-score) has been used for feature selection; also a data preprocessing procedure to select SVs candidates has been used, too.
SVM: SUPPORT VECTOR MACHINE
SVM has been introduced by Vapnik in the late 1960s on the foundation of statistical learning theory (Vapnik, 1999). However, since the middle of 1990s, the algorithms used for SVM have been started emerging with greater availability of computing power, paving the way for numerous practical applications.
Binary SVM formulation: The basic SVM deals with two-class problems, in which the data are separated by a hyper-plane defined by a number of Support Vectors (SVs). The performance of the SVM can be explained easily in two-dimensional plane, as shown in Fig. 1, without any loss of generality. This Fig. 1 shows a set of points for two different classes of data; circles (class A) and squares (class B).
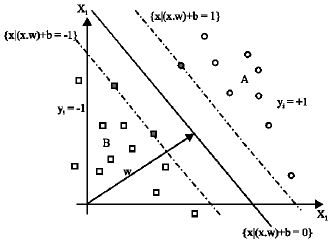 | |
| Fig. 1: | SVM based classification of data |
The SVM attempts to place a linear boundary (solid line in Fig. 1) between the two different classes and shifts it to maximize the margin (dotted lines in Fig. 1). The distance between the boundary and the nearest data point in each class must be maximized. The boundary is then placed in the middle of this margin. The nearest data points, used to define the margins, are known as Support Vectors (gray circle and square in Fig. 1). Once the Support Vectors (SVs) are selected, the rest of the points can be discarded, since the SVs contain all the necessary information for the classifier.
The boundary can be expressed by the following equation:
(1) |
Where, the vector w defines the boundary, x is the input vector of dimension N and b is a scalar threshold. At the margins, where the SVs are located, we have:
(2) |
and
(3) |
As Svs correspond to the extremities of the data for a given class, the following decision function can be used to classify any data point in either class A or class B:
(4) |
The optimal hyper-plane separating the data can be obtained as a solution to the following optimization problem (Scholkopf, 1998):
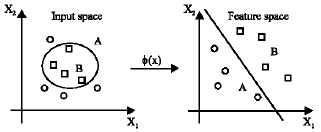 | |
| Fig. 2: | Non-linear separation of input data and linear separation in feature space |
(5) |
(6) |
Where, l is the size of the training set.
The solution of the constrained optimization problem can be obtained as follows (Scholkopf, 1998):
(7) |
Where, xi are SVs obtained from training. Substituting Eq. 2 in Eq. 4, the decision function can be obtained as follows:
(8) |
In cases where the linear boundary can` not properly separate two classes, it is possible to create a hyper-plane that allows linear separation in the higher dimension. In SVM, this is achieved by using the transformation φ(x). This transformation converts the data from an N-dimensional input space (x) to a Q-dimensional feature space as follows:
(9) |
Where, x ∈ RN and s ∈ RQ. Figure 2 shows the transformation from the input space to the feature space where the non-linear boundary has been transformed into a linear boundary in the feature space.
Substituting the transformation Eq. 9 in Eq. 8 gives the decision function as follows:
| | (10) |
The transformation into higher-dimensional feature space is relatively computation-intensive. A kernel can be used to perform this transformation and the dot product in a single step provided the transformation can be replaced by an equivalent kernel function. This point helps in reducing the computational load and at the same time retaining the effect of higher-dimensional transformation. The kernel function, K(x, x`), is defined by the following equation:
(11) |
The basic form of SVM is accordingly obtained after substituting Eq. 11 in the decision function, i.e., Eq. 10. As a result, we have:
(12) |
In Eq. 12, the parameter vi (0<8) are used as a weighting factor to determine which of the input vectors actually are SVs. There are different kernel functions. Some of the commonly used kernel functions are polynomial, Gaussian Radial Basis Function (RBF), Exponential Gaussian Radial Basis Function (ERBF) and sigmoid kernels which are presented in Eq. 13-16, respectively (Scholkopf, 1998).
(13) |
(14) |
(15) |
(16) |
Multi-class support vector machine: SVM has been originally designed for binary classification. There are two approaches for multi-class SVM. The first one is based on the construction and the combination of several binary classifiers while the other one can directly consider all data in one optimization formulation. In general, it is computationally more expensive to solve a multi-class problem than a binary problem with the same number of data. Therefore, methods based on constructing and combining several binary classifiers are preferable to methods based on solving a multi-class problem (Hsu and Lin, 2002).
The most popular algorithms, which are based on several binary classifiers, are: One-Against-All (OAA) (Vapnik, 1998), One-Against-One (OAO) (Platt et al., 1999), Direct-Acyclic-Graph (DAG) (Krebel, 1999) and Half-Against-Half (HAH) algorithms (Lei and Govindaraju, 2005).
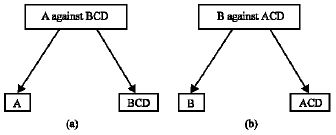 | |
| Fig. 3: | OAA; Multi-class SVM classifiers (a) class A against others and (b) class B against others |
One-against-all algorithm: The earliest used implementation for SVM multi-class classification is probably the One-Against-All (OAA) algorithm (Vapnik, 1998). It constructs k SVM models, where k is the number of classes. The ith SVM is trained with all of the examples in the ith class with positive labels and all other examples with negative labels. Figure 3 shows the multi-class SVM classifier by OAA for a four-class problem.
One-against-one algorithm: The One-Against-One (OAO) algorithm, constructs k(k-1)/2 classifiers where each one is trained on data from two classes (Platt et al., 1999).
There are different methods for doing the future testing after that all k(k-1)/2 classifiers are constructed. Most popular method is Max Wins strategy. In this strategy, if
says x is in the ith class, then the vote for ith class is added by one. Otherwise, the jth class vote is added by one. Finally we predicate that x is in the class with the largest vote.
Direct-acyclic-graph algorithm: The third algorithm, Direct-Acyclic-Graph (DAG), has been proposed by Krebel (1999). Its training phase is the same as the OAO algorithm. However, in the testing phase, it uses a root binary DAG which has k(k-1)/2 internal nodes and k levels. Each node is a binary SVM of ith and jth classes. Given a test sample x, starting at root node, the binary decision function is evaluated. Then it moves to either left or right depending on the output value. Figure 4 shows the DAG-SVM structure of a four-class problem.
Half-against-half algorithm: The latest algorithm is Half-Against-Half (HAH), which is built via recursively dividing the training data set of k classes into two subsets of classes. The structure of HAH is the same as a decision tree which at each node it has a binary SVM classifier that determines the class of a testing sample.
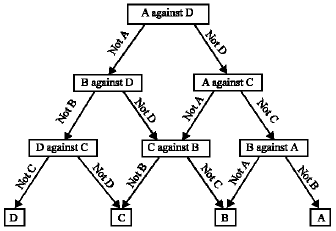 | |
| Fig. 4: | DAG structure for a four-class classification |
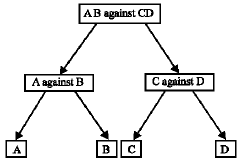 | |
| Fig. 5: | HAH classifier structure for a four-class problem |
The trained HAH classifier model consists of at most k binary SVM. If k is an even number it needs k binary SVM and if k is odd it needs (k-1) binary SVM. For each classification testing, HAH requires at most log2k binary SVM evaluations. Figure 5 shows the HAH classification structure of a four-class problem.
Both theoretical estimation and experimental results show that HAH has advantages over OAA, OAO and DAG based algorithms in the testing speed, the size of the classifier model and accuracy (Lei and Govindaraju, 2005). Considering these merits the HAH algorithm has been used in this paper.
PROPOSED ALGORITHM
The application of machine learning methods is based on our knowledge about the behavior of the system, obtained from a large number of off-line simulations. These simulations define two data sets; the training set and the testing set. The training data set is used to derive the security evaluation structure and the testing data set is used for testing the developed structures.
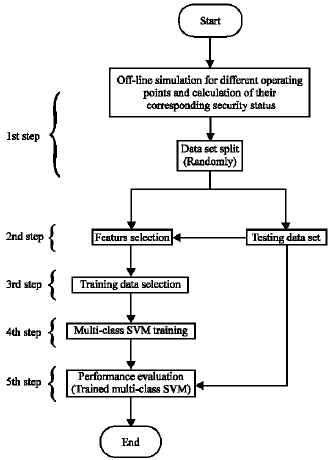 | |
| Fig. 6: | Flowchart of proposed algorithm |
The training data set should cover the entire demand space including hourly, daily and weekly variations of the system demand. Considering these points, the flowchart, shown in Fig. 6, has been proposed for static security assessment in this research.
Creation of knowledge base: The First step in the proposed algorithm shown in Fig. 6; is off-line simulations for different operating points of the system. In this step, the static security index will be calculated based on load flow results. Theses simulations must be carried out for different operating points at any contingency in the set of possible contingency set. In this study, the following Performance Index (PI) has been chosen to quantify the severity of a contingency and to classify the system security status. PI has been defined as follows (Kirschen, 2002):
(17) |
Where, Sl is the apparent power flow (MVA) of the line l, SlMAX is the maximum value of Sl, Nl is the number of lines in the system, n is the specified exponent of penalty function and wl is the real non-negative weighting coefficient (may be used to reflect the importance of some lines). In this study, n = 2 and wl = 1 (for all lines) have been selected.
In order to classify the system static security status, four different security levels have been considered; normal (class A), alert (class B), emergency 1(class C, correctable contingencies) and emergency 2 (class D, non-correctable contingencies or system splitting status). Based on the calculated PI index, the system security status can be determined.
Feature selection: Considering the following points, it can be said that one of the main aspects of the successful use of machine learning methods is the feature selection:
| • | Removing unnecessary or bad features can improve the accuracy of most machine learning algorithms |
| • | The feature selection does provide insights into the quality and productivity of each feature |
Several feature selection algorithms, such as Pearson`s correlation coefficient, Fisher-like criterion and Relief family, have been design for the feature selection (Guyon and Elisseeff, 2003; Jensen et al., 2001; Yang and Honavar, 1998).
In this study, Fisher-like criterion (F-score) has been used for feature selection considering its simplicity and accuracy. The Fisher score for a multi-class problem is defined as follows:
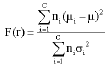 | (18) |
Where, ni is the number of data points in class i, μi and σi is the mean and variance of class i corresponding to the rth feature, respectively, C is the number of classes and μ is the mean value of the whole data set of the rth feature.
Training data selection: The next step in Fig. 6, is the training data selection. The data selection can be used for fast multi-class SVM training. The main point is the selection of the important data for SVM training. The SVM decision function depends only on a small subset of training data, called SVs. Therefore if one knows in advance which patterns correspond to SVs, the same solution can be obtained by solving a much smaller problem that involves only the SVs. According to Huanga et al. (2007) k-means clustering has been used for selecting patterns from the training set. According to Yeung et al. (2007). Mahalanobis distance has been used to identify SVs and boundary points. According to Wang et al. (2007) two data selecting algorithms have been proposed. In the first algorithm, the training data selection is based on a statistical confirm measure. In the second algorithm, the minimum distance from a training example to the training examples of a different class has been used as a criterion to select the important data.
The comparison of different data selection schemes with the scheme based on the decision SVM outputs, shows that the confidence measure provides a criterion for training data selection that is almost as good as the optimal criterion based on the desired SVM outputs. Also, it has been shown that the random sampling performance is not good in comparison with the confidence measure-based algorithm at low reduction rates (Wang et al., 2007).
In the confidence measure-based algorithm, a sphere centered at each training example xi, has been considered (Wang et al., 2007). This sphere should be as large as possible without covering a training example of a different class. The number of training examples that falls inside this sphere has been denoted by N(xi). Obviously, the larger, the number N(xi), the more training examples (of the same class as xi) will be scattered around xi, the less likely xi will be close to the decision boundary and the less likely xi will be a SV. Hence, this number can be used as a criterion to decide which training examples should belong to the reduced training set.
Based on this algorithm, N(xi) has been computed for each training point and then the training data have been sorted according to the corresponding value of N(xi). Finally, a subset of data with the smallest numbers N(xi), has been chosen as the reduced training set. In this algorithm, N(xi) should be computed for each training point.
Performance evaluation: The performance of the proposed method has been evaluated by using Sensitivity index of class i, (SNci), Precision Rate index of class i, (PRci)), for each class and Total Accuracy index (TA), as follows:
(19) |
(20) |
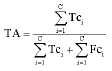 | (21) |
| Ci | = Index of classes |
| Tci | = No. of cases which are actually in class Ci and classified correctly by the trained SVM |
| Fci | = No. of cases which are actually in class Ci and the trained SVM classified in other classes by the trained SVM |
| Fcoi | = No. of the cases of other classes classified in class Ci, by the trained SVM |
| C | = No. of classes |
In the problem presented in this paper, the numbers of cases in different classes are not equal; therefore TA is not enough as a total performance evaluation index. For example, assume a test data set contains 40 class A, 30 class B, 20 class C and 10 class D cases. If all cases in class D have not been predicated correctly and all of the other cases have been predicated correctly, then TA is equal to 90%. It seems that TA doesn`t have enough information and a new evolution index for multi-class classification should be presented. In this paper, this new index is Balanced Error Rate (BER) as follows:
(22) |
CASE STUDY
In order to demonstrate the effectiveness of proposed technique, results of the application of the method to New England 39-bus power system have been presented. A contingency list consists of 8 single line outages has been considered. The load and generation of buses have been randomly changed between 30% up to 130% of their base case, resulting in 2125 different operating points. Among these operating points, 1500 points have been randomly chosen as the training data set and the remaining 625 cases have been used as the testing data set. In this study, the base case load is 6097 MW and system load has been changed from 1750 to 8250 MW.
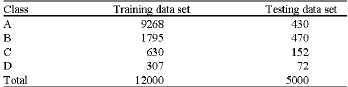
All contingencies have been simulated one by one and corresponding PI have been computed for each operating point. Based on calculated PI, the security status of each operating point for each contingency has been determined. The number of each class members in the training and testing data set is given in Table 1.
All contingencies have been simulated one by one and corresponding PI has been computed for each operating point. Based on calculated PI, the security status of each operating point for each contingency has been determined.
| Table 1: | No. of each class members |
 | |
| Table 2: | Results of fisher criteria feature selection |
 | |
The number of each class members in the training data set and testing data set is given in Table 1.
Feature selection: Line flows, currents, bus voltages and system other parameters can be selected as a system features. In this study, 46 active power flows on branches, 46 reactive power flows on branches, 39 bus voltages, 39 active power injections on buses, 39 reactive power injections on buses and a contingency identification number (an integer number among 1 to 8) have been considered as the input of the proposed feature selection algorithm.
The results of the first eight dominate features have been shown in Table 2.
Training data selection: Here, N(xi) has been computed for. The points with N(xi)<=2 have been selected for reduced training data set. Based on these assumptions, 4823 points have been selected for multi-class SVM training process.
Parameter tuning: The first step in the training of SVM classifier is to choose the kernel and its parameters. Four kernel functions have been mentioned in the section II. For the polynomial and sigmoid kernel functions, r = 0 and γ = 1/k have been chosen. Where k is the number of features (as a result, γ = 1/8). A grid search has been performed over the values of the penalty parameter, P for each kernel, the parameter d for polynomial kernel and parameter γ for RBF and ERBF kernels. Figure 7 and 8 give an example for the influence of penalty parameter P upon the prediction performance on training set. These search results show that the best result has been obtained by the ERBF kernel function. The parameters for each binary SVM have been presented in Table 3.
| Table 3: | ERBF kernel function parameters for each binary SVM |
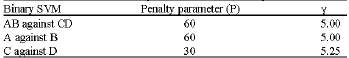 | |
| Table 4: | No. of SVs for each binary SVM |
 | |
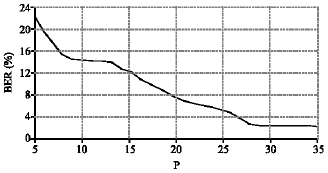 | |
| Fig. 7: | Influence of penalty parameter P upon the BER |
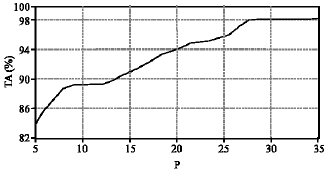 | |
| Fig. 8: | Influence of penalty parameter P upon the TA |
SVM training: Three binary SVM according to the HAH classifier structure have been trained. The number of the SVs for each binary SVM has been presented in Table 4.
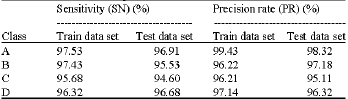
Performance evaluation: The SVM prediction results for the testing data set and all training data set have been shown in Table 5.
TA and BER for the testing data set are 98.71 and 0.63% and for the all training data set 96.51 and 2.14%, respectively.
In order to show the effectiveness of the training data selection algorithm, the multi-class SVM has been trained by using all of the training data set (1500 operating points). In this case, the training time has been approximately increased by ten times. Table 6 compares the number of the SVs for reduced training data set and all training data set. Table 6 shows that the proposed data selection algorithm can remove a significant amount of data while the trained binary SVMs are same.
| Table 5: | Multi-class SVM prediction results |
 | |
| Table 6: | No. of SVs for reduced training data set and all training data set |
 | |
CONCLUSION
A multi-class SVM based static security assessment algorithm for power system has been proposed. The proposed algorithm has been applied to New England 39-bus power system. It is shown that the proposed algorithm is less sensitive to the size of input features and it does not need to extract signal features. This property is very effective on power system monitoring and its measurements for the system security assessment.
Also, it needs only a small number of operating points to train the classifier (only support vectors). This capability is very useful to reduce the training data while maintaining the generalization performance of the resulting SVM classifiers and therefore the training time is reduced significantly.
REFERENCES
- Guyon, I. and A. Elisseeff, 2003. An introduction to variable and feature selection. J. Mach. Learn. Res., 3: 1157-1182.
Direct Link - Hatziargyriou, N., G.C. Contaxis and N.C. Sideris, 1994. A decision tree method for on-line steady state security assessment. IEEE Trans. Power Syst., 9: 1052-1061.
Direct Link - Hsu, C.W. and C.J. Lin, 2002. A comparison of methods for multi-class support vector machines. IEEE Trans. Neural Networks, 13: 415-425.
CrossRef - Huanga, J.J., G.H. Tzeng and C.S. Ong, 2007. Marketing segmentation using support vector clustering. Expert Syst. Appli., 32: 313-317.
Direct Link - Jensen, C.A., M.A. El-Sharkawi and R.J. Marks, 2001. Power system security assessment using neural networks: Feature selection using fisher discrimination. IEEE Trans. Power Syst., 16: 757-763.
Direct Link - Kim, H. and C. Singh, 2005. Power system probabilistic security assessment using bayes classifier. Elect. Power Syst. Res., 74: 157-165.
Direct Link - Moulin, L.S., A.P. Alves da Silva, M.A. El-Sharkawi and R.J. Marks, 2004. Support vector machines for transient stability analysis of large-scale power systems. IEEE Trans. Power Syst., 19: 818-825.
Direct Link - Neibur, D. and A. Germond, 1991. Power system static security assessment using Kohonen neural network classifier. IEEE Trans. Power Syst., 7: 865-872.
CrossRefDirect Link - Platt, J., N. Cristianini and J. Shawe-Taylor, 2000. Large margin DAGs for multiclass classification. Proc. Neural Inform. Process. Syst., 12: 547-553.
Direct Link - Scholkopf, B., 1998. SVMs-A practical consequence of learning theory. IEEE Intell. Syst., 13: 18-19.
Direct Link - Shanti, K.S., 2008. Artificial neural network using pattern recognition for security assessment and analysis. Neurocomputing, 71: 983-998.
CrossRefDirect Link - Vapnik, V.N., 1999. An overview of statistical learning theory. IEEE Trans. Neural Networks, 10: 988-999.
CrossRefDirect Link - Wahab, N.I.A., A. Mohamed and A. Hussain, 2007. Transient stability assessment of a power system using PNN and LS-SVM methods. J. Applied Sci., 7: 3208-3216.
CrossRefDirect Link - Wang, J., P. Neskovic and L.N. Cooper, 2007. Selecting data for fast support vector machine training. Stud. Comput. Intell., 35: 61-84.
Direct Link - Yang, J. and V. Honavar, 1998. Feature subset selection using a genetic algorithm. IEEE Intell. Syst., 13: 44-49.
CrossRefDirect Link - Yeung, D.S., D. Wang and E.C. Tsang, 2007. Weighted mahalanobis distance kernels for support vector machines. IEEE Trans. Neural Networks, 18: 1453-1462.
Direct Link - Zhou, Q., J. Davidson and A.A. Fouad, 1994. Application of artificial neural networks in power system security and vulnerability assessment. IEEE Trans. Power Syst., 9: 525-532.
CrossRefDirect Link