
Yousef ErfaniFard
Department of Forestry and Forest Economics, Faculty of Natural Resources, University of Tehran, Karaj, Iran
Jahangir Feghhi
Department of Forestry and Forest Economics, Faculty of Natural Resources, University of Tehran, Karaj, Iran
Mahmoud Zobeiri
Department of Forestry and Forest Economics, Faculty of Natural Resources, University of Tehran, Karaj, Iran
Manouchehr Namiranian
Department of Forestry and Forest Economics, Faculty of Natural Resources, University of Tehran, Karaj, Iran
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 1 | Page No.: 152-157







ABSTRACT
Regarding to the importance of Zagros forests and spatial pattern studies as a criterion to control changes and monitor forests, two main distance techniques were investigated in this research to suggest a suitable method to study the spatial pattern of trees in Zagros forests. In Kohgiluyeh Va Buyer Ahmad Province, a plot in Servak Forests near Yasuj was chosen as the study area. The 30 ha plot was surveyed by full callipering method and the position of each tree was determined via azimuth and distance measurement to prepare the point map of tree locations. Using Nearest Neighbor Index, the spatial pattern was determined as Dispersed. Then two main distance methods named T-square sampling and Index of dispersion were compared to figure out the most suitable one in the study area as a method of spatial pattern analysis. Comparing the results with the true distribution pattern of trees in the study area showed that T-square sampling is a robust index to detect spatial arrangement of trees.
PDF Abstract XML References Citation
How to cite this article
Yousef ErfaniFard, Jahangir Feghhi, Mahmoud Zobeiri and Manouchehr Namiranian, 2008. Comparison of Two Distance Methods for Forest Spatial Pattern Analysis (Case Study: Zagros Forests of Iran). Journal of Applied Sciences, 8: 152-157.
DOI: 10.3923/jas.2008.152.157
URL: https://scialert.net/abstract/?doi=jas.2008.152.157
DOI: 10.3923/jas.2008.152.157
URL: https://scialert.net/abstract/?doi=jas.2008.152.157
INTRODUCTION
Zagros forests cover a vast area of Zagros mountain ranges stretching from Piranshahr (Western Azerbaijan Province) in the northwest of the country to the vicinity of Firoozabad (Fars Province) having an average length and width of 1300 and 200 km, respectively. Classified as semi-arid, Zagros forests cover 5 million hectares and consist 40% of Iran's forests (Sagheb-Talebi et al., 2003). They influence on water supply, soil conservation, climate change and socio-economical balance of the country. Also they are one of the most important biologic sources and genetic reservoirs of the country (Tavakoli, 1996). Forest stand structure is a key element in understanding forest ecosystems. One of the major components of forest stand structure is the spatial arrangement of tree positions (Kint et al., 2004; Wolf, 2005). Spatial information for individual trees is increasingly sought by forest managers and modelers as a means to improve the spatial resolution and accuracy of forest models and management scenarios (Wulder et al., 2004). Generating hypotheses relating to the structure of ecological communities is the aim of spatial pattern recognition. How trees are located on an area in relation to their neighbors affects stocking and the subsequent growth of individual trees and yield of the stand (Jayaraman, 2000). There are three basic spatial patterns as following: clumped, random and dispersed (Fig. 1) (Mitchell, 2005). A dispersed pattern is usually most desirable where timber production is the main stand management objective. More random or clumped patterns may be more desirable where wildlife habitat enhancement is a major management goal (Anonymous, 2003). For forest communities sampling, an alternative is using distance (plotless) methods.
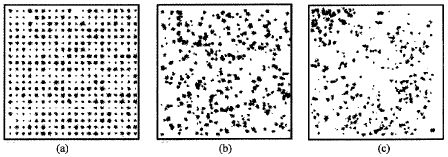 | |
| Fig. 1: | Three basic spatial patterns including: (a) dispersed, (b) random and (c) clumped (Anonymous, 2003) |
Distance sampling techniques were developed to obtain a rapid estimate of forest parameters by ecologists. These methods are more efficient than quadrat sampling, since searching and counting individuals in quadrat samples is very time-consuming (Lo and Yeung, 2007). Regarding to the importance of Zagros forests and spatial pattern analysis as a criterion for forest monitoring and management planning, the spatial arrangement of trees in Zagros was studied in this research and a practical method was recommended to determine it.
Heidari (2006) used Hopkins index to determine spatial pattern of trees in Zagros forests. He concluded that the trees were arranged in a clumped pattern in his study area. Alavi (2004) used a combination of quadrat-variance and plotless methods and resulted that the spatial pattern of Elm tree (Ulmus glabra) was clumped in hyrcanian forests in the north of Iran. Pourbabaee et al. (2004) studied the spatial pattern of Maple trees in the north of Iran. Neeff et al. (2005) made a point map of old trees in Amazon forests and used it to determine the spatial pattern. Wolf (2005) used spatial pattern analysis to study changes in natural deciduous forests. Nelson et al. (2002) located tree positions and used nearest neighbor index to determine spatial arrangement of trees.
MATERIALS AND METHODS
Study area: A 30 ha plot was selected in Servak forests in Kohgiluyeh Va Buyer Ahmad Province next to Yasuj city (Fig. 2). According to the statistics, 82% of rainfall occurs in the second half of the year and the mean annual rainfall is 902.9 mm. The site is 1880 m above sea level and five months of the year is in dry season.
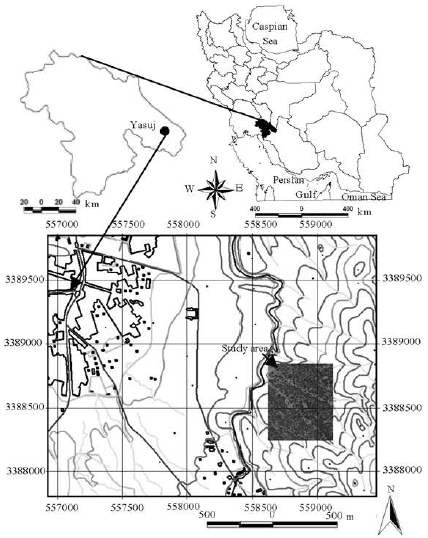 | |
| Fig. 2: | The location of study area in Iran |
These characteristics have an important role in the formation of open forests in Servak. Persian oak (Quercus brantii var. persica) is the most abundant tree species in the study area (99.85% of all trees) and other species are Azarole (Crataegus aronia), Maple tree (Acer monspessulanum) and Pistachio (Pistacia atlantica) (Sabeti, 2002; Jazirehi and Rostaghi, 2003).
The point map of tree locations: An ideal statistical summary of a forest would be a complete description of the spatial distribution of its trees (Scheuder et al., 1993). The spatial arrangement of trees can be investigated by the map of tree locations in the area. This map is obtained in two different ways. The first treatment considers the mapped positions of plants and deals with only two elements, the continuous background of the plane itself and dimensionless points representing the plants. The second treatment is to treat the plane as a mosaic of discrete non-overlapping continuous domains, each of which is classified as belonging to a particular type of phase (Dale, 1999). The first approach was used in this research.
In the study area that was 30 ha (500x600 m), 24 west-east lines were imagined. The distance between the lines was 25 m. The vertical distance of each tree and its distance from the first of each line were measured (Fig. 3). The point map of tree locations was obtained (Anonymous., 1996). Due to the UTM (Universal Transverse Mercator) coordinates of the starting point, the coordinate of each tree is obvious.
Spatial pattern analysis method: There are different methods to study the arrangement of points that show the position of trees in an area. Some of them are Quadrat analysis (overlaying areas of equal size), nearest neighbor index (calculating the average distance between points) and K-function (counting the number of points within a defined distance) (Mitchell, 2005). Quadrat analysis suffers from certain limitations. This analysis may be insufficient to distinguish certain point patterns. The other main limitation of quadrat analysis in mapped-point pattern analysis is the size of quadrats that may affect the results (Wong and Lee, 2005). Also K-function has a disadvantage when the defined distance becomes large. Determined patterns in this circumstance are suspect because of edge effect. Points near the edge are likely to have fewer neighboring points within the distance and it affects the results (Mitchell, 2005). Regarding to the description of these two methods, nearest neighbor index was selected to use in this research for the total map of study area.
This index measures how similar the mean distance is to the random mean distance. To calculate it, the average distance of each point to its nearest neighbor in observed distribution is divided by the average distance in random distribution that is called r. Also the difference between the average distance in observed distribution and random distribution can be criterion to judge about spatial point pattern that is demonstrated by d (Table 1).
A point pattern may seem clumped or dispersed visually or by calculating its d and r but this result should be confirmed by a statistical test. In the test used for this purpose, a z-score is calculated. This score indicates that the difference between the observed and random distribution is statistically significant or not. If this score changes between -1.96 and +1.96 (confidence level of 95%), it is concluded that there is no significant difference between the observed and random distribution statistically although d and r show clumped or dispersed pattern. However, greater amounts of z-score show significant difference between observed and random distribution (Lee and Wong, 2001).
Distance methods for data sampling: For forest communities sampling, an alternative is using plotless (distance) methods. Distance sampling techniques were developed to obtain a rapid estimate of forest parameters by ecologists. These methods are more efficient than quadrat sampling, since searching and counting individuals in quadrat samples is very time consuming and it has disadvantages mentioned above (Lo and Yeung, 2007). Among a number of distance-sampling procedures that have been introduced for spatial pattern analysis, a method called T-square sampling provides a powerful index of pattern analysis.
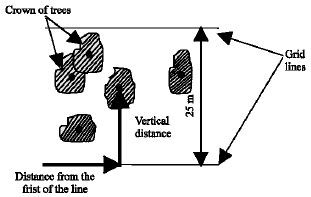 | |
| Fig. 3: | The position of trees survey |
| Table 1: | Spatial pattern determination by calculating d and r |
 | |
This method requires to measure two distances at each sampling point that are: the distance from the point to the nearest individual and the distance from that individual to its nearest neighbor (Fig. 4).
The index of spatial pattern obtained by T-square sampling (C) is calculated by the following equation and is tested by z-score. The results are compared with the random pattern (Table 2).
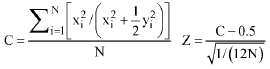 |
The second distance procedure that was used in this study is Index of dispersion which has been shown to be a powerful index of spatial patterning. This method is based only on point-to-individual distances and the index (I) is calculated by its equation and is tested by z-score. The results are compared with the random pattern (Table 2) (Ludwig and Reynolds, 1988).
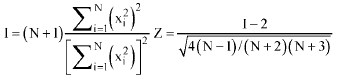 |
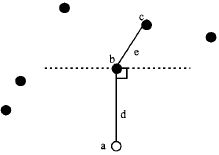 | |
| Fig. 4: | T-square sampling procedure: (a) is the sampling point, (b) is the nearest feature, (c) is the nearest neighbor to the nearest feature, (d) is the distance from sampling point to the nearest individual and (e) is the distance from the individual to its nearest neighbor |
| Table 2: | Spatial pattern determination by calculating C and I |
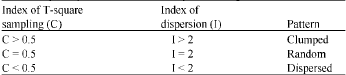 | |
As recommended in different studies, the two mentioned distance methods are studied in this research to find out the more suitable one for spatial pattern analysis in forest communities.
Sampling points: Statistical sampling is one of the basic techniques for collecting the information needed in forest management planning. Due to different aspects of sampling methods, the systematic sampling was used in this research. This method guarantees a good distribution of samples over the study area that practical experience has proved it (Zobeiri, 2005). So a 100x100 m grid with 30 sample points was designed and overlaid on the map of study area. The necessary distances were measured in each sample point.
Software: In this study, ArcView GIS 3.2a (ESRI, Redlands, CA) was used for tree stem map making, nearest neighbor index calculation and performing distance methods. PC ArcInfo 3.5.2 (ESRI, Redlands, CA) was used to make the sample plot grid.
RESULTS AND DISCUSSION
The map of points that show the position of trees in the study area was obtained (Fig. 5). This map was analyzed by nearest neighbor index and the necessary parameters were calculated (Table 3). As mentioned before, 30 sample points in a 100x100 m grid were overlaid on the map (Fig. 5). As demonstrated earlier, the distance from sampling point to the nearest tree and the distance from the nearest tree to its nearest neighbor were measured in each sample point (Fig. 6). Then the indices of C and I were calculated and tested by z-score (Table 4).
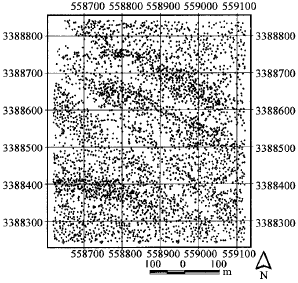 | |
| Fig. 5: | The point map of tree locations in the study area that the sample points are shown on it |
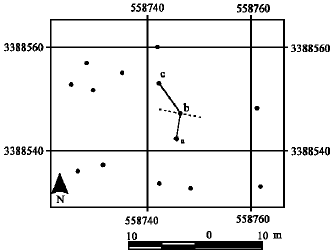 | |
| Fig. 6: | |
| Table 3: | The results of nearest neighbor index calculation |
 | |
| Table 4: | T-square and dispersion indices |
 | |
The analysis of spatial pattern is one way to distinguish between the different factors acting on forest ecosystems (Wolf, 2005). Also monitoring changes in spatial pattern is a suitable indicator for following the achievements of management in the forest stands. Regarding to the importance of spatial pattern of trees, especially in degraded Zagros forests, the objective of this study was to develop a practical method for spatial pattern analysis. Due to the circumstances of Zagros forests, it is necessary to figure out their spatial pattern in order to use it in forest management planning, forest monitoring, preventing degradation, livestock grazing and non-irrigated farming control and conservation. The kind of data that will be used for spatial pattern studies is mapped plant positions within a defined study area or plot. In using the point pattern approach, complete mapping is the best sampling method. So a 30 ha plot in Zagros forests was inventoried by full callipering method. Regarding to earlier demonstrations, the nearest neighbor index (r) was used to determine the spatial arrangement of trees in the study area. The amount of this index (r) was 1.26 for all the study area and the difference of observed and random mean distances (d) was 1.21 (Table 3). According to the classification of the index (r) and the difference (d), it is concluded that the spatial pattern of study area is dispersed (Table 1).
As explained earlier, it is necessary to confirm the results of nearest neighbor index by z-score calculation. This score was 29.283 for the study area (Table 3). It is not between -1.96 and +1.96 so the spatial pattern of the study area is significantly different from random pattern. When this score is greater than +1.96, it shows that the arrangement of points is dispersed. So the statistical test proves the result of nearest neighbor index.
In order to recommend a practical method to study the spatial pattern of trees, two main distance methods were compared. The index of spatial pattern (C) derived from T-square sampling was 0.3904 in the study area. This index is 0.5 for random pattern and it is less than 0.5 for the study area so its pattern is dispersed (Table 2). To test the significance of C, the z-score was calculated and it was 2.0873 (Table 4). It is greater than 1.96 so the pattern is significantly non-random. The index of dispersion (I) was 2.0746 for the study area. This index is 2 for random pattern and it is more than 2 for the study area so its pattern is clumped (Table 2). Although it is greater than 2 but the difference is very small (0.0746) so it may be random. The z-score was 0.2263 (Table 4). It is less than 1.96 so there is no significant difference between the observed and random pattern (Mitchell, 2005; Wong and Lee, 2005).
Heidari (2006) studied spatial pattern in Zagros forests. Although his study area was similar to the study area of this research due to the dominant species (Persian oak), structure (coppice) and location (Zagros forests), he used Hopkins index and concluded that the arrangement of trees is clumped. The validity of Hopkins index depends on obtaining a true random selection of individuals to compute the index. So, it makes Hopkins index impractical because using random points is not a legitimate procedure in distance sampling in a field survey.
CONCLUSION
The nearest neighbor index was used for a 30 ha study area in Zagros and the results showed that the pattern is dispersed. It is not possible to perform a full callipering survey because of cost and time in many researches. In order to choose a suitable practical method to study spatial pattern of trees in the study area or forests with similar characteristics, the indices of C and I were compared. The results showed that I could not detect the spatial pattern of trees in the study area but C determined the pattern correctly according to the results of nearest neighbor index in the study area. So it is recommended to use T-square in a systematic sampling to compute C for spatial pattern analysis in the study area or forests with similar characteristics.
REFERENCES
- Kint, V., D.W. Robert and L. Noel, 2004. Evaluation of sampling methods for the estimation of structural indices in forest stands. Ecol. Modell., 180: 461-476.
Direct Link - Ludwig, J.A. and J.F. Reynolds, 1988. Statistical Ecology. John Wiley and Sons, USA., pp: 37-39.
Direct Link - Nelson, T., K.O. Niemann and M.A. Wulder, 2002. Spatial statistical techniques for aggregating point objects extracted from high spatial resolution remotely sensed imagery. Geogr. Syst., 4: 423-433.
Direct Link - Wolf, A., 2005. Fifty year record of change in tree spatial patterns within a mixed deciduous forest. For. Ecol. Manage., 215: 212-223.
CrossRefDirect Link - Wulder, M.A., K.O. Niemann and T. Nelson, 2004. Comparison of airborne and satellite high resolution data for the identification of individual trees with local maxima filtering. Int. J. Remote Sens., 25: 2225-2232.
Direct Link