
S. Modallaldoust
Department of Watershed Management, University of Mazandaran, Iran
F. Bayat
Researches and Sciences Unit, Islamic Azad University of Tehran, Iran
B. Soltani
Mazandaran Administration, Islamic Republic of Iran Meteorological Organization
K. Soleimani
RS and GIS Center, University of Mazandaran, Iran
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 8 | Page No.: 1471-1478







ABSTRACT
A watershed management program is usually based on the results of watershed modeling. Accurate modeling results are decided by the appropriate parameters and input data. Precipitation is the most important input for watershed modeling. Precipitation characteristics usually exhibit significant spatial variation, even within small watersheds. Therefore, properly describing the spatial variation of precipitation is essential for predicting the water movement in a watershed. This study is concerned with mapping annual precipitation in Jam and Riz watershed of Iran, from sparse point data using Inverse Distance Weighting (IDW) method. The objective in the optimization process is to minimize the estimated error of precipitation. Thus the performance of each interpolation was assessed through examination of mapped estimates of elevation. The results show that the estimated error is usually reduced by this method. Particularly, when optimized exponent in IDW method was selected for digital elevation model which, is secondary variable for the annual average precipitation gradient equation. It was conclude that IDW-3 with the best conditions and lowest mean standard error provides the most accurate estimates of precipitation.
PDF Abstract XML References Citation
How to cite this article
S. Modallaldoust, F. Bayat, B. Soltani and K. Soleimani, 2008. Applying Digital Elevation Model to Interpolate Precipitation. Journal of Applied Sciences, 8: 1471-1478.
DOI: 10.3923/jas.2008.1471.1478
URL: https://scialert.net/abstract/?doi=jas.2008.1471.1478
DOI: 10.3923/jas.2008.1471.1478
URL: https://scialert.net/abstract/?doi=jas.2008.1471.1478
INTRODUCTION
Spatial interpolation methods are widely used in creating continuous environmental data sets from network of sparsely sample points (Cooper and Jarvis, 2004). In particular, they have been employed to build continuous representations of terrain, soil composition, terrestrial, atmospheric pollution and climate variables (Heuvelink and Webster, 2001; Hutchinson and Gallant, 1999; Jarvis and Stuart, 2001a, b; Kurtzman and Kadmon, 1999; Mitas and Mitasova, 1988; Oliver and Khayrat, 2000; Oliver and Webster, 1990; Philip and Watson, 1982). Maps of precipitation have a wide range of applications and many different interpolation procedures have been used to drive maps from collected as part of monitoring networks (Hutchinson, 1995). There has been a range of studies which compared different algorithms for deriving estimates of precipitation from point data (Bastin et al., 1984; Tabios and Salas, 1985; Hevesi et al., 1992a, b; Hutchinson, 1998a, b; Hay et al., 1998; Pudhomme and Reed, 1999; Goovaerts, 2000; Gomez-Hernandez et al., 2001; Hofierka et al., 2002), also several more recent geostatistical textbook are available (Isaaks and Srivastava, 1989; Cressie, 1991; Goovearts, 1997; Armstrong, 1998; Chiles and Delfiner, 1999; Webster and Oliver, 2000; Wackernagel, 2003) that describe in more detail these algorithms. The inverse distance method, which is also called the Inverse Distance Weighted (IDW) interpolation, is a general technique for interpolating (Ware et al., 1991). The basic equation, Eq. 1 for the inverse distance method is:
| (1) |
where, ki is the control value for ith sample point, wi represents a weight determining the relative importance of individual control point ki in the interpolation process, Kxy is the point to be estimated and N is the number of sample points (Bartier and Keller, 1996). This concept is also commonly applied to estimate average precipitation and interpolate unknown rainfall. In the case, when each control point has the same relative importance, the inverse distance method is identical to the arithmetic average method for estimating precipitation (Ashraf et al., 1997). Using this approach, wi is equal to 1 for the several control points nearest to the point to be interpolated, or for the set of control points within some radius of the point being interpolated and wi is given by 0 otherwise (Meyers, 1994). An alternative weighting strategy near points more influence than distance points is based on a formula using the inverse of distance to a power, such as Eq. 2:
| (2) |
where, dxy is the distance between Kxy and ki and m is an exponent given by the users and also named the order of distances (Deraisme et al., 2001). As the exponent becomes larger distances from the location becomes smaller. In other word, as the value of the exponent is increased, the estimate at a given location becomes more similar to the closest observations (Burrough and McDonnell, 1998). The inverse distance method is flexible due to the adjustable nature of the order of distances (Ghohroudi, 2006) Eq. 1 can be rewritten as:
| (3) |
Also, the weighting factors, wi, which represents the relative influence, can be defined as Eq. 4. The sum of the weighting factors of each rainfall gauging station in the neighborhood is equal to one (Sullivani and Unwin, 2003).
| (4) |
After determining the weighting factors, the average precipitation can be estimated. The basic calculation of the IDW interpolation for estimating precipitation is expressed as Eq. 5:
| (5) |
where, Pp is the interpolated precipitation in the area p; Pi is the precipitation of rainfall gauge i; wi is the weighting factor that represents the relative influence of gauging station i and dpi is the distance between the area p and the rainfall gauge i (Chang et al., 2003). The IDW interpolation is univariate with a single influence factor, namely horizontal distance. This technique assumes that the interpolation area is uniform rather than variable (Hodgson, 1989). Therefore, it cannot be applied in an area with abrupt changes in elevation, which would create a major obstacle to estimating unknown information (Lloyd, 2005). Subsequently, precipitation multivariate IDW interpolation, a modified version for considering additional independent variables, was developed to improve upon the previous method. The modified equation can be given by Eq. 6:
| (6) |
where, the weights wi are determined by the variables vi… vx. A multivariate version based on Eq. 3 can be redefined as Eq. 7:
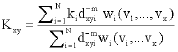 | (7) |
The data value independency and the pure linearity of IDW enabled isolating the effects of missing data on the variation in mapping accuracy from the effects of the nonlinearity and data value dependency (Yuval et al., 2005). In this equation, it is assumed that there are two independent weights (horizontal distance and elevation difference), represents the influence of all other factors (Chang et al., 2005).
MATERIALS AND METHODS
Jam and Riz basin is located in 25 km toward North Kangan and Jam town and 220 km from Southern part of Boushehr Port. The geographical location of the study area is indicated 51°, 48’, 31.7″E. to 52°, 25’, 14″E. and 27°, 44’,28″N to 28°, 14’, 55″N (Fig. 1).
The area of the basin was estimated as 90919.2 ha using Arc GIS 9.2 software. The highest point of the study area shows 1414 m and its lowest point is 57.764 m from the sea level (Modallaldoust, 2007). Annual precipitation investigation shows that maximum precipitation in Baghan station have been 724.5 mm and minimum value in Ghantareh station have been 82 mm. The study of coefficient of variation represents disorderly rainfall in the region. Seasonal distribution of rainfall in the region, clears that rainfall regime is base on Mediterranean regime. It means, more than 60% of annual precipitation is in winter and summer with only 1% annual precipitation is driest season. Monthly precipitation regime represent that maximum rainfall happens in January and December, respectively. June and July are month with lowest rainfall.
Following materials and methods have been used in this research:
 | |
| Fig. 1: | Geographic location of Jam and Riz watershed |
| • | Topographic maps at 1:250000 scale of 1999 from the Iranian Geographical Organization. |
| • | Topographic maps at 1:25000 scale of 2001 from the National Cartographic Centre of Iran. |
| • | Climatic statistics and data, prepared by researches organization of water resources. |
Determining the optimized digital elevation model using interpolation method of IDW: First, they have scanned as topographic maps and then georeferenced in Erdas Imagin 9.1 software. The border of basin which was already limited on the mentioned maps traced in ArcView3.2a environment and then border vector layer was prepared. In next stage between 15156 elevations points of the base map 10637 points were selected to consider the basin border in the form of digital which was occurred during the process. These points were gained from ground control using Global Positioning System (GPS) during 2003 to 2004 period in the study area. These numbers of elevation points were selected to cover out of the study area. The reason is related to the accurate results from the used model of DEM. In this method, two factors such as neighbor points and point searching radius assumed as model variables. Weight standard distance which is searching radius of standard ellipse (Fig. 2) calculated in ArcView3.2a by Spatial Analysis Extension automatically. During the past three decades, models that solve the catchments and or solute transport equations in conjunction with an optimization technique have been increasingly used as watershed management tools (e.g., Rizzo and Dougherty, 1996; Minsker and Shoemaker, 1998; Zheng and Wang, 2002; Mayer et al., 2001). Simulation-optimization models have been developed for a variety of applications. Standard ellipse is an appropriate way to show the spatial protection of points group (Greene, 1991) but in geographic view the points group may have directional deviation. This problem is very important specially in preparing the numerical models by use of elevation points. In fact, elevation points in different directions to each other can represent several geomorphologic features of special area. The standard deviation ellipse was identified as follows (Fig. 3).
According to the mentioned methods, the model was tested with 4 categories of 3, 5, 7 and 15 dotted of neighbors points in two radius domains of standard searching circle and standard deviation ellipse. Therefore 8 digital elevation models were extracted. Then 10637 points equal to 10637 land dots evidence were driven for each model. Finally, the extracted points from each model using SPSS14 and by use of means difference test were compared with the land evidence point.
Identifying the means gradient of annual precipitation by use of existent database: In first stage the total existent stations in Jam and Riz basin, which is about 103 stations, were prepared. Because of long distance and in according with climatic conditions, many of the stations omitted. Then 22 stations were selected. In second stage, reconstruction procedure for whole rain gauge stations was done by normal ratio method. The reason of selecting this method was it’s applicability in mountainous region, lower limitation and instability between data average during statistical period. In order to reconstruct the precipitation statistic, the normal ratio technique was used (Mahdavi, 2007a, b):
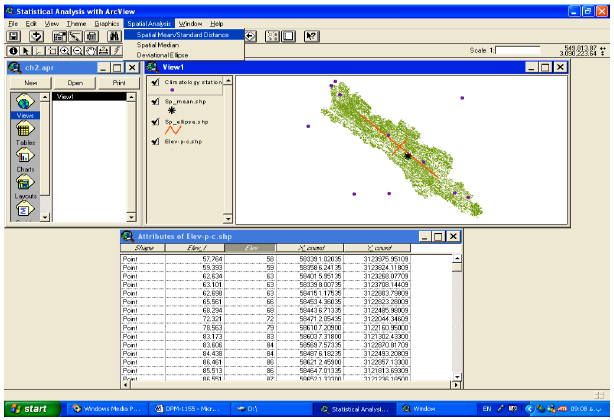 | |
| Fig. 2: | Using spatial analysis menu for production of weight standard distance |
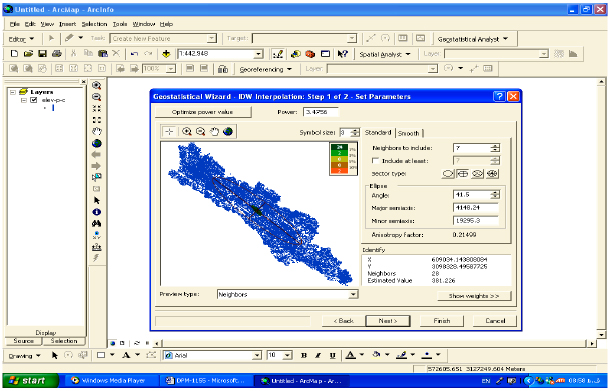 | |
| Fig. 3: | Standard ellipse and standard deviation ellipse for elevation point group |
| Table 1: | The values of annual precipitation of stations |
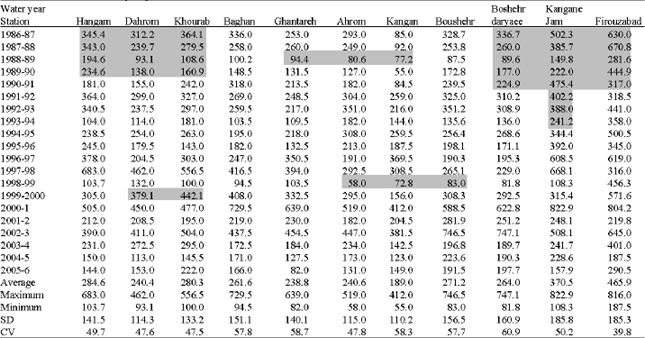 | |
| The No. of gray cells was reconstructed, SD: Standard deviation, CV: Coefficient of Variation | |
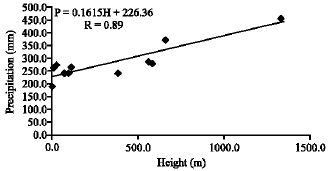 | |
| Fig. 4: | The annual precipitation gradient of Jam and Riz basin |
| (8) |
where, Px is precipitation of deficient station in a regarded year, n is number of reference stations, ![]() is average precipitation in a deficient station with existent statistic,
is average precipitation in a deficient station with existent statistic, ![]() are average precipitations in reference station and are contemporary with statistic of deficient station, PA, PB are precipitations in reference stations of A and B in concerned year to complete the statistic of deficient station. It should be mentioned that between 22 stations the stations had short term statistic, did not contain in analysis and obviously they applied to conform achieved results and used as aid points in drawing the map. So, according to expert studies just 11 stations were selected and whole calculations and analyses about precipitation subject was done on 11 selected stations. The annual rainfall values of concerned stations have given in Table 1. After studying the concerned stations, means annual precipitation gradient equation of Jam and Riz basin achieved (Fig. 4).
are average precipitations in reference station and are contemporary with statistic of deficient station, PA, PB are precipitations in reference stations of A and B in concerned year to complete the statistic of deficient station. It should be mentioned that between 22 stations the stations had short term statistic, did not contain in analysis and obviously they applied to conform achieved results and used as aid points in drawing the map. So, according to expert studies just 11 stations were selected and whole calculations and analyses about precipitation subject was done on 11 selected stations. The annual rainfall values of concerned stations have given in Table 1. After studying the concerned stations, means annual precipitation gradient equation of Jam and Riz basin achieved (Fig. 4).
P and H: Are annual precipitation and height value base on millimeter and meter respectively. Finally, optimized digital elevation model put in place of elevation factor (H) in equation. So, for all Jam and Riz basin according to applied cells size net, the amount of rainfall in millimeter was calculated as digital precipitation model in Arc GIS 9.2 software.
RESULTS AND DISCUSSION
Spatial modeling of climate variables is of interest because many other environmental variables depend on climate. Accurate climate data only exist for point locations, the meteorological stations, as a result of which values at any other point in the terrain must be inferred from neighboring stations or from relationships with other variables (Marquinez et al., 2003). This technique (IDW), can obtain satisfactory results from limited data, based mainly on the geographic situation of the sampling points, on the topological relationships between these points and on the value of variable to be measured. Precipitation generally increases with elevation (Spreen, 1947; Smith, 1979) and so many authors have incorporated elevation into geostatistical approaches (Martinez-Cob, 1996; Goovaerts, 2000).
| Table 2: | The value of optimized power in digital elevation models |
| Table 3: | Test of compare means (paired t-test) for observation elevation value and elevation values of inverse distance weighting model |
 | |
Others have developed relationships between precipitation and various topographic variables such as altitude, latitude, continentally, slope, orientation or exposure, using regression (Basist et al., 1994; Goodale et al., 1998; Ninyerola et al., 2000; Wolting et al., 2000; Weisse and Bois, 2001). In this research the described expansion of elevation points set based procedure by two hypothesized of spatial dispersion and point's directional deviation was investigated using standard and standard deviation ellipses (Fig. 3). With an assessment of the necessary factors such as cell size in network (value 3), number of neighbor points (3, 5, 7, 15), standard radius (for standard ellipse) and ellipse rotation angle (in standard deviation ellipse), the optimized power was calculated for each one of 8 digital models automatically (Table 2).
According to this value and the represented factors, digital elevation models was prepared for the study area. With comparing the 10637 extracted points of 8 digital elevation models by SPSS14 which due to geographic coordinates is equal to 10637 land evidence points and using of means differences test, the best digital elevation model was obtained. The related results to this analysis are shown in Table 3. In fact, from the gained digital models the accurate one is a model which it’s resulted elevation points has the lowest difference with land elevation points. However it is logical that the data which do not have main differences to land observation in significant 5% is with most accurate. According to the Table 3, four elementary digital models, from IDW1 to IDW4, can not show the main differences with the land observations. To identifying that between 4 digital models which one is with high accuracy, it can be determined with the average of fault value in Table 3. It seems that this data are extremely similar but between them the IDW3 digital elevation model has the lowest RMSE of 27.68. On the other hand these conclusions show that digital earth data with standard ellipse had sensible response rather than standard deviation ellipse. He described data have spatial dispersion and the points contain lower directional deviation. However, it can concluded that, IDW3 digital elevation model with optimized power of 3.3 using IDW interpolation is the best digital elevation model for the study area of Jam and Riz basin in Iran which is recommended to used for the same catchments. Therefore, by putting the digital elevation model (IDW3), would achieved the optimized digital precipitation model in Jam and Riz basin.
REFERENCES
- Acık, L., M. Ekici and A. Celebi, 2004. Taxonomic relationships in Astragalus sections Hololeuce and Synochreati (Fabaceae): Evidence from RAPD-PCR and SDS-PAGE of seed proteins. Ann. Bot. Fennici, 41: 305-317.
Direct Link - Akan, H. and Z. Aytaç, 2004. Astragalus ovabaghensis (Fabaceae), a new species from Turkey. Ann. Bot. Fennici, 41: 209-212.
Direct Link - Aytac, Z., 1997. The revision of the section Dasyphyllium bunge of the genus Astragalus L. of Turkey. Turk. J. Bot., 21: 31-57.
Direct Link - Duman, H. and H. Akan, 2003. New species of Astragalus (sect. Alopecuroidei: Leguminosae) from Turkey. Botanical J. Linnean Soc., 143: 201-205.
Direct Link - Dural, H., O. Tugay, K. Ertuğrul, T. Uysal and H. Demirelma, 2007. Astragalus turkmenensis (Fabaceae), a new species from Turkey. Ann. Bot. Fennici, 44: 399-402.
PubMed - Duran, A. and Z. Aytaç, 2005. Astragalus nezaketae (Fabaceae), a new species from Turkey. Ann. Bot. Fennici, 42: 381-385.
Direct Link - Ekici, M. and Z. Aytaç, 2001. Astragalus dumanii (Fabaceae), a new species from Anatolia, Turkey. Ann. Bot. Fennici, 38: 171-174.
Direct Link - Ekici, M., D. Yuzbasioglu and Z. Aytac, 2005. Morphology, pollen, seed structure and karyological study on Astragalus ovalis Boiss. and Balansa (Sect. Ammodendron) in Turkey. Int. J. Bot., 1: 74-78.
CrossRefDirect Link - Ghahremaninejad, F. and L. Behçet, 2003. Astragalus subhanensis (Fabaceae), a new species from Turkey. Ann. Bot. Fennici, 40: 209-211.
Direct Link - Hamzaolu, E., 2003. Astragalus hamzae (Fabaceae), a new species from Central Anatolia, Turkey. Ann. Bot. Fennici, 40: 291-294.
Direct Link - Kandemir, N., H. Korkmaz and A. Engin, 1996. The morphological and anatomical properties of Astragalus barba-jovis DC. var. barba-jovis (Fabaceae). Turk. J. Bot., 20: 291-299.
Direct Link - Karagöz, A., N. Turgut-Kara, Ö. Çakır, R. Demirgan and Ş. Arı, 2007. Cytotoxic activity of crude extracts from Astragalus chrysochlorus (Leguminosae). Biotechnol. Biotechnol. Equipment, 21: 220-222.
Direct Link - Podlech, D., 1986. Taxonomic and phytogeographical problems in Astragalus of the Old World and South-West Asia. Proc. Royal Soc. Edinburgh Sect. B. Biol. Sci., 89: 37-43.
CrossRefDirect Link - Spellenberg, R., 1976. Chromosome numbers and their cytotaxomic significance for North American Astragalus (Fabaceae). Taxon, 25: 463-476.
Direct Link